
Abstract
This work is focused on the problem of performing multi-robot patrolling for infrastructure security applications in order to protect a known environment at critical facilities. Thus, given a set of robots and a set of points of interest, the patrolling task consists of constantly visiting these points at irregular time intervals for security purposes. Current existing solutions for these types of applications are predictable and inflexible. Moreover, most of the previous work has tackled the patrolling problem with centralized and deterministic solutions and only few efforts have been made to integrate dynamic methods. Therefore, one of the main contributions of this work is the development of new dynamic and decentralized collaborative approaches in order to solve the aforementioned problem by implementing learning models from Game Theory. The model selected in this work that includes belief-based and reinforcement models as special cases is called Experience-Weighted Attraction. The problem has been defined using concepts of Graph Theory to represent the environment in order to work with such Game Theory techniques. Finally, the proposed methods have been evaluated experimentally by using a patrolling simulator. The results obtained have been compared with previous available approaches.
1. Introduction
Domains, where distributed surveillance, inspection or control are required, are candidates for being secured by performing patrolling tasks, usually by walking throughout at regular intervals (Abate, 1996), (Almeida et al., 2004). Currently, security system solutions are mostly predictable and inflexible. Additionally, since they are controlled by human operators, their performance can be affected by limitations such as boredom, distraction, or fatigue. Furthermore, in some environments, people must deal with hazardous conditions. As a consequence, it is important to improve the security elements used in these types of systems, which assist human beings in dangerous scenarios such as mine clearing or search and rescue operations. They are then able to perform other type of high level tasks, i.e., monitoring the system from a safe location (Oates et al., 2009). Recently, new research efforts have arisen trying to solve some challenges related to security tasks automation by using mobile robots (Everett, 2003). Thus, mobile robots aim to perform some useful task that a human either cannot, or would prefer not to do. Moreover, the robot should hopefully do it better, cheaper, safer, and more reliably. Security systems that utilize mobile robots in these types of applications have a great deal of advantages, i.e., they do not experience human limitations. However, some tasks are too complex that a single robot cannot achieve good results, especially in the presence of uncertainties, incomplete information, distributed control, and so forth. To overcome these challenges, Multi-Robot Systems can be used. They are characterized as a set of homogeneous or heterogeneous robots operating in the same environment using cooperative behaviors (Farinelli et al., 2004).
In this paper, new collaborative multi-robot approaches for infrastructure security applications at critical facilities are explored. The work is focused on area patrol, i.e., the activity of going throughout an area. Thus, given a set of robots and a set of points of interest, the patrolling problem consists of constantly visiting these points at irregular time intervals for security purposes. This problem has been formulated using concepts of Graph Theory to represent an environment where nodes stand for specific location of interest and edges for possible paths. By using this representation, each path has a cost that represents the time required to go from one node to another. The main advantage of this representation is its application. It can be easily used in other domains, i.e., computer networks, distributed coverage, and so forth. Additionally, there is a wide variety of problems that may be reformulated as particular patrolling task such as cleaning or surveillance. Since the patrolling problem seeks to maximize the number of visits to each node in a given environment, a good patrolling strategy must reduce the time lag between two visits to the same location (Chevaleyre, 2004).
The main contributions of this work are summarized as follows: An analysis of the behavior of game theory models in the multi-robot patrolling problem context is presented. A dynamic and distributed solution has been developed in order to solve the aforementioned problem. A novel decision-making rule has been defined. This rule attempts to allow robot dispersion, i.e., at each point of interest, each robot chooses a different available set of actions. A demonstration of how multiple robot interaction arises with the definition of multiple games at each point of interest has been defied. Finally, a detailed study of the behavior of the implemented model parameters has been described.
The rest of this paper is organized as follows. Section 2 briefly describes related work. Section 3 gives definitions of game theory and introduces the problem. Section 4 shows the implemented models in order to solve the patrolling problem. Section 5 presents the evaluation and experimental results. Finally, section 6 summarizes the obtained results.
2. Related work
The multi-robot patrolling problem has received much attention in recent years, specially in works that develop algorithms to coordinate decision-making among robots, (Portugal and Rocha, 2011). These works have implemented different principles such as reinforcement learning (Santana et al., 2004); negotiations methods (Hwang, 2009); swarm optimization (Glad and Buffet, 2009); cycle and partitioning strategies (Chevaleyre, 2004); and adaptive solutions (Sempé and Drogoul, 2003). A description of all of them can be found on a recent survey by (Portugal and Rocha, 2011). Beyond this survey, the multi-robot patrolling problem was tackled in (Ahmadi and Stone, 2006). In that work, the problem was called Continuous Area Sweeping, which is solved with a partitioning area method. Moreover, in (Aguirre et al., 2011), the multi-robot patrolling is applied to patrol national borders. In that work, elements of game theory as well as Monte Carlo simulation are used to solve the problem via genetic algorithms. Another work that utilizes game theory principles is described in (An et al., 2012). In that work, solutions to solve competitive or zero-sum games for the protection of critical infrastructure via Stackelberg Games are presented.
Among all these works, three of them are directly related with this work. The pioneer work in the multi-robot patrolling problem was carried out by (Machado et al., 2003). In that work, authors defined an evaluation criterion based on idleness. Idleness is the time that a place remains unvisited. Thus, Total Idleness is defined as the average of the idleness of all places of a given environment. Since this criterion is widely used in literature, it was used to measure the performance of the methods proposed in this work. Moreover, the problem of generating a patrol path inside a target area was tackled in (Elmaliach et al., 2007). The algorithm applied to generate this patrol path is called Cycle and it guarantees that each point is covered with the same optimal frequency. The solution presented in that work uses Spanning Tree Coverage method to find a minimal Hamilton path of minimal costs. Once a path is obtained, robots are uniformly distributed along this path and follow the same patrol route over and over. Thus, uniform frequency of the multi-robot patrolling task is achieved as long as one robot continues working properly. Moreover, authors present criteria based on frequency optimization in order to evaluate multi-robot patrolling algorithms. Finally, in (Portugal and Rocha, 2010) is presented an algorithm called MPS. Such an algorithm divides the environment into regions with the same dimension by using a balanced graph partitioning approach. Each of these regions is assigned to a robot that follows a local patrolling route. The procedure to obtain this patrolling route mainly seeks Euler and Hamilton circuits and paths. However, if such circuits and paths do not exist, the procedure seeks longest paths and Non-Hamiltonian cycles. Non-Hamiltonian cycles are selected only when they have at least half of the vertices of a graph; if not, the patrolling route remains the longest path. Since the longest path and the Non-Hamiltonian cycle do not contain all vertices of the graph, the procedure includes such vertices to complete the patrolling route. Then, ultimately inverse path procedure is used to return to the starting vertex of the route when is required.
Previous literature has demonstrated the effectiveness of methods that implement solutions based on cycles and paths (Chevaleyre, 2004). The good performance of these approaches could be explained by their centralized and explicit coordinator scheme, (Almeida et al., 2004). However, a centralized solution has several disadvantages such as lack of scalability in the number of places to protect and susceptibility to single-point failure, due to its unique, and hence vulnerable, control point. In addition, these approaches are deterministic, and therefore not suitable for security purposes due to their predictability.
The present work differs from others on the manner in which the patrolling problem was solved by implementing learning models from Game Theory. The theory of learning in games defines equilibrium as the result of dynamic adjustment processes in which players interact for optimality over time in repeated normal-form games. Thus, they compute their myopic best response based on the accumulated experience achieved by tracking previous plays history of other players. The learning model selected in this work to patrol throughout an environment was proposed by Camerer and is called Experience-Weighted Attraction (Camerer, 1999). Implementing such adaptive models allows developing dynamic and distributed solutions similar to (Santana et al., 2004) in contrast to several literature works.
3. Concepts from game theory
A brief overview of concepts as well as some definitions of game theory (Fudenberg, 1998) are given in order to clarify the description in the following sections. In this work, an abstract representation of the environment as an undirected weighted graph G has been adopted. This graph is an ordered pair consisting of a set E (G) of edges and a set N (G) of nodes. Each node is a special point of interest that needs to be observed in search of intruders, but it is assumed that such observation is instantaneous. Each edge represents a path by using a number corresponding to the cost proportional to its length.
Thus, given such graph and a set of robots, the patrolling task consists of visiting at each time step as many nodes as possible in order to minimize the time lag between two visits at the same node. Therefore, each node not only is an environment point of interest to be inspected, but also a point where interaction among agents arises, i.e., each robot in graph node n ϵ N (G) must select, based on other robots selections, an appropriate action in order to choose the next node to visit. Taking into account this interaction, normal-form games at each graph node n ϵ N (G) have been defined.
A finite set M of robots i = 1,…,n.
A finite set A = A1×…×An, where Ai={a1i,…,aik} is a finite set of actions for robot i = 1,…,n. Each vector
A finite set S = S1×…×Sn, where Si={si1,…,ski} is a finite set of strategies for robot i = 1,…,n. Each vector
A payoff function
Therefore, πi (s) is the payoff of robot i when strategy profile sis chosen.
In this implementation, each node n ϵ N(G) has a fixed number of normal-form games which depends on the edges connected to it. At time step zero, the robots are randomly positioned on the set N(G).
Thus, at every time step, the robot i ϵ M reaches a node n ϵ N(G) and plays its corresponding normal-form game Γ. As a consequence, the robot chooses its individual strategy
A manner to represent a game Γ is through the use of a n × n matrix payoff game in which each cell of this matrix indicates a strategy profile and contains the outcome or mixed strategy payoffs of the game when such profile is selected. Such outcome take the form C(x,y) = (π1,…,πn),x,y = 1,…,n where the entry πi is the payoff of robot i ϵ M

where Pr(aiji) is the probability that action ji will be played by robot i ϵ M.
Thus, the robots that interact in these types of games choose an action that maximize its expected payoff considering the actions selected by all other robots. This is called best response and it leads to the central solution concept of game theory, the Nash equilibrium. From now on, the robots other than robot i ϵ M are specified by -i = {(1,…,i - 1,i + 1,…,n)ϵM}. Moreover, the strategy profile without the strategy of robot i ϵ M is defined by

Equilibrium if, for all robots i ϵ M, siji is a best response to s−i.
In the games played in this implementation, the robots do not have conflicting interests and their sole challenge is to coordinate on actions that are maximally beneficial to all. These types of games are called team games.
Finally, in order to visit as many nodes of a graph as possible, a set of robots must disperse throughout the environment. Based on this requirement, the payoffs are defined as follow: let τi(sj−1) be the times that robots other than robot i ϵ M select the strategy j ϵ {1,…,k}, where sj−1 = {(s1j,…,sji-1, sji+1,…,snj)}. Thus, the payoff for robot i ϵ M playing such strategy is defined as πi (sij,sj−i) = |M| - τi(sj−i). Therefore, the payoff is low when several robots choose the same strategy. Henceforth, at each time step that a robot i ϵ M reaches a node n ϵ N(G),plays a normal-form game Γ against -i ϵ M, chooses an available action of its set of actions Ai and goes to the next node n ϵ N(G).
4. Experience-weighted attraction learning model
In the Experience-Weighted Attraction or EWA learning model each strategy siji ϵ Si has a numerical value called attraction, which specifies the probability of choosing that strategy. Each attraction has an initial value, which is updated each period through the use of two rules that update two variables. The first variable
Thus, the first rule updates the level of attraction according to

The decay rate φ depreciates previous attraction
The second rule updates the amount of experience according to

where (1 - v)· φ is the rate of decay for experience, which measures the impact of previous experience. Moreover, the parameter v specifies how quickly robot i ϵ M lock in to a strategy. When v = 0, attractions are weighted averages of past attractions and payoffs. Past attractions are weighted by
The initial attraction level of each strategy siji ϵ Si is denoted by
Thus, an EWA robot i ϵ M using these rules shapes a set of attractions which specify preference for a specific strategy siji ϵ Si. Such preference is given as a choice probability Piji in time step t + 1 through a logistic stochastic response function defined by

where λ is the response sensitivity. With λ = 0 the choice is stochastic while λ = ∞ is best response.
Beyond these rules, specific values of ψ(0),δ and ρ reduce this general model to special cases such as reinforcement and belief-based models.
4.1. Reinforcement Model
In the reinforcement model of EWA, every time step that a robot i ϵ M reaches a graph node n ϵ N(G), it performs three steps. In the first step, the robot selects one of the strategies available at such node. This selection is based on a logistic stochastic response function defined by
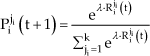
where λ is the response sensitivity. With λ = 0 the choice is stochastic, whereas λ = ∞ is best response. The response function Piji specifies the selection probability of the strategy siii
Each strategy siji is related to a reinforcement value Riji. When this reinforcement value is updated, its related strategy is reinforced. Thus, in the second step, once a strategy is selected, only this strategy is reinforced by previous received payoffs according to

As can be seen, this rule is the result of setting in the EWA model δ = 0, v = 1, and ψ(0) = 1, therefore ψ (t) = 1. This is the simplest form of cumulative reinforcement. When δ = 0, v = 0 and ψ(0)= 1/(1 - φ), EWA model becomes a form of averaged reinforcement governed by
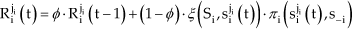
where reinforcements are averages of previous attractions and incremental reinforcement. The initial reinforcement value of the strategies available at each node is defined by
Finally, in the last step, the i robot i ϵ M communicates the strategy selected to the other robots, so that they update the reinforcement value of the strategy selected by the robot i ϵ M in the noden ϵ N(G). Thus, similar to the behavior of attractions in EWA model, in the reinforcement case, each robot shapes the reinforcement of each strategy by utilizing the aforementioned rules. The Algorithm 1 describe the three steps accomplished in this model.
4.2. Belief-Based Model
Belief-based models start with the premise that each robot i ϵ M identifies that it is playing a game Γ with other robots, and it forms beliefs about what these robots will play in the future based on its past observation. Then, it attempts to define dynamic processes that lead to a Nash Equilibrium by choosing a best response strategy that maximizes its expected payoff to its beliefs.
There are different iterative learning rules to form beliefs. One widely used model of learning is the process of Weighted Fictitious Play and its variants, such as Cournot Best-Response Dynamics, which looks back only one play, as opposed to Fictitious Play which looks back the t most recent plays, (Brown, 1951). At each time step in the model of Weighted Fictitious Play, each robot i ϵ M chooses its strategies to maximize its expected payoff given its prediction about the distribution over strategies of other robots at that time step. Therefore, Weighted Fictitious Play is an instance of model-based learning in which a robot maintains beliefs Bit(s−i) about the strategies of other robots s−i ϵ S−i. In the prediction of this learning rule, the initial prior belief that robot i ϵ M assigns to strategies s−i of robots -i ϵ M is governed by
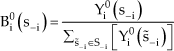
where

The initial weight assigned is different for each strategy. This assignation permits that the updates performed by 9 do not lead to weights with the same value, which allows to avoid selection problems.
The belief that robot i ϵ M assigns to the robots -i ϵ M playing s−i at time step t is given by

The updating rule formulated by 10 can be defined in terms of previous-period beliefs by

In 11, Bit(s−i) is expressed in terms of previous-period beliefs, similar to EWA model with previous-period attractions and reinforcement model with previous-period reinforcements.
Following this updating rule, most recent and previous-period beliefs are updated φ times. When φ = 0 Weighted Fictitious Play becomes Cournot Best-Response Dynamics, and when φ = 1 it becomes Fictitious Play. Once beliefs are updated, expected payoff of robot i ϵ M in period t,Eit (siji) is defined according to

As in the case of beliefs, expected payoffs can be expressed as a function of previous-period expected payoffs which yields

Finally, the best response of the robot i ϵ M in Weighted Fictitious Play is given by

5. Experiments and result
In order to evaluate and compare this implementation with other methods, a patrolling simulator developed from pioneers works (Machado et al., 2003) has been used.
Thus, the first experiments aim at analyzing the behavior of these models with different values of their parameters, namely, for EWA model φ, δ and v, for reinforcement model φ and v, and for belief-based model φ. In order to do so, the map shown in figure 1(a) was used. Where unfilled small circles stand for nodes or points of interest, lines stand for edges of a graph or paths that robots use to move throughout the map. Filled big circles stand for robots patrolling such map. In this set of experiments, a group of 20 robots started at node number 22 and patrol until each node had been visited 256 times.

Maps used in order to evaluate performance of each algorithm
Figure 2 shows the performance of the models evaluated. At each plot, color intensity, coordinates, and box plots represent the total idleness. Thus, figure 2(a) shows the behavior of EWA model using six slice planes at the axis v through a volumetric data created with values of 0 ≤ v, δ ≤ 1.0 As it can be seen, the best behavior was obtained with the slice at v = 02. In this slice, the volumetric data shows that the idleness is, in general, approximately 2.5. The region around the points δ = 0.7 and φ = 0.9 presents the lowest idleness, whereas the idleness value hardly ever reaches values of 2.55. Figure 2(b) shows a surface expressing the behavior of the reinforcement model for values of 0 ≤ v, φ, δ ≤ 1.0. It shows that the bigger the value of v and the lower the value of φ, the better the performance of the model. Indeed, the surface has a minimum at coordinate (v = 0.9, φ = 0.3). In general, v = 0.9 achieves the best behavior, which indicates that the form of cumulative reinforcement performs better than the average reinforcement. In the form of cumulative reinforcement, each strategy has a level of reinforcement, which is incremented cumulatively by received payoffs. Finally, figure 2(c) shows the performance of the belief-based model for values of 0.0 ≤ φ ≤ 1.0 by means of using box plots. The size of each box represents the spread of the data, whereas the symbols “+”, called outliers, are values distant from the rest of the data. For security purpose, it is not suitable to have several outliers because they represent nodes with high idleness, which indicates points of weakness. In general, the nature of the belief-based model is almost the same in all cases. When φ = 0.1 the median, 2.29, of the data is the smallest. Even though, the smallest median does not mean better performance, the size of the box when φ = 0.1 is lower than the other options. This size indicates that the total idleness of all nodes is similar. Moreover, there are only two outliers, at nodes 28 and 40 with total idleness of 5.22 and 5.61, respectively. Although, there are options with two or less outliers, their values are bigger. Based on this information, values of v = 0.2,φ = 0.9 and δ = 0.7 for EWA model; v = 0.9 and φ = 0.3 for reinforcement model, and φ = 0.1 for belief-model model were selected.
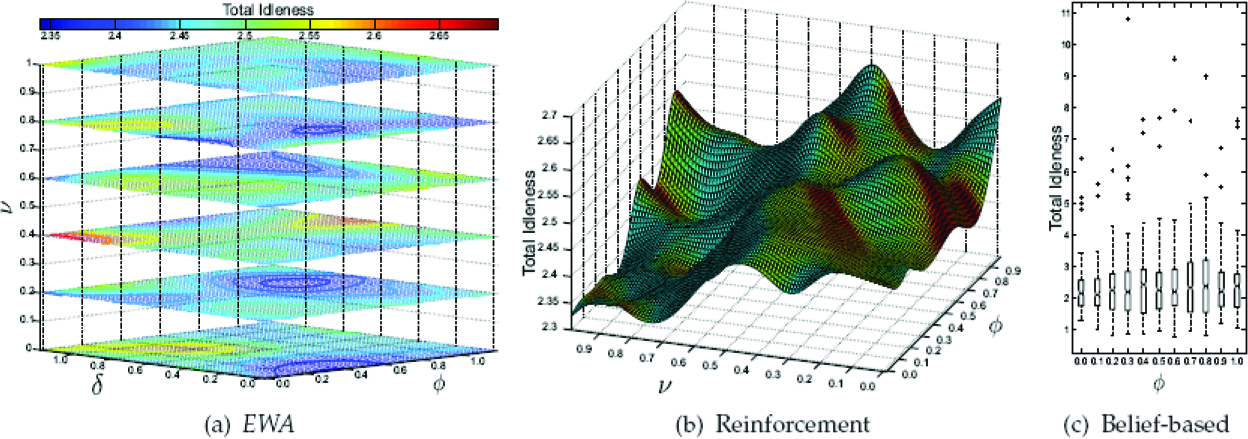
Performance of the models evaluated utilizing the map of figure 1(a).
Once all parameters of the models were determined, the next experiments aimed at evaluating the models in comparison to other methods available in the Patrolling Simulator, namely, the Cycle algorithm and the MPS algorithm, which were described in section 2. For these experiments, all the maps of figure 1 were used. For each map, sets M of 6, 8, 10, 15, 20, 25, 30 robots were evaluated. This combination generates 21 cases of study to experiment. Each experiment consists of visiting all nodes 256 times. At time t = 0, each robot was placed randomly at one node of the map.
Table 1 shows the results of these experiments for Strongly Connected, Maze and Grid maps. In these results, the lower the size of μ, the better the performance of the algorithm and the lower the value of σ, the lower the variance. As it can be observed, if the value of M increases, the performance of all of the algorithms is better. Although this behavior seems obvious, if the coordination among robots is not appropriate, bigger values of M will not lead to better performance of the algorithms. Therefore, this nature is due to the suitable coordination.
Performance of the algorithms with a different size of
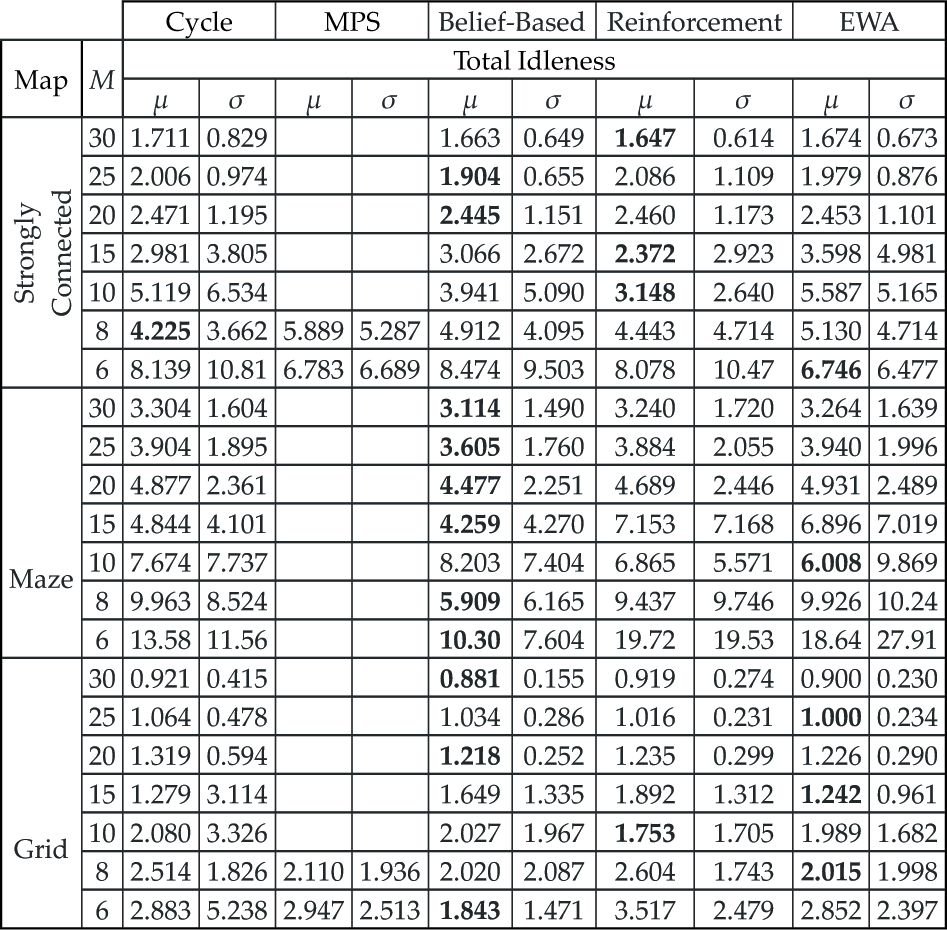
Apart from having a more suitable architecture for security purposes, in as many as 95% of cases one of the methods presented in this work improves Cycle algorithm. The only case where Cycle algorithm performed better was in Strongly Connected map with M = 8. Most notably, these results indicate that regardless of which map is used, in all cases, at least one of the methods presented in this work improves MSP algorithm. Taking into account that both Cycle and MPS algorithms use a centralized and explicit coordinator scheme, this improvement in performance is significant. Finally, in 80% of cases MPS algorithm does not work due to partitioning problems. Portugal and Rocha (2010) describe the reasons of these problems. It is worth noting that the proposed solution does not have these problems.
6. Conclusions
Several dynamic and distributed collaborative multi-robot approaches for security applications at critical facilities have been developed. Thus, a team of robots endowed with patrolling behaviors based on learning models from game theory as well as a thorough study of such models in the context of the patrolling problem has been presented. As shown in section 5, a significant improvement in performance was obtained by using the proposed methods with respect to Cycle and MPS algorithms. Moreover, the distributed characteristics of these models offer solutions with several advantages, such as scalability, modularity, and incremental expandability. Furthermore, the behavior of the robots patrolling that are using the techniques of this work is non-deterministic, which is suitable for security applications due to the fact that intelligent intruders can learn patrolling paths, and based on this information, perform attacks to the protected system. The evaluation to support this claim is not part of the scope of this work. However, results in (Sak and Wainer, 2008) demonstrate that system protection based on not static solutions is less susceptible to be attacked.
Despite the good performance achieved with the models implemented, there are significant remaining questions for future research. Firstly, interference among robots arises when more than one robot utilizes the same edge. In order to avoid this interference, it is necessary to evaluate if the edge selected is used or not by other robots. Future research consisting of studying the behavior of these methods including such aspect is necessary. Secondly, the metric of the patrolling simulator to evaluate the performance of the algorithms only includes the idleness of each node, however it does not take into account if one edge connected to such node (in the case that it has more than one) is used or not. Thus, an interesting future research consisting of evaluating the behavior of the algorithms including such a restriction because it allows to have a more secure system. Finally, even though the expected payoff matrix defined has achieved suitable results, new definition matrices should be explored.
Footnotes
7. Acknowledgements
This work has been supported by the Robotics and Cybernetics Research Group at Technique University of Madrid (Spain), and funded under the projects “ROTOS: Multi-Robot system for outdoor infrastructures protection”, sponsored by Spain Ministry of Education and Science (DPI2010-17998), and the project ROBOCITY 2030 Project, sponsored by the Community of Madrid (S-0505/DPI/000235).