
Abstract
With the development of Internet of Things, heterogeneous data from all kinds of sensors are processed and stored in the cloud server provider. Cloud can be regarded as one of the important layers in the Internet of Things architecture and Internet of Things is the biggest customer of the cloud. As to the security in the Internet of Things, encryption is one of the important mechanisms to achieve confidentiality of the data. However, data encryption introduces new challenges for its assured deletion in cloud, which becomes crucial for big data storage and processing in cloud for Internet of Things. Most existing solutions of cloud data assured deletion only delete the key while the ciphertext is still intact. On the other hand, the decryption time of the user increases with the size of data in the solutions. In this article, we propose a novel assured deletion scheme over encrypted cloud data based on the idea of uploading by sampling slice and outsourcing the decryption of ciphertext policy attribute–based encryption. The analysis and simulation results show that our scheme is secure and efficient, especially on reducing the decryption time of the user. We also designed a ciphertext deduplication scheme based on this scheme and explained its flow.
Introduction
Internet of Things (IoT) is a complex system with multiple heterogeneous networks. 1 Heterogeneous Internet of Things (HetIoT) is an emerging research field that has strong potential to transform both our understanding of fundamental computer science principles and our future living. 2 Qiu et al. 2 proposed a four-layer future HetIoT architecture as shown in Figure 1, which includes applications layer, cloud computing layer, networking layer, and sensing layer. The sensing data collected from various sensors are stored at cloud servers through efficient heterogeneous networking units. In this article, we focus on the cloud computing layer. Cloud computing layer in future HetIoT will receive and process data from other layers. 3

Future HetIoT architecture.
Concerning the integration of IoT and cloud computing, there have been made some previous studies. 4 A propose of a new platform for using cloud computing capacities for provision and support of ubiquitous connectivity and real-time applications and services for smart cities’ needs is given in Suciu et al. 5 The CloudThings architecture, a cloud-based IoT platform which accommodates CloudThings IaaS, PaaS, and SaaS for accelerating IoT application, development, and management proposed in Zhou et al. 6
The huge amounts of sensor data become an important resource, and at the same time, the data and the cloud have to face kinds of security risks which includes cloud data assured deletion. The data in IoT will keep sensitive for a long time, although it may be expired and it can also be abused by the attacker to do harm on the node or the IoT which is so dangerous. Most data stored in cloud is encrypted because cloud computing makes the ownership of cloud data separate from management, which may lead to security issues such as user data leakage, illegal migration across the cloud, and unauthorized access in cloud service provider (CSP). Furthermore, if owner’s data are stored in CSP for a long time and lack of effective assured deletion mechanism, it will not only cause huge waste of CSP storage space, but also lead to serious problems such as user data abuse and privacy leakage. Iqbal et al. 7 presents taxonomy of cloud security attacks and potential mitigation strategies with the aim of providing an in-depth understanding of security requirements in the cloud environment. Therefore, it is necessary to study the assured deleting technology of big data in cloud storage. 8 The technique named assured deletion will make sure that the expired or backup data was reliably deleted and remain permanently unrecoverable and inaccessible by any party. The explosive growth of data volume has introduced more challenges to cloud storage systems. Research shows that 60% of the data stored in the cloud storage system is redundant and it is also increasing over time. In order to improve the efficiency of cloud storage services and cut down the waste of resources, it is especially important to study ciphertext deduplication protocols in cloud storage.
Xiong et al. 9 divided the existing research into three categories: cloud data assured deletion based on trusted execution environments, cloud data assured deletion based on key managements, and cloud data assured deletion based on access control policies:
Cloud data assured deletion based on trusted execution environments.10,11
The basic idea of this method is to build a secure deleted executable environment from two aspects of hardware and software, but it needs to add trusted enhancement settings on the existing cloud computing infrastructure, so this method is difficult to achieve.
Cloud data assured deletion based on key managements.
This method includes cloud data assured deletion based on key centralized managements,12,13 cloud data assured deletion based on key distributed managements14–16 and cloud data assured deletion based on key hierarchical managements.17,18 The basic idea of this method is to delete the key to prevent the user from decrypting. However, the previous schemes only deleted the key while the ciphertext is still intact. Once the key was compromised, it would be a great threat to the privacy of sensitive data. Therefore, it cannot satisfy the real sense of assured deletion.
Cloud data assured deletion based on access control policies.
The attribute-based encryption (ABE) 19 is a prevailing technology to achieve data security access in the cloud environment, which includes the key policy attribute–based encryption (KP-ABE) and the ciphertext policy attribute–based encryption (CP-ABE). Xiong et al. 20 proposed the KP-ABE with time specified attributes (KP-TSABE) scheme, in which every ciphertext is labeled with a time interval while the private key is associated with a time instant. The ciphertext can only be decrypted if both the time instant is in the allowed time interval and the attributes associated with the ciphertext satisfy the key’s access structure. Zhang et al. 21 proposed a new scheme based on ciphertext sample slice named Assured Deletion based on Ciphertext Sample Slice (ADCSS). The incomplete data by means of ciphertext sample slice, which contributes to the top confidentiality of outsourced data even the key is obtained by accident or by malicious attacks.
Most of the existing cloud data assured deletion schemes are the destruction of the key. Zhang et al. 21 first realized part of the deletion of the ciphertext, the idea is similar to Secure Self-Destructing scheme for electronic Data (SSDD), 22 IBE based Secure Self-destruction scheme (ISS), 23 FULL lifecycle Privacy Protection scheme for sensitive data (FULLPP). 24 However, the encryption and decryption of this method are based on the bilinear pairing, which requires a large amount of calculation and calculation time, especially when the size of data is very large. To solve this problem, we combine the idea of uploading by sampling slice and outsourcing the decryption of CP-ABE.25,26 CP-ABE encryption mechanism can realize the secure sharing of cloud data among multi-users and flexible high-fine-grained access control. By associating user attributes with their private keys, the necessity of centralized key management is weakened, and the risk of key theft is reduced. This new scheme can achieve assured deletion and the decryption time has little change as the size of data is increased.
Background
Access structures
Definition 1 (access structure
27
) Let
In our context, the role of the parties is taken by the attributes. Thus, the access structure A will contain the authorized sets of attributes. We restrict our attention to monotone access structures. However, it is also possible to (inefficiently) realize general access structures using our techniques by defining the “not” of an attribute as a separate attribute altogether. Thus, the number of attributes in the system will be doubled. From now on, unless stated otherwise, by an access structure, we mean a monotone access structure.
Linear secret-sharing scheme
We will make essential use of linear secret-sharing schemes. We adapt our definitions from those in Beimel. 27
Definition 2 (linear secret-sharing schemes (LSSS))
A secret-sharing scheme
The shares of the parties form a vector over
There exists a matrix
It is shown in Green et al.
26
that every LSSS according to the above definition also enjoys the linear reconstruction property, defined as follows: suppose that
Like any secret-sharing scheme, it has the property that for any unauthorized set
System notation
Symbolic definition
Table 1 lists the definition of the related symbols in the scheme.
Symbolic definition.

Algorithm definition
This scheme includes five algorithms, which are defined as follows:
System model and scheme
System model
As shown in Figure 2, the system contains five types of entities: (1) CSP that offers storage services and cannot be fully trusted since it is curious about the contents of stored data, but should perform honestly on data storage in order to gain commercial profits; (2) data owner (DO) that uploads and saves its data at CSP; (3) authorized user (AU) that be authorized ones to access the documents of CSP; (4) trusted third party (TTP) that managed by authority, such as the government; (5) trusted authorized party (TAP) that generates keys in the algorithm:
The TAP runs the setup algorithm setup
The DO takes sample of the message
The DO sends
The TAP runs the key generation algorithm
The AU sends the set of attributes
The CSP sends the set of attributes
The CSP runs the outsourcing decryption algorithm
The TTP sends the
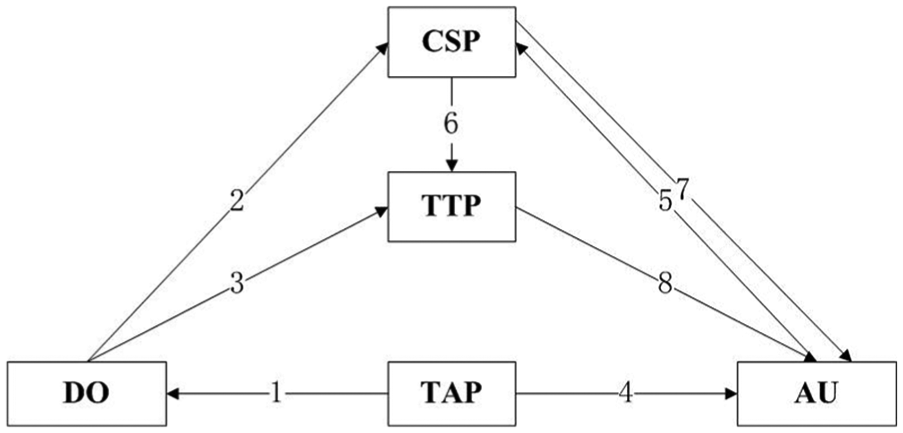
System model.
Then the AU runs the decryption algorithm
Scheme
Our cloud data assured deletion approach based on the CP-ABE construction of Waters. 28


The ciphertext of
The ciphertext of
The ciphertext of



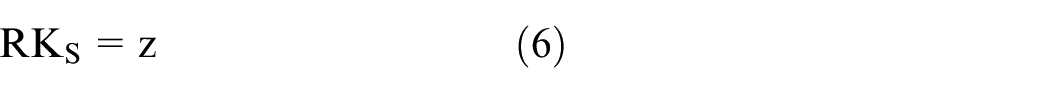

Performance analysis
Theoretical analysis
Theorem 1
If an attacker A breaks the scheme in a polynomial time with an negligible dominant
Proof
Let
Init: Attacker A selects an access policy
Setup: B sets up a parameter
KeyQuery 1: Attacker A selects attribute sets which will not satisfy the access policy
Challenge: Attacker A selects two plaintexts
If
If
KeyQuery 2: The same as KeyQuery 1.
Guess: Attacker A guesses
Implementation
Experimental environment
The testing environment was Intel Core i5-6200U CPU at 2.30 GHz, 2.40 GHz, 8.0 GB RAM, Windows 10 (64 bit). The software was MyEclipse 10, jdk1.6.0 and JPBC 1.2.0.
The symmetric encryption algorithm Advanced Encryption Standard (AES) used in CP-ABE, which was the algorithm in the security component Java Cryptography Extension (JCE) in Java Development Kit (JDK), and the key length is 128 bit. The sizes of the test files are selected in order of 8, 16, 32, 64, 128, 256 and 512 MB. The local decryption time is recorded respectively. The decryption time is the time from the ciphertext data flow to the plaintext data flow, that is, it does not include the time when the decrypted data stream is restored to a file.
Experimental results and performance analysis
The results of the experiment are shown in Tables 2 and 3. The decryption time refers to the time when the encrypted data stream is decrypted into a plaintext data stream. As shown in Figure 3, When there is no outsourced decryption in Zhang et al., 21 the decryption time increases as the file grows, while in our scheme the local decryption time almost remains unchanged and is less than 1 millisecond.
Decryption time.

Total time of decryption.


Decryption time.
The total decryption procedure includes the decryption and the coding. As shown in Figure 4, the total decryption time of our scheme is less than the scheme in Zhang et al., 21 and the larger the amount of data, the better our scheme performs. As the encoding time occupies most of the total decryption time, the study of efficient coding strategy helps us improve the efficiency of decryption.

Total time of decryption.
Experiments show that this scheme can realize the assured deletion over encrypted cloud data and reduce local decryption time by outsourcing complex bilinear pairings to a cloud server. With the huge amount of data in the cloud storage, the scheme overcomes the shortcoming of traditional algorithm that the decryption time increases with the increase of data. Although this study shortens local decryption time significantly, the time to restore the data stream to the file is far greater, which will be further discussed in future research.
Ciphertext deduplication protocol
Based on the assured deletion protocol in the fourth part, we extended the ciphertext deduplication protocol. The ciphertext deduplication protocol includes two sub-protocols, a duplicate data detection protocol, and a provable user ownership protocol.
As shown in Figure 5, the DO wants to upload a new data

Data deduplication protocol system model.
Duplicate data detection protocol
The proposed scheme in this section is improved based on the literature. 29 A decision tree is a tree structure that classifies data according to different attributes. Each of the internal nodes represents an attribute judgment. Each branch represents the output of the attribute result according to the difference of the attribute judgment results, and each leaf node represents a classification result.
The cloud server creates a decision tree as shown in Figure 6 for the data stored in it. Each node consists of two parts of information, the hash value and parameters of the file. The specific parameter generation process is that the cloud server generates a seed parameter s0, which is a root node parameter, and sequentially generates respective node parameters of the left and right subtrees according to the seed parameter and the following calculation rules.

Duplicate data detection protocol.
Left subtree parameter calculation rule

Right subtree parameter calculation rule

1. The DO sends the query information


(In the initial case,
2. The cloud server starts from the root node of the decision tree and verifies whether the following equation is set,
3. When the equation holds, it means that there are duplicate data. The cloud server will send the hash value of the file to the TTP.
Analysis of duplicate data detection protocols
First, the protocol will get the correct path to the tree during the verification process. Since the decision tree in the protocol is a self-generating tree, obviously if
Second, in the verification process, each step will judge whether the following equation is true,
Provable ownership protocol
If Challenger C wants to access a file stored in cloud server, it should submit a query information to the cloud server first. Then both of them run the duplicate data detection protocol as above steps 1–3 to verify if there is such a file in the cloud server. If the equation holds, then:
4. Receiving
5. The Challenger C samples the owned data
6. The TTP calculates
7. If the authorized organization receives 0, nothing will be done. If the authorized organization receives 1, the Challenger C is authenticated as a legitimate user, and the authorization center runs two algorithms
Analysis of the proof of ownership protocol
With reference to the proof steps in the random detection of data blocks in Zhao,
30
we have the following verification. Suppose that the file to be verified contains n data blocks, in which t data blocks are inconsistent with original file. The TTP requires verification of randomly selected c data blocks, while R is the number of the inconsistent data blocks in them.

Due to

And so

The analysis shows that when there are 1% inconsistent blocks out of n, only 460 randomly selected blocks can satisfy the detection probability which is more than 99%. In other words, when the detection file is inconsistent with more than 1% of the data block in the original file, we select 460 data blocks for detection, and the inconsistent one can be found with probability more than 99%.
Protocol workflow
The system should further implement the two functions of assured deletion and ciphertext deduplication on the basis of implementing the cloud storage service function. As shown in Figure 7, the workflow of the protocol is described below.
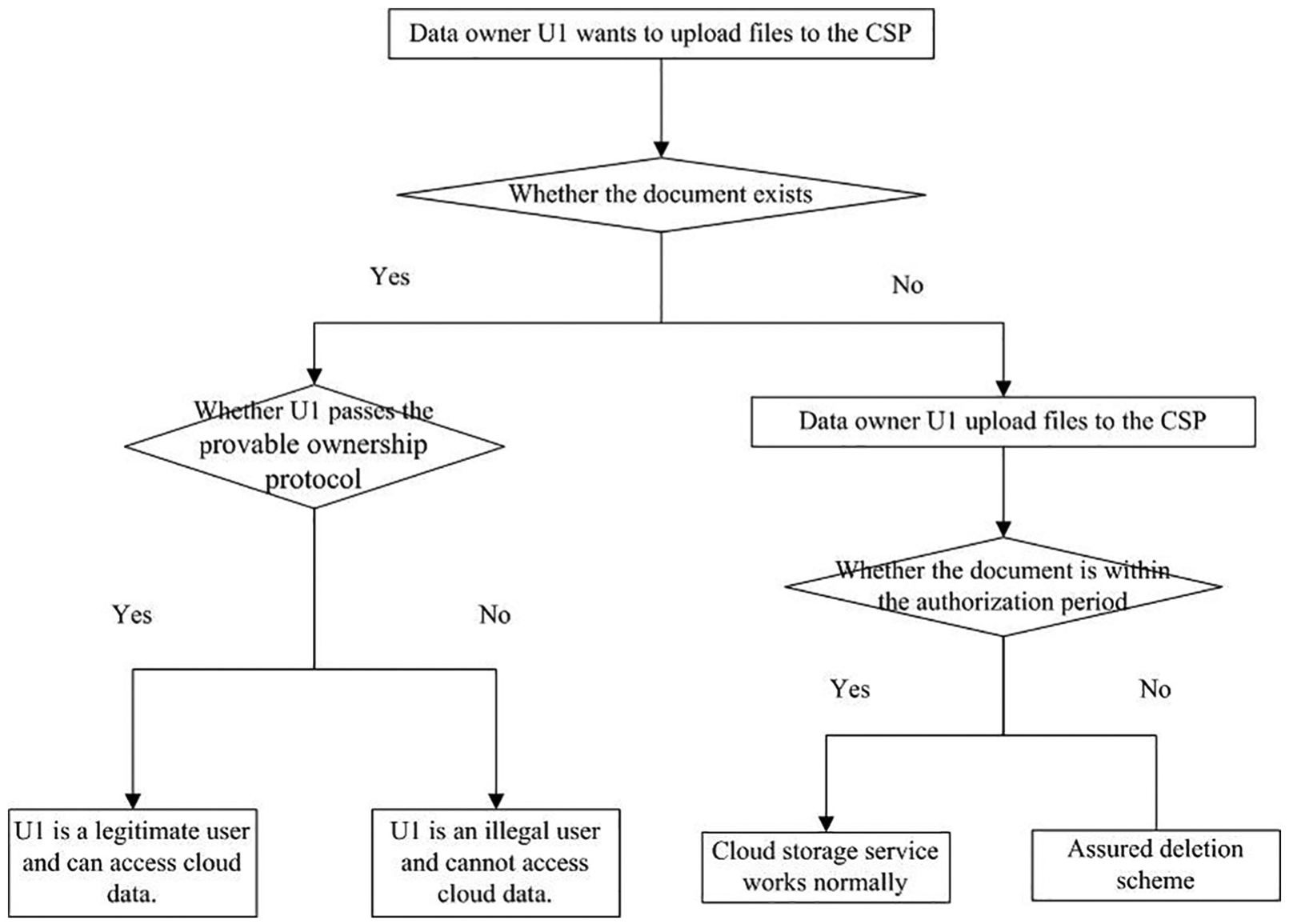
Protocol workflow.
The DO U1 wants to upload a file to the cloud server and runs a duplicate data detection protocol with the cloud server first. The detection result will show whether the file already exists in the cloud server or not.
If the file already exists in the cloud server, the user ownership verification protocol is run between U1 and the TTP. If U1 passes the ownership verification protocol, it is a legitimate user who can access the cloud data. Otherwise, U1 is an illegal user to access the cloud data.
If the file does not exist in the cloud server, U1 will be the initial uploader to upload the encrypted sampled slicing file. The user can use the cloud storage service normally during the authorization period. Otherwise, the TTP performs the assured deletion protocol to delete the sampled data information when the authorization expires.
Conclusion
The WSN in IoT is the data source of the cloud computing and cloud computing makes the heterogonous data available for many services and applications in IoT. The combination of the IoT and cloud computing had to face problems in their practical way as they are based on the Internet. The assured deleting of cloud encrypted data is one of the issues. By researching and combing out the existing assured deletion methods, we adopt a method of outsourcing the decryption part to innovate the method of assured deletion of cloud data based on ciphertext sampling in this article. In this method, complex bilinear pairings will be performed by cloud servers instead of local ones. Therefore, once the user gets the transposed ciphertext, it takes only one simple calculation to get the plaintext data stream. Extensive performance analysis and test showed that our scheme can effectively shorten the local time for the user to decrypt, and it also improves the security of confidential data while improving the decryption efficiency. It means that an attacker has to get four parts of information to get relevant information, which includes the transpose key, the remaining ciphertext, the sampling ciphertext bit information, and the location information of the encrypted ciphertext. Future work will extend the function of assured deletion and deduplication on encrypted big data in cloud.
Footnotes
Handling Editor: Fei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.