
Abstract
Detecting objects on unmanned aerial vehicles is a hard task, due to the long visual distance and the subsequent small size and lack of view. Besides, the traditional ground observation manners based on visible light camera are sensitive to brightness. This article aims to improve the target detection accuracy in various weather conditions, by using both visible light camera and infrared camera simultaneously. In this article, an association network of multimodal feature maps on the same scene is used to design an object detection algorithm, which is the so-called feature association learning method. In addition, this article collects a new cross-modal detection data set and proposes a cross-modal object detection algorithm based on visible light and infrared observations. The experimental results show that the algorithm improves the detection accuracy of small objects in the air-to-ground view. The multimodal joint detection network can overcome the influence of illumination in different weather conditions, which provides a new detection means and ideas for the space-based unmanned platform to the small object detection task.
Introduction
The object detection technology under the air-to-ground field of view is a special but widely used application of multi-object detection technology. In air-to-ground applications, the scale of view is large, and therefore the target of interest tends to be rather small, which will bring new difficulties in object detection. 1 –4 In the military field, object detection can be directly applied to tasks such as battlefield investigation, situation analysis, air-to-ground target strike, and object tracking. In other civilian fields, air-to-ground object detection can be directly applied to various tasks, such as traffic monitoring, natural disaster analysis, and agricultural ecological management. The object detection in the air-to-ground scenario has the following characteristics.
In air-to-ground applications, the visual distance is always long, in which the target seems to be rather small, and less feature information can be involved. In air-to-ground views, targets tend to have only a few tens of pixels of information, and convolutional neural networks (CNN) have much less information available in feature extraction than in conventional life scenarios. At the same time, the air-to-ground target scene has a large field of view, and the detection target has many environmental changes (occlusion, background interference), so it is hard to acquire satisfied detection results.
In addition, in the dark environment, at night for example, the object contour is not clear, and the feature information is lost. The traditional single-mode (visible light) detection poses a severe challenge, which makes the detection task unable to adapt to different lighting conditions. With the increasing research on air-to-ground object detection technology based on deep learning, the target detection method seems to be maturing. However, as the scene and application environment become more complex, the traditional single-mode visible light detection problems are gradually becoming prominent.
Most of the early object detection is concentrated in the framework of traditional computer vision and image processing. In order to achieve the feature description of the object, scale invariant feature transform (SIFT), 1 histogram of oriented gradient (HOG), 2 speeded up robust features (SURF), 3 and other artificial design features play an important role. However, all the artificially designed features are difficult to obtain satisfactory results in complex background or subtle object detection and recognition applications due to their low dimension and insufficient target description. In recent years, the development of deep learning has provided us with an effective way of image description. With the advent of big data and the continuous development of high performance computing hardware, data-driven deep CNN have made great progress in feature extraction performance. In just a few years of development, feature extraction networks such as AlexNet, 4 VGGNet, 5 GoogLeNet, 6 ResNet, 7 and MobileNets 8 have been proposed, which laid the foundation for the goal detection task using deep learning. Based on the feature extraction network, the development of object detection technology based on deep learning has gone through two stages: the two-stage detection algorithm based on region proposal and the one-stage detection algorithm based on regression. The previous stage is represented by RCNN. 9 –11 Among them, Faster RCNN 11 improves the feature extraction mechanism of Fast RCNN based on RCNN and combines multitask loss optimization with regional proposal network which achieves an end-to-end detection network. It can achieve real-time performance of object detection better than other RCNNs. In order to further improve the real-time performance of object detection, the You Only Look Once (YOLO) 12 algorithm is proposed outside the RCNN framework. This method abandons the process of Faster RCNN regional proposal and performs regression calculation on the randomly generated bounding box. This end-to-end detection further improves the real-time performance of the object detection algorithm. However, due to the constraints of its network structure, the typical YOLO algorithm encounters difficulties in performing small object problems. The emergence of Single Shot Multi-Box Detector (SSD) 13 algorithm overcomes the inherent defects of YOLO algorithm and effectively improves the performance of small object detection. A typical SSD detection network can be divided into two parts: a feature extraction subnetwork in the front end and a detection subnetwork in the back end. On the detection subnetwork side, the SSD combines the anchor idea of the Faster RCNN with the regression idea of YOLO, which generates a priori frames on six different scale feature maps for prediction, thus enriching the feature scale of the detection. Different feature maps have different receptive fields after convolution operations. Feature maps of different scales can predict boxes of more scales. However, due to lack of semantic information, shallow feature maps still have low detection performance, which limits its application.
In this article, a new network structure is designed based on the original SSD with the air-to-ground small object detection as the entry point. At the same time, based on the complementarity of infrared radiation (IR) and visible light images in practical applications, from the perspective of multimodality, the experimental study of multimodality detection under different illumination conditions is carried out. The main contributions of this article are: In order to achieve the object detection task under different day and night conditions, this article integrates the long wave infrared and visible light data collected by the laboratory to produce a multimodal detection data set. A new object detection model is proposed to correlate different receptive field feature map information to improve the accuracy. Using the cross-modal conception, the IR image and the visible light image are jointly trained to realize the detection function under different illumination conditions. For example, under the condition of weak illumination at night, visible light can use less feature information, detection often fails, and temperature-sensing infrared image detection becomes more advantageous.
Related work
Using contextual relationships to assist object detection is a hot research direction of deep learning detection algorithms. For example, in the works of Chen et al. 14 and Liu et al., 15 the ContextNet and ParseNet are proposed, respectively, which can improve the detection ability of small objects by merging the object feature map information and the lower level feature maps which have the object context information. Zhao et al. 16 propose a PSPNet, which uses different pooling operations to generate feature maps of different receptive field sizes and then combines to increase the small object detection capability. In general, the mainstream method to improve the performance of small object detection is to generate feature maps of different size receptive fields and integrate context information to increase the accuracy of detection. For machine vision, the receptive field characterizes the range of perception of the image. As shown in Figure 1, when the target receptive field is small, it is affected by the imaging field of view, and less information is obtained by using the small receptive field, which is easy to cause misclassification (considered as a car). However, when expanding the receptive information and making full use of the target’s more surrounding information and scene information, it is more effective to distinguish the real category of the object. In Figure 1(a), a boat parked by the lake and in Figure 1(b), a car on the road and it’s shaded by trees.

Different receptive field information in object detection.
The SSD model is a network that naturally uses different receptive field information formed by different scales to be detected. According to the limited calculation sources, we choose the faster SSD as the basic framework in our air-to-ground applications. The structure of SSD is shown in Figure 2.

SSD structure. SSD: Single Shot Multi-Box Detector.
The SSD network model consists of a feature extraction subnetwork and a detection subnetwork. The feature extraction subnetwork is usually a traditional convolutional network such as VGG16 and ResNet. A large number of improved models are proposed based on the unique structure of SSD network, such as FSSD 17 which combines the feature extraction subnetwork low-level feature map and high-level feature map. And the fine-grained feature map is beneficial to the robustness of the detection algorithm. Benefiting from the unique structure of the SSD detection subnetwork, several feature fusion methods were proposed by using the context information. For example, RFBNet 18 and RUN 19 use the inception and ResNet network structures, respectively. They use the multibranch convolution to simulate the change of the receptive field and join the residual module to improve the ability of the feature extraction. Another version is the fusion of feature maps, such as DSSD 20 and RON, 21 which use the FPN 22 framework to fuse different semantic information (as shown in Figure 3(a)). In addition, DSOD, 23 RRC, 24 and RSSD 25 fuse the deep feature map with the shallow feature map (as shown in Figure 3(b)) by using the deconvolution and pooling tricks. It enriches the fine-grained and topological information of different size feature maps.

The mainstream way of SSD feature association. SSD: Single Shot Multi-Box Detector.
In deep learning algorithm, it’s highly depending on training data. The well-known Pascal VOC and Microsoft COCO can be used in object detection tasks, whereas in air-to-ground applications, data sets are affected by the brightness conditions, and the number of concerned objects is relatively few than that in VOC and COCO. Air-to-ground data sets are always based on visible light cameras. Since there are no official data sets in multiple modalities, it is impossible to realize multi-weather detection tasks in different environments, without specialized air-to-ground data sets. In artificial perception field, the multimodal fusion is considered as an effective way to enhance the information completeness of the environment. 26 The multimodal fusion attracted attentions in various applications, such as material retrieval, 27 image annotations, 28 and robotic perception. 29 Actually, the air-to-ground detection process is rather a similar process of robot perception, thus this article presents a novel object detection method by using multimodal observations.
Multimodal detection and feature association detection model
In poor brightness conditions, the use of temperature distribution to characterize the infrared image of an object has great advantages in target description. Therefore, it is urgent to establish a multimodal detection model compatible with visible and IR images. Whereas, infrared thermal image characterizes the temperature distribution of the scene and has no stereoscopic sense, so the resolution is low and the resolution potential is poor for human eyes. On the other hand, due to the thermal balance of the scene, long wavelength, long transmission distance, and atmospheric attenuation, the infrared image has strong spatial correlation, low contrast, and blurred visual effects. Therefore, using deep learning algorithm to describe IR image is a valuable work. The fusion of IR and visible light is visualized by using picture-in-picture method directly, and it can combine visible light and infrared information to enrich the purpose of the characterization. As shown in Figure 4, under daylight conditions, visible light data can clearly represent the contour and feature information of the target. Under this kind of circumstance, it is more suitable for visible light image. When the light is dark, visible and IR fused picture-in-picture data sets can compensate for the loss of characteristic information of visible light data set due to insufficient light. And when the nighttime illumination information is seriously insufficient, the visible light target almost disappears, and infrared imaging can play an important role.

Comparison between white light images and IR images in different brightness environments. (a) Strong brightness conditions, (b) low brightness conditions, and (c) dark conditions.
Feature maps of different sizes represent different scale of receptive field, which can be utilized to build the contextual relationships. The general SSD object detection algorithm often learns the feature information from small receptive field to large receptive field by using multi-scale boxes in feature maps. But this class of learning methods pays less attention to the context-related problem. Reasonable use of different sizes to feel the relationship between the fields is beneficial to the object detection process. In traditional methods, the simple fusion method makes the network itself lack the filtering control ability. In Faster RCNN, YOLO, and SSD, the posterior feature map learns the information from the front layers, which is derived from the feedforward nature mechanism of the neural network. However, it is obvious that the information of back layer feature map can also affect the front layer features. This bidirectional associative feature map can better learn the deep topological relationship between different feature maps. In this article, combined with the unique structural relationship of SSD series detection network, an object detection algorithm for feature association learning is proposed. The feature correlation detection network is shown in Figure 5.

Feature association detection model.
The main structure uses a bidirectional feature information flow, and the core module is a gated convolution operation. The bidirectional feature information flow is divided into bottom-up and top-down parts. The bottom-up information flow (

The top-down propagation method of information flow is written in equation (2)
The two types of information are integrated in equation (3)

In the feature map




In the above formulations,
The loss function of the model is defined as follows
where N is the number of a priori boxes that match the default box. If N = 0, the loss is 0. c, g are the class label and box coordinate parameters of the ground truth. x, l are the predicted class labels and the box coordinate parameters. α is a trade-off parameter.
The optimization function of box regression loss is defined as follows
herein
The optimization function of confidence loss uses the softmax and is defined as follows
where
Experiments
In this article, the multimodal data sets are collected from white light camera and long-wave IR camera simultaneously. The same scene was measured in three different styles, which include white light, IR, and white-IR fused mode, as shown in Figure 6. In order to validate the environmental adaptability of detection algorithm, different light conditions are involved in our data sets. In this experiment, we choose a car and a bus as the concerned targets. The total number of data sets contains 1500 images, including 500 visible light images, 500 infrared images, and 500 fused images.

Three-mode images sampled simultaneously.
After the multimode data sets were sampled, they are trained and tested under the framework of the proposed detection network. Ubuntu 16.04 (64-bit) and the PyTorch framework are involved, and the NVIDIA GTX 1080 Ti graphics card (11G) is utilized. In order to evaluate the performance of the proposed algorithm, the Pascal VOC2010 verification standard 30 is adopted in the experiments. Where the accuracy object type is verified by the average accuracy, it’s defined as follows
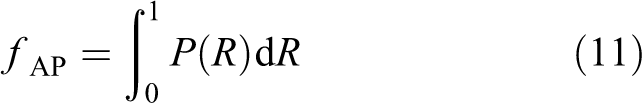
herein P is the accuracy and R is the recall rate. They are calculated as follows
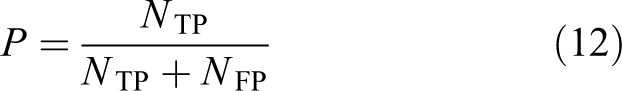

where

where N is the number of categories.
Before air-to-ground detection, it’s necessary to retrain the feature extraction subnetwork to improve the task description performance. When compared to the existed traditional feature description network, such as VGG16, the fine-tune process with the special data sets is able to improve the data adaptability. Therefore, this article utilizes the white light data set to validate the effectiveness of the proposed bidirectional network. And the results are shown in Table 1.
Comparison with traditional SSD series model.
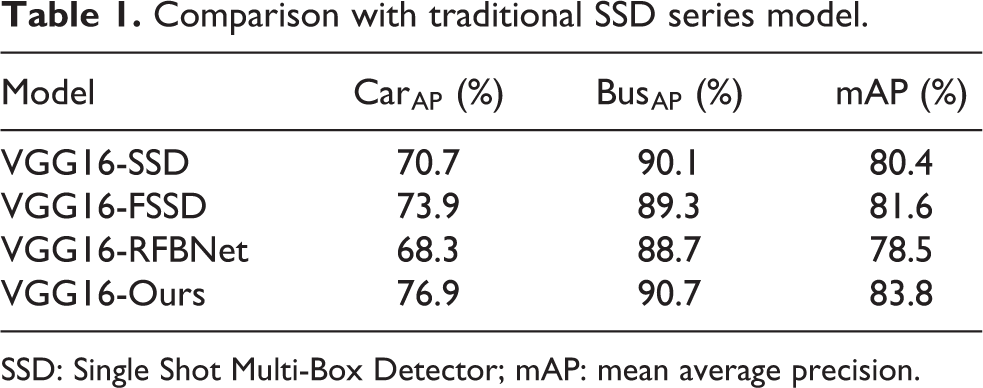
SSD: Single Shot Multi-Box Detector; mAP: mean average precision.
As illustrated in Table 1, we can find that the proposed model, which adopts the bidirectional structure, effectively improves the detection accuracy of air-to-ground small targets. In the following experiments, this article implements the proposed model in three different modal data sets. Herein, the data sets are divided into single-modal data set and multimodal ones. In the single-modal data sets, both the visible data sets and IR data sets are included. Firstly, we use the multimodal data set to improve the performance of single-mode detection. The evaluation of single-modal data sets is divided into visible light validation and IR validation. The contents of the two validation sets are consistent with that of multimodal data sets, which include visible light, IR, and fused data sets. Then the multimodal and single-modal data are respectively performed. The experimental results are shown in Tables 2 and 3.
Comparison of single-mode IR image training and three-modal joint training.

mAP: mean average precision.
Comparison of single-mode visible light image training and three-modal joint training.

mAP: mean average precision.
As described in the above results, we can easily find that the fusion of multimodal features is beneficial to the object description. And the utilization of multimodal data sets can effectively improve the detection performance compared to the single-modal data set.
In order to show the advantages of the IR and the multimodal observation, especially when the brightness environment is poor (weak brightness), we implement the detection experiments in the data sets collected in the low-light conditions. The experiment results are shown in Table 4.
Detection results in weak brightness conditions.

mAP: mean average precision.
From the above results, we can find that the low-light data set verification accuracy for visible light alone is not as high as the picture-in-picture data set. The fused modal data sets that combines visible light and IR can effectively solve the problem of detecting weaker scenes. For the sake of simplicity, the visible results of the detection experiments in weak brightness conditions are shown in Figure 7.

Visualization of the fused modal (top) and IR (bottom) image validation sets.
From the visualization results in Figure 7, it can be seen that the introduction of IR images makes the target features clearer under both low-light conditions and dark conditions. In addition, due to the utilization of infrared sensors, the air-to-ground detection also shows better robustness under the occlusion of trees and other objects.
Conclusions
Air-to-ground object detection are of critical technologies in various application in either military or civilian fields. In aerial observations, the information of target itself is inadequate to interference from large visual complex image. Besides, in case of light deficiency, the performance of object detection based on single-mode visible light is seriously degraded. In order to solve the aforementioned two problems, this article provides improvements from both network structure and data sets. Based on the context, the target detection network with feature association is designed. Infrared imaging is combined with the data sets of two different imaging mechanisms of visible light to produce multimodal data sets. The final experiments validate the effectiveness of the network design and the robustness of the multimodal data set under different brightness conditions, which provides a new effective manner for the aerial detection tasks.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Natural Science Foundation of China (grant nos. 61673017, 61403398) and the Natural Science Foundation of Shaanxi Province (grant nos. 2017JM6016, 2018ZDXM-GY-039).