
Abstract
In this article, we introduce a learning-based vision dynamics approach to nonlinear model predictive control (NMPC) for autonomous vehicles, coined learning-based vision dynamics (LVD) NMPC. LVD-NMPC uses an a-priori process model and a learned vision dynamics model used to calculate the dynamics of the driving scene, the controlled system’s desired state trajectory, and the weighting gains of the quadratic cost function optimized by a constrained predictive controller. The vision system is defined as a deep neural network designed to estimate the dynamics of the image scene. The input is based on historic sequences of sensory observations and vehicle states, integrated by an augmented memory component. Deep Q-learning is used to train the deep network, which once trained can also be used to calculate the desired trajectory of the vehicle. We evaluate LVD-NMPC against a baseline dynamic window approach (DWA) path planning executed using standard NMPC and against the PilotNet neural network. Performance is measured in our simulation environment GridSim, on a real-world 1:8 scaled model car as well as on a real size autonomous test vehicle and the nuScenes computer vision dataset.
Keywords
Introduction
Research in the area of autonomous driving has been boosted in the last decade both by academia and industry. Autonomous vehicles are intelligent agents equipped with driving functions designed to understand their surroundings and derive control actions. As shown in the deep learning for autonomous driving survey of Grigorescu et al., 1 the driving functions are traditionally implemented as perception-planning-action pipelines. Recently, approaches based on End2End learning from Bojarski et al. 2 and Pan et al., 3 or the deep reinforcement learning (DRL) shown by Kendall et al. 4 have also been proposed although mostly as research prototypes.
In a modular perception-planning-action system, visual perception is most of the times decoupled from low-level control. A tighter coupling of perception and control was researched in the field of robotic manipulation with the concept of visual servoing, as in the case of the manipulation fault detector of Gu et al. 5 However, this is not the case in autonomous vehicles, where intrinsic dependencies between the different modules of the driving functions are not taken into account.
This work is a contribution in the area of vision dynamics and control, where the proposed learning-based vision dynamics nonlinear model predictive control (LVD-NMPC) algorithm is used for controlling autonomous vehicles. An introduction of the vision dynamics concept in learning control can be found in the work of Grigorescu. 6 The block diagram of LVD-NMPC is shown in Figure 1, where the main components are a vision dynamics model defined as a deep neural network (DNN) and a constrained nonlinear model predictive controller, which receives input from the vision model. The model, trained using the Q-learning algorithm, calculates desired state trajectories and the tuning gains of the NMPC.
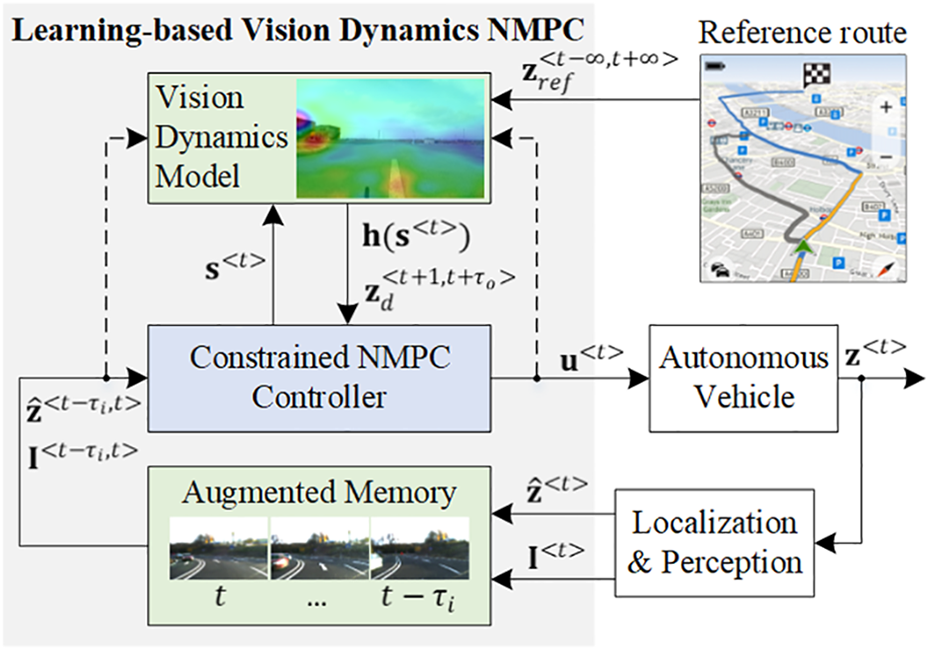
LVD-NMPC: learning-based vision dynamics nonlinear model predictive control for autonomous vehicles. The dotted lines illustrate the data flow used during training. LVD-NMPC: learning-based vision dynamics nonlinear model predictive control.
Synergies between data driven and classical control methods have been considered for imitation learning, where steering and acceleration control signals have been calculated in an End2End manner, as proposed by Pan et al. 3 Their approach is designed for driving environments with predefined boundaries, without any obstacles present on the driving track.
As shown by Grigorescu et al.,
1
traditional decoupled visual perception systems use visual localization to estimate the pose of the ego-vehicle relative to a reference trajectory, together with obstacle detection. The information is further used by a path and behavioral planner to determine a safe driving trajectory, which is executed by the motion controller. In our work, we improve the traditional visual approach by replacing the classical perception-planning pipeline with a learned vision dynamics model. The model is used to calculate a safe driving trajectory and estimate the optimal tuning gains of the NMPC’s quadratic cost function. Our formulation exploits the advantages of model-based control with the prediction capabilities of deep learning methods, enabling us to encapsulate the vision dynamics within the layers of a DNN. The key contributions of the article are as follows: the autonomous vehicle LVD nonlinear model predictive controller, based on an a-priori process model and a vision dynamics model; a DNN architecture acting as a nonlinear vision dynamics approximator used to estimate optimal desired state trajectories and the NMPC’s tuning gains; a method for training the LVD nonlinear model predictive controller, based on imitation learning and the Q-learning training approach.
The rest of the article is organized as follows. The related work is covered in the next section. The methodology of LVD-NMPC is given in “Vision dynamics model learning and control system” section, followed by the experimental results. Finally, the article is summarized in the “Conclusions” section.
Related work
Recent years have witnessed a growing trend in applying deep learning techniques to autonomous driving, especially in the areas of End2End learning, as in the methods proposed by Pan et al., 3 Fan et al. 7 and Bojarski et al., 2 as well as in DRL. Relevant algorithms for self-driving based on DRL can be found in the works of Kiran et al., 8 Kendal et al., 4 and Wulfmeier et al. 9 Flavors of machine learning techniques have also been encountered in more traditional control approaches, such as NMPC, the uncertainty aware NMPC of Lucia and Karg 10 and the learning controllers of Ostafew et al. 11 and McKinnon and Schoellig. 12
End2end learning, as described by Amini et al., 13 directly maps raw input data to control signals. The approach in LVD-NMPC is similar to the one considered by Pan et al. 3 Compared with our method, their DNN policy is trained for agile driving on a predefined obstacle-free track. This approach limits the applicability of their system to autonomous driving since a self-driving car has to navigate roads with dynamics obstacles and undefined lane boundaries. An end2end neural motion planner has been proposed by Zeng et al., 14 while Fan et al. 7 designed an End2End learning system to predict the drivable surface. The work considers no obstacle detection and avoidance, improving solely the perception system, without tackling the intrinsic dependencies between perception and low-level vehicle control.
DRL is a type of machine learning algorithm, where agents are taught actions by interacting with their environment. An extensive review of DRL for autonomous driving has been published by Kiran et al. 8 The main challenge with DRL for real-world physical systems is that the agent, in our case, a self-driving car, learns by exploring its environment. A solution here is provided by inverse reinforcement learning (IRL), which is an imitation learning method for solving Markov decision processes. Wulfmeier et al. 9 have extended the maximum entropy IRL with a convolutional DNN for learning a navigation cost map in urban environments. However, such methods usually do not take into consideration the vehicle’s state and the feedback loop required for low-level control.
NMPC, as presented by Garcia et al., 15 is a control strategy, which computes control actions by solving an optimization problem tailored around a nonlinear dynamic system model. In the last decades, it has been successfully applied to autonomous driving applications, both in research and in the automotive industry. Nonlinear model predictive controllers have been proposed by do Nascimento et al. 16 and Nascimento et al. 17 for trajectory tracking in nonholonomic mobile robots. To deal with uncertainties, learning-based approaches to model predictive control have been used by Lucia and Karg, 10 as well as by Gango et al., 18 for approximating an explicit NMPC system.
Learning controllers (traditional feedback controllers), such as NMPC, make use of an a-priori model composed of fixed parameters. Unlike controllers with fixed parameters, learning controllers make use of training information to learn their models over time. In previous works, learning controllers have been introduced based on simple function approximators, such as the Gaussian process modeling in the work of Ostafew et al. 11 or Bayesian regression algorithm of McKinnon and Schoellig. 12
In the light of the current approaches and their limitations, the LVD-NMPC method is proposed for encapsulating the driving scene’s dynamics within a vision dynamics model, which adapts a constrained NMPC for executing the desired vehicle state trajectory.
Vision dynamics model learning and control system
Problem definition
Figure 2 shows a simple illustration of the autonomous driving problem. Given past vehicle states

Autonomous driving problem definition. Given the vehicle’s state, the global route (red line) and a set of sensory measurements, the goal is to calculate a safe path for tracking (blue line) over the control horizon
The reference trajectory
The vehicle is modeled based on the kinematic bicycle model of a robot described by Paden et al.,
19
with position state
The driving scene is modeled as the vision dynamic state
When acquiring training samples, the following quantities are stored as sequence data: the historic position states
Control system design
The block diagram of LVD-NMPC is shown in Figure 1. Consider the following nonlinear, state-space system

where

where
These dependencies are composed of the system’s and environment’s states at time t, defined as

where
The models

where L is the length between the front and the rear wheel.
We distinguish between the given reference trajectory
The vision dynamics model learns to predict the driving scene’s dynamics
The scene’s dynamics are used to calculate the desired trajectory

where

where
As detailed in the “Learning a vision dynamics model” section, a DNN is utilized to encode

where

where

and

The curvature
The traversable width


In this way, more aggressive control actions can be chosen when the road has high traversability, indicated by a high value of w.
The constrained NMPC objective is to find a set of control actions that optimize the vehicle’s motion over a given time horizon

such that




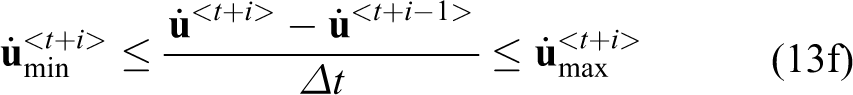
where

at each iteration t.
We leverage on the quadratic cost function from equation (7) and solve the nonlinear optimization problem described above using the Broyden–Fletcher–Goldfarb–Shanno algorithm of Fletcher. 21 The optimization problem from equation 13(a) has been solved in real time using the C++ version of the open-source Automatic Control and Dynamic Optimization (ACADO) toolkit of Houska et al. 22,23
Learning a vision dynamics model
The role of the vision dynamics model is to estimate the scene’s dynamics
Although the model could learn local state sequences directly, as in the previous NeuroTrajectory work of Grigorescu et al.,
24
we have chosen to learn the vision dynamics model
Given a sequence of temporal observations
In reinforcement learning terminology, the autonomous driving problem can be described as a partially observable Markov decision process (POMDP)

where
I represents the sensory measurements;
S is a finite set of states;
Zd
is a set of trajectory sequences, used by the vehicle to navigate the driving environment measured via
The training objective is to find the desired trajectory that maximizes the associated cumulative future reward. We define the optimal action-value function

where

Vision dynamics model implemented as a deep neural network. The training data consist of observation sequences, historic system states, and reference state trajectories. A convolutional neural network firstly processes the observations data stream. Secondly, separate LSTM branches are responsible for calculating the road’s curvature and width, which are then used to obtain the desired path. LSTM: long short-term memory.
Our deep network is processing sequences of continuous temporal observations from the augmented memory component. The augmented memory acts as a buffer, where the observations
The architecture of our DNN is mainly based on convolutional, recurrent, and fully connected layers, shown in Figure 3 in gray, orange, and blue, respectively. The sequence of four convolutional layers is used for encoding the visual input into a latent one-dimensional intermediate representation that can be fed to the subsequent recurrent layers. In particular, the visual input is firstly passed through
One of the biggest challenges of using data-driven techniques for control is the so-called “DaGGer effect” described by Pan et al., 3 which is a significant drop in performance when the training and testing trajectories are significantly different. One measure to cope with this phenomenon is to ensure that sufficient data are provided at training time, thus increasing the generalization capabilities of the neural network. The “DaGGer effect” is also the main reason why a deep Q-learning approach, which uses the reward function to explore different trajectories, is preferred over standard supervised imitation learning. In the next section, it is shown that a high generalization can be achieved, demonstrating that LVD-NMPC can safely navigate the driving environment, even if the encountered obstacles were not given at training time.
Experiments
The performance of LVD-NMPC was benchmarked against a baseline nonlearning approach, coined DWA-NMPC, as well as against PilotNet of Bojarski et al. 2 DWA-NMPC uses the DWA proposed by Fox et al. 25 and Chang et al. 26 for path planning and a constraint NMPC for motion control, relying for perception on the YoloV3 algorithm of Redmon and Farhadi. 27
LVD-NMPC has been tested on three different environments: (I) in the GridSim simulator, (II) for indoor navigation using the 1:8 scaled model car from Figure 4(a) and (III) on real-world driving with the full scale autonomous driving test vehicle from Figure 4(b), as well as on the nuScenes computer vision dataset.

Test vehicles used for data acquisition and testing. (a) Audi 1:8 scaled model car and (b) real-sized VW Passat autonomous test vehicle.
Competing algorithms and performance metrics
DWA has been implemented based on the robot operating system DWA local planner, taking into account obstacles provided by the YoloV3 object detector of Redmon and Farhadi.
27
In the case of the PilotNet algorithm proposed by Bojarski et al.,
2
the input images are mapped directly to the steering command of the vehicle. The steering commands are executed with an incremental value of 0.01°, dependent on the PilotNet’s output, while the velocity is controlled using a proportional feedback law, with gain
To assess the success rate of each algorithm, the ground truth is considered as the path driven by a human driver. The ground truth of the curvature and road width is calculated as for the trajectory sequences Zd in the POMDP setup from “Learning a vision dynamics model” section. The curvature is given by the polynomial interpolation of the human driven path, while the road width’s ground truth is correlated to the longitudinal velocity of the vehicle.
Ideally, each method should navigate the environment collision-free at maximum speed and as close as possible to the ground truth. As pointed out by Codevilla et al.,
28
there are limits to the offline policy evaluation employed in experiment III, which can be partially overcome by choosing an appropriate evaluation metric. The cumulative speed-weighted absolute error of Codevilla et al.
28
has been chosen as performance metric. This metric is intended to equally quantify experiments I and II, which are pure closed loop experiments, with the offline evaluation performed in experiment III. Additionally, the average speed, the curvature error ec
and the processing time have been evaluated. ec
represents the difference between the estimated and actual path curvature, calculated using polynomial interpolation, while
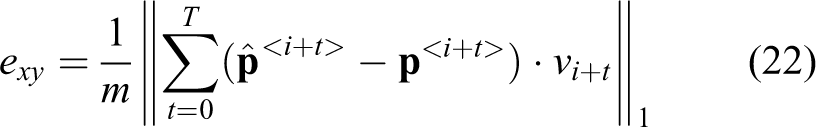
where
The percentage of times an algorithm crashed the vehicle and the number of times the destination goals were reached have also been measured for experiments I and II. In the following, we discuss the obtained values of the computed metrices for the three competing algorithms in the experiments, as summarized in Table 1.
Results for experiments I, II, and III.

LVD-NMPC: learning-based vision dynamics nonlinear model predictive control; DWA-NMPC: dynamic window approach nonlinear model predictive control; STD: standard deviation.
Experiment I: Simulation algorithm comparison
The first set of experiments are simulations over 10 goal-navigation trials performed in GridSim. GridSim, proposed by Trasnea et al., 29 is our autonomous driving simulation engine that uses kinematic models to generate synthetic occupancy grids from simulated sensors. It allows for multiple driving scenarios to be easily represented and loaded into the simulator. The simulation parameters are the same as in the NeuroTrajectory state trajectory planning approach of Grigorescu et al. 24
For training PilotNet and LDV-NMPC, the goal navigation task was run over
Overall, as indicated by the values of the percentage of crashes (
Experiment II: Indoor algorithm comparison
In this experiment, we have tested using the 1:8 scaled Audi model-car vehicle from Figure 4(a) with different indoor navigation tasks. The reference routes which the car had to follow were defined as straight lines, sinusoids, circles, and a
LVD-NMPC provided the highest quantitative results, apart from the processing time, which was better for PilotNet. The main reasons for DWA-NMPC’s increase in computation time comes from uncertainties in environment perception and localization. This is a common phenomenon encountered in decoupled processing pipelines, where a decrease in perception accuracy produces a decrease in control performance and vice versa. This is not the case with LVD-NMPC, since perception is tightly coupled to motion control through our vision dynamics model. The model-based nature of our algorithm allowed us to outperform a model-free method such as PilotNet, which tends to have a jittering effect in its control output.
A snapshot from the control loop of LVD-NMPC is shown in Figure 5, where the desired trajectory (depicted in green) is calculated using the output of the proposed DNN from Figure 3 and a set of candidate trajectories (shown in blue) calculated using the dynamic model of the vehicle from equation (4). We have observed that the advantage of LVD-NMPC relies in the combination of the analytical dynamic model of the car, which is subsequently adapted to unseen situations by the deep network’s estimations, as specified in the state estimation equation (2).

Desired trajectory estimation using LVD-NMPC. The vehicle selects the best desired trajectory (green) from the set of possible candidates (blue) (best viewed in color). LVD-NMPC: learning-based vision dynamics nonlinear model predictive control.
Figure 6 shows velocity, steering, position errors, and heading errors for a trial distance of
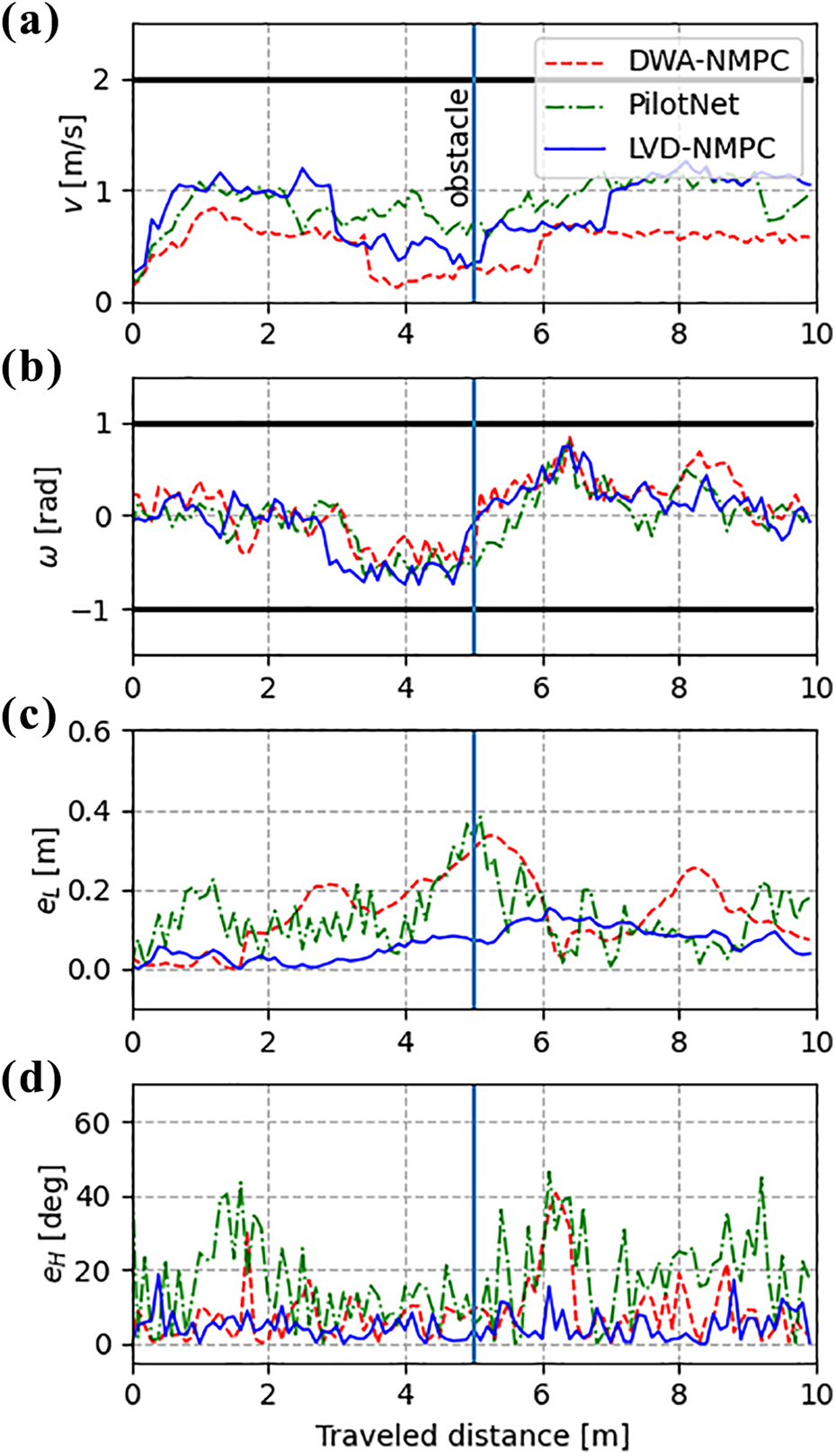
(a–d) Velocity, steering, position errors and heading errors versus a 10-m travel distance using the model car from Figure 4(a). LVD-NMPC provides a smoother vehicle trajectory, leveraging on learned obstacles and environmental landmarks when learning the vision dynamics model. Actuator constraints are shown with black lines. LVD-NMPC: learning-based vision dynamics nonlinear model predictive control.
To assess the behavior of the methods with respect to the DaGGer effect, we have placed on the reference route obstacles, which were not given at training time. The DNNs embedded in LVD-NMPC and PilotNet managed to bypass the obstacles, leveraging on environment landmarks present in the training data. This points to the fact that although the learning-based approaches were able to correctly adjust the vehicle’s trajectory, they still require enough training data to recognize environment landmarks.
Experiment III: On-road algorithm comparison
Finally, the third experiment tested LVD-NMPC on over
In addition to our own real-world driving data, we have evaluated the competing methods on the nuScenes dataset (https://www.nuscenes.org/). Among different benchmarking datasets, we have chosen nuScenes due to its sensor setup and odometry information. The data collection contains over
We have encountered similar results to the ones in experiment II, with LVD-NMPC providing a more accurate estimate of control outputs. Due to the fact that the test vehicle is a real-sized car (as opposed to the 1:8 Audi model car), the values of
As shown by the results from the real-world experiments I and II, given in Table 1, our model delivers an inference time of slightly above 60 ms on an embedded NVIDIA AGX Xavier development board, equipped with an integrated Volta GPU processor, having a 512 CUDA cores. Depending on the speed of the vehicle, this inference time could be sufficient if the vehicle is traveling at a relatively low speed. However, an increase in computation time is required for high speed vehicles, where the environment also varies with a higher speed.
The metrics used in Table 1 could be aggregated together in a single metric, where each element, that is percentages of crashes and goal reach, average speed, position and curvature errors and processing time, would be combined in a single weighted function. Nevertheless, in this case, the intrinsic values of the individual measurements would be lost. As an example, a model yielding an optimal metric value due to high processing time could crash more often than a model, which is slower in terms of computation time.
Conclusions
This article introduces the LVD-NMPC approach for controlling autonomous vehicles. The method uses a DNN as a vision dynamics model, which estimates both the desired state trajectory of the vehicle, given as input to a constrained nonlinear model predictive controller, as well as the weighting gains of the aforementioned controller. One of the advantages of LVD-NMPC is that the Q-learning training is self-supervised, without requiring the manual annotation of the training data. The experimental results show the robustness of the approach with respect to state-of-the-art competing algorithms, both classical as well as learning-based.
As future work, we plan to investigate the stability of LVD-NMPC, especially in relation to the functional safety requirements needed for automotive grade deployment. Being already implemented on an embedded device, that is the NVIDIA AGX Xavier, we believe that the controller can be used on real-world cars, provided that the safety requirements are met. Setting safety aside, its current implementation is directly linked to the computation power of the vehicle’s computer. The faster its deep learning accelerator is, the more dynamic situations LVD-NMPC could cope with.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed the receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the European Union’s Horizon 2020 research and innovation program under grant agreement no. 800928, European Processor Initiative EPI.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.