
Abstract
In this article, we propose an autonomous exploration system based on transfer learning for target point exploration in unknown environments. The system generates a series of clustering points based on the local perceptual information and selects suitable local exploration points through a heuristic method to guide the robot towards the global target direction. This approach alleviates the problem of local optima to a significant extent. To reduce the time cost of deep reinforcement learning in the initial stages, we employ transfer learning by training a model capable of avoiding static obstacles in a simulated environment to accomplish local dynamic navigation tasks. By combining the locally learned dynamic navigation policy with global motion planning, we achieve autonomous exploration for the robot. During the fully autonomous navigation process, we record the robot’s movement trajectory and the generated map. Experimental results demonstrate that compared to similar exploration methods, this approach exhibits advantages in complex dynamic environments, even with the sole use of two-dimensional laser, without the need for maps or excessive information.
Keywords
Introduction
With modern advancements in science, technology, and artificial intelligence (AI), an increasing number of tedious and repetitive manual tasks can now be performed by AI systems. In the field of simultaneous localization and mapping (SLAM) and navigation, traditional approaches have relied on direct human intervention and remote sensing for mapping the environment. 1 In this process, human operators are required to make decisions and control the robots. However, due to factors such as changes in the external environment, personnel scheduling, and rising costs, manual operation is not always feasible. AI can now be used for such monotonous, repetitive, and tedious tasks. In the context of practical application deployment, there exist target-driven search tasks, exemplified by personnel rescue operations within disaster environments. In these domains, autonomous exploration by robots and environmental mapping are closely related challenges.
In the realm of autonomous robotic exploration, the selection of appropriate local target points is crucial for minimizing the time cost to reach the final destination. Clustering methods can be utilized to extract cluster points (CPs) from laser sensor data, which are then evaluated using a heuristic function to determine the most optimal local target points. Furthermore, with the evolution of AI, deep reinforcement learning (DRL) has become a pivotal element in robot navigation. In the aspect of local navigation, dynamic environment transfer learning offers an enhancement over the static obstacle avoidance models previously employed, 2 leading to reduced training durations and an improved capacity for exploration. Previous study 3 has achieved exploration tasks concerning local target points but lacked necessary decision-making and control strategies, making it challenging to ensure safety and avoid becoming trapped in local optima in complex dynamic environments.
Inspired by the aforementioned backdrop, we introduce a fully autonomous exploration system driven by robot-independent decision-making, aiming to achieve secure navigation in intricate environments. This approach relies solely on two-dimensional (2D) laser data without the need for supplementary sensors. The primary contributions of this article can be summarized as follows:
By leveraging transfer learning, we enhance the capability of a neural network model originally designed for static environment obstacle avoidance to handle dynamic obstacles. We employ clustering algorithms to label local target points in the surrounding environment, reducing redundant target points and accelerating the exploration process. We conducted simulation experiments to evaluate the proposed transfer learning method, combining the enhanced model with clustering algorithms and introducing cluster autonomous exploration (CAE). Ultimately, we applied this approach to an actual robot, demonstrating its feasibility by comparing the outcomes with those of prior research.
In the upcoming sections, we will explore the technical intricacies of the proposed approach. Initially, the related work section will present a thorough analysis of prior efforts in DRL and transfer learning. Following that, the Methodology section will offer a comprehensive elucidation of the transfer learning technique aimed at enhancing dynamic obstacle avoidance capabilities. This will encompass its foundational model in static environments as well as enhancements tailored for dynamic environments. Furthermore, we will elucidate on generating CPs through clustering methods in a local perceptual environment and selecting appropriate local target points using heuristic approaches. Subsequently, within the validation experiments, we will delineate the setup and outcomes of simulation trials, demonstrating the application of the proposed approach through real robot experimental data. Lastly, we will recapitulate the content discussed in this article and deliberate on potential avenues for future research.
Related works
In the field of mobile robotics, environment exploration and target navigation have always been significant topics of research.4–7 In previous works, various sensors, such as laser, depth camera, or their fusion, were used to enhance the perception and exploration capabilities of robots, enabling simultaneous localization and mapping (SLAM). Most of the previous works required manual map creation as a prerequisite for development. According to Zhu et al., 8 exploration of the surrounding environment was achieved by tracking predefined targets using red green blue camera images. Nevertheless, this approach only partially reduces the need for human intervention.
To reduce human intervention and enable autonomous exploration of robots, recent studies have extensively applied DRL, which guides robots’ decision-making and action selection through neural networks. For example, according to Chen et al., 9 researchers achieved obstacle avoidance in static environments by passing sensor information of the environment to a neural network and setting rewards and state space. The study by Kiran et al. 10 compared different DRL algorithms to improve the convergence speed of models for specific tasks. Furthermore, to enhance learning efficiency and adaptability to new environments, transfer learning methods were used by Kebria et al., 11 applying pretrained models to other tasks’ objectives, thereby reducing the pretraining cost of DRL. However, in the field of reinforcement learning, this technique faces more complex challenges and is still under development. Researchers by Chen et al., 9 Wenzel et al., 12 and Lee and Lee, 13 achieved better dynamic obstacle avoidance through sensor fusion, incorporating techniques like camera-based dynamic recognition and laser-based distance measurement. Zhang et al. 14 employed clustering techniques to address the intricate motion trajectories formed by tracking specific feature points or objects in video sequences. Martins et al. 15 employed clustering methods to generate optional local clustering target points (PCs) to assist in navigation planning. The clustering approaches discuss in these works serve as training data for relevant learning models rather than being directly utilized in navigation planning. According to Devo et al., 16 a right wall-following strategy is implemented in a maze environment by combining visual and laser information, but this strategy is applicable only to specific scenarios and is not suitable for complex environments. Li et al. 17 proposed a pretraining and fine-tuning transfer learning method for robot navigation tasks in unknown environments. They use a pretrained model based on the DRL and fine-tune it in different simulated and real environments, achieving efficient navigation performance. However, the fine-tuning method used in this paper is based on the demonstration learning, requires expert demonstrations, and may suffer from inconsistent demonstration quality and insufficient quantity. The approach presented by Cimurs et al. 18 combines DRL with points of interest (POI) for global destination exploration (GDAE), which has greatly inspired our work. However, the local planning model that this method employs exhibits poor performance in dynamic environments. Additionally, while the integration of POI enhances the overall exploration capability of the system, it also introduces a significant number of redundant points, thereby reducing the exploration efficiency in certain specific environments. A detailed comparison is conducted in the subsequent experimental section. Patel et al. 19 employed the dynamic window approach algorithm as a value function to assist DRL, effectively achieving path planning. This approach also inspires the possibility of enhancing the dynamic obstacle avoidance capability of DRL models through the design of value functions.
Although the aforementioned papers gradually introduced ideas for autonomous exploration, they lack considerations for safety, model robustness, portability from simulation models to real robots, and local optima during the navigation process. Additionally, there is a lack of solutions for the significant time consumption issue of reinforcement learning in simulation experiments.
Therefore, this article’s central concept involves transferring a pretrained model, integrating 2D laser technology and optimized global navigation strategies for real-time dynamic obstacle avoidance. To enhance exploration efficiency and minimize redundant target points, a tailored local target point generation method is employed. The primary goal of this method is to decrease the initial learning time and enhance the model’s adaptability in intricate environments. By leveraging an optimized global navigation strategy, it effectively tackles the challenge of mapless autonomous exploration for mobile robots. This approach provides efficiency, autonomy, and adaptability advantages while reducing the initial learning investment and improving exploration safety in unfamiliar settings. The fundamental principle of autonomous exploration is visually represented in Figure 1.

Visual representation of the principle behind the autonomous navigation system. The figure illustrates the configuration of the robot and the components and data flow of the global and local navigation modules within the autonomous navigation system. The visualizations in the middle and right sections provide a description of the implementation principles for global and local navigation, respectively.
Methodology
To achieve mapless autonomous exploration and navigation of robots, this study introduces cluster autonomous exploration (CAE), consisting primarily of two key components: local navigation based on the transfer DRL and global navigation. During the global navigation phase, distance measurements are conducted using 2D laser, and a clustering algorithm is employed to assess the current environment. This facilitates the identification of suitable CPs as optional target points for navigation and promotes map generation during this process. The task of local navigation is achieved by a transfer learning-based model, ensuring navigation towards selected local target points while avoiding dynamic obstacles. By integrating these two components, the robot can adeptly maneuver around dynamic obstacles, progress along the path delineated by local target points, and ultimately reach the global target point.
Global navigation
To enable the robot to navigate toward a predefined final target point, we need to select suitable intermediate local navigation target points from the clustered target points. However, in mapless autonomous exploration, obtaining the optimal path is not feasible. Therefore, the robot needs to simultaneously accomplish two tasks: exploring the local environment and progressing toward the final target point. In this process, the robot may encounter dynamic obstacles or become trapped in locally optimal environments such as dead ends. Hence, the robot needs to not only avoid dynamic obstacles but also search for alternative paths when encountering locally optimal environments. To achieve this, we need to acquire potential cluster target points in the environment and store them for future planning.
In this study, we employ two methods to obtain new cluster target points:
Obtaining through real-time laser data: We cluster data within a specified range to obtain potential cluster target points. Candidate target points are then scaled by a pre-defined proportion and incorporated into the environment. This method effectively reduces redundant target points compared to exploration methods such as the rapidly exploring random tree (RRT) algorithm, information gain, and POI. Moreover, it is more conducive for subsequent transfer learning models to perform dynamic obstacle avoidance tasks. Drawing inspiration from the POI method, we make judgments regarding points beyond the laser measurement range. If the number of consecutive inf values exceeds a predefined threshold, we label those points as potential target points. Figure 2 illustrates the comparison between cluster target points and POI.

In both figures, blue dots represent optional local target points, and green dots indicate the currently selected target points.
Figure 2(a) presents the POI extracted from the environment during the initial phase. Figure 2(b) showcases the CPs obtained through the clustering algorithm. Comparing these two figures, we observe that the POI method extracts more target points, which implies a decrease in exploration efficiency, while the CPs are more concentrated. Figure 2(a) exhibits more POI that can have higher fault tolerance in map exploration, but it also introduces redundant points. On the other hand, Figure 2(b) demonstrates moderately suitable CPs that are more applicable in pre-defined scenarios and are easier to integrate with transfer learning models.
Obtain potential cluster target points

In Algorithm 1, when extracting clustered points from normalized laser data, we introduce a parameter
Figure 3 clearly illustrates the difference between cluster target points and POI.
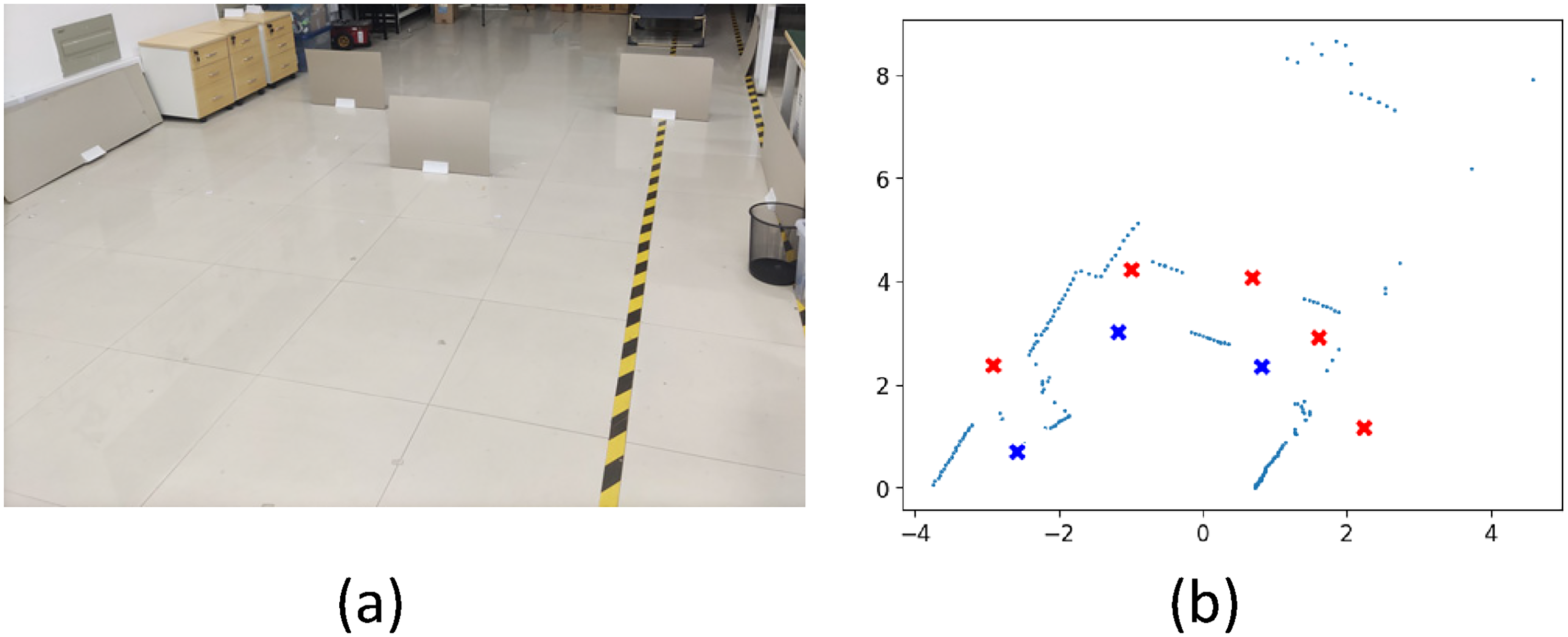
Comparison between laser information and target point generation methods: (a) shows a photograph of the real environment, while (b) displays the laser scan results in this environment, where red cross marks represent points of interest (POI), and blue cross marks represent clustered points.
To further align with the DRL obstacle avoidance model and retain a maximum number of exploration target points, the configuration of clustered points, as opposed to the POI method, can offer increased clearance for obstacle avoidance around local target points, facilitating more convenient dynamic obstacle avoidance.
Once we have obtained usable CPs, the next step is to select appropriate target points for local navigation. In this study, we adopt an evaluation method using a heuristic function (
Local navigation
In a planning-based navigation stack, local motion is executed based on a local planner. In our approach, we replace this layer with a neural network. By combining the preprocessing model used for static obstacle navigation with the decision-making principles of transfer learning, we achieve dynamic obstacle navigation that adapts to changing environments. First, the neural network architecture of the preprocessing model is based on the twin-delayed deep deterministic policy gradient (TD3) for training the motion policy,20,21 which has been implemented in a simulation environment. TD3 is an actor–critic network that allows actions to be executed in a continuous action space, as illustrated in Figure 4.

TD3 network structure with actor and critic components. Layer types and their corresponding parameters are labeled within the layers. TFC layers represent transformation fully connected layers (
The model takes input states consisting of 2D laser data from the frontal direction and target point polar coordinates. The neural network consists of an actor network and two critic networks. The actor network comprises two fully connected (FC) layers followed by rectified linear unit (ReLU) activation functions. It is then connected to the output layer, which outputs the robot’s linear velocity (
The state-action of the actor is evaluated by two critic networks with identical structures. In this network, the state and action are used as inputs. The state is fed into a FC layer followed by a ReLU activation function with an output 
Based on previous research,
22
transfer learning can utilize the preprocessing model as

Workflow of transfer learning applied to the twin-delayed deep deterministic policy gradient (TD3) neural network.
Due to the differences between the source and target domains, transfer learning can be facilitated by designing a reward function 
In the article referred to in the previous section 18 , we were inspired to modify the reward function of the source domain to address the issue of sparse rewards in traditional reward functions. In this study, an artificial potential field was introduced into the reward function to guide the robot through navigation tasks by the change in potential energy and applied in the context of transfer learning. However, such a reward function design did not adequately address complex unknown dynamic environments. During the experimental observations on the dynamic obstacle avoidance task using the preprocessing model, we found that the agent’s judgment on dynamic obstacles in the frontal direction was not sufficiently accurate. It could only avoid dynamic obstacles from the side that did not change direction. Based on this characteristic of the preprocessing model, we referred to the time-to-enter (TTE) decision-making approach by Noh 23 and designed a time-to-collision (TTC) metric for danger assessment. TTC represents the time it takes for the robot to reach the nearest obstacle at its current position and velocity, taking into account the robot’s own collision volume. The region divisions are illustrated in Figure 6:

This picture shows the time-to-collision (TTC) decision-making area centered on the robot.
In Figure 6, the regions outside the yellow area are deemed safe (i.e. the red portion), which preserves the reward settings of the pre-trained model. The green area signifies the robot’s hazardous zone, corresponding to a region size of 
In equation (5), derived from the aforementioned TTC strategy, delineates the correlation between various distance regions and time 
Through the above settings, we meet the requirements for reward value setting in transfer learning. To guide the navigation policy toward the given goal, we adopt the delayed attribute reward method for calculation:
Exploration
Autonomous exploration

In Algorithm 2,
Experiments
To verify the excellent performance of transfer learning on the model in the target domain task and to accomplish the exploration of global goal points through the clustering method, we conducted experiments in different complex environments.
Preparation
In this study, we used a laptop with an NVIDIA GTX 1050 graphics card, 8 GB of RAM, and an Intel Core i5-7300HQ CPU for transfer learning of the preprocessing model. The simulation environment used to train the model is based on the robot operating system (ROS), specifically version noetic. Due to the deployment of the physical mobile base as Turtlebot2, in order to enhance deployment on actual robots, the simulation model will also conducted deployment experiments using the Turtlebot2 model. The experimental results showed that the transfer learning method can also perform well in low-spec systems. First, we prepared the preprocessing model required for transfer learning. We trained the TD3 preprocessing model for 750 episodes in the Gazebo simulation environment, which took
To perform transfer learning on the pretrained model, we designed a new simulated environment with a size of

(a) and (b) illustrate the training simulation environment. The blue area represents the input laser readings and range. At the beginning of each training instance depicted in the figures, the robot undergoes random initial position changes. Additionally, the dynamic pedestrians in the figures possess collision attributes, further enhancing the randomization of the training data. (c) and (d) showed the effect curve of transfer learning.
After 8 h of transfer training, the pretrained model converged. The curve in Figure 7(c) represents the average reward value used to evaluate the learning performance of the agent. The green curve represents the training without using the pretrained model, directly training with the modified policy. Although it eventually converged, it taked a relatively long time and does not meet the requirement of reducing training costs. The blue curve represents the training using the pretrained model while still following the previous policy. Although this model showed a trend of convergence, the obtained expected value significantly deviated from the actual value, indicating that the agent had not fully mastered the skill of dynamic obstacle avoidance. The red curve represents the convergence after using the pretrained model and applying transfer learning, demonstrating the fastest convergence among the three curves and proving the feasibility of this method.
Dynamic obstacle avoidance experiment
To further examined the capabilities of the pretrained model and the model after transfer learning in dynamic obstacle avoidance, we conducted dynamic obstacle avoidance tests in a simulation environment, as shown in Figure 8.

Simulation test environment. (a) Testing obstacle avoidance capability of different models in front of the robot. (b) Testing obstacle avoidance capability of different models with multiple side obstacles. (c) illustrates the bar chart depicting obstacle avoidance success rates for various models within two simulated environments. Here, env 1 corresponds to the environment depicted in (a), while env 2 corresponds to the environment shown in (b).
From Figure 8, it could be observed that the success rate of the pretrained model in frontal obstacle avoidance is relatively low, while the success rate of side obstacle avoidance is higher but still does not achieve high reliability. When the original policy was directly applied to dynamic environments for obstacle avoidance, the avoidance performance did not improve and even decreased. However, by using the transfer model optimized with the TTC strategy, both frontal and side obstacle avoidance showed some improvement and alleviate the burden of subsequent program optimization.
Upon the application of the aforementioned models to an actual robot, their performance proved to be equally remarkable, as depicted in Figure 9. For the control of the actual robot, remote communication was facilitated by using a laptop and an industrial computer. The configuration of the laptop was identical to that used during the model training phase. The mobile robot’s chassis was the Turtlebot2, equipped with a Hokuyo laser range finder to perceive local environmental information, under which settings the relevant experiments with the actual robot were conducted.

The performance of the transfer learning model was evaluated in different scenarios: (a) Obstacle avoidance capability of the transfer model in static scenes with continuous transformations (Image 1). (b) Obstacle avoidance ability of the transfer model when facing pedestrians (Image 2). (c) Obstacle avoidance experiment between two robots. The white robot represents a commercial robot, and the black robot is a Turtlebot2 robot equipped with the transfer model (Image 3). (d) presents a bar graph illustrating the obstacle avoidance success rates of various models across three distinct real-world scenarios, where env 1, env 2, and env 3 correspond to the environments depicted in (a), (b), and (c), respectively.
In Figure 9(a) to (c), the green dashed line delineates the trajectory of a robot integrated with a DLR model, while red denotes the pedestrian trajectories, and yellow signifies the movement trajectories of diverse robots. As depicted in Figure 9(d), the results from 10 tests executed in each scenario reveal that the transfer model optimized using the TTC strategy attains notably elevated obstacle avoidance success rates in the actual environment when compared to the remaining two models. This outcome aligned with the findings of analogous comparative experiments conducted within the simulation environment.
Images a 1 and 2 vividly illustrated the excellent obstacle avoidance capability of the transfer learning model in various environments. In Image 3, the white commercial robot relies on map, laser, and visual information for obstacle avoidance. On the other hand, the Turtlebot2 robot performed obstacle avoidance by executing commands from the transfer model. Compared to the commercial robot, the Turtlebot2 robot clearly demonstrated superior obstacle avoidance performance and smoother operation.
Global objective point exploration experiment
To assessed the performance of the proposed exploration method, we compared it with other exploration methods in different indoor environments. We refer to the method presented in this article as CAE, which combines transfer reinforcement learning with a heuristic clustering-based global exploration strategy to achieve global navigation objectives.
In the global exploration experiments, the global target points were selected manually. To assess the robustness of the search algorithms under consideration, we specifically opted for global target points that are challenging to reach using only local target points. These selected locations are all accessible in real-world environments, albeit with varying degrees of difficulty. We compared three methods: the CAE proposed in this article, the GDAE mentioned by Cimurs et al. 18 and the usage of the Dijkstra algorithm as a standard after constructing a map. Each method was tested five times, and the average distance traveled (Av.D.) in meters, average travel time (Av.T.) in seconds, the total number of potential local target points generated during exploration of an average global target point task (Av.p), the map size in square meters, and the number of times the method reached the final objective point was recorded. The recorded map size was calculated using only known pixels.
First, let us consider the first environment shown in Figure 10, which consisted of a simple, smooth corridor, and multiple local extremum points. The environment had minimal human activity and static obstacles. The final objective was set at (45,

Grid map of a corridor and path trajectories of various algorithms for different global exploration strategies in narrow indoor environments.
It was observed that there was not much difference between the two algorithms for simple indoor environments. This was because the environment was too homogeneous, and the generation of target points was similar. To further highlight the difference in target point generation between the two algorithms, we selected a more complex environment as the experimental site. This was a cafeteria with numerous tables, chairs, and pedestrians, and the target point was set at (27,

Exploration of target points in a complex and dynamic cafeteria environment using GDAE and CAE algorithms. (a) Photograph of the experimental setup. (b) Exploration results achieved by GDAE. (c) Exploration results achieved by CAE. In Figure 11, purple represents the starting point, and green represents the endpoint. GDAE: goal-driven autonomous exploration; CAE: cluster autonomous exploration.
From Figure 11, it can be observed that the exploration path generated by GDAE, as depicted in Figure 11(b), was more intricate. This could be attributed to the distribution of tables and chairs in the environment, which resulted in an excessive generation of target points, consequently leading to a longer exploration time. On the other hand, the exploration path produced by CAE, illustrated in Figure 11(c), appeared relatively smoother. This could be attributed to the adoption of a clustering approach to obtain target points, which, to a pre-defined extent, enhanced the efficiency of exploration. The experimental data for this particular site was also collected through five trials, as shown in Table 2.
Experimental results in narrow indoor environments.

GDAE: goal-driven autonomous exploration; CAE: cluster autonomous exploration; Av.T.: average travel time; Av.D.: average distance traveled; Av.p: average global target point task.
Complex dynamic environmental experimental results.

GDAE: goal-driven autonomous exploration; CAE: cluster autonomous exploration; Av.T.: average travel time; Av.D.: average distance traveled; Av.p: average global target point task.
From the data in Table 2, it can be observed that both algorithms reached the final target point in all five experiments. Under the GDAE algorithm, the number of candidate target points increased, resulting in a larger exploration map range. However, the time taken to reach the target point also increased. On the other hand, in the CAE algorithm proposed in this article, the time taken to reach the target point was shorter, despite the decrease in the number of candidate target points, which led to a corresponding reduction in the exploration map range.
Finally, to conduct experiments in a typical indoor environment, a densely populated underground parking lot with minimal static obstacles was chosen to conduct the experiments. Furthermore, the target points were set in unreachable areas. Five experiments were conducted, as shown in Figure 12.

Mapping process in an underground parking garage used GDAE and CAE. (a) Exploration results achieved by GDAE. (b) Exploration results obtained by CAE. In Figure 12, purple represents the starting point, and green represents the endpoint. GDAE: goal-driven autonomous exploration; CAE: cluster autonomous exploration.
From Figure 12, it could be observed that in an open environment with the additional influence of pedestrian traffic, the path generated by CAE is more complex compared to the path generated by GDAE, indicating a lower exploration efficiency of the CAE algorithm. Detailed data can be found in Table 3.
Complex dynamic environmental experimental results.

GDAE: goal-driven autonomous exploration; CAE: cluster autonomous exploration; Av.T.: average travel time; Av.D.: average distance traveled; Av.p: average global target point task.
From Table 3, it can be seen that GDAE, due to its larger number of candidate target points, achieved a shorter time and path compared to the CAE algorithm. However, this inevitably results in a computational burden, which reduced the flexibility of the robot.
Based on the three experimental results mentioned above, CAE demonstrated significant advantages over GDAE in more complex areas with moderate human traffic.
Conclusion
This article introduces a target-driven robot autonomous exploration system based on transfer learning and refines its conclusions. In the relevant experiments, this system demonstrates the ability to address static and dynamic obstacles in local environments, as well as global navigation strategies. The experimental results indicate that transfer learning can reduce initial training costs, enable learning of new tasks, and reduce human intervention. The combination of these two approaches makes global exploration possible.
To further improve this system, the following are potential future research directions:
Multirobot collaboration
24
: Exploring the direction of multiple robots was a promising research area. By enabling collaboration and information sharing among multiple robots, the efficiency and robustness of global exploration could be enhanced. Future research could focus on issues such as communication between multiple robots, task allocation, and collaborative path planning to achieve a higher level of global exploration capability. Improvements in reinforcement learning algorithms
25
: Although transfer learning had advantages in reducing initial training costs, improving reinforcement learning algorithms themselves was also an important research direction. Researchers could explore new algorithms and techniques to enhance the robot’s learning efficiency, generalization capability, and stability. Multimodal perception
26
: Integrating multiple sensory modalities, such as vision, sound, and lasers, can provide a more comprehensive environmental perception capability. Future research can explore how to combine multimodal perception with transfer learning to enhance the robot’s environmental understanding and decision-making ability.
These directions for improvement will further enhance the performance and application scope of the robot autonomous exploration system, promoting its practical application and development in the real world.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project is supported by XXX.