
Abstract
People detection and tracking is an essential capability for mobile robots in order to achieve natural human–robot interaction. In this article, a human detection and tracking system is designed and validated for mobile robots using color data with depth information RGB-depth (RGB-D) cameras. The whole framework is composed of human detection, tracking and re-identification. Firstly, ground points and ceiling planes are removed to reduce computation effort. A prior-knowledge guided random sample consensus fitting algorithm is used to detect the ground plane and ceiling points. All left points are projected onto the ground plane and subclusters are segmented for candidate detection. Meanshift clustering with an Epanechnikov kernel is conducted to partition different points into subclusters. We propose the new idea of spatial region of interest plan view maps which are employed to identify human candidates from point cloud subclusters. Here, a depth-weighted histogram is extracted online to feature a human candidate. Then, a particle filter algorithm is adopted to track the human’s motion. The integration of the depth-weighted histogram and particle filter provides a precise tool to track the motion of human objects. Finally, data association is set up to re-identify humans who are tracked. Extensive experiments are conducted to demonstrate the effectiveness and robustness of our human detection and tracking system.
Introduction
People detection and tracking is a necessary skill that a mobile robot possesses to achieve a natural and intuitive human–robot interaction (HRI). Understanding how people move through the scene is a key issue for decision-making for an autonomous mobile robot in crowded zones. Therefore, accurately detecting and tracking people from a mobile platform can help improve interaction effectively and efficiently. In this article, we tackle the problem of detecting and tracking people using an Color data with depth information RGB-depth (RGB-D) camera mounted on a mobile robot. Our goal is to design a human detection and tracking system that can be adaptable for a wide range of applications of HRI.
Unfortunately, people detection and tracking in a real environment is extremely difficult. The first challenge is ascribed to non-rigid people’s poses, variant appearances, and cluttered occlusion. Another challenge is the complexity of unpredicted motion patterns. What’s more, human detection and tracking from a mobile platform introduces additional challenges, such as dynamic background, temporal constraints, and view-angle changes. The dynamic background leads to the failure of traditional segmentation-based and motion-based perception approaches; temporal constraints cause mobile robots react to human movements and view-angle changes introduce additional noise.
To cope with existing problems, much work has been investigated. To our knowledge, human detection and tracking can be implemented through vision-based techniques and multisensor fused strategies, such as laser range finders, sonar, and Lidar. In most vision-based detection and tracking systems, a particle feature, such as the face, 1 the skin, 2 the upper body or torso, 3 or the entire body, 4 is widely used to detect and track people, or multiple different visual cues are integrated to build a more robust and adaptable tracker. 5,6,7 Additionally, multisensor based human detection and tacking systems take full advantage of different sensors to augment accuracy and reliability. Laser-based leg detectors and face detectors are fused using a sequential implementation of an unscented Kalman Filter for robust detection and tracking. 8 An RGB-D camera, laser, and thermal sensor are combined and mounted on a mobile robot, and a real-time particle filter system is implemented to merge the information provided by these sensors to realize a human following system. 9 Generally speaking, for humans that demonstrate unique characteristics, such as color, shape, texture, or motion, these humans’ attributes are extensively used in perception tasks for easy implementation and simplicity, and the integration of measurement from multisensors causes increasing implementation cost and augmenting system complexity. A detailed survey has been presented to investigate human perception methods for HRI. 10
Depth sensing technology assisted human detection and tracking systems take full advantage of three-dimensional (3D) point position and space geometric constraints, such as 3D-laser, 11 3D rotating Lidar, 12 stereo camera, 13,14 Time-of-Flight (ToF) camera, 15 and RGB-D camera. 6,16 3D visual signals can provide the distance information of a human with whom a robot is interacting. With the assistance of such 3D spatial information, the robot knows what the surrounding environment looks like.
Beymer and Knolige 17 had employed plan view maps for people tracking using a stereo camera placed at the height of people’s knees. People are detected and tracked by their legs using an occupancy map. However, where the lower body is occluded, the method of detection and tracking of legs is invalid. Two different plan view maps, named occupancy map and height map, were employed to create the likelihood map for person candidates 7 using stereo cameras. Kalman filtering and a maximum likelihood estimate (MLE) were adopted to determine which of the person candidates detected correspond to the person being tracked. However, the noisy raw point cloud is projected on the ground plane so that a high value not only increases the computational effort and memory resources used, but also decreases the precision.
Our work is inspired by the concept of plan view maps to complete the task of human detection and tracking, using a unique integration of new ideas and established techniques. In our implementation, not all 3D space points are projected into plan view maps. We downsample and filter the noisy raw point cloud to increase the precision and save computational effort.
In this article, a human detection and tracking system is designed and validated for mobile robots. A prior-knowledge guided random sample consensus (RANSAC) fitting algorithm is employed to detect the ground plane, and the ground points and ceiling plane are removed to decrease noise. Here, we propose a new candidate detection strategy with a modified plan view map generation method. Instead of projecting raw points onto the ground plane, refined preprocessed points are projected onto the ground plane and subclusters are segmented for candidate detection. Meanshift clustering is employed to segment the point cloud into different subclusters. We suggest a special spatial region of interest plan view map from subclusters to increase precision and save computational effort. Two different plan view maps, named occupancy map and height map, are employed to identify human candidates from point cloud subclusters. A height range is set to avoid not relevant computing time. Meanwhile, color is a powerful cue that can be used to distinguish the tracked persons from others. Here, a depth-weighted histogram is extracted online to feature a human candidate. Then, a particle filter algorithm is adopted to track the human’s motion. The integration of the depth-weighted histogram and particle filter provide a precise tool to track the motion of human objects. Finally, data association is set up to re-identify humans which are tracked.
System overview
Our human detection and tracking framework is described in Figure 1, which clarifies our methodology by breaking it down into logical blocks. The whole system takes 3D point cloud sequences as input, and outputs human tracking information. The 3D point cloud sequence is acquired from a RGB-D camera mounted on a mobile robot. The major procedures are listed as follows.

Overview of our multiple human detection and tracking system. Starting with the input Point Cloud Data (PCD) point cloud, the system: (1) detects the ground and ceiling planes and removes them; meanwhile, a prior-knowledge guided random sample consensus (RANSAC) is used to fit the ground plane; (2) projects all points onto the ground plane, and applies a meanshift clustering algorithm to segment candidates for generating plan view maps; (3) associates motion and detection data for multiple human object tracking. Our tracking results are demonstrated using a bounding box in which a human is tracked.
Ground detection and ceiling removal
Implementation of our multiple person perception system involves projection of 3D points onto the ground plane. When the input 3D point cloud is preprocessed, a prior-knowledge guided RANSAC fitting algorithm is adopted to detect the ground plane. Meanwhile, ceiling planes, which are assumed at a higher height, are detected and removed.
Human detection using modified plan view maps generation
We first project preprocessed cloud points onto the ground plane, setting vertical height
Multiple person tracking
We use a depth-weighted histogram to feature a human candidate, and implement a particle filter algorithm to efficiently handle detected human candidates. The Global Nearest Neighbor approach is utilized to make data association with human candidates.
Contributions
Our human perception method combines a set of novel techniques to create a system that is capable of tracking multiple human targets and rejecting nonhuman objects from a mobile robot. What’s more, our perception system is robust to occlusion, illustration changes, and unpredicted motion patterns. The main contributions of this article include: the introduction of a new idea using meanshift clustering candidate segmentation for plan view map generation from a RGB-D camera, which allows us to avoid using the noisy point cloud for computationally expensive plan view map generation, augment detection precision, and speed up to achieve real-time performance; the use of point cloud preprocessing, where planes, cylinders, or other regular objects are removed to lower the false positive ratio, followed by tracking-by-detection over a 3D point cloud that associates motion tracking and object detection which can extensively be applied to HRI.
The remainder of the article is organized as follows. The second section overviews the related literature of human perception. The third section depicts our approaches to detect and track multiple humans in preprocessed 3D point clouds. Experimental results are presented in the fourth section. Finally, the conclusion of this article is given in the fifth section.
Related work
To achieve natural human perception in crowded human zones, a large number of human detection and tracking approaches have been investigated. Using a consumer-grade camera is cost-efficient, so it is widely adopted in human detection and tracking. To detect and track people in the real world from a moving camera, great efforts have been made. A probabilistic framework was proposed 5 to detect multiple people in a crowded scene by combining multiple detectors. By combining multiple detectors, the Reversible Jump Markov Chain Monte Carlo particle filtering method was adopted to find maximum a posteriori probability (MAP) of a posterior probability to track people in a single coherent framework. Mekonnen et al. 18 designed a cooperative perception system made up of wall mounted cameras and a mobile robot to perceive passers-by and obtain their positions and trajectories. Jia et al. 19 presented a visual human tracking approach based on a meanshift algorithm. In their implementation, color and texture histograms were integrated into a meanshift tracker under the double-layer locating mechanism. The Histogram of Oriented Gradient (HOG), 4 also known as the Dalal–Triggs detector, was introduced to localize people utilizing a sliding window and support vector machines (SVM) to discriminate people from others. A drawback of using a single camera is that occlusion causes a false negative.
What’s more, a legTracker 20 was proposed to detect and track human legs by the application of the support vector data description scheme using measurement from a laser range finder. In addition, networks of laser range finders were calibrated to determine the positions of pedestrians, which enabled pedestrian tracking within 11 cm accuracy. 21 But these laser range finder based human detection and tracking systems provide only partial depth information about a single plane.
3D sensors, such as a 3D-laser, 3D rotating Lidar, stereo camera, ToF camera, and RGB-D camera, can provide 3D position information and spatial geometric constraints of a human. With the assistance of such 3D spatial information, the robot knows how people move about in the surrounding environment. Depth sensing technology assisted human detection and tracking systems have also been extensively discussed.
3D-lasers. Spinello et al.
11
proposed a novel approach for pedestrian detection in a 3D range data based on supervised learning techniques to create a bank of classifiers for different height levels of the human body. Benedek
12
provided a real-time 3D human surveillance system using a rotating multibeam (RMB) Lidar through robust probabilistic background-foreground classification of the recorded RMB-Lidar point clouds. Subsequently, short- and long-term object assignment were combined to detect and track pedestrians. Biometric features derived from the range and intensity channels of the Lidar data flow were extracted for online person re-identification.
Stereo vision. Bajracharya et al.
14
implemented an integrated system for human detection, localization, and tracking from a moving vehicle, using range data from stereo vision. The scene was segmented into different regions of interest, and shape features were extracted and used to classify pedestrians. Two different plan view maps, named occupancy map and height map, were employed to create the likelihood map for person candidates.
7
Kalman filtering and a MLE were adopted to determine which of the human candidates detected correspond to the person being tracked. Muñoz-Salinas et al.
22
also employed an occupancy map and height map to register the volume and height of the objects. In addition, a confidence map was adopted to fuse the information captured by multiple cameras. Then, a particle filter algorithm was proposed for tracking people in the fused plan view map. But stereo vision, which involves disparity computation and triangulation computation, is time consuming, so it is not suitable for real time mobile robot operation.
ToF cameras. Brscic et al.
23
offered a person tracking system in large public spaces using multiple overhead mounted 3D ToF sensors. Head and shoulder shape features were extracted to estimate people’s positions and orientation, and a set of sequential importance resampling particle filters were used to combine estimations from multiple sensors for large area smooth and continuous tracking. However, this system consisted of multiple stationary sensors distributed in the environment and was not suitable for a mobile robot.
RGB-D cameras. A 3D-laser, 3D rotating Lidar, stereo camera, and ToF camera are usually several tens of times more expensive than the available RGB-D camera, such as Microsoft Kinect, ASUS Xtion Pro, and PrimeSense PrimeSensor. Consumer-graded RGB-D cameras can provide both RGB information and range data. Several human detection and tracking systems based on RGB-D sensing technology have also been extensively investigated. Hu et al.
24
developed a human tracking system based on a novel 3D meanshift algorithm on a RGB-D camera for mobile robots. The depth information was added into the target model and the candidate model as a kernel weighting function to predict the human trajectory and to take preemptive action. Zhang et al.
16
introduced a novel depth of interest concept to identify human candidates for detection and represented a candidate tracking algorithm with a decision directed acyclic graph. Munaro and Menegatti
6
presented a fast multiple person tracking system designed to be applied on mobile service robots. They introduced a novel depth-based sub-clustering method to detect people and trained an online learning appearance-based classifier with motion, color, and HOG joint likelihood to track identity switches (ID-SW). Gritti et al.
25
designed a Kinect-based human detection and tracking system from small-footprint ground robots for clustering indoor environments. Leg-like objects were segmented and classified as either human legs or distractors from a low-lying viewpoint. Wei et al.
26
validated a vision system using a 3D range camera for scene segmentation and pedestrian classification. Pedestrians and non-pedestrians are classified by the Fourier and GIST descriptor with a Radial basis function (RBF) SVM. Liu et al.
27
proposed a human detection and tracking algorithm in 3D space using a discriminative combination of a histogram of height difference and a joint histogram of color and height.
Human detection and tracking in a 3D point cloud addresses commonly encountered issues, for example, humans which are occluded from other people because of interaction or other objects. In this article, we extend the concept of plan view maps in people detection. Unlike in Muñoz-Salinas et al., 7 plan view maps are generated through a unique new idea of a spatial region of interest in this research, which is able to save computational effort and improve detection precision. Meanwhile, a depth-weighted histogram 24 is employed to feature a human candidate.
Human detection and tracking strategy
In this article, our goal is to design a human detection and tracking system, allowing a mobile robot to efficiently interact with humans. Our system is based on the methodology of tracking-by-detection. We begin to depict the procedures of 3D point cloud processing, and a prior-knowledge guided RANSAC ground fitting and removal, accompanied by the detection and removal of ceiling planes. Then, plane view maps are generated to identify human candidates from a spatial region of interest. We discuss how to use a depth-weighted histogram combined with particle filtering to feature a candidate for motion tracking. Finally, we describe data association to track multiple people.
Candidate segmentation
Our human detection approach is based on a highly probable interval of human or object instances in the 3D point cloud depth distribution. A human candidate is identified by finding a local maximum in the depth distribution and selecting a depth interval centered at that distribution by the observation that any object in a point cloud includes a set of points with similar depth, or several spatially adjacent sets. In our system, we reduce complicated spatially adjacent sets into a two-dimensional (2D) ground plane for candidate detection.
To efficiently generate candidates from a 3D point cloud, the following procedures are conducted at each input point cloud frame. Firstly, a VoxelGrid filter is used to downsample the 3D point cloud to a small size. In addition, a pass through filtering is implemented along the depth dimension according to Kinect’s characteristics, by selecting all points within each frame, to save computation consumption. Secondly, for each point, we compute the mean distance from it to all its neighbors. By assuming that the resulted distribution is Gaussian with a mean and a standard deviation, all points whose mean distances are outside an interval defined by the global distances mean and standard deviation can be considered as outliers and trimmed from the dataset. To preserve the 3D point clusters that contain only human candidates, a cascade of nonhuman object removal is used to reject candidates that contain only nonhuman objects. Mainly, height limits are used to remove relevant nonhuman objects. A simple nonhuman objects remover is first applied to reject the majority of candidates before more complex detection is performed. In our system, planes, cylinders, or other regular objects are removed to lower the false positive ratio, see Figure 2(c).
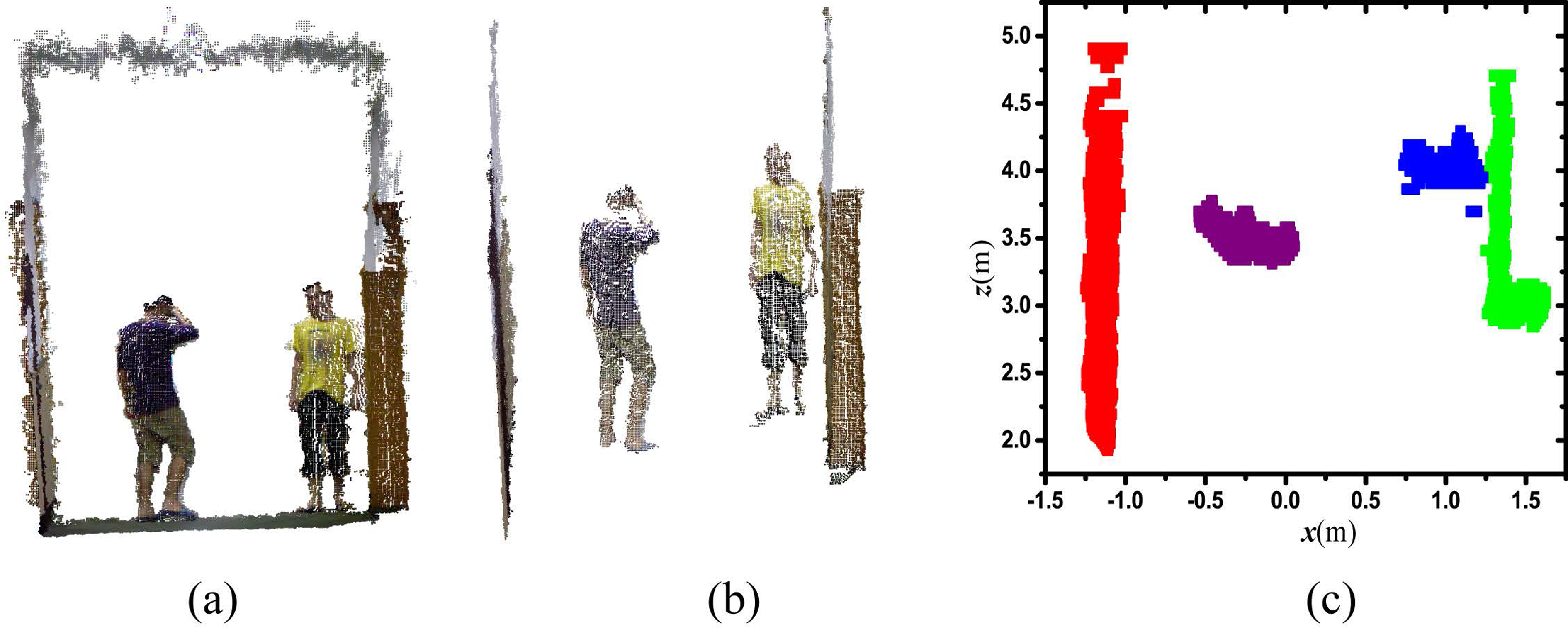
(a) Point cloud with downsample filtering, visualized in MATLAB. (b) Ground removal using a y-coordinate values distribution histogram. (c) Ground view map of objects. Objects are segmented using clustering, where points are projected on the plane.
In this article, we assume that humans and robots exist and operate in an indoor environment and on a flat ground plane, and that a ceiling plane is available and viewable at a higher height when robots move across the room. Since our RGB-D camera is installed on a mobile robot in a horizontal plane, points on the ground can be extracted using a y-direction height histogram to perform this task. Here, we use a RANSAC method to estimate the ground plane parameters
In Muñoz-Salinas et al., 7 two different plan view maps, named occupancy map O and height map H, were employed to denote human candidates. However, the noisy raw point cloud from stereo vision is projected on the ground plane so that a high value not only increases the computational effort and memory resource used, but also decreases the precision. In this research, we propose a spatial region of interest plan view map to increase precision. A meanshift clustering algorithm is implemented to segment human candidates on the ground plane, see Figure 2(c). We also use the occupancy map to register in each region R(x,y) the amount of points within a point cloud subcluster that are projected in it. It is calculated as in equation (1)

The occupancy map denotes that the human candidates are projected by a value proportional to the surface which occupies the spatial scale in a real scene. Points which are away farther from the camera, that is to say, are corresponding to large surfaces and vice versa. The focal length of the camera is a scale factor that compensates the difference in size of the objects observed in the point cloud.
In addition, the height map of the segmented region,

Then the occupancy map of the region,
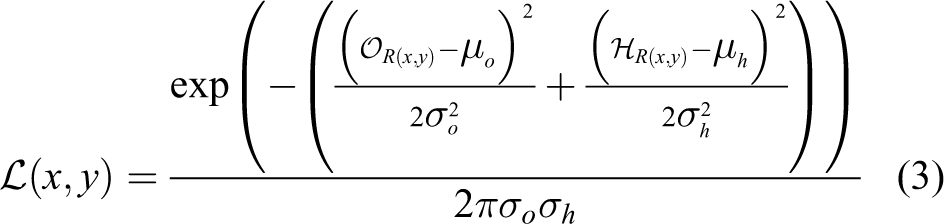
In equation (3), the parameters μo and σo represent the expected mean and standard deviation of
Motion tracking
The RGB-D camera provides RGB data with point cloud data. Depending on the RGB-D camera model, we can acquire the 3D position of the tracked human in the camera coordinates. The target and candidate model are represented by the color pdf which is distributed on the 2D image plane in meanshift tracking.
24
In this article, we adopt a depth-weighted histogram to feature a human candidate. We consider the center of the target model
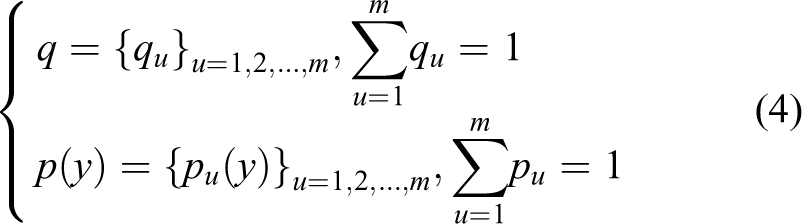
A rectangular region with N pixels is selected in the image as the target. Let

where the kernel function k is a 2D normal function and s is a one-dimensional normal function. lavg is the average depth in the central area of the region. The bandwidth hl depends on the maximum movement of the target between successive frames in the camera coordinate. The depth kernel function s can reduce the influence of the background with a similar color to the tracking object. δ is the Kronecher delta function. For the condition

As the modified target model with depth kernel function, the modified target candidate with Nc pixels and bandwidth h is

where

A particle filter is exploited to predict people’s positions and velocities along the two ground plane axes (x,y).
Data association
To perform data association from motion and detection, the Global Nearest Neighbor approach 28 (solved with the Munkres algorithm) is adopted. The cost matrix derives from the evaluation where it is used as a two-term joint likelihood for every target-detection couple. For motion tracking, we employ the Mahalanobis distance between tracker i and detector j, given in equation (9)

where Sk(i) is the covariance matrix of tracker i that is provided by a particle filter tracker and

The values of the Mahalanobis distance between tracker i and detector j are used to represent people’s positions and velocities in ground plane coordinates. Given a tracker i and a detector j, the observation vector
Then, the joint likelihood for every target-detection couple is to be maximized as in equation (11)

Actually, we minimize the log-likelihood instead of equation (11) for simpler algebra, given in equation (12)
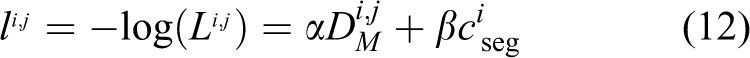
where
Our human detection and tracking skeleton is illustrated in Figure 3. Human detection, tracking, and re-identification are handled by a combination of plan view map generation, integration of depth-weighted histogram and particle filter, and searching of a MLE of joint likelihood.
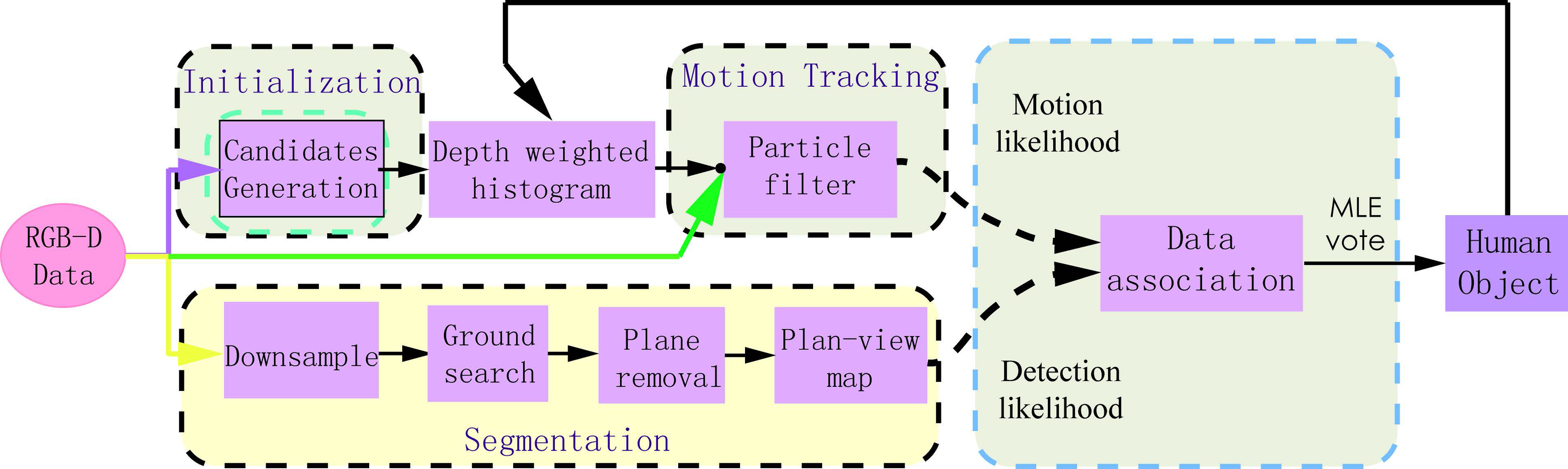
Illustration of our human tracking skeleton. Motion likelihood and detection likelihood are associated through the Global Nearest Neighbor approach. This framework is also simultaneously used to handle tracked humans, and to perform human identification.
Experimental analysis
Robotic platform
The experiment has been implemented with the mobile robot represented in Figure 4. It consists of an xPartner IN-R platform equipped with a Kinect RGB-D camera. We perform experiments using our human perception system which is implemented with C++ with OpenCV 29 and point cloud library (PCL). 30 Meanwhile, MATLAB is used to enable data visualization. We create a dataset that is captured suitable for the task of multiple human detection and tracking in our laboratory using our xPartner IN-R platform as shown in Figure 4. In the human candidate detection module, the parameters of height threshold are set manually: the minimum height threshold hmin = 0.8 m, and the maximum height threshold hmax = 2.3 m.

RGB-D camera mounted a IN-R mobile robot.
Test with indoor datasets
Analysis and evaluation
We collected a variety of datasets to evaluate the performance of our human perception system. The dataset was recorded with a Microsoft Kinect Xbox 360 camera in our indoor library environment. Our dataset considers two scenarios with different difficulties. Each sample in our dataset is a sequence of 3D point clouds that are captured with a frame rate at 30 fps and saved as PCL PCD format. Each 3D point cloud contains 307,200 points, corresponding to 640 × 480 color images, and each point has its coordinates in the RGB-D camera frame and red green blue alpha (RGBA) values.
We first analyze the tracking results from our human perception system to demonstrate its effectiveness and robustness in challenging tracking tasks. For each detected and tracked human, a bounding box is drawn according to the point cloud spatial distribution of people. Different people are represented with different colored bounding boxes. Our tracking results with bounding boxes are illustrated in Figure 5.

Experimental bounding box. (a) Dataset 1: people move across in front of the robot and act with complicated postures. Meanwhile, mobile robot IN-R stays stationary. We place a carton, a cylinder, and water dispenser in the pedestrian zone. Lower bodies are occluded when people are behind obstacles. (b) Mobile robot IN-R navigates along a long corridor in the building. People perform complicated actions, involving human–human interaction, and targets leave and re-enter the robot’s field of view.
Clear multiple object tracking (MOT) metrics 31 are proposed to quantitatively evaluate MOT performance, which consists of three scores: MOT precision (MOTP), MOT accuracy (MOTA), and the number of ID-SW. In this article, as shown in Table 1, we unitize MOTP distance to measure the error between the tracking results and the actual targets, and evaluate the ability of the tracking module to estimate target positions and keep consistent trajectories. In addition, the MOTA score combines the errors that are made by the people perception system, in terms of false negatives and false positives. A false negative occurs when a human is annotated in ground truth, but not detected by the perception system. This usually happens for people that are severely occluded, or on the boundary of the camera’s field of view, or filtered by the pass through filter according to the Kinect’s characteristics. A false positive occurs when the candidate that is detected as a human does not have a match with any annotated humans in ground truth. In our system, this happens with the nonhuman objects that have a similar height, size, shape, and surface property to a human. To establish ground truth, we extract axis aligned bounding boxes of the human candidate cloud indices. The evaluation result is shown in Figure 6.
Evaluation results of our human detection and tracking system using the clear multiple object tracking (MOT) metrics.

MOTA: multiple object tracking accuracy; FN: false negatives; FP: false positives; ID-SW: identity switches.
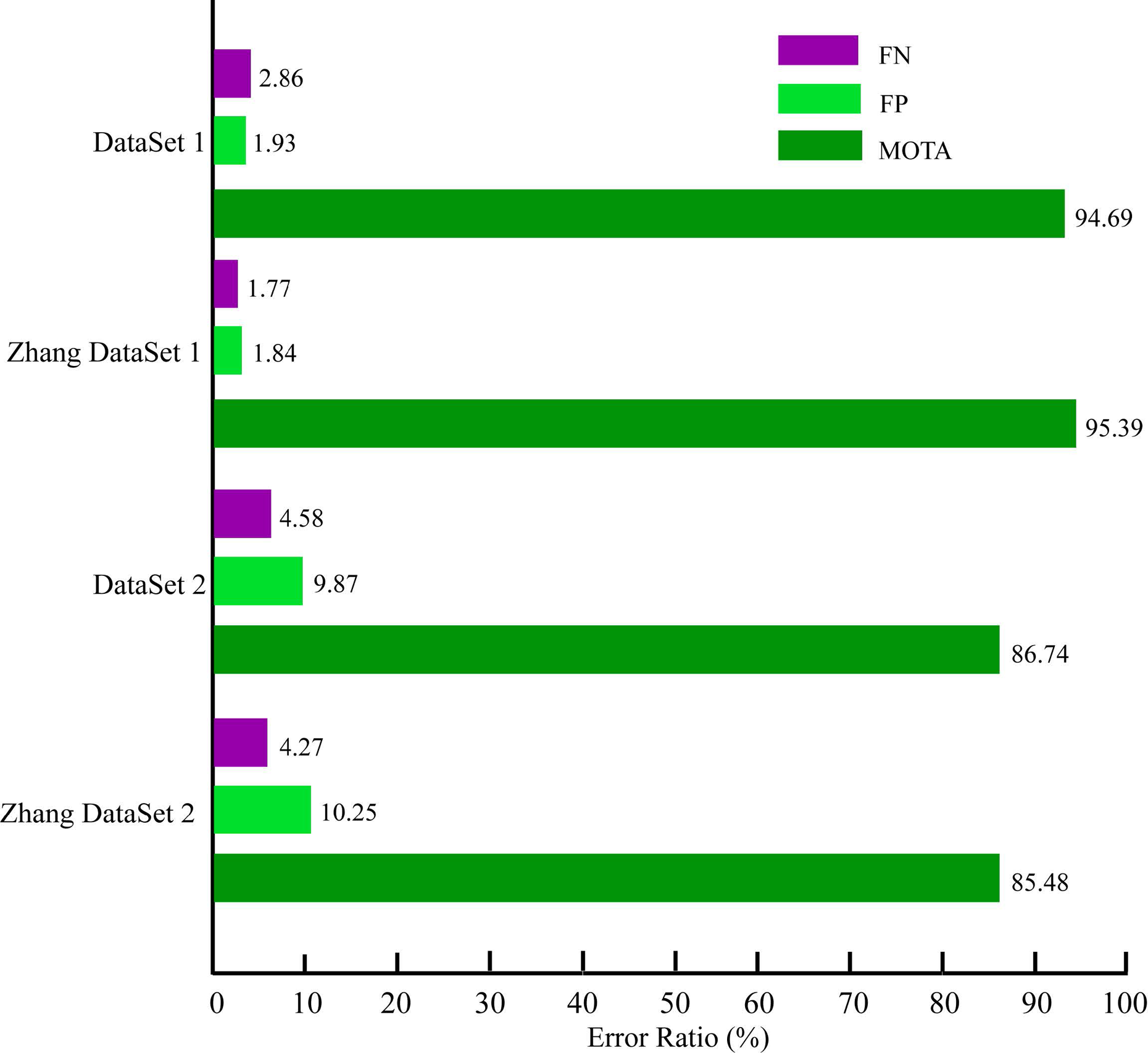
Error ratios (i.e. multiple object tracking accuracy (MOTA), false negatives (FN) and false positives (FP)) over our 3D-based approach.
The experiments were repeated five times for our dataset collected from our tracking platform. We use the label P to indicate a tracked human. From the examination of the performance of our human detection and tracking system, several observations should be emphasized.
First, our system has a low number of ID-SW. This property enables our tracking system to discriminate humans, which is essential for achieving natural HRI in a human–robot team. This highlighted ID-SW ratio is accomplished by combining the following ideas and techniques. Combination of multifilter, depth range, and height range results in avoiding computationally expensive plan view map generation and speeding up to achieve real-time performance; furthermore, the removal of regular nonhuman objects reduces computation complexity and augments our tracking system precision. The spatial depth information is added to a traditional color appearance. The depth-weighted histogram is extracted online to feature a highly accurate appearance model. Global Nearest Neighbor based data association from motion and detection enables our tracking system to re-identify people re-entering.
Second, our human detection and tracking system does not perform as well with Dataset 1, because people not only are often occluded from humans when they are interacting, but also remain the boundary of acquired point cloud.
Finally, an important trade-off between precision and computation complexity must be taken into account for the choice of depth range and height range. The higher these values are, the faster the algorithm is because fewer points have to be processed.
Our human candidate detection is inspired by plan view maps. 7 Muñoz-Salinas et al. used a stereo camera to acquire point cloud data, accompanied by RGB information. From their experimental results, we have get similar good results. Furthermore, compared with 16 , our goal and system is similar that we all want to detect and track people using a RGB-D camera from mobile robots. But they also do not publish their datasets. Compared with their 3D multiple human perception system, our work get very similar results.
In the human candidate’s module, the parameters of the height threshold are set manually: the minimum height threshold hmin = 0.8 m, and the maximum height threshold hmax = 2.3 m. Meanwhile, the parameters μo, σo, μh, and σh are selected in this work to detect and track adult people. Under these considerations, our method is limited to adult human detection and tracking. We looked up several 3D datasets from the PCL official site (http://pointclouds.org/media) and other sites, and we list ViDRILO (http://www.rovit.ua.es/dataset/vidrilo/), RGB-D Object Dataset (http://rgbd-dataset.cs.washington.edu/index.html), NYU Depth Datasets (http://cs.nyu.edu/silberman/datasets/), and RGB-D SLAM Dataset 32 here. Datasets, obtained from the list above and the PCL official site, are mainly for use in place classification and object recognition, and SLAM and 3D reconstruction, respectively. So our goal is different.
Limitations
In this article, we assume that pedestrians stand upright and a height range is set to avoid not relevant computing time. Moreover, a pass through filter is implemented along the depth dimension according to Kinect’s characteristics by selecting all points within each frame, to save computation consumption. These procedures would reject human objects, who squat down below the lower limit or who are out of range of the pass through filter, to result in a false negative. Thus, when human candidates are highly occluded by obstacles or other candidates, a false negative will occur.
Conclusion
Nowadays, the availability of consumer-grade RGB-D cameras allows mobile robots to observe their surroundings and perceive in dynamic 3D space. In this article, a human detection and tracking system is designed and validated in 3D space using RGB-D cameras mounted on an IN-R mobile robot. The whole framework is composed of human detection, tracking, and re-identification. But our human perception system consists of multiple submodules, where each submodule is designed to increase precision and save the computational effort of our system. The input point cloud from the RGB-D camera is downsampled with a VoxelGrid filter and a pass through filter according to the RGB-D camera’s characteristics. Ground and ceiling planes are removed from 3D points to reduce data size. A prior-knowledge guided RANSAC fitting algorithm is used to detect the ground plane, and all filtered points are projected onto the ground plane. A height range is set to avoid not relevant computing time. Then, point cloud subclusters are segmented for candidate detection using meanshift clustering. A new idea of spatial region of interest plan view maps, named occupancy map and height map, are employed to identify candidates from point cloud subclusters. Detection precision is augmented through the improved plan view maps. In the tracking module, a depth-weighted histogram is extracted online to feature a human candidate. Meanwhile, a particle filter algorithm is adopted to track a human’s motion. The integration of the depth-weighted histogram and particle filter allows us to track the motion of human objects precisely. Finally, data association is set up to re-identify humans which are tracked. Our proposed method was demonstrated in two challenging scenarios with complexity, including occlusion, robot motion, and people leaving the field of view, etc. Evaluation of our perception system is validated using clear MOT metrics showing both high precision and accuracy. Extensive experiments are conducted to demonstrate the effectiveness and robustness of our human tracking system.
The proposed human detection and tracking system is performed in an indoor environment that provides the mobile robot with the basic skills to interact with the people around. In this article, we assume that human candidates are detected and tracked on the ground plane. We can extend our work using a plan view map to build an occupied 3D surrounding column map from the 3D point cloud captured by RGB-D cameras for mobile robot navigation, as shown in Figure 2(c). This work can also be extended to build a human follower that accompanies him/her along the environment avoiding obstacles in the way. Future works will be focused on the development of these techniques.
Footnotes
Acknowledgements
The authors gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was partly supported by the National Natural Science Foundation for Distinguished Young Scholars (grant number 61525305), the National Natural Science Foundation of China (grant numbers 61233010, 61305106, 61573236), the Science and Technology Commission of Shanghai Municipality (grant number 14DZ1110900), the Shanghai Economic and Information Technology Commission Research Project (grant number Hu CXY-2013-27).