
Abstract
In this article, we propose a road detection method based on the fusion of Lidar and image data under the framework of conditional random field. Firstly, Lidar point clouds are projected into the monocular images by cross calibration to get the sparse height images, and then we get high-resolution height images via a joint bilateral filter. Then, for all the training image pixels which have corresponding Lidar points, we extract their features from color image and Lidar point clouds, respectively, and use these features together with the location features to train an Adaboost classifier. After that, all the testing pixels are classified into road or non-road under a conditional random field framework. In this conditional random field framework, we use the scores computed from the Adaboost classifier as the unary potential and take the height value of each pixel and its color information into consideration together for the pairwise potential. Finally, experimental tests have been carried out on the KITTI Road data set, and the results show that our method performs well on this data set.
Introduction
Road detection is always a key problem in autonomous driving. For its driving safety, an unmanned ground vehicle must have the ability to distinguish road or free space from obstacles in various environments, as well as to obey the traffic rules. Over the last decades, many different methods have been proposed to deal with this problem. However, due to the complex surroundings and obstacles in different environments, as well as various lighting conditions, road detection is still a challenging task.
Many road detection methods based on monocular images have been proposed. Compared with other sensors, the monocular visible light camera is much cheaper so that it can be widely used for this task. Nowadays, with the rapid development of the 3-D sensors, more and more road detection methods are based on the stereo vision or laser range finder. For example, Kinect, a cheap 3-D sensor that can provide the dense depth map registered with an RGB image (RGB-D) is widely used in the indoor scenes. On the other hand, in the outdoor scenes, the most common kind of 3-D sensors is the light detection and ranging (Lidar), such as the Velodyne HDL-64E (Velodyne LIDAR, USA). This kind of sensors can provide 3-D range data in the form of point clouds, which have maximum ranges of 60–80 m.
The 3-D sensors have many advantages, for example, they can provide the 3-D structure information and they are robust to the changing of lighting conditions. However, they also have some weaknesses. For example, stereo vision sensor is sensitive to the noises and object movements in the environment, and the Lidar can only generate very sparse data of distant objects without color information, which is helpful to detect the road areas. Therefore, fusion of data from different kinds of sensors is a better way for road detection.
However, even though many methods have been proposed, the road detection still remains an open problem, and that is because most of the proposed methods only extract low-level features from image and Lidar data and then fuse them in feature level to train a classifier to detect road. In order to improve the performance of road detection, in this article, we propose a road detection method based on multi-sensors and try to fuse data in both data level and feature level. To be more specific, in our method, firstly, we project the Lidar point clouds into the images and obtain original height images which are sparse. Then, we upsample these height images via a joint bilateral filter so that all pixels will have their own height values. For each image pixel which has its original corresponding Lidar points, we extract the textons features, 1 the Lidar-based features, and the location features. After that, we use conditional random field (CRF) framework to classify each pixel into road pixel or non-road pixel. Under this CRF framework, all the extracted features are used to train an Adaboost classifier, and the scores computed from this classifier are considered as the unary potential. At the same time, the differences in color values and height values of pixels are taken into consideration as the pairwise potential. Then, it is optimized with graph cuts. Experimental tests have been carried out on the KITTI Road data set, 2 and the results show that our method performs well.
This article is organized as follows: Firstly, the related works are briefly reviewed. Then our method is given in detail. After that, we show our experimental results on KITTI Road benchmark, and finally, we conclude our article.
Related works
A variety of road detection methods have been proposed in the last decades. Among these methods, two different kinds of sensors are used individually or jointly: the monocular vision sensors (visible light cameras) and the 3-D sensors (including stereo vision sensors and the Lidar sensors).
There are lots of road detection methods based on the monocular vision sensors. Since this kind of sensors is very cheap, it has been used in this task for decades. Most of these methods use low-level features of pixels, such as texture, edge, or color, to separate the road areas from non-road areas. For example, Malik et al. 1 designed an N-dimensional filter bank and convolved images with it to get responses of every pixels as their textons features. This kind of feature has been proven to be effective, and some other improved methods based on that were also proposed. 3,4 Besides, these methods often make the assumption that the particular part of the images, such as the lower part of the images, is more likely to be the road part. 3 Except for the low-level features, some researches use contextual cues to improve the results. For example, Alvarez and Lopez 5 proposed a method that combined the context, including horizon lines, vanishing points, lane markings, and so on, with low-level cues to detect road, making the method robust to varying imaging conditions.
Some other methods used the data from 3-D sensors (such as stereo camera or Lidar sensors) or fused data from 3-D sensors and monocular cameras to detect the road area. Nanri et al. 6 proposed a method to compute height changes against road surface on several multi-directional scanning lines from the dense disparity map, and they can detect a variety of road boundaries even with unsmooth edges or jagged boundaries. Suger et al. 7 generated a 2-D grid map from 3-D points and extracted features from every individual cells. This kind of features contained five measurements: the absolute maximum difference in the z-coordinate, the mean of the remission values, the variance of the remission values, the roughness, and the slope of the cell. Xiao et al. 4 fused the Lidar data and monocular image under the framework of CRF to detect the road. In their method, they used the pixel-wise texture, dense histogram of oriented gradients (dense HOG), color and location cues as the image features, and the normalized 3-D location and the direction of the local normal vector of every point as the Lidar features. Shinzato et al. 8 also proposed a road terrain detection method via sensors fusion, they used spatial relationship in image perspective view combined with real 3-D metric values to determine whether a point corresponds to an obstacle or not. After that, they used polar histograms to generate a confidence map that represented the road areas in the images.
In our method, we also detect road areas based on the fusion of Lidar and image data. However, in those methods mentioned above, they usually extract low-level Lidar–based features, such as the absolute maximum in heights, the mean of heights, the normal vector, and so on, to fuse with image-based features. Compared to them, we propose a Lidar-based feature which can describe the distribution of one Lidar point and its neighbors. Besides, we project Lidar point clouds into the images to generate dense height images and use these height images in our CRF framework to eliminate the effects of shadows on the road surface.
Road detection based on Lidar and image fusion
Height image upsampling
Usually, the different illumination conditions have great impact on the color differences. Therefore, removing shadows from the road surface can greatly improve the performance of road detection. 5 The most popular way to deal with this problem is to convert the color images into “shadow-free” images, which are not sensitive to the lighting conditions. For example, Alvarez and Lopez 9 proposed a method that converted images from RGB channels into shadow-invariant feature channel. They used r = log(R/G) and b = log(B/G) to take replace of R, G, and B, which means each pixel Pi = (Ri ,Gi ,Bi ) in RGB images is now converted into P′ i = (ri ,bi ). And then they are projected into a line lθ, where θ was the direction of the line. After that, we denote the distance between projection results of P′ i = (ri ,bi ) and P′0 = (0,0) as each pixel’s value in shadow-free channel. These converted images are named as shadow-free images.
However, as shown in Figure 1, the shadow-free image has many noises, and some road edges, for example, the left curb on the image becomes unclear. Therefore, instead of using those shadow-free images, we generate height images by fusing Lidar and image data and use these height images to eliminate the influence of the shadow while keeping the edges clear as well.

The shadow-free image and the height image. The first row is the color image, the second row is the shadow-free image, and the third row is the high-resolution height image.
As we mentioned above, some other methods also use height smoothness or height change to detect road areas,
6
but unlike only using heights of Lidar points, we try to obtain the heights of every image pixels and generate the dense height images. In order to do this, firstly, we fuse the Lidar point clouds and color images by transforming the 3-D points

where
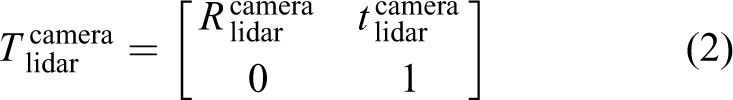
where
Usually, such matrixes are pre-calculated on some data set such as KITTI. Therefore, in our method, we assume that those matrixes are calculated in advance. For more details, refer to Geiger’s works. 10,11
After the projection, some of the image pixels have their heights while the others not. These sparse height images have to be upsampled to generate high-resolution smooth and dense height images. Generally, there are two kinds of methods to upsample these images, one of them is based on MRF frameworks 12,13 and the other is based on joint bilateral filters. 14 –16 In our method, we choose the joint bilateral filter to upsample height images. The joint bilateral filter is based on the assumption that areas of similar color usually have similar height values. Just like the methods we mentioned above, 14 –16 the joint bilateral filter we use can be formalized as


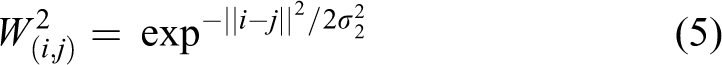
where α is a normalizing factor, which ensures weights sum to one,
As shown in Figure 2, after the upsampling processing, all the pixels have their height values.

The upsampling of height image. The first row is the color image, the second row is the low-resolution height image, and the third row is the high-resolution height image.
Feature extraction
The unary potential of the CRF we use is the negative log likelihood of variable Xi taking label xi:
Textons features are the responses of Filter Bank 3 on color images. The Filter Bank consists of Gaussians at scales k, 2k, and 4k; x and y derivatives of Gaussians at scales 2k and 4k; and Laplacians of Gaussians at scales k, 2k, 4k, and 8k. After we convert the images into the Lab color space, the Gaussian filters are applied to all three color channels, while the other filters are applied only to the L channel. Finally, we can get an 18-dimension vector for each pixel.
We also propose a Lidar-based feature named local distance distribution (LDD). To be specific, a neighborhood η for a 3-D point
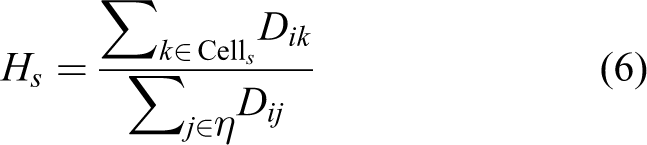
Therefore, the LDD feature of point Pi is an N*M*K-dimensional feature

The extraction of LDD features. LDD: local distance distribution.
Besides, since the middle lower parts of the images are more likely to be road, we also use the locations of the pixels in the images as the location features.
CRF for road detection
Since Shotton et al.
17
firstly used CRF in semantic labeling, there have been many variants proposed after that. Road detection can be seen as a two-class (road and non-road) labeling problem, in which each pixel pi is modeled as a discrete random variable
For a given observed image I, the posterior probability of the labeling is a Gibbs distribution and can be written as

where
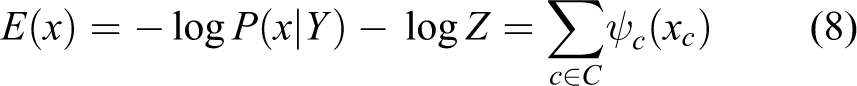
Then, the most possible labeling result of X can be written as

For most of the methods, the pixel labeling problems can be formulated as pairwise CRFs, which only consider the unary potential and pairwise potential. And usually the neighborhood relationship in these CRFs is defined as locally four-connected or eight-connected neighborhood. Their energies can be written as the sum of unary and pairwise potentials

where the unary potential
The pairwise potential encodes a smoothness prior which encourages neighboring pixels in the image to have the same labels. Usually, the pairwise potential



where γ is the trade-off parameter between the unary potential and the pairwise potential, λ1 and λ2 are parameters to balance the weights of height difference and color difference, Dij is the Euclidean distance between the pixel points Pi and Pj, Ii and Hi are the color value (in RGB channels) and the height value of pixel point Pi, respectively, and β1 and β2 are two deviations.
There are many ways to solve the energy minimization problem under CRF framework. In our work, we use α-expansion method which is available from an open source library named graph cuts optimization (GCO). 18 –20 For more details, refer to their work.
Experiments
Data sets
In order to test the performance of our proposed method, we use the KITTI Road data set as benchmark. This data set contains 579 frames of color images, Lidar point clouds, and their calibration parameters. The average spatial resolution of the images is 1242 × 375 px. For this data set, 289 frames are as the training data and 290 frames are as the testing data.
All the data are divided into three different categories and each category belongs to one road scenes: urban marked (UM), urban multiple marked (UMM) lanes, and urban unmarked (UU). Figure 4 shows some of the scenes of these three categories. From Figure 4, we can see that the environment surroundings and the lighting conditions are quite variable.

Some scenes of different road categories. Three images in the left column belong to UM, three images in the middle column belong to UMM, and three images in the right column belong to UU. UM: urban marked; UMM: urban multiple marked; UU: urban unmarked.
Our method only detects the road areas and does not consider the lane information. For evaluation, a set of metrics including precision, recall, maximum F1-measure, average precision, false positive rate, and false negative rate are used.
Experimental settings
In the unary potential of our CRF framework, we use the results from Adaboost classifier. And for this classifier, we set decision tree with depth d = 5 as the weak classifier and run for 50 rounds. The parameters of our CRF are analyzed in the following subsections. All the experiments were carried on a PC with 4 GB of RAM and a dual-core Intel Core i5-3230M CPU clocked at 2.6 GHz, and the code is written in C++ and Matlab environment. The average time of processing a frame of testing data is 6.3 s.
Lidar-based features
In this subsection, we will present the road detection performances of different kinds of Lidar-based features. The Lidar data are in the form of point clouds:
Different kinds of Lidar-based features.

LDD: local distance distribution.

The receiver operating characteristic (ROC) curves of road detection based on different kinds of Lidar-based features.
Removing the effects of the shadows
As we mentioned above, removing the shadows from the road surface is very important for road detection. To verify the shadow elimination performances of shadow-free images 9 and our height images, we convert all the color images from UM training data set to those two kinds of images, respectively. The parameter θ of shadow-free method is 42°. The parameter σ1 is 10 and σ2 is 3 of the joint bilateral filter. Then, the UM training dataset is randomly divided into two parts for training and testing, respectively, as we do in the experiments above. After that, we train two different CRF frameworks to detect road. In one of which the Hi is the height value of Pi from height images, and in the other, the Hi represents the value in shadow-free channel of Pi from shadow-free images. Table 2 shows the average accuracies of road detection under those two CRFs. From the table, we can see the CRF framework with height images has better performance in detecting the road, and this proves the height images are more effective to eliminate the effects of shadows compared to the shadow-free images.
Average accuracies of road detection under two CRF frameworks.

CRF: conditional random field.
Performances
To show the road detection performance of our proposed method, we use all the training data to train an Adaboost classifier and our proposed CRF. All the parameters are set via 10-fold cross validation experiments on the training data set. The parameters M, N, and K of LDD are all 3, and the γD of LDD is 0.3 m. Since the GCO can only take integers as the unary potentials, the unary potentials are converted to 0–255. Under such constraint and based on the experiments on the training data set, the parameters of pairwise potential are set empirically as γ is 200, λ1 is 0.6, λ2 is 0.4, β1 is 10, and β2 is 10. Then, we test our method on the testing data set and evaluate the results in the bird eye view on the KITTI website. Table 3, Figures 6 and 7 show some results.
Results of our method.

MaxF: maximum F1-measure; AP: average precision; PRE: precision; REC: recall, FPR: false positive rate; FNR: false negative rate.

The evaluations in bird’s eye view. Here, red denotes false negatives, blue areas correspond to false positives, and green represents true positives.

Some results of different road categories. Here, red denotes false negatives, blue areas correspond to false positives, and green represents true positives. The first row belongs to UM, the second rows belong to UMM, and the third row belongs to UU. UM: urban marked; UMM: urban multiple marked; UU: urban unmarked.
We compare our method with some other methods which also used Lidar data or CRF framework, including HybridCRF, FusedCRF, 4 GRES3D+VELO, 8 and RES3D-Velo. 8 The results are shown from Tables 4 to 6. From the tables, we can see that our method performs the best in UM and UMM data set. Although our method performs slightly worse than HybridCRF in UU data set (that may be because we use different image features in the Adaboost classifier), it still outperforms the others overall.
Results of online evaluation on UM (BEV).
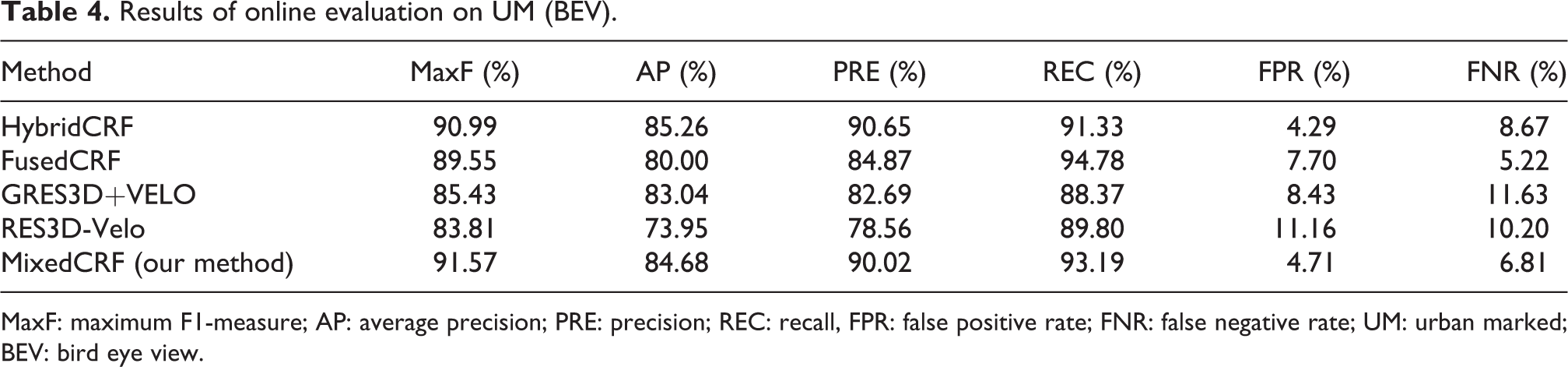
MaxF: maximum F1-measure; AP: average precision; PRE: precision; REC: recall, FPR: false positive rate; FNR: false negative rate; UM: urban marked; BEV: bird eye view.
Results of online evaluation on UMM (BEV).

MaxF: maximum F1-measure; AP: average precision; PRE: precision; REC: recall, FPR: false positive rate; FNR: false negative rate; UMM: urban multiple marked; BEV: bird eye view.
Results of online evaluation on UU (BEV).

MaxF: maximum F1-measure; AP: average precision; PRE: precision; REC: recall, FPR: false positive rate; FNR: false negative rate; UU: urban unmarked; BEV: bird eye view.
Discussion
Although we have achieved really good performance on KITTI road benchmark, there are still some limitations of our proposed method. Firstly, there are many false positives of our results, as shown in the first row of Figure 7. This is because the road areas and non-road areas are very similar in colors, textures, and heights, therefore the features extracted from images or Lidar point clouds cannot distinguish them well. Secondly, the second row of Figure 7 shows that, because the Lidar point clouds are sparser and sparser as the distance increases, we have a few false positives in the far areas from the vehicle. These problems should be further studied in our future work.
Conclusion and future works
In this article, we propose a road detection method based on Lidar and image data. Firstly, we project the Lidar points into the images and use a joint bilateral filter to generate the dense height images. Then, we extract the image-based features (textons), Lidar-based features (LDD), and location features to train an Adaboost classifier. After that, we use CRF framework to get the road detection results.
The main contributions of our work are as follows: (1) We propose a Lidar-based feature called LDD, which is effective to describe the spatial relationship of one point and its neighborhood points. This kind of feature is fused with textons features and location features to train an Adaboost classifier, and experimental results show that the fused features can improve the performance of road detection. (2) To resist the influence of shadows on the road surfaces, we use height images together with color images in the pairwise potential of CRF framework. The height images have less noises and more clear edges than traditional shadow-free images, so that we can use them to improve the road detection results under different lighting conditions.
The experiments are carried out on the KITTI Road data set, and the results show that our method performs well. We will try to use our method on more road detection data set to verify its effectiveness in different environments in the future.
Footnotes
Acknowledgements
The authors would like to thank the referees for their comments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by the National Natural Science Foundation of China (NSFC) (Nos. 61233011, 61403202, and 91220301), by the National Science and Technology Major Project of China (No. 2015ZX01041101), by the 111 Project of China (No. B13022), by the Jiangsu Key Laboratory of Image and Video Understanding for Social Safety (Nanjing University of Science and Technology, China; No. 30920140122007) and by China Post Doctor Foundation (No. 2014M561654).