
Abstract
Stereoscopic correspondence matching is applied in many applications like robot navigation, automatic driving, virtual, and augmented reality by reconstructing the scene in three-dimensional environments. In the most real scenes, the moving objects attract more attentions than static objects and background. Thus, temporal information of consecutive frames like motion flow has been proven to improve the matching accuracy as weight prior. In this article, we propose a cost-aggregation method joining object flow and minimum spanning tree-based support region rather than aggregating on fixed size windows. However, directly combining object flow and minimum spanning tree filtering is not straightforward, due to the extremely high computing complexity. The proposed scheme implements nonlocal cost aggregation with object-based optical flow, which extends the idea of the minimum spanning tree and flow-based motion estimation to increase the matching accuracy. Temporal evidence of object flow is not only used in minimum spanning tree support region building but also incorporated with one hybrid edge prior to optimize the disparity estimation. The experimental results with synthetic stereo videos show that the proposed method outperforms other state-of-the-art stereo matching methods in most data sets. The whole stereo correspondence algorithm achieves competitive performance in terms of both accuracy and speed. We also illustrate the performance of the proposed method with the Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) benchmark as one extensive comparison.
Introduction
Correspondence matching between pairs’ images, termed stereo matching, is a significant respect of visual-based applications such as three-dimensional (3-D) reconstruction, automatic driving, and robotic navigation. Exactly, stereo matching approach defines the horizontal offsets between the correspondence paired images. The offset, namely disparity, represents the 3-D parameters in 3-D reconstruction, which could be converted to depth. Indicated by Scharstein and Szeliski, 1 a stereo matching method generally consists of four steps as costs computation, costs aggregation, disparity determination, and disparity refinement. Cost aggregation is the most important one among these steps, in order to improve the accuracy of disparity estimation for most local methods 2,3 and global methods. 4,5 Cost aggregation is also considered as filtering over the cost volume, termed as disparity space image. Traditional cost aggregation methods perform as image filters and blur the depth boundaries during cost aggregation. Thus, edge-preserving filters such as bilateral filter 6 and guided image filter 7 are introduced for cost aggregation. Yoon 8 adopted the bilateral filter to adjust the support-weights of the pixel in a given support window to reduce image ambiguity. Several papers have proposed some effective strategies. Recently, Yang 9 proposed a nonlocal cost aggregation (NLCA) scheme based on pixel similarity on a minimum spanning tree (MST) structure, in order to improve the matching accuracy and computational efficiency. The MST structure combined the advantages of both the local and the global methods. In addition, segmentation was also integrated NLCA framework, which was faster and more accurate than the guided image filter. Mei et al. 10 improved the NLCA by incorporating image segmentation in the tree construction procedure. This results in the new tree structure, which is termed segment tree (ST). In practice, this tree can be efficiently built in time nearly linear to the number of the image pixels. Compared to MST, ST introduces some decision rules: the pixels in one consistent segment are more likely to share similar disparities, and therefore their connectivity within the segment should be first enforced in the tree construction. Zhang et al. 11 reformulated cross-scale cost aggregation for stereo matching. In general, human beings process stereoscopic scenes across multiple scales, which make it reasonable to aggregate costs across multiple scales rather than aggregating at the finest scale by conventional methods.
In this article, we propose a novel joint flow-based stereo matching algorithm. This is the first time that the temporal information contribute to MST building. In addition, we extended the NLCA framework and suggested a refinement technique to further improve disparity maps. According to abundant experimental results, the proposed flow-based MST (F-MST) method outperforms the state-of-the-art stereo matching methods, especially for the Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) dataset. The rest of this article is organized as follows. In section “Related works,” a review of existing stereo methods is introduced. In section “Proposed method,” the proposed F-MST stereo matching method is then presented. In section “Experiment and evaluation,” the experimental results are compared with those of existing stereo matching methods. Finally, section “Conclusion” provides some concluding remarks regarding this research.
Related works
In the practical applications like autonomous driving, moving objects in urban scene is the mainly concerning situation. The region with moving objects should be considered with higher priority than background. Different with the static scenes, the occlusion region of urban scenes changes dynamically in the consecutive frames. Most stereo matching methods make such one smoothness hypothesis: disparity of neighborhood region should be the same (or similar), except for depth boundaries. While Zhang et al. 11 and Cheng et al. 12 have recently demonstrated their impressive performance in this context, none of them explicitly takes advantage of the fact that temporal information could be considered as a to improve the cost aggregation in stereo matching. Meanwhile with motion estimation techniques, temporal information could be introduced to decrease the impact of occluded pixels in disparity maps. Similar to the full frame motion estimation method, Perez et al. 13 proposed one object flow motion estimation method, which calculates the flow vectors for each pixel inside an object, which distinguishes different objects according to the motion amplitude. Zhang et al. 14 proposed that temporal information, gathered from consecutive frames, had been proven to improve the accuracy of stereo matching, which also reflects the changes in occlusion region happened in the disparity discontinuity area.
In the NLCA method framework, the reference image I is treated as a four-connected, undirected graph G = (V, E). A pixel in I corresponds to a node in V, and an edge in E connects a pair of neighboring pixels. However, the aggregation over a tree structure generated from truncated edge weight will suffer from edge blurring effect since it assumes that disparity smoothens at every point. Due to this reason, appropriate priors must be employed to indicate the potential locations of the depth boundaries. Based on NLCA, Cheng et al. 12 proposed one crosstree structure, which adopts edge and superpixel priors tackling the false cost aggregation across the depth boundaries. But it only verifies edge and superpixel priors with static paired images, without considering the moving objects in the urban scene. Inspired by the NLCA method, Pham et al. 15 proposed one effective segment-simple-tree that is more adequate for outdoor driving images than the MST.
However, there are still some challenging problems for stereo matching algorithms, especially in dynamical scene. With these challenges, it is important for stereo matching algorithms to overcome those problems and generate an accurate disparity map. In this article, we propose a novel joint motion NLCA method with low computational complexity. To accomplish this, the proposed method employs object guided motion estimation and NLCA together, which integrates the motion flow into the disparity estimation for dynamic scenes. The proposed method, F-MST, is the first time that the flow map has been introduced to optimize the MST building and cost aggregation for acquiring accurate disparity maps in dynamic environments. Meanwhile, a hybrid edge prior which combines the edge prior and the superpixel prior is also proposed to restrain the edge fatten effect across disparity boundaries. In addition, the proposed stereo matching system including the object flow and F-MST aggregation step is implemented on a graphics processing unit (GPU) using the open computing language. Moreover, it is possible to achieve real time by implementing the algorithm on parallel devices like GPUs. Thus, our contribution in this article mainly focuses on the following three aspects: Introducing the temporal information with object flow to the MST building. Integrating Laplace edge and superpixels prior in cost aggregation. Quantitative evaluation of representative cost aggregation methods on three data sets.
Proposed method
First of all, the procedure of proposed F-MST approach is illustrated in algorithm 1, the object-guided motion estimation and NLCA are combined together to integrate the motion flow into the disparity estimation for dynamic scenes. The F-MST is the first time that the flow map has been introduced to optimize the MST building and cost aggregation for acquiring accurate disparity maps in dynamic environments. In this article, our method focus on motion flow-based cost aggregation and disparity post processing, which greatly impacts the speed and accuracy of such a stereo system.
Calculate the object flow f =(u, v) for Generate the initial cost volume Cd with subtraction by bilateral filtering (BilSub) and Census cost according to equation (1); Flow map segmentation with Laplace and superpixels prior; Build the MST with hybrid edge prior based weight; Cost aggregation on MST with two step; Disparity determination and refinement.
Matching cost computation
The proposed method basically involves four images: paired-images in t time

where
F-MST cost aggregation
Menze and Geiger
17
and Richard et al.
18
indicated that motion boundaries are more likely to occur at discontinuous area than smooth surface. In the traditional NLCA framework, the reference image I is treated as a four-connected, undirected graph

Is and Ir are the intensities of s and r, respectively. The set of edges
In F-MST framework, the reference image I is defined as a eight-connected undirected graph

where s and r are two adjacent pixels in I, τ is the threshold of the difference between s and r.
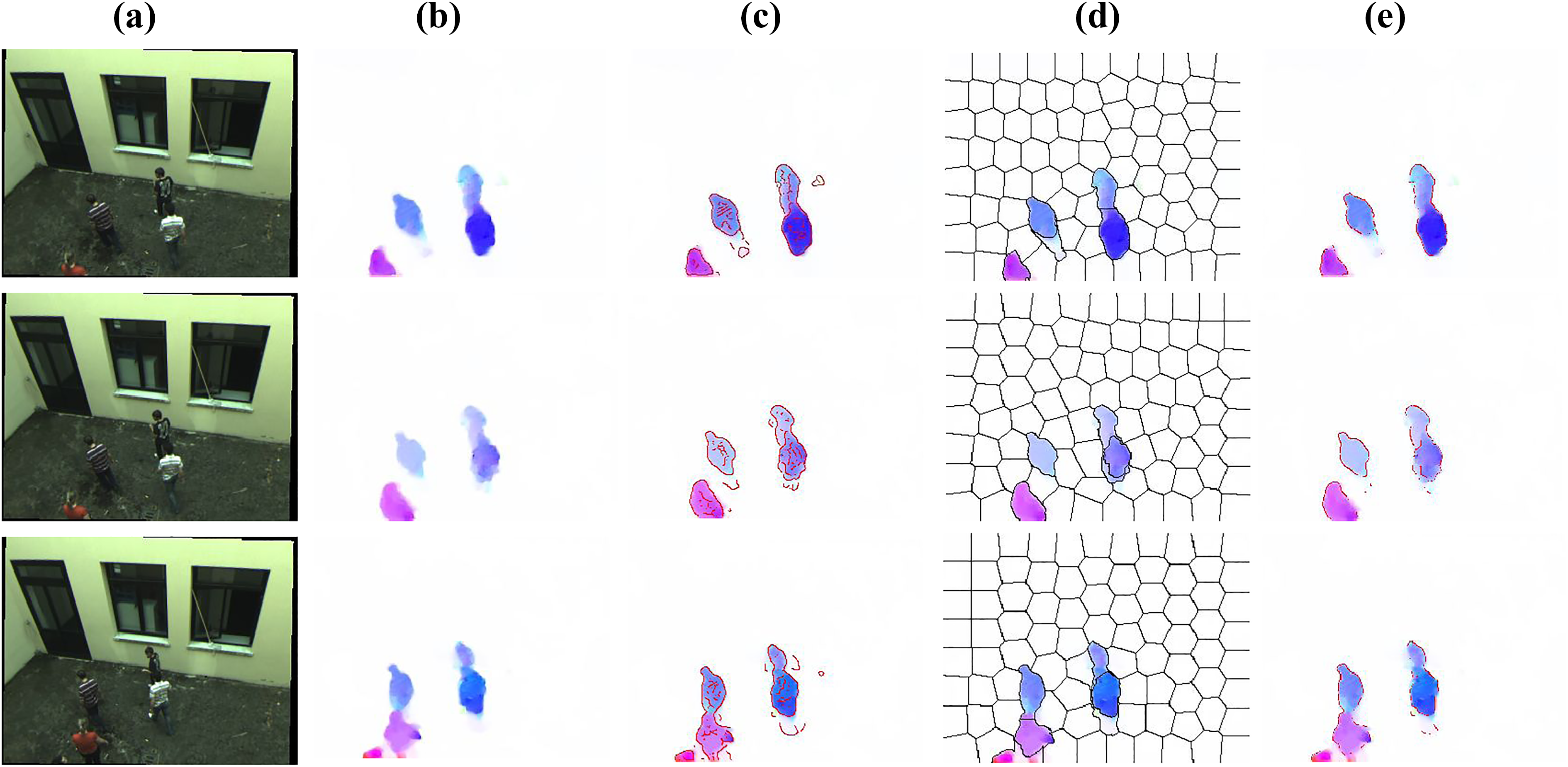
Proposed hybrid priors with flow map (a) consecutive images
Figure 2(a) illustrates the consecutive images

The difference of four- and eight-neighbors structure.
As shown in Figure 3, the matching cost is then aggregated traversing the tree with two passes “leaf to root” and “root to leaf” successively, to make sure each pixel receives the proper contributions from all the other pixels in the image. As defined in equation (4),
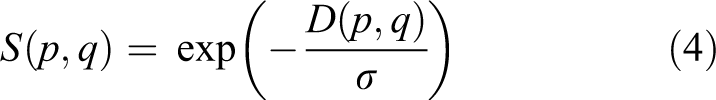

Two steps cost aggregation-based MST. MST: minimum spanning tree.
Consequently, the distance D(s, r) between two arbitrary nodes s and r in this tree is computed as the sum of the weights along the path connecting them. In general, the closer the two pixels locate, the more contribution they impact the aggregated costs. In the “leaf to root” pass, the intermediate aggregated cost

where q indicates every pixel in reference image I, Par(q) denotes the parent node of q. In the “root to leaf” pass, the final aggregated cost
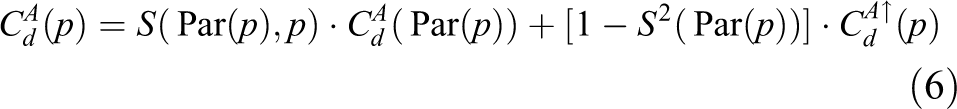
Depending on the hybrid prior segmentation results, the precise support region of cost aggregation is built as shown in Figure 4. During the NLCA, the detected prior (blue line in Figure 4) selects optimal support region for pixel p. The edge weights that cross the prior will be raised sharply if the intensity and motion differences are large. That is to say that the
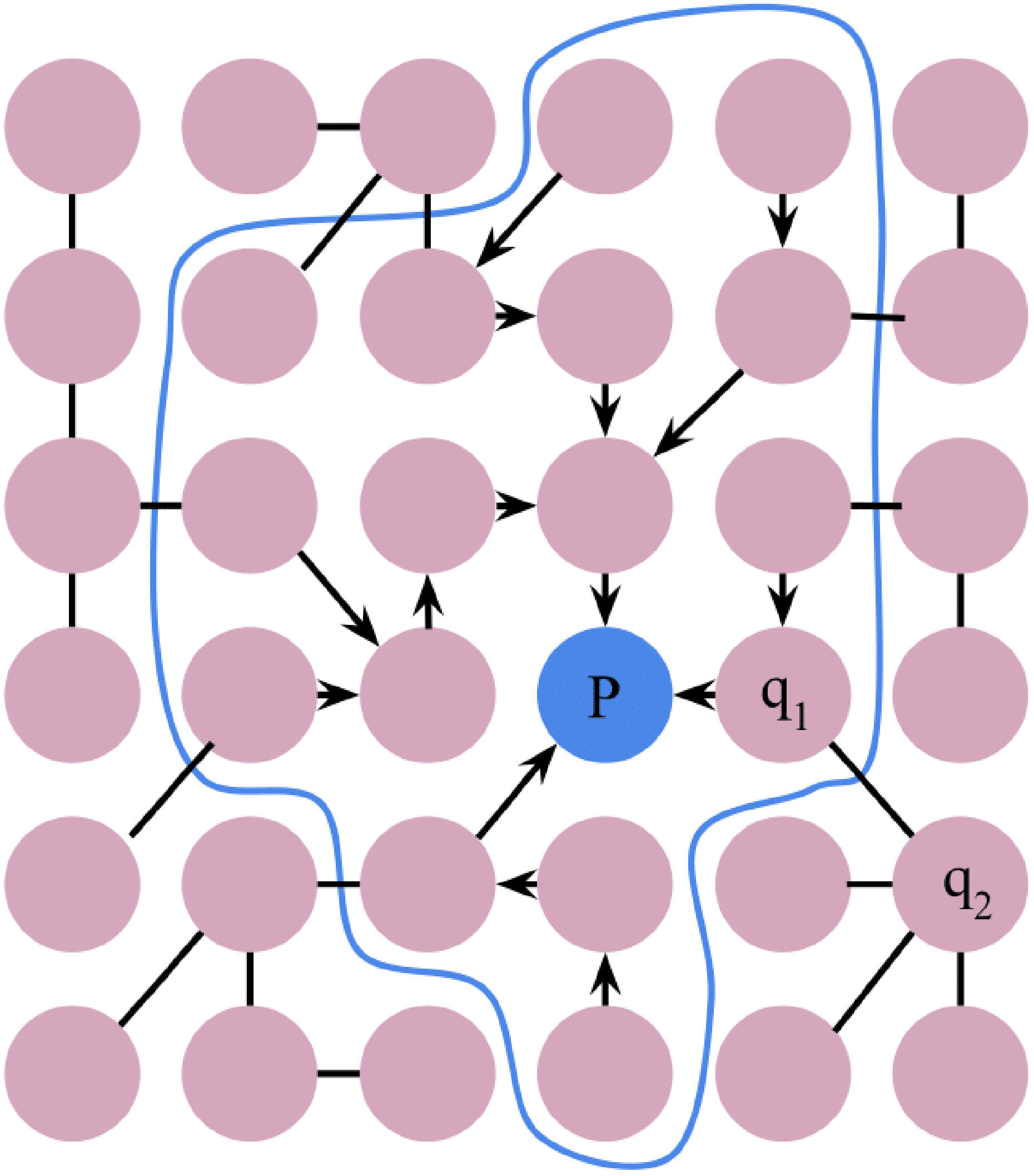
Nonlocal cost aggregation for pixel p on eight-connected MST structure with hybrid prior. MST: minimum spanning tree.
Disparity determination and refinement
After the above cost aggregation step, winner-takes-all (WTA) strategy is adopted to obtain raw disparity map, which represents the accurate disparity in most regions, mismatching still happening due to the occlusion. The left and right disparity maps are first computed using the above steps, taking the left and right image as reference images, respectively. Then the left right consistency is employed to detect occluded pixels in disparity maps. Based on previous research work, the disparity change linearly related to the pixel’s intensity values of neighborhood windows. Hence, one 3 × 3 Laplacian occlusion pixel filling method 18 is introduced to update the occlusion pixel with new disparity value. The redefined matching cost is calculated as

where τd represents the truncated threshold. Meanwhile, in order to restrict on cost aggregation, the similarity function is redefined as

where φ represents a constant with range [0,1] suppressing the cost aggregation from unstable pixel to stable pixel; σ is a constant used to adjust the similarity between p and q. After the adaptive nonlocal refinement, the final disparity map is generated by implementing the WTA strategy again.
Experiment and evaluation
Experimental setup
In this section, we compare the overall performance of our method against the state-of-the-art stereo matching methods with five synthetic stereo sequences and KITTI dataset. Our experiments are evaluated based on such hardware environments: Intel I7 4702MQ (2.2 GHz) and NVIDIA GTX760 m. Meanwhile, there are many parameters defined in the proposed method. The best preset configuration of our evaluations is confirmed based on the large amount of tuning experiments. For instance, the constant φ and threshold τ are set to (0.2, 10) for all the experiments. The σi and σm are fixed with (3, 7) for five synthetic stereo videos, (5, 11) for KITTI data set in the following experiments.
Evaluation with synthetic stereo videos
As the most important criterion in stereo matching algorithm, matching accuracy determines the final quality of the disparity map. In order to evaluate the performance of F-MST against the state-of-the-art stereo matching methods, five synthetic stereo video sequences proposed by Richardt et al.
20
are introduced in this context and they are “book,” “tank,” “tunnel,” “temple,” and “street,” respectively, with 400 × 300 pixels resolution and disparities range

Visual comparison of evaluation with five video sequences: book, tank, tunnel, temple, and street. (a) Left frame of stereo video, (b) ground truth, (c) JMSS, (d) SSL, (e) TDCB, and (f) our method. JMSS: A joint motion-based square step; SSL: square step local; TDCB: temporal dual-cross-bilateral.
Generally speaking, the real scenes contain many kinds of noise, but the ground truth of a stereo video does not. Thus, zero-central Gaussian noise is integrated into each color channel of five synthetic videos to evaluate the performance of different methods as described in our previous work. 14 Some stereo matching algorithms available in the internet, such as NLCA and square step local (SSL), are evaluated under our experiment platform. Hierarchical Belief Propagation-Total Variation (HBP-TV) and temporal dual-cross-bilateral (TDCB) are designed for stereo video matching and are already evaluated with the same data set. The experimental results of HBP-TV and TDCB are reported in their literature 20 , 21 because they are designed for dynamic scenes and already evaluated with the five synthetic stereo sequences.
As shown in Table 1, aforementioned methods are evaluated under Gaussian noise with a SD of σ = 20. We can see that F-MST outperforms other methods at average error rates on book, tanks sequences. Generally, the temporal information impacts the matching result, according to two aspects: MST building and adaptive weight. Meanwhile in order to verify the robustness of the proposed approach, additive Gaussian noise (ranging from 0 to 100) has been introduced into the “book” and “tank” sequences. Plots of the error that evaluates performance of the different methods are illustrated in Figure 6. The proposed F-MST method performs better than other method under different noise conditions, especially in the video sequences with abundant motion happened like “book” and “tank.”
Evaluation on synthetic stereo videos with additive Gaussian noise (σ = 20). Shown values are the mean and SD of the percentage of bad pixels (threshold is 1).

JMSS: A joint motion-based square step; HBP-TV: Hierarchical Belief Propagation-Total Variation; NLCA: nonlocal cost aggregation; SSL: square step local; TDCB: temporal dual-cross-bilateral.

The error versus Gaussian noise curves of different stereo matching methods for “book” and “Tanks”.
Time efficiency is another significant criterion in stereo matching method. So we also evaluate the time efficiency of F-MST in Table 1. As we can see, F-MST is almost two times slower than NLCA and a joint motion-based square step (JMSS) but achieves better matching accuracy in most test sequences, which could be optimized in future for real-time applications.
Evaluation with KITTI data set
Geiger 23 proposed the KITTI dataset, which contained 194 training image pairs and 195 test image pairs for evaluating stereo matching algorithms. In KITTI data set, image pairs are captured under real-world illumination condition and have a large portion of textureless regions. Therefore, 20 paired images with ground truth disparity maps available from KITTI dataset are random selected in our evaluation. As shown in Table 2, the evaluation metric is the same as the KITTI benchmark with an error threshold of three. Out-Noc and Out-All represent percentage of erroneous pixels in non-occluded and all regions, respectively. Avg-Noc and Avg-All represent average disparity error in non-occluded and all regions, respectively. Our method outperforms other three stereo matching methods in different regions.
Evaluation for proposed method on KITTI dataset.

JMSS: A joint motion-based square step; HBP-TV: Hierarchical Belief Propagation-Total Variation; NLCA: nonlocal cost aggregation; TDCB:temporal dual-cross-bilateral.
Here, we choose three image pairs for visual comparison, as illustrated in Figure 7. It compares the results of the proposed F-MST and JMSS, which heavily enforces spatial smoothness and obtains state-of-the-art performance against the KITTI benchmark. As F-MST computes the disparity of each pixel independently without global regularization, it obtains better detail information than JMSS, which could well recover details of the further objects.

Disparity maps generated by the proposed method and the competing method JMSS using KITTI dataset. (a) selected images, (b) proposed method, (c) JMSS: A joint motion-based square step.
Overall, the proposed method outperforms other state-of-the-art methods in most of cases. Therefore, a confirmation is made that the additional temporal information could improve the matching accuracy, especially in the dynamic scenes. The improvement with flow map not only removes outlier errors but also respects the structures of objects and background.
Conclusion
A novel motion flow-based stereo matching algorithm has been proposed in this article. To the best of our knowledge, it is the first time that the flow map has been introduced into MST building for acquiring accurate disparity maps in dynamic environments. In addition, we extended the NLCA framework and suggested a refinement technique to further improve disparity maps. Experimental results have shown that the proposed F-MST method not only outperforms the state-of-the-art stereo matching methods on test sequences but also performs better in time efficiency. Even with a lot of noise, the proposed method performs satisfactorily well in most regions.
We also discuss how the hybrid prior with edge and superpixels impact the MST aggregation region building and the final accuracy of stereo matching. Moreover, the results show that the MST aggregation region building is more important than the other steps, which can attract more attention to stereo refinement, in company with the recent intensive efforts on cost aggregation of stereo matching.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Natural Science Foundation of China (Award IDs: 41775008; 61702275) and Natural Science Foundation of Jiangsu Province (Grant No. BK20150931).