
Abstract
This work introduces Deep Policy Similarities (DeePS), a learning-based bisimulation approach designed to enhance generalization in reinforcement learning for robotic control. Traditional reward-based bisimulation metrics often fail to enable effective policy transfer, particularly in environments with inconsistent reward structures. DeePS overcomes these limitations by leveraging policy similarities and approximating the policy similarity metric using a forward dynamics model. This approach facilitates more efficient and effective policy transfer across semantically equivalent environments. Through a series of control experiments, DeePS is shown to significantly outperform standard reinforcement learning methods and reward-based bisimulation approaches. In the noisy cartpole environment with randomized rewards, DeePS achieved 53.5% and 79.0% higher test rewards compared to Soft Actor-Critic and Deep Bisimulation for Control (DBC), respectively. Additionally, in a zero-shot evaluation on the Minigrid simple crossing environment, DeePS outperformed existing approaches, with test rewards 79.9% and 99.5% higher than DBC and RAPID, respectively. These results demonstrate that DeePS significantly enhances the ability of reinforcement learning models to generalize to diverse, unseen environments. This makes DeePS a valuable advancement for reinforcement learning, particularly in robotic applications where adaptability and robustness are critical.
Keywords
Introduction
Reinforcement learning is a powerful framework for developing autonomous systems capable of making sequential decisions to maximize cumulative rewards. In the realm of robotic control, reinforcement learning enables robots to learn complex behaviors through interactions with their environment, eliminating the need for pre-programmed instructions. This capability is critical for tasks such as navigation, manipulation, and coordination in complex environments with undefined solutions.
A significant breakthrough in reinforcement learning for robotics was the development of Deep Q-Network, 1 which integrated deep learning with traditional Q-learning. 2 This innovative approach enabled reinforcement learning to manage high-dimensional state spaces, making it feasible to apply reinforcement learning techniques to more sophisticated robotic tasks. For instance, reinforcement learning was successfully applied to train robots for object manipulation, locomotion, and autonomous navigation.3–6
Despite these advances, applying reinforcement learning to real-world robotic problems remains challenging, particularly in achieving generalization—the ability to transfer learned behaviors from training environments to unseen, semantically equivalent environments. Real-world environments are inherently unpredictable, posing a significant challenge for reinforcement learning models that are often optimized for static, well-defined environments. For instance, a robot trained with reinforcement learning to navigate a specific indoor environment may perform well in training, but struggle in new settings with different layouts or goals. This difficulty in adapting to changes highlights the fragility of current reinforcement learning approaches as a result of overfitting to training conditions leading to poor performances in novel situations.7,8
Traditional reinforcement learning benchmarks such as MuJoCo 9 or the Arcade Learning Environment 10 evaluate agents in controlled and repeatable settings. While useful for assessing specific agent capabilities, these benchmarks fail to capture the complexity and variability of dynamic real-world environments. To this end, more recent benchmarks, such as those presented in Nichol et al., 11 which introduce a train–test split reveal that standard deep reinforcement learning methods perform poorly under varied conditions. This discrepancy in performance between tightly controlled experiments and practical deployment further underscores the need for reinforcement learning models that are robust and can generalize effectively across diverse conditions.
To address this challenge, studies have explored various strategies to improve the generalizability of reinforcement learning in robotics. Techniques such as data augmentation12–14 and domain randomization15,16 introduce variability during training, helping to develop more robust models. Regularization and dropout17,18 were also applied to neural models to reduce overfitting to training environments. In parallel, procedurally generated environments7,19 offer a means to create diverse training conditions, alleviating concerns with overfitting. These environments continuously generate new and varied scenarios, guiding the agent to learn more adaptable policies. However, these existing methods largely fail to leverage the temporal dependency between sequential decisions when considering generalization for reinforcement learning—a characteristic that is unique to reinforcement learning.
More recent approaches have adapted the temporal properties of reinforcement learning to learn general policies with bisimulation techniques.20–25 Bisimulation methods, in general, seek to encode state representations such that states leading to similar behaviors are represented similarly. This helps in learning policies that are more general and adaptable by recognizing and responding to behavioral similarities in different states. Notably, bisimulation approaches are flexible and can be integrated with other existing enhancement techniques such as the data augmentation or algorithmic modifications described previously.
Enhancing the generalization capabilities of reinforcement learning is crucial for deploying it in real-world robotics, making it a key focus of ongoing research. By addressing these generalization challenges, reinforcement learning can maximize its potential, enabling trained robots to perform a wide range of tasks autonomously and effectively in diverse settings.
The contribution of this work is as follows: (i) we introduce a novel learning-based bisimulation approach that leverages policy-driven actions to enhance the generalization capabilities of reinforcement learning models efficiently and (ii) propose the use of an additional nonlinear projection layer on the encoder representations for improved performance. (iii) We also demonstrate that our proposed method improves generalization across diverse environments that are semantically equivalent, through a series of control-related experiments.
These advancements represent a critical step toward developing generalized reinforcement learning policies that are not only effective in controlled scenarios, but also capable of handling the complexities and unpredictability of real-world applications. Our findings suggest that integrating bisimulation with policy-driven strategies using a learning-based approach can bridge the gap between theoretical research and practical deployment, paving the way for more reliable and versatile robotic systems.
Markov Decision Processes
Markov decision processes (MDPs) 26 provide a mathematical framework for modeling decision-making in situations where outcomes are influenced by both the action of the agent and the probabilistic elements of the environment. MDPs are widely used in various fields of work, including robotics, transportation systems, 27 and artificial intelligence, particularly in the context of reinforcement learning.
An MDP is defined by a tuple
The objective in reinforcement learning is to find an optimal policy
MDPs assume the Markov property, where the future states depend only on the current state and action, simplifying decision-making. While this assumption facilitates modeling and optimization within individual environments, generalization across environments requires understanding and identification of similarities between the states for effective policy transfer. Solving an MDP focuses on maximizing returns in a single environment28–30 and generalization requires the policy to recognize and adapt to similarities across multiple MDPs.
Although deep reinforcement learning techniques have shown remarkable success in developing effective policies for individual MDPs,
MDPs form the backbone of reinforcement learning algorithms, where an agent learns to make decisions by interacting with the environment. Through trial and error, the agent seeks to discover the optimal policy that yields the highest rewards and MDPs provide the theoretical foundation for understanding how agents can learn effective strategies in these uncertain environments. It offers a robust framework for modeling complex decision-making problems essential for developing intelligent robotic systems capable of operating autonomously.
Bisimulation in Reinforcement Learning
In MDPs, bisimulation provides a systematic approach to measure the similarity between states, where bisimilar states are expected to exhibit similar behavior. This approach is especially useful for tasks such as model reduction or state aggregation, 31 which aim to simplify a complex MDP while maintaining key behavioral characteristics. A significant advancement for applying bisimulation in MDPs is the introduction of the bisimulation metric, 20 which provides a quantitative measurement of the similarity between states, focusing particularly on their reward structures.
(Bisimulation metrics 20 )
Let

This bisimulation metric provides a nuanced method for evaluating similarities between states in MDPs, comprising two main components: the absolute difference in immediate rewards from specific actions and the variation in future state transitions, assessed using the 1-Wasserstein distance,
32
denoted as
The bisimulation metric evaluates the differences between states
The on-policy bisimulation metric
22
was introduced to address these limitations by focusing on a specific policy
Let

However, relying solely on reward similarities may not be sufficient for effective policy transfer between environments which is essential for the broader adoption of these metrics in reinforcement learning. The policy similarity metric (PSM) represents a novel approach that differs from traditional reward-based bisimulation metrics by focusing on the alignment of actions derived from policy
Let

In the PSM, emphasis is placed on the difference in agent actions measured using a pseudo-metric
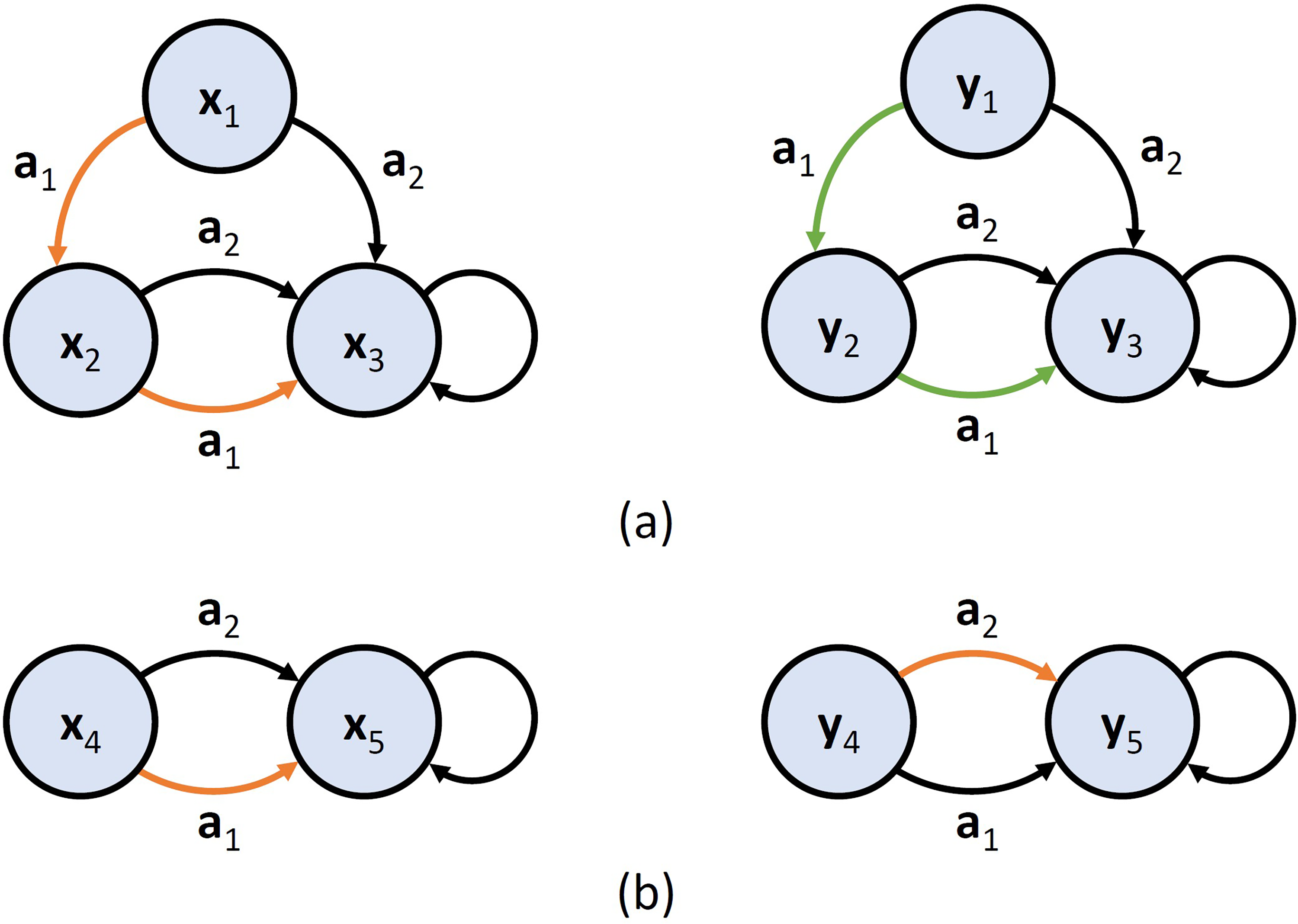
Consider MDPs with states
As shown in Figure 1, the action-based PSM provides a more effective comparison metric for generalizing learned policies. Unlike
By prioritizing action-based comparisons, PSM facilitates more robust policy generalization and enhances the agent’s ability to adapt to new and varied environments. This capability is essential for real-world robotic applications where consistency and adaptability of the learned policies are critical for success.
Learning-based bisimulation metrics
Learning-based bisimulation approaches have been extensively explored22,24,25,34,35 in recent works, marking a significant progress in addressing the generalization challenges posed by environments with extensive or continuous state spaces. These advanced methods utilize deep learning to approximate the bisimulation metric, facilitating its scalable application in complex settings and contributing to the development of more robust and generalized reinforcement learning approaches that can be effectively applied across diverse environments.
The Deep Bisimulation for Control (DBC)
34
is a notable example that approximates the


DBC directly enforces bisimilarity properties on the encoder representations by applying an auxiliary loss designed to aggregate bisimilar states (i.e. in this case, states with very similar values). This is achieved by minimizing the mean squared error:

However, the use of an approximate dynamics model to estimate the
To the best of our knowledge, most learning-based bisimulation research continues to focus on the reward-based
Deep policy similarities
This work proposes adapting the DBC methodology to learn generalized policies using action-based similarities, specifically the PSM. We call our proposed methodology the Deep Policy Similarities (DeePS), where a neural network
Let

By representing the transition probabilities as a Gaussian distribution,

For any two distributions

Assume

The existence proof is virtually identical to the proof presented in Kemertas and Aumentado-Armstrong.
31
For continuous MDPs, the proof of the existence of the unique metric depends on the state space




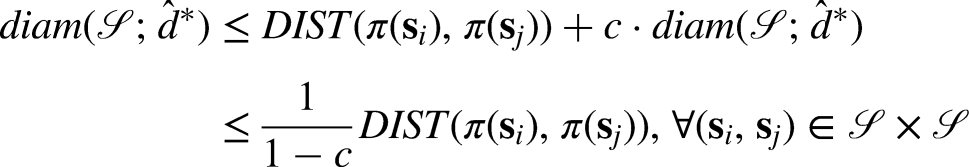

Instead of normalizing the latent states within a closed ball

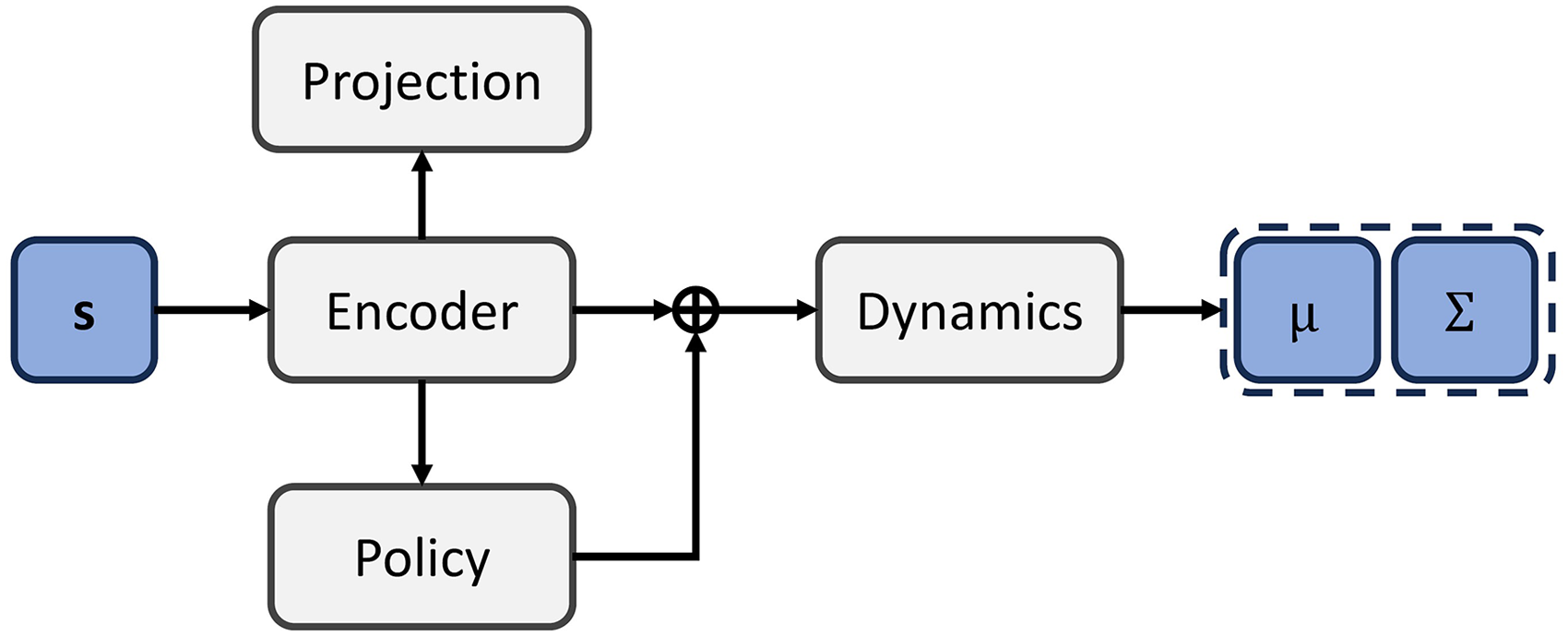
The proposed DeePS architecture bears a strong resemblance to the DBC architecture, with the key distinction being the omission of the reward network and the additional projection layer. The encoder processes the input observation, extracting a latent representation

Experiments
Noisy sparse cartpole environment
We study the effectiveness of our proposed approach using a modified version of the traditional cartpole environment. This variant
31
offers a more challenging adaptation of the well-known OpenAI Gym environment
40
and is specifically designed to test the robustness and adaptability of reinforcement learning models for control under increasingly complex conditions. The noisy sparse cartpole environment introduces three key modifications:
These adaptations not only increase the complexity of the task but also necessitate advanced techniques to accurately capture latent state representations for developing effective policies. By evaluating our approach in this challenging environment, which mimics the complexities of a robotic control problem, we aim to demonstrate its robustness and ability to learn generalized policies, highlighting its potential for real-world robotic applications.
We assess the performance of our proposed approach DeePS alongside its reward-based counterpart DBC, both of which employ the Soft Actor-Critic (SAC)
39
as the standard reinforcement learning model. This analysis aims to underscore the strengths and potential weakness of our method in comparison to the state-of-the-art for generalization in reinforcement learning which leverages on the
In models that utilize intrinsic rewards, the forward model error in the latent space is employed.31,41–43 This intrinsic reward is mathematically defined as:

Network architecture and hyperparameters
The neural network architecture used in this experiment closely follows the design outlined in Kemertas and Aumentado-Armstrong. 31
The encoder network comprises a four-layer multilayer perceptron (MLP) with
The critic network employs double Q-learning, with each Q-function represented by a three-layer MLP featuring
When utilizing a predictive dynamics model, an additional network approximates a Gaussian distribution representing the transition probabilities. For simplicity, deterministic transitions were assumed in this environment. The forward dynamics model is a two-layer MLP with a hidden layer dimension of 512, with layer normalization applied after the first fully connected layer, followed by a
In our proposed approach, which incorporates a nonlinear projection, the projection layer consists of a single fully connected layer with an output dimension of 32, followed by a
All other hyperparameters used in the experiment are summarized in Table 1.
Hyperparameters for noisy sparse cartpole environment.

Results and discussion
Our initial analysis concentrates on the boundedness of the state space. We demonstrate the feasibility of DeePS in the noise-free setting (

The solid lines represent the average episode rewards, while the dashed lines indicate the
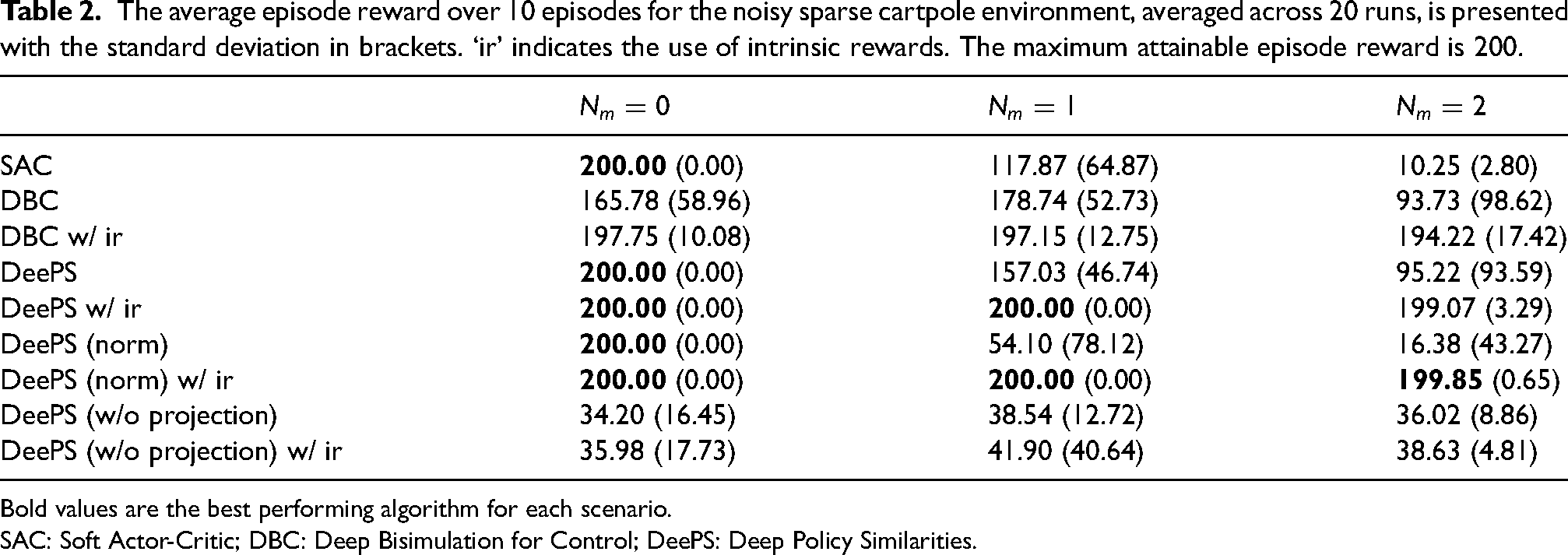
The performance of the different models (SAC, DBC, DBC w/ ir, DeePS, and DeePS w/ ir) are illustrated in Figure 4, and the average episode rewards are summarized in Table 2, with noise intensity incrementally raised from

Performance comparison of SAC, DBC, and DeePS (ours) in the noisy sparse cartpole environment. ‘ir’ indicates the use of intrinsic rewards. Each plot represents the average episode reward over 10 episodes, averaged across 20 runs, with the 95% confidence interval indicated. SAC: Soft Actor-Critic; DBC: Deep Bisimulation for Control; DeePS: Deep Policy Similarities.
The average episode reward over 10 episodes for the noisy sparse cartpole environment, averaged across 20 runs, is presented with the standard deviation in brackets. ‘ir’ indicates the use of intrinsic rewards. The maximum attainable episode reward is 200.
Bold values are the best performing algorithm for each scenario.
SAC: Soft Actor-Critic; DBC: Deep Bisimulation for Control; DeePS: Deep Policy Similarities.
The SAC, a representative of standard reinforcement learning methods, managed to achieve optimal performance in the noise-free setting despite the sparse rewards. However, its performance declined significantly as the noise intensity increased, eventually failing at
Interestingly, the DBC approaches, both with and without intrinsic rewards, failed to achieve optimal performance even in the noise-free setting, indicating instability. This instability may stem from inaccurate state clustering where states with similar values but different optimal actions are aggregated incorrectly, as discussed previously. The declining performance of DBC, along with the high standard deviations, further supports the notion that state aggregation using
Although DeePS also experienced reduced performance as noise intensity increased (as seen in Table 2), the evaluation curves suggest that, unlike DBC which appeared to plateau, training was incomplete for DeePS, hinting that extended training could improve performance. Our approach showed delayed improvements during training, likely due to the difficulty of policy learning in sparse reward settings early in the training process, and state aggregation based on these random or poor policies hurt the training process. This points to a potential weakness in our approach in the reliance on the quality of the baseline policy. This is evident from the improved performance of DeePS w/ ir as seen in Figure 4 when intrinsic rewards were used to counteract reward sparsity. Despite this weakness, DeePS still outperforms the SAC, indicating that the model likely benefits from state aggregation based on policy-driven behaviors.
We conducted additional ablation studies to assess the impact of nonlinear projection on performance. As shown in Table 2, the model suffers catastrophic failure when no projection or normalization constraint is applied to the latent space. When intrinsic rewards are included, models utilizing nonlinear projection and normalization exhibit comparable performance. However, in the absence of intrinsic rewards, the normalized variant performs significantly worse, highlighting the robustness of the nonlinear projection approach.
In this experiment, our approach based on an approximation of the policy-driven PSM demonstrates significant promise in addressing the generalization challenge more effectively than standard reinforcement learning algorithms or the reward-based DBC. The superior performance of our approach validates the feasibility of using approximate forward dynamics to estimate the PSM, which is then used to improve generalization for reinforcement learning.
Noisy cartpole with randomized rewards
To study the impact of reward structures on the generalization ability of our action-based approach, we introduce slight variations to the noisy cartpole environment. We simulate a generalization problem where semantically equivalent environments have different reward structures by integrating randomized rewards. Specifically, the agent receives a reward that uniformly varies between 50% and 150% of the original reward for each successful timestep. This setup disregards reward sparsity to allow for greater variations in state values.
The randomization of reward signals introduces stochasticity, creating a more challenging and realistic environment for evaluating generalization. By testing the models in these varied environments, we can assess their ability to learn robust policies that generalize across different reward structures—essential for real-world applications where reward functions may be inconsistent. This allows us to compare the flexibility and adaptability of our proposed policy-driven DeePS approach to standard reinforcement learning algorithms and DBC.
Network architecture and hyperparameters
In general, we made use of the same network architecture and hyperparameters as with the previous experiment. However, to better manage the increased complexity introduced by randomized rewards, we made several adjustments to both the network architecture and training process. The hidden layer dimensions for both the actor and critic networks were reduced from 256 to 128 in an attempt to reduce the model’s capacity, preventing it from memorizing and overfitting to specific reward structures. In addition, we decay the learning rate by 0.99 every 1000 environment steps and increase the training batch size from 512 to 1024 to stabilize the training process. These adjustments help ensure that the models can handle the increased complexity and stochasticity of the noisy cartpole environment with randomized rewards, facilitating a thorough evaluation of the robustness and adaptability of our proposed method in a setting that closely simulates real-world scenarios.
Results and discussion
The performance of different models (SAC, DBC, and DeePS) in the noisy cartpole environment with randomized rewards is illustrated in the provided plots (Figure 5) and the table of results (Table 3). The results demonstrate the superiority of our proposed DeePS approach against the SAC and DBC across different noise levels ranging from
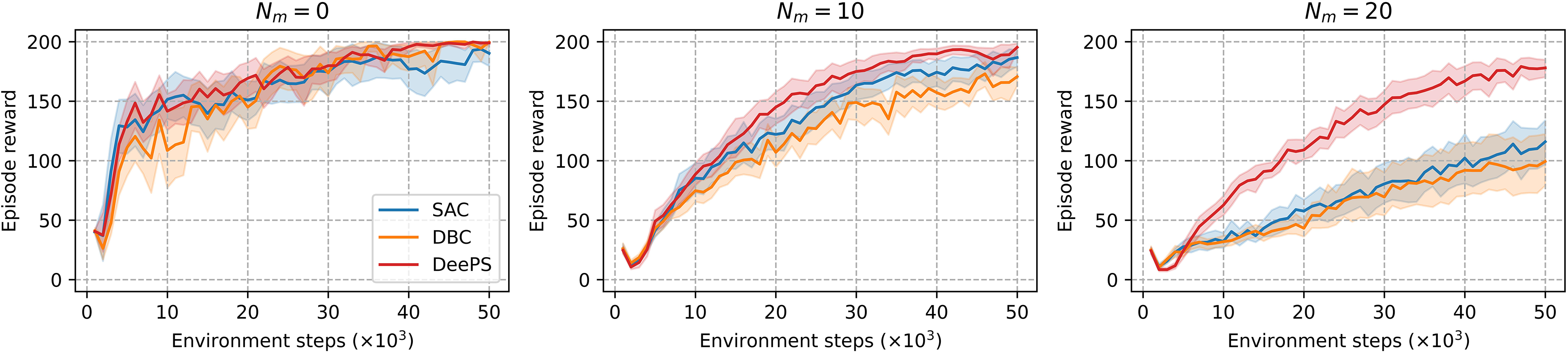
Performance comparison of SAC, DBC, and DeePS (ours) in the noisy cartpole environment with randomized rewards. Each plot represents the average episode reward over 10 episodes, averaged across 20 runs, with the 95% confidence interval indicated. SAC: Soft Actor-Critic; DBC: Deep Bisimulation for Control; DeePS: Deep Policy Similarities.
The average episode reward over 10 episodes for the noisy cartpole environment with randomized rewards, averaged across 20 runs, is presented with the standard deviation in brackets. The maximum attainable episode reward is 200.

Bold values are the best performing algorithm for each scenario.
SAC: Soft Actor-Critic; DBC: Deep Bisimulation for Control; DeePS: Deep Policy Similarities.
In the noise-free setting (
The evaluation curves in Figure 5 further support these findings, showing that DeePS consistently delivers higher and more stable performance as noise increases. The decline in SAC’s performance underscores the limitation of standard reinforcement learning in effectively generalizing across MDPs with variable reward structures. While DBC marginally outperformed DeePS in the absence of noise, its performance deteriorated more rapidly as noise levels increased, eventually performing worse than SAC at
Overall, these experiments highlight the effectiveness of DeePS in generalizing across continuous control tasks affected by noise and inconsistent rewards. Our method consistently outperforms both standard reinforcement learning algorithms and reward-based bisimulation approaches, demonstrating its robustness in handling complex and variable environments. By focusing on action-based similarities, DeePS enables more reliable policy transfer and adaptability, making it a valuable tool for real-world robotic applications. This success underscores the potential of our approach to enhance the development of more resilient and versatile reinforcement learning agents for actual robotic systems.
Crossing environment
We further validate our proposed approach in a simple environment that mimics robotic navigation problems in indoor settings. For this purpose, we utilize the simple crossing environment (
We study generalization by training the agent on 10 different layouts (training set) and testing it on three other semantically equivalent layouts (testing set) as shown in Figures 6 and 7, respectively. The layouts in the training and testing sets do not overlap, requiring the agent to adapt to the test environments after training for 1,500,000 timesteps in the training set. This presents a very challenging task known as zero-shot generalization.

Environment layouts used to train the agent in the crossing environment. The agent should move through the crossing in the wall towards the goal  located at the bottom right corner as quickly as possible.
located at the bottom right corner as quickly as possible.
Environment layouts used to test the agents in the crossing environment. The agent should move through the crossing in the wall towards the goal located at the bottom right corner as quickly as possible.
We evaluate the performance of our proposed approach alongside standard reinforcement learning and also DBC. Additionally, we consider the use of the RAPID algorithm,
44
designed to enhance reinforcement learning in procedurally generated environments. While the RAPID algorithm is not specifically designed for generalization, it is state-of-the-art for improving agent performance in procedurally generated environments. The RAPID algorithm uses a ranking buffer to gather high-quality state-action transitions for imitation learning. These transitions are ranked based on the weighted sum of their extrinsic rewards and their local and global exploration scores, defined as
As noted in previous experiments, DeePS is dependent on the quality of the baseline policy during training. Therefore, to ensure effective generalization, we first train the DeePS model with an additional RAPID loss for 1,000,000 timesteps to establish a strong baseline policy (for the training domain) before applying state aggregation for the remaining 500,000 timesteps.
Network architecture and hyperparameters
The encoder network consists of a two-layer MLP with
Hyperparameters for crossing environment.

Results and discussion
The performance of the different models (PPO, RAPID, DBC, and DeePS) is shown in Figure 8, and the summary of the results provided in Table 5.

Comparison of training (top) and testing (bottom) performance for PPO, RAPID, DBC, and DeePS (ours) in the crossing environment. The training plots represent the average episode rewards over 100 episodes, and the testing plots represent the average episode rewards over 30 episodes. Both are averaged across five runs, with 95% confidence intervals included. PPO: Proximal Policy Optimization; DBC: Deep Bisimulation for Control; DeePS: Deep Policy Similarities.
The average episode reward over 100 episodes (train) and 30 episodes (test) for the crossing environment, averaged across five runs, is presented with the standard deviation in brackets.

Bold values are the best performing algorithm for each scenario.
PPO: Proximal Policy Optimization; DBC: Deep Bisimulation for Control; DeePS: Deep Policy Similarities.
We observed that PPO, as a representative of standard reinforcement learning models, performed poorly on both the training and testing sets. Although extended training could potentially enhance PPO’s performance on the training set, its testing performance is unlikely to improve due to its tendency to overfit to the training conditions.
The other models demonstrated strong training performance, as shown in Table 5, with DBC achieving the highest average training reward. Surprisingly, DBC performed well in the test environments during the early stages of training. However, its near-optimal training performance did not translate into effective generalization as the training progressed. This is evident in its test performance, which remained comparable to PPO despite the superior training results. The inefficiency of DBC is further illustrated in the evaluation curve in Figure 8, where its test performance deteriorates sharply after plateauing in training, underscoring its susceptibility to overfitting.
Similarly, while RAPID achieved better training performance than the baseline PPO, this improvement did not generalize. In fact, RAPID’s test performance was observed to be worse than PPO and clear signs of overfitting were apparent in its evaluation curve as seen in Figure 8. This further highlights the impracticality of using RAPID for generalization purposes.
In contrast to the other models, DeePS demonstrated substantial improvements in generalization, achieving approximately 99.5% higher test rewards than RAPID and 79.9% higher test rewards than DBC (and PPO). Despite achieving slightly lower training performance compared to DBC, DeePS’s performance on the test environments was the best among all models, with a test reward of 0.403, nearly doubling that of PPO and DBC. This result highlights the ability of DeePS to strike a balance between strong training performance and robust generalization.
As seen in the evaluation curves, DeePS effectively leverages its state aggregation mechanism to enhance both training and testing performance. Unlike RAPID and DBC, DeePS avoids overfitting, enabling it to perform consistently across unseen environments. By focusing on action-based similarities, DeePS offers a reliable method for policy transfer and adaptation, ensuring that agents remain effective across diverse environments.
Although DeePS’s test performance remains below optimal levels, it represents a significant step forward in reinforcement learning methodologies. By improving generalization without compromising training performance, DeePS demonstrates its potential to enhance the robustness and adaptability of reinforcement learning policies, particularly in challenging and varied environments.
Limitations
While the proposed DeePS method is effective in enhancing the generalization of reinforcement learning policies, its reliance on a quality baseline and certain assumptions about environmental transitions limit its overall effectiveness. Specifically, the assumption of a Gaussian transition probability may not hold across all environments, and the requirement of accurate modeling of the transition dynamics may limit the reliability of the metric estimates. Nonetheless, a significant amount of existing works have shown the possibility of accurately modeling environmental transitions.45–48 which supports the use of our proposed methodology.
Conclusion
In conclusion, this work introduced a learning-based bisimulation approach that leverages policy similarities. Our experiments demonstrated the effectiveness and robustness of the proposed methodology, showing that DeePS outperforms the state-of-the-art reward-based bisimulation methods. Furthermore, the approach manages to preserve the integrity of the training process while substantially improving the model’s ability to generalize to new, unseen environments with semantically equivalent dynamics. Even in environments with different reward structures, DeePS was able to generalize effectively. This makes it particularly valuable for real-world robotic applications, where adaptability and robustness are essential.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Unmanned Vehicles Core Technology Research and Development Program through the National Research Foundation of Korea (NRF), Unmanned Vehicle Advanced Research Center (UVARC) funded by the Ministry of Science and ICT (MSIT), the Republic of Korea (no. 2020M3C1C1A0108237512).