
Abstract
Deep learning technology has been widely used in various field in recent years. This study intends to use deep learning algorithms to analyze the aeroelastic phenomenon and compare the differences between Deep Neural Network (DNN) and Long Short-term Memory (LSTM) applied on the flutter speed prediction. In this present work, DNN and LSTM are used to address complex aeroelastic systems by superimposing multi-layer Artificial Neural Network. Under such an architecture, the neurons in neural network can extract features from various flight data. Instead of time-consuming high-fidelity computational fluid dynamics (CFD) method, this study uses the K method to build the aeroelastic flutter speed big data for different flight conditions. The flutter speeds for various flight conditions are predicted by the deep learning methods and verified by the K method. The detailed physical meaning of aerodynamics and aeroelasticity of the prediction results are studied. The LSTM model has a cyclic architecture, which enables it to store information and update it with the latest information at the same time. Although the training of the model is more time-consuming than DNN, this method can increase the memory space. The results of this work show that the LSTM model established in this study can provide more accurate flutter speed prediction than the DNN algorithm.
Introduction
The aeroelastic flutter is a dynamic instability of a flight vehicle associated with the interaction of aerodynamic, elastic, and inertial forces. The flutter phenomenon is a self-excited destructive oscillatory instability. As the aerodynamic force exerted on the flexible body is coupled with its natural vibration mode, the vibration amplitude increases. Flutter speed is the critical speed when the flutter just occurs. Nearly 80% of aeroelastic flutter analysis in the industry is based on classical flutter analysis (CFA). 1 The objective of the CFA is to determine the flight conditions that correspond to the flutter boundary. The flutter boundary corresponds to the conditions for which the aircraft is sustaining a simple harmonic motion. In the past decades, among many methods for analyzing flutter phenomena, P, K, and P-K methods are more practical and well known. 1 Bisplinghoff et al. 2 not only studied flutter phenomena and explained the physical meaning of flutter, but also made great contributions to flutter analysis, prediction of structural divergence and control of aeroelastic structures. Based on the complexity of aeroelastic coupling, Pitt and Haudrich 3 used the artificial neural network to analyze various flutter phenomena. Due to the difficulty in establishing computer instruction cycles and data at that time, the accuracy was not high, but it has inspired the follow-up research direction. In recent years, machine learning has developed vigorously. For example, Google recently defeated top Go players with AlphaGo 4 artificial intelligence Go software. Besides, deep learning methods are also widely used in image recognition, voice recognition, and data analysis and processing. In fact, the concept of “artificial intelligence” was put forward by American scholar John McCarthy in 1955. Around the 21st century, the development of artificial intelligence has undergone major changes. Hao 5 showed the design concept of artificial intelligence, which transits from establishing a large number of rules and system knowledge to machine learning. Machine learning is a branch of artificial intelligence. The concept of machine learning is to use different algorithms to establish a set of systems that can enable computers to learn automatically, and the cognitive model trained by this can predict and judge unknown data. Deep learning (DL) is a branch of machine learning, which was first proposed by Hinton et al. 6 in 2006. The concept of DL is to superimpose multiple hidden layers to simulate the neural network of the human brain for learning, but it also has the risk of over-fitting. Therefore, Hinton et al. also proposed the concept of dropout7,8 to improve the phenomenon of over-fitting. The concept of dropout is to randomly discard some neurons during the training process of the neural network, thereby reducing the risk of over-fitting. Recently, both Li et al. 9 and Halder et al. 10 used the deep long short-term memory (LSTM) networks to analyze the aeroelastic effects on the bridge and airfoil, respectively. They both used the high-fidelity computational fluid dynamics (CFD) to establish their fluid-solid coupled models. CFD uses computers to perform the calculations required to simulate the free-stream flow of the fluid. Most of the computing time is used to calculate the interaction of the fluid with the solid surface defined by the boundary conditions. With high-speed supercomputers, better solutions can be achieved. It is commonly known that the CFD method is time consuming 11 and is difficult to build the big data for machine learning. Ziaei et al. 11 used the machine learning method to predict non-uniform steady turbulent flows in a 3D domain. Their proposed method provides an easy way for the designers and engineers to generate immense amounts of design alternatives without facing the time-consuming task of evaluation and selection.
In the development of modern deep neural networks (DNNs), feature learning and classification applications are even more outstanding. AlexNet 12 won the ImageNet LSVRC title in 2012. GoogLeNet 13 won the championship in the ILSVRC competition in 2014. They achieved an error rate of only 6.67% using a 22-layer neural network architecture, which indirectly proves that increasing the number of layers of neural networks can describe complex models more accurately and bring better accuracy.
Hochreiter and Schmidhuber 14 improved the recurrent neural network (RNN) algorithm and proposed a long short term memory (LSTM) model. This model has a longer-term memory ability than the recurrent neural network. In recent years, Li et al. 9 and Halgan et al. 15 have used computational fluid dynamics (CFD) method to build long short term memory network models and analyze the aeroelastic phenomena of bridges and airfoils. In the framework of deep learning, long term short term memory models can process a large amount of data and learn more hidden information from non-linear systems. 16
In order to analyze flutter speeds under various flight conditions, this study adopted K method of flutter analysis method to analyze the occurrence of flutter speeds and build a large amount of data. The K method is a semi-analytical and numerical method. This method needs to establish the mathematical model and also needs computer coding to find flutter speeds. Most importantly, the flutter speed can only be predicted by K method case by case each time. Once the data bank was established, using the deep learning method can be efficiency and easier in predicting the results. The present study uses the DNN algorithm of machine learning to process complex aeroelastic model by superimposing a multi-layer neural network architecture. Referring to Hagan et al. 15 ’s research on neural network architecture, the present study designed a set of machine learning methods for computers to find rules from tens of thousands of flight data and obtain a set of classification methods. At the same time, this research also uses the LSTM algorithm to establish a deep learning model, and compares the advantages and disadvantages of DNN and LSTM. The supervised learning was used to guide the machine to recognize the learning target with Labels. Among many programming languages, Python has the highest support at present.17,18 Python has a large number of third-party modules and a powerful standard library in order to use extended modules of other programming languages. This study used this tool as the basis. Under such analysis, the deep learning network can extract the features from various flight data, and find the flutter speed of the aircraft under different flight conditions. Finally, the theoretical predictions from the K method were applied to verify the learning status of deep learning and analyze the effectiveness of deep learning.
Introduction to the basic theory
Among many flutter analysis methods, P-K method is often used for analysis. Compared with P-K method, the K method occasionally misjudges the degree of freedom of structure flutter when analyzing aeroelastic problems.1,19 However, this study only considered flutter speed, and did not focus on the flutter related to different degrees of freedom. Therefore, using K method will not affect the prediction of flutter speed, and can save much time when generating a large amount of flutter data.
Aeroelastic equations of motion for two-dimensional airfoils
Referring to the theory of flutter analysis proposed by Hodges and Pierce,
1
we analyzed the flutter phenomenon of an airfoil, in which this model includes two degrees of freedom: plunge, and pitch. We assumed that these two degrees of freedom are subjected to springs Kh and
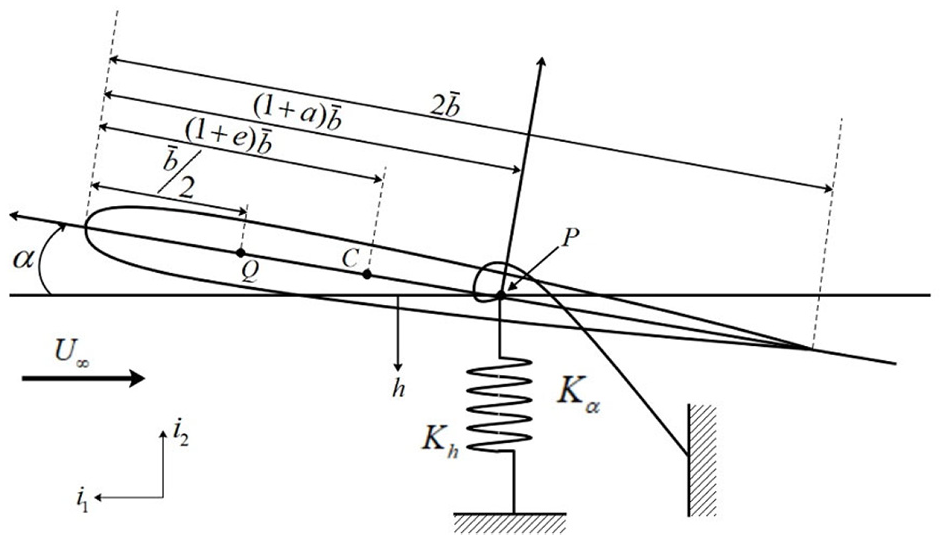
Schematics of the airfoil.
Here, Q in Figure 1 is the aerodynamic center. The aerodynamic center is the point that the pitching moment for the airfoil does not vary with lift, and usually defines as dCm/dCL =
0, where Cm is the pitching moment coefficient, CL is the lift coefficient. C is the center of mass, and P is the elastic axis
Through Euler-Lagrange equation, we can get the basic Airfoil equation of motion as follows 1 :


where, m is the mass of airfoil, Ip is the moment of inertia of the airfoil,



Then

K method
K method is to add the artificial damping term to the right of the original aeroelastic equation of motion. By observing the variation of artificial damping, we can judge the divergence trend of the structure. Because K method is not like the general classical flutter analysis method, which needs a lot of iteration to calculate flutter speed, the K method is also the most efficient among many classical flutter analysis methods. Therefore, we chose K method to establish and verify the deep learning model in this study.
After adding artificial damping term (


We used simple harmonic motion to express the plunge motion (h) and pitch motion (


After substituting

where,
After solving the determinant of equation (11), the flutter speed can be obtained. Figures 2 and 3 are the results of using K method to obtain flutter speed. From the change of artificial damping in Figure 2, it can be seen that artificial damping will change from negative value to positive value at the position of 4.6, which means that flutter will occur at the position of dimensionless flutter speed (1/k) = 4.6. Meanwhile, comparing with Figure 3, we can see the change trend of system frequency before and after flutter generation.
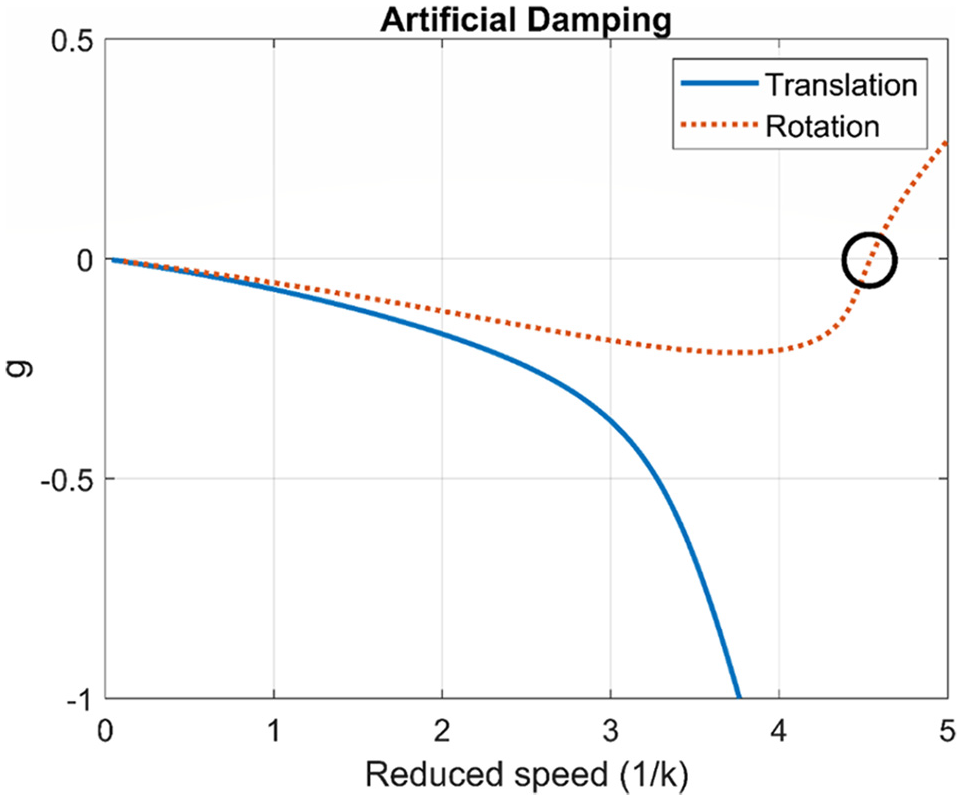
Artificial damping of K method prediction.

Frequency of K method prediction.
Deep learning
This study used the deep learning algorithm to perform flutter speed analysis. The DNN architecture adopted herein is based on supervised learning, and a set of neural networks was designed to predict the results after repeated operations by a large number of artificial neurons. In this study, supervised learning in machine learning was adopted, so in building a learning model, besides the features of data, data labels should also be the input. Therefore, we needed to mark huge data, and the data marking in this study was based on K method of flutter analysis. We set the parameters used in the airfoil equation of motion in Section II as data features, and the flutter speed obtained by using K method was the data label. We used computer processing to carry out a large number of labels to avoid spending too much time on data collection. The parameters used in the learning model are the location of center of mass, the location of elastic axis, mass ratio, radius of gyration, frequency ratio, and static unbalance parameter. Table 1 is the parameter data used by the dataset. Finally, there are 350,892 data sets established in this study.
Parameters used by the dataset.

In the feature scaling of data, the data normalization method we used is Min-Max normalization, which scales the data to the [0, 1] interval in equal proportion to avoid the excessive contribution of a certain parameter, which affects the convergence speed of model building and further reduces the training efficiency. The expression of Min-Max normalization is as follows:
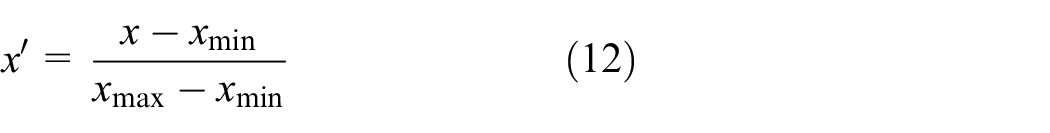
where, x′ denotes normalized data, x is raw data, xmin is the smallest data value in the raw data set, and xmax is the largest data value in the original data set.
Deep neural network (DNN)
DNN is a kind of Artificial Neural Network (ANN), also known as the Neural network. The concept of deep neural network is a neural network formed by a combination of a large number of neurons, which simulates the behavior of the human brain to transmit and process information through neuronal connections to respond or solve problems. In the basic architecture of a deep neural network, there are multiple hidden layers between the input layer and the output layer, and each layer is composed of a large number of neurons, and all the neurons in the input layer are individually connected to the neurons in the hidden layer, and the neurons in the hidden layer are also individually connected to the output layer. The schematic diagram of the neural network-like structure is shown in Figure 4.

The schematic diagram of the neural network-like structure.
Neural network is composed of many artificial neurons, in which each artificial neuron is connected with a weight value, and each artificial neuron has a deviation value. The relationship between the input value and the output value is generally expressed by the following form,

where x is the input value of the artificial neuron, w is the weight, b is the deviation value, y is a value obtained by multiplying each input value and weight value and summing it up with a given deviation value,
Long short term memory (LSTM)
LSTM uses three control gates to learn and achieve the effect of long-term memory, and these three control gates will determine the storage and use of memory, which are Input gate, Forget gate, and Output gate. Figure 5 is a schematic diagram of the LSTM model. When a long-term and short-term memory model is operating, the hidden state at the previous time state and the current input value will be entered into the long-term and short-term memory for calculation at the same time, which will be multiplied by a weighting value and added to a deviation value. Then, the conversion is performed through the activation functions of the input gate, the forget gate, and the output gate. The activation functions are all sigmoid functions, and the updated cell state uses the hyperbolic tangent function as the activation function. The calculations are shown as follows:.

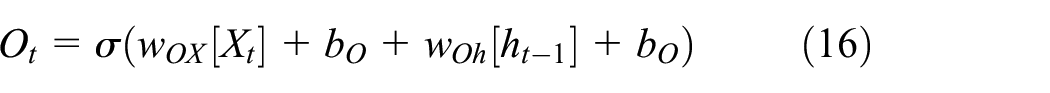
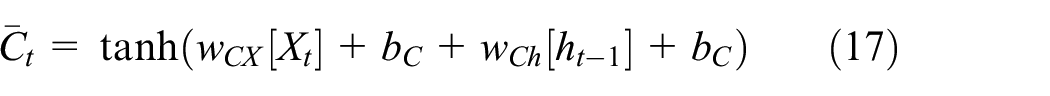
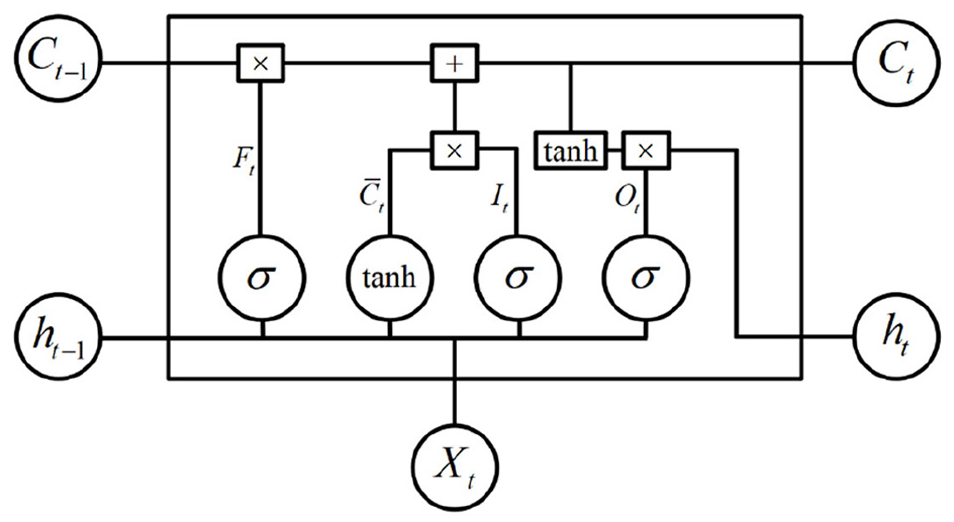
LSTM model.
where It is the information passing through the input gate, Ft denotes the information passing through the forgotten gate, Ot represents the information passing through the output gate,

Ct is not only the updated cell state, but also the cell state transferred to the next long and short-term memory. Finally, the result of the output gate calculation will determine how to update the hidden state. If the value of the activation function converted by the output gate is 0, it means that the current unit state cannot pass the output gate, so the hidden state will not be recorded. The updated hidden state expression is shown in equation (19).

At this point, the long and short-term memory unit has been completely trained. The LSTM method uses memory units and hidden states to increase the dependence of data training. Therefore, we use the LSTM method to establish the deep learning model to predict the flutter speed.
Loss function
The loss function we used in deep neural networks is categorical cross-entropy. It is applicable to a variety of classification problems. We also use Softmax function as the activation function of the output layer. The calculation of categorical cross entropy is shown in equation (20).

where n is the number of classification categories, yi is the label of the data, and pi is the accuracy of the classifier in predicting the occurrence of flutter speed. In LSTM method, we used the mean square error (MSE) to evaluate the error of the training model. This method is a commonly used regression loss function. This is a commonly used regression loss function. The calculation of the mean square error is shown in equation (21).

where q is the total number of data, yi is the label of the data, and
Back propagation
Back propagation is a sequential transmission from the output layer to the input layer, and the difference between the training data converted by the activation function and the corresponding input target value is obtained, thus obtaining the loss function gradient related to each weight parameter. Here, input training data is converted through AF and we can obtain

After obtaining the gradient of the loss function in each hidden layer, the weight can be updated by using the gradient of the loss function to obtain the best weight value. The loss function used by us in the DNN was categorical cross-entropy. Finally, the Softmax function was adopted as the AF of the output layer. The loss function of classification cross entropy is as follows.

where, n is the number of classification categories, yi is the volume label of the data,
Other parameter setting
In the weight update of the DNN, we choose Adam method 20 to calculate and adjust the weight value of the updated model. We chose Adam method for weight update because compared with other weight update methods, this method is easier to execute, has relatively high calculation efficiency, requires less memory, and is suitable for problems with a large amount of data and parameters. Adam related expressions are as follows.


where, new representations


In equations (24) and (25), gt is expressed as loss function gradient,

where m and v are parameters used to adjust the weight values of neural networks. Among them, the default value of
Modeling and Analysis
DNN model
Based on the deep learning theory proposed in last Section and referring to Hagan and Schmidhuber’s 14 research on neural network architecture, this Section constructed a set of deep learning architecture that can predict flutter speed, and carried out deep learning on 350,892 flight data. Among them, 70% of the flight data are regarded as training set, 20% as validation set, and the remaining 10% as prediction data. In the design of architecture, we first established the most basic three-layer deep learning framework for test training. Among them, the starting function in the deep learning architecture uses ReLU function for training except for Softmax function in the output layer. After 10,000 Epoch training, the results obtained are not satisfied. The training accuracy and testing accuracy are stuck at 82%. The training results are shown in Figures 6 and 7.

Accuracy of 1-layer deep learning architecture training.

Loss of 1-layer deep learning architecture training.
After the first test, we decided to increase the number of artificial neurons and the number of layers of deep learning architecture to achieve better accuracy. When a 7-layer deep learning architecture was used, after 10,000 Epoch training, the training accuracy has reached 97%, and the accuracy of verification reaches 94%. However, in the loss results, there is an increasing trend with the increase of Epoch. The reason is that the over-fitting phenomenon is due to the deep learning architecture stacking too many layers or using too many artificial neurons, which causes the noise in each data to be amplified when verifying the results, resulting in an increasing trend of loss. The training results are shown in Figures 8 and 9.

Accuracy of 7-layer deep learning architecture training.

Loss of 7-layer deep learning architecture training.
Figure 10 shows the training loss and testing loss results of different layers of neural network architecture. After many attempts (see Figure 10), we chose a 6-layer deep learning architecture and used Dropout 7 to improve the over-fitting phenomenon. Although its accuracy is not as high as that of the 7-layer deep learning architecture, it avoids the phenomenon of over-fitting. We adopted Sigmoid function, ReLU function, and Softmax function as the activation function of the model in this study. The Categorical cross-entropy was selected as the loss function of this model, and Softmax function as the starting function of the output layer. The activation function of each other layer uses Sigmoid function and ReLU function. Table 2 shows the results of model training loss under different combinations of Sigmoid and ReLU activation functions.

Training loss and testing loss of different layers of neural network architecture.
Training loss results with different activation function combinations.
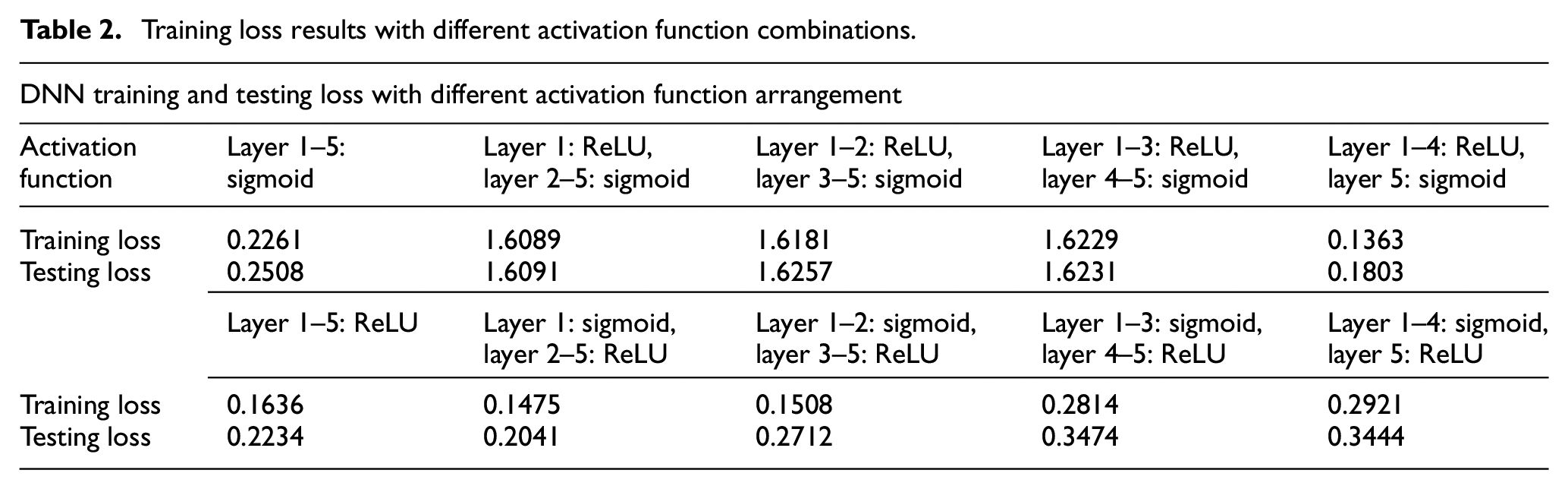
As shown in Table 2, when the ReLU function is used as the activation function in Layer 1 to Layer 4, and the Sigmoid function is used as the activation function in Layer 5, the loss of training results is the relatively lowest compared with other combinations, and its training loss is 0.1363, and the loss during verification is 0.1803. Therefore, this group of combination was chosen as the basis for establishing the deep learning model activation function of this study. After determining the activation function of the model in this study, we decided to train the model with different number of neurons and find out the number of neurons suitable for this model. Figure 11 is the result of training losses using different number of neurons. From the training loss results of different number of neurons, it can be seen that when the number of neurons increases, the training loss tends to decrease with the increase of the number of neurons. However, the loss of test tends to increase after 120 neurons, we then use 120 neurons to establish the deep learning model of this study. Based on the above results, we have established a 6-layer deep learning architecture, in which layers 1–5 use ReLU function as activation function, layer 6 uses Sigmoid function as activation function, the output layer uses Softmax function as activation function, the loss function uses Categorical cross-entropy method, and each layer is established with 120 neurons. Figure 12 is the framework of the deep learning model in this study, and the training results are shown in Figures 13 and 14, and the accuracy of the trained model is 95.6%. Although it is 1.4% lower than the previously established 7-layer deep learning architecture (97%), this model has higher robustness.

Training loss results of different number of neurons.
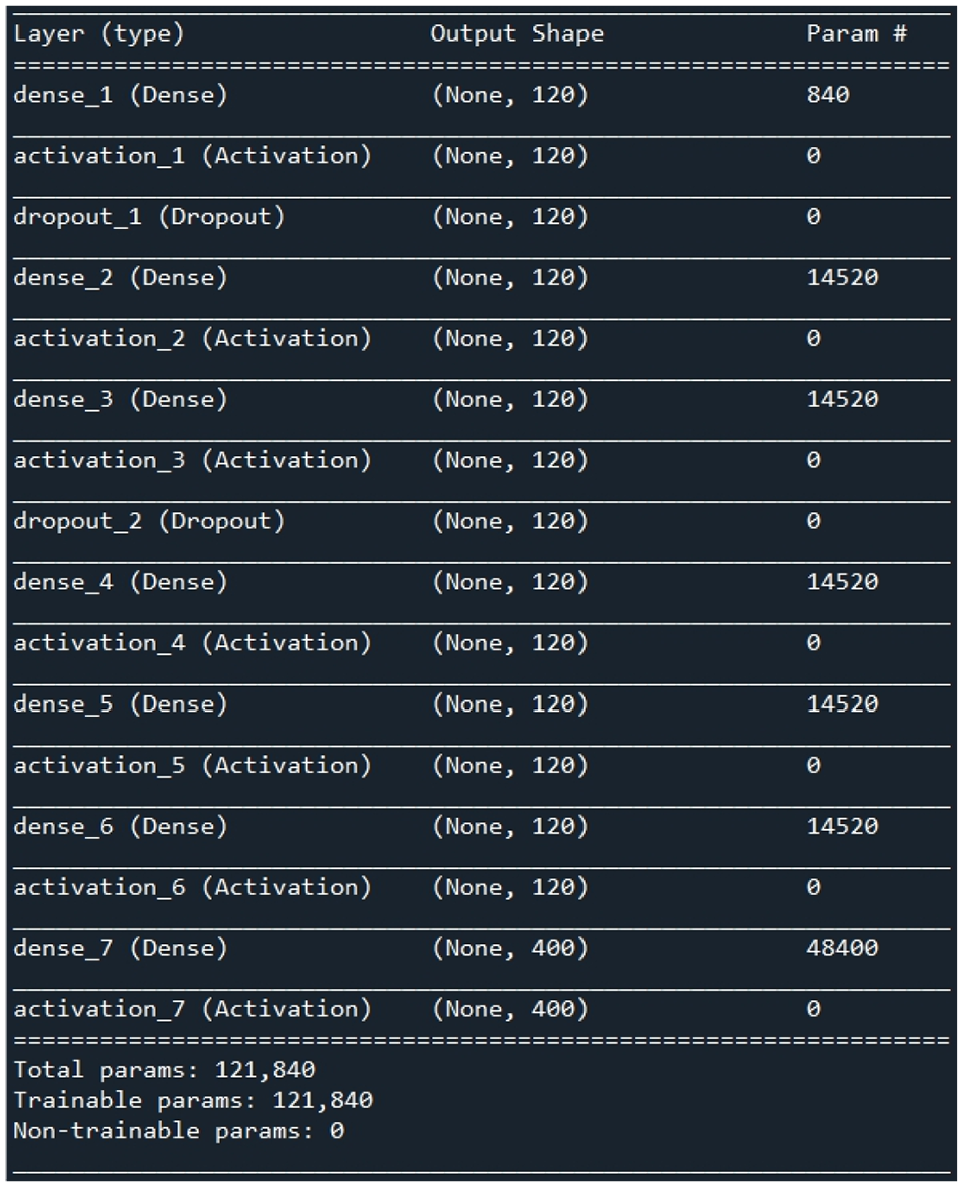
Deep learning model.

Precision of deep learning architecture.

Loss of deep learning architecture.
LSTM model
We regard 70% of the 350,892 flight data as the training set, 20% of the data as the validation set, and the remaining 10% as the predicted data and import them into the LSTM model for training. The input parameters of the LSTM model in this study are consistent with the DNN model. In the design of the LSTM architecture, we first established a basic single-layer deep learning architecture for testing and training, and then increased the number of layers of long-term and short-term memory. Finally, we chose to use five layers of long- and short-term memory as the LSTM model. The LSTM architecture test training results of different layers are shown in Figure 15.

LSTM testing and training results of different layers.
Since the Sigmoid function and the hyperbolic tangent function have been used as the activation function in the LSTM model, we no longer use the activation function between the hidden layers to avoid excessive non-linear conversion between the hidden layers causing the output value to be distorted. In the training process, we also added a dropout layer between the hidden layers to prevent over-fitting. This study uses a 5-layer LSTM layer. Since the previous training has used a fixed number of LSTM cells, we will tune the number of LSTM cells to obtain the best number of long and short-term memory cells. Figure 16 shows the training loss results using different numbers of LSTM cells. From the training loss results of different numbers of long and short-term memory cells, it can be seen that when the number of cell is 80, the training loss and test loss are small, so we chose to use 80 cells to establish this deep learning model. Next step is to choose an appropriate number of epochs to train the LSTM model in this study. Figure 17 shows the loss and accuracy results of different epoch training. It can be seen from Figure 18 that the loss result after 3000 epochs training is low; however, when it is increased to 4000 epochs, the accuracy does not increase significantly. Therefore, we choose to use 3000 epochs to build the deep learning model of this research.

LSTM training loss using different numbers of cells.

Loss and accuracy of different epoch training.

Architecture of the LSTM model.
Based on the above results, we have established a 5-layer LSTM architecture, in which the loss function uses the mean square error method, and each layer is built using 80 LSTM cells, and the number of training is 3000 epochs. Figure 17 is the architecture of the LSTM model of the present study. The average accuracy of the trained model is 96.8%. The accuracy and loss results of the training are shown in Figures 19 and 20.
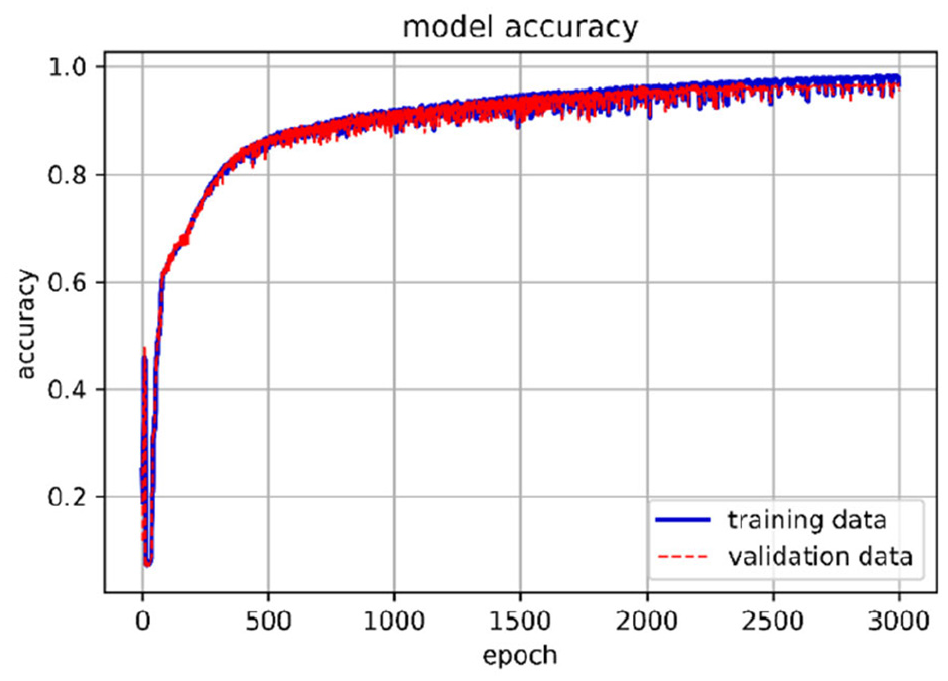
Accuracy of the LSTM training model.

Loss of the LSTM training model.
Model prediction and result discussion
In this Section, the deep learning model obtained from last Section was used to predict flutter speed of various flight parameters. The verification results by DNN model are shown in Figure 21. Table 3 is the relevant data of this DNN model. In the verification result, an accuracy of 95.6% is achieved. It is noted that the red dots in Figures 21 and 22 indicate the results of the true flutter speed versus the predicted flutter speed, while the dashed line represents the ideal case of DNN (Figure 21) or LSTM (Figure 22) model prediction result. The verification results by LSTM model are shown in Figure 22. In the verification result, an accuracy of 96.8% is achieved. Again, the red dots in Figure 22 indicate the results of the true flutter speed versus the predicted flutter speed, while the dashed line represents the ideal case of LSTM model prediction result. The results show that the LSTM model has better accuracy than the DNN model.

DNN prediction results.
DNN model data.


LSTM prediction results.
Figures 23 to 27 are the prediction results of flutter speed after input and training of various parameters. Vertical axis is flutter speed. The higher the value is, the higher the flutter speed is. A higher flutter speed means that it is less likely to cause structure divergence. For each figure, (a) is the predicted results by DNN, and (b) is the predicted results by LSTM model. Figure 23 shows that this model has high stability if the center of mass locates from quarter chord to half chord, the estimated value is consistent with aeroelastic point of view. That is, when the center of mass is located in the front half of airfoil (quarter chord), the model has higher stability than the rear half. Figure 24 shows that the aeroelastic model is more stable when the position of elastic axis is placed near the quarter chord. It is true that from aerodynamic point of view, when the position of elastic axis is placed near the quarter chord, the system will have higher stability. Figure 25 is the relationship between mass ratio and flutter speed, where the mass ratio is expressed as

Relationship between location of center of mass and flutter speed, predicted by (a) DNN model and (b) LSTM model.
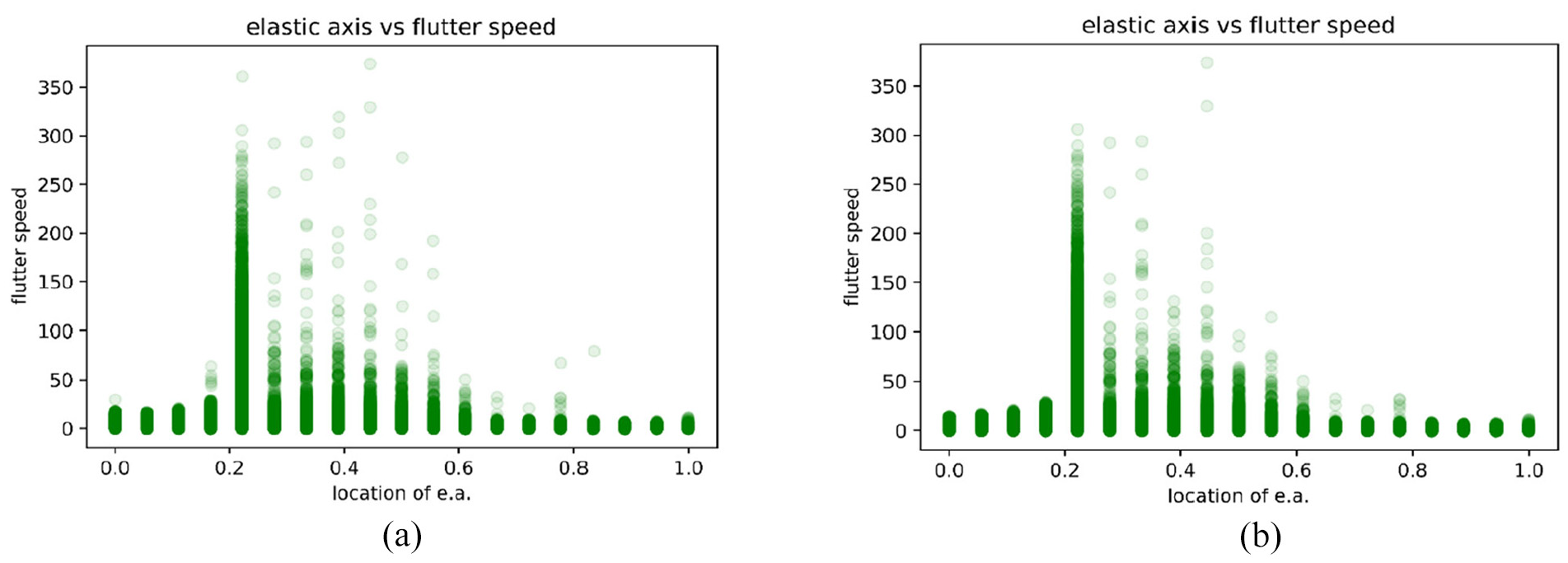
Relationship between location of elastic axis and flutter speed, predicted by (a) DNN model and (b) LSTM model.

Relationship between mass ratio and flutter speed, predicted by (a) DNN model and (b) LSTM model.
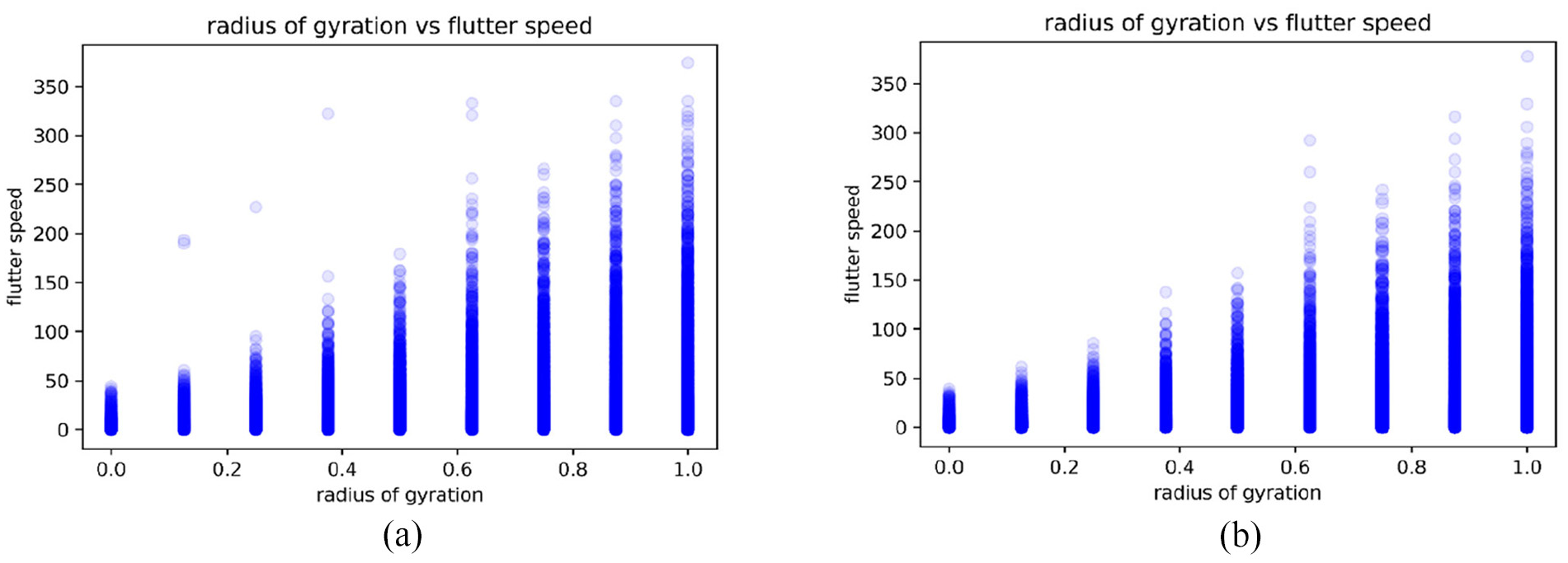
Radius of gyration and flutter speed, predicted by (a) DNN model and (b) LSTM model.

Relationship between static unbalance and flutter speed, predicted by (a) DNN model and (b) LSTM model.
From Figures 23 to 27, we can see the trend of the flutter speed predicted by LSTM is consistent with the trend of the prediction result of the DNN model, and the prediction conditions of both can be explained by the physical meaning of aerodynamics and aeroelasticity. As far as the results of the current stage of this research are concerned, the prediction of flutter speed has reached a good level, among which the average prediction accuracy of the DNN model and the LSTM model have reached more than 95%. Figures 21 and 22 are the predictions by importing the same data set. From the two figures, it can be clearly judged that the deep learning model established by using the LSTM method is better than the deep learning model established by the DNN method. Moreover, most of the predictions of the LSTM model are closer to the theoretical flutter speeds than the DNN model. From Figures 23 to 27, the fluctuations of the flutter speeds predicted by the DNN model are larger than that of the LSTM model, and the robustness is also lower than that of the LSTM model. We believe that the reason for this result is that the LSTM model has a cyclic architecture, which enables it to store information and update it with the latest information at the same time. It also uses three control gates to adjust and select memory storage and access. Although the training of the model is more time-consuming than DNN, this method can increase the memory space. The DNN model is a feed-forward neural network. The data sets imported into this model are not well related. Although the accuracy of the DNN model has reached 95.6%, the prediction robustness of the DNN model is relatively low.
Conclusions
This study uses deep learning algorithms to analyze the aeroelastic phenomenon and compare the differences between Deep Neural Network (DNN) and Long Short-term Memory (LSTM) applied on the flutter speed prediction. Instead of time-consuming high-fidelity computational fluid dynamics (CFD) method, this study uses the K method to build the aeroelastic flutter speed big data for different flight conditions. The flutter speeds for various flight conditions are predicted by the deep learning methods and verified by the K method. The detailed physical meaning of aerodynamics and aeroelasticity of the prediction results are studied. The conclusions are listed below:
The number of layers and the number of neurons for the DNN and the LSTM will affect the accuracy of the model. Not that the more layers the better the effect. The number of neurons is not the more the better the effect. Too many layers or too many neurons will cause the model to produce over-fitting phenomenon, resulting in a decrease in the accuracy of the prediction results. A case analysis based on this research is necessary.
The number of epochs of the deep learning model in this study determines whether the model is fully trained, but if the epoch is set too large, it may cause the model to be over-fitted during the training process, which will affect the accuracy. At the same time, too many number of epochs will increase the calculation time and reduce the efficiency of training. Choosing the appropriate number of epochs will improve the efficiency of training.
The prediction results of the DNN and the LSTM deep learning models conform to the theoretical explanation of aeroelasticity and aerodynamics.
This study uses DNN and LSTM methods to build deep learning models, with an average accuracy of more than 95%. The LSTM model performs better than the model established by the DNN method, and its robustness is also higher.
In this study, DNN and LSTM are employed to predict the occurrence of flutter speed, both of the deep learning methods are used to learn the relation between each flight data and its associated flutter speed by considering this problem as a multi-class classification, so as to achieve the goal of this study. The results show that the LSTM architecture can effectively predict the flutter speed, and it is a potential model in the application of aerospace field.
Footnotes
Appendix
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Ministry of Science and Technology of Taiwan, Republic of China (grant number: MOST 110-2221-E-032-026).