
Abstract
In this article, according to the real-time and accuracy requirements of advanced vehicle-assisted driving in pedestrian detection, an improved LeNet-5 convolutional neural network is proposed. Firstly, the structure of LeNet-5 network model is analyzed, and the structure and parameters of the network are improved and optimized on the basis of this network to get a new LeNet network model, and then it is used to detect pedestrians. Finally, the miss rate of the improved LeNet convolutional neural network is found to be 25% by contrast and analysis. The experiment proves that this method is better than SA-Fast R-CNN and classical LeNet-5 CNN algorithm.
Introduction
In the field of computer vision, pedestrian detection technology can accurately position pedestrians, and so is widely used in advanced intelligent vehicle auxiliary driving, intelligent robot, human behavior analysis, intelligent video surveillance, and other fields. According to statistics, more than 430,000 people are injured in traffic accidents worldwide each year, and more than 39,000 people are killed in traffic accidents. 1 With the increasing development of urbanization, the environmental conditions of urban and rural traffic roads have become complicated, and the life and safety of people have become difficult to be guaranteed. Therefore, a number of car dealers, research institutions, and universities have begun to conduct in-depth detection and research on pedestrians. For example, the research institutions of foreign pedestrian detection systems include Daimler Chrysler R&D Center, Carnegie Mellon University (CMU), German Volkswagen, Japan Toyota Motor Research Center, 2 Domestic Jilin University, Tsinghua University, Shanghai Jiaotong University, Automation Institute of Chinese Academy of Sciences, Xi'an Jiaotong University, Zhejiang University, University of Science and Technology of China, 3 etc.
Since 2002, some researchers have started to study pedestrian simple features and classification algorithms. Dalai and Triggs proposed the histogram of oriented gradients (HOG) algorithm in 2005, 4 where the features of the algorithm can improve pedestrian detection to a certain extent. Subsequently, pedestrian detection technology appeared to be practical, and the size of datasets began to expand. In 2008, Pedro Felzenszalb and others considered the variability of pedestrians and expanded the features of the HOG algorithm to further improve the pedestrian detection performance. 5 In 2013, the Chinese University of Hong Kong 6 used the convolutional neural network (CNN) model to combine the occluded pedestrian model with the deformation model, used the CNN network model structure to extract pedestrian features, and detected pedestrians, thus achieving good results in dealing with pedestrians’ occlusion problems. Beginning in 2015, some researchers began to study different network structure experiments to analyze the impact of the number and size of different convolution kernels on the pedestrian detection performance. Through several experiments, the detection performance as well as the real-time performance and accuracy have improved.
Pedestrian detection algorithm can be divided into two categories: one based on the background modeling method, which extracts the target of foreground motion and performs feature extraction in the target area. Then the classifier is used to classify whether pedestrians are included or not. But the main problems of the background modeling are as follows: it is difficult to detect the dense material, illumination changes result in changes of the image color, background difference detection algorithm could be covered with the object of the area error detection for sports. The other is based on the statistical learning method, which is also the most commonly used method for pedestrian detection. Pedestrian detection classifier is constructed according to a large number of samples. The extracted features mainly include the target’s gray scale, edge, texture, color, gradient histogram, and others. Classifiers mainly include neural networks, support vector machine (SVM), adaboost, and deep learning. However, there are some difficulties in statistical learning. 7 For example, pedestrians are different in size, posture, and clothing coupled with complex background. The performance of classifier is greatly influenced by training samples, and negative samples during off-line training cannot cover all real application scenarios.
The current pedestrian detection is based on the pedestrian detection algorithm of HOG+SVM proposed by Dalal, a French researcher. 8 The classic LeNet-5 network can also detect pedestrians and is superior to HOG+SVM in algorithm, but it takes a long time. In order to solve this problem, this paper combined the LeNet-5 CNN to automatically study the texture and gradient feature of pedestrian targets and introduced a new algorithm, namely nine-layer LeNet CNN to detect pedestrians. Based on the strong learning ability and robustness of the new LeNet CNN, a pedestrian detection sample database and a CNN training detection model were established, and a large number of pedestrian detection samples were trained to obtain deep sample features. A pedestrian detection system with high detection speed, high accuracy, and strong scene adaptability can be obtained. By using this pedestrian detection system, vehicles can autonomously detect the surrounding environment in real time. It also aids in the accurate analysis of test results to provide the driver with more accurate opinions and also helps the driver to respond to the hidden dangers in the surrounding environment immediately, so as to protect pedestrians.
Convolutional neural network pedestrian detection framework
The method of HOG feature and SVM classification can detect pedestrians with complex background, and has good robustness to light changes and high detection rate. However, the process of HOG feature extraction is time-consuming, so the real time is relatively weak. Although the classical LeNet-5 CNN has a higher detection rate than the HOG+SVM method, a large amount of time is wasted on training samples, and the real-time performance is also found to be weak. Therefore, a new pedestrian detection method is proposed based on LeNet-5 CNN structure, which can effectively detect pedestrians and improve real-time and accuracy.
The whole detection process consists of the following parts: first, the Caltech pedestrian detection training and test sample database is established; then, video frames were pre-processed, network parameters were adjusted, and the model was trained. Finally, pedestrian information is detected. The entire detection process is shown in Figure 1.

Convolutional neural network framework.
Improved LeNet-5 CNN pedestrian detection algorithm
In this paper, the classical LeNet-5 CNN
9
is improved by adding layers, which ensures high detection rate while maintaining the speed. Improvement is made from the following three aspects: first, normalized layer BN is added after each convolution layer. Then, the dynamic adaptive pooling model is adopted. The improved Relu activation function is used to alleviate the gradient vanishing problem effectively. The final classification layer is classified using SVMs. Through the optimization of these three methods, the training speed is greatly improved and the detection rate is also improved.
Addition of normalized layer BN
10
When the image input convolution layer is trained, the gradient descent method is mainly used for training. The entire program must be manually set before the operation of the network parameters, learning rate, etc. This operation is cumbersome and the detection rate is subject to human factors, and the same cannot guarantee real-time requirements. To solve this problem, the normalization (BN) layer can increase the learning rate and accelerate the convergence rate.
The input data are normalized and then sent to the next layer, which will not adapt to the new data distribution. However, the normalization layer is a learnable and parameterized network layer, so the best way to preprocess data is by whitening. The amount of calculation is particularly large with Whitening pre-treatment. The formula used for pretreatment to facilitate calculations, approximate whitening is
11

By directly using equation (1) to normalize the data will reduce the level of expression. If the data are distributed in the 0 to 1 interval, the sigmoid function will greatly reduce the ability to express the model. Therefore, two learnable parameters

Each neuron will have a pair of such parameters


It can completely restore the original data of a layer. The entire BN algorithm is as follows




The input data are
After training the network, the data need to be tested, and BN is tested using the following
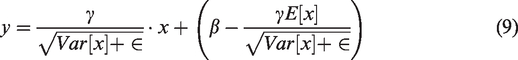
Because this is the test process, the average here is not the average of each batch, but the average of the entire dataset. During the training process, the mean and variance of each batch should be recorded so as to record the mean and variance of the entire dataset after the training
2. Improvement of the sampling layer


The purpose of sampling is to perform quadratic feature extraction, among which pooling is the most important process. The high-level feature map obtained after pooling can not only reduce the dimension and resolution of the original feature map, but also avoid overfitting and other issues. Pooled methods include mean-pooling and max-pooling. 12 These two pooling models cause some damage to the representation of global features and the accuracy of the model, and so they cannot extract the features of the pooling region very well.
Owing to the above problems, this paper improves the pooling model based on the maximum pooling algorithm. The improved model is called the dynamic adaptive pooling model. The model can dynamically adjust its pooling process according to different feature maps, and adaptively adjust the pooling weight according to the content of each pooling region. If the pooling region has only one value, then this value is both the maximum and a representation of its features. If the eigenvalues of the pooling region are all the same, the maximum value can also be expressed as the eigenvalues of the pooling region. Therefore, on the basis of the maximum pooling algorithm, a mathematical model is constructed to simulate the function according to the interpolation principle. If

The pooling factor

In equation (13),
Dynamic adaptive pooling is improved and optimized on the basis of maximum pooling. The input part of the maximum pooling model is a two-dimensional matrix such as the input feature map in Figure 2(a). Convolution kernel is also the same as Figure 2(a), and uses four different convolution kernels. The matrix of weights
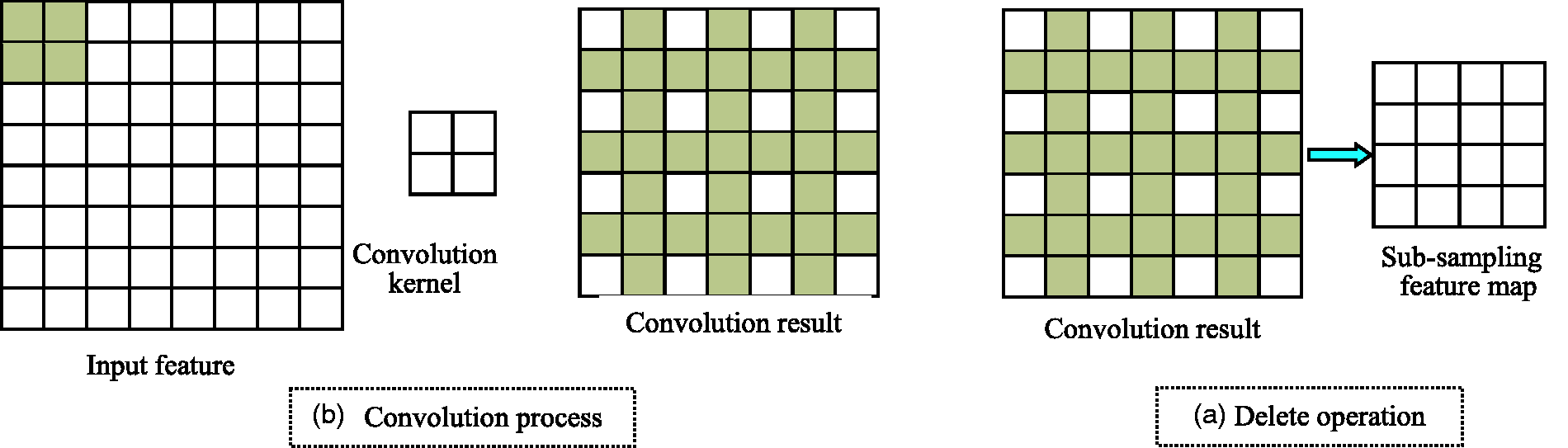
The process of realizing pooling.
When the dynamic adaptive pooling finds a three-dimensional matrix on the maximum pooling algorithm, it is further summed to obtain a three-dimensional matrix 3. Improvement of the ReLU activation function algorithm
The most commonly used activation functions are sigmoid functions and ReLU functions 13 in CNNs. But the gradient vanishing problem during the post-transfer process of sigmoid function greatly reduced the training speed. While the ReLU activation function can effectively alleviate the gradient vanishing problem, it trains the deep neural network in the way of supervision, without relying on the unsupervised layer-by-layer pre-training, which significantly improves the performance of the deep neural network. But ReLU also has fatal flaws. First, the output of the ReLU function is prone to produce mean shift, 14 and the neurons that cause the latter layer get a nonzero mean signal from the output of the previous layer, making the network parameter calculation difficult. Secondly, as the training progresses, part of the input will fall into the hard saturation region of the ReLU function, resulting in the inability to update the corresponding weight as shown in Figure 3. Mean shift and neuron death jointly affect the convergence and convergence speed of deep neural networks. Therefore, we improve it on this basis. The improved ReLU function can not only effectively alleviate the problem of gradient disappearance, but also effectively avoid the phenomenon of mean shift.

ReLU activation function.
The part of ReLU function

The image is shown in Figure 4, where the image of
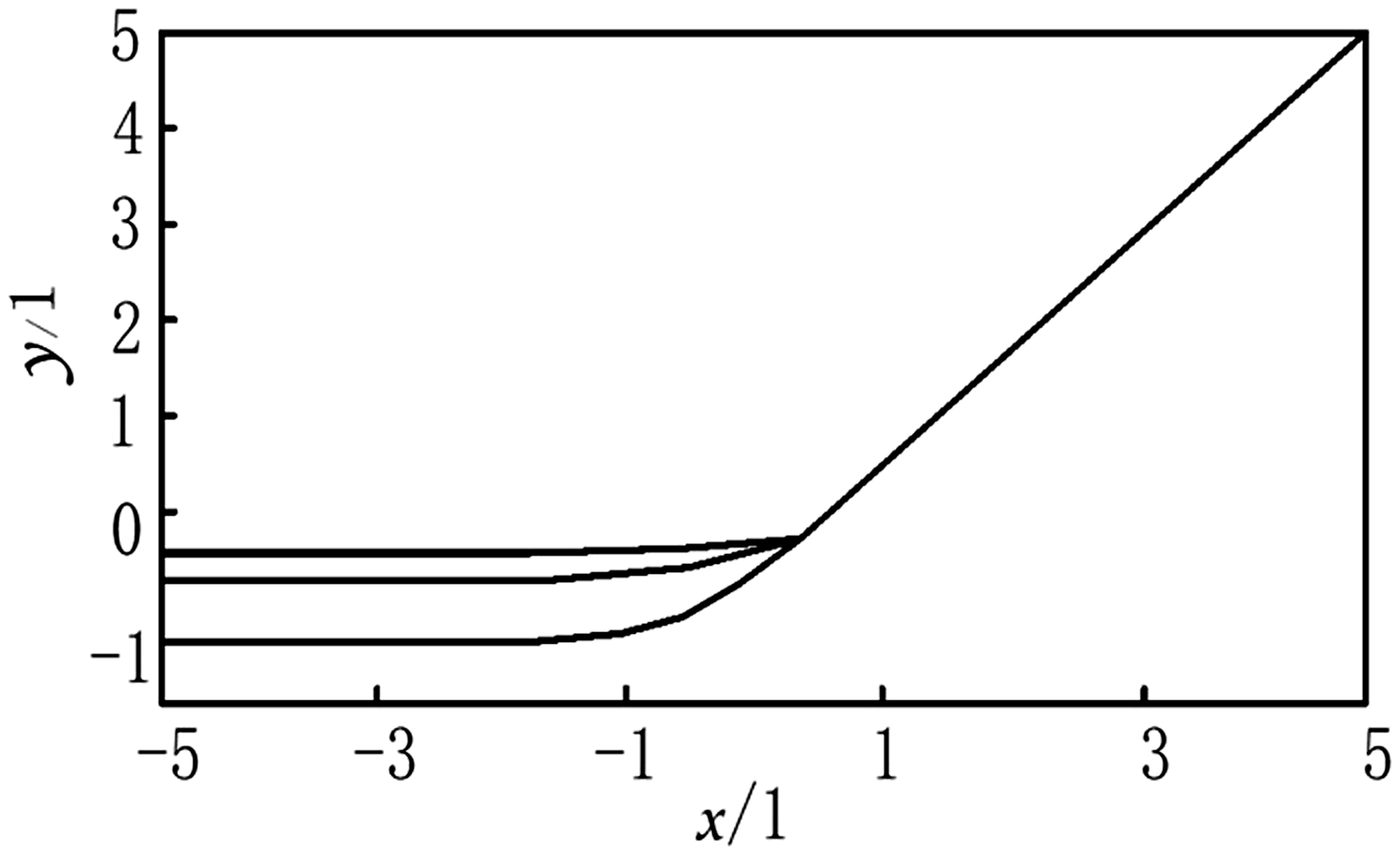
Improved ReLU activation function.
On comparing the improved ReLU function with the original ReLU function, the nonlinear part ( 4. Replacement of Softmax classifier by SVM classifier
The final output layer was identified by the SVM classifier. 15 The function of the SVM is to minimize the risk of classification under the principle of spatial global separation of samples. According to the continuous updating of forward and backward propagation parameters of network training, Softmax classifier uses probability estimation to judge pedestrians. SVM can shorten the detection time, and does not need network iteration. The accuracy of classification is obviously higher than that of the Softmax classifier. The accuracy of classification is obviously higher than that of the Softmax classifier. 16
5. The classical LeNet-5 CNN model structure was improved, and after deepening to nine layers, improved LeNet-5 CNN parameters were in Table 1, the structural changes were as follows (Figure 5):
1. C1 convolution layer. There are six feature maps in the convolution layer. The normalized BN algorithm is used for the feature maps respectively, and the size of the convolution kernel is normalized, and then the convolution operation is performed through the filter. 2. S1 pooling layer. The maximum pooled algorithm is adopted. The convolution kernel is 2*2, the sliding step of each pooled process is 2, and the image size after pooled is 14*14. 3. C2 convolution layer. The feature graph of this layer is combined with the BN layer, and the normalized BN algorithm is adopted to normalize the size of the convolution kernel, and then the convolution operation is carried out through the filter. 4. S2 pooling layer. The maximum pooled algorithm is adopted. The convolution kernel is 2*2, the sliding step of each pooled process is 2, and the image size after pooled is 5*5.

Improved LeNet-5 CNN model structure.
Multistrategy fusion window selection
As shown in Figure 6, we combine selective search for multiscale selection windows (SEL) with binary normalized gradients (BING) to obtain preferred regions of high quality.

Multistrategy fusion window selection.
In the preparation phase, we first use the INRIA dataset to train the BING model: we use the training set of the INRIA pedestrian database, and the training model uses a linear support vector machine. The positive example is the ground truth corresponding to the normalized gradient feature. The negative example is the randomly selected background window normalized gradient feature.
Using selective search algorithm to extract candidate regions. In order to obtain candidate region with higher quality and recall, we use the selective search quality model instead of the previous fast model. The candidate regions of selective search proposal are filtered by using the aspect ratio and resolution features of pedestrians. Using this prior knowledge we can filter out a lot of useless windows. It not only improves the speed of subsequent algorithm, but also reduces a large part of the misjudgment window. The candidate area is filtered using the trained BING model. Previous methods do not consider the edge features of the object, so we use BING to further filter the candidate region. It should be noted that the edge detection operator combined with some prior knowledge cannot distinguish objects and background very well, and the algorithm is time-consuming. But the BING method is simple, time-saving, and effective, which is why we choose BING for filtering.
After these three selection filters, we obtained a candidate region with a small number and higher quality.
Comparison of experimental results and analysis
Development platform
The image acquisition device is the Point Grey gray point camera with 13 million pixels, frame rate of 85 fps, Ethernet communication CMOS camera, 1280 × 1024 pixel. In order to reduce the amount of calculation on the appropriate processing of the image, the image pixel to be identified was 640 × 480. Using the TCP/IP protocol as the communication protocol between the server and the host PC client, the video transmission part is mainly connected by the server thread Server_thread to the host PC client through the Socket communication based on the TCP protocol. The image and video processing platform is an ASUS desktop with an Intel Core i7 processor, a 2.5 GHz frequency, a GTX1080 graphics card, a 120 GB solid state drive, and a memory size of 4G. The experimental platform is shown in Figures 7 and 8.
Pedestrian detection based on CNN runs under Windows 10 system environment. The pedestrian image is detected by using Python3.5, VS2015 programming software combined with MATLAB2014a, TensorFlow, and Caffe.
Analyses of experimental results
In the process of improving LeNet-5 network training, we can intuitively and clearly observe the dynamic process of improving LeNet-5 training by drawing accuracy and loss curves. Figure 5 shows the corresponding accuracy and loss curves of the improved LeNet-5 network during training. As can be seen from the figure, when the epoch with the number of network iterations is 1500–2000, the network reaches stability.

Smart car.

Identification platform.
In order to test the applicability of the improved LeNet-5 CNN algorithm proposed in this paper, the VJ, HOG+SVM, HOGLBP, Multifu+Motion, LeNet-5 CNN, and the improved LeNet-5 CNN detection algorithm were compared. The number of network iterations is 1500–2000 epochs. Training data and testing data were obtained from Caltech datasets at the California Institute of Technology. 17 There are 11 data packages in this dataset, of which set00–set05 are the training set, and set06–set9 are the test sets. There are a total of 64,468 data samples, including 4396 positive samples and 60,072 negative samples. As shown in Figure 9, when the network iterated with 1500–2000 epochs, the network reached stability.
As shown in Figure 10, when the false positive rate FPPI is 10%, improved LeNet CNN achieves 25% missed detection rate, while LeNet CNN achieves 33% missed detection rate, which was much lower than the traditional statistical learning methods such as VJ, HOG+SVM, MultiFtr+Motion, etc. It also shows that improved LeNet CNN performance is better than leNet-CNN. So when training on Caltech dataset, improved LeNet CNN has good applicability. As can be seen from Figure 10, SA-fastRCNN, the best method for pedestrian detection can achieve a miss rate of 13%. It is also a pedestrian detection method based on CNN. Considering the influence of pedestrian size, different detection models are adopted according to different pedestrian heights. Although the proposed convolutional neural network method in this paper has a gap of nearly 12% in comparison, the improved LeNet CNN proposed in this paper has scale invariance and has near real-time processing speed, and the miss detection rate can basically meet the actual needs.

Accuracy and loss of curves training.

Overall results on the Caltech dataset.
On the same experimental equipment platform, the performance of the algorithm is analyzed by running time. The above three detection algorithms are trained with set05 dataset. Table 2 shows the training time comparison of the three algorithm network models. After the three classifiers have been trained, the set9 dataset was detected and the mean of all detection time was taken. Table 3 shows the comparison of the average detection running time for the three algorithm network models.
Improved LeNet-5 CNN parameters.

Comparison of training time between three algorithm network models.

Comparison of detection time between three algorithm network models.

According to Table 2, the training time of ours, SA-FastR-CNN, and LeNet CNN algorithms are respectively 0.701, 0.892, and 1.096 h. According to Table 3, it takes about 0.598 s to detect each image by using the LeNet CNN algorithm, which is the longest time among the three algorithms. It takes about 0.359 s to detect images per frame by using SA-FastR-CNN, more than 0.155 s of the proposed algorithm. This is because BN normalization algorithm, dynamic adaptive pooling model, and improved Relu activation function are adopted in the improved LeNet-5 CNN layer, which speeds up the operation of the network.
This paper also shows the actual result of the classical LeNet-5 CNN and the improved LeNet-5 CNN model algorithm. When verifying the real time and accuracy of the LeNet-5 CNN model and the improved LeNet-5 CNN model, pedestrians are effectively detected in the video. The results of the detection are shown in Figures 11 and 12.

LeNet-5 CNN structure pedestrian detection.

Improved LeNet-5 CNN structure pedestrian detection.
As can be seen from Figure 11, when the pedestrian scale is relatively small, the LeNet CNN algorithm can hardly detect pedestrians, and there are many cases of missed and mistaken detection. Especially when two pedestrians overlap and there is large human traffic, only one can be detected. The improved LeNet CNN algorithm in Figure 12 improves the detection efficiency of occluded pedestrians, smaller scale pedestrians, and so on, but occasionally misjudgments occur. In general, the improved LeNet-5 CNN algorithm has better detection rate than the classical LeNet-5 CNN algorithm in real time and complex background.
Conclusion
This paper improves the classical LeNet-5 CNN from the following three aspects. first, a normalized layer BN is added after each convolution layer, then a dynamic adaptive pooling model is adopted, and the improved activation function of Relu can effectively alleviate the problem of gradient disappearing. In this paper, the Caltech pedestrian database was detected and analyzed by nine-layer LeNet CNN model. Experiments show that the improved LeNet CNN detection time saves 0.155 s compared with SA-FastR-CNN, and saves 0.394 s compared with the mainstream LeNet CNN detection time. In the case of occlusion, weak illumination, and complex environment, the missing detection rate of the proposed model can reach 25%, and it has high real time and accuracy. But the improved LeNet-5 network will also have misjudgment, so the future studies will focus on this aspect.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Shaanxi Province of China (2016GY-007) and the key research and development program of Shaanxi Province (2016KTZDGY4-05–1). It was also supported by the Xi'an University of Science and Technology.