
Abstract
Multi-robot with advantages of spatial distribution and fault tolerance is competent for patrol missions and has the potential to be used in security and surveillance applications. This article focuses on the frequency-based patrol designed to guarantee the frequent access to key positions in the environment. A distributed algorithm based on expected idleness is proposed, aiming to promote the efficiency of cooperation, which remains to be fault tolerant and scalable. The expected idleness is estimated with information shared between robots and utilized to avoid conflicts in the decision process. Comparisons with state-of-the-art algorithms have been conducted in a realistic simulator, Stage; moreover, the fault tolerance and scalability have also been tested. Experiments on real robots have further verified the applicability of the proposed algorithm.
Introduction
Patrol is the monitoring task needed to go around or through a specified area frequently, which can be employed in environmental monitoring, information collection, intrusion detection and other security or surveillance applications. But sometimes, the patrol mission may be tedious or even dangerous, so as the advancement in robotics research in recent decades, it is expected that mobile robots can be a substitute for humans in such mission. 1,2 Compared with a single robot, multi-robot system is more competent for patrolling, due to the spatial distribution, scalability and fault tolerance brought by redundancy.
Research on multi-robot patrol can be grouped into two categories: adversarial patrol and frequency-based patrol. The adversarial patrol 3 aims to detect the possible intruders who attempt to access the protected area, and the patrol path is a circular boundary in most cases. On the other hand, the frequency-based patrol 4 is designed to guarantee the frequent access to the specified area in order to gather information in time. Normally, the patrol area can be abstracted into a topological map, equivalent to an undirected graph in graph theory. Robots are capable of sensing within a certain range, so they can just visit some key positions (equivalent to the vertices of the graph) instead of covering the entire area. The performance is usually measured by the time interval between two visits to the same position, which is referred to as idleness. This article mainly concentrates on the latter problem, and the expression multi-robot patrol refers to frequency-based patrol without any instructions.
From the optimization theory point of view, the multi-robot patrol problem has a close connection with the vehicle routing problem (VRP) 5 and multiple traveling salesman problem. 6 However, these combinatorial optimization problems do not consider the repetitive and dynamic characteristics of the patrol problem, nor the cooperation between robots during patrolling. 7 The algorithms of multi-robot patrol can be divided into two categories: centralized algorithms and distributed algorithms. Two typical centralized algorithms 8,9 are cyclic patrolling based on the cycle in the graph and independent patrolling based on graph partition. The centralized algorithms are able to achieve good enough solutions in most cases. However, the cycle is not easy to find out especially in sparse topology graphs, and the partition may be unbalanced under certain configurations; moreover, the offline planning procedure of centralized algorithms is unable to adapt to possible changes in time. In distributed algorithms, 10 each robot independently chooses patrol route during the online planning procedure using greedy strategies or task allocation methods with limited communications. Compared with centralized algorithms, although distributed algorithms often result in worse performance, but they can offer better fault tolerance and scalability. More specifically, they can adapt to environments with diverse topological structure, and can also tolerate robots to join or withdraw during patrolling.
This article proposes a distributed algorithm based on expected idleness, aiming at the effective implementation of multi-robot patrol. The expected idleness is estimated with shared information through distributed communication and utilized to avoid potential conflicts between robots in the decision process. In this way, the simple and reactive algorithm in this article can provide a competent solution for patrolling compared with the previous studies. The algorithm is executed on each robot independently without the need for offline planning or centralized control, thus offers fault tolerance and scalability for the robot team.
The rest of this article is organized as follows. The literature review and problem formulation are presented in sections ‘Related work’ and ‘Problem formulation’. Then, the proposed algorithm is described in section ‘Distributed patrol algorithm based on expected idleness’. Sections ‘Experiments’ and ‘Simulation tests about scalability and fault tolerance’ report the results of simulation and real robot experiments. Finally, this article ends with conclusions in section ‘Conclusions’.
Related work
Research on multi-robot patrol issue uses the model of undirected graph to represent the patrol area. The vertices of the graph correspond to the key positions needed to be visited frequently, and the edges and their weight stand for connections and path lengths between these positions. Thus, algorithms from the graph theory can be utilized to solve the patrol problem with appropriate modifications, and this is the basic idea of most centralized algorithms. Centralized algorithms relied on graph methods can be divided into two categories: the cyclic algorithms and the partition-based algorithms.
In cyclic algorithms, robots move along a precalculated cyclic path through all vertices in the graph. The cyclic path can be calculated as a traveling salesman problem (TSP) problem (NP-hard problem can use heuristic algorithms to reach near-optimal solutions). Chevaleyre 8 proved that there exists an upper boundary of maximum idleness for the cyclic path based on the TSP solution. He also pointed out that the partition-based algorithms are preferred when graphs have long edges separating several regions. Further analysis and comparative study between the cyclic algorithms and the partition-based algorithms are provided in the study by Portugal et al. 9 Elmaliach et al. 4 assigned robots evenly in travel time along the cyclic path, so as to guarantee all the vertices to be visited under uniform frequency. For maps with appropriate cyclic path, homogeneous robots coordinated tightly to maintain uniform temporal separation can be efficient, but such method for heterogeneity of robots (with different velocities) under unreliable communication performs poorly. 11
The partition-based algorithms make a partition of the map into several disjoint regions and assign each robot a region to patrol independently. Furthermore, the graph partitioning and the local route planning could be optimized together by minimizing the local route with the maximum length. 9 In this way, the partition-based patrolling could be construed as a variant of the VRP. 5 Multilevel subgraph patrolling algorithm 12 is a typical partition-based algorithm, which uses a multilevel method for partitioning graphs, 13 and optimizes the local patrolling route of each robot. The performance of this algorithm mainly relies on whether the graph partition is balanced enough. 14 In partition-based algorithms, each robot patrols inside its own region after the partition of the graph is completed during the initialization phase. In the course of patrolling, some robots may not perform as expected or even be broken, and original partition-based algorithms could not cope with such situations. Pippin et al. 15 used an external monitor to inspect the visits of each vertex and adjust the task assignment among robots through auction in order to achieve better balance of robots’ payload. This method introduces the process of online decision-making to improve the robustness, which is the main idea of distributed patrol algorithms.
Different from the previous centralized algorithms, Pasqualetti et al. 7 analysed the patrol problem according to three categories of graph structure. In the case of a chain graph, they proposed a centralized polynomial time algorithm to compute the optimal trajectory and designed a distributed procedure to approach the optimal trajectory. In the case of a tree or cyclic graph, they focused on optimization problems rather than distributed algorithms. They proposed a polynomial time algorithm for the optimal trajectory of a tree graph. They showed that the optimization problem for the graph with cyclic structure is NP-hard and proposed approximate algorithms accordingly. The issue of patrolling a set of vertices with different priorities is considered in the study by Pasqualetti et al. 16 A closed path through all vertices is constructed with graph-theoretic methods, and a Stop-Go team trajectory, which optimizes the weighted idleness, is presented for robots along the path.
Incipient research of distributed patrol algorithms uses intuitive methods to guide individual robots towards left positions unvisited for some time, which are discussed and compared in the studies by Portugal and Rocha, 14 Machado et al. 17 and Almeida et al. 18 Task allocation, auction mechanism and game theory have also been used for distributed patrolling. 19 –21 In distributed algorithms, each robot is offered with proper autonomy without the usage of centralized planning, and the patrol routes are determined online to accommodate the possible changes over time. For example, the conscientious reactive (CR) algorithm chooses the next vertex to visit from neighbors of the current position, considering only the instantaneous idleness. Iocchi et al. 22 examined the performance of multi-robot patrol algorithms in a realistic simulator, Stage, investigated the impact of some realistic circumstances (e.g. conflicts or deadlocks between robots in narrow environments, robots with different velocities in coordinated cyclic patrolling) and demonstrated the necessity of online coordination for robust patrolling.
Portugal and Rocha 10 presented two distributed multi-robot patrol algorithms using Bayesian-based mathematical formalism, named greedy Bayesian strategy (GBS) and state exchange Bayesian strategy (SEBS). The GBS drives each robot to maximize the local benefit (the instantaneous idleness divided by estimated time of movement) without negotiation with other robots. Furthermore, the SEBS enables the robot to consider the impact of other robots in the decision process, by sharing intention with robots around. The utility function is equivalent to the local benefit multiplied by a factor of intention. Both realistic simulations and real robot experiments are presented in their work. Typically, the SEBS performs better than the GBS and preceding distributed algorithms, due to the decrease of conflicts between robots. But the performance of SEBS would be affected when the number of robots changes dynamically, as some parameters in the algorithm need to be determined based on the number of robots.
Generally speaking, the distributed algorithms are less efficient than the centralized algorithms, mainly because of conflicts between robots. Further research to promote the efficiency of distributed patrol is still needed. The algorithm SEBS 10 takes into account the intentions of robots in order to prevent robots from competing for the same region. The work presented in this article exploits similar ideas but reduces the dependence on specific parameters (e.g. the number of robots and the upper bound of idleness in the SEBS algorithm). Comparisons with the state-of-the-art algorithms using Stage simulator and experiments on real robots show that the proposed algorithm is efficient in patrolling. The fault tolerance and scalability are also tested under various conditions through simulations using Stage.
Problem formulation
As mentioned earlier, the patrol area is represented as an undirected graph G(V, E), in which
The graph G(V, E) can be extracted from the occupancy grid map or the geometrical map. A common method is to generate the Voronoi diagram to represent the skeleton of the map 23 and to form vertices at the junction of edges. 24 In this article, the graph is assumed to be obtained in advance and known by all patrol robots.
To evaluate the performance of different patrol algorithms, idleness, 10 also referred to as refresh time, 7 which represents the time interval between two consecutive visits to the same vertex, is introduced as a criterion.
The idleness of a vertex vi ∈ V is calculated whenever the vertex is visited by a robot. Suppose vertex vi is visited by a robot at time tk for the k-th time, the idleness is calculated as

where tk − 1 represents the previous time instant that the vertex was visited.
Consequently, the average idleness of vertex vi at time tk is updated as

where k is the number of visits to vertex vi until time tk. Obviously, this is a recursive expression and can be calculated step by step.
The average idleness of the graph G(V, E) can be calculated as

The average idleness of the graph is an important criterion to evaluate the performance of different patrol algorithms. Another important criterion is the maximum average idleness of all vertices in the graph, which is defined as
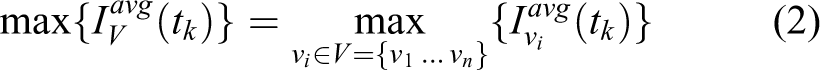
The patrol route of a robot can be expressed as an array of vertices to be visited sequentially. For a team of m robots, the set of patrol routes can be formed as

where xr is the patrol route of the r-th robot and can be expanded as

The patrol mission requires the set of patrol routes

The global objective function is to minimize the average idleness of the graph or the maximum average idleness of all vertices

In centralized algorithms, the patrol routes of all the robots are precalculated based on the static information about the environment and robots. In contrast, distributed algorithms enable each robot to choose patrol route dynamically and independently, according to the estimation of instantaneous information. The instantaneous idleness is the most commonly used information for online planning in distributed algorithms.
The instantaneous idleness

where tlast is the last time instant that the vertex was visited.
The last visit time tlast of every vertex in the graph G(V, E) is shared among robots using distributed communication mechanism. When a robot reaches a vertex, it publishes a message of arrival to inform other robots to update their records. In the process of determining the next vertex to visit, the instantaneous idleness can be obtained from current time minus last visit time.
Note that the published messages may be delayed or lost and be limited by the range of communication. So the information maintained by a robot may be inaccurate estimation of the instantaneous idleness, and robust distributed algorithms need to tolerate such deviation.
Distributed patrol algorithm based on expected idleness
The proposed algorithm uses a similar decision process like other distributed patrol algorithms. After the current vertex is reached, the robot chooses the next vertex to visit from neighbors of the current vertex according to specific criteria. The algorithm is reactive rather than cognitive, because the robot only determines the next vertex instead of a path of several vertices, in order to cope with unforeseen situations while patrolling. Then, the robot publishes its next target vertex to notify other robots with the purpose of reducing conflicts (e.g. more than one robots move to the same vertex).
In the previous research, robots only share their next target vertex to avoid conflicts without considering their expected time of arrival. But conflicts occur mainly when robots approach the same vertex within a short period of time. In this article, the effect of time constraint is considered for the cooperation between robots. A reactive algorithm concerned with expected time is proposed and named as expected reactive (ER) algorithm .
In the proposed algorithm, the expected time of arrival is estimated by each robot and shared with other robots. Then, the expected idleness of vertex is calculated on the basis of collected information and used in the decision process. Meanwhile, the estimation of travel time is utilized to replace path length as the cost function, so as to adapt to different velocities of robots.
ER algorithm
Suppose the r-th robot reaches vertex vr,k at time t. The robot publishes the message of arrival (vr,k,t) to inform other robots to update their records of last visit time tlast. Then, the robot needs to decide the target vertex to visit next.
Each robot maintains the set Sints that contains the target vertices of other robots and corresponding expected time of arrival. At the beginning of the decision process, the set Sints is updated to filter out outdated intention information, which may cause by faults of communication or robot.
The robot computes the utilities of visiting all the adjacent vertices and chooses the maximum as the next target vertex. For an adjacent vertex

where vel(r) is the estimation of average velocity of the r-th robot, which can be revised while patrolling, and

where
The expected time of arrival at vertex vi is estimated according to the current time t and the travel time Δt, as
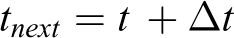
The expected idleness is used instead of the instantaneous idleness to evaluate the urgency of visiting the vertex. If the vertex vi belongs to the set Sints, which means the vertex is expected to be visited by another robot at time texp, the expected idleness is calculated as

Otherwise, the calculation of expected idleness is similar to instantaneous idleness as

where tlast is the last time that the vertex was visited.
The travel time Δt is used instead of the path length

For each of the adjacent vertex
After the robot determines its next target vertex, it publishes a message of intention
The process of the ER algorithm is reviewed in algorithm 1. This algorithm is executed on each robot, respectively, and the decision process of each robot is asynchronous and independent of each other. The cooperation between robots can be achieved through the messages of arrival and intention, whose structures are tuples

Discussion
The meaning of the utility function U(vi) is discussed in this section.
If the vertex
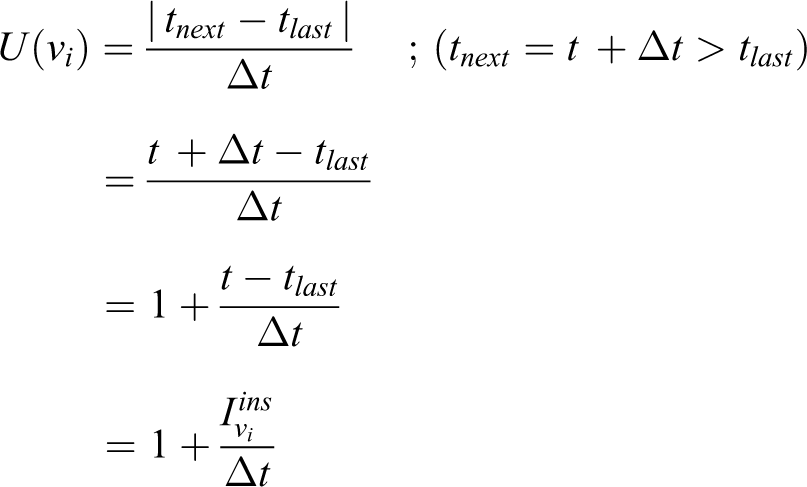
which signifies that the utility function is equal to one plus the instantaneous idleness divided by travel time. Maximizing the utility function means to find vertex left unvisited for a long time and also can be reached quickly.
If the vertex
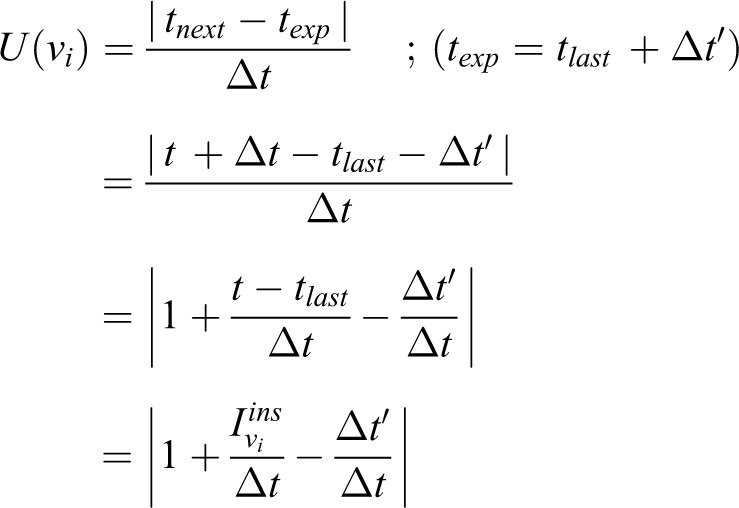
where Δt′ is the travel time of another robot moving to vertex vi. The absolute value is taken in the utility function, because texp may be greater than tnext, which means the robot may arrive at vertex vi earlier than other robots. The intention of other robots visiting vertex vi introduces a penalty term in the utility function, so as to decrease the utility of competing for the same vertex. In this case, the robot tends to choose other free vertex or vertex with larger time interval between arrivals, so as to decrease the occurrence of conflicts between robots.
Experiments
Both simulation experiments and real robot experiments are used to verify the validity and applicability of the proposed algorithm in this article. Simulation experiments are implemented under the 2-D multi-robot simulator, Stage, 25 together with the Robot Operating System (ROS) environment. Three TurtleBot (http://www.turtlebot.com/) robots driven by ROS 26 are utilized to perform the patrol algorithm in a corridor environment. With the convenience brought by ROS, the code can run both on real and simulated robots by modifying a few configuration parameters (the code is available at https://github.com/Chuanbo/my_patrol_sim).
Simulation experiments
Stage simulates mobile robots with different kinematics models and sensors in a 2-D bitmapped environment. The simulated robot is differential drive with a maximum velocity of 0.3 m/s and carries a range sensor with 60° forward-facing horizontal field of view (detection range: 0–10 m)The configuration of the simulated robot is similar to that of the TurtleBot robot.
Two maps (reference from https://github.com/davidbsp/patrolling_sim) with different graph structures are used to evaluate the performance of related patrol algorithms, as shown in Figure 1. The graph information used for patrolling is obtained in advance and known by all the robots. The map cumberland is constructed from an indoor environment with 40 vertices and 44 edges. The map grid is a virtual environment with 25 vertices and 40 edges. The algebraic connectivity (the algebraic connectivity of a graph is the second smallest eigenvalue of the normalized Laplacian matrix, and it is greater than 0 for a connected graph) of cumberland and grid is 0.0109 and 0.1313, respectively, which means grid is better connected than cumberland.

Maps with different graph structures used in simulation experiments. (a) cumberland and (b) grid.
A monitoring program has been implemented with two purposes. First, it visualizes the state of robots and controls the start as well as stop of the simulation (Figure 2). Second, it listens to the publishing messages from patrolling robots to record the idleness information. The idleness of each vertex begins to be recorded since the second visit by a robot, so as to skip the transition period and reach the steady patrol state. The estimation of average velocity vel(r) is chosen to be 0.2 m/s in the simulation.Comparative simulations between the proposed algorithm –ER and several other patrol algorithms were conducted in the two maps with different numbers of robots (1, 4, 8, 12). The duration of the simulations is ranged from 1 h to 8 h according to the number of robots (about 30 visits per vertex), and each simulation was repeated three times. The related algorithms involve two distributed algorithms: SEBS,
10
CR
17
and a centralized partition (CP)-based algorithm. The CP-based algorithm uses program METIS (https://mathema.tician.de/software/pymetis)
13
to partition the graph and computes the local patrolling route with a greedy TSP solver (https://github.com/dmishin/tsp-solver). It should be noted that this centralized algorithm is not fully optimized, as the focus of this article is the distributed algorithm. The average idleness of the graph

The Stage simulator and the monitor with map cumberland. (a) The Stage simulator and (b) the monitor.
Simulation results in map cumberland.
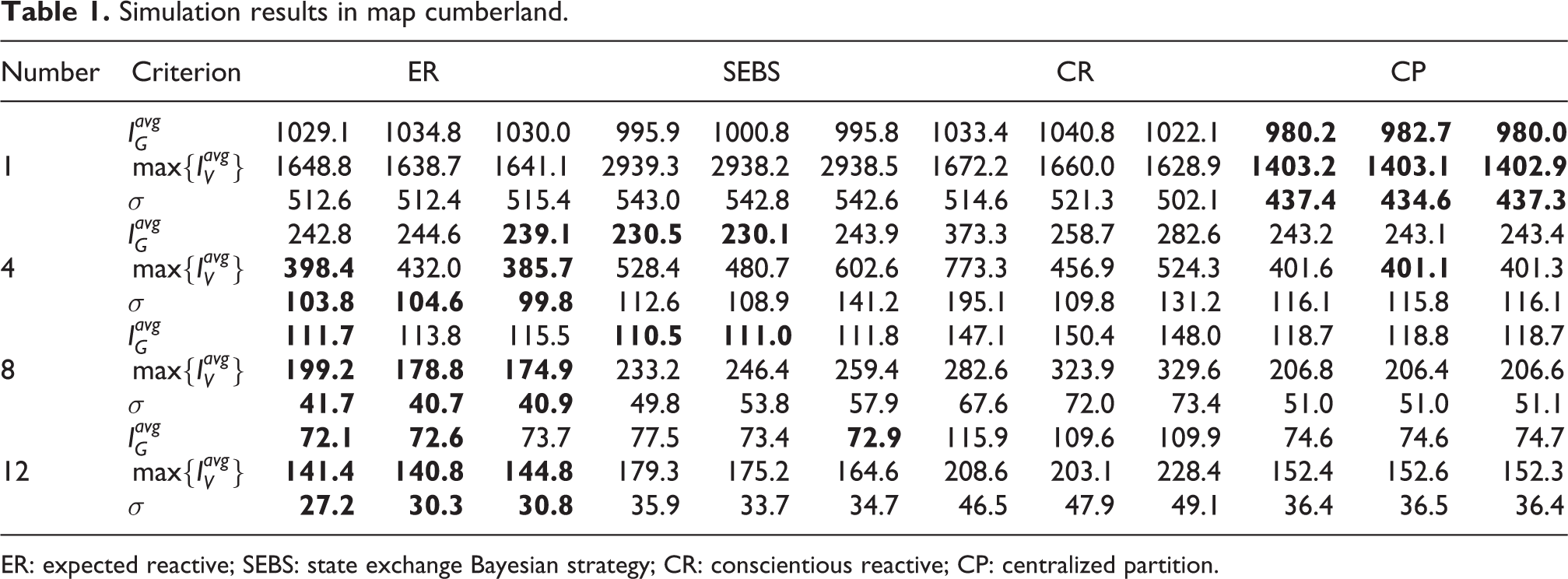
ER: expected reactive; SEBS: state exchange Bayesian strategy; CR: conscientious reactive; CP: centralized partition.
Simulation results in map grid.

ER: expected reactive; SEBS: state exchange Bayesian strategy; CR: conscientious reactive; CP: centralized partition.
In the case of single robot patrolling, the decision rule of ER is similar to that of SEBS (since the distribution function F(g) in SEBS is monotonically increasing,
10
the probabilistic model dose not affect the decision of choosing vertex with the largest utility function), but the constraint condition equation (5) of path length between vertices is different. Compared with SEBS, the proposed algorithm (ER) gives results with higher average idleness
The difference in performance of these algorithms appears gradually as the number of robots increases. In the case of multi-robot patrolling, ER and SEBS perform better than other distributed algorithms and can even have a comparable with the CP-based algorithm. In other distributed algorithms, conflicts between robots increase with the number of robots. The conflict, which means several robots approach the same region within a short period of time in patrolling, would decrease the efficiency of multi-robot cooperation, as the robot has to avoid collision from each other. In ER and SEBS, conflicts between robots could be reduced by considering the intentions of robots. As a result of graph partition, conflicts can also be avoided in CP.
The speed-up measurement 10,27 is introduced to analyse the scalability of different algorithms and can be calculated as

where p(r) is the performance for r robots measured by average idleness

The speed-up of different algorithms (a) in map cumberland and (b) in map grid.
The results show that ER and SEBS scale well for the number of robots. The distributed characteristic of both algorithms offers the potential of fault tolerance. Compared with the SEBS, the ER reduces the dependence on specific parameters (e.g. parameter L, M and the number of robots R, in SEBS algorithm 10 ) and thus has better scalability for dynamically formed robot teams.
Robot experiments
The proposed algorithm in this article has been tested in a corridor environment with three TurtleBot robots (Figure 4). A graph with 13 vertices and 14 edges is extracted from the 29.50 × 11.35 m environment, as shown in Figure 5. Each TurtleBot runs its local ROS master for data collection and control of the robot. The lightweight communications and marshalling,
28
a library independent of ROS environment, is used to exchange relevant information between robots. The proposed algorithm (ER) is used in the software layer of each robot to determine the patrol route independently and sequentially.The monitoring program used in simulation is also used in real robot experiments. The average idleness of the graph

TurtleBot robots used in the experiments.

The corridor environment for robot experiments.
Experiment results in map corridor.

In order to verify the convergence of idleness during patrolling, the average value and the maximum value of the instantaneous idleness (defined in equation (4)) are recorded every second and plotted as Figure 6. As the initial idleness is set to 0 for all vertices, there exists a transition period before the average instantaneous idleness

The instantaneous idleness along time. (a) one robot and (b) three robots.
Simulation tests about scalability and fault tolerance
In order to further analyse the scalability and fault tolerance of distributed patrol algorithms, more simulation experiments with the Stage simulator were conducted due to the convenience in configuring different test conditions.
The impact of robot failures
The fault tolerance of distributed algorithms is brought by the autonomy of every robot and the redundancy of the robot team. The robot team can be dynamically formed which means robots may join or withdraw during patrolling. This feature is tested through simulations for algorithm ER and SEBS.
Four robots were placed in map grid and began patrolling at time 50 s. A robot withdrew from patrolling at time 350 s and rejoined at time 650 s. In order to describe the evolution of the system status, the average value and the maximum value of the instantaneous idleness (defined in equation (4)) are recorded every second and plotted as Figure 7. As the initial idleness is set to 0 for all vertices, there exists a transition period before the idleness reaches stability within a certain scope. After a robot quit, the idleness rose to a higher level, but the patrolling team remained functional with the robots left (the idleness of every vertex remained within a limited scope). Furthermore, the idleness fell back to normal soon after the stopped robot rejoined the team. So it can be seen that both ER and SEBS are robust to robot failures and tolerate the robot to join or withdraw during patrolling.

The instantaneous idleness along time with robot failures. (a) ER and (b) SEBS. ER: expected reactive; SEBS: state exchange Bayesian strategy.
The impact of unreliable communications
In the previous experiments, communication between robots is assumed to be reliable, which means the robot can receive all messages sent between each other. But in practice, this is not always the case. Messages between robots may be lost or delayed because of unreliable communications and may even be confined to local interactions because of restrictions on communication range.
Comparative simulations on different error rates of communication were conducted in map grid with eight robots for algorithm ER and SEBS. In the simulations, the robot would ignore the received message with a certain probability: 0, 25, 50 and 75%, so as to simulate different error rates. Each simulation lasted 1 h (about 30 visits per vertex) and was repeated three times. The average idleness of the graph
Performance with different error rates of communication.
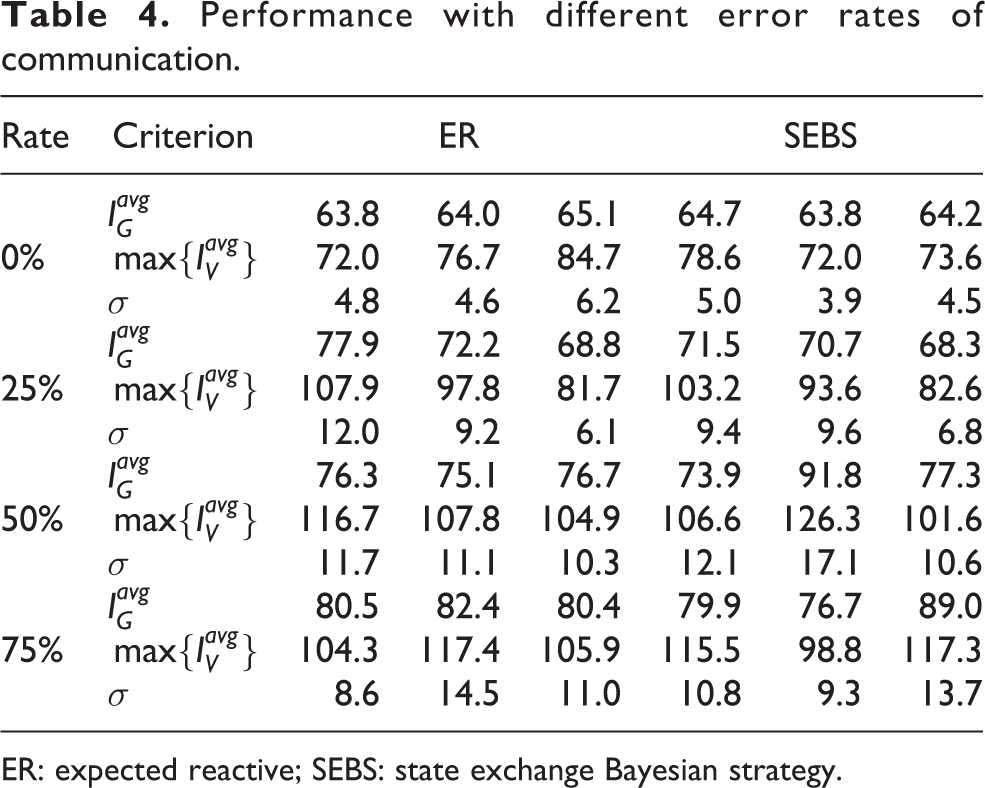
ER: expected reactive; SEBS: state exchange Bayesian strategy.
Similar to the preceding configuration, comparative simulations on the time delay of communication were conducted as well. The difference is that the robot would wait for a certain time: (0 s, 5 s, 10 s and 15 s) before processing the received message in order to simulate the time delay. Note that the time required by a robot to move between two adjacent vertices in map grid is about 20 s. The simulation results are shown in Table 5. The delay in message delivery reduces the performance of the distributed algorithms. But the performance degradation is only 9% when the delay is 5, which means these algorithms could tolerate moderate communication delay and still perform well.
Performance with time delay of communication.
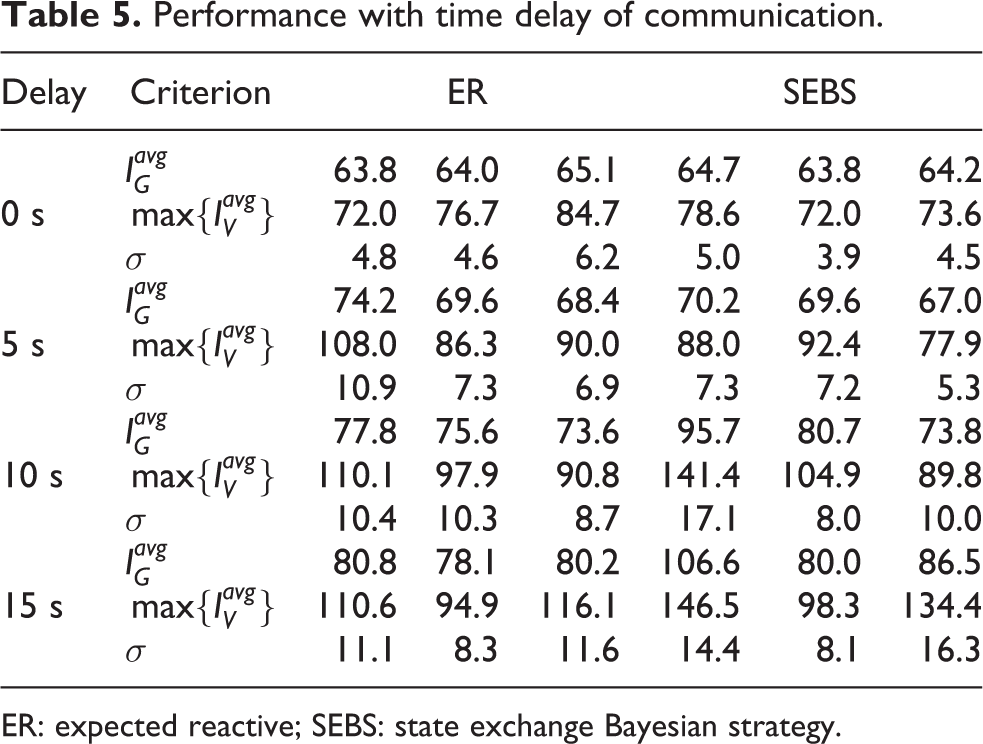
ER: expected reactive; SEBS: state exchange Bayesian strategy.
Simulations about the restriction on communication range were conducted in map grid with eight robots for algorithm ER and SEBS. In the simulations, the robot would only receive messages from robots whose distance to the robot is less than 12 m, so as to permit only local communication between robots within two edges in the graph. Since the robot makes decisions and publishes messages at the location of vertex in the graph, it is difficult to avoid conflicts when the communication range is less than two edges. But for purposes of comparison, the simulations with a smaller communication range – 6 m (one edge in the graph) – were also conducted. Each simulation lasted 1 h (about 30 visits per vertex) and was repeated three times. The simulation results (
Performance with restriction on communication range.
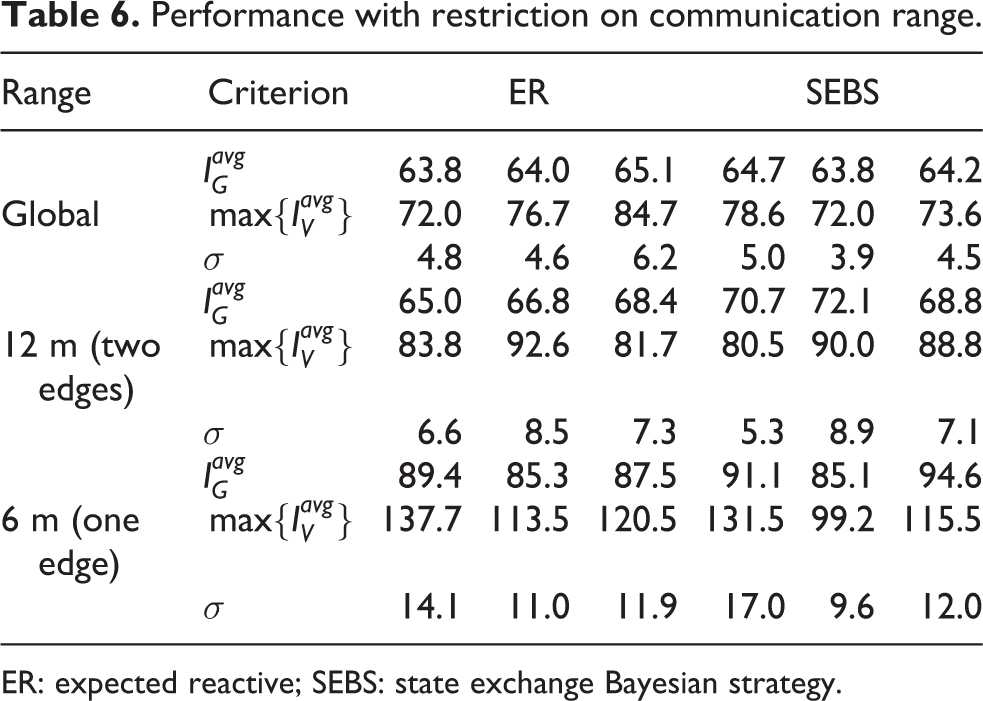
ER: expected reactive; SEBS: state exchange Bayesian strategy.
Conclusions
In this article, focusing on the frequency-based patrol with multi-robot, a distributed algorithm based on expected idleness is proposed. Using the information shared between robots, the expected idleness is estimated by each robot, which indicates the impact of other robots. In the decision process, the expectation about future status is considered to avoid potential conflicts between robots. The proposed ER algorithm is adaptive and distributed without the need for off-line planning or centralized control.
Comparisons with the state-of-the-art algorithms have been conducted in a realistic simulator, Stage, and shown the ER algorithm is efficient in patrolling which could even be comparable with centralized algorithms. More simulations have also been conducted to verify the scalability and fault tolerance. Experiments on real robots have further verified the validity and applicability of the ER algorithm. Further research to improve the algorithm for weighted idleness, which represents different priority of each vertex will be future works.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.