
Abstract
This work focuses on multi-objective scheduling problems of automated manufacturing systems. Such an automated manufacturing system has limited resources and flexibility of processing routes of jobs, and hence is prone to deadlock. Its scheduling problem includes both deadlock avoidance and performance optimization. A new Pareto-based genetic algorithm is proposed to solve multi-objective scheduling problems of automated manufacturing systems. In automated manufacturing systems, scheduling not only sets up a routing for each job but also provides a feasible sequence of job operations. Possible solutions are expressed as individuals containing information of processing routes and the operation sequence of all jobs. The feasibility of individuals is checked by the Petri net model of an automated manufacturing system and its deadlock controller, and infeasible individuals are amended into feasible ones. The proposed algorithm has been tested with different instances and compared to the modified non-dominated sorting genetic algorithm II. The experiment results show the feasibility and effectiveness of the proposed algorithm.
Keywords
Introduction
Scheduling is a resource allocation process over a period of time to perform a set of tasks. 1 Flexible flow-shop and job-shop scheduling (FSP and FJS, respectively) are one of the most important problems in the area of production scheduling, and these are all well-known non-deterministic polynomial-time (NP)-hard. 2 In the study of these scheduling problems, it is usually assumed that the capacity of buffers for storing jobs is unlimited, and hence, when a machine has finished processing a job, the job can leave immediately, and the machine can start processing other jobs, that is to say, there is no blockage. However, in practical automated manufacturing systems (AMSs),3–5 machines, buffers, robots, and other resources that can hold jobs are always limited. The finiteness of all these resources makes the system not only have the blockage problem but also encounter the so-called deadlock.6–21 The deadlock situation occurs when a set of jobs are in “circular waiting,” that is, each job in the set waits for a resource held by another job in the same set. 9 For such an AMS, the required resource allocation or scheduling strategy can not only prevent the system from falling into deadlock but also optimize the system performance.7,12,13,22–26 Therefore, it is more important to develop such a scheduling strategy.
In order to solve the problem of optimization scheduling for AMSs with limited resources, deadlock control strategies should be established in advance. 22 This is much of the reason that the deadlock problem of AMSs has been studied extensively. Since Petri nets (PNs) can clearly describe the characteristics of AMSs such as resource sharing, conflict, concurrency, and deadlock,14–18 they are widely used to model the dynamic evolution of AMSs. Based on PNs, various deadlock control strategies or controllers for AMSs have been proposed, mainly including two kinds: deadlock avoidance and deadlock prevention. Of these, the former are online control policies that use feedback information on the current resource allocation status and future process resource requirements to keep the system away from deadlock states,13,14 while latter are offline and guarantee that necessary conditions for circular waiting or deadlock cannot be satisfied at any time of the AMS dynamic.20–24
The joint consideration of scheduling and deadlock control of AMSs leads to more complex and difficult combinatorial optimization problems. Classical scheduling methods for flexible flow-shop and FJS cannot be directly used to solve such problems, while it is a great challenge to extend and modify them for deadlock-prone AMSs. Therefore, there are few researches on AMS scheduling. Ramaswamy and Joshi 7 established a mathematical programming model of the scheduling problem for AMS with no route flexibility, and a Lagrangian relaxation heuristic was used to search for the optimized average flow time. Gomes et al. 8 investigated the scheduling problem of flexible job-shop with groups of parallel homogeneous machines and limited intermediate buffers, and developed the integer linear programming model of the scheduling problem to meet the just-in-time due dates. By solving this integer linear programming, an optimal schedule can be obtained if it is feasible. Brucker et al. 10 and Heitmann 11 investigated job-shop scheduling problems with limited buffer constraints by classifying buffers into machine-dependent output and input buffers, and part-dependent buffers. Fahmy et al.12,13 presented an insertion heuristic based on Latin rectangles. This heuristic is capable to take into account limited buffer capacities and to avoid deadlocks, and hence, can obtain a feasible schedule.
In Xing et al., 25 a genetic scheduling algorithm for AMSs is developed directly using a predesigned controller to minimize the makespan. Based on the deadlock search algorithm, 20 a one-step look-ahead method is developed to avoid deadlocks by amending those infeasible individuals to feasible ones. A feasible individual can be decoded directly to a schedule. This approach is improved in Han et al. 26 using different kinds of crossover and mutation operations in genetic algorithm. Computational results show the good improvement in performance. At the same time, based on the one-step look-ahead method presented in Xing et al., 20 several kinds of heuristic and intelligence optimization scheduling algorithms are established.27,28 Baruwa et al. 29 proposed a heuristic scheduling algorithm based on timed-colored PNs. During the exploration, deadlock states are marked and the paths to those states are terminated to prevent the system from encountering them.
All above research on scheduling problems of AMSs has been concentrated on single objective alone. However, several objectives must be considered simultaneously in the real-world production situation and these objectives often conflict with each other. Previous research on multi-objective scheduling mainly focused on flexible flow-shop and FJS,30–39 while for deadlock-prone AMSs, it hardly involved. Kacem et al. 30 developed an effective evolutionary algorithm to solve multi-objective scheduling problems for flexible job-shops. An effective hybrid tabu search algorithm for solving multi-objective flexible job-shop scheduling problems was introduced by Li et al. 31 A Pareto-based particle swarm optimization and local search approach to multi-objective scheduling problems of flexible job-shops was proposed by Moslehi and Mahnam. 32 Rahmati et al. 33 proposed two evolutionary algorithms to solve the flexible job-shop scheduling problems with three objectives. To solve multi-objective flexible job-shop scheduling problem, a hybrid discrete particle swarm optimization algorithm with simulated annealing algorithm and Pareto-based grouping discrete harmony search algorithm were proposed by Shao et al. 34 and Gao et al. 35 For solving the multi-objective flexible job-shop scheduling problem with limited resource constraints, a hybrid discrete firefly algorithm is presented in Karthikeyan et al., 36 where limited resource constraints are used to balance between the resource limitation and machine flexibility. While for different multi-objective flow-shop scheduling problems, many methods are proposed, such as estimation of distribution algorithm, 37 multi-phase covering Pareto-optimal front method, 38 and multi-phase approach. 39
For a multi-objective optimization problem, there is often no single optimal solution, but rather a set of optimal solutions, called as Pareto-optimal solutions. They are optimal in the wider sense that no other solutions in the search space are superior to them when all objectives are considered. A number of evolutionary algorithms have been used to deal with multi-objective optimization problems.40,41 They generate widely different Pareto-optimal solutions by combination of parent and offspring populations and using various diversity-preserving mechanisms, and have the ability to find multiple Pareto-optimal solutions in one single run. The non-dominated sorting genetic algorithm II (NSGAII) 42 is one of such evolutionary algorithms that is modified from non-dominated sorting genetic algorithms (NSGA) in Srinivas and Deb 40 and Deb 41 and hence better than NSGA.
This article considers the multi-objective scheduling problems for deadlock-prone AMSs. A Pareto genetic algorithm (PGA) is proposed based on the PN models of AMSs. In the proposed PGA, a candidate schedule is first represented as an individual. Due to the constraint of limited resource capacity, these individuals in a population may be infeasible, that is, they cannot be directly decoded into feasible schedules or feasible firing sequences of transitions in PN model, and hence, it is necessary to check the feasibility of new individuals generated in initialization and genetic operators and modify infeasible individuals into feasible ones. In this article, deadlock control policies are used directly to check the feasibility of individuals and modify them if necessary, and the Pareto dominance and crowding distance in Shao et al. 37 are used to update solutions in the sense of multi-objective optimization, while a new elitist strategy in order to avoid premature convergence is proposed.
A set of simulation examples is used to show the feasibility and effectiveness of the proposed method. At the same time, the proposed algorithm is compared with NSGAII. Note that the basic NSGAII in Deb et al. 42 is aimed at continuous optimization problems and cannot be directly used to solve our scheduling problems. In order to solve our combinatorial optimization problem, the basic NSGAII is modified first. In the modified NSGAII (MNSGAII), the mechanism of evolution and elitist strategy in the basic NSGAII is adopted directly, while a deadlock prevention policy is embedded to ensure individual feasibility. Hence, MNSGAII is actually another new algorithm for solving the multi-objective scheduling problem of deadlock-prone AMSs. The simulation results show that PGA and MNSGAII are feasible for solving the multi-objective scheduling problem considered, and PGA has better performance.
The remaining contents are organized as follows. In section “Modeling of AMSs and deadlock controller based on PNs,” PN scheduling modeling of AMS and its deadlock control policy are briefly reviewed. In section “Multi-objective deadlock-free genetic scheduling algorithm for AMSs,” the PGA is proposed. Section “Simulation results and comparisons” presents the results of the simulation computation and comparison. Section “Conclusion” concludes this article.
Modeling of AMSs and deadlock controller based on PNs
This section introduces the AMSs considered, and their PN scheduling models, and then the deadlock control policy used in this article.
PN scheduling models of AMSs
An ordinary PN is a four-tuple N = (P, T, F, M0), where P and T are finite sets of places and transitions, respectively. F⊆ (P×T) ∪ (T×P) is the set of directed arcs. M0 is the initial marking of N and M0: P→ℤ+, where ℤ+ is the set of non-negative integers.
For place p ∈ P and transition t ∈ T, let •p (p•) denote the set of input (or output) transitions of p, and let •t (t•) denote the set of input (or output) places of t.
Transition t is enabled at M0, if ∀p ∈ •t, M0(p) > 0. An enabled transition t at M0 can fire, resulting a new marking M, denoted by M0[t > M, where M is obtained by removing one token from each input place of t and putting one token to each output place of t. Let R(N, M0) be the set of all markings of N reachable from M0.
The AMS considered in this article consists of m types of resources and can process n types of jobs. A type of resources may be some identical machines, robots, automatic guidance vehicles, and buffers. The capacity of each type of resources is limited.
A job can have multiple predefined sequences of operations and can be completed by processing all operations of such one sequence in order. The processing of an operation requires a unit resource and appropriate time. At the same moment, each unit resource can process at most one job, and a job can only be processed on one unit resource. We assume that the resources for processing two adjacent operations in the same sequence are different, and all jobs and resources are available at the beginning. For job j, let Oj = oj1ou2…ojL(j) be a predefined operation sequence for it, and ℜ(ojk) be the resource required for processing operation ojk. Then, ℜ(Oj) ≡ℜ(oj1)ℜ(oj2) …ℜ(ojL(j)) is a processing route of job j though the system. The same type of jobs has the same set of processing routes.
Following the PN modeling methods proposed in Ezpeleta et al. 21 and Xing et al., 25 this article develops a PN model for AMS, called PN for Scheduling (PNS). The PNS of a simple flexible manufacturing system (FMS) is depicted in Figure 1.

The PNS of a simple FMS.
In the PNS of an AMS, there are two classes of places, operation and resource places. A token in an operation place represents a job whose operation is being performed, while a token in a resource place represents that a unit resource is available. Resource type r is modeled by a resource place, denoted also as r. Its initial marking is the capacity of r, C(r), indicating that the maximum number of jobs that such type of resources can simultaneously hold.
A processing route or an operation sequence of a job is modeled by a path of transitions and operation places in PNS. For example, a predefined operation sequence of job j, Oj = oj1oj2…ojL(j) is modeled by a path π j = tj1pj1tj2pu2…tjL(j)pjL(j)tj(L(j)+1), where place pjk simulates operation ojk of job j being processed on R(ojk); the firing of a transition represents either the start or/and completion of an operation process, and the completion transition of the current operation is the same as the start transition of the next operation. For example, in Figure 1, tj1 is the start transition of operation oj1, while tj2 is the start transition of operation oj2 and the completion transition of oj1.
Two types of virtual places in PNS are used to model two classes of infinite buffers storing unprocessed and finished jobs, respectively. For example, in PNS shown in Figure 1, p1s and p2s store unprocessed jobs, and p1e and p2e store finished jobs of types, q1 and q2, respectively. The requirement and release of resources are modeled by arcs. If an operation oij modeled by place p in path π requires resource r, then add an arc from resource place r to start transition t1 of oij and an arc from its completion transition t2 to r. Then, for a given transition t, •t = (o)t ∪ (r)t, where (o)t is the input operation place of t and (r)t is the input resource place of t.
In addition, the processing time of an operation of a job is represented by time delay associated with the corresponding operation place, say p, and is defined as d(p). That is, PNS is a place-timed PN.
At the beginning, all jobs are unprocessed and the resources are idle and available. Then, the initial marking M0 of PNS is M0(pis) = χ i and M0(r) = C(r), where χ i is the number of type-qi jobs and C(r) is the capacity of type-r resources; the initial markings of other places are 0. When all operations of all jobs are finished, tokens in pis are moved into pie, and the PNS reaches its final marking Mf.
Example 1
Consider an AMS consisting of five machines m1–m5. Their capacities are given as C(mi) = 1, i ∈ {1, 2, 4}, and C(mj) = 2, j ∈ {3, 5}. The system can process two types of jobs, types q1 and q2. Type-q1 jobs have two processing routes, denoted as w1 and w2, respectively. Type-q2 jobs have one processing route, denoted as w3. If three type-q1 and two type-q2 jobs are processed, then the PNS of the system is as shown in Figure 1, and there are three and two tokens in places p1s and p2s, respectively. Three processing routes for jobs are modeled by three paths in PNS, w1 = p1st11p11t12p12t13p13t14p14t15p1e, w2=p1st11p11t22p22t23p23t24p14t15p1e, and w3 = p2st31p31t32p32t33p33t34p2e, respectively. At the beginning, the system state, that is, the initial marking of the PNS is M0 = 3p1s + 2p2s + 2 m1 + m2 + m3 + 2 m4 + m5, where kp denotes that place p has k tokens. When all the jobs are finished, the PNS reaches the final marking Mf = 2 m1 + m2 + m3 + 2 m4 + m5 + 3p1e + 2p2e.
Deadlock controllers for PNS
Since all resources are finite, the considered AMS may enter deadlock state if not be properly constrained or controlled. A lot of research has been done on deadlock problem in AMSs and many deadlock prevention policies or controllers for AMSs have been proposed. All these policies can be directly used to avoid deadlock in stochastic Petri nets (SPNs). For details of the deadlock control, please refer to previous studies.12–20
Multi-objective deadlock-free genetic scheduling algorithm for AMSs
Multi-objective optimization problem
In mathematical terms, a multi-objective optimization problem can be formulated as

where x is a feasible solution, F is a vector of L objective functions, and X is the feasible solution space. In a multi-objective optimization, there does not typically exist a feasible solution that optimizes all objective functions simultaneously. Therefore, attention is paid to Pareto-optimal solutions. That is, solutions that cannot be improved in any of the objectives without degrading at least one of the other objectives:
Pareto dominance: let x1 and x2 be two feasible solutions. x1 is said to dominate x2, denoted as x1 ≺ x2, if fj(x1) ≤ fj(x2), ∀j ∈ ℤ L ≡ {1, 2, …, L} and ∃k ∈ ℤ L , fk(x1) < fk(x2).
Pareto-optimal solution: a feasible solution x* is a Pareto-optimal solution if there does not exist any other feasible solution which dominates x*. The corresponding objective function is called the Pareto-optimal front vector f(x*). The Pareto set is the set of all Pareto-optimal solutions and the corresponding objective vectors form the Pareto-optimal front.
Formulation of scheduling problem
Suppose that there are n jobs J1–Jn to be processed, and the due date of Ji is di. The goal is to find a feasible schedule so as to optimize a set of predefined objectives. Such a feasible schedule is equivalent to a feasible sequence of firing transitions of the SPN model from the initial marking M0 to final marking Mf.
For a feasible schedule π, let Ci(π) denote the completion time of job Ji under π, and the lateness of Ji is Li(π) = Ci(π) – di. The following scheduling objectives are frequently used:1,33,39
1. Makespan (Cmax): it is the maximal of completion time of all jobs and can be defined as

2. Mean of earliness and tardiness (ϖ): it is the average of the earliness or tardiness of all jobs relative to their own due dates, denoted as

3. Mean completion time (Δ): it is defined as Δ = Σi ∈ ℤn Ci(π)/n.
In this article, we consider the above three scheduling objectives—Cmax, ϖ, and Δ. In PNS, let π = t0t1t2…tN−1 be a feasible sequence of transitions, oij denote the jth operation of Ji, and L(tk[oij]) denote the earliest firing time of tk that is also the start processing time of operation oij, where tk[oij] denotes tk as the start transition of oij. Feasibility of π implies that π can be fired sequentially. Thus, tk[oij] can be fired only after operation oi(j−1) is finished and tk−1 is fired. Let tk−1 and ts be the start transitions of ouv and oi(j−1), respectively. The completion time of oi(j−1) is L(ts[oi(j−1)])+d (oi(j−1)), and the firing time of tk−1 is L(tk−1[ouv]). Then, L(tk[oij]) = max{L(ts[oi(j−1)]) + d(oi(j−1)), L(tk−1[ouv])}. The completion time of job Ji and the makespan of π are Ci(π) = maxj{L(tk[oij]) + d(oij)} and Cmax(π) = maxi, j {L(tk[oij]) + d(oij)}, respectively. Clearly, when due date di (i ∈ ℤ n ) is given, we can calculate ϖ and Δ based on Ci(α(π)).
Multi-objective scheduling algorithm
In order to obtain a feasible sequence of firing transitions to optimize multiple objectives, this article proposes a PGA based on PNS. In AMSs, a job may have multiple processing routes, and a scheduling should arrange not only a processing route for each job but also the start processing time of each operation. Hence, in the proposed PGA, an individual consists of two sections, route, and operation sections. The former sets up a processing route for each job, while the latter provides a sequence of operations of all jobs. As long as this operation sequence can be executed according to the given routes, this individual can be decoded directly into a feasible schedule, which is a feasible sequence of transitions without leading to deadlocks, and hence it is called as a feasible individual. Note that not all individuals are feasible because deadlocks may occur. With the help of the SPN model and its deadlock controller, the feasibility of each individual is checked and unfeasible individual is repaired to feasible one. The main components of the proposed PGA can be described in detail as follows:
1. Encoding and decoding: the encoding scheme in this work is based on the job permutation with repetition. A job permutation with repetition is a permutation of jobs, and each job may appear many times. Similar to Xing et al., 25 an individual can be written as two sections π = (Sr; So), where Sr describes the route information of jobs and So is a permutation with repetition of all the jobs. Sr is an n-dimension vector Sr = (w1, w2, …, wn), where n is the number of jobs and wi represents the route through which job Ji is processed. In So, a type-x job Ji appears l(x) times, where l(x) is the number of operations on the longest processing route of type-x jobs.
In individual π = (Sr; So), let the jth Ji in So represent the jth operation of Ji on route wi. Then, So can also be expressed as a sequence of operations (discarding redundant jobs), and by one-to-one correspondence between the operation and its start transition in PNS, π can be decoded uniquely as a sequence of transitions, denoted as α(π). In the decoding process, if there are some redundant Ji (i.e. the route specified by Sr for Ji, wi, is shorter than the longest route of Ji), discard them.
Example 2
Reconsider the PNS shown in Figure 1. Now suppose that there are five jobs to be processed, three type-q1 jobs J1−J3 and two type-q2 jobs J4−J5. The PNS has three processing routes, denoted as w1, w2, and w3, where w1 and w2 are for type-q1 jobs and w3 for type-q2 jobs, respectively. Then, Sr1 = (w1, w2, w1, w3, w3) can be used as the first section of an individual π1, meaning that jobs J1−J5 are processed through routes w1, w2, w1, w3, and w3, respectively. Since l(q1) = 4 and l(q2) = 3, the operation section can be expressed as a permutation with repetition in which J1, J2, and J3 all appear four times, while J4 and J5 appear three times, respectively. For example, So1 = (J1, J1, J5, J3, J2, J2, J4, J5, J2, J3, J3, J4, J4, J5, J2, J1, J1, J3) can be used as the second section of π1. Then, π1 can be expressed as π1 = (Sr1; So1) = (w1, w2, w1, w3, w3; J1, J1, J5, J3, J2, J2, J4, J5, J2, J3, J3, J4, J4, J5, J2, J1, J1, J3). The first three terms of So1 are J1, J1, and J5, and represent the first and second operations of J1 in route w1, and the first operation of J5 in route w3, respectively. As a sequence of transitions, π1 can be decoded as α(π1) = (t11[J1], t12[J1], t31[J5], t11[J3], t11[J2], t22[J2], t31[J4], t32[J5], t23[J2], t12[J3], t13[J3], t32[J4], t33[J4], t33[J5], t24[J2], t13[J1], t14[J1], t14[J3]). Note that α(π1) is not a complete and feasible sequence, that is, it cannot lead the system from M0 to Mf, because it does not include the last transition in each route, say t15 and t34, and may lead deadlock. For completeness, add the last transition of each route for each job to the back of α(π1), and α(π1) added to these transitions is still denoted as α(π1), called the transition sequence of π1.
In the above decoding procedure, resource and deadlock control constraints are not considered. As a result, although α(π) contains complete firing transitions from M0 to Mf, it may still be infeasible. Thus, the feasibility of each individual needs to be checked, and it is necessary to amend infeasible individuals into feasible ones.
2. Individual feasibility check and amendment: in this article, individual feasibility check and amendment is based on SPN and the used deadlock controller. When an individual is checked as infeasible, it is amended. The check and amendment are carried out in the same recursive procedure, and the details as shown in Algorithm IFCA.
Let (N, M0) be the PNS model of an AMS and its deadlock controller (C, MC). The controlled PNS can be expressed as (NC, MC0) = (N, M0) ⊗ (C, MC). For a given individual π = (Sr; So) and its transition sequence α(π), the algorithm is a recursive procedure based on the controlled PNS (NC, MC0). It begins from the first transition of α(π) and the initial marking MC0, and checks whether the current transition t is enabled at the current marking M. If t is enabled, update the current marking M by firing t and move to the next transition in α(π); otherwise, find the first enabled transition t* at M after t in α(π) and move t* to the tight front of t in α(π). If no transition after t is enabled at M, it is necessary to adjust the processing route of some job. Repeat the aforementioned steps until the last transition in α(π) is checked.
Since the controlled PNS is live, there exists at least one transition enabled at any reachable marking M ∈ R(NC, MC0)\{Mf}. But, it is possible that none of transitions enabled at M are in the routes specified in π. That is, the routes that some jobs can take conflict with the specified ones. In this case, it is necessary to change the specified processing route in π for the corresponding job.
Algorithm IFCA: Individual feasibility check and amendment
Input: An individual π≡ (Sr; So);
Output: A feasible schedule α(π).
Generate π = (w1, w2, …, wn; o1, o2, …, oK) and α(π) = t1t2…tK by decoding π;
Let i:= 1, and Mi:= MC0;
For (i = 1; i≤K; i ++) do {
For (j = 0; j < K; j++) do {
If (i + j ≤ N and ti + j is enabled at Mi) then {
Set α(π) ≡t1t2…tN := t1t2…ti−1ti + jti…ti + j−1ti + j + 1…tK;
Set So≡o1o2…oN:= o1o2…oi−1oi + joi…oi + j−1oi + j + 1…oK;
Mi[ti + j > Mi + 1;
break;
} //end If()
If (i + j > K) then { /*ti, …, tK are not enabledat Mi.*/
Find a transition t enabled at Mi. Suppose that the job enabling t is Ju, and t is on route w of Ju; //note that such t certainly exists, and wu≠w.
Reset wu = w, and update Sr, So, and α(π) correspondingly;
j = 0; /* restart from ti.*/
} //end If()
} //end For(j)
} //end For(i)
Output α(π);
The individual feasibility checks and amendment in Algorithm IFCA are based on the controlled net, that is to say, the deadlock controller is designed beforehand. For a given individual, the number of transitions in α(π), K, is at most l * n, where l is the longest length of all processing routes and n is the number of jobs to be processed. That is, K≤l * n. The algorithm need to check all K transitions once, while for each of them, say t, at most all transitions after t in α(π), less than K transitions, are detected. Thus, at most K2 transitions are detected in Algorithm IFCA, and hence, the algorithm has polynomial time complexity O((l * n)2).
When the algorithm is finished, a new feasible individual is obtained, and its corresponding sequence of transitions α(π) leads the PNS from M0 to Mf, and hence, is feasible. If the algorithm does not adjust any order of transitions of the input sequence α(π), the input individual π itself is feasible.
3. Non-dominated sort and crowding distance: for a multi-objective optimization problem, generally, there is no single solution that is the best with respect to all objectives. Alternatively, there usually exists a set of non-dominated solutions or Pareto-optimal solutions, for which no improvement in any objective is possible without sacrificing at least one of the other objectives.
For a given population W, in order to identify solutions of its first non-dominated front F1, Deb 41 proposed a sorting algorithm, called as Fast-Non-Dominated-Sort, FNDS(W), in which each solution is compared with every other solution in W to find if it is dominated. The first front F1 is a completely non-dominant set in the current population W, and actually, is the Pareto-front of W. Then, the algorithm is applied to the set of non–first front individuals, namely, W\F1, and the second front F2 is obtained. Repeat the algorithm, F3, …, and FV are computed. The algorithm sorts all individuals in population W into V non-dominated fronts F1, F2, …, and FV, Fu ∩ Fv = ∅ for u ≠ v, and W = F1 ∪ F2 ∪ … ∪ FV. The first front F1 is a completely non-dominant set in W, the second front F2 is dominated by the individuals in F1 only, F3 is dominated by the individuals in F1 ∪ F2, and so on. In this article, this Fast-Non-Dominated-Sort algorithm is used in the proposed PGA.
In the basic GA, the fitness function is used to guide simulations toward optimal solutions and the chromosome generation of the population. In this article, the individual fitness function is based on non-dominated fronts, and the fitness values of individuals in the same front are set to the same, and hence, for all individuals in Fk, their fitness values can be set to k. Thus, minimizing the fitness is the goal of simulation in this article.
Once the non-dominated sorting is completed, the crowding distance for individuals in front Fi can be calculated using the method proposed in Deb et al. 42 and then used to estimate individual density in the population.
4. Genetic operations: once the individuals are sorted based on non-domination and with crowding distance assigned, every individual π i in the population has two attributes, rank ri and crowding distance di. Then, the selection is carried out using a crowded-comparison operator, denoted as ≺. Let π i and π j be two different individuals in the population. Define crowded-comparison operator as πi ≺ π j if ri < rj, or πi ≺ π j if ri = rj and di > dj.
This means that for two individuals with different ranks, we prefer one with the lower rank, and one with the larger crowding distance for two individuals in the same front.
In this work, the tournament selection method is used in genetic operations. Two individuals are randomly chosen from the current population, and the better one is selected by the crowded-comparison operator as a parent individual for crossover. Repeat the process to select another parent individual.
Once the individuals for reproduction have been selected, the crossover and mutation genetic operators are applied to produce the offspring. The crossover operator applies to pairs of individuals, while the mutation operator applies to single individual. The goal of the former is to obtain better individuals by exchanging information in parent individuals. In this article, crossover is only done in the second section of individuals and Generalization of Order Crossover (GOX) is used. In the following, an example is used to describe its procedure. Reconsider the PNS in Example 1 and let π1 and π2 be two parent individuals:
π1 = (Sr1; So1) = (w1, w2, w2, w3, w3; J1, J1, J5, J3, J2, J2, J4, J5, J2, J3, J3, J4, J4, J5, J2, J1, J1, J3).
π2 = (Sr2; So2) = (w2, w1, w2, w3, w3; J2, J4, J2, J1, J5, J2, J2, J1, J3,
π2 is used as the donator of a crossover string. First, the crossover string is randomly chosen from the operation section of π2. Second, all genes in π1 that occur in the crossover string with the same operations are marked and then deleted. Finally, the crossover string is implanted into π1 in the same position as it is in π2.
Suppose that the length of crossover string in π2 is 5, and the first gene of crossover string corresponds to o13 or the third J1 in So2. In other words, the crossover string is σ = (J1, J4, J5, J3, J4), and its corresponding operation sequence is (o13, o42, o52, o32, o43). Next, delete jobs that correspond to operations o13, o42, o52, o32, and o43 from π1 and implant σ into So1. Then, a new individual π3 = (Sr3; So3) = (w1, w2, w2, w3, w3; J1, J1, J5, J3, J2, J2, J4, J2, J3,

Illustration of GOX.
In order to increase the diversity of the population, the mutation operator further operates on a parent individual, generating a new offspring. Since an individual π = (Sr; So) includes route section Sr and operation section So, the mutation operator considers both two sections of an individual. First, another route (if any) can be reset for a job. For instance, in Example 1, type-q1 jobs J1, J2, and J3 have two routes w1 and w2, and thus their routes can be mutated between w1 and w2. While type-q2 jobs J4 and J5 have only one route, and thus their routes cannot be mutated. For the mutation of So, the inversion mutation is adopted. In other words, we can select randomly a mutation string in So and then reverse it. Taking π3 for example, we select a mutation string from the third to the eighth genes, that is,
5. Elitist strategy: in the elitist strategy of the basic NSGAII, elite individuals in offspring and parent populations are effectively retained to the next population, and hence avoid optimal solutions from being lost in the evolutionary process. This evolutionary process may make all individuals in the first few non-dominant fronts of the population as elites, and may cause early convergence or convergence to local optima. For this reason, a new elitist strategy is proposed by improving one in the basic NSGAII in this article.
In our proposed elitist strategy, the offspring population is first combined with its parent population, forming a new combined population. Then, the combined population is sorted based on non-domination. According to the following rules, determine whether an individual is retained to the next generation:
For the individuals with the same objective function value in front Fk, at most one of them can be retained to the next generation. Note that for some objective functions, for example, Cmax and ϖ, in our simulation example, many individuals have the same objective function value. If these individuals with the same objective function value were not eliminated, the whole population would be almost filled with them, leading to premature population.
Let α(π1) and α(π2) be the transition sequences of two individuals π1 and π2 in front Fk, respectively, and ψ(π1, π2) be the number of positions in the transition sequences at which the corresponding transitions are same. The similarity of π1 and π2 is defined as S(π1, π2) = ψ(π1, π2)/Lα, where Lα is the maximum length of α(π1) and α(π2). For example, if α(π1) = t1t2t3t4t5 and α(π2) = t1t5t3t4, then Lα = 5, the transitions in the first, third, and fourth positions are the same, respectively, and hence S(π1, π2) = ψ(π1, π2)/Lα = 3/5. In order to maintain population diversity and prevent the premature convergence, among individuals whose similarity is more than 60%, only one is selected randomly to be reserved for the new generation in our simulation.
According to the above two rules, select individuals from Fk forming elite set Fk*, denoted as Fk* = Ω(Fk). Let Uk and Vk denote the parent and offspring populations in the kth generation, respectively. Then, the elite selection procedure can be given as follows.
Input Uk and Vk;
Output Uk+1; //Uk+1 the population of elites reserved for the (k+1)th generation.
Wk = Uk∪Vk;
F = FNDS(Wk); /*Fast non domination sorting Wk and F = (F1, F2, …, FV). */
Uk +1 = ∅; l = 1;
While (|Uk+1| + | Fl | ≤psize && l≤V) do
{
Fk* = Ω(Fk); //Select individuals from Fl underrules (A) and (B);
Uk+1 = Uk+1∪Fl*; l = l+ 1;
}
while (l≤V)
{
Fk* = Ω(Fk);
Sort (Fl*,≺); /* Sort Fl in ascending order using ≺*/
Select the first (psize− |Uk+1|) individuals in Fl* as reserved individuals, and the set of selected ones is denoted as Fl′; // |Fl*| may has less than (psize− |Uk+1|) individuals.
Uk +1 = Uk+1∪Fl′;
If |Uk+1| = psize, break;
l = l+ 1;
}
Output Uk + 1.
6. Procedure of PGA.
Based on the above discussion, the presented algorithm, Algorithm PGA, can be stated as follows.
Algorithm PGA
Step 1. Initialize population size psize, maximum generation count gmax, crossover rate pc, and mutation rate pm; randomly generate the initial population U0 and set k = 0;
Step 2. Check and amend feasibility of each individual in U0 by Algorithm IFCA;
Step 3. While (k < gmax): Step 3.1. Generate offspring population Vk by applying the genetic operators (selection, crossover, and/or mutation) to Uk; Step 3.2. Check and amend feasibility of each individual in Vk by Algorithm IFCA; Step 3.3. Let Wk = Uk ∪ Vk; for each individual in Wk, calculate its objective function values; Step 3.4. Fast-Non-Dominated-Sort(Wk), obtaining non-dominated fronts F1, F2, …, FL, compute crowding distances of individuals in each non-dominated front; Step 3.5. Obtain Uk + 1 from Wk (or F1, F2, …, FL) using the designed elitist strategy; k = k + 1; Step 3.6. If (k > gmax/2), for each individual, a local search operation (only including multiple genetic operations) is performed on the probability of 0.3, and replace the old with a new and better individual;
Step 4. Output computational results (e.g. Uk + 1 and F1).
According to this procedure, the genetic operators are based on non-domination sort of the population and the crowding distances of individuals. By applying these operators, new individuals are generated, and then their feasibility is checked, and infeasible ones are repaired to feasible ones. As a result, each individual can be decoded directly into a feasible schedule. In addition, parent and offspring populations are combined, and then generate a new population by the elitist strategy designed, and the population performance is improved in the process of evolution.
Simulation results and comparisons
This section evaluates the performance of the proposed algorithm, PGA, through simulation examples under the following common criteria, and comparison with the MNSGAII.
Evaluation metrics
Pareto-based multi-objective optimization algorithms are devoted to finding a set of non-dominated solutions. Hence, the performance metrics are different from single-objective optimization. In general, the quality of non-dominant solution sets is mostly measured by the following well-known indicators used in Behnamian et al. 38 and Karimi et al.: 39
The number of Pareto solutions with different objective function values, Nα: note that many individuals may have the same objective values, and here, only one is counted. Usually, more Pareto solutions provide more candidates for decision makers and therefore have better performance.
MID (mean ideal distance): the closeness between the Pareto solutions and ideal point (often referred to original point for the minimization of non-negative functions). Then, MID can be defined as MID = Σ1 ≤ k ≤ Nα Dk/Nα, where Dk = sqrt(Σ1 ≤ j ≤ L fkj2) and L is the number of optimization objectives, and fkj is the jth objective function value of the kth non-dominated solution. The lower the MID, the better solution quality.
SNS (spread of non-dominated solutions): as a diversity measure, SNS can be expressed as SNS = sqrt(Σ1 ≤ k ≤ L (MID – Dk)2/(Nα – 1)). If Nα = 1, SNS is undefined. This metric allows us to measure the uniformity of the spread of the solutions in the non-dominated solution set. The larger the SNS, the better solution quality, that is, more diversity in obtained solutions.
RAS (rate of achievement to several objectives): it is represented by RAS = (Σ k Σ l (fkl − Fk)& Fk)&Nα, where Fk = min{fkl, l = 1, 2, …, Nβ}. The solution with a lower value of RAS has better quality.
Experimental setup
To test the performances of the proposed PGA for multi-objective deadlock-free scheduling of AMSs, we use a set of simulation examples constructed from a well-known AMS, but with different numbers of jobs to be processed. The optimization objectives are Cmax, Δ, and ϖ. Parameters are set as population size psize = 100, maximum number of generations gmax = 1000, mutation rate pm = 0.4, and crossover rate pc = 0.6. Referring to the estimation of due date for flexible job-shop in Behnamian et al. 38 and Karimi et al., 39 the due date of job Ji used in this simulation is defined as di = (1 + γ × n/m) × Σ j di, j , where γ is a parameter that has been fixed as γ = 0.3, n is the total number of jobs, m is the number of machines, and di, j is the processing time of the jth operation for job i. Referring to this valuation of the due date of job Ji, for our AMS scheduling problem, n and di,j have the same meaning, while m is changed to the number of resource types, and γ = 0.3Cap if the capacity of all resources is Cap. Note that if Cap = 2, two jobs can be processed simultaneously on the same type of resources.
Based on the criteria introduced in the last section, we evaluate the performances of PGA and compare PGA with NSGAII through the set of simulation examples. Note that the basic NSGAII does not contain any deadlock prevention strategy, it is impossible to obtain a feasible solution directly by using it. In this article, the basic NSGAII is first modified by introducing proper deadlock policies, called as the MNSGAII, so that it can output feasible solutions. Also, the rule (A) for eliminating the same individuals is adopted in MNSGAII.
The PN model of AMS used in simulation is shown in Figure 3. This AMS includes four machines m1–m4, and three robots r1–r3. The system can process three types of jobs, q1–q3. Type-q1 and type-q3 jobs have one processing route, and type-q2 has two processing routes. In this AMS example, we consider 16 instances that contain different resource capacities and job lot sizes, denoted as In01–In16, respectively. The processing time of each operation for a given job is listed in Table 1.

PNS of an AMS.
Processing times for AMS shown in Figure 3.

AMS: automated manufacturing system.
Let χ i denote the number of type-qi jobs to be processed. We use (χ1, χ2, χ3) to represent a batch with χ i type-qi (i ∈ ℤ3) jobs. Four batches, (8, 12, 8), (10, 20, 10), (15, 20, 15), and (20, 20, 20), are considered and In01–In04 are with batch (8, 12, 8), In05–In08 with (10, 20, 10), In09–In012 with (15, 20, 15), and In13–In16 with (20, 20, 20), respectively.
Sixteen instances are divided into four groups to run under different resource capacities. The instances included in each group and the resource capacity utilized by each group are as follows, and the algorithms PGA and MNSGAII are run 10 times independently for each instance:
In01, In05, In09, In13: C(mi) = 2, i ∈ ℤ4, C(r1) = 1, C(r2) = 2, and C(r3) = 1.
In02, In06, In10, In14: C(mi) = 2, i ∈ ℤ4 and C(rj) = 2, j ∈ ℤ3.
In03, In07, In11, In15: C(mi) = 3, i ∈ ℤ4 and C(rj) = 2, j ∈ ℤ3.
In04, In08, In12, In16: C(mi) = 3, i ∈ ℤ4 and C(rj) = 3, j ∈ ℤ3.
Results and comparisons
1. Two-objective optimization: we test the performance of PGA and MNSGAII for scheduling AMS with two objectives, that is, Cmax and Δ.
The Pareto-optimal fronts from a run of PGA and MNSGAII on each instance and CPU time, TCPU, are listed in Table 2. As shown in Table 2, two algorithms, PGA and MNSGAII, both can successfully solve the AMS scheduling problem with two objectives. The non-dominated solution set of PGA on each instance is obviously better than that of MNSGAII and all Pareto solutions obtained by MNSGAII are dominated by any solution obtained by PGA, but PGA takes longer time than MNSGAII. This is mainly due to the addition of local search and new elite selection strategy in PGA, which takes up a certain amount of time and improves the performance of the algorithm. In addition, with the increase in the resource capacity, the objective function values Cmax and Δ are both decreasing. For example, the capacities of resources processing batch (8, 12, 8) increase gradually in In01, In02, In03, and In04, and correspondingly, no matter which objective function value, Cmax or Δ, decreases. Similar conclusions are valid for the increasing capacities of resources processing batches (10, 20, 10) in In05–In08, (15, 20, 15) in In09–In12, and (20, 20, 20) in In13–In16.
Pareto fronts obtained by PGA and MNSGAII on In01–In16 and CPU time.
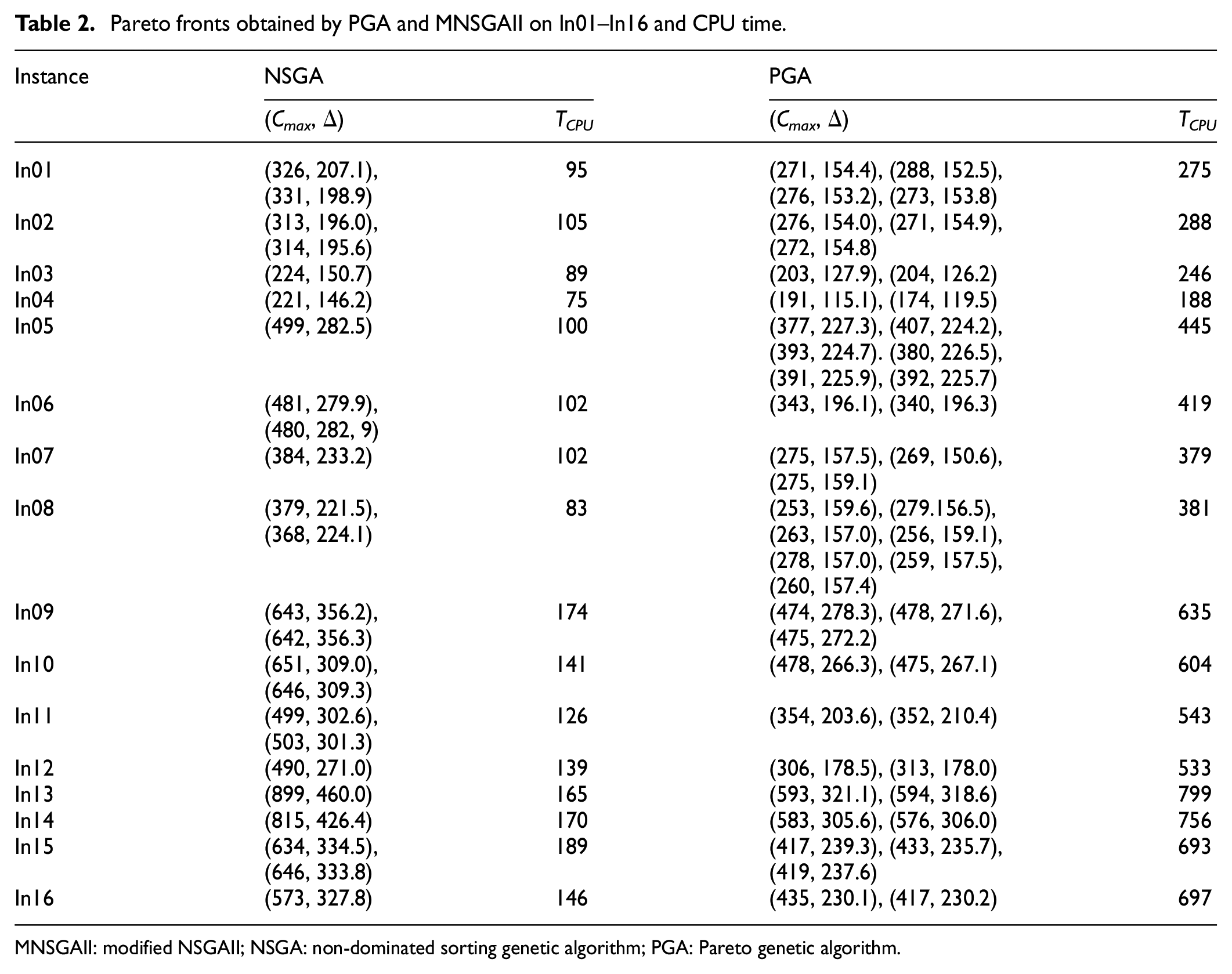
MNSGAII: modified NSGAII; NSGA: non-dominated sorting genetic algorithm; PGA: Pareto genetic algorithm.
Table 3 shows the average value of each index of two algorithms under 10 independent runs of 16 instances. From the table, we can observe that there exist some differences between PGA and MNSGAII on the statistical performance metrics. First, the average number of different non-dominated solutions under MNSGAII is relatively low, for most or many runs, only one Pareto solution is obtained. PGA can obtain more non-dominated solutions than MNSGAII for each instance. This is because MNSGAII does not eliminate individuals with high similarity according to rule (B), although individuals with the same objective values have been eliminated according to rule (A). Note that in the simulation, we found that if the rules (A) and (B) are not used, most individuals in the population would be the same after 200 generations. That is, the population matures very prematurely.
Metric comparison with two objectives.

MID: mean ideal distance; SNS: spread of non-dominated solutions; NSGA: non-dominated sorting genetic algorithm; PGA: Pareto genetic algorithm.
N α = 1 and SNS is undefined.
The indicators MID and SNS of PGA are also better than those of MNSGAII. This is mainly because the new elitist strategy of PGA is superior to that of MNSGAII and the local search is performed. Hence, it is concluded that PGA is more efficient than MNSGAII for solving our bi-objective scheduling problems.
2. Three-objective optimization: for AMS scheduling problem with three objectives, that is, Cmax, Δ, and ϖ, Table 4 lists the Pareto-optimal fronts obtained from a run of PGA and MNSGAII on each instance, and CPU time, and Table 5 shows the average solution number and the average value of MID under 10 independent runs. We can draw similar conclusions as those for AMS scheduling problems with two objectives. From Table 4, we can know that for most simulation instances, PGA can obtain more non-dominated solutions. The only exception is in In14. For this instance, PGA obtains only three solutions, while MNSGAII gets five solutions. But note that each solution obtained by PGA dominates all solutions of MNSGAII. In Table 5, the average value of MID of PGA is less that of MNSGAII. That means that, on average, the solutions obtained by PGA is closer to the optimal solution than that obtained by MNSGAII. For In02, In04, and In07, although MNSGAII obtains more Pareto solutions, the corresponding MID values are much larger than that of PGA, and hence, it can be inferred that PGA has better performance. To sum up, PGA is more effective than MNSGAII for three-objective scheduling problem of deadlock-prone AMSs.
Pareto fronts of three-objective scheduling problem on In01–In16 and CPU time.

NSGA: non-dominated sorting genetic algorithm; PGA: Pareto genetic algorithm.
Metric comparison with three objectives.

MID: mean ideal distance; SNS: spread of non-dominated solutions; NSGA: non-dominated sorting genetic algorithm; PGA: Pareto genetic algorithm.
N α = 1, and SNS is undefined.
Conclusion
This article proposes a PGA for solving the multi-objective scheduling problem of deadlock-prone AMSs with limited resource capacity. A candidate schedule, that is, a sequence of transitions in PN model of AMS, is represented as an individual consisting of route selection and operation sequence. To handle the fitness assignment and solution update in the sense of multi-objective optimization, Pareto dominance and crowding distance in NSGAII are adopted. By introducing new elitist strategy and local search, premature convergence of the population is improved. The feasibility of individuals can be checked based on the PN model of AMS and its deadlock controller, and infeasible individuals can be repaired to feasible ones. Consequently, deadlock is prevented from occurring under the constraint of limited resource capacity, and a deadlock-free schedule is obtained by decoding a feasible individual. Simulation results and comparisons with the MNSGAII in terms of well-known performance metrics show the effectiveness and efficiency of the proposed PGA. The future work is to improve the performance of PGA by considering local search methods and to apply the proposed PGA to solve other AMS scheduling problems with setup and/or uncertain processing time.
Footnotes
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by the National Natural Science Foundation of China under grants 61573269, 61873277, and 71571190 and the Key Research and Development Program of Shaanxi Province under grant 2019GY-056.