
Abstract
In the complex marine environment, target recognition is difficult, and the real-time detection has a slow speed. In this article, a target recognition method combining underwater generative adversarial network and improved YOLOv4 is proposed, which is named M-YOLOv4. Firstly, the images collected by the underwater inspection robot are enhanced using the underwater generative adversarial network algorithm to obtain the training datasets. Secondly, the YOLOv4 target detection algorithm combines the feature extraction network of MoblieNetv3 for lightweight processing, which reduces the network model size, and reduces the number of algorithm calculations and parameters. Then, change the size of the spatial pyramid pooling module pooling kernel, which can enlarge receptive field and integrate characteristics of different receptive fields. Finally, the processed datasets are transferred to the improved M-YOLOv4 algorithm for training, and the trained model is transplanted to the Jetson Nano hardware device for real-time detection. The results of experiments show that the mean average precision value of the improved M-YOLOv4 recognition is 90.77%, which is 2.02% higher than that of the unimproved one. The frame per second value of the lightweight YOLOv4 algorithm with MobileNetv3 is 27, an increase of 12 compared with YOLOv4. The improved M-YOLOv4 algorithm can perform accurate detection of marine multi-targets on embedded devices.
Introduction
The ocean is an important resource and space for human survival and development. To make marine resources better develop and utilize, marine ranching has begun to receive attention. 1,2 Marine ranching and offshore cage culture need to pay attention to every move in the area at any time. Monitoring, fishing, and other work are mainly completed by underwater workers. The traditional method is not only costly but also dangerous, and it cannot timely know the underwater situation of creatures. Once problems are found, it was too late and the marine organisms were already dead. With the continuous development of intelligent technology, underwater inspection robots are used to carry out underwater fishing, monitoring, recognition, and so on. It is of great significance to reduce the labor intensity, risk of marine organism fishing, and the cost of fishing. The technical core of this work is the target detection algorithm.
With the development of deep learning technology rapidly, 3 target detection algorithm has been widely used in many fields 4 –7 and achieved some results. Researchers at home and abroad have progressively applied deep learning-based target recognition techniques to ocean target detection. Lin et al. 8 used the improved Mask Region Convolutional Neural Network (RCNN) to detect ships, with good results for small targets at long-distance, but the mask cannot cover the target edge well. Han et al. 9 proposed real-time classification and detection of marine organisms based on improved HyperNet method and Faster RCNN. The above literatures use Mask RCNN and Faster RCNN algorithm for underwater target detection, which belongs to the two-stage target detection algorithm. The images of candidate regions need to be extracted, which detection speed is slow, and takes up a lot of memory for training. It cannot meet the requirements for real-time detection of underwater multitargets. In recent years, the one-stage target detection algorithm with simpler network model has been developed, and some research results have been achieved. Ma et al. 10 proposed an improved Single Shot MultiBox Detector (SSD) and depthwise separable convolution algorithm to detect sea cucumbers. Multiscale Retinex was used to enhance images, and MobileNet optimization model was introduced to improve the detection speed and accuracy. Jalal et al. 11 proposed a method combining optical flow and Gaussian mixture model with YOLO network to detect and classify fish. Park and Kang 12 proposed an underwater fish identification method based on YOLOv2 network and genetic algorithm, which can accurately classify and count fish, and the detection accuracy is low. Mathias et al. 13 proposed a fusion method of visual features and Gaussian mixture models with YOLOv3 network to improve the efficiency of underwater target detection. Fu et al. 14 proposed an improved YOLOv4 marine object detection method combined with Convolutional Block Attention Module (CBAM), which add a convolutional attention model to the YOLOv4 network. It increases the weight of useful features, while suppresses the classification of invalid features to improve the detection accuracy. Zhang et al. 15 proposed a lightweight underwater target detection method based on YOLOv4 and multiscale attention feature fusion. It uses MobileNetv2 as the backbone network and introduces an attention mechanism into Feature Pyramid Networks (FPN) module to improve the detection speed and accuracy of the model. According to the literature, 10 –15 in the one-stage target detection algorithm, YOLOv4 16 has a better detection effect on marine targets, and the lightweight MobileNet network is introduced to improve the detection speed. The lightweight algorithm has higher detection accuracy and detection speed for real-time detection.
In practical applications, due to the complex marine environment, the collected images are not clear. They have a certain impact on the feature learning and recognition of underwater targets. Therefore, the images are enhanced preprocessing operation before training and detection. At present, image enhancement methods include traditional image enhancement methods and deep learning-based methods. 17 Traditional image enhancement methods include histogram equalization method, Retinex theory, 18 and so on, which mainly enhance images from aspects of improving contrast and brightness. The underwater images are clearer, but the effect is not strong. There are problems of color distortion and much noise. Image enhancement algorithms based on deep learning 19 include convolutional neural network (CNN), 20 underwater convolutional neural network, 21 and water generative adversarial network, 22 which can eliminate the blue–green bias and alleviate the problem of image distortion. And the color of the generated image is close to the color of the target image. This article uses the underwater generative adversarial network (UGAN) image enhancement algorithm 23 to enhance the unclear pictures obtained and obtain images with better visual effects. It is conducive to feature learning and improves the accuracy of target recognition.
Marine multitarget recognition requires not only high real-time performance but also high accuracy. Real-time target detection needs to embed algorithms into Jetson Nano hardware devices. Compared with computers, its computing power is limited to a certain extent. At present, the YOLOv4 target detection algorithm is difficult to balance the relationship between speed and accuracy. The improved M-YOLOv4 algorithm with less hardware requirements is used for marine multitarget recognition. This algorithm uses the lightweight neural network MobileNetv3 24 to replace the CSPDarknet53 25 network in the feature extraction part of the YOLOv4 algorithm, and improves the SPP 26 structure of YOLOv4. Changing the SPP kernel size and increasing the range of feature extraction are conducive to the recognition of small targets and multiple targets and improve the missed detection. The proposed image enhancement and improved M-YOLOv4 algorithm can balance the speed and accuracy of underwater target recognition in complex marine environments.
Image enhancement
For problems of unclear marine biological images collected by the underwater inspection robot, the images are enhanced using the UGAN algorithm, which is a deep learning-based underwater image enhancement method. UGAN can eliminate the blue–green bias and make the image features more obvious, which is easy to extract the features of the network later. The UGAN algorithm requires the use of paired training data, so the underwater images need ground truth images corresponding to them. Cycle-consistent generative adversarial network (CycleGAN) is used as a distortion model to generate distorted images from undistorted images and generate paired images for training.
Principle of CycleGAN algorithm
Given two datasets X and Y, X is a set of undistorted underwater images, Y is a set of underwater images with distortion, IC is an undistorted underwater image, and ID is the same image with distortion, where IC ∈ X, ID ∈ Y, and the learn function f: ID → IC . All images in X use the F mapping function (F: X → Y) to obtain distorted images to generate images that look like they are underwater, while ground truth values are retained to generate paired of training image data. Figure 1 shows the paired samples generated from CycleGAN.

Data pair (a) undistorted image (b) distorted image generated using CycleGAN. CycleGAN: cycle-consistent generative adversarial network.
The clear underwater images are learned from the underwater images taken in the real environment through CycleGAN. The generated pairs of images are used as the training dataset for the UGAN underwater image enhancement algorithm.
Principle of UGAN algorithm
UGAN algorithm is used to train the data pairs generated by CycleGAN, which can recover the missing color information and correct the existing color information. UGAN is improved from generative adversarial network (GAN), which is composed of generator network (G) and discriminator network (D). After the fuzzy underwater image is input to the generator network, the realistic image is output. The real images and the generated realistic images are transmitted to discriminator network and calculate the resulting expected probability. The output above 0.5 is true, and the output below 0.5 is false. The principle of GAN is shown in Figure 2.

GAN schematic diagram. GAN: generative adversarial network.
GAN formula is shown in (1)

In formula (1), the discriminator is assumed to be a classifier with an S-type cross entropy loss function, which may lead to problems such as vanishing gradient and mode collapse in practice. The disappearance of generator gradient and the improvement of discriminator make training difficult or impossible. Only one instance can fool the discriminator. To mitigate mode collapse and gradient disappearance, different loss functions are assumed for the discriminator. The objective function of UGAN is shown in formula (2)
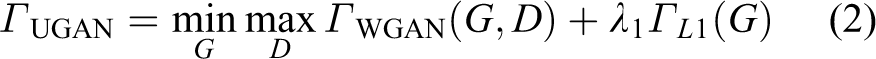
where

where
L1 loss is defined as shown in formula (4), which is designed to give G a basic realism and to capture low-level frequencies in the images

The marine biological images before and after enhancement by the UGAN algorithm are shown in Figure 3.

Image comparison before and after UGAN enhancement: (a) original marine organism images and (b) UGAN-enhanced marine organism images. UGAN: underwater generative adversarial network.
After using UGAN algorithm to process the collected marine biological images, the image quality is better, and the characteristics of marine life are more obvious.
YOLOv4 algorithm principle
The marine organism images collected by the underwater robot are preprocessed by the UGAN enhancement algorithm to make the images clearer and have better visual effects. The enhanced marine organism images are transmitted to improved M-YOLOv4 algorithm for image recognition.
YOLOv4 network structure
YOLOv4 algorithm is improved on YOLOv3 27 , which is composed of Backbone part, Neck and Head module. Feature extraction is performed on the transmitted marine target images using the CSPDarknet53 structure in the backbone network and then transmitted to the neck module for feature fusion. The feature fusion network includes the SPP structure and the Path Aggregation Network (PANet) 28 structure. In the PANet part, three feature layers of different scales are output to the head module, the obtained features are used for prediction, and the prediction results are obtained. The YOLOv4 network structure model is shown in Figure 4.
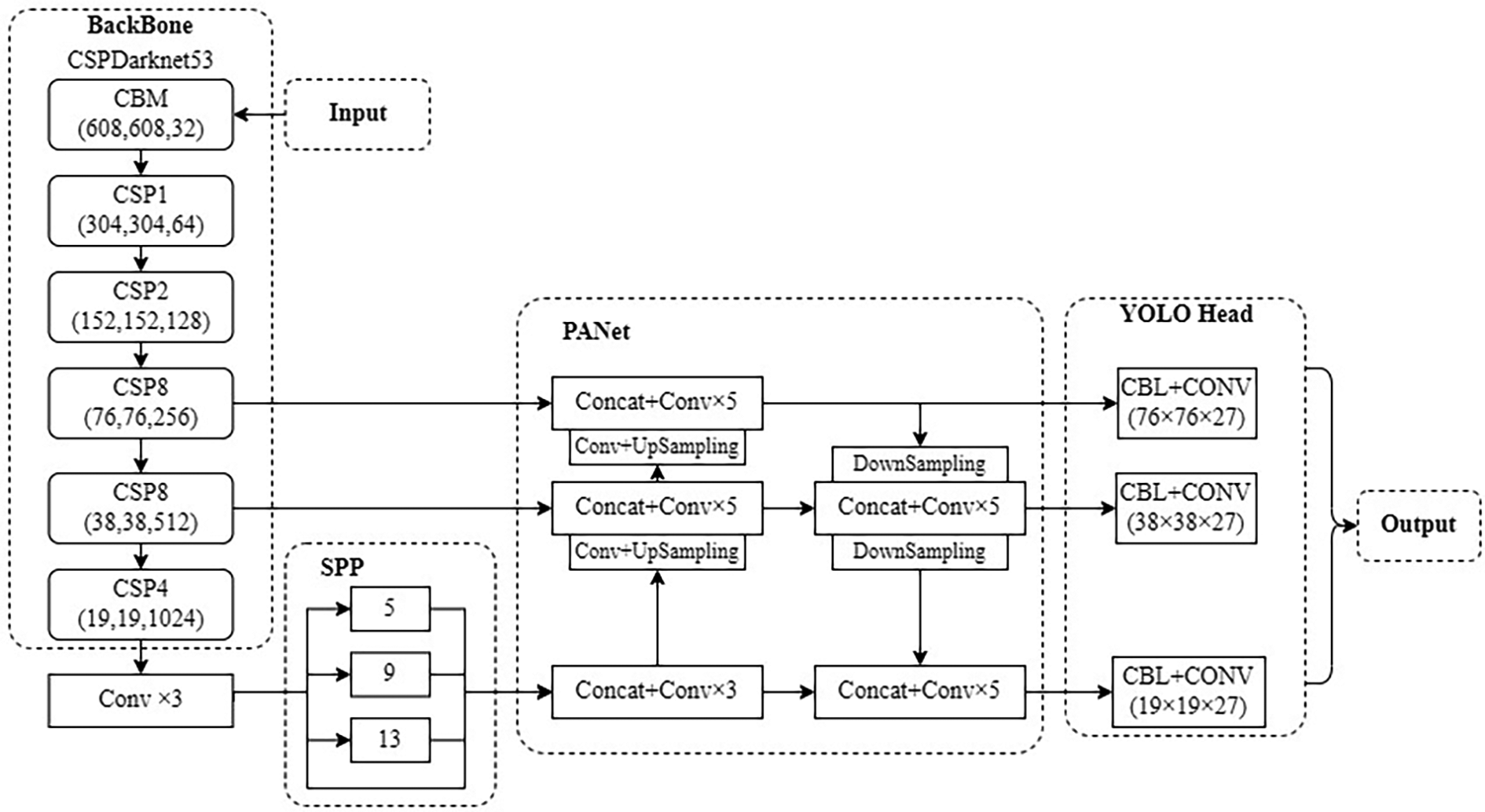
YOLOv4 network structure diagram.
In the backbone module, CSPDarknet53 network is composed of five large residual modules, each of which corresponds to 1, 2, 8, 8, and 4 small residual unit, respectively. The residual modules can reduce the number of parameters, which results in less computation. After dimensionality reduction, data training and feature extraction can be carried out more effectively and intuitively. It can also improve the depth of the neural network, thereby improving the performance of the network. The size of the transmitted image is stretched to 608 × 608. After five convolutions, the width and height of the images are continuously compressed, while the number of channels is continuously expanded. And finally, three output feature layers with scales of 76 × 76, 38 × 38 and 19 × 19 are obtained.
After the feature extraction in the backbone module, the extracted marine target features need to be fused in the neck module to improve target recognition ability. The SPP module is located after the CSPDarknet53 network. Four maxpooling layers form four vectors of different scales for multiscale feature fusion. CNN can input images of any size for training. The output feature layer of CSPDarknet53 is processed to widen the sensory field, enhance the extraction of feature maps, and effectively prevent overfitting. PANet up-samples the 19 × 19 feature map twice, and the results are stacked with the feature maps of 38 × 38 and 76 × 76, respectively, for convolution. And then a series of down-sampling and stacking convolution are carried out from bottom to top to fully integrate the features of three different scale feature maps. Finally, three effective feature layers of YOLO head with 19 × 19, 38 × 38, and 76 × 76 are output, respectively.
The three different scale feature layers extracted by PANet are transferred to YOLO head for classification and regression prediction. The feature layer contains prediction frame coordinates, categories, and confidence information. The sigmoid function is used to decode the category and confidence, and the complete IOU loss is used to predict the regression of the target frame. Set confidence threshold to screen out some anchor frames. The remaining anchor frames perform nonmaximum suppression operation and obtain marine life detection results.
Backbone network optimization
YOLOv4 structure has high detection accuracy in performance, but its model weight is large and slow in detection speed. It cannot meet the requirements of applying to embedded devices. Therefore, based on the idea of lightweight network, the backbone module is replaced by CSPDarknet53 with MobileNetv3 24 for feature extraction. MobileNetv3 is an improved network based on MobileNetv2. 29 It introduces a lightweight attention model of squeeze-and-excitation network structure, combines the depthwise separable convolution and inverse residual structures, and uses h-swish instead of swish as the activation function. It improves the computing efficiency of the network while reducing number of computation and parameters. And the performance of the network is improved.
In the MobileNet structure, the core algorithm is using depthwise separable convolution instead of standard convolution. According to the idea, depth separable convolution is used to replace some standard convolutions in PANet and YOLO head networks. Figure 5 shows the structure of standard convolution and depthwise separable convolution.

Structure diagram of standard convolution and depthwise separable convolution.
As shown in Figure 5, the size of input feature map is
The parameters used for the two convolutions are calculated, respectively, and the results are shown in formula (5) and formula (6)


where
The number of input channels is much smaller than the number of output channels, when performing standard convolution. Formula (7) is the ratio of formula (5) to formula (6)

In formula (7), the result of
SPP structure improvement
The size of the input marine target images is inconsistent with the requirements and should stretch and shrink the images. It will change the size of the images, so that the original image will be deformed. To make feature maps of any size can be converted into feature vectors of fixed size, introduce the SPP network. Specifically, the feature extracted images enter the SPP network, four kernels of different scales are used for maximum pooling operations, and the results of each pooling are output to the PANet structure after channel splicing.
The input image size is 608 × 608, the changes of feature map size is 608, 304, 152, 76, 38, and 19, and the output dimension is 19 × 19. After entering the SPP module, the pooling kernels with sizes of 1 × 1, 5 × 5, 9 × 9, and 13 × 13 are used for maxpooling and merge the feature maps of different scales. According to the characteristics of marine organisms, the multiscale maxpooling in the SPP network structure is improved to improve the accuracy of target detection. As shown in Figure 6, the kernel size of the Multi-scale Maxpooling is set to 1×1, 5×5, 11×11, 19×19 respectively, and generate four feature maps, then concat the four feature maps. The maxpooling uses the padding operation, and after pooling, the feature map size remains at 19 × 19 × 512. The improved SPP network structure increases the extraction range of feature extraction network and improves the extraction capability of target features. Thus, it reduces the influence of the complex marine environment on the effect of marine multitargets recognition, improves the recognition capability of marine biological targets, and reduces the occurrence of false detection and missed detection.

Improved SPP network structure diagram. SPP: spatial pyramid pooling.
Improved network structure is shown in Figure 7.

Improved M-YOLOv4 network structure diagram.
Analysis of results
Dataset and experimental environment
Some images of marine organism collected by underwater inspection robots in offshore marine ranches are used as the dataset of this article. There are four species of marine organism datasets, namely sea echinus, starfish, scallops, and holothurians. After the data are preprocessed to remove the useless images, 3408 images are used for training, of which the ratio of validation set to training set was 2:8.
The setup environment for the experiments is shown in Table 1.
The experimental environment set.

The dataset is transferred to the server for training, and the trained model is transferred to the Jetson Nano development board. The corresponding trained model file is optimized and compiled on the Jetson Nano development board. After completion, the model is converted from PyTorch format through neural network exchange format to TensorRT format. Then using the hardware development identify marine target.
The underwater inspection robot is used to real-time transmit marine organism images, explore and capture underwater target. The underwater inspection robot is shown in Figure 8. The buoyancy block adopts Continuous Fiber Reinforced Polymeric (CFRP) composite material structure, which has the characteristics of high-pressure resistance and corrosion resistance. The submersible power system adopts propeller propulsion, which can prevent foreign matters from winding. Its power is strong, and the maximum flow rate can reach 1.5 m/s. The battery compartment stores lithium batteries with large capacity, which can work continuously for 5 h. The protective frame is made of high-strength materials, which has the characteristics of wear resistance and corrosion resistance. The high-definition camera has IP68 level protection and 500w pixels. It integrates infrared and white light compensation lamps to collect and identify underwater biological images. Manipulators can be used to grasp underwater marine organisms and improve underwater operation capability.

Underwater inspection robot.
Experimental process
After the images collected by the underwater inspection robot are enhanced by the UGAN algorithm, they are transmitted to the improved M-YOLOv4 algorithm for training, and set the batch-size, learning rate, and iteration to train the optimal model for marine organism recognition. Batch-size is the number of samples in a batch. The larger the batch-size is, the faster the detection speed is, but the higher the hardware requirements are. According to the Graphic Processing Unit (GPU) display memory, after experiment, it is found that batch-size is set to 16 for the best detection results. The learning rate determines how fast the parameter moves to the optimal value. The appropriate learning rate should be able to converge as soon as possible on the premise of ensuring convergence. After many experiments with multiple learning rates, the best effect is to set the learning rate at 10−3. To make the loss function converge quickly, the experiment introduces the pretraining weight according to the idea of migration learning, so that it can extract effective features at the beginning. Then, freezing training is introduced to suppress overfitting in the training process, which can also speed up the training efficiency and prevent the weight from being damaged.
The experiment is divided into freezing stage and thawing stage. The first 60 iterations are the freezing stage, with learning rate of 10−3 and the step size of 16. The 60–140 iterations are the thawing stage. The learning rate is 10−4 and the step size is 8. The input images are 680 × 680 pixels, the confidence is 0.5, and the Intersection over Union (IOU) is 0.5. Because of the introduction of pretraining weights, the value of loss function first decreases rapidly and then gradually stabilized. The data are quickly fitted. After thawing, the data will rise slightly, then begin to decline, and finally tend to stable. The final loss function value will be lower than that before thawing. The lower the loss function value, the better the image recognition effect. Finally, the best loss function value with the best recognition is 2.26. Figure 9 is the loss function curve image.

Improved M-YOLOv4 loss function curve.
Evaluation parameters
Use mean average precision (mAP) as the model evaluation standard, and the calculation formula is (8). The AP is the evaluation precision of a single category, which is the area of the R-P curve enclosed by precision (P) and recall (R). The precision and recall formula are (9) and (10)
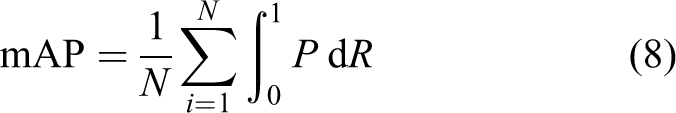


where TP is a positive example of recognition accuracy, FP is a positive example of recognition error, and FN is a negative example of recognition error.
Use frames per second (FPS) to evaluate the model detection speed. The more the FPS, the smoother the video will be and the faster the detection speed will be.
Result analysis
The improved M-YOLOv4 trains a model to identify marine targets. Figure 10 shows the mAP value of the improved M-YOLOv4 algorithm for the detection of four marine organisms. Table 2 shows their respective AP values, precision and recall rates.
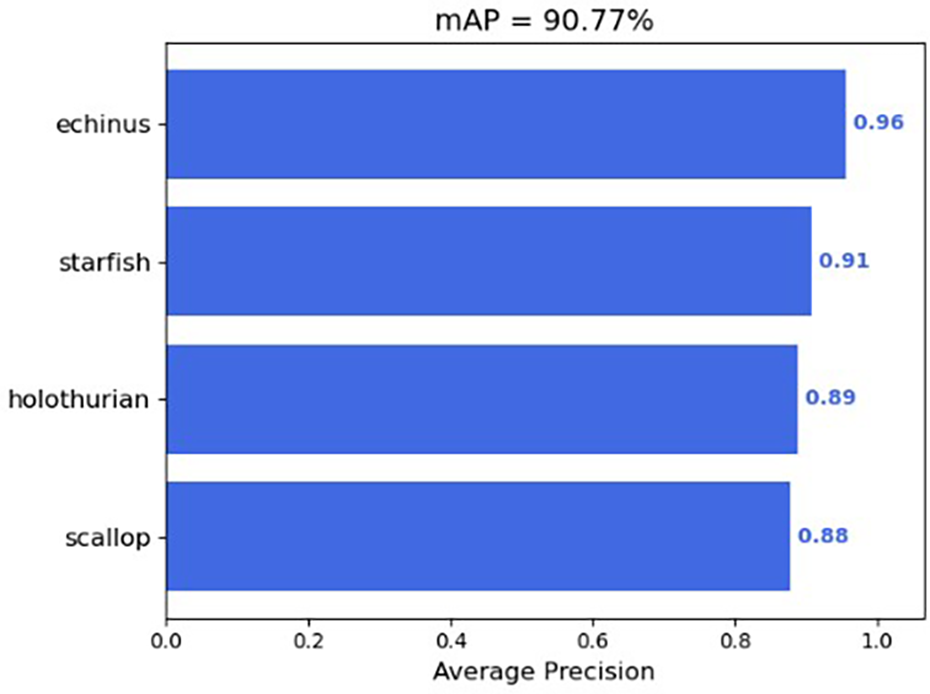
mAP value of the improved M-YOLOv4. mAP: mean average precision.
Improved M-YOLOv4 detection results.
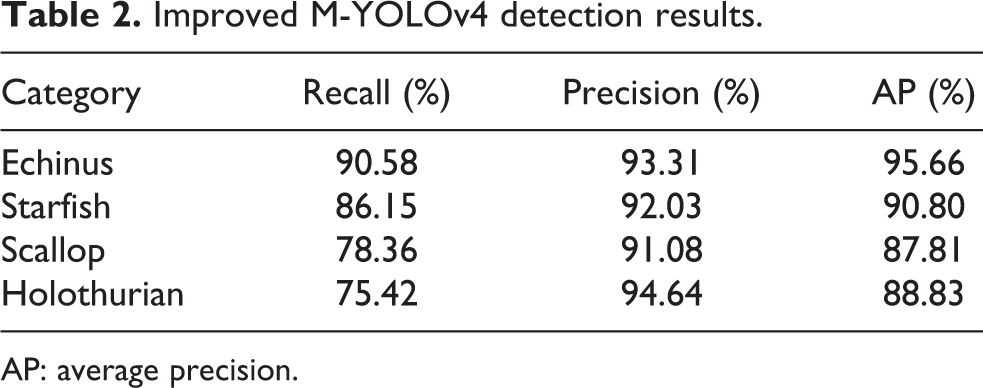
AP: average precision.
In Table 2, echinus has the highest AP value, while starfish, holothurian, and scallop have lower AP values in order of 95.66%, 90.80%, 88.83%, and 87.81%, respectively. Mainly because echinus has the largest number and largest proportion in the training set, while holothurians and scallops for a small proportion. So their recall rates are low, and the detection results are not good relatively.
Figure 11 shows the recognition results of improved M-YOLOv4 for marine multitarget organisms.

(a) and (b) Improved M-YOLOv4 algorithm detection results.
In Figure 11(a) and (b), there are four kinds of marine organisms, namely echinus, starfish, scallop, and holothurian, which are identified by green, purple, blue, and red boxes, respectively. The category and accuracy of marine organisms are shown in the upper left corner of the box. The improved M-YOLOv4 algorithm can accurately identify categories of marine organisms, and the accuracy of each marine organism is high. In Figure 11(a), some marine organisms are obscured, or the individuals are incomplete at the edge of the image. The recognition confidence can reach at least 0.75. In Figure 11(b), the marine environment is complex, the image is unclear, and the individual is small. The recognition confidence can reach at least 0.93. They all have good recognition effect. Therefore, the improved M-YOLOv4 algorithm can accurately identify small targets, multiple targets, occluded targets, and unclear targets with high accuracy.
Algorithm comparison
Comparison of target detection results of different algorithms
To compare the performance of the M-YOLOv4 algorithm with other mainstream target detection algorithms, a comparative experiment was conducted between the M-YOLOv4 algorithm and other algorithms. The detection results are shown in Table 3.
Comparison of target detection results of different algorithms.
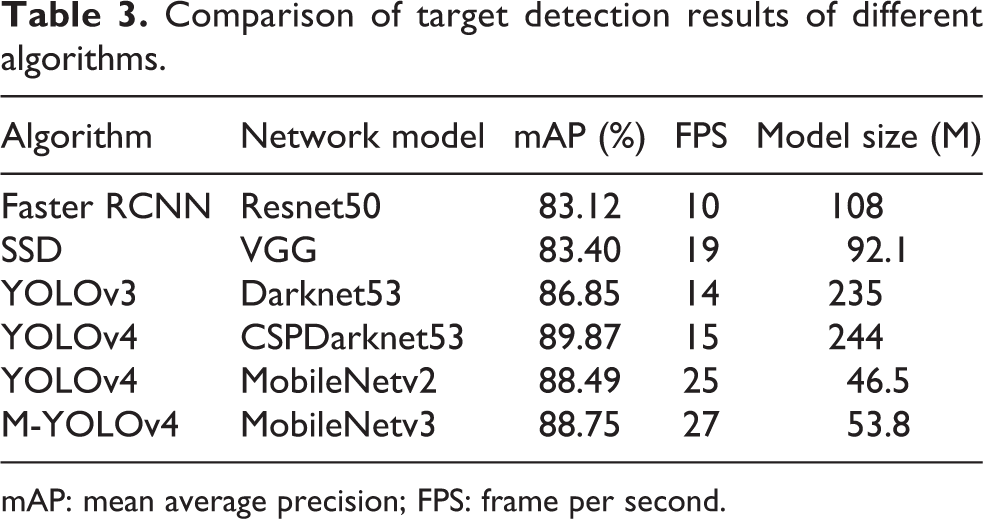
mAP: mean average precision; FPS: frame per second.
In Table 3, the detection results of Faster RCNN algorithm, SSD algorithm, and YOLO series algorithms are compared. Their mAP values are 83.12%, 83.40%, 86.85%, and 89.87%, respectively, among which the YOLOv4 algorithm has the highest mAP value, so it has better results for marine organism detection. Compared with other algorithms, the YOLOv4 model size is higher, but its FPS value is 15. The FPS value of YOLOv4 is 5 higher than that of Faster RCNN and 4 less than that of SSD. Therefore, YOLOv4 algorithm introduces the MobileNet network model to reduce the model size and increase the FPS. This results in increased the detection speed.
In the MobileNet series, the mAP value of MobileNetv2 is 88.49%, the mAP value of MobileNetv3 is 88.75%, and the FPS values are 25 and 27, respectively. Collectively, the YOLOv4 algorithm, which introduces the MobileNetv3 network model, is used for target detection.
Figure 12(a) to (c) is the video recognition results of MobileNetv3, MobileNetv2, and YOLOv4 algorithms on hardware devices, respectively. The upper left corner shows the detected transmission FPS. The FPS is 27.06, 26.39, and 15.57, respectively. The MobileNet network detects faster and can achieve better results in real-time detection.

(a) MobileNetv3 network detection result, (b) MobileNetv2 network detection result, and (c) YOLOv4 network detection result.
Ablation experiment and result analysis
For the sake of verify the optimization effect of the improved M-YOLOv4 algorithm, ablation experiments are conducted in this article. M-YOLOv4 has good results in detection speed. So as to improve its detection accuracy, this article preprocesses the image dataset using the enhancement algorithm based on the M-YOLOv4 algorithm. Improve the SPP module of M-YOLOv4 and change the maxpooling kernel from 1, 5, 9, 13 to 1, 5, 11, 19. The detection results of the M-YOLOv4 ablation experiment are shown in Table 4. Group 1 is the original M-YOLOv4 algorithm detection results, group 2 adds the UGAN enhancement algorithm, group 3 has the improvement of the SPP structure, and group 4 introduces UGAN enhancement algorithm and SPP improvement at the same time.
M-YOLOv4 ablation experiment.

UGAN: underwater generative adversarial network; mAP: mean average precision; SPP: spatial pyramid pooling.
In Table 4, the data of group 1 and group 2 verify the effect of adding the UGAN enhancement algorithm. The detection mAP values by the M-YOLOv4 algorithm without image enhancement and with the image enhanced by the UGAN algorithm are 88.75% and 90.12%. The detection result increases by 1.37% after enhancement with UGAN. The detection accuracy of starfish, scallops, and holothurian has been significantly improved. It shows that adding UGAN enhancement algorithm can recognize the fuzzy images that cannot be recognized originally.
In Table 4, the data of group 1 and group 3 verify the effect of the improved SPP structure. The improved algorithm has increased AP values for four marine organism detections. The AP values of echinus and starfish have increased by 0.24% and 0.52%, respectively. The AP values of scallops and holothurian have increased by 1% and 2.09%, respectively. Therefore, the overall mAP value is improved with an increase of 0.96%. It is verified that the improved SPP structure has a better effect on underwater target recognition.
Group 4 introduces the UGAN enhanced algorithm and improves the SPP structure at the same time. The detected mAP value is 90.77%, which is higher than the detection results of the first three groups of algorithms. Once again, the availability of UGAN enhanced algorithm and improved SPP structure is verified. The improved M-YOLOv4 algorithm can detect biological multitarget in complex marine environment.
Improve M-YOLOv4 detection results
Compare the detection results of improved M-YOLOv4 algorithm before and after UGAN algorithm enhancement. Figure 13(a) and (b) shows the recognition results of the original and the enhanced marine organism images, respectively.

(a) The recognition result without UGAN image enhancement and (b) the recognition result with UGAN image enhancement. UGAN: underwater generative adversarial network.
In Figure 13, the same images are detected by the enhanced and unenhanced models, respectively, both of which can accurately identify marine organism species with high confidence. In Figure 13(a), there is a phenomenon of missed detection in target recognition, which is not good for the fuzzy target recognition. In Figure 13(b), model trained by UGAN algorithm can detect smaller and less clear organisms, which are more sensitive to small objects with higher confidence.
Compared with the recognition results of the unimproved SPP algorithm and improved SPP algorithm, Figure 14 shows the recognition results.

(a) The detection results of the unimproved SPP algorithm and (b) the detection results of the improved algorithm of SPP. SPP: spatial pyramid pooling.
In Figure 14(a), small targets have the problem of missed detection. In Figure 14(b), the number of marine organisms missed is decreasing in detection, and the anchor frames are more closely fitted to the target. The improved M-YOLOv4 algorithm can accurately recognize blurred images and complex background images. Most of the detection confidence can reach more than 0.8.
Conclusion
This article proposes a marine multitarget recognition algorithm based on image enhancement and improved M-YOLOv4. The algorithm introduces the UGAN algorithm to preprocess the acquired unclear images and obtains clear images that are convenient for training and detection. In the backbone module, CSPDarknet53 is replaced by lightweight MobileNetv3. MobileNetv3 greatly reduces the number of parameters through depthwise separable convolution. The trained model is smaller, and the detection speed is improved. Based on this, the SPP network structure is improved, and its pooling kernel size is replaced. The mAP value detected by using MobileNetv3 is lower than that of the original YOLOv4, but its FPS value is improved from 15 to 27. It has a good effect on real-time detection of Jetson Nano development board. The detection effect after images with UGAN enhancement is better compared to the unenhanced images, and its mAP value is increased from 88.75% to 90.12%. After changing the pooling kernel, the detected mAP value is 90.77%, and it is higher than the original accuracy. Consequently, the improved algorithm has outstanding advantages in real-time detection of marine organisms and has certain expansibility and practicability.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (U1806201) and the Shandong Province Natural Science Foundation of China (ZR2022ME194, ZR2020MF087).