
Abstract
A novel image zooming algorithm based on sparse representation of Weber’s law descriptor is proposed in this article. It is known that features of low resolution can be extracted using four one-dimensional filters convoluting with low resolution patches. Weber’s law descriptor can well deal with local feature, so we extract low-resolution image feature replacing one-dimensional with Weber’s law descriptor in the four filters. In addition, fractional calculus can deal with nonlocal information such as texture. For avoiding small complex component when the size of image is not an odd integer, we modify the extending image method used by Bai, so it can save lots of calculation. The proposed approach combining the Weber’s law descriptor with fractional calculus achieves a very good performance. Experimental results show that our method can well eliminate jagged effect when up-sampling an image and is robustness to noise.
Introduction
The establishment of a modern intelligent transportation system can effectively help to solve the problems of traffic congestion, blocking, and violations, and the license plate recognition system has played an important role in intelligent transportation system. However, when the image acquisition just get a low-resolution (LR) image and it is unsuitable for intelligent recognition, we need to expand the size of the image for further work.
Image zooming aims to restore an image from a degraded image. Applications of super-resolution (SR) image are very important in many fields with the development of modern information technology. The image reconstruction methods can be categorized into four categories: 1 frequency-domain based methods, 2,3 example-based methods, 4 –7 regularization functional-based methods 1,8 , and partial differential equation (PDE)-based directional diffusion methods. 9,10 In this article, we focus on the example-based methods for image reconstruction.
Freeman et al. 11 described a learning-based method that uses generic images in which SR is predicted from LR. The predicting model is learned by adopting a Markov network solved with a belief propagation algorithm. Yang et al. 5 proposed an image SR method via sparse representation in which the coefficients between sparse representation for each patch of the LR image are used to get a high-resolution image. The compatibilities among adjacent patches are enforced both globally and locally, while there is a problem that how to determine the optimal dictionary size for natural image patches. Soon, Yang et al. 4 introduced a novel coupled dictionary training method based on patch-wise sparse reconstruction, where the learned coupled dictionaries relate to the LR and high-resolution image patch spaces via sparse representation. A fast regression model based on in-place examples was proposed for practical single image SR. 12 Yin et al. 13 proposed a novel method for image SR and fusion, and the method is as follows: For given LR images, up-sampling and decomposing them into low and high frequency components; and then computing and fusing sparse coefficients from the low and high frequency components; reconstructing a high-resolution fused image using the fused sparse coefficients. All aforementioned methods share the same common traits: the LR image is divided into blocks, and the first-order and the second-order gradient is used as the image features. The key problem is how to choose the dictionary and its size. 14 These methods ignored image nonlocal information, but nonlocal information can help to improve the SR reconstruction performance and fractional calculus can well deal with nonlocal information such as texture. 1,9,15
Pu 16 introduced first fractional calculus to image processing and proposed digital images fractional differential mask templates and inhibition principle according to the capabilities of the fractional differential approach for enhancing textural features. Because of the capability of better handling nonlocal features, such as textures, Zhang et al. 9,15 proposed a fractional diffusion-wave equation for image denoising, and experiments show that the proposed method is effective. Ren et al. 1 proposed a novel method that combined the local with global features for image zooming, and the experiment results do not suffer from staircase edges block artifacts.
In this article, a novel SR reconstruction method is proposed. The proposed method combines the local operator with the nonlocal operator. The local operator can better handle the textures, and the nonlocal operator has a favorable performance on textures and noise compared to state-of-the-art methods. First, we adopt modified Weber’s law descriptor (WLD) 17 to describe the image feature instead of the image gradient. The WLD can make use of image local information, which can be used in the sparse representation method for SR. Second, we modify the image denoising method 18 based on fractional calculus to get a new denoising algorithm. Finally, for further dealing with the texture and reducing the effects of the noise, we enhance image by optimization based on the modified discretization of fractional calculus. Experimental results show that the proposed method has a state-of-the-art performance and do not suffer from staircase effects and noise.
The main contributions of the article are as follows: A novel image zooming method based on sparse representation is proposed. The method replaces the local filter operator with the WLD, which is modified for considering the weight of each point to the center pixel and eliminating the influence of the noise. The modified WLD can better extract the textures. Fractional PDE is adopted to smooth the output high-resolution image for removing block effects and noise, and fractional PDE can well deal with the textures and can preserve the image texture structure. The modified discretization of fractional calculus using Fourier transform can avoid extending four times of the original image and can save lots of computation cost.
The organization of the rest of the article is as follows. In section “Related work,” we give a brief review of the method based on sparse representation. The proposed model and its analysis are introduced in section “Proposed method.” Section “Experiments results” is devoted to implementation details of numerical experiments. Finally, some conclusions are summed up in section “Conclusion.”
Related work
Image super resolution based on sparse representation was first proposed by Yang et al. 5 The idea of the method is to obtain the SR image Y from a given image (LR) X using sparse representation. In this method, there are two dictionaries denoted as Ds and Dl, which are trained to have the same sparse representation for each SR and LR image patch pair. For each given LR patch x, a sparse representation will be found with respect to Dl. The corresponding SR patch Ds will be combined according to these coefficients to yield an output SR patch y.
According to hypothesis, the SR image can be represented sparsely in the right over-complete dictionary as

where y is a small patch of the SR image Y and αs is the sparse representation in over-complete dictionary of Ds.
Suppose x is a small patch of LR corresponding to y, and then, x can be sparsely represented as

The sparse coefficients αs can be restricted by representing patches x of the LR image X, with respect to a LR dictionary Dl co-trained with Ds.
For a given image signal x and dictionary Dl, the problem of finding the sparsest representation of x can be formulated as

where F is a feature extraction operator or an unit matrix and α is a sparse representation.
Donoho 19 has shown that as long as the desired coefficients (α) are sufficiently sparse, they can be efficiently reconstructed by minimizing the l1-norm, as 5

Lagrange multipliers offer an equivalent formulation

Equation (5) just solves the local image patch optimal solution. However, for each local patch, it does not guarantee the compatibility between adjacent patches. Therefore, for the compatibility, Yang et al. modified equation (4) to be
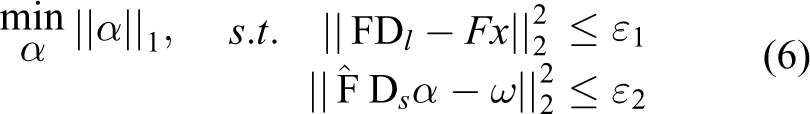
where matrix

where
But equations (4) and (6) do not demand exact equality between the LR patch x and its restoration Dlα. For eliminating this discrepancy by projecting Y0 onto the solution space of SHY = X, we can obtain more accurate SR image by computing equation (8) using the back-projection method

where S represents for a blurring filter and H stands for down-sampling operator.
Proposed method
Weber’s law descriptor
In this section, we will briefly review the feature extracting method proposed in the study by Yang et al. 5 and discuss the model of the WLD. For illustrating that WLD can well be used to extract feature, we carry out an experiment of WLD compared with the method by Yang. 5
From the view of perception, humans are more sensitive to the details of the high frequency details than that of the low frequency of an image. Generally, Gauss filter is used as a feature extraction operator in equation (3). Experimental results show that it is feasible to reconstruct a high-resolution image using the high frequency part of a LR image. Many researchers suggest that different features of LR images should be extracted to ensure the precision of prediction. Freeman et al. 11 extracted edge information of LR as the features using a high-pass filter. Sun et al. 20 extracted the contour of LR as the features using a set of Gauss iterative filters.
In the method by Yang, 5 there are four one-dimensional filters for extracting the features as follows 21

Four groups feature vectors convoluting four filters with the LR blocks were first obtained, and then, grouped the four sets of vectors together to get the final feature of the LR image blocks. There, we get a good compatibility between reconstructed high-resolution image blocks and the surrounding blocks.
WLD was proposed for extracting local area features by Chen et al. 17 and motivated by Weber’s law. Weber, a German physiologist, 22,23 first described Weber’s law in 19th century. The law reveals that the ratio of the background stimulus u to the intensity increment δu is a constant. 24 This relationship can be expressed as

WLD is based on a physiological law, it has three advantages: detecting edges elegantly, robustness to illumination change and noise, and its powerful representation ability. 17 It consists of differential excitation and orientation. Differential excitation (ω) is a function of the Weber fraction and orientation (θ) is a gradient orientation of the current pixel.
The changes of the current pixel can be described by intensity differences between its neighbors and a current pixel. So the step of computing a differential excitation ω(Ic) of the current pixel comes to be as follows: computing the differences between the center point and its neighbors is the first step

where Ii stands for the intensities of p neighbors of Ic, i = 0,1,…, p−1. p is the number of p neighbors.
The second step is computing the arctangent of the sum of differences ΔIi

where p stands for the number of p neighbor and ΔIi have different values when p has different values.
For considering the weight of each point to the center pixel, in this article, we modified the formulation of ΔIi. We adopt p1 = 12 and p2 = 8 in this article, then we get

where w1 and w2 represent different weights on the neighborhood p1 and p2, respectively.
We will carry out an experiment for extracting the textures of an image using WLD. For a given image, we first compute the image differential excitation and then make sure the gradient direction according to gradient difference. Finally, we show the differential excitation by mapping it to [0,255]. Figure 1 shows the comparison result of different filters, and we can see that the result of the WLD is better than that of other filters in extracting textures.

Comparison of the different filters. (a) “Barbara” original image. (b) Filtered image using WLD. (c) Filtered image using the first filter f1. (d) Filtered image using the second filter f2. (e) Filtered image using the third filter f3. (f) Filtered image using the fourth filter f4. (g) Filtered image using the grouped four filters. WLD: Weber’s law descriptor.
Modified method of fractional calculus
In this section, first, we give a discussion of calculus from integer to fractional calculus. Then, discrete fractional calculus adopting frequency domain definition is introduced. Finally, we improve the discretization method introduced in the study by Bai and Feng. 18 We will carry out experiments to show that the modified method is effective and has a less computation cost than that of the method by Bai and Feng. 18
As we all know, fractional calculus is an extent of integer calculus, and the definition of fractional calculus has many formulations, such as definition Rieman–Liouville, Caputo, Weyl, and Grünwald–Letnikov. 1,9,18,25 In this article, we adopt frequency domain definition for considering fractional calculus is easy to compute.
For a given function
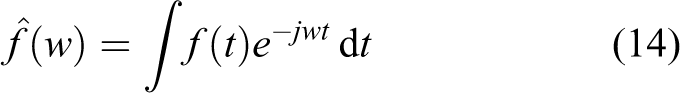
The equivalent formulation of the first-order derivative in the frequency domain is

From equations (16) and (17), we can extend the integer-order Fourier transform to a fractional one. For a fraction number v, we can obtain the fractional derivative of f(t) in the frequency domain with

Similarly, we can get forms of the fractional-order partial derivative of

Now, we can define the fractional gradient operator
There are many methods to implement the fractional order differential. Here, we adopt frequency domain definition introduced by Bai and Feng.
18

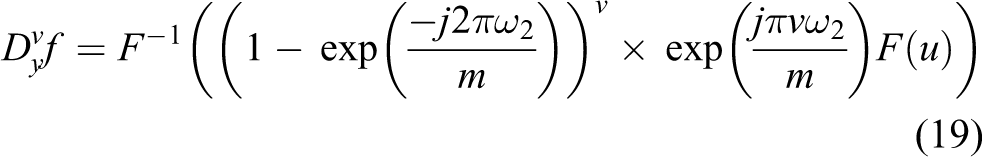
and the adjoints of
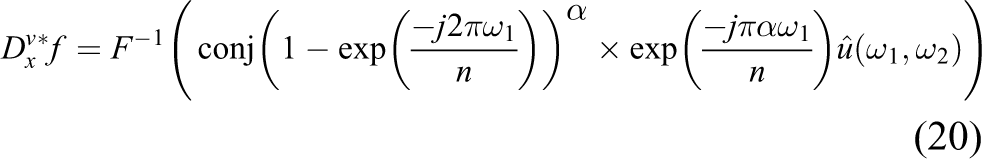

When m is an odd integer,

(a) “Lena” original image, (b) pixel gray values of the selected rectangular in the original image (a), (c) the lower left is result image (output) that performs Fourier transform and inverse Fourier transform, (d) pixel gray values of the selected rectangular in the result image after performing modified fractional calculus (c).
Computation time and SNR results of our method and the method by Bai and Feng. 18

SNR: signal noise ratio.
We can see that the cost of computation of the method by Bai and Feng 18 and modified method is increasing and SNR values are decreasing when the numbers of the iteration increasing from Table 1. While the time of the method by Bai and Feng 18 is almost five times of the modified method, and the SNR values of the method by Bai and Feng 18 are smaller than modified method. This shows that the modified method not only save the computation time and also can get larger SNR values.
The scheme of the proposed method
The process of the proposed algorithm can be described as follows: Initialization: input the LR image X, dictionary Dl of LR, dictionary Ds of high resolution, and other related parameters; Iteration for each patches of X. Feature extracting: Extract the WLD feature ω(Ic) of LR image using equation (12). To recover each LR patch and get sparse representation α according to x = Dlα, where α must be satisfied the optimization problem: To compute the high-resolution image patches using y = Dsα, put the high-resolution image patches into a high-resolution image Y0. End for iteration. Image reconstruction: Use the back-projection method to find the closest image to expected image that satisfies the reconstruction constraint as equation (8)

5. Output the high-resolution image Y′ using the following equation
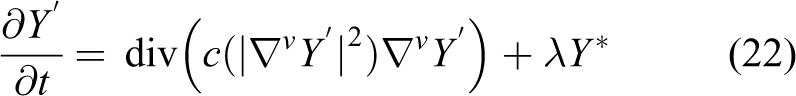
where Y′ is the final result.
In the proposed method, the first step is we input the LR image, dictionary size, image patch size, numbers of patches to sample, dictionaries of LR, and high resolution, which can be pretrained using many different types of images. The second step begins an iteration, for each patches of the LR image X, we first extract features of the LR image patches using differential excitation equation (12) of the modified WLD introduced in section “Weber’s law descriptor.” The parameter p in equation (12) is selected to be 8 and 12, respectively. Second, each LR patch is recovered according to the features obtained in the second step, and the high-resolution image patches are generated by solving the optimization problem:
Experimental results
In this section, we will compare the output images of our proposed method with that of one of the up-sampling algorithms (bilinear interpolation (BLI), 26 the bicubic interpolation (BCI), 27 the traditional super-resolution method of sparse representation (SCSR) 5 ), the decorrelated vectorial total variation (DVTV 28 ), the structure tensor total variation 29 , and the Hessian Schatten-norm Poisson Image Reconstruction by Augmented Lagrangian (HSPIRAL 30 ). The experimental environment is set as: operating system is Microsoft Windows 7 ultimate edition (Service Pack 1), CPU is Intel® Core™ i3-2120 @3.30G Hz, 8.00 GB of memory. First, we enlarge the parts of the input LR image by a factor of 4; then test effects of the magnification factor; third, verify the robustness to noise; and finally, analyzing effects of the dictionary size. All the test images are downloaded from the Web site: https://www.cs.cmu.edu/∼cil/v-images.html. The images tested in the experiments are Barbara, Lena, butterfly, leaves, parrot, liberty statue, and plants.
The formula of peak SNR (PSNR) and root mean square error (RMSE), respectively, is

where I and K represent input and output images, respectively.
Selection of fraction number v
In this subsection, we will discuss the selection of the fraction number v. Different values of v can introduce different results. In this experiment, the discussed range of v is [0.2, 1.9] for different images, and the performance evaluation employs the PSNR and RMSE. The bigger the PSNR’s value, the better the result of the restored image is. On the contrary, the smaller the RMSE’s value, the better the result of the restored image is. We have tested seven images for selecting proper fractional order v and computed the values of PSNR and RMSE when v has different values. We can see that PSNR achieves the largest and RMSE gets the smallest when value of v floating around 0.8 as seen from Table 2. Therefore, we will adopt the value of v as 0.8 in this article.
Value of PSNR and RMSE when adopting different value of v.
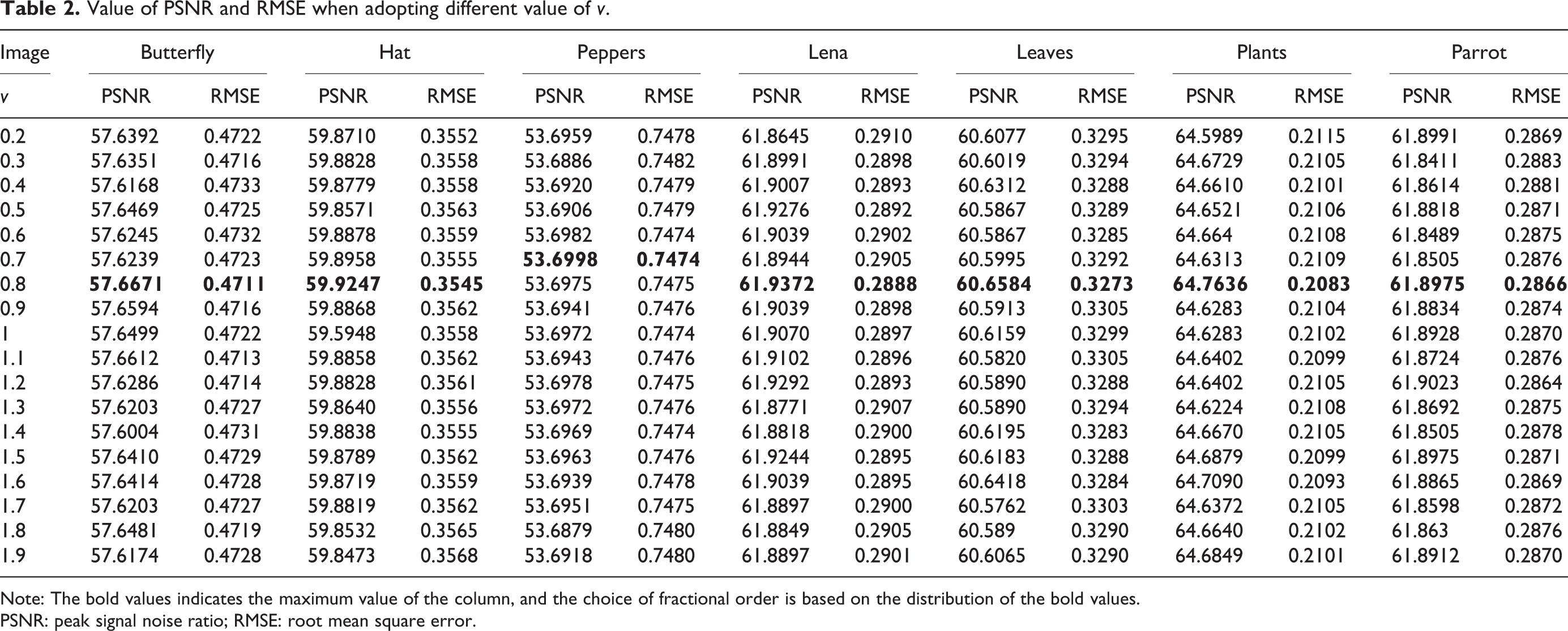
Note: The bold values indicates the maximum value of the column, and the choice of fractional order is based on the distribution of the bold values.
PSNR: peak signal noise ratio; RMSE: root mean square error.
Image super resolution
The outputs of our method along with methods of BLI, 26 BCI, 27 DVTV, 28 Weber22, and SCSR 5 are shown in Figure 3. The key idea of the BLI is first to perform the linear interpolation in one direction and then in the other direction. Though each step is linear in the sampled values and in the position, the interpolation as a whole is not linear but rather quadratic in the sample location. In contrast to BLI, which only takes 4 pixels into account, BCI considers 16 pixels. Therefore, images up-sampled with BCI have fewer interpolation artifacts and are smoother. We can see there are many jagged effects in the first column and not clear enough except for the image (p). There are less jagged effects in the outputs of SPSR than the result of BCI but have undesired smoothing (we choose patch size as 5 × 5 pixels and dictionary size 512), especially in “butterfly” image. Because the method of Weber22 aims at gray image, so there are some shortcomings when it is used for processing color images. We will see double edges in result images of method by Weber. 22 In Figure 3(q), the original color of the area of we select is close to gray and white, but the color after zooming is distortion, so the results of the method by Wang et al. 8 is the worst in this experiment. The results have the almost same clear texture in the images (h) and (k), and the output image (n) is the worst. We computed the PSNR and RMSE of the method mentioned earlier, and we can see that the PSNR value is the biggest and the RMSE value is the smallest in the results of this method. So, we can state that the output images of our proposed method have lesser jagged effects and well dealt with background image (p = 8 in equation (13)). We plot a curve for three images’ PSNR using six methods, it shows that PSNR of our method is the biggest from Figure 4.

Results of the images magnified with a factor of 4. (a–c): BLI, PSNR = 36.5053, 40.3627, 41.4907, RMSE = 8.091, 4.8022, 3.4463; (d–f): BCI, PSNR = 33.1309, 37.1606, 37.6421, RMSE = 13.0153, 7.9019, 6.0192; (g–i): SCSR, PSNR = 40.2745, 53.2414, 45.5901, RMSE = 3.5732, 2.5484, 1.9224; (j–l): our method, PSNR = 40.3212, 44.1811, 46.5835, RMSE = 3.5659, 2.2878, 1.7318; (m–o): method by Ono and Yamada, PSNR = 32.9813, 35.2006, 35.4041, RMSE = 4.2273, 3.5658, 3.4674 28 ; and (p–r): method by Wang et al., 8 PSNR = 22.2222, 27.9341, 26.2997, RMSE = 19.7437, 10.2290, 12.3468.
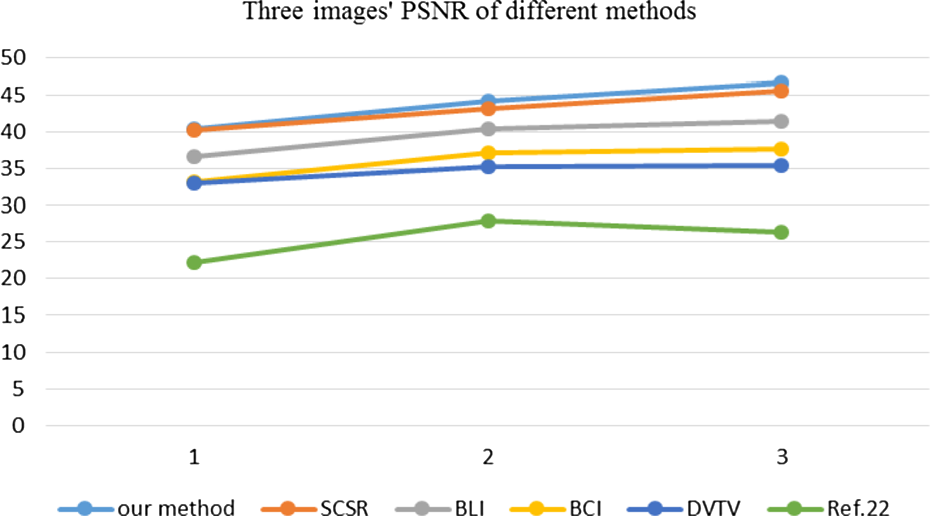
PSNR of three images of six methods. PSNR: peak signal noise ratio.
Effects of magnification factor
For validating the effectiveness of our proposed method, we up-sample portion of the “parrots” image with different magnification factors, such as 2, 3, 4, and 5. The results of the BCI method, SCSR 5 method, DVTV 28 method, and the proposed method are shown in Figure 5. When taking the magnification factor as 2, almost there exist not any differences between the results of these three methods. When taking the magnification factor as 3, there are some differences between the results of these three methods. The result of the BCI method is less clear than that of SCSR and the proposed methods. The color of the area of we select is distorted in the result of the study by Wang et al., 8 because the method by Wang et al. 8 aims at image zooming of the gray image. As the magnification factor value increases, the results of SCSR and the proposed methods are clear than that of bicubic’s. The texture of the proposed method is clear than that of SCSR method. There are some zigzags in the result of the algorithm DVTV, 28 and as the magnification factor raises, the jagged phenomena are increasingly evident. But the texture of the method described in this article does not.

Performances evaluation of our proposed method with different magnification factors. (a–d): BLI, 26 PSNR = 40.8793, 40.4315, 40.3627, 40.3066, RMSE = 4.1283, 4.6531, 4.8022, 4.8733; (e–h): SCSR, 5 PSNR = 41.9838, 42.8629, 43.2414, 43.5568, RMSE = 3.04 93, 2.6704, 2.5484, 2.4557; (i–l): DVTV, 28 PSNR = 31.3349, 33.7491, 35.2006, 36.4023, RMSE = 4.1363, 3.7435, 3.5658, 3.4195; (m–p): proposed method, PSNR = 42.0961, 43.0331, 44.1811, 43.6948, RMSE = 2.9779, 2.6038, 2.2878, 2.4128; (q–t): method by Wang et al., 8 PSNR = 25.2455, 26.9764, 27.9341, 28.9267, RMSE = 13.4668, 11.4214, 10.229, 9.1244, respectively, and from left to right are with magnification factors of 2, 3, 4, and 5. PSNR: peak signal noise ratio.
Effects of noise
To verify the robustness of our proposed method against noise, we test the LR image with different levels of standard deviation of Gaussian noise from 5 to 20. Figure 6 shows the outputs of our proposed method applying to the Liberty statue images with different levels of Gaussian noise. As the noise level increases, different effects exhibit in the results of different methods. There are small differences and removed influence of noise in the first column except of SCSR. When the level of Gaussian noise increases to 10, BLI and BCI methods have almost the same results and are poor of robustness, and the output image with SCSR method has many noises in it and is the worst case among the results with these four methods in the second column. When the noise level being set to be 15 or 20, the results of BLI, BCI, DVTV, and SCSR have many noises among the output images. In these levels of noise, there are some noises in the output image of our proposed algorithm too, but it is the best result of these methods. Table 3 also shows that proposed algorithm achieves the lowest RMSE among these methods as well.

Performances evaluation of our method on noisy data. Noise level (standard deviation of Gaussian noise) from left to right: 5, 10, 15, and 20. (a–d): results of BLI; (e–h): results of BCI; (i–l): outputs of SCSR; (m–p): denoised images using our method; and (q–t): method by Chan et al. 3
The RMSEs of reconstructed images from different levels of noisy inputs.
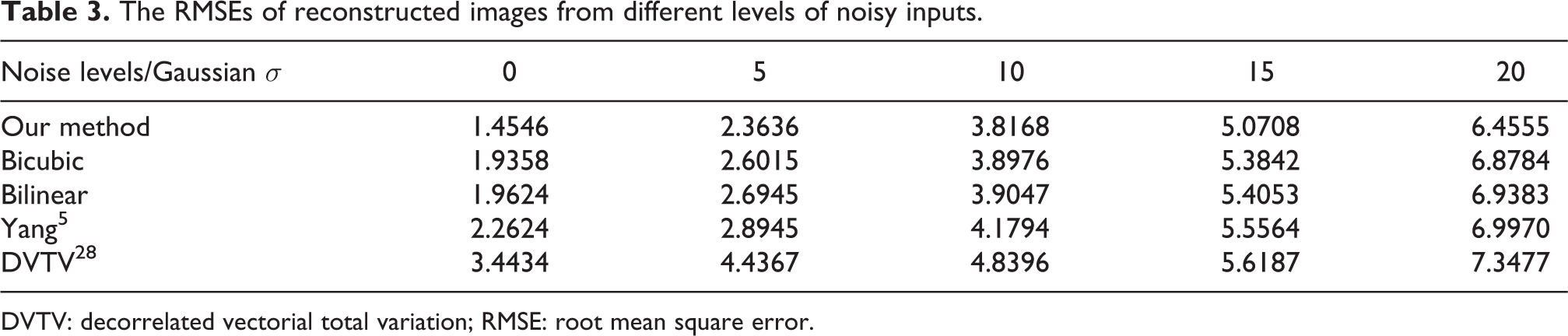
DVTV: decorrelated vectorial total variation; RMSE: root mean square error.
Effects of dictionary size
Less dictionaries should possess less expressive power and may get a less accurate approximation but less computing cost. In this section, we will evaluate the effect of the dictionary size on image SR. We train eight dictionaries with size of 16, 32, 64, 128, 256, 512, 1024, and 2048 from the sampled 10,000 images. Table 4 shows the reconstructed results for five images (including leaves, liberty statue, parrots, plants, and butterfly image) using dictionaries with different sizes. The lower the RMSEs are, the better the reconstructed images. The results of our algorithm for these five images are lower than that of SCSR except few numerical values. The results of SCSR method are relative stability as the dictionary size increasing, while the result of our algorithm doesn’t. Fluctuation of the results of SCSR is bigger when the dictionary size increasing from 512 to 1024 and 2048. According to the study by Yang et al., 5 we knew that the bigger the size of the dictionary, the more accurate approximation is, but the more computation cost. Larger dictionary sizes should increase the computation cost, but the RMSE have changed little in proposed method in this article. So, we always fix the dictionary size as 64 in all our experiments for a balance between image quality and computation cost.
Results of our algorithm compared to SCSR 5 and the corresponding RMSEs.

SCSR: super-resolution method of sparse representation; RMSE: root mean square error
Conclusion
In this article, a novel algorithm is proposed toward the single image super-resolution based on WLD and fractional calculus. The idea is based on that nonlocal information such as texture can be well dealt with fractional calculus, the modified discretization of fractional calculus not only can save lots of computation cost but also can well deal with nonlocal information; and the local information can be extracted using Weber’s law descriptor, the modified WLD can well extract textures and avoid effects of noise. Experimental results show that our presented method is effective for eliminating jagged effect and removing noise. In the future work, we will try to fuse the extraction method with other algorithms.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by Fundamental Research Funds of the Central Universities (NO.106112014CDJZR188801) and the Major Project of Fundamental Science and Frontier Technology Research of Chongqing CSTC (Grant No. cstc2015jcyjBX0124), and also supported by the Scientific and Technological Reseach Program of Chongqing Municipal Education Commission (KJ1600410).