
Abstract
Scholars have proposed a cable-driven parallel robot (CDPR) with aerial and ground actuators, referred to as a cable-towed aerial platform (CTAP), to address the limited ability to withstand external forces of existing unmanned arrival vehicle (UAV)-based aerial platforms. To tackle practical problems (e.g., firefighting), a CTAP may need to perform motion planning in an environment with obstacles and communication failures. To this end, this article proposes an online decentralized planning approach based on multi-agent reinforcement learning (MARL) for a CTAP to achieve real-time motion planning in a communication-denied environment with obstacles. This article then defines the state and action spaces of a MARL-based planner. A reward function is designed for the MARL-based planning approach according to the widely used optimization-based planning approach. This study has successfully trained a MARL-based planner using this approach, and the important training techniques used in this study are reported. Statistical comparison of the MARL-based decentralized planner and an optimization-based centralized planner is conducted in simulation. The MARL-based and optimization-based planners are deployed to a CTAP prototype to address motion planning problems in the real world. Experimental results show that the MARL-based planner can achieve successful, decentralized, and online motion planning for a CTAP.
Keywords
Introduction
Efforts have long been underway to achieve efficient aerial manipulations, such as high-rise firefighting and aerial rescue. Aerial manipulations usually require a large workspace, even in a complex environment with obstacles, leading to challenges for aerial manipulation systems. To address aerial manipulations, researchers have proposed aerial platforms based on unmanned aerial vehicles (UAVs). 1
For instance, UAVs have been used for high-rise building firefighting, as shown in Figure 1.

UAV-based aerial platforms used for high-rise building firefighting.
To address the limited load capacity and the limited ability to withstand external forces of UAV-based aerial platforms, scholars have proposed the concept of a cable-driven parallel robot (CDPR) with aerial and ground actuators, 2 referred to as a cable-towed aerial platform (CTAP), as shown in Figure 2. A CTAP is a CDPR3–5 driven by several aerial and ground actuators via cables collaboratively. Researchers have addressed some problems of CTAPs, including static workspace, 2 energy efficiency, 6 and real-time reconfiguration planning. 7 To operate a CTAP in an environment with obstacles (e.g., buildings), it is important to plan the proper motion of aerial and ground actuators. Thus, the motion planning of a CTAP in an environment with obstacles is a critical problem.8,9

Process of the deployment of a cable-towed aerial platform for firefighting.
The motion planning of a CTAP in an environment with obstacles is challenging for several reasons. Firstly, the heterogeneous nature of a CTAP and the combination of aerial actuators, ground actuators, and multiple flexible and rigid bodies lead to a complex and high-dimension motion-planning problem. Secondly, a target position may be located at the back of a building where a CTAP cannot reach directly, forcing the motion planning of a CTAP to address obstacles for aerial actuators, the moving platform, and cables. Thirdly, a complex environment (e.g., firefighting) may have communication failures. 10 To address the motion planning of a CTAP, an effective motion planning approach is required.
Existing methods for multi-agent system planning can be broadly classified into centralized and decentralized planning approaches. 11 Researchers have studied centralized planning algorithms for systems similar to a CTAP. Gagliardini et al. 12 and Rasheed et al. 13 formulated the problems of reconfiguration planning and obstacle avoidance for reconfigurable CDPRs and developed optimization-based and search-based planning methods to solve these problems. A novel constrained path planning method has been proposed for a reconfigurable CDPR to achieve obstacle avoidance by simultaneously adjusting the cable anchor positions and cable lengths. 14 An adaptive sampling-based path planning method has been proposed for CDPRs to find collision-free trajectories in a dynamic environment. 15 Liu et al. 16 proposed a reconfiguration planning method based on reinforcement learning (RL), enabling reconfigurable CDPRs to avoid dynamic obstacles. Joyo et al. integrate twin delayed deep deterministic policy gradient (TD3) with a proportional-integral-derivative (PID) loop for reference tracking under tension constraints, demonstrating improved accuracy and stability and the practicality of deep policy gradients in multi-constraint settings. 17 It was shown that RL offers a promising direction for achieving real-time obstacle avoidance. Centralized planning involves a central planner generating the target trajectories, which are then sent to individual agents. However, the communication between the central planner and an agent may suffer from signal delays or communication failures. 10 A communication failure could result in the paralysis of the entire system.18,19
To address issues including communication failure, scholars have proposed decentralized planning methods, 20 consisting of optimization-based decentralized planning methods and heuristic-based decentralized planning methods. Alessandro et al. 21 proposed a heuristic algorithm to address collaboration problems in logistics scenarios. Harikumar et al. 11 employed both heuristic algorithms and an optimization-based multi-UAV search and dynamic formation control framework to search for targets in uncertain environments, such as forest firefighting. However, the time consumption of the optimization-based decentralized planning methods and heuristic-based decentralized planning methods 22 prevents the online planning of a CTAP.
The integration of learning-based approaches in motion planning has become a significant research trend.23,24 For instance, Ding et al. recently proposed a federated reinforcement learning framework for intelligent route planning in aerial–terrestrial networks,
25
which addresses privacy preservation and cross-environment knowledge sharing. While this line of work is not directly applicable to a CTAP—since the system involves tightly coupled aerial and ground actuators within a single physical platform rather than independent environments—it highlights the growing interest in distributed RL approaches for aerial–ground systems. To address online decentralized planning, researchers have turned their attention to multi-agent reinforcement learning (MARL).
26
The classic algorithms, such as multi-agent trust region policy optimization (MATRPO), multi-agent deep deterministic policy gradient (MADDPG), and their improved versions multi-agent proximal policy optimization (MAPPO) and multi-agent twin delayed deep deterministic policy gradient (MATD3), have all achieved excellent results in scenarios like multi-robot collaboration and intelligent transportation.
27
Recently, Gabler and Wollherr proposed a decentralized MARL framework grounded in best-response policies with hierarchical opponent modeling;
28
it surpasses MADDPG in benchmarks and mitigates combinatorial explosion in interactions. While highlighting decentralized decisions and opponent modeling, evaluations remain in generic domains rather than online planning on a CTAP. Several works have already applied MARL to multi-robot cooperative systems,
29
but these studies are mostly restricted to settings with few degrees of freedom and simplified dynamics. To this end, this article proposes an online decentralized planning approach based on MARL for a CTAP. The main contributions of this work can be summarized as follows.
This article proposes an online decentralized planning approach based on MARL for a CTAP to address path planning and obstacle avoidance in an environment with obstacles. The approach enables the multiple actuators of a CTAP to operate independently, in real time, and move the moving platform to a target position collectively in scenarios where communication is denied. This study applies the proposed online decentralized planning approach to a CTAP in simulation and in the real world and compares the proposed approach to a commonly used centralized optimization-based planning approach, aiming to verify the effectiveness of the proposed approach. The performance metrics including time consumption and path length achieved by the proposed approach compared to those of the centralized optimization-based planning approach are reported.
Compared with prior studies, this study applies multi-agent reinforcement learning to an aerial–ground cooperative system with higher degrees of freedom, achieving near-optimal planning results while maintaining real-time performance. Unlike single-agent reinforcement learning approaches, the proposed method remains effective under communication interruptions and exhibits stronger robustness to partial agent failures. In contrast to existing applications of multi-agent reinforcement learning, the target system of this study involves higher degrees of freedom and more complex dynamics, which further demonstrates the applicability and potential of the proposed approach in challenging cooperative control scenarios.
The remaining sections of this article are structured as follows. Section “Preliminaries” presents the preliminaries of this study, including the problem statement and the notation for a CTAP. Section “Problem formulation” formulates the motion planning of a CTAP as an optimization problem. Section “MARL-Based decentralized planning approach” proposes a decentralized motion planning approach based on MARL for a CTAP. Section “Experiments” conducts experiments in simulation and in the real world to demonstrate and verify the proposed MARL-based decentralized planning approach for a CTAP. Finally, Section “Conclusions” summarizes the article and suggests potential directions for future research.
Preliminaries
In this section, the problem statement and the notation for a CTAP in an environment with an obstacle are presented.
Problem statement
This article addresses the problem of online decentralized motion planning of a CTAP with a point-mass moving platform and both aerial and ground actuators in an environment with obstacles, motivated by the deployment of a CTAP for firefighting, as shown in Figure 2. Every aerial actuator connects to the moving platform through a fixed-length cable and every ground actuator connects to the moving platform through a variable-length cable. The positions of ground actuators are fixed. The CTAP is required to move the moving platform from an initial position to a target position. The desired velocity of each aerial actuator is required to be determined by an agent attached to the aerial actuator and the desired cable stretching velocity of ground actuators is required to be determined by an agent on the ground. The moving platform may move around an obstacle (e.g., a building). The position and velocity of the moving platform and aerial actuators, as well as the state of cables and the obstacle, can be observed, for instance, using visual sensors (e.g., cameras), inertial measurement units (IMUs), and encoders.
Notation for a CTAP
The notations for a CTAP with

Notations of a cable-towed aerial platform.
It is assumed that an obstacle is contained within a cuboid, since buildings are frequent obstacles in high-rise building firefighting. The center of the bottom surface of the cuboid is denoted as
Problem formulation
This section formulates the motion planning of a CTAP demonstrated in Section “Problem statement” as an optimization problem, inspired by Gagliardini et al.,
12
Rasheed et al.
13
The formulation provides a basis for the development of an online decentralized planning approach based on MARL and the baseline—a conventional centralized planning approach based on optimization.



The motion planning of a CTAP can be formulated as an optimization problem defined as





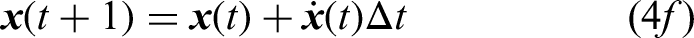

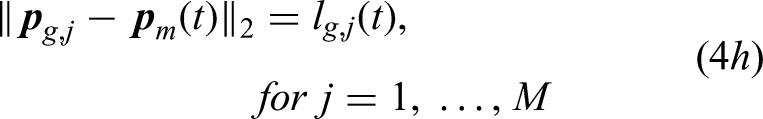
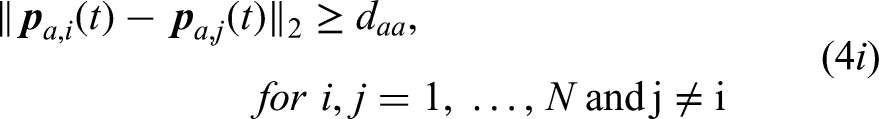




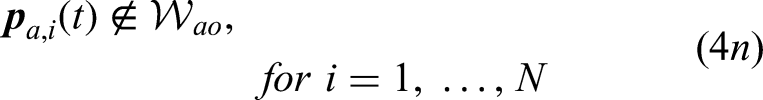

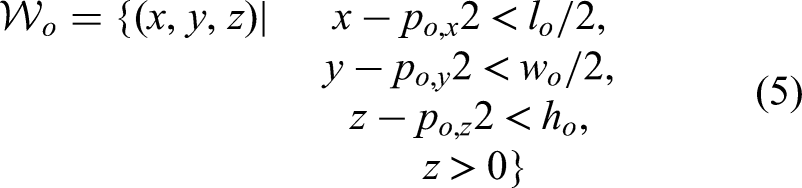


MARL-Based decentralized planning approach
To address the online decentralized motion planning of a CTAP, this section proposes a decentralized planning approach based on MARL. The MARL-based decentralized planning approach develops a decentralized planner including an agent for every aerial actuator and an agent for all ground actuators. For a CTAP with

Flow diagram of a MARL-based decentralized planner applied to the motion planning of a cable-towed aerial platform.
Regarding MARL algorithm selection, this study compared the performance of MAPPO and MATD3. As an on-policy method, MAPPO requires freshly collected data for each update and thus suffers from low sample efficiency. 30 This led to convergence difficulties during the early training phase, making it hard to obtain stable policies within a limited number of interaction steps. In contrast, MATD3, as an off-policy algorithm, can repeatedly reuse past experiences via a replay buffer, which significantly improves sample efficiency and accelerates convergence. Therefore, this study adopted MATD3 to ensure efficient training in the complex CTAP environment.
State space and action space
The state spaces for an aerial-actuator agent and for the ground-actuator agent are the same. The state space comprises the position of the moving platform
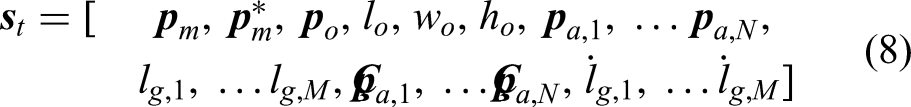
The output of the agent of the
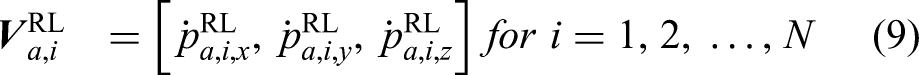

Reward function for ground actuators
Inspired by Gagliardini et al.,
12
Xiong et al.,
7
this study proposes a reward function that accumulates multiple terms for the agent of ground actuators based on a multi-objective optimization problem as
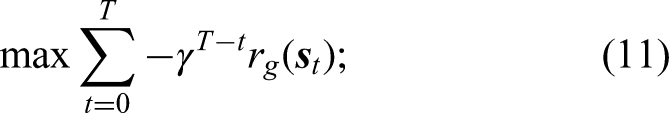
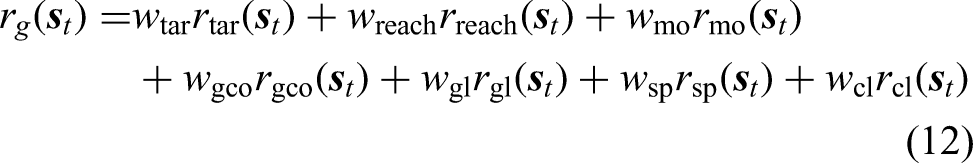



where

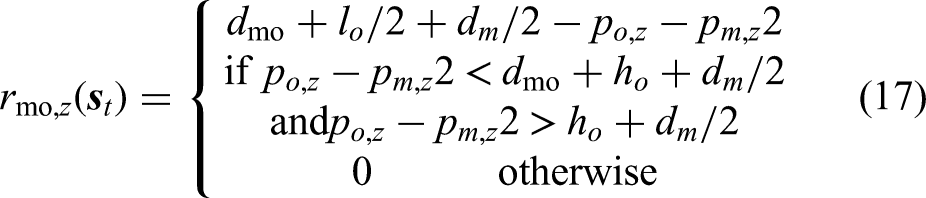







Although defined separately,
Reward function for an aerial actuator
This study designs a reward function that accumulates multiple terms for the agent of an aerial actuator based on a multi-objective optimization problem as




The purposes of

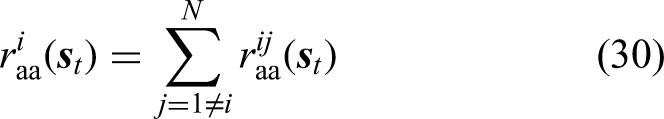




In summary, the reward terms can be grouped into three categories. First, the goal-reaching rewards (i.e.,
Experiments
To evaluate and demonstrate the proposed decentralized planning approach, a CTAP prototype is established, as shown in Figures 5 and 6, and a model of the CTAP prototype is built based on the MuJoCo simulation environment,
31
as shown in Figure 6. The CTAP prototype involves two aerial actuators and two ground actuators (i.e.,

A cable-towed aerial platform prototype with two aerial actuators and two ground actuators in the real world.

A cable-towed aerial platform with two aerial actuators and two ground actuators in the MuJoCo simulator.
The MATD3 algorithm suppresses the overestimation problem more effectively than MADDPG. 32 Additionally, its deterministic policy enables more precise action control than the MAPPO algorithm. In this study, the MAPPO algorithm was first applied to training. However, with MAPPO, the achieved reward is hard to converge in training. For this reason, the MATD3 algorithm is used to train a decentralized planner consisting of two agents designed for the two aerial actuators and one agent for the two ground actuators, according to the decentralized planning approach presented in Section “MARL-Based decentralized planning approach”. A centralized optimization-based planner is developed working as a baseline. The effectiveness of the decentralized planning approach is verified through the training of a decentralized planner in simulation, statistical comparison in simulation, and a case study in simulation and in the real world.
Setup
In this study, a planner is required to guide a CTAP to move in an environment with an obstacle with a height of up to 1.0 m, a length of up to 0.5 m, and a width of up to 0.5 m. The length of the cable between an aerial actuator and the moving platform is 1 m. The maximum velocity of aerial actuators is 0.2 m/s. The maximum cable stretching velocity of the cables driven by the ground actuators is 0.2 m/s. A planner defines a world frame and the origin of the world frame is on the ground and at the center of the two ground actuators. The
A personal computer with an Intel i9-10900K CPU, Nvidia 3080Ti GPU, and 64 gigabytes of memory is used for the training of a MARL-based decentralized planner and the analysis of the MARL-based planner and the optimization-based planner in simulation. In simulation, the positional and geometric information of aerial actuators and the moving platform as well as the length of variable-length cables can be obtained by the Mujoco simulator.
For experiments in the real world, a laptop with an AMD R5-5600U CPU and 16 gigabytes of memory is used for the optimization-based planner and the agent of ground actuators of the MARL-based decentralized planner. Two Jetson Orin Nano onboard computers with 8 gigabytes of memory are used for the two agents of aerial actuators of the MARL-based decentralized planner, respectively. The positional and geometric information of the moving platform, obstacle, and aerial actuators are measured by a NOKOV motion capture system. The length of variable-length cables is recorded by encoders.
Implementation and training of a MARL-based decentralized planner
The MATD3 algorithm
32
is used for this study due to its robust framework, which is based on decentralized execution and centralized training, making it well-suited for developing decentralized controllers for multiple agents. According to the MATD3 algorithm, the policy and value networks are both designed based on a multilayer perceptron (MLP) architecture, consisting of three fully connected (FC) hidden layers. Each layer includes 256 units and employs the leaky-ReLU activation function. The output layer of the policy network is a tanh layer, which ensures that the output of the policy network ranges from



To train a MARL-based decentralized planner, obstacles with a height ranging from 0.2 m to 1.2 m and a length and a width ranging from 0.1 m to 0.6 m are randomly generated. The position of the obstacle is randomly selected up to 0.8 m from the origin of the world frame. A target point around the obstacle is randomly selected. The learning rates of the actor and critic networks are set to 0.001 and 0.0001, respectively. The actor and critic networks are updated every 0.005 s. The batch size is set to 256.
According to the practice of this study, it is difficult to directly train an effective MARL-based decentralized planner. Thus, this study adopts the following strategies to achieve a successful training, inspired by Liu et al., 16 Xu et al. 33
Phased training
The training of a MARL-based decentralized planner is divided into three phases.
The first phase is to guide the agents to learn to move the moving platform to a target point in an environment without an obstacle. Reward functions revised from (26) and (12) are used. The rewards at time step The second phase aims to guide the agents to learn to address small obstacles. The rewards at time step The third phase aims to train the agents to address all possible obstacles. The size of an obstacle is increased with training. Eventually, the maximum length and width of an obstacle are both set to 0.6 m, while the maximum height is set to 1.2 m. The rewards at time step
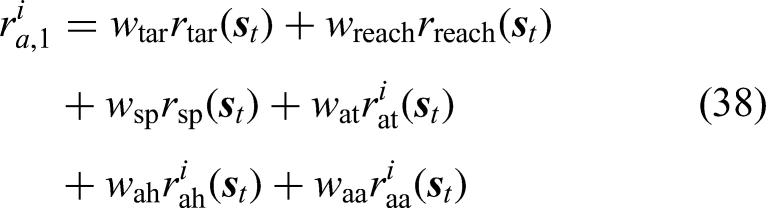
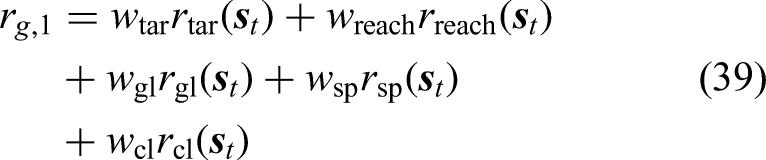
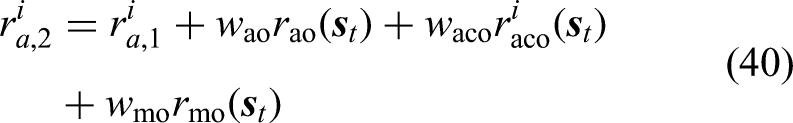

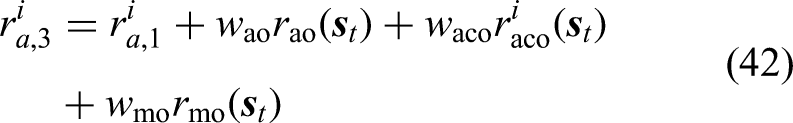

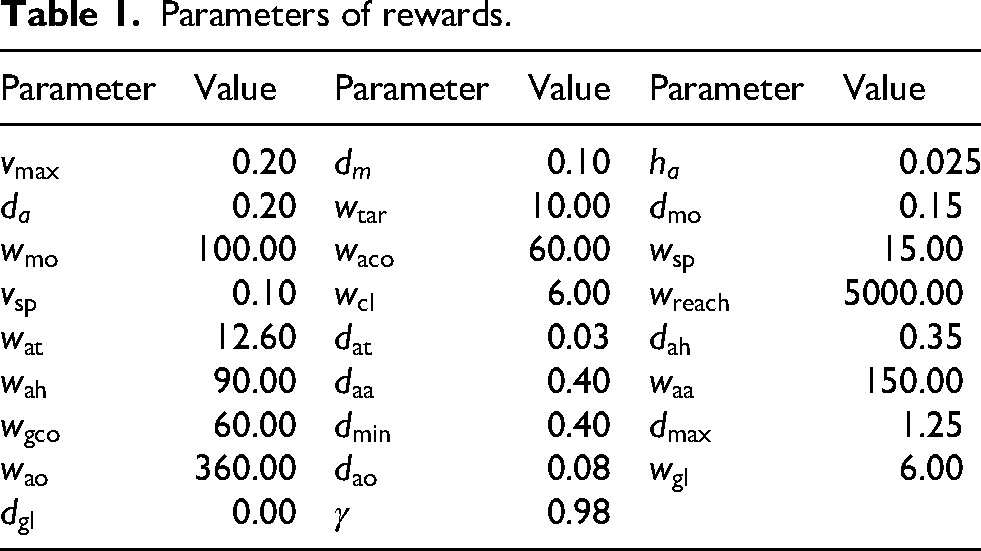
The weights of the reward functions are tuned based on multiple attempts and analysis of the reward achieved in order to balance the different reward terms. The parameters of the reward functions determined through multiple attempts are listed in Table 1.
Parameters of rewards.
Curriculum learning
The curriculum learning technique is used to facilitate the third phase.35,36 Curriculum learning allows one to start learning from simpler tasks (addressing smaller obstacles) and gradually increase the difficulty of tasks. In the third phase, initially, the MARL-based decentralized planner is trained based on an environment with a randomly generated small obstacle, the maximum height, length, and width of which are 0.1 m, 0.2 m, and 0.2 m, respectively. With the increase in the number of training episodes, the size of the randomly generated obstacle increases, according to curriculum learning. Eventually, the maximum height, length, and width of the obstacle are 1.2 m, 0.6 m, and 0.6 m, respectively.
The accumulated rewards achieved by the two agents of aerial actuators and the agent of ground actuators are presented in Figures 7 to 9. The horizontal axis of the figures denotes the number of training steps, while the vertical axis of the figures indicates the value of accumulated reward. The accumulated rewards have similar trends due to the collaboration of the agents. In the first phase, the rewards increase rapidly in an obstacle-free environment. In the second phase, the agents can achieve the same level of rewards in addressing small obstacles. In the third phase, with the increase of the size of obstacles, the accumulated rewards decrease and then converge, suggesting a successful training.

Accumulated reward achieved by the agent of aerial actuator 1.

Accumulated reward achieved by the agent of aerial actuator 2.

Accumulated reward achieved by the agent of ground actuators.
Implementation of the optimization-based planner
The optimization-based planner used in this study is achieved by applying the CasADi solver to solve the optimization problem of the motion planning of a CTAP defined in Section “Problem formulation.” If a target point is on the front side of the obstacle, the number of time steps is set to
Statistical comparison of the MARL-based planner and optimization-based planner
To investigate the effectiveness of the MARL-based decentralized planning approach, this study applies both the MARL-based decentralized planner and the optimization-based centralized planner to perform 100 tests of addressing random obstacles and target positions, respectively. For fairness, both the MARL-based planner and the optimization-based planner are run on the same personal computer presented in section “Setup”. The test process can be summarized as follows. (a) The moving platform is initialized at [0 m, 0 m, 0.5 m]. (b) An obstacle is randomly generated with a length and a width ranging from 0.1 m to 0.5 m and a height ranging from 0.2 m to 1.0 m. (c) The target position is randomly generated around the obstacle. 4) The MARL-based planner and the optimization-based planner address the motion planning of the CTAP and move the moving platform to the target position, respectively.
The success rate, time consumption, and path length of the planners are investigated. The results of the 100 tests are shown in Table 2. It is shown that both the MARL-based planner and the optimization-based planner can achieve a 100% success rate, indicating that both planners can address the motion planning of a CTAP. It should be emphasized that the MARL-based planner can address the motion planning of a CTAP based on decentralized agents. The time consumption of the MARL-based planner in determining target velocities is two orders of magnitude lower than the time consumption of the optimization-based planner. The cost of the high time efficiency and decentralization achieved by the MARL-based planner is slightly worse in terms of path length than that of the optimization-based planner.
Results of the statistical comparison of the MARL-based planner and optimization-based planner.

To further evaluate robustness, this study has tested the MARL planner in the presence of dynamic obstacles. In this scenario, obstacles moved randomly at a velocity of
Regarding communication failures, the proposed MARL design does not rely on explicit inter-agent communication during execution, as each agent makes decisions based on local observations and rewards. Therefore, communication interruptions have no effect on task execution. The optimization baseline is an offline centralized solver, which also does not depend on runtime communication. This demonstrates that, while communication failure is a critical issue in many distributed systems, it is not a limiting factor for the studied approaches.
Sensitivity analysis of reward components
To assess the effectiveness of different reward components, this study conducted an ablation-style sensitivity analysis on a previously trained MARL model. The reward terms were grouped into three categories: (1) goal-reaching rewards, (2) collision-avoidance rewards, and (3) coordination rewards (ensuring cables remain taut). Starting from the same initialization, this study retrained three models, each with one category removed, for
The results highlight the necessity of each component. Without goal-reaching rewards, the agents failed in all trials because the moving platform did not learn where to move, leading to timeouts. Without collision-avoidance rewards, only 7% of the trials succeeded; the majority failed due to collisions between the moving platform or cables and an obstacle. Without coordination rewards, the success rate dropped to 38%; the failures were caused by violent oscillations near the target, where slack cables led to collisions. These observations confirm that all three categories are essential. Goal-reaching rewards provide the primary task objective, collision-avoidance rewards ensure safety, and coordination rewards stabilize the system by maintaining cable tension.
Case study in the real world
A case study of applying the MARL-based planner and the optimization-based planner to the CTAP prototype is performed in the real world to investigate the performance of the MARL-based planner in detail. The MARL-based planner runs on a laptop and two onboard computers introduced in section “Setup” while the optimization-based planner runs on the laptop. An obstacle with a height of 0.8 m and a width and a length of 0.4 m is selected according to the limitations of the experimental site. The obstacle is located at [0.450 m, -0.498 m, 0.00 m]. The CTAP prototype is required to bypass the obstacle and reach a target position behind the obstacle located at [0.900 m, -1.096 m, 0.853 m].
The trajectories of the aerial actuator 1, aerial actuator 2, and moving platform of the CTAP prototype following the MARL-based planner and the optimization-based planner are presented in Figures 10 and 11, respectively. The time consumption and path length of the MARL-based planner and the optimization-based planner are listed in Table 3. The results show that the optimization-based planner takes 20 s to address the motion planning of the CTAP prototype based on the laptop, suggesting that the optimization-based planner cannot achieve online planning for a CTAP. The agents of the MARL-based planner can be deployed on different devices and can determine the target velocities for aerial and ground actuators within 0.01 s, indicating that the MARL-based planner can achieve online decentralized planning for a CTAP (Figures 12 and 13). The path length of the trajectories achieved by the MARL-based planner is longer than that achieved by the optimization-based planner, consistent with the result of path length in the statistical analysis in section “Statistical comparison of the MARL-based planner and optimization-based planner.”

Trajectories of the CTAP prototype following the MARL-based planner in the real world.
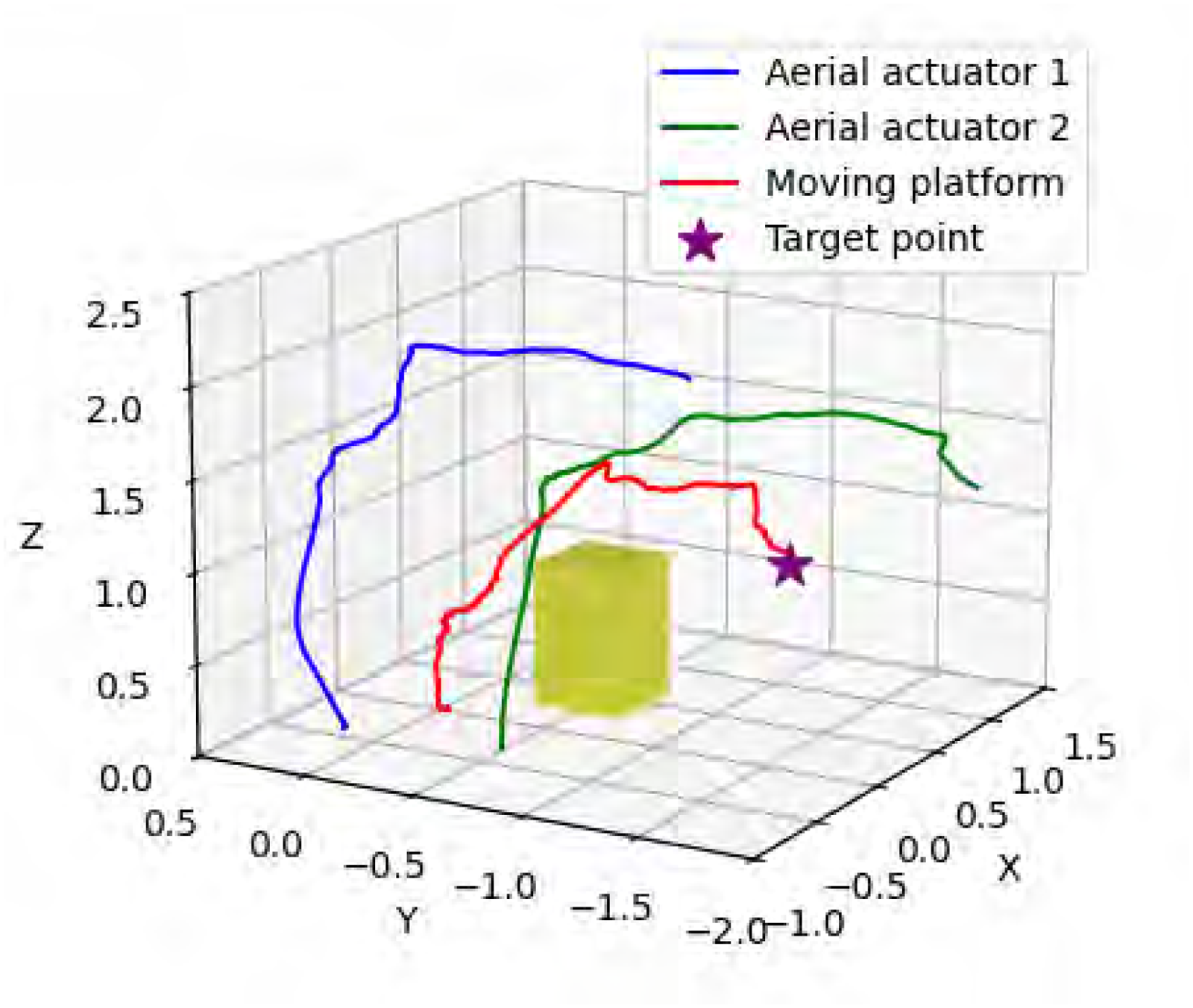
Trajectories of the CTAP prototype following the optimization-based planner in the real world.

Behaviors of the CTAP prototype following the MARL-based planner.

Behaviors of the CTAP prototype following the optimization-based planner.
Time consumption and path length results in approaching a target position on the back of an obstacle in the real world.

In this experiment, this study quantified path tracking accuracy for the moving platform, aerial actuator 1, and aerial actuator 2 following the proposed planner. The commanded trajectory 



Success rates under ablation of different reward categories (100 trials).

Path tracking accuracy.

It should be noted that compared to optimization-based methods, the MARL-based planner provides control actions within milliseconds, thereby offering superior real-time performance at the cost of somewhat longer paths. In high-risk applications such as firefighting, real-time responsiveness is often more critical than achieving the shortest path. Faster decision-making enables the platform to promptly handle sudden hazards, whereas the extra energy cost from longer paths is relatively minor. Therefore, this trade-off is acceptable in practice.
Discussion
It should be noted that the experiments in this study were based on several simplifying assumptions. First, the number of obstacles was fixed to one, and its shape was constrained to a cuboid. This reduced problem complexity and facilitated training, but it does not cover more complex scenarios such as multiple or irregularly shaped obstacles. Second, the positions of the ground actuators were fixed symmetrically, which stabilized training and reduced the dimensionality of the action space. However, in more general settings, non-symmetric actuator placements may significantly increase planning difficulty. Third, the system considered in this work included only two aerial and two ground actuators. While this simplified CTAP provides a useful starting point, scaling the proposed approach to larger systems with more actuators remains a challenge, as the joint action space grows rapidly with the number of agents. To extend the proposed approach to handle more complex scenarios (e.g., multi-robot coordination in large-scale environments), possible ways include improving the scalability of the proposed approach by adopting modular or hierarchical MARL architectures to coordinate larger groups of actuators, or by integrating safety filtering mechanisms such as quadratic programming (QP) projections to ensure feasibility constraints when more agents are involved.
It should also be emphasized that deploying the proposed CTAP system in real-world settings introduces additional challenges beyond the simulation assumptions. Environmental factors such as wind disturbances, extreme weather, complex terrain, and sensor noise may cause deviations from planned trajectories and reduce robustness. Hardware limitations further constrain performance: aerial agent’s endurance restricts mission duration, actuator dynamics impose limits on responsiveness, and onboard computation is limited compared to simulation resources.
Conclusions
This article has developed a MARL-based online decentralized planning approach for a CTAP to achieve motion planning in a communication-denied environment with a cuboid obstacle. The motion planning problem of a CTAP has been formulated as an optimization problem and the reward function of the MARL-based planning approach has been defined according to the optimization problem. A MARL-based decentralized planner has been successfully trained according to the MARL-based planning approach and the important training techniques used in this study have been presented. Statistical analysis of the MARL-based decentralized planner in simulation and deployment of the MARL-based decentralized planner on a CTAP prototype has been performed to validate that the MARL-based planner can achieve successful, decentralized, and online motion planning for a CTAP.
Although the proposed MARL-based decentralized planning approach demonstrates advantages in real-time performance and decentralization, it also has several limitations. First, as the number of agents increases, the action space dimensionality grows rapidly, making the training process more challenging. Second, the simulator used does not support realistic cable–obstacle collisions, and the geometric approximation requires additional computation and may introduce errors. Third, the paths generated by the MARL-based planner are generally longer than those produced by optimization-based methods, deviating from the theoretical optimum. Fourthly, the proposed MARL-based decentralized planner has been validated in static obstacle-rich environments, but its performance in highly dynamic environments remains to be explored.
Future research could explore methods for improving the system’s adaptability to an increased number of agents and highly dynamic environments. Moreover, developing hybrid approaches combining MARL with model-based planning methods might offer benefits in terms of both efficiency and robustness.
Footnotes
Ethical approval and informed consent statements
This article does not contain any studies with human or animal participants.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the National Natural Science Foundation of China (Grant No. 52405010), the Guangdong Basic and Applied Basic Research Foundation (Grant No. 2023A1515011010), and the Shenzhen Science and Technology Innovation Program (Grant No. GXWD20231130150349002).
Conflicting interest
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: I hereby disclose that I am a current member of the editorial board of the International Journal of Advanced Robotic Systems. However, I affirm that this affiliation has not influenced the objectivity, analysis, or conclusions presented in this work. All editorial processes for this submission, including peer review and decision-making, were managed in strict accordance with the journal’s ethical guidelines to ensure impartiality.
Data availability statement
Any data gathered and reported in this study are available from the corresponding authors upon reasonable request.