
Abstract
Cognitive radio is a paradigm that proposes managing the radio electric spectrum dynamically by integrating the spectrum sensing, decision-making, sharing, and mobility stages. In the decision-making stage, the best available channel is selected for transmitting secondary user data in an opportunistic fashion, and the success of that stage depends on the efficiency of the primary user characterization model. Use of the long short-term memory technique based on the deep learning concept is proposed in order to reduce the forecasting error present in the future estimation of primary users in the GSM and WiFi frequency bands. The results show that long short-term memory has the capacity needed to improve channel use forecasting significantly more than other methods such as multilayer perceptron neural networks, Bayesian networks, and adaptive neuro-fuzzy inference systems (ANFIS-Grid). It is concluded that although long short-term memory exhibits better performance generating forecasts for time series, computing complexity is higher due to the existence of input, forget, and output gates within the neural structure; therefore, implementation is feasible in cognitive radio networks based on centralized network topologies.
Introduction
In the same manner as land is more costly and scarce in urban areas due to the fact that they are densely populated (because of the quality of life they offer), the operating range of the radio electric spectrum is more useful in certain frequency bands than others because they facilitate the interconnection of devices and reduce the probability of errors. Wireless systems are currently characterized by a spectrum allocation policy that is established and regulated by the government of each country. This presents spectrum distribution issues (Figure 1) 1 because spectrum use is deficient due to large spatial and temporal variations in spectrum occupation.2–4 A consequence of underutilization is a current spectrum shortage, which causes a significant degradation in the quality of service (QoS) offered by telecommunications companies (e.g. wireless band), an aspect that has motivated researchers from different fields to formulate possible solutions for optimizing spectrum use. Dynamic spectrum access is a solution, along with the cognitive radio (CR) concept, the main purpose of which is to identify spectrum holes not used by primary users (PUs) so that they can be used opportunistically by secondary users (SUs).

Spectrum occupation in the 30 MHz to 3 GHz range. 1
CR can be defined as a system that is controlled by a cognitive process capable of perceiving and processing existing environmental conditions. CR can subsequently be used by a learning technique capable of optimizing network performance. The above task implies the use of highly intelligent algorithms that are capable of making decisions under different conditions in different radio environments, as well as other challenges that need to be resolved.5–7
Dynamic spectrum management in CR includes four main stages,8–10 one of which is spectrum decision (in charge of selecting the best channel available based on the SU’s service quality requirements), which is important and relevant because it is one of the least explored stages, 11 and essentially depends on the characterization and statistical behavior of channel use by the PU. In this regard, one of the variables on which the success of band selection depends is related to the quality of the prediction model used to represent PU dynamics; if the prediction is not very good, an inadequate channel will probably be selected, and the SU will generate an interference that is unacceptable for the PU.
Several proposals for modeling PU activity exist. Nevertheless, it is important to continue delving into the research and application of new models that seek to minimize error percentages in the prediction or future estimation of PU behavior in licensed spectrum bands. The purpose is to detect white spaces that could potentially be used by SUs in an opportunistic fashion to transmit information. That is the focus of the research paper, which develops an algorithm that is based on the long short-term memory (LSTM) deep learning methodology and characterizes (i.e. models and predicts) PU activity in the GSM (850 MHz) and WiFi (2.4 GHz) spectrum bands.
It is important to note that currently new solutions are being developed to existing problems in engineering by applying methodologies based on neural networks with deep learning as shown in Wang et al., 12 where a new system is proposed for earthquake prediction from the spatio-temporal perspective through the design of an LSTM network with bi-dimensional input, which can reveal the spatio-temporal correlations between the occurrences of earthquakes and take advantage of the correlations to make precise earthquake predictions; or, 13 which assesses the performances of LSTM-based mechanical state prediction systems; or in Li et al. 14 where an innovative dual primary neural network for the resolution of redundancy of robotic manipulators in noisy environments is presented which, in the presence of noise, is able to achieve an optimal control of the manipulators with guaranteed convergence. Other interesting studies can be found in Jin et al. 15 where the authors design a neural-dynamic distributed scheme for the cooperative control of multiple redundant manipulators with limited communications, 16 which studies the problem of energy prediction by considering different dimensions of analysis spatio/temporal autocorrelation, the learning setting (structured output vs non-structured output), and the learning algorithm (ANNs vs regression trees).
Taking the above premises as reference, the research work’s main contributions and developments are shared in this article. They include the development of a complete mathematical model for the LSTM system that was implemented for modeling future PU activity in spectrum channels; the implementation of a C# algorithm for the licensed user characterization system; for the system that was developed, an evaluation using data traces not only generated through simulation, but also representing real traffic traces in the GSM and WiFi bands, thus enhancing the proposal’s plausibility; and the validation of the model that was built, through the comparison of results generated by LSTM with results by other prediction methodologies such as multilayer perceptron neural network (MLPNN), Bayesian networks, and adaptive neuro-fuzzy inference systems (ANFIS-Grid).
Based on the above discussion, the rest of the paper includes a section with a description of the state of the art of PU characterization in CR. The proposal is subsequently developed, and the results are evaluated and validated. At the end are some discussion items and conclusions.
Scientific review
Future estimation of channel occupation from the perspective of PUs gives SUs an indication of the times when they can make use of the spectrum; such a metric is considered sensitive to and highly dependent on the prediction model. In a characterization, 17 concludes that a significant number of existing approaches have a very high computing cost, which makes implementation practically impossible in nodes in which useful life is based on battery use (in rural areas). This conclusion suggests that there are still several development challenges including the need to propose methodologies that reduce computing cost (especially for ad hoc topologies) when estimating future predictions based on existing data, 11 as well as the imperious need for the lowest possible prediction error when estimating future behaviors.
The article in Uyanik et al. 18 proposes three prediction mechanisms based on correlation, linear correlation and regression, and self-correlation, based on previous decisions, to predict future spectrum status as well as decision-making regarding PU occupation. The prediction-based correlation scheme uses the Pearson correlation coefficient which is measured from historical samples of windows; if the coefficient is above a certain threshold, the prediction window is filled with the latest sample. Linear regression prediction based on the Pearson coefficient establishes the correlation between the spectrum detection status and the index vector. This coefficient is determined by a threshold value similar to the previous approximation, and there will be a correlation and regression if a linear relationship exists. If a relationship exists, it is used for spectrum prediction. Simulations show the proposed prediction scheme exhibits better results in diverse simulation settings. Furthermore, in order to obtain a more realistic evaluation, it is necessary to take into account the values of the utility system along with the PU’s disturbance relationship values.
With the purpose of maximizing spectrum use in licensed bands, 19 describes a spectrum selection (SS) system that was developed. It has an algorithm based on discrete Markov chains that is capable of estimating the occupation of spectrum shared by PUs and SUs. In order to minimize algebraic complexity when dealing with the problem, it is considered that PUs and SUs request a single transmission channel. One of the highlights of the proposal is the use of stochastic processes to determine the number of PUs and SUs that are in the system at any given time. The results indicate that exploring dependency structures that may exist between primary activity and the duration of channel inactivity significantly improves the reliability of remaining inactivity durations specifically for high dependency and low variability levels. An evaluation of SS performance when using different formulations for the fittingness factor shows that the relevance of each formulation greatly depends on the traffic loads of CR applications; in particular, for low traffic loads, a simple formulation that maximizes the attainable bit rate is sufficient to achieve good SS performance; on the other hand, for higher traffic loads, a more intuitive formulation is required in order to efficiently exploit available bands.
In Khan, 20 different SU spectrum assignment techniques based on genetic algorithms are applied based on previously detected radio surroundings where the QoS is specified by the SU. The wireless channel (WSGA) is represented in the research as a genetic algorithm that can perceive its wireless surroundings, along with a cognitive monitoring system (CMS) based on a genetic meta-algorithm. For monitoring and changing system behavior, the following parameters are considered: the frequency bands (represented in terms of bits), modulation scheme, power, and bit error rate, all of which will contribute to the chromosomes’ total aptitude according to the respective weights assigned by the SU. Use is made of an environmental information detection module, which will serve as the initial population for the genetic algorithm. From that point on, the calculation of the evolution begins with the random selection of some chromosomes (individuals). The aptitude of each individual in a generation will be evaluated as a function of mutations and stochastic calculations. This will give rise to a new population, which is expected to be better than the previous one. The algorithm becomes iterative and continues the process from one generation to the next until reaching a maximum of generations or finding an optimal solution. The authors conclude that the values for fitness (i.e. the aptitude function that measures the genetic representation’s quality) of the chromosomes increase with the number of generations or the population’s initial size. This implies that each gene assigns a greater power in decision-making, and these genes’ fitness function will have a greater value than that of genes with less power during the increase of generations. An additional parameter benefiting the research is that the user (application) is able to specify the QoS requested for each gene.
In Chen et al., 21 a mechanism for efficient spectrum assignment in cognitive radio networks (CRNs) is proposed. An algorithm is developed for auctioning available spectrum to SUs when the PU is absent. Each PU is a resource provider announcing a price and a reserve offer. Each SU acts as a client. Since there are several SUs, the cognitive nodes will be forced to compete in a non-cooperative auction. The authors also focus their study on the setting of prices by the PU in order to maximize revenue. The authors propose a learning algorithm for setting the prices, considering that each PU’s revenue must be proportional to the threshold interference level. The results show that the learning algorithm that was designed can converge in a balanced manner with a reasonable efficiency in a distributed network. They also conclude that the proposed auction framework has a high level of efficiency and equilibrium in terms of spectrum assignment.
In Canberk et al.,
22
a framework for spectrum decision-making is designed based on SUs’ QoS requirements, seeking greater performance and equity
23
in CR-based systems. To this end, the short-term fluctuations of the available spectrum are characterized by including a module that studies and evaluates PU activity (for each spectrum band in an individual manner) through the opportunity index parameter (
The predictor based on the static neighbor graph (SNG)
24
is designed to predict future locations of PUs according to prior information collected from the mobility topology of said licensed users. Initially, a graph is built in order to represent the mobility history of PUs. To that end, when a SU observes the movement of a PU from location i to j, a directed line segment
In Yao et al.,
26
a new spectrum decision strategy is discussed. It considers the combination of error detection, competition, and collision in SU transmission taking into account channel use status. The authors adopted a comparison algorithm based on diffuse logic that combines three probabilities (the
The state of the art described in Masonta et al. 7 can be synthesized by saying that since there is no guarantee that a band is available during the period required by a SU for transmission, it is important to take into account how frequently PUs appear. Using CR’s learning ability, a PU’s history of spectrum use activity can be used to predict the spectrum’s future profile, a process that is achieved through characterization. SUs can decide on the best spectrum bands available for transporting their data considering the future behavior of PUs. The above statement reflects this article’s intention, which is to characterize PUs using a LSTM neural network methodology that includes the deep learning concept. 27
Development of the proposal
Making highly accurate predictions is quite beneficial to planning and control in many fields of research and development. However, an elevated accuracy level entails a high level of difficulty. 28 One of the most promising estimation techniques applicable to CR is artificial intelligence (AI), which is capable of providing conscience, reasoning, and learning elements 29 which interact to promote the best performance from CR.
Future estimation of channel status in the GSM and WiFi band (from the perspective of the PU) was addressed as a binary series prediction problem based on the conversion of power levels (dBm) captured and delivered by the spectrum analyzer as discrete values, and the proposed solution was the use of neural systems based on deep learning (LSTM).
LSTM
Traditional artificial neural networks are not capable of storing information. In order to do so, it is necessary to modify the topology by creating recurrent structures that retro feed the neurons and allow information storage. Such structures are known as recurrent neurons. A set of such neurons is called a recurrent neural network (RNN). An RNN allows storage of subsequent states in different time intervals where the parameters are shared among the different parts of the model, which allows for better generalization. 30 One of the problems of an RNN is long-term dependency, which suggests the need to not always study historical data to perform a current task. This implies an RNN stores only information learned in the past and is not capable of storing new information in the short term. LSTM can be expressly designed to avoid the long-term dependency problem by remembering information during long periods of time and learning new information in the present. LSTM blocks contain memory cells which allow a value to be remembered for an arbitrary time period and used when necessary. There is also a forget layer which can erase memory content that is not useful. All the components are built for differentiable functions and are trained during the backpropagation process. 31 The structure of an LSTM can be represented as shown in Figure 2, where the memory cell is identified with a letter “C,” the forget layer, with an “O,” the input layer, with an “E,” and the output layer, with an “S.”
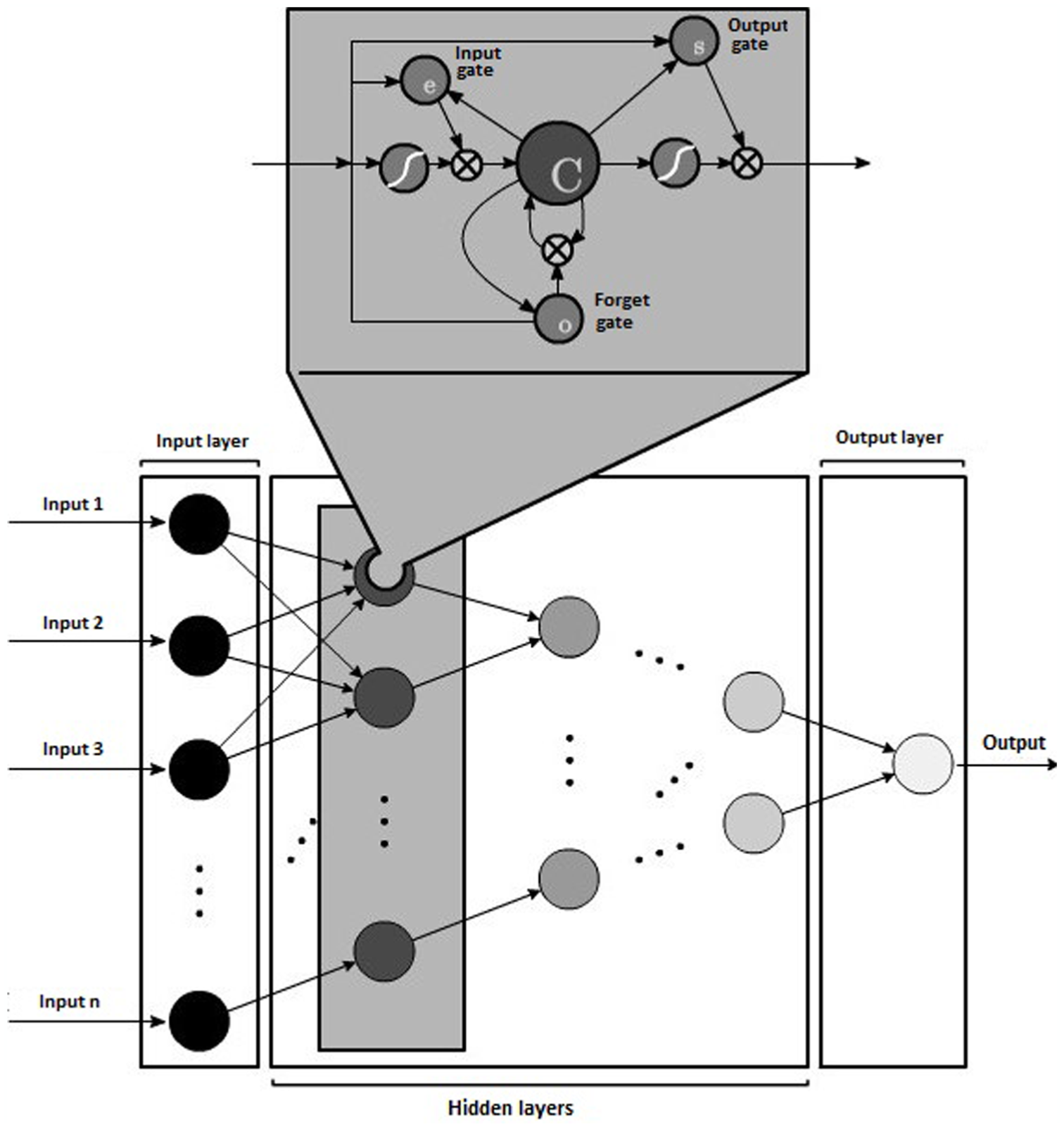
Graphical representation of LSTM-type neural networks.
Modeling of the input signal and LSTM model layers
A discrete input signal indicates the presence (1) or absence (0) of a PU within a spectrum band for a time period T, according to equation (1), in which, based on the binary sequence, the predictor is trained to forecast channel status not only in the next time slot, but also in subsequent points in time based on the historical data of a PU’s behavior in the channel

Determining the exact number of neurons for resolving the characterization problem is especially difficult. A very small neural network cannot learn how to correctly solve the problem, but a very large network will generate an over adjustment (i.e. the problem is singled out, not generalized).
32
In addition, it must be taken into account that the more layers and neurons there are, the training time is greater, and more resources are used. In this article, the authors used a numerical optimization technique based on the geometric pyramid rule, which is especially useful when the number of input layer neurons is greater than the number of output layer neurons,
33
as is the case with this problem. Since it is necessary to divide the number of input layer neurons n times a power of

It is possible to discern from the preceding equation that the number of layers grows in a controlled fashion according to the increase in the number of input neurons. Due to the fact that a design decision was made to develop a dynamic software application where the creation of the LSTM neural network varies and depends on the input sequence, the total number of neurons that comprise a network topology is obtained from equation (3)

Equation (3) can be approximated to a geometric series that converges to equation (4)

Taking Co (from equation (4)) as a very large number, it can be assumed that the total number of neurons tends to

Equation (5) indicates that as the number of input layer neurons increases, the total number of neurons is approximately twice the number of input layer neurons. 34
LSTM system operating model
LSTM can be considered a differentiable function approximator that is usually trained with a descending gradient. 35 Although a truncated form of backpropagation through time (BPTT) was initially employed to approximate the error gradient, 36 a BPTT calculation without truncation, based on the discussion by Graves and Schmidhuber, 37 was used in this research. The operation of the LSTM neural network described in sections “Forward pass equations” and “Backward pass equations” uses the notation shown in Table 1. 35
Notation for the development of the mathematical model.

Forward pass equations
For the three cell gates (input, output, and forget),
35
the propagation functions
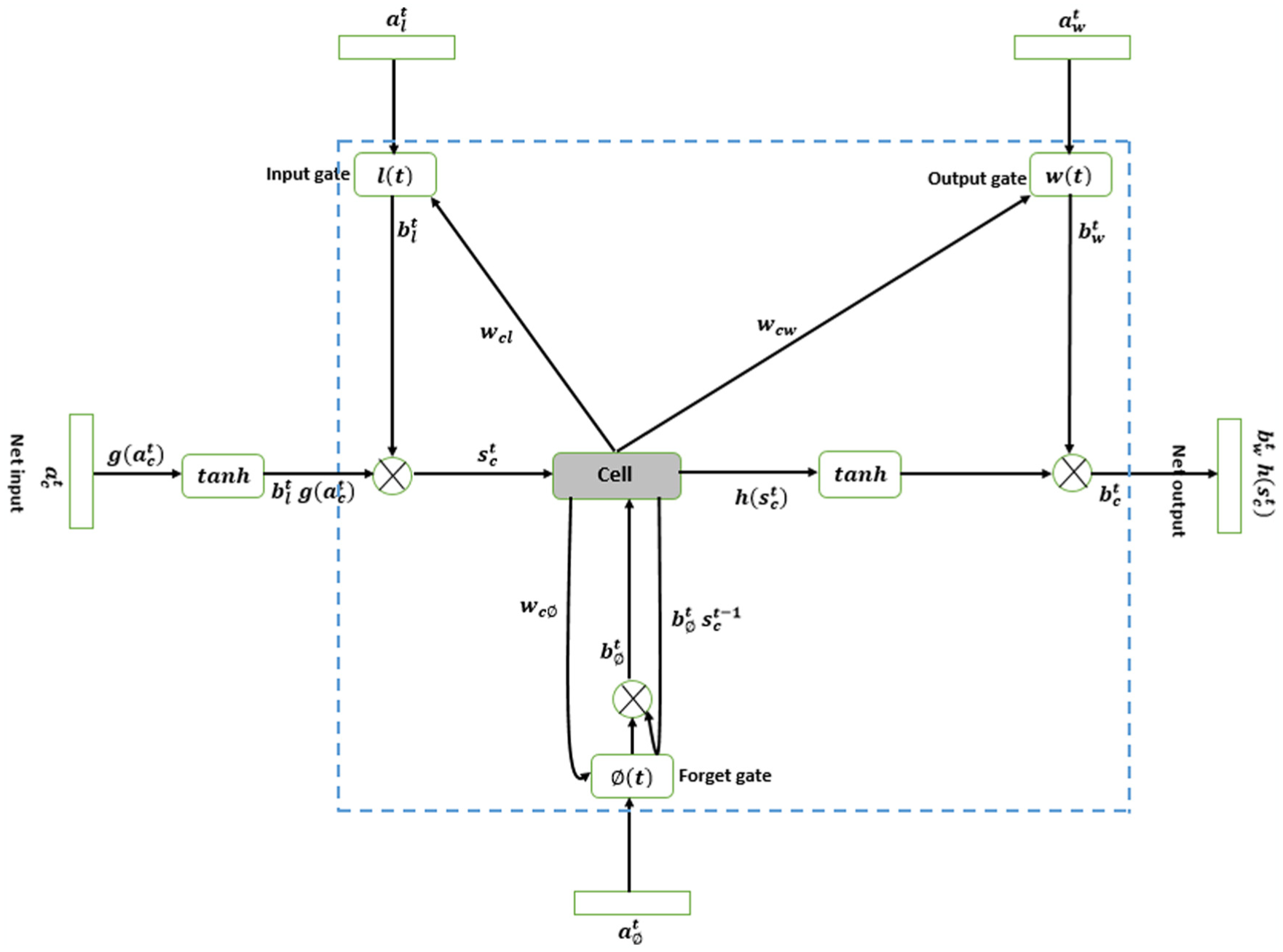
LSTM architecture used for the characterization of PUs.
For the input gate


For the forget gate


For the output gate

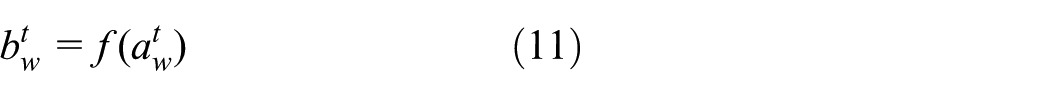
In order to describe a cell’s behavior, two elements must be taken into account. The first one is the
The neuron output
Neuron status


Neuron output

Backward pass equations
In order to obtain the backward pass equations, the BPTT method is used (as previously mentioned), 35 which implies using the chain rule to calculate the derivatives of errors at the exit of the components of an LSTM block.
When defining the outputs for input gate, output gate, and forget gate as

In addition, in defining cell output (
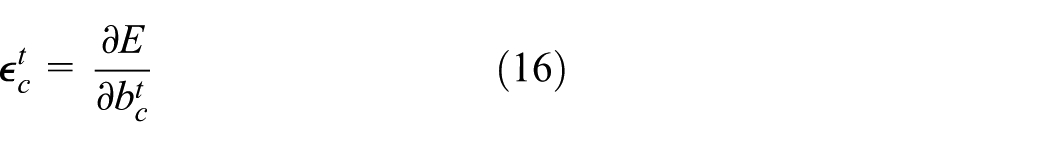

Defining E (in equations (16) and (17)) as the loss function (error), and based on the fact that the purpose is to establish how the error varies when the weights are modified, the following is obtained based on the chain rule

From equation (18), it is clear the goal is to calculate




Taking into account that the summation is done over c because the model is developed in a single block (with C cells inside), the mathematical descriptions shown in equation (23) are found when calculating the respective derivatives 34

Based on the mathematical analysis applied above, the following backward pass equations are obtained34,35
Output gate
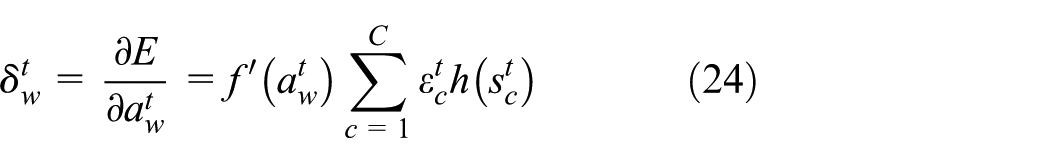
Cell

Forget gate

Input gate

Note that equations (24)–(27) depend on the
In this case, keep in mind that the error is a function with variables that are the K outputs generated by the H blocks of the hidden layer; in fact, for a given block, the resulting output in a time t will affect the K units of the output layer (at a time t) and at the next input to each one of the H blocks in the hidden layer.
34
Therefore,
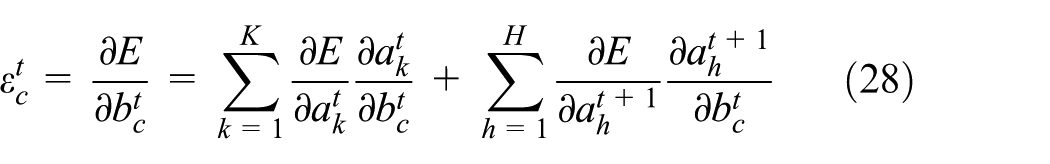
The cell output is described as follows by equation (29)

Finally, it is necessary to analyze what happens with the error if changes to cell status are made. The status of the cell c in time

The status of the cell is 35 (equation (31))

Flowchart and pseudo-code for the LSTM system
The training flowchart (Figure 4) for the process begins by randomly initializing each neuron with values between −1 and 1; after that, each training example is read and the output is compared with the expected output. If the response obtained does not match what was expected, the algorithm calculates the error between the system output and the expected output, correcting each weight of the gates (input, output, forget) and the cell by applying weighting and making use of hyperbolic tangent and sigmoid functions until completing all training examples, thus bringing the model’s output close to the expected output (by error reduction, as shown in section “LSTM system operating model”). 34

Flowchart for LSTM training.
Part of the pseudo-code for the algorithm that was implemented 34 is shown below.

Results analysis and evaluation
Capture and processing of spectrum information
For data capture, the first step was to determine what wireless network application would be used to evaluate the deep learning–based technique. 36 Cellular (GSM) and Internet access (WiFi) communications were chosen as the main objective. The second step was to select the spectrum detection technique to be used. Energy detection was selected because it is easily implemented and has low requirements. 39 On the latter, it is important to indicate that in order to determine whether a frequency channel is occupied or not, a decision threshold was determined based on the noise floor average for the frequency band used, and from said value, a guard level of 5 dBm above was determined, with the aim of minimizing possible false alarms or detection failures.
The manner in which data capture was performed is shown in Figure 5; Table 2 shows the spectrum measurement technical specifications. Table 3 shows the characteristics of the cluster used as a computing resource for the development of the algorithm and the execution of the training and prediction tests.

Interconnection of equipment for capturing spectrum occupation data. 33
Specifications of equipment for spectrum measurement and capture.

Cluster specifications.

For the processing of spectrum information, measurements were made every 290 ms in the WiFi band (2.4–2.48 GHz) and GSM (uplink 824–849 MHz) in terms of transmission power; in addition, in order to facilitate pattern recognition, power levels were presented in binary form based on the definition established in equation (32) 34

where the values of a are −89 dBm for GSM and −88 dBm for WiFi.
Figure 6 shows the procedure for converting the spectrum data traces into discrete signals. It is worth noting that when performing the tests, a 6.79 GB database was available with information on GSM traffic traces, and a 9.63 GB database was available for WiFi traces, with more than 10,000 data records per files obtained from Pedraza et al. 40

Flowchart for the discretization of spectrum data.
Evaluation and validation of the proposed LSTM algorithm
The performance of the proposed algorithm was tested for PU behavior with simulated and real data sequences (GSM and WiFi traces), based on the premise that 70% of the data is used in the LSTM network training stage, and the other 30% for validation (estimating the prediction).
First group of test cases
Behavior patterns (of multiple sizes) were created through simulation based on what is suggested in Saleem and Rehmani 41 and in accordance with Table 4. 34
Test cases for PU traffic traces generated through simulation.

PU: primary user.
For qualitative purposes, results are presented for the LSTM algorithm when modeling and estimating the future behavior of a licensed user (for TC2), with a high fluctuation between presence and absence in the licensed channel. 35 The binary sequence that simulates channel use is made up of 50 digits. Figure 7 shows the sequence for the first 22 digits as 01111011110111101, where PU presence is represented by a 1, and PU absence, by a 0.

Behavior of historical data for 77 samples.
The application that was developed generates adaptively (Figure 8) the LSTM neural network structure that is most appropriate for the input sequence according to what was set forth in section called “Modeling of the input signal and LSTM model layers.”

Neural network topology.
The learning stage (training-modeling) is shown in Figure 9, where it is concluded that the LSTM network was 100% capable of determining the pattern of channel use.

Results of the training stage (network learning phase).
The future estimation (forecast) delivered by the neural network through the developed application is shown in Figure 10, where we can see that the success level comparing the original signal (purple sequence) and the one projected by the system (blue lines) is 81.77%, concluding that the prediction error is 18.2275%, which indicates that the network is relatively efficient for the case evaluated. Quantitative results for the different cases listed in Table 4 are shown in Table 5. The performance evaluation metrics (Table 5) refer to average values, because historical data of various sizes were created (17, 35, 77, 157, and 200 binary digits), applying 10 tests for each case because different solutions could be obtained each time the algorithm is executed. The LSTM algorithm was validated with the same metrics and the same considerations, but using a pyramid MLPNN (see Table 6).

Prediction results.
Performance of LSTM in the characterization of PUs.

LSTM: long short-term memory; PU: primary user.
Performance of MLPNN in the characterization of PUs.

MLPNN: multilayer perceptron neural network; PU: primary user.
Analysis of Tables 5 and 6 reveals that the average prediction error for LSTM ranges from 0% to 35.45%, placing the forecast level above 64.54% in the worst case (TC5), a percentage that is higher than what was found with MLPNN (49.19%). This indicates LSTM was able to generalize the behavior for the various cases that were submitted and was able to adequately predict PU behavior at any instant in time t as long as the PU continues to have the same behavior. Another important feature is that although LSTM has more neurons in its structure than MLPNN, it required less iterations in TC1 through TC4, which proves that the complexity of the LSTM structure allows abstracting the PU signal behavior pattern at a lower computing cost when the size of the matrix used for historical data has a short length. Finally, the average validation error is very small for both types of neural networks, a condition that guarantees the network can be optimally modeled.
Second group of test cases
To demonstrate the viability of the proposed algorithm with real GSM and WiFi traffic traces (according to the characteristics laid out in section “Capture and processing of spectrum information”), a metric called Index of Occupation (Io) was defined (equation (33)) in order to divide spectrum band use levels into high, medium, and low; this allows a more objective and detailed assessment

where
Algorithm performance for GSM flows.

LSTM: long short-term memory; MLPNN: multilayer perceptron neural network; ANFIS-Grid: adaptive neuro-fuzzy inference systems.
Algorithm execution results for WiFi flows.

LSTM: long short-term memory; MLPNN: multilayer perceptron neural network; ANFIS-Grid: adaptive neuro-fuzzy inference systems.
Based on the quantitative results in the above tables, it can initially be concluded that the training time of the various models for estimating channel use behavior (on the part of PUs) is greater in the case of LSTM due to greater complexity (input, output, and forget cells) incurred by this type of recurrent network when modeling PUs. LSTM’s ability to learn patterns and forget sequences directly impacts the validation error performance evaluation metric, which is optimal in comparison with MLPNN, Bayesian networks, and ANFIS-Grid. It was also found that the training error exhibits better values in LSTM than in ANFIS-Grid, due to its storage and pattern utilization capability over time, a characteristic that is inherent to deep learning intelligent systems.
Regarding LSTM’s accuracy percentage, the values range between 98.25% (for a low Io) and 79.85% (for a high Io) in GSM systems, and between 87.46% (for a low Io) and 64.87% (for a high Io) in WiFi, thus validating that LSTM is more efficient than MLPNN, Bayesian networks, and ANFIS-Grid, as shown in Table 9; however, it is important to point out that greater efficiency implies greater hardware requirements, a factor that is not relevant if the prediction system is implemented in CR networks with a centralized topology.
Accuracy percentage in the estimation of licensed channel use by primary users.

LSTM: long short-term memory; MLPNN: multilayer perceptron neural network; ANFIS-Grid: adaptive neuro-fuzzy inference systems.
Regarding the algorithms’ performance improvement with GSM and WiFi traffic traces, better performance is observed for GSM, probably due to the chaotic nature of signals in WiFi networks.
Finally, just as in the first test case, Figures 11–14 are a qualitative description of the visual behavior of the characterization software that was developed, in part of the sequence used as a historical representation in system performance evaluation with GSM traces.

Historical representation of inputs to the system (discretized GSM traces).

LSTM network topology dynamically generated by software.
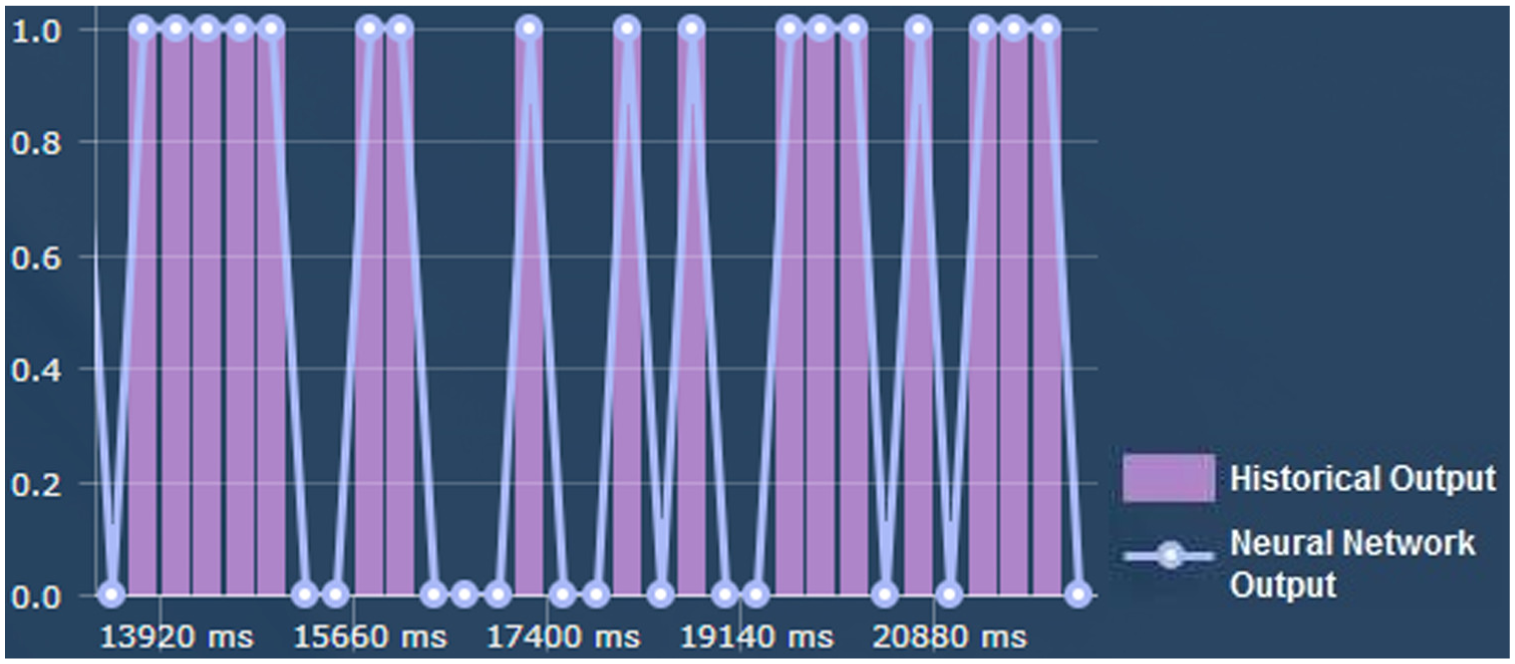
Results of the training stage (network learning phase).
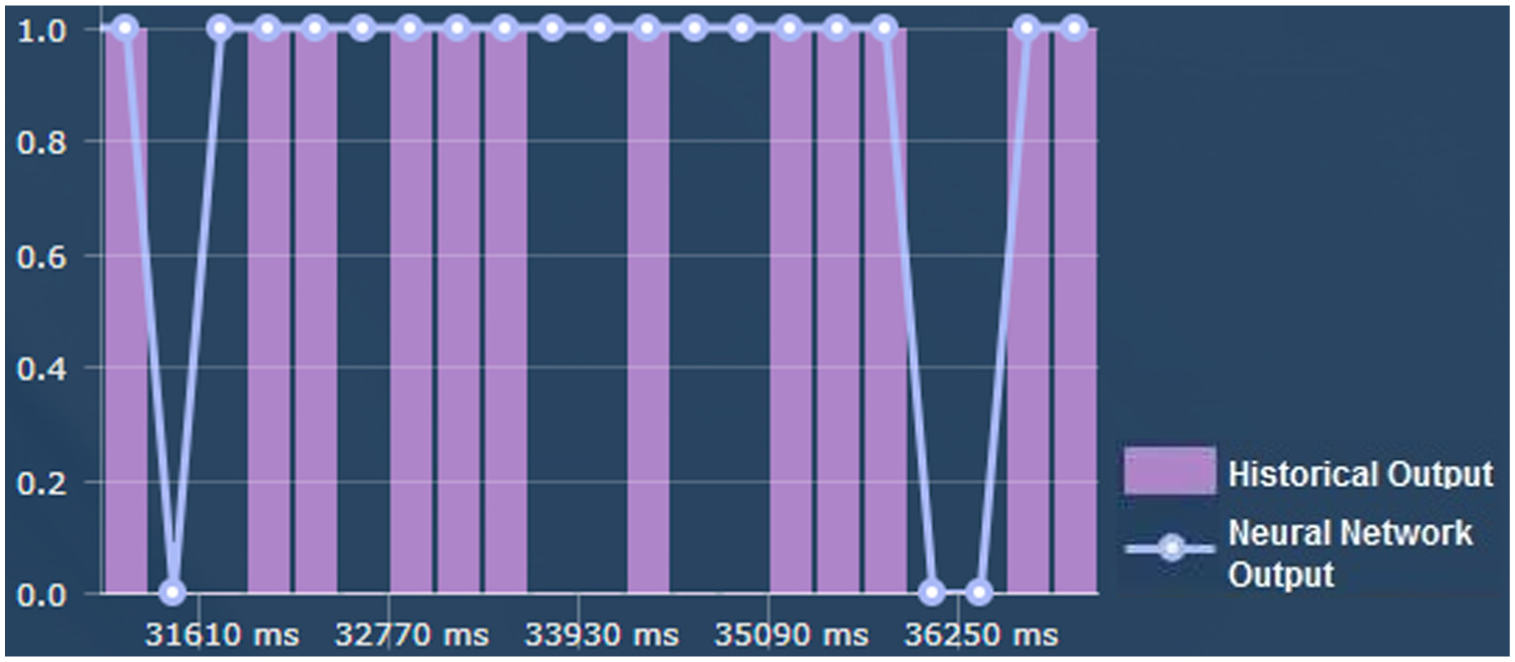
Prediction delivered by the characterization software with LSTM.
Discussion
In the AI field, neural networks have been extensively applied to time series given the prediction capabilities for unknown time units, due to the ability to be trained by means of examples in order to abstract a behavior. This contrasts with other AI techniques, which obtain the knowledge from an expert through the representation of variables relevant to the solution of the problem. One of the most widely used supervised learning methodologies for the characterization of PUs is MLPNN, which can achieve an efficiency improvement of up to 60% in prediction, as concluded in Adeel et al. 42 (although higher percentages were achieved in tests); however, there have been recent proposals for the use of techniques based on deep learning, due to its high abstraction level 43 for the solution of multiple problems,44–47 a significant reason for suggesting its use in CR.
From the analysis in the previous section, it is evident that although LSTM exhibits a greater prediction capability, it still has a significant estimation error in cases in which PU behavior is chaotic or random; however, obtaining an error close to zero is difficult due to signal nature, a condition that can be supported from the perspective of entropy. From equation (34), when entropy is 1, this indicates there is a 50% probability the spectrum band is occupied at any point in time, which generates a high level of uncertainty when making channel occupation estimations. The opposite occurs when the value tends to zero (a more favorable condition)

where
Based on the above consideration, when calculating, for example, values for GSM–LSTM with high and low occupation indices, values of 0.7087981 and 0.1589255, respectively, are obtained, which is coherent with the prediction errors in Table 7; on the other hand, historical data generate indications of PU behavior, but no guarantee that it will actually occur again. However, having an indication of possible behavior allows a cognitive network central station to be prepared to take actions on the possible assignment of a frequency band to a SU.
An additional contribution of the application that was developed (for the LSTM algorithm) is the ability to automatically create a neural structure according to the size of the trace to be characterized; this is positive because no additional efforts are required to build the topology when modifying the behavior of input data. The opposite occurs, for example, in Adeel et al. 42 and Winston et al. 48
Another important aspect of analyzing relates to the speed of convergence shown by the algorithms (Figures 15 and 16), where it can be seen that the convergence time of LSTM is 78.15% (in the case of GSM) and 82.62% (in the case of WiFi) slower than MLPNN; this is due to the ability of LSTM to detect, process, and memorize characteristic patterns in PU signals that can later be reused to raise the level of prediction; this allows to infer that although LSTM improves the characterization of PUs, the computational cost is much higher since the operational complexity (described in Figure 3) is much greater.

Convergence time for GSM traffic flows.

Convergence time for WiFi traffic flows.
Finally, based on the results of PU activity modeling with the LSTM methodology, and taking as reference the proposal’s validation with respect to the MLPNN, Bayesian network, and ANFIS-Grid learning techniques, it can be concluded that deep learning–based techniques are potentially more suitable for solving the current problem in CRN networks. The reason is the structures contain deep layers or processing units that specialize in the detection of certain characteristics or hidden patterns in processed data, which are not found in other types of networks such as the ones evaluated in this article.
Conclusion and future work
Given the research results, the proposal for developing PU characterization algorithms that operate on input data using neural networks49,50 based on deep learning (as is the case for LSTM) should be considered a real and valid option in the search for new methodologies to minimize modeling and prediction error in the estimation of spectrum band use by PUs, thus improving performance in the spectrum decision stage for CR wireless networks. This statement is supported by the validation of results obtained with LSTM in contrast with other neural network techniques such as MLPNN, Bayesian networks, and ANFIS-Grid.
In reference to the test cases, where various PU behaviors were simulated, it was found that LSTM can easily adapt to multiple variations in traffic patterns, with a forecast accuracy above 79%; when the historical sequence has a prolonged absence/presence characteristic (as in television signals), it is possible to find estimations above 82%.
An important aspect of the research (contrary to what is said in multiple state-of-the-art proposals) is that the operation of the algorithm was corroborated with real traffic sources (GSM and WiFi), achieving accuracy percentages ranging from 79.85% to 98.25% (for GSM), thus proving the use of LSTM in real wireless systems is promising.
Based on multiple existing characterization proposals, there is no doubt that the application of LSTM neural networks is an innovative concept for the solution of the modeling and prediction problem. This line of research should continue to be evaluated when, for example, the neural system input data sequence does not exhibit a binary behavior, but a continuous behavior. The response to methodologies based on Arima time series should also be validated.
Footnotes
Handling Editor: Michelangelo Ceci
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.