
Abstract
The emergence and development of deep learning theory in machine learning field provide new method for visual-based pedestrian recognition technology. To achieve better performance in this application, an improved weakly supervised hierarchical deep learning pedestrian recognition algorithm with two-dimensional deep belief networks is proposed. The improvements are made by taking into consideration the weaknesses of structure and training methods of existing classifiers. First, traditional one-dimensional deep belief network is expanded to two-dimensional that allows image matrix to be loaded directly to preserve more information of a sample space. Then, a determination regularization term with small weight is added to the traditional unsupervised training objective function. By this modification, original unsupervised training is transformed to weakly supervised training. Subsequently, that gives the extracted features discrimination ability. Multiple sets of comparative experiments show that the performance of the proposed algorithm is better than other deep learning algorithms in recognition rate and outperforms most of the existing state-of-the-art methods in non-occlusion pedestrian data set while performs fair in weakly and heavily occlusion data set.
Introduction
Vision-based pedestrian detection in traffic scene is a very critical part for many applications such as vehicle active safety, intelligent vehicles and intelligent traffic surveillance. 1 –3 Subsequently, due to the obvious theoretical research value and practical value, pedestrian detection in traffic scene has continuous interest in academic and industrial fields. However, robust pedestrian detection in traffic scene is still facing number of challenges due to different human poses, occlusion and clothing, in addition to complicated backgrounds especially in a moving objects such as vehicles. To date, many review reports about pedestrian detection are given. 4,5
Pattern recognition is proved to be the most effective framework for vision-based object detection tasks including pedestrian detection. The key point for object detection under this framework is establishing an appropriate representation of the perception object. In other words, proper features are able to retain more information related to perception object and hardly affected by unrelated changes. For pedestrian detection tasks, many of the existing works focus on how to design or choose better features.
Most of the existing state-of-the-art pedestrian detection methods use various handcrafted features such as Histogram of Oriented Gradient (HOG) feature, 6 Haar wavelet feature, 7 Gabor feature 8 and their variants or combinations. After features are designed, all the samples are represented by the chosen features and are loaded to a trainable classification framework such as support vector machine (SVM), 9 Adaboost, 10 decision tree, 11 random forest 12 or other frameworks. Finally, a supervised training is performed to maintain a pedestrian recognition classifier.
As mentioned before, in the traditional machine learning methods, all the handcrafted features are selected by researchers and lack theoretical basis and scientific support. Accordingly, the selection of features is mainly based on the researchers’ experience and by luck which is dramatically unstable. Moreover, the process of designing the features is time-consuming. Therefore, it is important to find automatic methods to design suitable features for pedestrian recognition. The proposed deep learning method is expected to solve the feature automatic design problem. 13 –17 Deep learning is a bio-inspired architecture which describes data such as image, voice and text by mimicking the human brain mechanisms of learning and analysis. Through deep learning, features are transformed from original space of lower layer to new space in higher layer. Compared with handcrafted feature, the automatic features generated by deep learning are more capable of expressing the details of internal properties of the data. Because of its robust ability in feature leaning, the interest in deep learning is increasing among academic researchers as a new important branch of machine learning.
Recently, deep model was gradually used for pedestrian detection. In the study of Norouzi et al., 18 they proposed a convolutional restricted Boltzmann machine (CRBM)-based deep model to learn a novel shift-invariant feature and apply this new feature to pedestrian detection tasks, which performs better than traditional scale-invariant feature transform (SIFT) feature. In the study of Ouyang and Wang, 19 they proposed a discriminative deep model (DDM) for pedestrian detection. Sermanet et al. 20 proposed a pedestrian detection with unsupervised deep convolutional neural network (DCNN). Zeng et al. 21 proposed a transfer learning method for pedestrian detection which combines the feature extraction ability of convolutional neural network and similar feature transfer ability of auto-encoder. Focusing on pedestrian occlusion, Ouyang et al. 22 proposed a mutual visibility relationship-based deep model (MDM).
With all the reasons mentioned above, a typical form of deep network named deep belief networks (DBNs) is chosen in this work. DBN is a common model in deep learning to achieve object classification tasks and is a new kind of neural network with a biological heuristic training infrastructure which avoids explicit feature sampling.
In this article, ‘Brief introduction of DBN’ section outlines our work. The construction and training method of the hierarchical deep model classifier will be given in ‘Construction of hierarchical deep model classifier’ and ‘Training of hierarchical deep model classifier’ sections, respectively. In ‘Experiment and analysis’ section, the experiment results and their analysis will be shown. Finally, a brief conclusion of this work is given in ‘Conclusions’ section.
Brief introduction of DBN
DBN is a multilayer network structure which can be seen as a variation of multilayer neural network. Each layer of DBN contains several neurons, and the neurons in adjacent layers are connected by weight matrix. The training process consists of two stages, which are unsupervised feature extraction stage and supervised network adjustment stage. In the unsupervised feature extraction stage, a huge number of samples without label are loaded to the network. The net weights are with unsupervised learning in order to achieve layer-wise feature extraction. In the supervised network adjustment stage, all the labels of samples are loaded to the network, and all the net weights are further trained with the target of maximum discrimination. Figure 1 shows a typical DBN which contains an input layer V1 and N hidden layers H1, H2,…, HN. Besides, x is the input sample with vector form and y is the corresponding label. In unsupervised feature extraction stage, adjacent layers such as V1 and H1 , H1 and H2,…, HN − 1 and Hn can be considered as restricted Boltzmann machine (RBM). RBM transform features from low-level loose features to high-level compact features with layer-wise reconstruction. 23 In supervised network adjustment stage, all net weights are refined with gradient-based global optimization strategy.

A typical DBN structure. DBN: deep belief network.
Due to excellent feature extraction ability, DBNs have achieved good performance in many applications such as handwritten digit recognition and voice recognition. However, for pedestrian detection, the structure and training method of traditional DBN have some weaknesses. First, all of the input data of existing DBN[Please note that the term “existed” has been changed to “existing” throughout the article. Please check and approve the edits.] are in vector form which works well for some applications such as voice detection but is not able to fully reveal spatial association of matrix such as image input. Second, all of the training methods now use unsupervised framework which focuses on digging the generative features. However, for pedestrian detection, the discriminative ability features are more vital.
In this work, an improved method is proposed based on traditional DBN. The improvements are made by taking into consideration the two main weaknesses mentioned before to achieve better pedestrian detection performance. The improvements and novelty of this work are in two fields. First, this work expends DBN from one-dimensional to two-dimensional and builds corresponding classification structure. This is to enable two-dimensional image pixel matrix as input directly. Second, on the basis of traditional unsupervised training target function, a discrimination regularization term with small weights is added. This term transforms existing fully unsupervised training to weakly supervised training, which increases the discriminative ability of extracted features compared to fully unsupervised extracted features.
Construction of hierarchical deep model classifier
In the machine vision-based visual pedestrian recognition, sub-image regions of images or video frames are the input for a trained classifier. Then, these regions are judged as pedestrians or not. In this process, classifier is the most important part which is trained with a huge number of samples.
Set

Similarly, set

where yk is the corresponding label of
To satisfy the requirement of pedestrian detection tasks, a two-dimensional DBN (2D-DBN) is designed as in Figure 2.

Pedestrian detection classifier with 2D-DBN structure. 2D-DBN: two-dimensional deep belief network.
The 2D-DBN is a layer fully connected belief network including input layer V1, several hidden layers H1,…,HN and label layer La on the top. The input layer contains P × Q neural whose size is equal to the dimension of input samples. The label layer only contains two neural, which is equal to the class number. All the hidden layers are between input layer, label layer and adjacent layers and are connected with weight matrix θ.
Training of hierarchical deep model classifier
In this section, traditional unsupervised training method will be introduced first, and then weakly supervised training algorithm will be proposed.
Traditional unsupervised training method
Unsupervised training is a traditional solution that mainly applies the greedy-wise reconstruction algorithm proposed by Hilton et al. 24 in which the weight of any two adjacent layers can be adjusted independently.
Take input layer V1 and hidden layer H1 as an example. The input layer V1 and hidden layer H1 can be considered as RBM. The energy state (v1, h1) of any two neural between these two layers can be written as
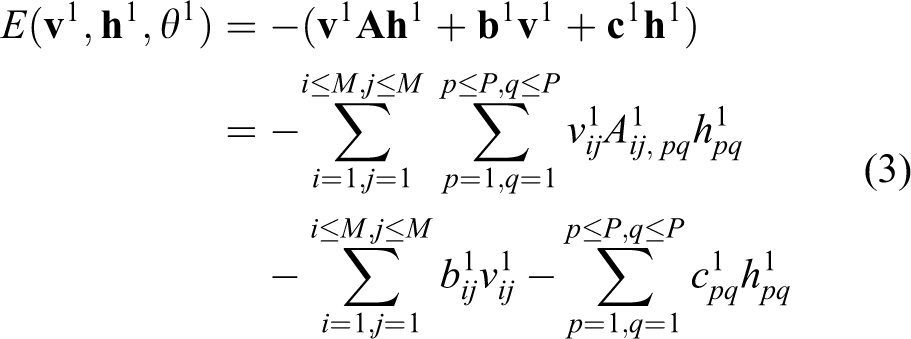
where
Based on the described structure, two adjacent layers of RBM can be viewed as a joint probability distribution

where Z is the normalized parameters.
The conditional probability distribution of input status

Here,
The unsupervised training object function of this RBM is

Here,
To optimize this object function, the contrastive divergence (CD) algorithm is applied to incrementally update the connection weights and offset in parameter θ. 25
Improved weakly supervised method
The features extracted with the traditional unsupervised training are generative features which are more close to overall expression of the samples. While in the two-class classification tasks, the discriminative features are more likely to be got.
Based on the analysis above, the modifications in this work are on the object function by adding sample discriminative regularization ability term. By inducing label information with a short weight, the new object function can be written as
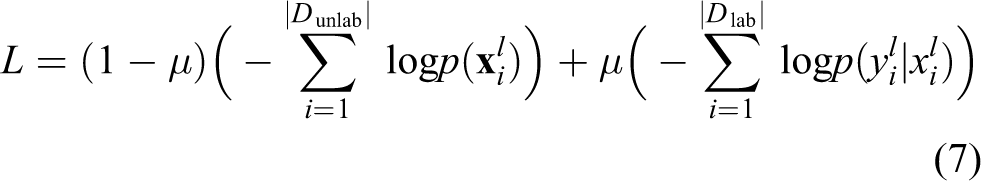
Compared to function (6), it can be seen the discriminative ability regularization term
Supervised deep network parameters locally optimization
Based on the basis of weakly supervised learning described in the ‘Improved weakly supervised method’ section, all the parameters of 2D-DBN are preliminary maintained, which means the features are extracted. Then, the whole network can be viewed as a general multilayer neural network, and the net weights

where
The weakly supervised hierarchical deep pedestrian classifier is achieved by processing the aforementioned method.
The overview of the algorithm is demonstrated with a pseudocode listed below as Algorithm 1.
Overview of our pedestrian detection approach.

Experiment and analysis
Experiment preparation
The training data set is National Institute for Research in Computer Science and Control (INRIA) pedestrian data set. 26 For better training effect, some preprocessing processes are made. INRIA data set contains 2416 positive samples and 1218 negative samples. The data set is expended as follows: Five variants are added to each original sample which has five random deforms such as positive and negative translation, positive and negative transformation and small-scale zooming. The purpose of this preprocessing is to maintain invariance. With this preprocessing, the whole number of training samples increases to 16,698.
The test data set contains two other independent pedestrian data sets which are Daimler data set 27 and Computer Vision Center of Universitat Autònoma de Barcelona, Spain (CVC) data set. 28
Daimler pedestrian data set is captured by on-board cameras which contain 4800 pedestrians’ images and 5000 non-pedestrians’ images. In this data set, the pedestrian contains large proportion of the image, which means it maintains less interference information.
The CVC pedestrian data set contains two sub-data sets (CVC-01 and CVC-02), which is more focusing on pedestrian detection in advanced driver assistant system. CVC-01 contains 1000 pedestrian image samples and 6175 non-pedestrian image samples. These samples are mainly selected from road images. Similarly, CVC-02 contains 1016 positive samples and 7650 negative samples.
Some typical images of those three data sets are shown in Figure 3.

Some of the positive samples of three data sets: (a) INRIA, (b) Daimler and (c) CVC.
Experiment results and analysis
The proposed algorithm is developed by using joint programming platforms, namely, Visual C++ and Matlab 2010b. The specification of hardware used for this algorithm is workstation with 3.6 GHz CPU, 4G RAM and operating system MS Window 8.
To test the proposed algorithm, three groups of experiments are designed.
In the first experiment, with the same structure of deep network, traditional unsupervised deep model pedestrian detection classifier is compared to the weakly supervised classifier. More specifically, the structure of the two classifiers is kept the same including one visible input layer, one visible output layer and five hidden layers. The neural number of input layer is 16 × 32. The neural number of five hidden layers is 64 × 128, 32 × 64, 32 × 64, 16 × 32 and 16 × 32, respectively. The neural number of output layer is 2 × 1. Meanwhile, the supervise weight parameter μ in equation (6) is picked from 0.1 to 0.9 with 0.1 interval increments.
The experiment is conducted on Daimler and CVC data sets separately. The result of this experiment is shown in Tables 1 and 2. The detection rate and false detection rate of the two test data sets are also given in the tables.
Different deep learning classifiers effect in Daimler data set.

2D-DBN: two-dimensional deep belief network (when u = 2, the corresponding classifier has the best classification effect).
Different deep learning classifiers effect in CVC data set.

2D-DBN: two-dimensional deep belief network (when u = 2, the corresponding classifier has the best classification effect).
It can be seen from Tables 1 and 2 that the weakly supervised classifier with small weight parameter performances is better than pure unsupervised classifier. So, it can be considered that inducing the discriminative ability regularization term improves the discriminative ability of extracted feature compared to the original unsupervised object function. Moreover, it is found that when μ = 0.2, the corresponding classifier is the best classification effect. Meanwhile, when μ > 0.3, the classification ability of weakly supervised classifier drops significantly because the training transferred from weakly supervised to strong supervised gradually.
The second experiment is designed to explore the relationship between net layer number and classification ability. Eight types of weakly supervised deep structure with different numbers of hidden layers are tested. The hidden layer numbers of eight types of weakly supervised deep classifier are two to nine separately and are shown in Table 3. Meanwhile, the supervised weights μ are all set to 0.2 for every classifier.
Neural number of each layer for different classifiers.

The experiment results are shown in Figure 4, which demonstrates the detection rate and false detection rate of each classifier in two data sets. It is easy to find that the pedestrian classification effect was upgraded by increasing the hidden layer number till seven, and then by increasing the number, the classification effect was dropped slightly in both data sets.
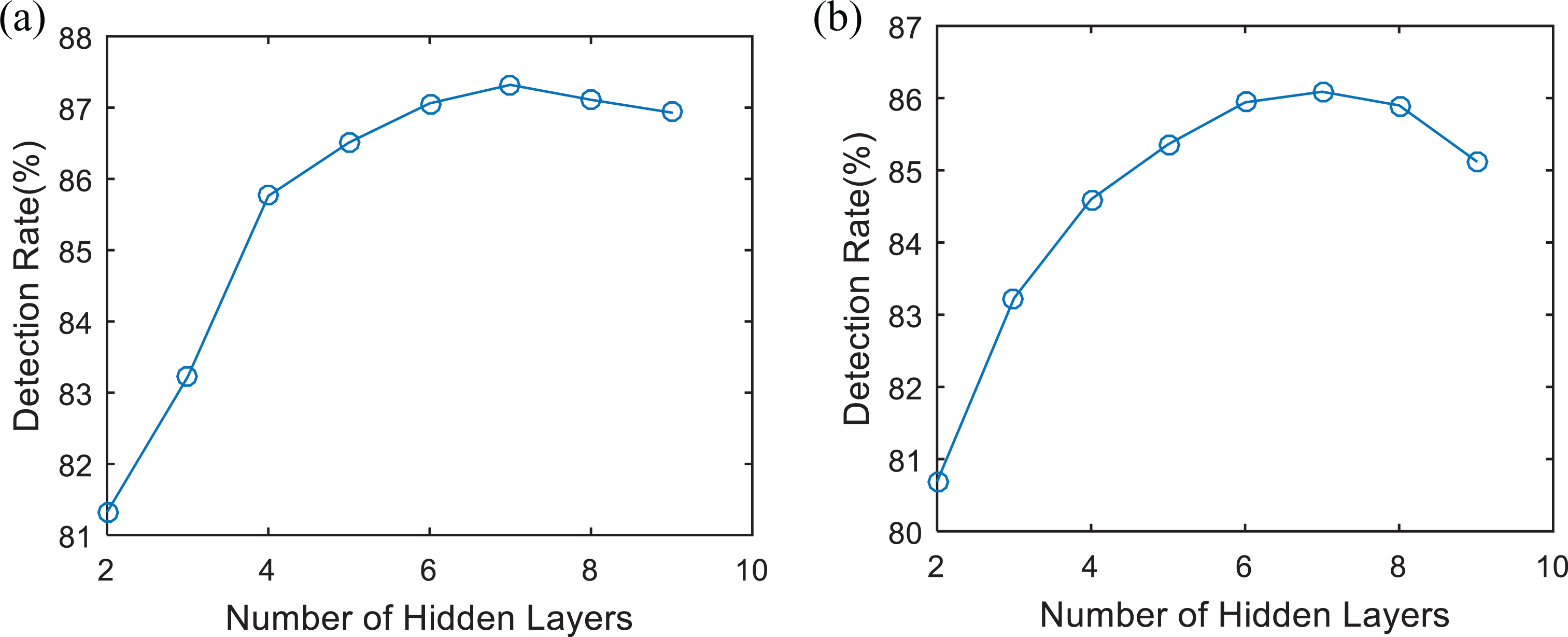
Classification effect in different classifiers with different hidden layer numbers: (a) performance in Daimler data set and (b) performance in CVC data set.
In the third experiment, the proposed weakly supervised hierarchical deep model-based pedestrian detection method is compared with several state-of-the-art pedestrian detection methods, such as Deformable Parts Model-based method (DPM), SVM-based method with SIFT feature (SVM), CRBM-based deep model, 18 DDM, 19 transfer deep model (TDM) 21 and MDM. 22 Beside, the experimental data set is divided manually into three kinds of situations that are non-occlusion, partially occlusion and heavy occlusion. The experiment results of these methods in different scenarios are shown with receiver operating characteristic (ROC) curves whose vertical coordinate is recall rate and the horizontal coordinate is false positives per image.
It can be seen from the comparison of results in Figure 5 that our method almost has a best performance which is equal to that of TDM in non-occlusion situation and is better than other five methods. However, in weakly and heavy occlusion situations, the proposed method is ranked just the second best performance which is just worse than MDM. Besides, the processing time for each cropped image provided by those data sets is 0.027 ms.

Detection performance in different situations for different methods: (a) non-occlusion situation, (b) partially occlusion situation and (c) heavy occlusion situation.
Finally, the trained weakly supervised hierarchical deep classifier is applied to captured road images with sliding window searching method. Some of the pedestrian detection results are shown in Figure 6, in which the blue box identified the correctly detected pedestrian and the red box identified false detected objects. The resolution of the images is 480 × 384, and the average processing time is 126 ms per frame.

The pedestrian detection results in real road images.
Conclusions
In this work, 2D-DBN structure is established and a weakly supervised deep learning algorithm is proposed for pedestrian detection application. The proposed work is designed to overcome the weaknesses of structure and training of existing DBN methods.
First, this work expends DBN from one-dimensional to two-dimensional and builds the corresponding classification structure which can able to take two-dimensional image pixel matrix as input directly. Second, on the basis of traditional unsupervised training target function, a discrimination regularization term with small weights is added. This term transforms existing fully unsupervised training to weakly supervised training which increases the discriminative ability of extracted features compared to fully unsupervised extracted features. The experiments also demonstrated that the proposed algorithm performance is better compared to the existing unsupervised method. Meanwhile, this work also experimentally investigated the relationship between the depth of hidden layers and the classification results. Finally, the proposed method is compared with several state-of-the-art pedestrian detection methods. The comparison results demonstrate that the proposed method outperforms most of the existing methods in non-occlusion pedestrian data set and performs fair in weakly and heavily occlusion data set.
The future research scope to improve our work is with two aspects. First, inspired by the work of Ouyang et al., 22 semantic information would like to be introduced to lower layers to improve the classifier performance in occlusion situation. Second, the weakly supervised framework will be used in other deep learning structures such as DCNN and region convolutional neural network.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by The National Natural Science Foundation of China (61403172, 61601203, U1564201), China Postdoctoral Science Foundation (2014M561592, 2015T80511), Key Research and Development Program of Jiangsu Province (BE2016149), Natural Science Foundation of Jiangsu Province (BK20140555), Six Talent Peaks Project of Jiangsu Province (2015-JXQC-012 , 2014-DZXX-040).