
Abstract
Free space detection is crucial to autonomous vehicles while existing works are not entirely satisfactory. As cameras have many advantages on environment perception, a stereo vision-based robust free space detection method is proposed which mainly depends on geometry information and Gaussian process regression. In this work, in order to improve the performance by exploiting multiple source information, we apply Bayesian framework and conditional random field inference to fuse the multimodal information including 2-D image and 3-D point geometric information. Particularly, a Bayesian framework is used for multiple feature fusion to provide a normalized and flexible output. Gaussian process regression is used to automatically and incrementally regress the data, resulting enhanced performance. Finally, conditional random field with color and geometry constrains is applied to make the result more robust. In order to evaluate the proposed method, quantitative experiments on popular KITTI-road data set and qualitative experiments on our own campus data set are tested. The results show satisfactory and inspiring performance compared to the outstanding works and even are competitive to some relevant Lidar-based methods.
Keywords
Introduction
Autonomous vehicle has a basic perception task often called “free space detection” which means to seek the ground where is able to traverse from the current location. The mostly used sensor for this task is Lidar which provides accurate 3-D measurement of the environment. However, it is very expensive and cannot capture the content information. On the contrary, camera is very cheap and also can provide dense points with color information. In addition, the great improvement of stereo vision in recent years allows feasible 3-D measurement. Thus, vision-based free space detection becomes very popular. 1
In the previous work, 2 Lidar-based ground segmentation using Gaussian process regression is very powerful not only in urban but also in rural environment which can be regarded as a versatile algorithm not limited by the scenes as well as pre-trained models. It models the heights of ground points to be jointly Gaussian distributed and applies the Gaussian process regression to incrementally classify the ground points. However, it is not sensitive to the obstacles with low height such as curbstones so that it needs additional curb detection module 3 to handle this problem. Actually, the source height as feature is not feasible in many cases because of the bias of calibration and the non-flat ground which both can cause the heights of objects in local coordinate to be inaccurate. Figure 1 shows a simple situation where a wrong height of the obstacle is measured due to the non-flat ground.
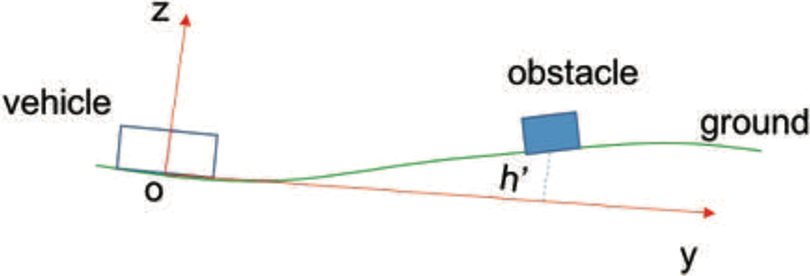
Illustration on the local scene of a vehicle. The non-flat ground makes the obstacle “fly” in the air.
In this article, in order to take advantages of multimodal information, both 2-D image and 3-D space geometric information are used. The method is focused on the 3-D geometry and tries to use a set of simple features to detect free space and applies a flexible fusion framework to improve the previous work without additional modules such as curb detection. The proposed method provides the 3-D points from the stereo for simplicity which is of cause not limited by this way and does not need to make prior assumptions about the geometry of the scenes and is able to detect many types of unstructured obstacles even the medium grass. Figure 2 shows a typical result. In this figure, it shows that the algorithm not only successfully detects the front cars as obstacles but also the small curbs on the left and even the medium grass on the right as well.

A typical result of free space detection. In the middle of (a) is the original image, top is the disparity map, and bottom is the free space detection result in green. (b) The corresponding bird view in which gray represents the traversable area, red represents the obstacles, and black is unknown area. Note that the cyan circle represents the location of the vehicle and the white lines from close to far represent the distance of 0 m, 10 m, 20 m, and 40 m, respectively. This map can be used for path planning which describes the local map of the span
Although free space detection is similar at some extent to road detection, they are indeed different in details. Thus, the evaluation criteria in KITTI-road 4 detection are not very feasible for this task. Actually, there is few labeled data set for free space detection. Perhaps for the evaluation, the suitable criteria should be made by path planning which says the detection is good when it returns a successful planning result. This will be discussed in “Experiments and discussion” section. Nevertheless, the tests are still performed on KITTI-road detection task for quantitative evaluation as a reference and on our own campus data for qualitative evaluation. Also the tests take the works by Badino et al. 5 and Chen et al. 2 as baseline of free space detection for comparison on these data sets. The performance shows classification results comparable to the state of the art.
Our contribution in this work includes: It is the first time to apply stereo vision with Gaussian process-based segmentation algorithm on free space detection. In order to avoid the hard threshold classification, a soft and flexible Bayesian probability-based multiple feature fusion framework is proposed. It is convenient to be extended because of the probability representation. Considering the stereo depth uncertainty, a feasible nonstationary covariance matrix for Gaussian process is modeled. It combines the curb detection naturally so that there is no need to add additional curb detection module. A high order geometry similarity constraint is added to the conditional random field to enhance the performance. Last but not the least, comparisons show not only on KITTI-road data set but also on our own data to validate the versatility of this method.
Related works
Over the past years, many works on vision-based free space detection have been proposed. Generally, they are classified as four methods which focus on different aspects: disparity property-based method, occupancy grid-based method, geometry-based method, and learning-based method.
V-disparity 6 is a prime approach in free space detection using disparity property and many other methods are based on this idea 5,7,8 It takes the disparity map as input and accumulates the number of pixels with the same disparity values along each row, obtaining a new map whose rows are the image rows and columns are the disparities sorted increasingly. Therefore, each row in this v-disparity map often contains a dominant value which shows that most of the pixels in this row take the same disparity. Thus, this new map will display a nearly linear slope because most of the pixels in each row are of the ground. Then, a Hough transform is utilized on this map to find the best disparities that are fitted in the slope. Those pixels with the corresponding disparities are of the free space. In addition, some vertical segments in the v-disparity map represent the obstacles. Depend on these features, it is able to distinguish the free space and obstacles. However, the accuracy of the calibration has to meet some high requirements to keep it not fail when the scene is complicated. Also it is much influenced by the aspect ratio of the v-disparity map. When it is large, the disparity slope will seem to be nearly vertical as well as the vertical segments which makes the segmentation between the free space and obstacles very difficult.
The next one is the occupancy grid method which is very widely used because it is suitable for local representation and convenient to the path planning. Badino et al. 5,9 proposed a middle-level representation called stixel for free space detection which uses erect sticks to represent the obstacles. It separates the local ground to be a set of grids and uses “u-column” coordinate to accumulate the disparity values into the grids. Then apply dynamic programming twice to calculate freespace and height segmentation to generate the stixels. This middle-level representation largely reduces the computation and makes it as a very popular baseline on free space detection. However, this algorithm is ambiguous to the free space selection because the dynamic programming considers u-column map as a whole at a time which is vulnerable to the noise so that this often returns false detection. In addition, it relies only on the accumulation of disparity and thus it is often not enough. Oniga et al. 10 and Oniga and Nedevschi 11 proposed an enhanced algorithm which uses a quadratic road surface model to fit the road and applies a plenty of features including height and point density and so on to classify the free space and obstacles. This, however, model limits itself to fit simple roads, and these features are not robust to the varying scenes. Another famous grid-like method is called Bayesian occupancy filter. 12,13 It considers not only the current but also the sequential local map within a Bayesian filtering framework to estimate and predict the status of the occupancy grids. This unified model takes the temporal information into account which improves the free space detection as well as the obstacle detection.
Nevertheless, the above methods have a common issue that they need to assume the ground to be flat or have to first estimate the ground using quadratic surface or Non-Uniform Ratioinal B-Splines (NURBS) models. 14 This kind of global estimation often fails due to many aspects in complex situations such as occlusion and it often smooths heavily so that omits some details like curbs.
Geometry-based methods are simple but effective. Manduchi et al. 15 proposed a geometry-based obstacle detection. The key idea is to use the natural property of the 3-D geometry such as the height difference between the points. This is a general way to classify the obstacles and ground. But the computational burden of this way is really heavy. Santana et al. 8 optimized the calculation for each 3-D point and utilized Graphics Processing Unit (GPU) to speed up. Mendes et al. 16 modified this algorithm in a dynamically sized sliding windows framework on a GPU to reduce the computation as well. Some varied approaches are proposed, 17,18 which use similar geometry principles to get a probability representation and apply Delaunay triangulation to generate the graph model for free space detection.
The statistical or machine learning techniques associated with temporal information are also popular in this topic. The learning-based method is powerful due to the well-developed learning models such as boosted trees and deep networks. They have the absolute advantages for the detection on content-oriented scenes such as road with grass aside which is hard to classify by geometry but very easy by learning-based methods. Nevertheless, they are limited by the training data and perhaps perform well at the pre-trained scenes. Kühnl et al. 19 proposed an approach based on the computation of spatial ray features which generates many rays in several directions of each base point and applies trained classifier on the accumulated ray features to detect the lanes and road. Xiao et al. 20 –22 use boosted trees to train the road model and fuse the color and Lidar information into the conditional random field to obtain a coincident result. Deep learning-based methods 23 have achieved nearly a perfect result that relies on powerful deep network architectures which shows that for certain scenes, the models can be well learned but it is not sure that the models can be transferred in other unseen environment without retraining.
In addition, for free space detection, most of these methods model the road well but often fails at the curbstones. Therefore, they have to add an additional curb detection module. Siegemund et al. 24 model the curb as the boundary between the road and sidewalk which are both regarded as flat surfaces, then it uses sigmoid function and conditional random field to fit the curb. In order to improve the smoothness of the curbs, in the study by Siegemund et al., 25 a temporal conditional random field is used to measure the sequential information. Kellner et al. 26 use stereo vision to generate a curb feature map and then fuse the sequential image information to find the edges. Similarly, Oniga and Nedevschi 27 also proposed an image processing-based method which uses sequential Digital Elevation Model(DEM) features to find the curb points and then connects them by polynomial curves. However, all these methods have to be delicately chosen and the assumptions are too restricted to utilize in other situations.
Lahat et al. 28 point out multimodal data which bring more information to improve the performance. Since 2-D image representation has its limitation, the capability of the method with the help of 3-D information such as Lidar points or even tactile 29 and haptic 30 information will be highly enhanced. For the fusion process, a wide range of methods are applied in different fields. Liu et al. 31 –33 apply sparse coding technique to fuse information from different sources or timestamps. Bayesian formula and conditional random field 34 are also excellent frameworks to fuse multiple types of data in a standard process.
System overview
Figure 3 illustrates the proposed vision-based free space detection system which consists of four parts: stereo processing, multiple features generation and Bayesian probability fusion, Gaussian process refinement, and conditional random field integration. At the beginning, the left and right image data are obtained. Then, a superpixel-based stereo method 35 is used to improve the disparity map at some extent. After the dense disparity map generated, some simple but very robust 3-D features are computed and fused into Bayesian framework to obtain an energy representation so that the output is mathematically normalized, which is a soft measurement compared to the previous work. Unlike the threshold strategy, a filter-like Gaussian process is utilized to automatically fit the energy values of the ground and reject those of obstacles. Finally, the energy data term and the pairwise term of color and geometry constrains are integrated into the conditional random field module to achieve a smooth and coincident free space local map. The following sections will discuss each module of the system.

System overview.
Stereo data acquisition, polar coordinate representation, and feature representation
Stereo data acquisition
An efficient and robust stereo algorithm is vital to a stereo vision-based system. As semi-global matching (SGM) 36 is very sophisticated and widely used not only in research but also in commercial products, 37 it is applied in our system as well. However, the original algorithm still cannot handle the holes well enough and sometimes fails due to the occlusion or light condition variation which makes the 3-D scene not feasible and consequentially deteriorates the performance. Therefore, the Slanted Plane Smoothing Stereo (SPSS) algorithm 35 is utilized for smoothing the scene. Figure 4 shows the comparison on the disparity maps between the two algorithms. It can be seen that there is few holes left, and the depth accuracy still remains in SPSS relative to SGM. Nevertheless, SPSS models the scene as a set of slanted planes, which weakens the vertical features that are important to the geometry-based obstacle detection such as cars and curbs detection and so on. This turns out to decrease the performance at some extent. In spite of this, it is still able to provide an acceptable disparity map in many cases. Note that the system is not limited to adopt this kind of stereo algorithm.

Comparison on (a) and (b) SGM results and (c) and (d) slanted plane smoothing results. SGM result (first row in (a)) leaves some holes in the ground causing false obstacles in the traversable area (bottom image in (a)) which can be best viewed in the BEV (b). However, SPSS (first row in (c)) resolves this issue and helps to improve the result best viewed in the corresponding BEV (d). SGM: semi-global matching; BEV: bird eye view; SPSS: Slanted Plane Smoothing Stereo.
Polar coordinate representation
After the disparity map is obtained, a suitable data representation is required. As some image-based methods 9,11,12 do, the local map is built in a grid style in which the columns mostly correspond to the image columns. However, this is sometimes unreasonable according to the basic ray-projection property of vision. To avoid misunderstanding, the polar coordinate representation is used. Figure 5 illustrates this representation. It can be seen that it is more natural than the column style especially in free space detection because each ray represents a possible direction that a vehicle can go through. Since the frontal area of a vehicle is usually traversable, the origin of the polar coordinate often settles here which corresponds to the middle of the bottom image. Note that the origin of the polar coordinate can also be set at the center of the vehicle but this will cause a small gap where there are no points due to the uncovered field of view so that it sometimes makes the system fails. This can be shown in the bird eye view (BEV) in Figure 2 where there is a gap between the location of the vehicle and the ground area.

Polar coordinate representation.
Therefore, after the stereo reconstruction with pinhole camera model, a set of 3-D points

where
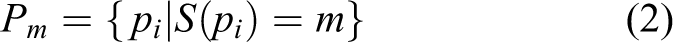
Each segment will be divided into N bins to separate the points for management. For the nth bin

This representation resolves the complex 2-D free space detection problem into many 1-D regressions. All points are well represented and free space detection aims to find the point set
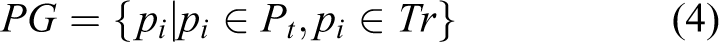
where
Bayesian-based multiple feature fusion framework
In the previous work, 2 only simple height feature is used, causing incorrect detections and making additional effort, for example, curb detection. 3 Additionally, the hard threshold classification on ground and obstacle cannot describe the extent how the point belongs to ground or obstacle. Therefore, Bayesian probability framework is proposed to tackle these problems.
Given a point

where g represents the class of free space,
One step further, in order to fit the conditional random field framework, the fused probability of point
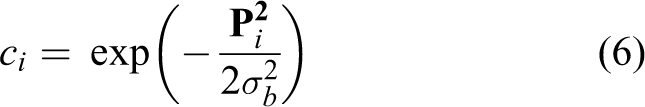
where
Note that, features are not restricted to 2-D or 3-D. Any feature is acceptable if it supports to distinguish the free space and obstacles. Theoretically, more features will certainly improve detection performance. Unlike the learning-based methods, in this article, we mainly focus on 3-D features which are very simple but effective and robust for general situations.
Next subsections will discuss about the features used in our system.
Normal vector feature
Vehicles can traverse flat ground and gradual slop while they are unable to pass through the sudden change area where it is often regarded as an obstacle. Many vision-based methods use the height difference as features to detect the obstacles such as cars or pedestrians, but sometimes the difference is not obvious such as curbs and so on. A simple but effective idea is to apply the normal on each point. It shows significant change even though an unnoticeable change in height feature space. Figure 6 illustrates the local normal features on the small curb obstacle compared to that on the ground. The normal changes 90°, while the height may differ just a little.
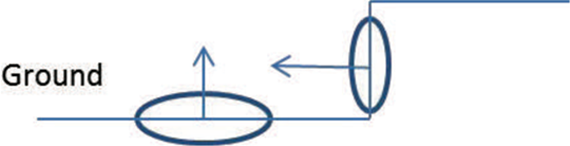
Simple illustration on the change of normal vector feature on different locations.
In this article, the problem of determining the normal to a point on the surface is approximated by the problem of estimating the normal of a plane tangent to the surface, which in turn becomes a least-square plane fitting estimation problem. 38
Here, Point Cloud Library (PCL) library 38 is used to compute the normals for each point. However, one important aspect which influences the estimation of the local normals is that the density of the points will decrease along the distance so that estimation in certain distance will probably fail and return null. Thus, it forces different algorithms for near and far. For the points whose distances are less than D, the radius-based method is used, while for the far points, the K minimum number-based method is used. Considering the reliable distance of points from camera is about 15 m, and for path planning, the grid resolution of the local map is about 0.2 m, and the parameters here are set as D = 15 m, R = 0.3 m, and K = 200.
When all points’ normal vectors are estimated, they are dotted by a normalized vector

Unlike the method to find a hard threshold to distinguish the ground and obstacle,

where
Vicinity height feature
The assumption is not always correct that the vicinity of a vehicle is traversable because sometimes an obstacle just stands nearby so as to make the normal vector feature happen to avoid the vertical surface. Although, as illustrated in Figure 1, the reliability of the height feature decreases along the distance, features in close area of a vehicle are accurate enough. Thus, a simple height feature is applied to describe the traversability in the vicinity of a vehicle.
Considering the situations vary in different directions where each direction corresponds to a polar segment. For polar segment m, the traversability of the ith bin

where k and K are with respect to the number of the points whose heights are higher than a threshold and the total number of the points in the first n bins of polar segment m,
This equation shows that, in vicinity, the ground height higher than a certain threshold will be assigned with low traversability and regarded as an obstacle to prevent the vehicle to go through. Practically, these parameters can be set as
Other useful features
Other useful features are also compatible to this framework. For example, the color and texture can bring useful information, especially for detection on the grass area of the two sides of the road. However, they vary in different scenes and light conditions. Learning-based methods have to collect a large number of training samples each time for specific scenes, otherwise the trained classifier may occur overfitting issue. Therefore, these features have to be carefully adopted.
In this article, the color and texture information in work 20 is adopted. This pre-trained road detection classifier uses boosted tree to generate probability output which is suitable into our framework.
Gaussian process regression
Motivation
There have been many models for this kind of regression task. 39 However, we need a probability representation in our framework. For this reason, the main aspect considered is the mean and variance for each point. However, among these regression models, only Gaussian Process (GP) can return not only mean but also the variance as a probability style, while other models like Support Vector Machine (SVM) or neural networks are probably not. In addition, as Figure 1 shows, the undulatory ground will cause the obstacle detection fail due to the incorrect height estimation. This also affects our fused features when the distance increases because the ground is not the same as the vehicle coordinate plane, especially in the distance. Therefore, an algorithm is needed to gradually fit the ground from near to far. As discussed in “Related works” section, some used methods such as quadratic or B-spline curves and surfaces (NURBS) 40 ground modeling are not accurate because quadratic plane modeling is too simple to fit the undulatory ground, while NURBS models the scene as a whole making the details missing especially in the distant area. However, because of the capability to represent mean and variance, the GP can process the points along each segment incrementally with a variance. It can predict the mean and variance for a new test point by the previous seed points. Thus, it can adapt to the case where the values gradually change along this segment direction. GP can also decide whether the non-seed point is a new seed by the criteria of mean and variance. However, if it is applied by SVM for the regression task, it has to firstly train a model for the initial seeds and use it to test a non-seed point and returns just a regression value but cannot be decided whether it is a seed or not unless it is given a threshold, and then train a new SVM model by the current updated seed points again for the test on next non-seed points. But this approach has to find a way to decide the thresholds and update them for all the points along this segment because the thresholds for the points at different distances should not be the same.
Brief overview of GP
Gaussian process models input to be a set of random variables, any finite number of which have a joint Gaussian distribution. 41 The key property is that it is a nonparametric continuous representation that provides a powerful basis for modeling spatially correlated and uncertain data. Gaussian process regression can be viewed as a filter to regress the data automatically and incrementally by their Gaussian attribute.
Recall that, the input data have been spatially separated into M segments. For each segment m, the process can be regarded as 1D Gaussian process regression. The pairwise data set
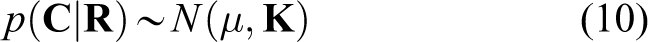
where

where
The covariance function has a variety of types. Among them, the frequently used

where l is the length scale, and

Therefore, the prediction for Gaussian process regression is as follows

where
So far, the problem can be set as given a set of input data in one segment, the goal of Gaussian process regression is to regress the cost values of the traversable points incrementally from close to far and return the estimated free space.
Gaussian process regression-based cost energy computation
When all points are assigned into the corresponding polar segments and bins, the fused probability and cost values for them are computed. Then next step is to find the free space points by Gaussian process regression. In equation (2), due to the powerful estimation ability, the Gaussian process regression is used in each segment not only to reject the outliers but also to regress the ground points by their height features and then apply a simple height threshold to classify the ground and obstacle points. However, as discussed above, there are at least two drawbacks. One is the height feature that it is insensitive to obstacles with small height such as curbs; the other is the hard threshold strategy that it is not robust enough for many cases. In this article, it is adopted but in a modified way to generate the energy for each point for the following CRF process. Algorithm 1 illustrates the main steps.
This algorithm shows the details of the module Bayesian probability and the module Gaussian process in Figure 3. It accepts the stereo 3-D points and image as input data and outputs the energy of traversability of each point. The algorithm contains seven steps: the polar grid map representation, fused feature cost computation, seed initialization, Gaussian process regression, new seed evaluation, mean and variance estimation for each bin, and energy of each point computation.
The polar grid map representation is processed as the function
The next step is the fused feature cost computation for each point in line 2, which computes multiple features and map them into a cost value through Bayesian probability framework and a Gaussian-like function. The detailed description is illustrated in “Bayesian-based multiple feature fusion framework” section.
The third step is the seed initialization in line 5. This process selects the initial points for the next Gaussian process regression as training data. The criteria for seed initialization are simple that the points with cost values less than
The Gaussian process regression in line 8 regresses the low costs of ground points automatically and incrementally from close to far through the model trained by the initial seeds as equation (13) illustrated while assigns gradually increasing costs to the outlier points whose costs go away from the estimated values of ground. This process will also


Details in a typical segment. (a) Original image with a green line covering a typical segment. The features in this segment are shown in (b). Two red rectangles point to the curbs. (c) Ground estimation based on Gaussian process regression.
The new seed evaluation is the process called eval in line 10. This step makes the ground estimation has the ability to extend further. After the covariance,

where
In order to transform the cost value of each point into the data term of CRF, the mean and variance of each bin are calculated (line 12) according to equation (14). When all the above procedures are done, the seeds and the corresponding Gaussian process regression model are determined.
The last step is the energy computation of each point. In each bin, the cost energy

where
From all the above steps, the modified algorithm has resolved the mentioned issues at some extent. Bayesian framework-based multiple features fusion outputs a more sensitive feature compared to just height feature which makes the description more robust. And an energy representation for CRF from Gaussian-like mapping is more flexible than a hard threshold as in equation (2).
For each pair of parameters, introducing Gaussian process regression will enhance the performance. In Figure 7, it shows a typical result in one segment. The green line in source image of Figure 7(a) marks the corresponding segment. It covers the ground firstly and a sudden change which may be regarded as a curb or an obstacle, then it goes through the surface of opposite road until reaching the other side curb and passes over it to the end. Figure 7(b) shows the source height and the corresponding feature values along this direction computed from “Bayesian-based multiple feature fusion framework” section. From this figure, it can be shown that modeling the ground to be plane or quadratic surface is not accurate even though B-spline-based fitting strategies may perform well, and it is much complex and cannot measure small regions precisely. Similarly, the ground and small obstacle (e.g. curb) segmentation based on height feature is also very difficult which can be seen from the two red rectangles containing the mentioned curbs. On the contrary, the values of the proposed feature vary significantly at the sudden changes while those of the ground remain stable and relatively small. This makes it easier to classify the ground and obstacles.
After the fused feature energy is obtained, Gaussian process regression is used to regress the values corresponding to the ground while rejecting the ones to the obstacles. In Figure 7(c), the blue points represent the initial candidate points, the red ones are the seeds for Gaussian process regression, and the green ones are the estimate values representing the ground. At the sudden changes, the estimate green points try to fit the candidate points but fails, then these outliers are assigned high energy as candidate obstacles by equation (6). So this process can be regarded as a self-adaptation and leads to improve the classification.
Covariance matrix selection
Although the SE covariance is suitable for many situations, the main drawback is that the length scale is constant over the whole input space. 41 Note that the length scale is the key element of the SE covariance matrix, and its main property shows that the Gaussian process will fit the input data tightly when the length scale is small, otherwise loosely. Further, the vision-based methods will also bring uncertainty in 3-D positions of the points which will also affect the accuracy at some extent. In order to modify the length scale automatically by the input data to fit different situations and also take into account the stereo uncertainty, the nonstationary, isotropic covariance matrix proposed by Paciorek and Schervish 43 with modified length scale for stereo data is proposed.
Take one segment of the polar grip map for example. The nonstationary, isotropic covariance matrix takes the form as follows

where
Therefore, the length scale
In this article, the modified length scale is modeled as follows
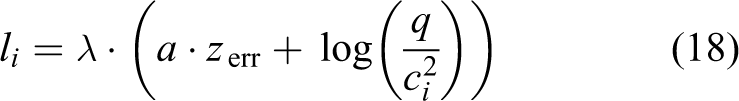
where a is a scale factor to balance the numeric issue between the stereo depth uncertainty and the cost value which is set as a = 10 in this article, and λ is a scale factor as well,

where
Note that covariance matrix has a variety of types as long as it is reasonable and the covariance matrix is to be positive defined. 41 This proposed matrix works well to represent the relationship between the length scale and the characteristics as discussed above. The next step is to seek the solution of the hyperparameters of the covariance matrix.
Learning geometric hyperparameters
As “Covariance matrix selection” section discussed, the nonstationary covariance matrix has the advantages over the stationary one but needs to be modified due to the vision uncertainty introduced. Equations (17) and (18) provide a feasible model to take into account the vision uncertainty in length scale. However, the hyperparameters
Given a set of training data

where
Therefore, compute the partial derivatives of the pseudo log marginal likelihood with respect to the hyperparameters to seek the feasible values as follows

where

where
As there are few labeled free space detection data sets for vision, the KITTI-road detection data set (4) is used. Actually Gaussian process regression is very robust to the parameters so that a few training data are enough to get a feasible result. In this article, three images from each scene are randomly selected as training data for Gaussian process regression to learn the hyperparameters. Finally, the obtained parameters are
Considering the number of the training images for Gaussian process regression is relatively small to the whole training image set provided by KITTI, testing on training data including the nine images for integrity consideration will have little influence on the performance.
CRF fusion
As Figure 3 shows, the Gaussian process regression will produce the energy-like output. However, incorrect detection is inevitable such as holes or false detection. In order to make the final result more robust and smooth, conditional random field is used which has been very popular in computer vision community. For free space detection, the final result can be regarded as a two-class classification problem (traversable and non-traversable) for each point. In addition, the method in this article focuses more on geometry features so that the constrains in CRF include not only the color information as usual but also the geometry information.
Given a set of pixels
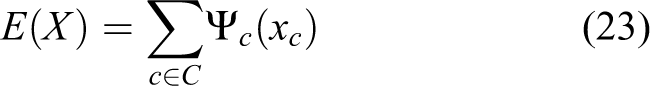
where C is the set of all cliques,
Usually, the potential function
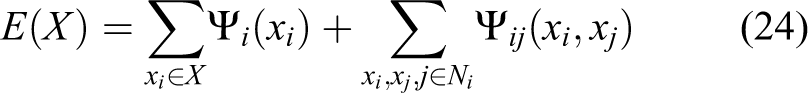
where
Similarly as the mapping in equation (20), the unary potential
Usually, the pairwise potential is quite important and most works take into account the color consistency. In this article, the pairwise potential also considers the geometry constrains. Thus, the pairwise potential takes the form as follows

where

where

where
In Figure 8, it shows the pairwise constrains of color information and geometry information.

Pairwise constrains displayed in images. The first row from (a) to (d) shows the pairwise constrains of color information which correspond to horizental, northwest, southwest, and vertical direction in image space, respectively. The bottom row from (e) to (h) shows the counterparts of geometry constrains.
Experiments and discussion
Experiment settings
Basically, the experiments are tested on a laptop with 16 GB RAM and single Intel Core i5-6300HQ with 2.3 GHz. The algorithm was implemented with C++ under Ubuntu14.04. The parameters of the proposed algorithm are mainly set for stereo matching, feature fusion, Gaussian process regression, and conditional random field inference. Note that the parameters of feature fusion and GPR are introduced in the corresponding “Gaussian process regression” and “Bayesian-based multiple feature fusion framework” sections. Others will discussed in the following. Table 1 briefly shows the time-consuming in each step in our proposed algorithm. Since it is not well optimized, the average computation time-consuming is about 30 s for each frame. However, it is possible to accelerate by parallel or GPU computation.
Time-consuming by steps.

For the parameter selection in stereo algorithm, our goal is to obtain a smooth depth map but still details remained as much as possible. In order to find a proper parameter set, the previous algorithm which only exploits the height feature is used. Figure 9 shows the comparison on MaxF scores with respect to the number of superpixels. More superpixels will keep more details theoretically, but probably make the depth map unsolvable and consume much more time. Therefore, 8000 superpixels are chosen and the smoothness is set to 10 experimentally.

MaxF scores with respect to the number of superpixels.
Data sets
In order to valid the approach proposed in this article, quantitative and qualitative experiments are tested on two different data sets. One is the KITTI-road (4) for quantitative test as a reference. Another is our own campus data set for qualitative test.
The KITTI-road data set benchmark contains 289 training and 290 testing pairs of images with calibrated parameters which includes three categories (both for training/testing):
The campus data set contains an amount of pairs of synchronized images in campus scene. Although the scenes in this data set are not complex, they are different in light condition and color distribution compared to KITTI data set.
Baseline
In order to show the improvement of this approach compared to typical free space detection algorithms, the method in previous work (2) is changed into vision-based version called Height+GPR, and the method in equation (9) is implemented called Stixel for comparison. Although the performance perhaps decreases due to the different implementation, the comparison will show the significant improvement.
At the same time, other similar methods in KITTI-road are also compared for reference including HistonBoost, 46 BL, 4 RES3D-Stereo, 17 and BM. 47 In order to compare a learning-based method, a subpart of the method in equation (20) called ColorBoost is used as an example.
Quantitative result on KITTI data set
In this part, three comparisons are tested.
MultiFeat+CRF versus MultiFeat+GPR+CRF
To valid the improvement of Gaussian process regression, the methods with and without this process are compared. One applies fused multiple features directly combined with CRF which is named MultiFeat+CRF for short. The other applies Gaussian process regression after the multiple feature fusion which is named MultiFeat+GPR+CRF. At the same time, a set of experiments on comparing the CRF parameters
As the metric MaxF comes in the first place in KITTI-road ranking, the comparison mainly focuses on this parameter. Figure 10 illustrates a set of comparisons on three different scenes of KITTI-road with different CRF parameter pairs. In this figure, it is obvious that one with Gaussian process regression outperforms the counterpart which is without this process.

MultiFeat+CRF and MultiFeat+GPR+CRF for MaxF result on training data set with different CRF parameter pairs.
In the methods with Gaussian process regression, the performances will gradually rise up when geometry constrain parameter

Comparison on CRF parameters showing the property of color and geometry constrains.
MultiFeat+GPR+CRF fuses pre-trained color and context classifier
The algorithm in this work mainly focuses on geometry features, while in order to show that it is flexible to add new features to improve the performance, the color and context features trained by boosted trees in equation (20) are introduced in the fusion framework. The improvement by new feature is shown in Figure 12 where the color and context information makes the first sudden change on the left at the boundary between road and medium grass rises up significantly in Figure 12(e) compared to that in Figure 12(d) without this additional feature, thus enhances the classification result.
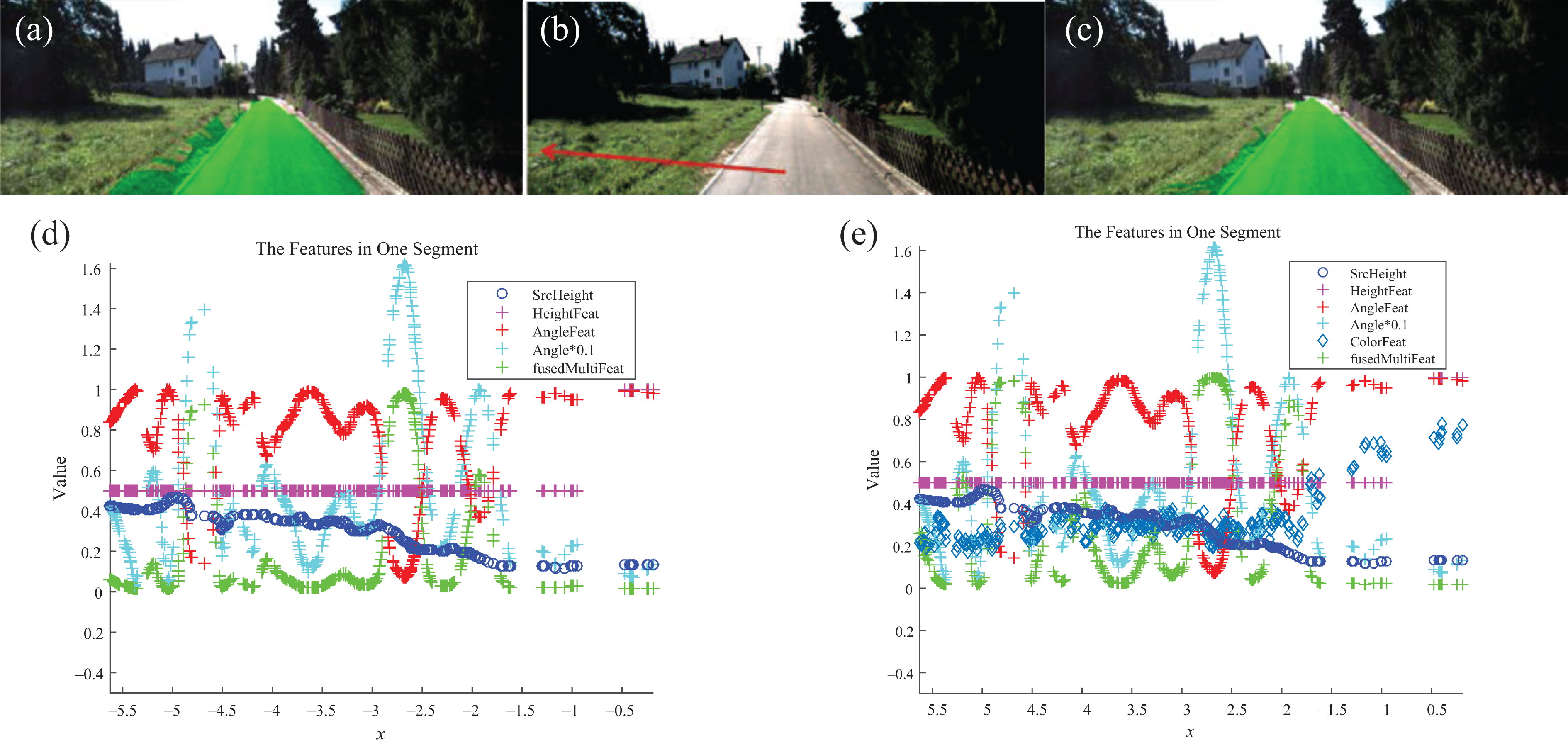
Additional color and context feature enhances the classification result. (b) The original image with the specified segment in red. (a) and (c) The detection results with respect to the methods with and without additional color feature. (d) and (f) The corresponding details of the features in this segmentation. The new added feature improves the energy (in green) of the free-space estimates.
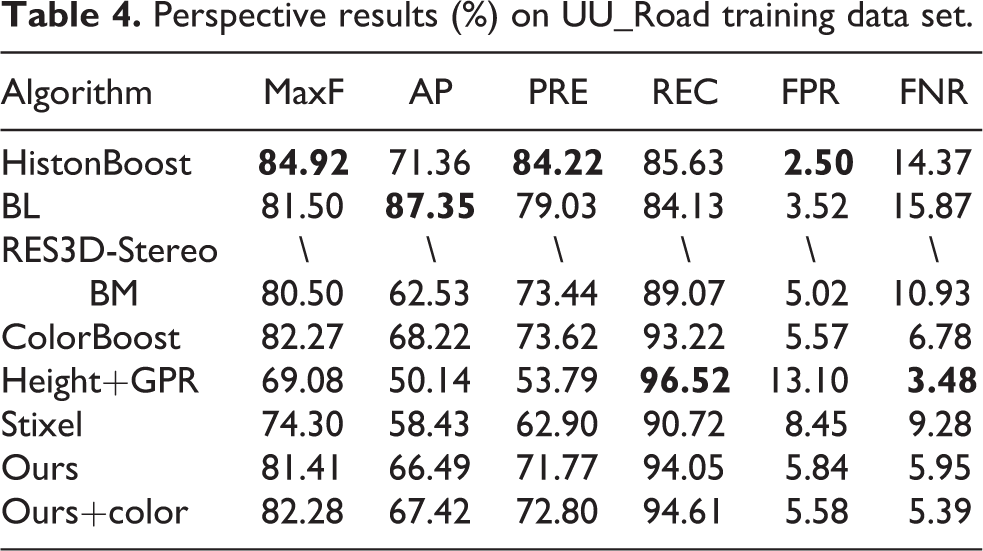
The metric results for KITTI-road training data set are provided in Tables 2 to 7. In these tables, this proposed algorithm shows a competitive results on the training data set both on perspective view and BEV.
Perspective results (%) on UM_Road training data set.

Perspective results (%) on UMM_Road training data set.

Comparisons to other methods
In order to evaluate the performance of the proposed algorithm (ours is short for Geo + GPR + CRF and ours + color for Geo + Color+ GPR + CRF), a set of comparisons on KITTI-road data set are taken including HistonBoost, 46 BL, 4 RES3D-Stereo, 17 BM, 47 and ColorBoost. 20 Tables 2 to 4 show the perspective view comparisons to other methods on training data set, while Tables 5 to 7 are for BEV comparisons. Note that the results are evaluated on the latest version of ground truth, while the results in HistonBoost, 46 RES3D-Stereo, 17 and BM 47 are from the corresponding literatures. Some of them may be evaluated on old version criteria but they will not vary dramatically.
Perspective results (%) on UU_Road training data set.
BEV results (%) on UM_Road training data set.

BEV: bird eye view.
BEV results (%) on UMM_Road training data set.

BEV: bird eye view.
BEV results (%) on UU_Road training data set.

BEV: bird eye view.
Figure 13 illustrates some typical comparison results on the training data set. The proposed method is compared to the baseline Stixel and Height+GPR, demonstrating inspiring improvement.

Comparison results on training data set. The first column shows row by row the original image and the road ground truth. The second column shows the corresponding results of our proposed method. The third column shows the Gaussian process regression results-based height feature while the last column shows the results of stixel-based method.
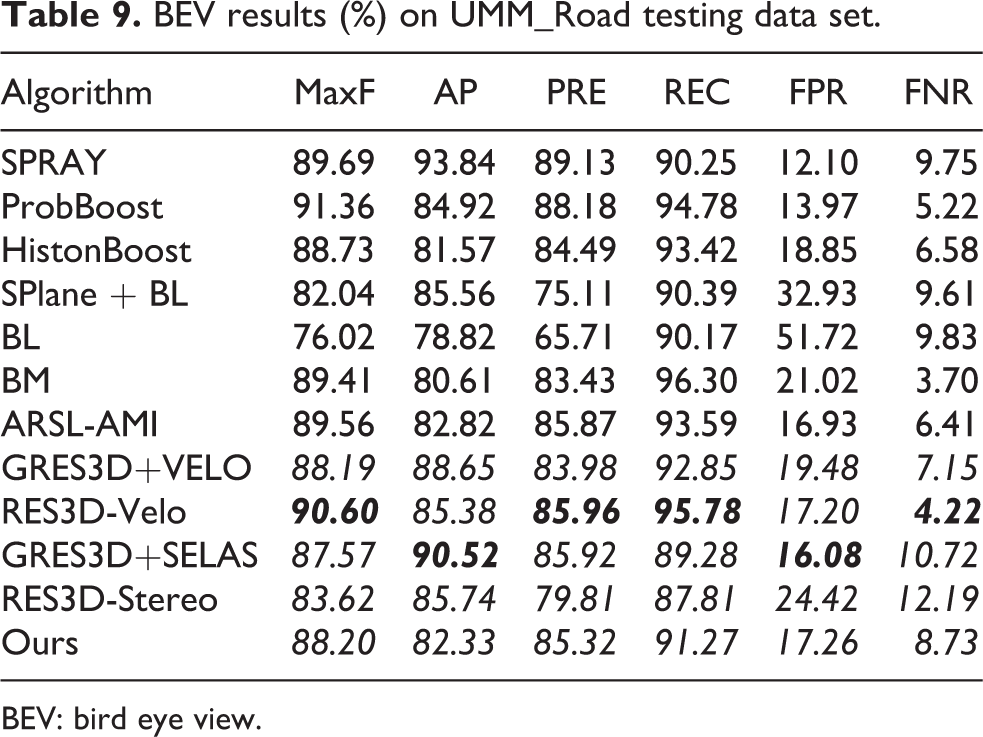
For online testing on KITTI road detection, Figure 14 illustrates some testing results for both BEV and perspective view. Tables 8 to 11 show comparisons of some relevant methods. In the ranking list online, it can be seen that the learning-based methods outperform others significantly, especially the approaches based on deep networks achieve almost perfect scores. However, these methods have potential risk in other inexperienced scenes. On the contrary, the method proposed in this article mainly relies on geometry information which makes it to be versatile to various scenes and is also compatible to learning-based methods due to the flexible fusion framework which makes it easy to be improved. In spite of the outstanding learning-based methods in the ranking list, our approach is competitive and promising. When compared to the methods based on only stereo and geometry information, ours can be regarded as the best one, being better than RES3D-Stereoand GRES3D+SELAS and even comparable to their upgraded Lidar-based versions GRES3D+VELO and RES3D-Velo. The relevant results are highlighted by bold italic in these tables which are typically regarded as geometry-based approaches. Note that Lidar point data will definitely improve the performance through precise 3-D structures.

Online testing results. The first row shows the BEV and the second row shows the corresponding perspective results. The color encodes green for truth positive, blue for false positive, and red for false negative. BEV: bird eye view.
BEV results (%) on UM_Road testing data set.
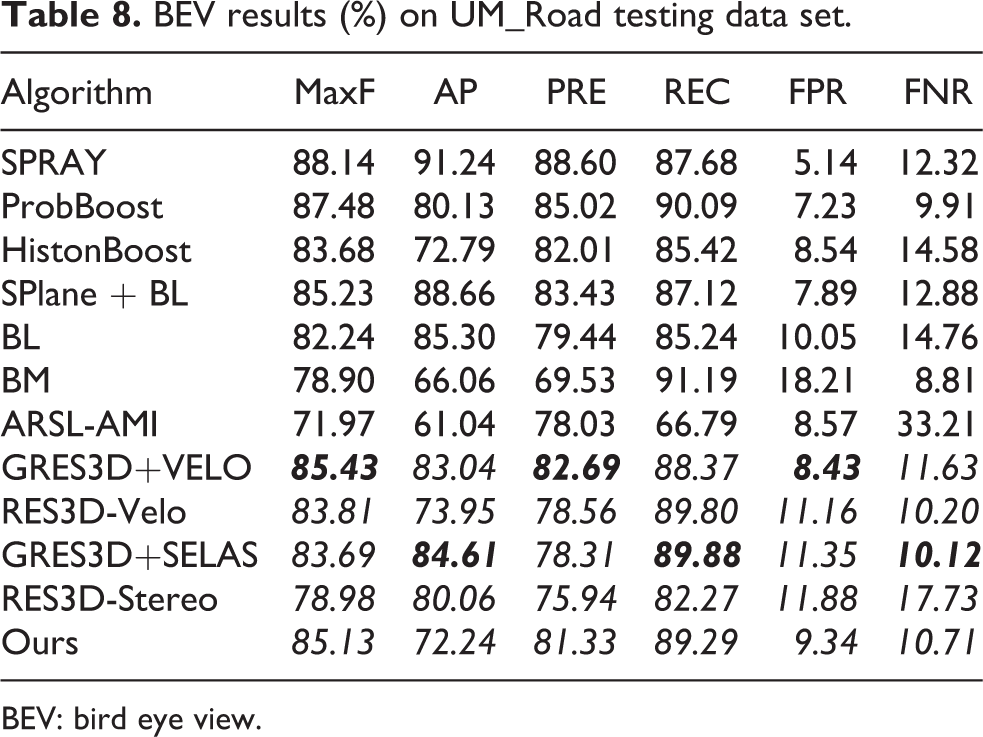
BEV: bird eye view.
BEV results (%) on UMM_Road testing data set.
BEV: bird eye view.
BEV results (%) on UU_Road testing data set.

BEV: bird eye view.
BEV results (%) on Urban_Road testing data set.

BEV: bird eye view.
Qualitative result on our own campus data set
To valid the versatility of this proposed method on other data set, our own campus data set is used for qualitative evaluation. For comparison, the color and context-based learning method ColorBoost in equation (20) is used. The metric scores in Tables 2 to 4 for KITTI-road test show its excellent performance. However, this pre-trained model on KITTI-road data set performs not appealing in our own campus data set. Although it returns good results in some scenarios which are similar to one of the pre-trained scenes as shown in the fourth row in Figure 15, it perhaps reflects at some extent that this learning-based method cannot work well on other different scenes, which is shown in the first to third rows. This also proves that the proposed geometry-based approach is robust and need not retrain on different scenes.

Some comparisons on our own campus data set. The first to forth columns are the results of ours proposed method in this article, the UM_Road color model, the UMM_Road color model, and the UU_Road color model, respectively.
Discussion on the results
Although the quantitative evaluation scores are behind the outstanding learning-based methods especially the ones with deep networks, the results of the proposed method can be considered very satisfactory and inspiring when compared to other excellent methods in the literature. And it can be regarded as a geometry-based method which is very versatile to many other scenarios. However, there are still some reasons limiting the improvement.
Criteria
Recall that our method aims at free space detection of which the criteria are little different from that of road detection. This can be illustrated in some typical situations shown in Figure 16. In image Figure 16(a), the path to the right passage is obvious traversable so that this region is classified as free space reasonably while the ground truth of road detection Figure 16(b) considers this region is non-road because seldom will a vehicle drive into this path. Similarly, although there is a small curb between the road and the parking place shown in Figure 16(c), yet it is too small to prevent the vehicle, resulting that the free space detection returns a high false positive rate which will cause decrease in the final metric scores. Another typical situation is shown in Figure 16(e). The left space of the left car is non-traversable because this car stops the way, thus it is not practical to go through it. For this reason, it is impossible to correctly classify this area as road under this criteria for free space detection methods while road detection methods will take this region into account as road which shows the ground truth in Figure 16(f).

Different criteria make the results different. The left column shows the free space detection results by our algorithm and the right column provides the corresponding ground truth in KITTI-road data set.
Actually, for autonomous vehicles, free space or road detection task aims at path planning. A successful path planning is made by a set of factors which are certainly different from the metrics here. Therefore, it perhaps does not affect the path planning results no matter what types of some area are classified. If so, the evaluation metrics from path planning may be another more reasonable criteria.
Stereo accuracy
Although the approach in equation (35) provides a state-of-the-art dense depth estimate method, the slanted plane model still modifies the scenes at the sudden changes and forces them tend to be smooth. As a result, this inevitably degenerates the accuracy. Despite of this effect, the stereo matching sometimes fails due to the variations of light condition and shadow effects. These issues will consequentially occur fatal errors, as can be seen in Figure 17(a) where the disparity map in the first row returns wrong matchings, causing a terrible failure. Additionally, due to the limit of stereo algorithm, the accuracy of distant points falls down so that the detection will return false results (see the left edge of the free space detection in the distance). This can be demonstrated in Figure 17(b).

Failure modes due to the failure of stereo matching and excess of stereo smoothing.
Features
Despite the satisfactory results obtained, the geometry features in this article are very simple. However, the flexible feature fusion framework ensures it extendable to more features which has been proved by the experiment that additional color and context information improves the performance. So more powerful features can definitely enhance the detection results.
Conclusions and future work
In this article, a robust geometry-based free space detection method is proposed which resolves some remain issues. The fusion framework is flexible to extend and Gaussian process regression automatically improves the energy distribution which both help conditional random field to achieve a better classification. This method avoids several common assumptions that is free to general scenes. In order to evaluate the approach, a set of experiments are tested on the popular KITTI-road data set for quantitative comparisons and our own campus data set for qualitative comparisons. The method returns satisfactory and inspiring performance on the free space detection compared to other outstanding approaches in multiple scenes without previous training and assumptions about road geometry. The performance is even competitive to some relevant Lidar-based methods.
As for the future work, in order to obtain a better 3-D environment modeling, methods for accurate 3-D measurement and more robust features are required as well as solutions for the light condition variation and occlusion. Also, Simultaneous Localization and Mapping (SLAM) based local mapping techniques will help to improve the understanding of the environment significantly and result in better free space detection.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work is support by National Nature Science Foundation of China under Grant No. 61375050 and Grant No. 91220301, and ARC Discovery grants: DP120103896, DP130104567, and CE140100016. The first author is funded by the Chinese Scholarship Council (CSC) to be a joint PhD student from NUDT to ANU. We would like to thank the anonymous reviewers for their valuable comments.