
Abstract
Security surveillance is an important application for patrol robots. In this article, a real-time running event detection method is proposed for the community patrol robot. Although sliding window-based approaches have been quite successful in detecting objects in images, directly extending them to real-time object detection in video is not simple. This is due to the huge samples and diversity of object appearances with multivisual view and scale. To address these limitations, first, a simple and effective spatial–temporal filtering-based approach is proposed to obtain moving object proposals in each frame; then, two-stream convolutional networks fusion architecture is introduced to best take advantage of the spatial–temporal information from the proposal. The algorithm is applied on PatrolBot in community environments and runs at 15 fps on a consumer laptop. Two benchmark data sets (the Kungliga Tekniska Högskolan [KTH] data set and Nanyang Technological University [NTU] running data set) were also used to compare results with previous works. Experimental results show higher accuracy and lower detection error rate in the proposed method.
Keywords
Introduction
Public regional security monitoring is a hot research direction. 1 A large number of stable surveillance cameras are installed in high traffic areas, such as public squares, bus stations, and subway stations, 2 to facilitate monitoring. However, monitoring work is primarily conducted by manual patrol for areas with low traffic flow. With the increasing in human resources costs and the development of robot technology, video event analysis technology based on the community patrol robot has been widely concerned. 3,4 Compared to that with stable cameras, video event analysis using onboard cameras presents two significant challenges 2 : the camera’s self-motion introduces noise into motion information, and the diversity of appearance and multiple visual scale.
Since video events can vary significantly, traditional approaches for video event detection require detecting and tracking objects first and then recognizing what is happening around those tracked objects. However, because tracking objects are challenging tasks in dynamic and crowded scenes, they may not provide robust event detection results.
Based on the assumption that an object in a specific event has an appearance or action significantly different from others, video event detection is generally treated as detecting a specific object from video. Thus, encouraged by the success of object detection, the sliding window approach was introduced to video event detection. 5 Instead of tracking objects, a sliding window-based approach extracts handcraft or automatically learns features from an image block or spatial–temporal subvolume, 6,7 and the classifier is designed to judge these features. Although it has advantages for video event detection, it fails to solve two unsolved problems in our real-time running event detection task.
First, many current sliding window-based methods do not fully exploit the motion information, which is an important cue for event detection. On the one hand, some algorithms only use appearance information to simplify the task. However, this information alone can hardly distinguish the running action. One reason for this is that the onboard camera brings the diversity of appearance and multiple visual scale. Another reason is that the running appearance may be similar to appearances of other actions. To illustrate this, Figure 1(a) shows running action appearances with different running direction and visual scale, and Figure 1(b) shows several people running and walking with only a few differences in elbow and knee bends. On the other hand, although some recent methods have been proposed to handle motion information in spatiotemporal video subvolumes (e.g. 3-D bounding box), these methods were inapplicable for “dynamic” events. An event is defined as static if an actor or object does not move when the event occurs, while an event is considered dynamic if movement does, during the event. Additionally, self-motion from the onboard camera results in the temporal feature extraction process becoming unstable.

Example appearances of people running. (a) People running with multi-visual scale, various running directions and clothes. (b) People walking (upper row) and people running (lower row) with similar appearances.
Second, it is very time consuming to search sliding windows in a 2-D space (frame) or 3-D space (spatial–temporal subvolume). For example, given a video frame of size w × h, where w × h is the spatial size. The total number of 2-D bounding boxes is O(wh). Although some recent methods were proposed to handle large search spaces, 8 such as edges, contours, and shapes, and these methods fail to significantly reduce the candidates.
To address these problems, we propose a novel approach to detect running events in real-time within a community environment. The approach begins with proposal extraction in each frame using motion cues and then considers spatial and temporal cues to judge the proposals. First, to greatly reduce the number of proposals at each frame, a simple and effective spatial–temporal filtering-based approach was applied to the continuous multiple optical flow from last several frames to find all objects of interest. Next, a two-stream convolutional networks fusion architecture was introduced to best take advantage of spatial–temporal information. The key contributions of this article include two parts: we constructed an moving object detector at frame level by taking motion cues into account, which extracts a limited number of running person proposals from the backgrounds and through detailed analysis of convolutional two-stream network fusion scheme, we proposed a fusion structure that made effective and consistent use of spatial and temporal cues.
The rest of the article is organized as follows: Related work is presented in section “Related work”. In section “Proposed approach,” a novel filtering-based proposal extraction method and our two-stream convolutional networks fusion architecture are described. The experimental results and discussion are presented in the section “Experimental results and analysis.” Finally, the article is concluded in section “Conclusions.”
Related work
Advances in image object detection methods, which were often adapted and extended to deal with video data, largely drove video events detection research. A large family of running event detection methods is based on shallow high-dimensional encodings of holistic spatial–temporal features. For instance, motion energy image and motion history image (MHI) were introduced by Bobick et al. 9 As the names suggest, the underlying idea is to encode motion-related information using a single image. By extracting the gradient of MHI template 10 or Harris interest points, MHI templates contain useful information about the context of videos 11 and proposed to identify running event based on the differential properties of the space–time volume (STV). An STV is built by stacking object contours along the time axis. Inspired by the success of the action bank method, 12,13 described a large set of detectors acting as bases for a high-dimensional “action-space,” which was constructed using the Laplacian of 3-D Gaussian filters. However, holistic approaches are too rigid to capture possible variations of actions, especially when the camera is moving.
Instead of computing holistic features, state-of-the-art shallow representations compute local video features over spatial–temporal cuboids. For instance, the algorithm of the study by Laptev et al. 14 consists in detecting sparse spatiotemporal interest points, which are then described using local spatiotemporal features: histogram of oriented gradients (HOG) 15 and histogram of optical flow. The features are then encoded into the bag of features representation, which is pooled over several spatiotemporal grids (similarly to spatial pyramid pooling) and combined with an Support Vector Machine (SVM) classifier. A more robust extension of optical flow features use of dense point trajectories. 16 –18 The approach, first introduced in the study by Wang et al., 19 consists in adjusting local descriptor support regions, so that they follow dense trajectories, computed using optical flow. The best performance in the trajectory-based pipeline was achieved by the motion boundary histogram, 20 which is a gradient-based feature, separately computed on the horizontal and vertical components of optical flow.
Recently, compared to handcrafted shallow features, deep learning methods learn features automatically, which receives a considerable success in image classification. The attempt to extend it to event detection or action recognition has received wide attention. In the majority of these works, the input to the network is a stack of consecutive video frames, so the model is expected to implicitly learn spatiotemporal motion-dependent features in the first layers, which can be a difficult task. In the studies by Chen, 21 Le et al., 22 and Taylor et al., 23 a convolutional Restricted Boltzmann Machines (RBM) and Invariant Spatio-Temporal Aggregates (ISA) were used for unsupervised learning of spatiotemporal features, which were then plugged into a discriminative model for action classification. Karpathy et al. 24 study several approaches for temporal sampling, including early fusion (letting the first layer filters operate over time as in the study by Ji et al. 25 ), slow fusion (consecutively increasing the temporal receptive field as the layers increase), and late fusion (merging fully connected layers of two separate networks that operate on temporally distant frames). 26 The architecture of these approaches is not particularly sensitive to temporal modeling, and they achieve similar levels of performance using a purely spatial network. This indicates that the model does not benefit much from the temporal information.
The most closely related work to ours, and the one we extend here, is the two-stream convolutional networks (ConvNet) architecture proposed in the study by Annane et al. 27 This method first decomposes video into spatial and temporal components using an RGB (red green blue) color and optical flow frames. These components are fed into separate deep ConvNet architectures, to learn spatial and temporal information about the appearance and movement of objects in a scene. Each stream performs video recognition on its own, and for final classification, softmax scores are combined through late fusion. Compared to the fusion at the last layer, we consider that the temporal and appearance information have consistent relations at the same local position. Therefore, we changed the fusion strategy, put the fusion at middle layer. Performance results show that this design is effective.
Proposed approach
Given an video sequence X = {X1, X2, …, Xt}, our goal is to find whether there are people running. In other words, we need to label the frames {Xi| target ∈ Xi} as presence of moving person. For the purpose of real time, we treat that one frame from the frames as presence of moving person has been detected as success detection of running event task. Therefore, our task become to determine whether each frame has a moving person. First, a proposal generation algorithm was used to greatly reduce the search space. Then, a two-stream convolutional neural networks fusion architecture was proposed to best take advantage of spatial–temporal information from the proposal. The input of the spatial stream was the proposal’s gray image, and the input of the temporal stream was the proposal’s processed optical flow. Two streams underwent fusion at middle layer. The overview of our proposed approach is shown in Figure 2.
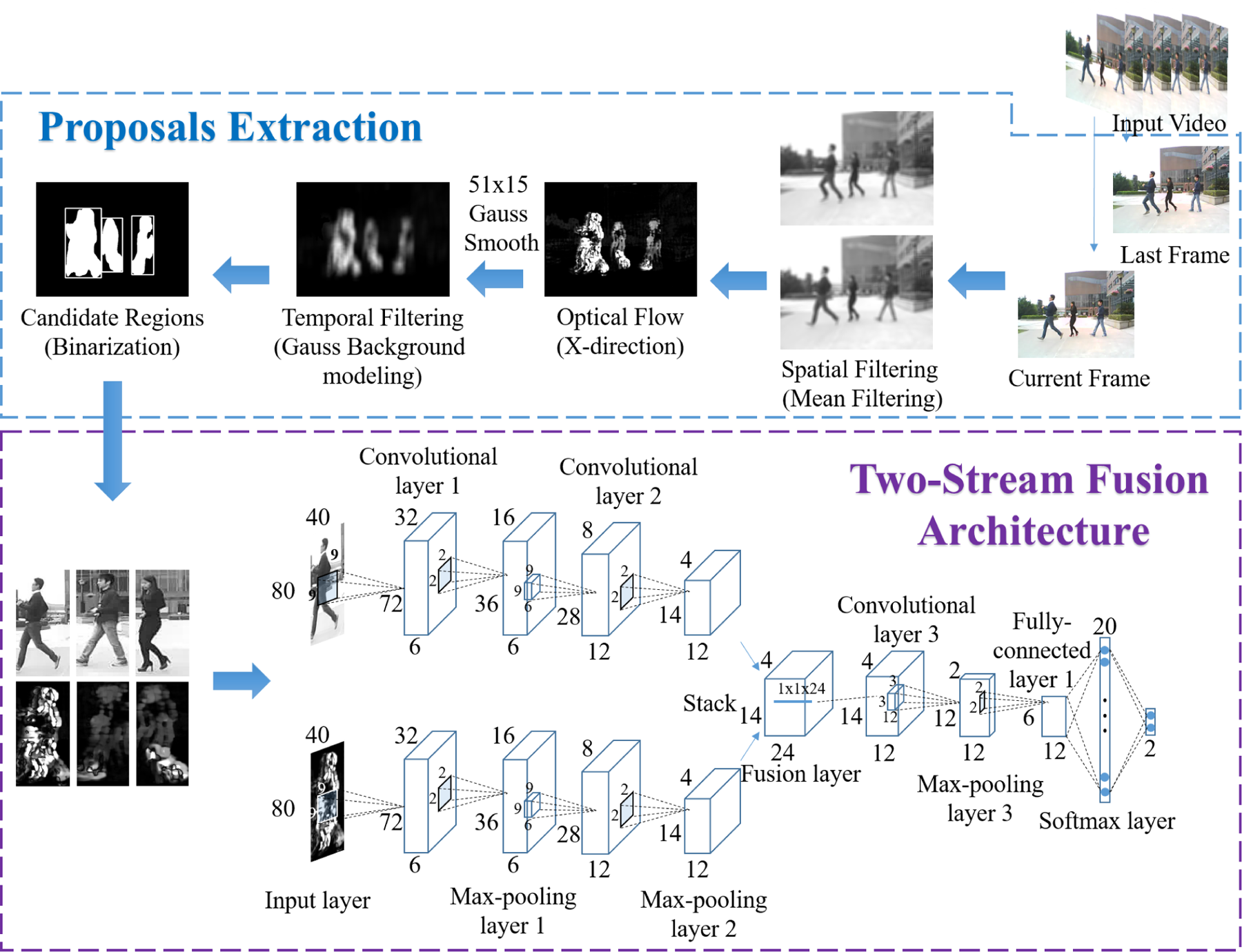
Flowchart of the proposed approach.
Proposal generation
For general events, motion cues, which are cues most distinguishable from other cues, are essential. It is especially crucial for our running event detection. Therefore, we applied optical flow, type of motion cue, to generate proposals.
The Gunnar Farneback optical flow approach 28 was applied to each frame, because of its fast calculation time. We denote the optical flow sequence as O = {O1, O2, …, Ot}, where Oi is a w × h optical flow frame and t is the current time. In an ideal environment with stable camera, only the moving target produces movement. However, the self-motion of the onboard camera affects optical flow results. Therefore, the influence of self-motion in each optical flow frame must be removed. Methods for compensation are not only time consuming but also fail to accurately calculate the actual optical flow value, because the self-motion of the camera is closely related to the speed of the robot itself and the surrounding environment. From the viewpoint of signal process, we use the filter algorithm to deal with the original optical flow. Treating the optical flow slip as a spatial–temporal data volume, the moving target belongs to the high frequency part of the signal in the time domain, while the low frequency part belongs to the signal in spatial domain.
In the spatial domain, we treated self-motion as noise. Due to perspective transformation, the self-motion in frame with different positions has different values and directions, as shown in Figure 3(a). However, the movement of the object is consistent. Thus, mean filter with a big size was applied to the original frame before optical flow. The size of the mask was related to the speed of the robot and was usually set as 15 × 15. The final optical flow result is

where Of( ) is the optical flow operation, fm( ) is the mean filtering operation, and r is the size of the mean filtering mask.

Example of our proposed proposals generation approach. (a) Self-motion optical flow with pure flat background. (b) X-direction optical flow (upper row is without mean filtering on frames, bottom row has 15 × 15 mean filtering.)
In the time domain, moving targets are dynamic, while other signals remain relatively unchanged. A high-pass filtering algorithm was usually considered. Therefore, to extract the moving target, the Gauss background modeling method was applied to the optical flow slip. Taking into account that we only care about object movement in the horizontal direction, only the x-direction optical flow was used. For the running event task, the Gunnar Farneback algorithm usually generated optical flow at the edge of the body. Thus, Gauss smooth operations with large size of rectangle mask were used to fill in the body’s void. Mask size was usually set as 51 × 15. The Gauss background modeling method is described as follows: For each spatial–temporal location v = (x, y, t), the optical flow modulus value obeys Gauss distribution

where α is 0, if Ot is the foreground. For our application, μt and dt are one-dimensional vectors, and the covariance matrix Σ t is simplified as variance σ2. The optical flow is processed as follows

Following the above processes, all the x-direction optical flow only kept moving objects with some scattered noise. Then, using morphological operations with small size of square mask, some scattered noise points were eliminated. Candidate regions were then extracted from each frame by finding all binary optical flow external contours. One example is shown in Figure 3. Each candidate region was normalized to a size of 80 × 40.
Two-stream convolutional networks fusion architecture
In this article, we built upon the two-stream architecture presented in the study by Annane et al. 27 This architecture has two parts: (i) the spatial part, in the form of individual frame appearance, carries information about objects depicted in the video and (ii) the temporal part, in the form of motion across frames, conveys object movement. Each stream was implemented using deep convolutional networks, softmax scores of which were combined by last fusion. In the original research, 27 two fusion methods are considered: averaging and training a multiclass linear SVM on a stacked L2-normalized softmax scores as features. This architecture has two main drawbacks: first, it is unable to learn the pixel-wise correspondences between spatial and temporal features (since fusion is only on classification scores) and second, high-level abstract features cannot effectively exploit spatial–temporal information.
For running person detection, pixel-wise correspondence between spatial and temporal features is important. Consider, for example, discriminating between the actions of walking and running, as shown in Figure 4. The spatial network recognizes the appearance but because the actions are similar, they are difficult to discriminate. However, the temporal network can recognize motion, and combining the networks enables action discrimination. Thus, we fused the two networks (at a particular layer point) such that channel responses at the same pixel position were put in correspondence.

The walking (upper row) and running (lower row) people with similar curved legs and different motions. Red rectangles show the pixel-wise correspondence position between spatial and temporal channels.
The fusion process requires two factors to be considered. First is the form of fusion. When the two networks have the same spatial resolution at fusion layers, spatial correspondence is easily achieved. The simplest way to accomplish this is overlaying (stacking) layers from one network on the other. Other methods are discussed in the following paragraph. The other factor requiring consideration is how to effectively combine temporal and appearance information, that is, locating the best fusion point on the total architecture. Suppose that different channels in the spatial network are responsible for different areas (legs, hands, head, body, etc.), and one channel in the temporal network is responsible for this type of motion. Then, after these special channels are stacked, filters in the subsequent layers can learn correspondence between these appropriate channels (e.g. as weights in a convolution filter) to best discriminate between actions.
There are a number of ways to fuse layers between two networks.
26
The fusion function
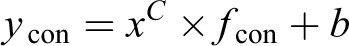
where
As mentioned earlier, fusion can be applied at any point in the two networks. For our application, we set the fusion point after the pooling layer in the middle of the structure. First, since the fusion layer is an AND operation, the best position for fusion was after the pooling layer. The convolutional layer was treated as an AND operation, while the pooling layer was treated as an OR operation. The decision to use the middle of the architecture was based on the following reasons. On one hand, low-level feature response at early layers was not appropriate for fusing the motion information. Visual features were not abstracted and therefore would produce significant interference. On the other hand, high-level abstract features in the spatial stream cannot provide pixel-wise correspondence with the temporal stream. The semantic features are more suitable for decision level fusion, for our application, while the local features are more helpful for applying spatial–temporal information. The two-stream convolutional networks fusion architecture is shown in Figure 2.
Experimental results and analysis
In this section, we evaluate the performance of the proposed approach. First, the training details of the two-stream fusion architecture are described. Then, we test our real-time running event detection system on PatrolBot in community environment. Finally, two benchmark data sets (the KTH data set 31 and NTU running data set) are also used to compare results with previous works.
Implementation details
Video data on the Internet is hard to meet the requirements, due to view angle and lack of camera self-motion. Therefore, we used PatrolBot to collect data from marathon race, community street, and sports playground. We manually labeled running people and obtained 14,232 positive samples with various angles, visual scales, clothes, illuminations, and backgrounds. Taking into account that the actions of walking and running are very similar, we used the “HOG + SVM” method 15 to obtain 4000 negative samples. Additionally, since the HOG + SVM method cannot detect walking action appearances that are similar to running, we manually extracted these walking appearances, to obtain 3000 negative samples. To balance the data and improve algorithm robustness, we collected 7232 negative samples from a variety of community backgrounds. Some samples are shown in Figure 5(a). Before fusion, we independently trained two convolutional neural networks. The structures of these two convolutional neural networks are same, while one input is frame image, and the other is processed optical flow. Detailed parameters are shown in Figure 5(b). The size of the input layer was 80 × 40, the kernel size of three convolutional layers were 9 × 9, 9 × 9, and 3 × 3, respectively. The number of output maps was 6, 12, and 24, respectively. All pooling layers had a max-pooling size of 2 × 2. The size of the fully connected layer was 20 × 1 and softmax layer was 2 × 1, respectively. At the training stage, the learning rate was one, the batch size was 100, and the number of epochs was 200.
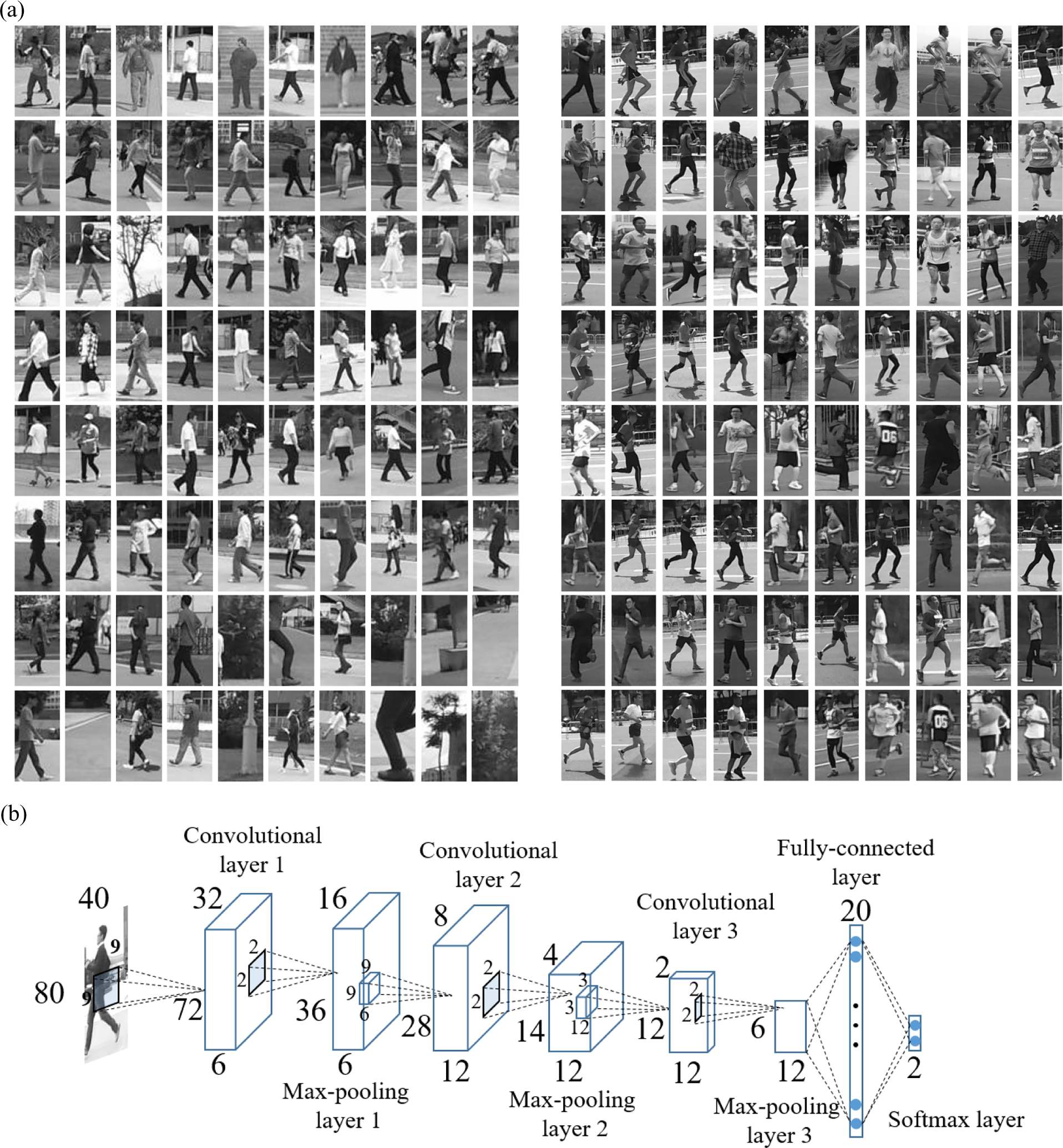
Training two single streams for fusion. (a) Some negative (left part) and positive (right part) spatial training samples. (b) Architecture of single stream convolutional networks. The spatial and temporal streams have same architecture.
During the fusion, each stream had 12 output maps with a size of 14 × 4, and the initialization parameters of the fusion architecture before the fusion layer were identical for each original stream. For our fusion method (treating the layer as convolutional), the kernel size was 1 × 1 and the number of output maps was 12. The following convolutional layer had a kernel size of 3 × 3 and 12 output maps. The closely followed pooling layer had a max-pooling size of 2 × 2. Finally, the fully connected layer was 20 × 1, while the softmax layer was 2 × 1. There were no major adjustments to the training strategy. Fusion architecture is shown in Figure 2.
Patrolbot experiment
We applied our method to PatrolBot, as shown in Figure 6. The camera was 1 m from the ground with horizontal view, and the resolution is 640 × 480. The PatrolBot’s speed was 1.5 m/s. The laptop is Surface Pro 2 with Core i5 CPU and 4 GB RAM. Our two-stream fusion architecture training code was completed under MATLAB [R2015b], while our testing code was completed using C# with mixed programming. Before testing our method, there are several parameters need to be determined. (i) The size of the mean filtering mask. This parameter was directly proportional to the velocity of the robot and the resolution of camera. For practical application, the faster the robot moves, the larger the mask size should be. So does the resolution of camera. However, the best size in different conditions is determined by the performance of the background elimination. For our application, it was set to 15, which eliminated the majority of camera self-motion. (ii) The threshold of Gauss background modeling. This parameter determined how fast moving objects could be detected. To detect someone running in a direction nearly parallel to the camera’s moving direction, we set this parameter to 1.5. The PatrolBot captured 30 videos containing people running and people walking with various backgrounds and covered all running angles (from parallel to perpendicular) and visual scales (the nearest is about 1 m and the farthest is about 8 m). In total, there were 152 people running and 237 people walking in the video. Some examples are shown in Figure 7.

Experimental device: PatrolBot.

Example detection results using PatrolBot. The first row shows the results with different visual scales. The second row shows results with various directions. The last two rows show results with different backgrounds, clothes and directions.
In order to quantify the evaluation of the algorithm, precision and recall of running persons were used. If there is one frame has been detected from frames that one running person appear in the video, and the overlap between detected running person and the ground truth is over 70%, it is considered as a successful detection for our system. On the contrary, it is regarded as false detection. Additionally, repeated detection of one person did not matter. Therefore, precision rate was calculated as the number of positive true detections divided by the number of total positive detections. Recall was calculated as the number of positive true detections divided by the total number of runner. To verify performance of the two-stream fusion architecture, the accuracy rate on proposals was used.
To verify our our convolutional fusion form, max fusion was used for comparison. Max fusion is typical for OR operations against with AND operations. We treated the max fusion as a max-pooling layer with a 1 × 1 × 24 mask. The mask was binary with 1 at randomly positions and 0 at the others. Several positions could undergo the fusion operation. We selected the pooling layers 1, 2, and 3 and the fully connected layer (the fusion process is similar to the literature 27 ) for fusion. Accuracy results for different fusion forms and fusion points on proposals that extracted by our proposal generation method on PatrolBot videos are shown in Table 1. Each walking person in the video appeared an average of 50 frames and each running person in the video appeared an average of 25 frames. The number of positive and negative proposals were 1903 and 2276, respectively. The running proposal detection rate was nearly 60%, while the walking proposal detection rate was 15%. As shown in Table 1, the spatial stream obtained only 86.1% accuracy. This is beacause there were too many similar samples between walking and running proposals. Results also show that convolutional fusion performed better than max fusion at any fusion point. Pooling layer 2 performed best. The better fusion point at pooling layer 3 than pooling layer 1 may be due to the low-level feature pixel-wise fusion missing early, yet important, local information. Furthermore, convolutional fusion at pooling layer 2 achieved 95.6% accuracy. For our applications, the cost of false positive detection was higher than that of false negative detection. Thus, we reduced false detection rate as much as possible by controlling the confidence threshold of the softmax layer’s output. There were 18 false positive samples and 166 false negative samples in the proposals.
Accuracy results of different fusion forms and fusion points on generated proposals using PatrolBot videos.

By selecting the convolutional fusion form and the pooling layer 2 location, we compared our method to previous methods used on PatrolBot videos. The original two-stream convolutional networks, 27 3-D convolutional networks 25 and 3-D-HOG 29,30 were selected, where the two-stream convolutional networks were the original fusion work, the 3-D convolutional networks were the typical deep learning structure used in event detection and the 3D-HOG detector was a popular shallow local spatial–temporal feature. The precision and recall curves at the person detection level are shown in Figure 8(a), and some detection examples are shown in Figure 7. In Figure 7, the first row shows our example results with different visual scales. Because of all samples extract features from continuous frames with fixed box size and position, thus these approaches were not affected. In the case of various running directions, similar appearances of walking persons and running persons often appear. Since 3-D convolutional networks stack frames directly, displacement caused by self-motion was not considered, making robust results hard to obtain. Although the 3-D-HOG method dealt with this problem using the spatiotemporal path search method, handcraft features could not extract effective information here. For our method, as temporal stream is used, the performances of two-streams networks and our method are better than 3-D based methods. In addition, our pixel-wise fusion strategy ultimately performed better than the original two-stream networks fusion. In various background case, as our samples are the external boxes of the running person body, some background pixels may affect the classification result slightly. These effects mainly occur in the case that background near the running object has curve edge similar to the legs. This situation is very rare. Thus, the complexity of the background is not much affected to our algorithm.

Comparison of precision and recall curves on two data sets. (a) Comparison of precision and recall curves on PatrolBot videos. (b) Comparison of precision and recall curves on NTU running videos.
In our system, the process most time consuming was optical flow calculations, with 41 ms required per frame. Although judging each proposal took 5 ms with no Graphics Processing Unit (GPU) acceleration, our proposal generation method greatly reduced the number of proposals requiring judgment. Other processes required 6 ms. Finally, our system detected running events in real time with 15 fps.
KTH data set
We also compared our method’s performance to those of previous methods on two data sets for the running event detection task.
KTH is a good data set for human action recognition and is widely used in the computer vision community. Although data set consists of six types of actions, we only used walking and running sequences for testing. Each action contained 100 sequences, 25 people, and 4 different scenarios: outdoors (cross), outdoors with scale variation (45°), outdoors with different clothing (cross) and indoors (cross). The person in each sequence appeared four times. Comparison results are shown in Table 2. Due to the emptiness and simplicity of backgrounds, well performances of running action, and simple and distinguishable clothes, there was no other noise on moving objects. Our proposed method obtained the best performance.
Comparison of precision and recall of different methods on the KTH data set.

HOG: histogram of gradients.
NTU running data sets
The NTU running data set consists of 15 positive sequences and 22 negative sequences. Each positive sequences contains one running person, who only appeared once. The big challenge of this data set is that although the camera is stable, the moving target is too far away from the camera in poor lighting. The compared precision and recall curves results are shown in Figure 8. Since precision was 100%, our methods missed three detections (Figure 9). Some example results are shown in Figure 10.

Example detection results on KTH. Four situations are considered. From the left to right column, it is cross the camera, zooming-in or -out, different clothes and indoor background respectively.

Example detection results on NTU running data set.
Discussion
Our proposals generation approach greatly reduced the number of candidate regions, and the proposed two-stream convolutional networks fusion architecture best took advantage of spatial–temporal information for running event detection. However, there were several problems in the practical application that deserve attention. First, there was candidate region adhesion in crowded scenes. Since the adhesion problem usually occurs in the x-direction, we divided the adhesion regions into several parts based on the ratio of the length and width of the candidate region. However, sometimes this was invalid, due to the large degree of overlapping areas, which increased the number of useless samples and reduced the number of proposals. Second, detection was unstable for runners with a direction parallel to the camera moving direction. Since movment was perpendicular to the image plane, our proposal extraction method could only work in close distance situations. Lastly, since the x-direction optical flow was used as the motion cue for proposals extraction, a sharp turn from the robot resulted in a large number of useless candidate regions. Some remedial measures such as candidate region width limitation must be adopted to reduce these useless candidate regions. Some examples are shown in Figure 11.

Examples of problems for practical application. (a) Proposal adhesion and two split parts. b) X-direction optical flow of parallel running person. (c) X-direction optical flow and the extracted candidate regions upon a sharp left turn of the robot.
Conclusions
We proposed a novel approach for running event detection at real-time speed. The proposals generation method greatly reduced the number of candidate regions and, therefore, was well suited for practical application in a patrol robot. In addition, a two-stream convolutional networks fusion architecture was proposed to take advantage of spatial–temporal information. By fusing temporal and spatial information through pixel-wise form, running actions were well differentiated.
In conclusion, this article contributes a novel approach for running event detection with significant improvements over previous methods to computer vision literature. This study addresses many problems in video event detection, especially for events including objects with special spatial–temporal information. In practice, thanks to its proposals generation approach, this detection system was an efficient examiner for daily patrol missions of robots.
Footnotes
Author’s note
Huiwen Guo and Xinyu Wu are also affiliated to Key Laboratory of Human-Machine-Intelligence Synergic Systems, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China and Guangdong Provincial Key Lab of Robotics and Intelligent System, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The work described in this paper is supported by the National Natural Science Foundation of China (61473277, 61602014).