
Abstract
Genetic algorithm is one of primary algorithms extensively used to address the multi-objective flexible job-shop scheduling problem. However, genetic algorithm converges at a relatively slow speed. By hybridizing genetic algorithm with particle swarm optimization, this article proposes a teaching-and-learning-based hybrid genetic-particle swarm optimization algorithm to address multi-objective flexible job-shop scheduling problem. The proposed algorithm comprises three modules: genetic algorithm, bi-memory learning, and particle swarm optimization. A learning mechanism is incorporated into genetic algorithm, and therefore, during the process of evolution, the offspring in genetic algorithm can learn the characteristics of elite chromosomes from the bi-memory learning. For solving multi-objective flexible job-shop scheduling problem, this study proposes a discrete particle swarm optimization algorithm. The population is partitioned into two subpopulations for genetic algorithm module and particle swarm optimization module. These two algorithms simultaneously search for solutions in their own subpopulations and exchange the information between these two subpopulations, such that both algorithms can complement each other with advantages. The proposed algorithm is evaluated on some instances, and experimental results demonstrate that the proposed algorithm is an effective method for multi-objective flexible job-shop scheduling problem.
Keywords
Introduction
Flexible job-shop scheduling problem (FJSP) is an extension and generalization of the classical job-shop scheduling problem (JSP).1–3 Generally, in a classical job-shop model, all jobs follow fixed routes, but not necessarily the same for each job, and every operation of all jobs is required to be processed on one predetermined machine.4,5 JSP determines a sequence of operations on each machine to optimize one or multiple objectives. By contrast, if there exist two or more machines that can be allowed to process one operation, the model is called flexible job shop. The FJSP is required not only to determine the sequencing of operations on machines, but also to assign each operation to a machine.1,2,6 It is well known that the JSP is non-deterministic polynomial (NP)-hard. 7 As a generalization of the JSP, the FJSP is equally known to be NP-hard and is challenging due to the expanding machine flexibility.1–3,8–11
The FJSP has important applications in many real industries such as semiconductor manufacturing, automobile assembly, and textile, where a group of machines is capable for each operation. Therefore, from both the theoretical and the practical viewpoint, FJSP is one of the most common scheduling models existing in modern industry environment. In addition, it is often necessary to optimize several conflict objectives simultaneously in the real world, and therefore, the multi-objective flexible job-shop scheduling problem (MOFJSP) has become a hot and important research topic.
Generally, the approaches applied to solve MOFJSP can be roughly divided into two categories, that is, priori method and posteriori method.1,12 In the priori method, a MOFJSP is usually converted into a single-objective FJSP by combining multiple objectives into a single-objective function. According to the existing literature, the priori method got more concerns by researchers on earlier studies. For example, Brandimarte 13 presented a hybrid tabu search (TS) with dispatching rules to solve MOFJSP. Specially, TS was used to solve the sub-problem of optimizing the operations sequencing and dispatching rules were applied to solve the sub-problem of operations assignment to machines. Kacem et al. 14 embedded the local optimization algorithm within an evolution algorithm. Xia and Wu 15 proposed a hybrid method to solve MOFJSP. They used particle swarm optimization (PSO) to assign operations and used simulated annealing (SA) algorithm to sequence operations on each machine. Gao et al. 16 developed an adapted genetic algorithm (GA) hybridized with a shifting bottleneck strategy for MOFJSP. The posterior method has recently attracted many researchers to investigate multi-objective problems. For example, Kacem et al. 17 presented a Pareto method based on the hybridization of fuzzy logic and evolutionary algorithms for MOFJSP. Li et al. 18 developed a Pareto-based discrete artificial bee colony algorithm for MOFJSP. Ho et al.10,19 proposed a hybrid evolutionary algorithm with local search and meanwhile introduced an elitism memory to store all non-dominated solutions that have been found. Yuan and Xu 1 elaborated a new memetic algorithms (MAs) by incorporating a local search algorithm into the adapted Non-dominated Sorting Genetic Algorithm II (NSGA) for MOFJSP. Wang et al. 20 developed a GA based on the immune and entropy principle to address MOFJSP. Wang et al. 21 proposed an enhanced Pareto-based artificial bee colony algorithm for MOFJSP.
In general, there are two limitations about the priori methods mentioned above. One is that the priori methods require priori information, such as weighting factors of each objective, which are usually subjective. Another is that multiple runs are needed to get a set of satisfactory solutions. Unlike the priori method, the posterior method requires no priori information and therefore has more extensive applicability. Most of the posterior methods mentioned above have obtained better solutions by combining the explorative search of one algorithm and the exploitative search of another algorithm together. It is noticeable that these methods are Pareto-based and they can obtain a set of non-dominated solutions in a single run. Considering that GA and PSO are different in terms of optimization mechanism, information sharing scheme, and capabilities in explorative search and the exploitative search, and meanwhile, GA and PSO have achieved promising results by combining another algorithm,10,15,19 it is meaningful to investigate the hybridization of GA and PSO to solve MOFJSP. In this context, considering the advantages and limitations of GA and PSO, this study aims to develop a novel hybrid GA with PSO to address MOFJSP, which hybridizes both algorithms to complement each other. External memory library stored with elite individuals is incorporated to improve the GA’s memory and learning capability for the elite individuals. Besides, based on the merits of the posteriori method, we adopt it to address MOFJSP in this study.
The contributions of this article are reflected in algorithm design. The novelties are stated as follows. First, because GA and PSO have their own advantages and disadvantages for MOFJSP, but they are also complementary. In this study, we combine GA with PSO to complement each other for solving MOFJSP; simultaneously, external memory library stored with elite individuals is also incorporated to improve the learning capability for GA. Second, to improve the crossover operation performance, GA is adapted by introducing a third parent to provide offspring, which has more opportunities to inherit good genes from parents. Third, the procedure of GA is redesigned by combining crossover and mutation operations to diversify population and retain good genes in population. In addition, a method is proposed to generate the initial population by considering the characteristics of MOFJSP. To our knowledge, this is the first time that the related algorithms and strategies have been used for MOFJSP.
The remainder of this article is organized as follows. We present the notations as well as the details of the mathematical formulation of MOFJSP in section “Problem statement and mathematical formulation.” The framework of the proposed approach is described in section “Teaching–learning-based hybrid genetic-particle swarm optimization algorithm for MOFJSP.” Section “Computational results” deals with a comparative study of the computational results. Finally, the last section discusses the conclusion and some directions for future research.
Problem statement and mathematical formulation
In FJSP environment, there are a set of independent jobs
Jobs are independent of each other and are all available at the begin;
Jobs have equal priorities to begin processing;
Preemption is not allowed;
For each operation, there is a set of machines capable of performing it;
An operation is not allowed to process until its preceding operation is completed;
Each machine can perform at most one operation at any time.
This study aims to solve MOFJSP under all basic assumptions mentioned above. Terminologies and notations in this study are set up as below.
Sets and indices
m Total number of machines on the shop floor
M Set of machines
Mi ith machine (i = 1,…, m)
n Total number of jobs
J Set of jobs
Jj jth job (j = 1,…, n)
hj Number of operations associated with the job Jj (j = 1,…, n)
Ojh hth operation associated with the job Jj (j = 1,…, n, and h = 1,…, hj)
Ω jh Subset of machines required for the operation Ojh
mjh Number of machines required for the operation Ojh
Parameters
Pijh Processing time of the operation Ojh by the machine Mi
Sjh Starting time of the operation Ojh (release time)
Cjh Completion time of the operation Ojh
dj Due date of the job Jj
Cj Completion time of the job Jj
Cmax Maximum completion time over all jobs(makespan)
H Large positive integer
T0 Total number of all operations
Decision variables
Objective functions
The minimization of makespan (Cmax), bottleneck machine workload (Wm), and total workload of machines (Wt) are the main objectives adopted by academic and industrial practice.8,10,15,18 For the purpose of comparison with other methods, we also take them as criteria in this study. The expressions of objective functions are given by


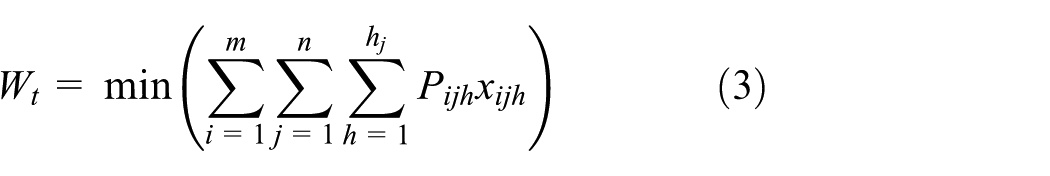
Constraints
The constraints of the mathematical model are defined as follows



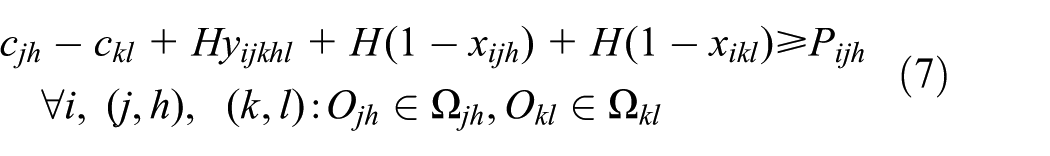


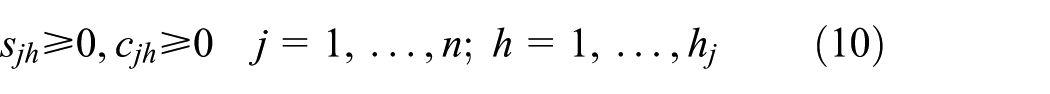
Constraints (4) denote that the difference between completion time and starting time of operation Ojh on machine Mi equals to its processing time on machine Mi. It means that the operation must be completed without interruption once started, which guarantees assumption (3). Constraints (5) correspond to assumption (4), presenting the fact that an operation must be assigned to only one machine among the subset of alternative machines at a time. To guarantee assumption (5), constraints (6) and (7) handle respecting predefined sequence of operations associated with each job. Constraints (8) ensure assumption (6), that is, each machine can only perform at most one operation at a time. Constraints (9) describe that the completion time of each operation cannot be later than Cmax. Constraints (10) define the domains of the decision variables.
Teaching–learning-based hybrid genetic-particle swarm optimization algorithm for MOFJSP
The structure of teaching–learning-based hybrid genetic-particle swarm optimization
GA is one of the algorithms used extensively to address MOFJSP. However, due to the problem of the slow convergence of GA, it cannot be directly applied to solve such a large-scale problem of MOFJSP. How to speed up the GA convergence while keeping its global search capability is a challenge. Many recent literatures adapted GA or/and incorporated other algorithms to speed up convergence.
GA and PSO are different from each other with respect to both the optimization mechanism and the information sharing scheme. In GA, the information is shared among chromosomes. Via the exploitation of the information shared among chromosomes and the operations of selection, crossover, and mutation on chromosomes, GA produces new generations of solutions. It means that GA can finely search solutions within the whole search space. However, GA lacks the adequate memory and learning capability for the elite individuals during the process of evolution, resulting in a relatively slow converging process. In addition, the performance of GA is easily affected by parameters and falls into a local optimum. In contrast with GA, PSO has memory and learning capability, and its information sharing scheme is one-way. In PSO, a particle obtains the information of the best particle in swarm and the best position in history of its own and updates its velocity and position only based on this information. As a result, PSO converges to satisfactory solutions at a high speed, but it also reduces the search accuracy. Therefore, PSO is suitable for coarse-grained searching in large-scale solution space. Overall, in solving MOFJSP, GA has strong global search capability but slow convergence while PSO has fast convergence but low accuracy convergence.
This study considers the combination of GA and PSO to address MOFJSP and proposes a novel approach, called teaching–learning-based hybrid genetic-particle swarm optimization (TL-HGAPSO). TL-HGAPSO consists of three modules, that is, GA module, bi-memory learning (BL) module, and PSO module. Figure 1 shows the structure of TL-HGAPSO and the relationship among the modules. GA is taken as the framework of TL-HGAPSO while PSO and an external memory library are incorporated in TL-HGAPSO. The purpose of introducing PSO is to improve the convergence speed of GA using the fast search capability of PSO, and on the other hand, to avoid GA falling into local optimum to some extent. In the meantime, the strong global search capability of GA is used to enhance the search accuracy of PSO in TL-HGAPSO. Through exchanging mutual information, GA module and PSO module improve the quality of their populations. In addition, since GA lacks the capability to learn from the elite individuals, in BL module, we implement an elitism strategy that stores elitist solutions in an external library and reintroduces them to GA population to improve learning capability of TL-HGAPSO. During the process of evolution, the individuals in GA module continuously learn from elitism individuals in BL module, and vice versa, inferior individuals in BL module are replaced with the elitism individuals in GA module simultaneously. In short, the purpose of TL-HGAPSO is to maintain the diversity within the population and to accelerate the process of convergence to optimal solutions.

The structure of TL-HGAPSO.
GA module
We take the GA as the main framework of TL-HGAPSO. In GA module, to improve the performance of GA for MOFJSP, we modify the genetic operators and introduce an individual self-learning mode based on the adaptive crossover and mutation. The major elements of GA module are described as follows.
Coding and decoding
In the MOFJSP environment, operations should be assigned to machines before sequencing the operations on each machine. Therefore, the MOFJSP can be divided into two sub-problems: operations assignment and operations sorting.3,6,11,20,22,23 Specially, the former aims to allocate the machine for each operation, and the latter to sequence the operations on each machine. Accordingly, the coding scheme in TL-HGAPSO consists of two sections: machine allocation (i.e. assign operations to machines) and operations sorting. Tay and Wibowo 24 described four chromosome representations commonly used for coding GA-based solutions to the FJSP. Specially, the third chromosome representation, which is called “Simple Operation Order” by Tay et al., has been used in many research studies.12,20,25 This article also uses this chromosome representation for coding solutions. The coding scheme used in this article is described as follows.
The length of two chromosomes are both equal to T0. In the coding scheme of operation sorting, each gene represents an operation, and its value denotes the sequence of the job associated with this operation. The value of occurrence of job’s sequence indicates the operation of the job. For example, in Figure 2, “1 2 1 3 2 1 3 2 3” is the operation sorting code. The first occurrence of “3” denotes the first operation of J3, that is, O31, the second occurrence of “3” denotes O32, and so on. Therefore, in this case, the sequence of the operation is O11, O21, O12, O31, O22, O13, O32, O23, O33. In the coding scheme of machine allocation, gene’s position and value indicate a specific operation and the sequence of the machine on which the operation will be performed. For example, in Figure 2, the machine allocation code “1 3 5 3 2 3 1 4 3” indicates that assign O11, O12, O13, O21, O22, O23, O31, O32, and O33 to machine M1, M3, M5, M3, M2, M3, M1, M4, and M3, respectively. This coding scheme ensures that offspring generated from the crossover or mutation operation remain feasible and suitable for both P-FJSP and T-FJSP.
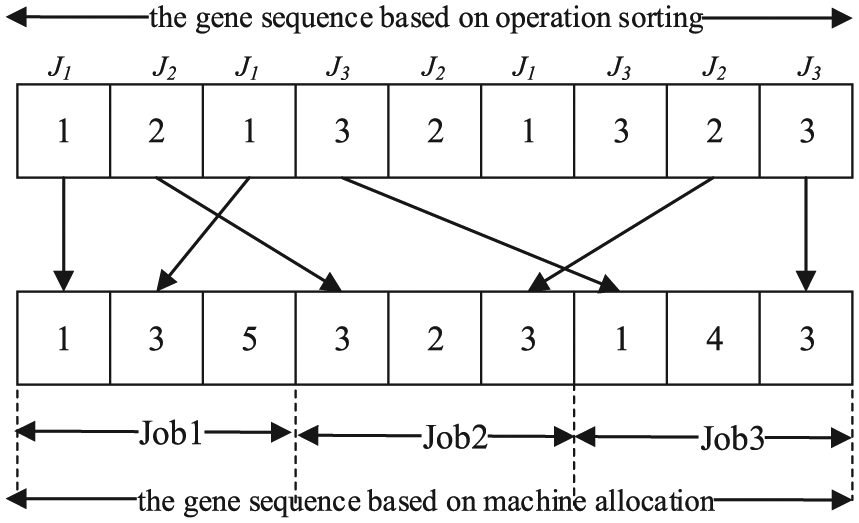
Coding scheme in TL-HGAPSO.
Population initialization
Initial population is important for the exploration and exploitation of GA. Initializing the population randomly is a simple method and it is extensively used for FJSP. This method is suitable and reasonable for the problem without prior knowledge. However, it may generate many inferior chromosomes. Therefore, to make better convergence toward optimal solution, large number of iterations is usually used which takes more computational time. In the proposed TL-HGAPSO algorithm, a part of initial population is generated randomly while the other part of initial population is created based on the characteristics of MOFJSP to improve the quality of the initial population. Regarding MOFJSP in this study, it can be intuitively concluded that the closer the waiting time of the operations is, the more opportunities to obtain low workload and short makespan. Therefore, to produce the rest of population, we design a dispatch rule, called minimizing waiting time, which aims to equalize the waiting times of the operations (i.e. to minimizing the variance of the waiting time). The details are shown as follows:
Step 1: Create an array used to store jobs in random order (e.g. J2J3J1).
Step 2: Assign the first operation (O21, O31, O11) of each job in array (J2J3J1) to machines (details of assignment see step 4). If the machine is idle, set the starting time of Oxl to zero. Otherwise, Oxl will be processed immediately once its precedent operation is completed.
Step 3: Select the machine Ms that will complete operation first, and the last operation Ojh on Ms. If more than one machine satisfies condition, one machine is randomly selected. Set t to the time when Ms is idle.
Step 4: For the subset of machines required for the operation Oj(h + 1), that is, Ω
j
Step 5: Go to step 3 until all operations have been assigned.
The randomized population helps maintain the diversity of population, while the population based on the characteristics of MOFJSP helps accelerate the process of convergence to optimal solutions. Therefore, the ratio of these two populations reflects the trade-off between population diversity and speed of convergence. In this study, when the ratio of these two populations is 1:1, better results can be achieved.
Crossover operation
The multi-parents precedence preserving order-based crossover (MPOX) is used to sequence operations. To improve crossover operation performance, we adapt GA algorithm by introducing a third parent to provide offspring more opportunities to inherit the good genes from parents. According to the fitness value of individuals, current population is partitioned into three sets, that is, Parent1, Parent2, and Parent3.
The detailed procedures of MPOX are given as follows:
Step 1: Put the individuals with fitness
Step 2: Partition the job set J
Step 3: Replicate the genes both belong to Parent1 and G2 into Children1, and the genes both belong to Parent2 and G1 into Children2; meanwhile, keep the position and sequence of genes unchanged.
Step 4: Replicate the genes both belong to Partent3 and G1 into Children1, and the genes both belongs to Parent3 and G2 into Children2; meanwhile, keep the sequence of genes unchanged.
An example of MPOX is shown in Figure 3.

MPOX crossover operation.
The multiple point preservation crossover (MPX) is leveraged to assign operations to machines. The detailed procedures of MPX are as follows:
Step 1: Create an array of size T0, named rand0_1, and initialize it with random binary numbers.
Step 2: From Parent1, replicate all genes with the same position as “1” in rand0_1 into Children2 and keep their position unchanged, and, in the same way, from Parent2, replicate the genes into Children1.
Step 3: Replicate the rest genes of Parent1 and Parent2 into Children1 and Children2, respectively.
An example of MPX is shown in Figure 4.

MPX crossover operation.
Mutation operation
Mutation operation aims to maintain the diversity of the population. GA conducts the crossover operation and mutation operation in sequence. In this paper, the procedure of mutation operation is incorporated with crossover operation to increase its efficiency.
It will help diversify population when an individual with a higher degree of similarity to other individuals has more opportunities to conduct mutation operation. Therefore, in our TL-HGAPSO, if an individual has a high similarity value, mutation will be conducted before crossover; otherwise, mutation operation will be skipped. A similarity threshold is used to decide whether an individual needs to mutate or not. The procedures are as follows:
Step 1: Partition the population into three subsets: Parent1, Parent2, and Parent3 (refer to procedures of MPOX).
Step 2: Calculate Hamming similarity and threshold according to formulas (11) and (12) 26


where Hij is the Hamming distance between individual i and individual j, Chmi(k) and Chmj(k) represent the kth gene on chromosome i and chromosome j, respectively; h13 and h23 denote Hamming similarity of Parent3 with Parent1 and Parent2, respectively; s13 and s23 denote the corresponding similarity threshold. If h13 > s13 and h23 > s23, conduct crossover operation; otherwise, conduct mutation and crossover in sequence.
Step 3: Keep Parent3 into the offspring generation.
Meanwhile, the variation in the best fitness value of successive generations is used to measure the degree of population evolution. If the best fitness value has not been improved after several generations, it indicates that the population is evolving too slowly and needs to increase the mutation probability. In TL-HGAPSO, a convergence threshold is set to control the mutation probability. The procedures are as follows:
Step 1: Suppose the fitness value of the best individual in the initial population is f1, the next generation is f2, and so on; the nth generation’s best fitness is fn;
Step 2: When f1 = f2, set convergence threshold Φ = 1; When f1 = f2 = f3, set Φ = 2; When f1 = f2 = f3 = …= fn, set Φ = n –1; otherwise set Φ = 0;
Step 3: Update the mutation probability according to the convergence threshold
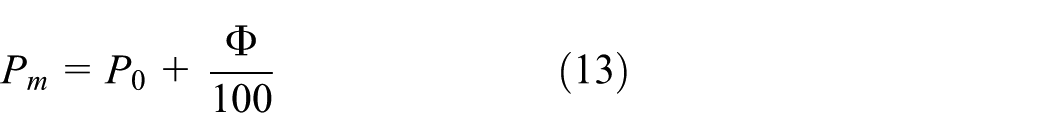
where P0 denotes the initial mutation probability.
In addition, in TL-HGAPSO, we leverage the Pareto-based fitness assignment based on the fast and elitist non-dominated sorting in NSGA-II algorithm to calculate fitness assignment 27 and use the tournament selection as the selection operator.
BL module
The schemata theory implies that giving high priority of replication to the individuals with good genes is conducive to producing better offspring. 19 Therefore, in BL module, two external memory libraries, that is, chromosome library and operation library, stored with good genes are introduced to direct the search into the promising areas.
The chromosome library stores the individuals with good genes to improve the offspring’s capability in learning good characteristics from parents. Thek-nearest neighbor (K-NN) classification algorithm is used to dynamically learn the elite schema in the chromosome library. More specifically, by comparing the best n individuals in the current population to the chromosome library, the most similar k individuals in the chromosome library are selected to replace the worst k individuals in current population.
Operation library is specially designed for MOFJSP. It is an integer array of size d, where d represents total number of operations, and each element is used to record the machine with shortest processing time for the corresponding operation. Note that if there exist two or more machines that have identical least processing time for an operation, one machine is selected by random. An example is presented here to illustrate operation library explicitly. Suppose that Table 1 gives processing time of the operations of a 3*5 FJSP. Figure 5 shows its operation library. As shown in Table 1, the processing time of O11 on M1, M2, M3, and M4 is 2, 3, 4, and 3, respectively, and the least one is 2, which takes place on M1. The sequence number of M1 is “1,” that is, the first left element in operation library in Figure 5, which means that assigning O11 to M1 might provide more opportunities to obtain the optimum or an approximate optimum.
Processing time of 3*5 FJSP.

FJSP: flexible job-shop scheduling problem.

An instance of operation library.
In addition, considering computation resources, we do not update the external library at each generation, but at every several generations using an elite selection strategy.
PSO module
The PSO has been introduced as an optimization technique in real-number spaces. 15 However, MOFJSP under studied in this article is set in a discrete space. For taking advantages of PSO to solve MOFJSP, it is necessary to adapt the original PSO. Thus, we re-define the position updating equation of PSO for MOFJSP as formula (14)
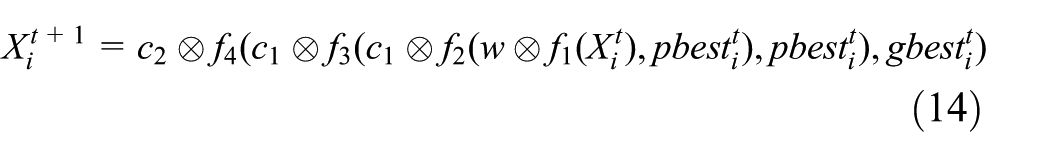
where Xti denotes particle position at the tth generation, w represents inertia weight, c1 and c2 are respectively self-awareness coefficient and society-awareness coefficient, pbestti and gbestti respectively indicate the best position of particle i at the tth generation and the best position of the particle in swarm at the tth generation. Note that

where


where
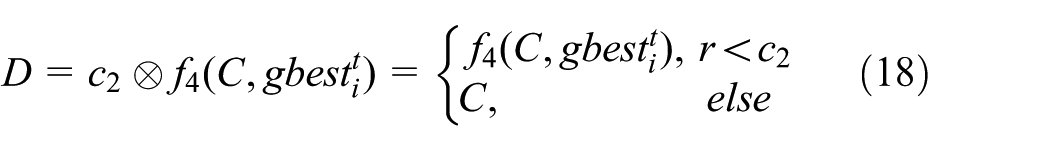
where

An instance of the operation of
To summarize, in TL-HGAPSO, we adapt the particle position updating formula for MOFJSP. Crossover operation is used to exchange information between particles and historical experiences of their own as well as of the swarm. Mutation operation, a random search strategy of particles in this article, is used to improve the local search capability of particles. Here, self-awareness coefficient
TL-HGAPSO algorithm procedures
The flowchart illustrated in Figure 7 shows the main procedures of TL-HGAPSO, and main procedures are described as follows:
Step 1: Set parameters and initialize population Rt(t = 0) (referring to section “Population initialization”).
Step 2: Decode individuals of population Rt and calculate their fitness values; sort individuals according to NSGA-II; get Pareto solution set Pt + 1.
Step 3: If termination criterion is satisfied, that is, t = Gen, stop algorithm and output the results.
Step 4: If t < Gen, hybridize GA with PSO to generate the next generation Rt + 1. The detailed steps are as follows.
Step 4.1: Partition Pareto solution set Pt + 1 into GA subpopulation and PSO subpopulation.
Step 4.2: Search in GA subpopulation.
Step 4.2.1: If t = 0, use population Pt + 1 to initialize two external libraries in BL module.
Step 4.2.2: Conduct best individual selection and tournament selection operations.
Step 4.2.3: Update current GA subpopulation according to chromosome library (referring to section “BL module”)
Step 4.2.4: Partition GA subpopulation into three subpopulations: Parent1, Parent2, and Parent3 (referring to section “Crossover operation”); calculate Hamming distance and similarity threshold according to formulas (11) and (12), respectively.
Step 4.2.5: Calculate mutation according to formula (13) and conduct mutation operation (referring to section “Mutation operation”).
Step 4.2.6: Conduct MPOX and MPX crossover operation.
Step 4.2.7: Calculate fitness value of individuals; update the external libraries every q generations.
Step 4.3: Search in PSO subpopulation.
Step 4.3.1: Update the position of the particle according to formulas (14)–(18).
Step 4.3.2: Calculate the fitness value of the particle.
Step 4.3.3: Update pbest and gbest (referring to section “PSO module”).
Step 4.4: By exchanging information between GA subpopulation and PSO subpopulation, use the best individual in GA subpopulation to replace the worst individuals in PSO subpopulation, and vice versa; merge GA subpopulation and PSO subpopulation to get population Qt + 1.
Step 4.5: Merge Pt+1 and Qt+1 to get population Rt+1.
Step 5: Set t = t + 1, go to Step 2.

Flow chart of TL-HGAPSO algorithm.
Computational results
TL-HGAPSO is programmed by MATLAB and running on a PC with 3.3G CPU and 8G RAM. We select three representative instances proposed by Kacem et al.14,17 and 10 datasets designed by Brandimarte. 13 Each instance runs 20 times. Because Kacem et al.,14,17 Xia and Wu, 15 and Xing et al. 28 provided relatively complete experiment results on the above representative instances in their studies, to illustrate the efficiency of our algorithm, we compare our results with theirs. Their algorithms are called Approach by Localization (AL), classic GA (CGA), PSO + SA and Search Method (SM) for short in this study, respectively.
The parameters are as follows: set the population size = 200, the maximum generation Gen = 200, the crossover rate
Kacem’s instances
Table 2 shows the comparison of experiment results on Kacem’s instances.
Comparison of experiment results on Kacem’s instances.

FJSP: flexible job-shop scheduling problem; PSO: particle swarm optimization; SA: simulated annealing; TL-HGAPSO: teaching–learning-based hybrid genetic-particle swarm optimization; AL: Approach by Localization; CGA: classic GA; SM: Search Method.
Problem 8*8
In 8*8P-FJSP, there are eight jobs with 27 operations performed on eight machines. The obtained non-dominated solutions by the proposed algorithm are characterized by the following values:
Solution 1: Cmax = 14; WM = 12; WT = 77.
Solution 2: Cmax = 15; WM = 12; WT = 75.
Solution 3: Cmax = 16; WM = 13; WT = 73.
Compared with AL + CGA, the proposed algorithm in this study finds better solutions in terms of Cmax and WT and provides the value of WM. Compared with PSO + SA, in addition to two sets of solutions obtained by PSO + SA, the proposed algorithm also finds another set of non-dominated solutions. Compared with SM, although the proposed algorithm cannot find a set of solutions obtained by SM, it takes shorter computational time than SM. Figure 8 shows the Gantt chart and convergence curve of the makespan (Cmax) of the first set of solutions obtained by the proposed algorithm. As shown in Figure 8, the value of makespan reduces dramatically at about 10th generation and the optimum of Cmax is found, and the solution remains stable during the process of evolution. In other words, the convergence speed of TL-HGAPSO is very fast.

The Gantt chart and the convergence curve of Cmax of 8*8 problem (Cmax = 14, WM = 12, WT = 77).
Problem 10*10
In 10*10T-FJSP, there are 10 jobs with 30 operations performed on 10 machines. The obtained non-dominated solutions by the proposed algorithm are characterized by the following values:
Solution 1: Cmax = 7; WM = 6; WT = 42.
Solution 2: Cmax = 8; WM = 7; WT = 41.
Compared with AL + CGA, the proposed algorithm reduces one objective WT (42 instead of 45), increases one objective WM (6 instead of 5) under the same value of Cmax (7), it also finds another non-dominated solution set. Compared with PSO + SA, the proposed algorithm reduces WT (42 instead of 44) under the same value of Cmax(7) and WM(6) and also obtains another set of non-dominated solutions. Compared with SM, the proposed algorithm cannot find a set of solutions obtained by SM, but it only takes about 1/3 computational time (17.92 instead of 55.18). Figure 9 shows the Gantt chart and convergence curve of the makespan of the first solution set achieved by the proposed algorithm. As shown in Figure 9, the value of makespan reduces dramatically at about fifth generation and the optimum of Cmax is found, and the solution remains stable during the process of evolution. In addition, N Shahsavari-Pour and B Ghasemishabankareh 8 evaluated their algorithm, called novel hybrid genetic algorithm and simulated annealing (NHGASA), on 10*10T-FJSP. Compared with NHGASA method, the proposed algorithm is also slightly faster than NHGASA (17.92 instead of 18.44). It means that the convergence speed of TL-HGAPSO is very fast.

The Gantt chart and the convergence curve of Cmax of 10*10 problem (Cmax = 7, WM = 6, WT = 42).
Problem 15*10
In 15*10T-FJSP, there are 10 jobs with 56 operations performed on 15 machines. The obtained non-dominated solutions by the proposed algorithm are characterized by the following values
Solution 1: Cmax = 12; WM = 11; WT = 91.
It is worth mentioning that there are two different schedules can get this set of solutions. Figure 10 shows these two schedules in the form of Gantt chart. Compared with AL + CGA, the proposed algorithm dramatically reduces Cmax(12 instead of 24) under the same value of WM(11) and WT(91) and finds the same solutions as PSO + SA. Compared with SM method, the proposed algorithm cannot obtain the same solutions as SM, and its Cmax is even worse than that of SM (12 instead of 11), but it only takes about one half of computational time (98.6 instead of 194.98). Figure 11 shows the convergence curve of the makespan (Cmax) of the proposed algorithm. As shown in Figure 11, the value of makespan reduces dramatically at about fifth generation and the optimum of Cmax is found, and the solution remains stable during the process of evolution. It means that the convergence speed of TL-HGAPSO is very fast.

The Gantt chars of two different schedules of the solution (Cmax = 12, WM = 11, WT = 91) on 15*10 problem.

Convergence curve of Cmax of 15*10 problem (Cmax = 12, WM = 11, WT = 91).
Brandimarte dataset
We compare the proposed algorithm with SM on Mk01 to Mk10 instances in Brandimarte dataset. The comparison of experiment results is shown in Table 3. In all the 10 instances except Mk08, the proposed algorithm finds at least one Pareto solution that can dominate the solution obtained by SM. In Mk08 instance, the proposed algorithm finds the same solution as SM, and another three sets of non-dominated solutions. In addition, the computational time of the proposed algorithm is significantly less than that of SM.
Comparison of experiment results on Mk01 to Mk10.
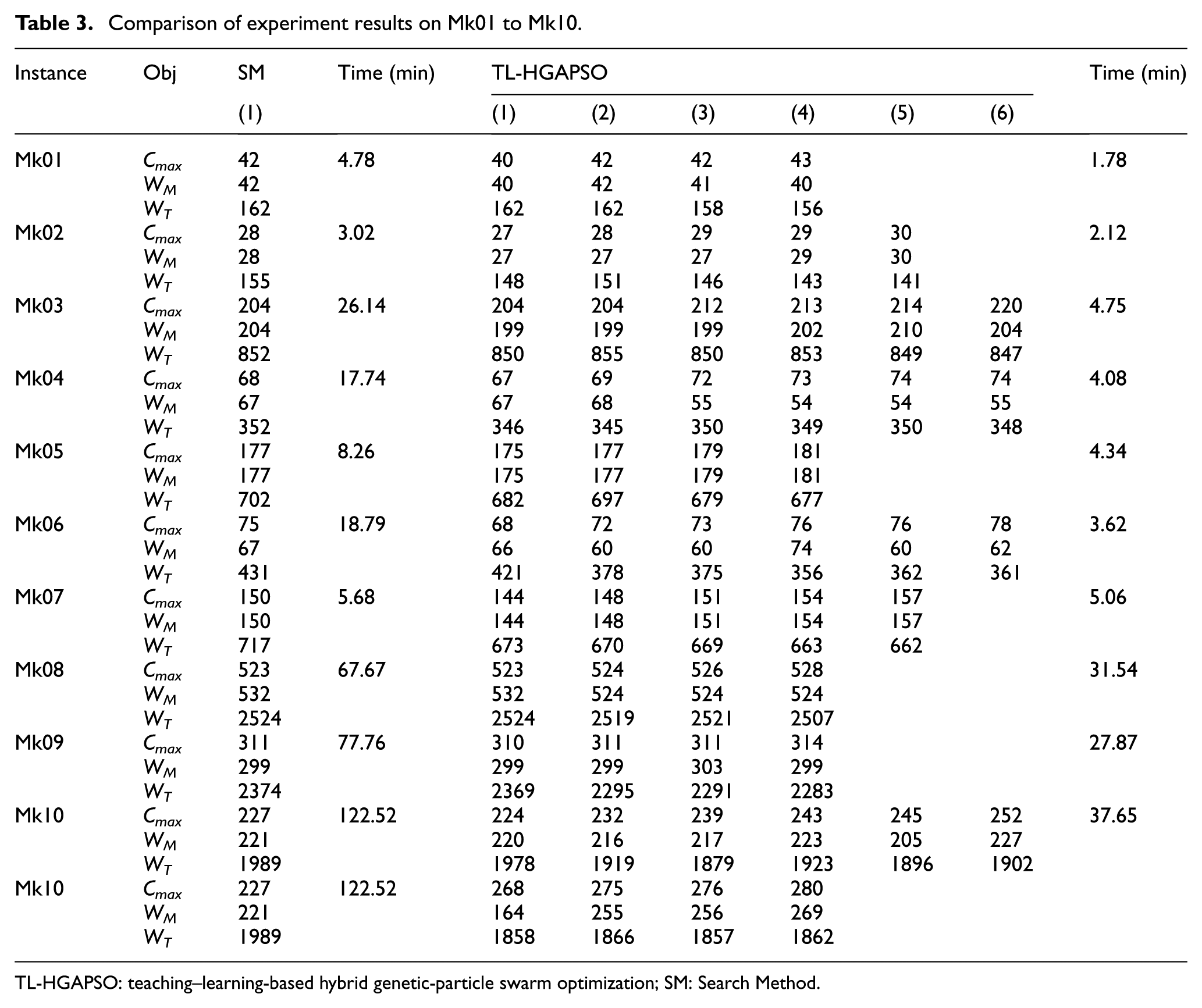
TL-HGAPSO: teaching–learning-based hybrid genetic-particle swarm optimization; SM: Search Method.
To sum up, it can be concluded that the proposed algorithm generally outperforms the other approaches in most of the 13 instances with respect to the quality of solutions and the computational time. Regarding the quality of solutions, the proposed algorithm gets no worse solution than other algorithms, and in some instances, its solution is much better than that of other algorithms. For the computational time, the proposed algorithm shows advantage over other algorithms. The experiment results verify the efficiency of the proposed algorithm for solving MOFJSP.
Conclusion and future research directions
Since GA lacks adequate memory and learning capability for the elite individual, it converges at a relatively slow speed. PSO can effectively solve this deficiency of GA. We develop a novel hybrid GA approach with PSO to solve MOFJSP, which combines both algorithms to complement each other. In addition, we introduce external memory library to improve the learning capability of GA. Numerical experiments show that the proposed method is superior to other methods in terms of both solution quality and computational time in most of instances.
In this article, we consider three objectives FJSP, and our future research can be directed to extend the proposed approach by considering many objectives (more than three objectives). In addition, the model established in this article does not take uncertain factors into account. However, the uncertain events such as rush orders, machine failures, and raw material shortages usually exist in the realistic production environment. Therefore, a real-time scheduling problem is the topic of our ongoing research. Although the coding scheme used in this study can ensure that a chromosome (genotype) produced by the crossover and mutation operation on parent chromosomes will be a feasible solution, it may lead to different chromosomes corresponding to an identical solution. Therefore, it also would be interesting to study coding schemes.
Footnotes
Handling Editor: Xichun Luo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project is supported by National Science Foundation of China (no. 71620107002, 71601050) and Social Science Foundation of Fujian Province, China (no. FJ2016C049).