
Abstract
Terrain traversability analysis is a challenging problem for mobile robots to adapt to complex environments, including the detection of cluttered obstacles, potholes, or even slopes. With the accurate distance information, using distance sensors such as three-dimensional light detection and ranging (LiDAR) for terrain description becomes a preferred choice. In this article, a terrain description method for traversability analysis based on elevation grid map is presented. After the elevation grid map is generated, the ground is segmented with the aid of a height difference kernel and the non-ground grids in the map are then clustered. The terrain description features, including height index, roughness, and slope angle, are calculated and estimated. The slope angle is estimated using random sample consensus (RANSAC) and least squares method, and specifically, the roughness is combined to eliminate false slopes. Experimental results verified the effectiveness of the proposed method.
Keywords
Introduction
Terrain traversability analysis 1 is an important and challenging problem for mobile robots. To acquire the terrain information, the sensors such as stereovision, three-dimensional (3-D) light detection and ranging (LiDAR) have been adopted to provide original point cloud.
Some researchers address the problem based on original point cloud. Akdeniz and Bozma 2 presented an approach to local terrain mapping using bubble space representation, where the bubble surfaces are constructed using 3-D laser data. Dargazany and Berns 3 presented a stereo-based superpixel surface approach for terrain traversability analysis of unmanned ground vehicles. Geometry-based features (pixel-based normal) are used to detect all the existing surfaces. Then, superpixel surface analysis is applied on these surfaces to classify them into five categories based on their traversability index. Still, the data processing including stereo matching and point cloud generation is time-consuming. Bellone et al. 4 –6 presented unevenness point descriptor (UPD) for terrain analysis. It uses principal component analysis (PCA) to estimate normal vectors of query points, and then UPD is given by these normal vectors. Lalonde et al. 7 proposed a 3-D data segmentation method for terrain classification. The “scatter,” “linear,” and “surface” objects can be classified with a Gaussian mixture model and a Bayesian classifier.
Obviously, directly applying these raw point cloud data shall increase the complexity of data processing. In this case, grid maps provide an effective solution. Belter and Skrzypczyński. 8 presented an algorithm for real-time building of a local grid-based elevation map from noisy two-dimensional range measurements. The terrain mapping supports a foothold selection for a walking robot based on grid level. More terrain analysis is not mentioned. Neuhaus et al. 9 presented a grid-based algorithm for classifying regions as either drivable or not. The local terrain roughness feature based on PCA is estimated for terrain drivability analysis. Reddy and Pal. 10 proposed a measure of terrain unevenness by computing ranges of neighboring laser beams of a 3-D laser scanner. The unevenness analysis forms an unevenness field around the robot. A traversable region can be marked out by setting thresholds on unevenness in order to detect obstacles. Tanaka et al. 11 proposed a terrain traversability analysis method for mobile robot navigation. With the roughness and slope features extracted from the grid map, they adopted fuzzy inference to calculate the traversability of the rectangular areas to generate a drivable direction.
It shall be noted that terrain description based on the map with grid-level analysis often focuses on the problem of whether the grid is traversable or not. On the one hand, there are some other terrain information such as slopes that should be described. On the other hand, for the grid map, grid-level analysis is a little trivial, and cluster-level analysis is preferable. Jin et al. 12 presented a method for traversability analysis, which extracts slope and roughness of a terrain patch along four heading directions and then uses them to evaluate the level of difficulty associated with the traversal. The slope is estimated by least squares method and the roughness is also obtained. Gu et al. 13,14 proposed a traversability approach based on an extended 2.5-D grid-based representation of the rough terrain using stereovision and omnidirectional vision sensors. Height difference, slope, and roughness are considered as terrain properties to assess the traversability, and a fuzzy logic framework is applied to extract traversability indices from terrain characteristics. Ye et al. 15 –17 constructed a polar traversability index (PTI) to evaluate terrain traversal property, which indicates the level of difficulty for a robot to move along the corresponding direction. Slope and roughness of each terrain patch are estimated through least-squares plane fitting.
It shall be noted that an advantage of 3-D LiDAR is to directly provide accurate distance information. With this advantage, we conduct the research on terrain description. In this article, a terrain description method for traversability analysis based on elevation grid map is presented. The slope angle is estimated using RANSAC and least squares method, and the roughness feature is adopted to eliminate false slopes. The effectiveness of this terrain description method is verified by experiments.
Elevation grid map
The point cloud data to acquire terrain information are from a 3-D LiDAR. The coordinate systems OLXLYLZL and ORXRYRZR are established as shown in Figure 1, where OLXLYLZL refers to LiDAR coordinate system and ORXRYRZR is the robot coordinate system.

Coordinate systems.
Based on the raw point cloud data, the transformed point cloud data set DP
in ORXRYRZR
can be acquired with the help of external parameters calibration.
18
Then, the elevation grid map M is generated with DP
, and each grid in M can be defined as cl
,w
, where l and w are the integer coordinates of this grid in M. The coordinate system OMXMYM
is established to describe M, where OM
is the center of M whose length and width are expressed by L and W, respectively. Figure 2 illustrates the elevation grid map M. For each point pi(xi, yi, zi) in Dp
, it will be projected into the grid cl
,w
in M if the following equation is satisfied
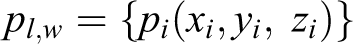




Illustration of the elevation grid map.
where pl ,w is the point cloud data set of the points in DP that are projected into cl ,w in M, and csize refers to the side length of each grid in M.
It can be found that
The height attributes of each cl
,w
, including maximum height,
15
minimum height, mean height,
13
and height difference,
19
are necessary features for elevation grid map, which should be calculated based on its corresponding pl
,w
. For each pl
,w
, the maximum height and the minimum height are labeled as
Terrain description based on elevation grid map
After the elevation grid map is generated, the terrain can be subdivided into different types, including obstacles, potholes, slopes, and so on. Grids in the elevation grid map shall be clustered after ground segmentation is finished. And then, the terrain description features including height index Hf , roughness Rn , and slope angle αs are introduced in details, which pave the foundation of terrain description.
Ground segmentation
There are many grids belong to the ground in M, which should be eliminated first to reduce the computational complexity. Height information in the elevation grid map provides an effective solution for ground segmentation. In this article, multiple height information is utilized for height description to detect non-ground grids as many as possible. For the grid cl ,w , it is marked as a non-ground grid if the following equation is satisfied

where T diff, T high, and T low are given thresholds, and CN is the non-ground grids set. Then, the set of ground grids is easily obtained and it is expressed by CG .
Notice that there are also some grids with small height values, which may be mistaken as ground grids according to equation (1). To solve this problem, a height difference kernel is exerted on the set CG . The kernel adopts not only the height information of the grid but also the height information from its neighboring grids. For a specific ground grid cl ,w in CG , it will be removed from the set CG and added to the non-ground grids set CN if equation (2) is satisfied

where w(s, t) is the neighboring height difference kernel (see Figure 3), w(0, 0) is the value of its center grid in the kernel, a = 1, b = 1, and

The neighboring height difference kernel with an 8-connected domain.
If the grid cl ,w is filled to the set CN , the mean height of cl ,w shall be increased to T high. It should be noted that this kernel processing only examines the ground grids in CG that have eight neighboring ground grids.
Roughness calculation process.
Grids clustering
Flood fill algorithm 20 is used to integrate the non-ground grids in CN that are adjacent in eight directions into the same cluster, as shown in Figure 4. The clusters that contain less than Tc grids shall be directly eliminated, where Tc is a given threshold. Notice that the point cloud data sets corresponding to the non-ground grids are also integrated.
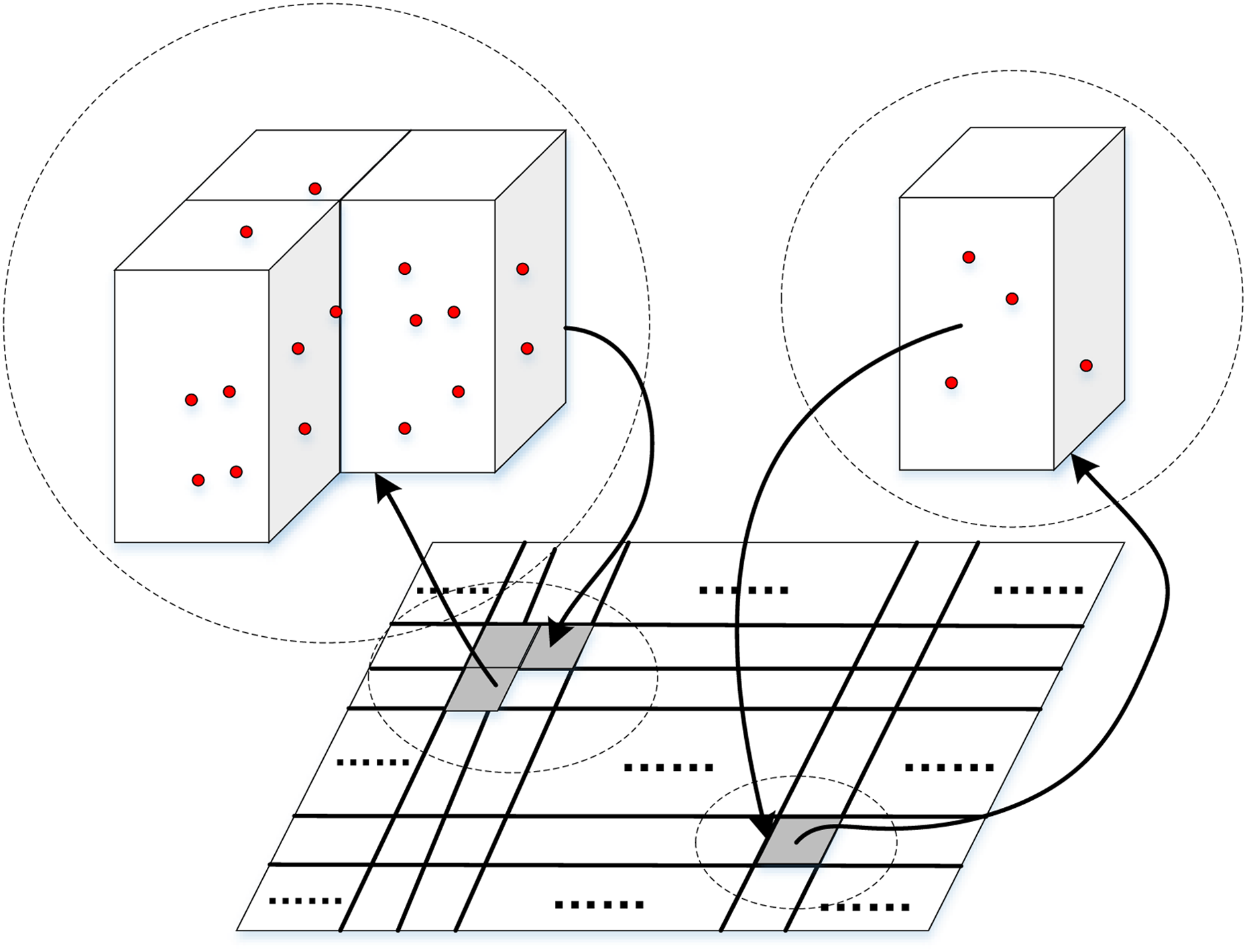
Non-ground grids clustering based on the elevation grid map.
Terrain description features
Based on these clustered grids and their corresponding clustered point cloud data, the terrain description features are addressed. Three features are chosen to describe the cluster-based terrain, and they are height index Hf , roughness Rn , and slope angle αs . Hf stands for the height information of a cluster. The unevenness degree of a cluster is reflected by Rn , and αs represents the steepness degree of a cluster.
Among the height features, the value of maximum height feature is easy to be changed due to robot motion, and the mean height feature cannot reflect the height range of the cluster. In contrast, height difference is a robust height feature for mobile robots. However, it cannot distinguish clusters of point cloud with large heights but small height differences. In this article, height index Hf based on the height attributes of all cl ,w in a cluster is introduced, which is a combination of the height-related attributes

where Hd
is the height difference of this cluster, Hm
is the mean height of this cluster,
Slope angle estimation process.

Flat terrains and rough terrains have different distribution of point cloud so that we can deduce the rough degree of a terrain according to the distribution of its point cloud. PCA method 21 provides a solution to infer the point cloud distribution. Let’s consider the covariance matrix S of Qf , where Qf is a cluster of point cloud after filtering. It can be found that the eigenvectors of matrix S must be mutually orthogonal, because S is a real symmetrical matrix. In this case, the PCA of the covariance matrix S of Qf is in fact equivalent to eigenvalue decomposition for S. 9 The eigenvectors and eigenvalues of S can be solved by singular value decomposition. S can be transformed into a diagonal matrix Λ with an invertible matrix V generated by these orthogonal eigenvectors, which is shown in the following

where qi
is the ith point of Qf
,
Obviously, the elements of diagonal matrix Λ are eigenvalues of S. That means the covariance in S is decoupled along three principal directions, which are defined by the eigenvectors of S. The sizes of eigenvalues indicate the distribution of the point cloud along these directions. If there exist two eigenvalues that are much larger than the third one, which means that there exist two main principal directions, the distribution of the point cloud is close to a plane. 7 Besides, the minimal eigenvalue and the median eigenvalue should satisfy the given thresholds. Define λk as the kth eigenvalue of S, and vk as the kth eigenvector of S, where k ∈ {0, 1, 2}. Then, the roughness Rn of the cluster is given as follows. Rn is a Boolean variable and it is set to 0 when λ 1 ≫ λ 0, λ1 ≥ TL and λ0 ≤ TS, where λ1 and λ0 are the median value and the minimum value of three eigenvalues, respectively, TL and TS are given thresholds. The cluster of point cloud will be viewed as flat if Rn = 0, or else, it will be viewed as rough. Algorithm 1 gives the implementation of roughness calculation process in detail.
Compared with the methods that usually measure the vertical cross section of a slope to estimate its angle, 2 the slope angle estimation through normal vector can reflect the global feature of a slope. In order to estimate normal vector of a cluster, many fitting methods can be adopted, such as least squares method and RANSAC family. Least squares method considers all the points in the point cloud to minimize the sum of the squares of the residuals. RANSAC algorithm 22 is a learning technique to estimate the parameters of the fitting plane by random sampling of observed data. Its goal is to maximize the size of inliers, which can be fitted into a hypothetical plane within a small error. However, both least squares method and RANSAC have disadvantages. The least squares method is easily to be trapped in local optimum and is vulnerable to interference, whereas the variances of the RANSAC estimation results are usually large. It should be noted that the estimation result of least squares method is accurate and stable if the point cloud data are clean enough, and RANSAC is more robust against the interference.
In this article, we propose a solution that combines the advantages of least squares method and RANSAC, where RANSAC is used for candidate points segmentation, and the least squares method is then used to estimate the normal vector with these candidate points. For a cluster, we assume that there exists a plane that contains as many points as possible within a given range of error. The hypothetical plane is illustrated in Figure 5, where the red points refer to the point cloud of the cluster.

Illustration of the fitting plane and its normal vector.
This solution can be divided into three steps: plane segmentation, 22 normal vector estimation, and slope angle calculation. In the first step, the cluster of the point cloud Qf will be divided into inliers and outliers, which is implemented through iterations. Three random points from Qf are selected in the ith iteration, with which a plane Si is generated as Aix + Biy + Ciz + Di = 0. For each point in Qf , if the distance between this point and Si is within a given threshold Tq , this point will be added into the inliers set. The size of inliers set is counted in each iteration to find out the best plane parameters with maximum inliers ever reached. If the ratio of the inliers in Qf reaches a given threshold or the iterations reach a given maximum number, the iterations will stop.
The second step is to estimate the normal vector for the inliers set segmented from Qf . All the points in the inliers set will be considered for normal vector estimation. The plane to be generated can be expressed as z = Anx + Bny + Dn , where An , Bn , and Dn are plane coefficients that can be estimated by the least squares method as shown in the following

where xk , yk , and zk are the coordinates of the kth point in the inliers set, and nt is the size of inliers.
To solve equation (5), singular value decomposition is used. Then, the normal vector is acquired as

where nv is the normalized normal vector of XRORYR in ORXRYRZR .
The entire slope angle estimation process can be described in Algorithm 2.
Terrain description
The terrain features including height index Hf , roughness Rn , and slope angle αs can be used for terrain classification. In order to reduce the computational complexity, these three features are estimated in sequence. If Hf of a cluster is smaller than T neg , it will be classified as a pothole, and the other two features will not be estimated for this cluster. The cluster of point cloud will be categorized as an obstacle if Hf is not less than T pos with Rn = 1. In this case, it is not necessary to estimate αs . Only when Rn = 0, αs shall be considered. In actual applications, there usually exists an interval for the slope angle. For example, a wall is considered as an obstacle not a slope with αs ≈ 90°. The abovementioned classification is summarized in Table 1, where T pos and T neg are given thresholds.
Terrain classification with terrain description features.

Experiments
In this article, experiments are conducted for terrain description using the height index Hf , roughness Rn , and slope angle αs . A 3-D LiDAR is adopted for point cloud acquisition, which is mounted with a height of 0.81 m. Only points in the point cloud whose heights are below 1.5 m are considered. The length L and width W of the elevation grid map are both set as 5 m in OMXMYM . c size = 0.05 m, T diff = 0.05 m, T high = 0.05 m, T low = −0.05 m, and T pos = −T neg = 0.05 m.
Height index verification
Height index is first verified. Figure 6 illustrates a terrain with an obstacle and a pothole, where red points and green points are acquired from the obstacle and the pothole, respectively. Fifty measurements are conducted, and the height index results are given in Figure 7. Figure 7(a) and (b) shows the obstacle and the pothole, respectively, where the blue lines represent the ground truth. The difference between the calculated height index and the ground truth is dentoted by δ. Table 2 summarizes the measurement results with the height index of our approach. It can be seen that both measurement results for the obstacle and the pothole are close to the ground truth with a good accuracy. It shows that the height index can provide an accurate measurement.

The point cloud of a terrain with an obstacle and a pothole. (a) Top view and (b) front view.

The height index results of Figure 6. (a) Obstacle and (b) pothole.
Measurement results of height index.

The experiment with the proposed method
On the basis of height index calculation, a more complex terrain is adopted to testify the proposed method. In the terrain shown in Figure 8, there are three obstacles and two slopes, which correspond to the red points and blue points, respectively. Based on our method, we obtain five clusters: clusters 1 to 5. It shall be noted that the obstacle corresponding to cluster 4 is composed of some cluttered objects. It is not a real slope, however, from the distribution of point cloud, it is close to a slope.

Point cloud of the terrain with three obstacles and two slopes. (a) Top view and (b) front view for clusters 3 and 4.
It is worth noting that the slope angle for each cluster can be directly calculated no matter whether the cluster is a slope or not. Figure 9 illustrates the slope angle estimation results for clusters 2 to 4 with 50 measurements. One can see that the results of cluster 3 remain stable, while the results of cluster 2 fluctuate greatly. For cluster 4, the slope angle curve has a relatively large fluctuation. Usually, a stable estimation of slope angle for a cluster means that this cluster corresponds to a real slope with a large probability. On the contrary, if the estimation curve has a large fluctuation, the possibility of this cluster corresponding to a slope is reduced. However, it is hard to quantify the relationship between the fluctuation and the real slope. Take cluster 4 as an example. The fluctuation of cluster 4 is neither too small nor too large, and it is improper to regard cluster 4 as a slope or not by only relying on the fluctuation analysis of slope angle estimation curve. More features including roughness are necessary.

Slope angle estimation results. (a) Cluster 2, (b) cluster 3, and (c) cluster 4.
Figure 10(a) and (b) shows the height index and roughness feature of the terrain in Figure 8. One can see that the height index of all clusters is larger than T pos, which means that each cluster corresponds to an obstacle or a slope. With the combination of roughness evaluation where a slope should have a flat distribution of its point cloud, we can obtain from Figure 10(b) that only clusters 3 and 5 are considered as two real slopes. It shall be noted that cluster 4 is not a real slope due to its large roughness. Intuitionally, the point cloud of cluster 4 (see Figure 8(b)) is clutted so that there does not exist a fitting plane that covers most points. With the combination of our three terrain description features including height index, roughness, and slope angle, the terrain in Figure 8 is correctly depicted. Table 3 illustrates the measurement results for cluster 3, where the difference between the estimated slope angle and the ground truth is dentoted by ξ. We can see that the slope angle is effectively estimated.

The height index and roughness feature of the terrain in Figure 8.
Measurement results of slope angle of cluster 3.

Comparison with slope angle estimation methods
In this section, we conduct the comparison with PCA, 11,13 least squares method, 12,15 RANSAC, 23 PROSAC, 18 as well as with the following methods: RRANSAC, 24 LMEDS, 25 MSAC, 26 and MLESAC. 26
Accuracy comparison
Three real slopes are adopted for comparison, and they are slopes A, B, and C, respectively. Figure 11 shows the point cloud of these three slopes, where Figure 11(a) and (b) shows the point cloud of slope A from the top view and front view, respectively. The point cloud of slopes B and C is shown in Figure 11(c) to (f), respectively.

Point cloud of slopes A, B, and C. (a), (c), and (e) Top view; (b), (d), and (f) front view.
Figure 12(a) to (c) describes the estimation results with 50 times for slopes A to C, respectively. The results of our proposed method are depicted in red color, and the ground truth is expressed in blue color. It can be seen that compared with other methods, our method can achieve an accurate estimation for the slope angle. The statistic results of all methods are illustrated in Table 4, where the best results are demonstrated in red color. One can see that the proposed method is better than other methods in most cases.

Accuracy comparison of different slope angle estimation methods. The estimation results of (a) slope A, (b) slope B, and (c) slope C.
Statistic results of slope angle estimation for different slopes.

RANSAC: random sample consensus, LMEDS: least median of squares, MSAC: m-estimator sample consensus, RRANSAC: randomized random sample consensus, MLESAC: maximum likelihood estimation sample consensus, PROSAC: progressive sample consensus, PCA: principal component analysis.
Robustness comparison
In this section, three objects with different sizes are placed on slope A, which are considered as three new slopes: A 1, A 2, and A 3. These objects can be regarded as the interference to testify the robustness of the methods. The point cloud of slopes A 1, A 2, and A 3 is shown in Figure 13.

Point cloud of slopes A 1, A 2, and A 3.
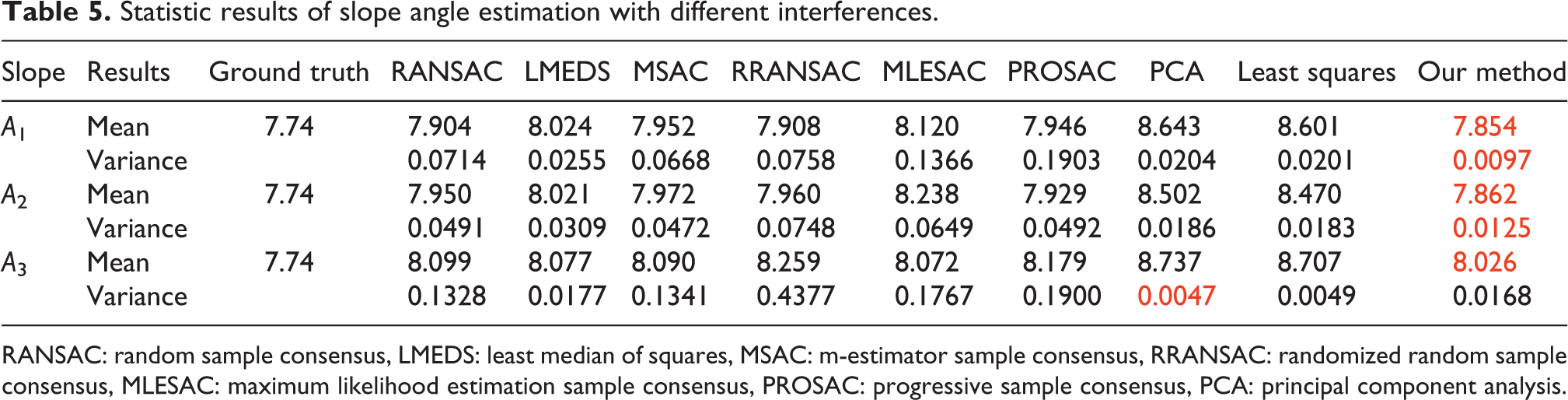
For slopes A 1, A 2, and A 3, the estimation results with 50 times are given in Figure 14(a) to (c), respectively. The statistic results of all methods are illustrated in Table 5. Clearly, PCA and least squares methods are obviously affected by the interference. The larger the interference is, the worse the estimation result is. In contrast, the RANSAC family methods are less affected due to their characteristics where the outliers are removed.
Statistic results of slope angle estimation with different interferences.
RANSAC: random sample consensus, LMEDS: least median of squares, MSAC: m-estimator sample consensus, RRANSAC: randomized random sample consensus, MLESAC: maximum likelihood estimation sample consensus, PROSAC: progressive sample consensus, PCA: principal component analysis.

Robustness comparison of different estimation methods. The estimation results of (a) slope A 1, (b) slope A 2, and (c) slope A 3.
Among these RANSAC family methods, the proposed method with the combination of RANSAC and least squares method is slightly superior to the others on the whole.
Conclusions
This article proposes a terrain description method for traversability analysis based on elevation grid map. Terrain features include height index, roughness, and slope angle. The proposed method can describe different types of terrain, including cluttered obstacles, potholes, and slopes. The experiments show that the measurements of obstacle’s height and pothole’s depth are effective. Real slopes can be distinguished with the help of roughness feature. The comparisons among different slope angle estimation methods are also conducted, which verify that the proposed method can achieve a better slope angle estimation.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work is supported in part by the Beijing National Science Foundation under Grant 4161002, and in part by the National Natural Science Foundation of China under Grants 61633020, 61773378, 61633017, U1713222.