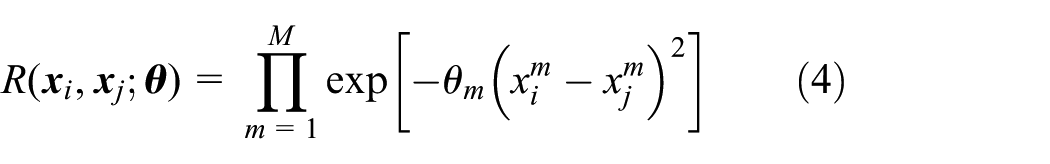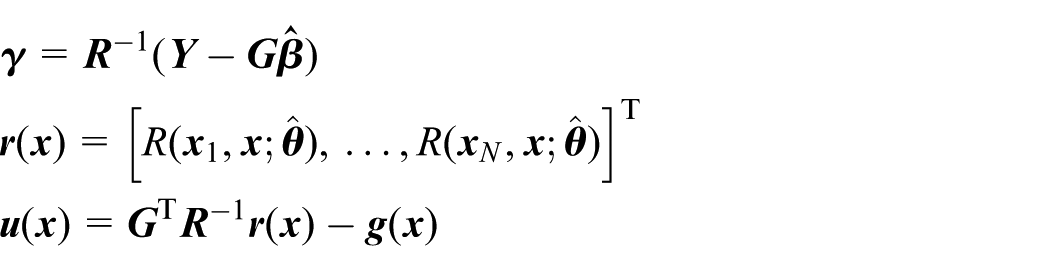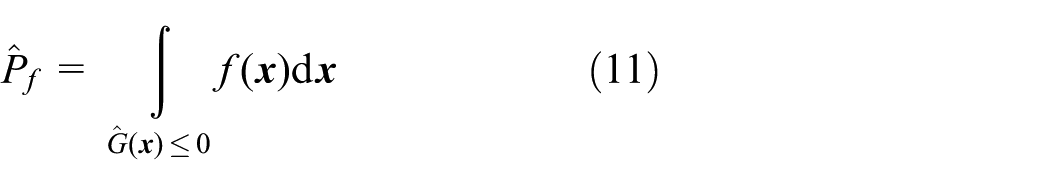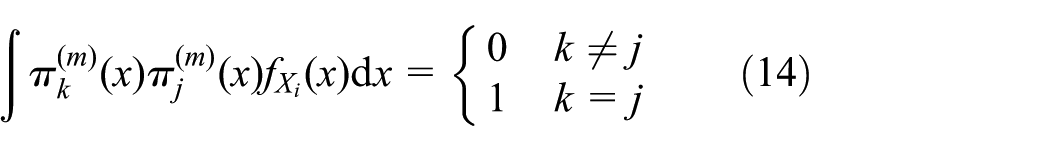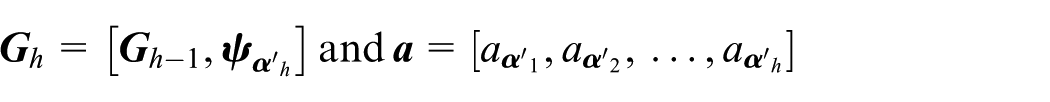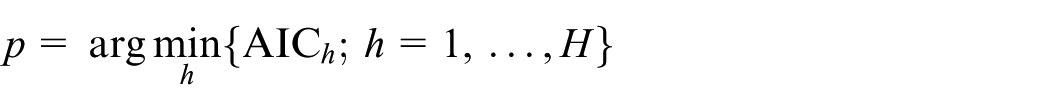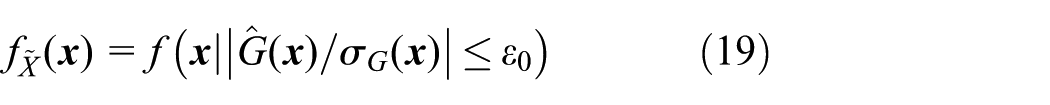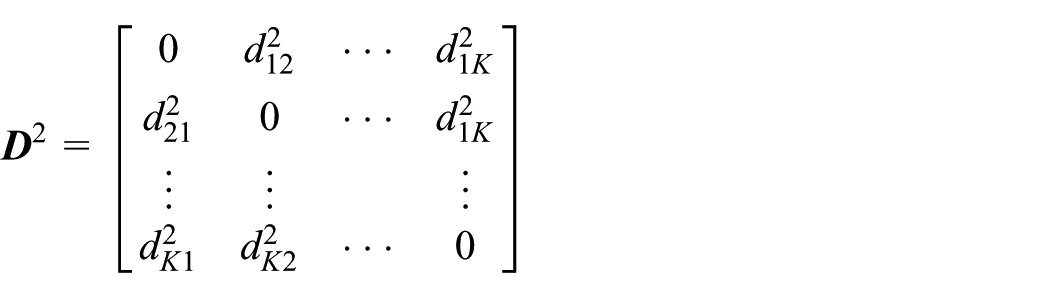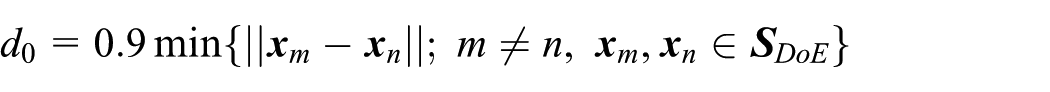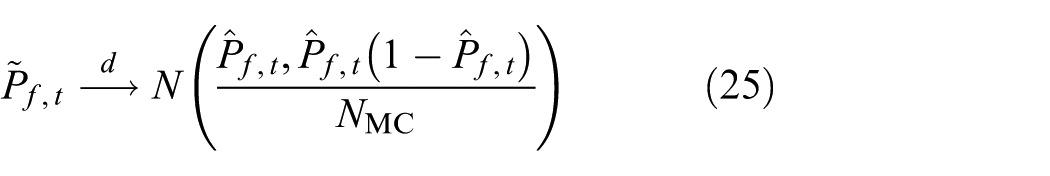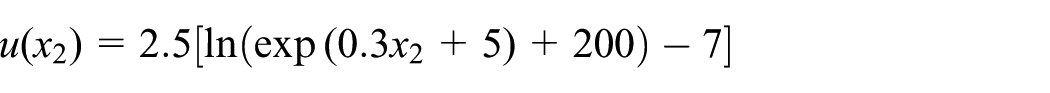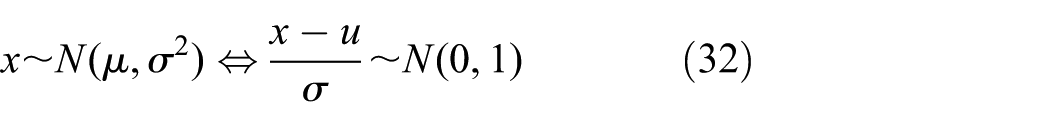As the numerical model of engineering structure becomes more and more complicated and time consuming, efficient structural reliability analysis is badly in need. To reduce the number of calls to the performance function and iterative times during structural reliability analysis, an innovative strategy of the design of experiments (DoE) called Isomap-Clustering strategy is proposed. According to the statistical information provided by Kriging, points with the worst uncertainty for reliability analysis are on the estimated limit state. Therefore, by combining Isomap and k-means clustering algorithm, Isomap-Clustering strategy refreshes the DoE of the Kriging model with a few representative points in the vicinity of the estimated limit state each iteration and iteratively “pushes” the estimated limit state to the real one until a stopping condition is satisfied. By employing the proposed DoE strategy and sparse polynomial-Kriging model, a structural reliability analysis method is constructed, whose stopping criterion is defined by derivation. Three examples are studied. Results show that the proposed method can lower the number of calls to the performance function and remarkably reduces the iterations of structural reliability analysis.
The input variables of structures in engineering are often influenced by kinds of randomness. It is necessary to analyze structural reliability by treating inputs as random variables. For a given structure, its performance function G(x) divides the input space into two domains: the safe domain G(x) > 0 and the failure domain G(x) ≤ 0. The boundary of them (G(x) = 0) is the limit state. The failure probability of the studied structure can be defined as
where x is a realization of M-dimension random input vector (X = [x1, x2, …, xM]T) and f(x) is the joint probability density function (PDF) of X. The main task of structural reliability analysis is to perform the integral of equation (1), which is troublesome for engineering problems with time-consuming G(x). Several kinds of methods, including the first-order reliability method (FORM) and second-order reliability method (SORM),1 random simulation–based methods,2,3 and surrogate model–based methods,4,5 have already been developed.
The performance function is usually implicit in engineering, which restricts the application of FORM and SORM. As the most robust method, Monte Carlo simulation (MCS) could meet any accuracy requirement theoretically.6 However, it needs to call the performance function too many times, which is usually impractical to implement. Some alternative simulation techniques, including importance sampling (IS),7,8 line sampling (LS),9,10 and subset simulation (SS),11 are constructed. When structural numerical model needs hours, even days, to calculate once, the existing variance reduction methods are still not efficient enough. In recent years, surrogate models, mainly including polynomial response surface,12,13 support vector machine (SVM),14 neural network,15 and Kriging,16 are widely used. Surrogate model–based methods construct an explicit expression () as the approximation of G(x) and then estimates the target failure probability by replacing G(x) with in equation (1). This article focuses on Kriging-based reliability analysis method. Compared with other surrogate models, Kriging is an interpolation model and provides an accuracy measure of the predictor, which is its most important advantage. It is widely employed in structural reliability analysis,5,17–19 global optimization,20,21 and sensitivity analysis.22,23
For reliability analysis applications, it is enough to accurately approximate the performance function in the vicinity of the limit state rather than in the whole space of inputs. Therefore, several adaptive DoE strategies are constructed, which aim to efficiently improve the Kriging-based estimate of the limit state and perform the structural reliability analysis by calling to the performance function as fewer times as possible. Inspired by the expected improvement function (EIF) proposed by Jones et al.20 for global optimization, Bichon et al.24 propose the expected feasibility function (EFF) to measure how close an untried point is to the limit state and define the next best point of the Kriging model as the maximum point of EFF. Echard et al.17 develop a reliability analysis method by combining the Kriging model with MCS (AK-MCS), in which the best next point is defined according to their proposed learning function U. The learning function U measures the probability that the Kriging model wrongly predicts the sign of the performance value at a point. It is also employed by AK-IS,25 AK-SS,26 and AK-SSIS.19 Lv et al.18 and Yang and colleagues27–29 measure the epistemic uncertainty of the sign of the performance value from different perspective and develop their learning functions H and expected risk function (ERF), respectively. Recently, Sun et al.30 propose an innovative learning function least improvement function (LIF) which quantitatively measures how much an untried point could improve the Kriging-based estimate of the failure probability.
These learning function–based adaptive DoE strategies mentioned above are able to efficiently enhance the accuracy of the Kriging model. However, because the Kriging model is refreshed with only one point every iteration, they always need many iterative steps to meet a stopping criterion. As the development of hardware, parallel computing is usually available in engineering, which is helpful to remarkably reduce the number of iterations.
To make the best of hardware resources and further improve the computational efficiency of structural reliability analysis with time-consuming performance function, an innovative adaptive DoE strategy of the Kriging model, named as Isomap-Clustering strategy, is proposed, which combines Isomap (a nonlinear dimensionality reduction method) with k-means clustering. The proposed strategy is designed to refresh the Kriging model with a few points each iteration. As the signs of performance values of points on the estimate of the limit state estimate () are with the most uncertainty, the proposed strategy selects “representative points” in the vicinity of to enhance the accuracy of the Kriging model. To realize the goal, Isomap maps the candidate points randomly generated to lower space, and then, k-means clustering algorithm is employed to find the cluster centers of the mapped points. Representative points can be obtained by one-to-one mapping of Isomap dimensionality reduction. In this way, it is avoided that any two of the representative points are too close to each other. A Kriging-based reliability analysis procedure is developed mainly based on the proposed Isomap-Clustering strategy. And the basic function of the Kriging model is sparse polynomial, which is constructed according to least angle regression (LAR) and Akaike information criterion (AIC).
The remainder of this research is organized as follows. Section “Sparse polynomial-Kriging” introduces the basic theory of Kriging and the selection procedure of its basic function. Section “The Isomap-Clustering strategy” details the proposed Isomap-Clustering strategy, which is followed by the Kriging-based reliability analysis method. Section “Numerical applications” studies two analytical examples and one truss structure to demonstrate the advantage of the proposed adaptive DoE strategy. Section “Conclusion” presents the conclusion.
Sparse polynomial-Kriging
The Kriging model
Kriging developed by Krige for geostatistics and improved by Matheron31 is a nonlinearity interpolation meta-model. It supposes that the deterministic function needed to be approximated consists of two parts, that is, a regression model and a random function
where gh(x) (h = 1,2, …, p) is the regression basis, which is discussed in section “Basic function of the Kriging model.”z(x) is a Gaussian stochastic process with zero mean, whose covariance is defined as
where σ2 is the variance of z(x). R(xi, xj; θ), the correlation coefficient between z(xi) and z(xj) with parameter θ, is the Gaussian correlation function generally
where is the mth component of xi.
Given a DoE SDoE = [x1, x2, …, xN], and the corresponding performance values Y = [y1, y2, …, yN]T, the unknown parameters β, σ2, and θ in equations (2)–(4) can be estimated by maximum likelihood estimation
where
The optimum estimations of β, σ2, and θ obtained from equation (5) are denoted by , respectively. The best linear predictor at x reads
The minimum variance unbiased estimator of G(x) is
where
So, the real performance value at x subjects to normal distribution, whose mean and standard deviation are and , respectively
Bichon et al.24 show the detailed theory of the Kriging model.
The failure probability of studied structure can be estimated as
MCS is adopted here to perform the multiple integration of equation (11)
where xMC,i (i = 1, 2, …, NMC) is a sequence of independent identically distributed (i.i.d.) points generated from f(x) and NMC is the number of random points. The coefficient of variation of is
Basic function of the Kriging model
It is supported that the input random variable X subjects to multivariate standard normal distribution and the components are independent. Otherwise, X is available to exactly or approximately transform into multivariate standard normal distribution.
Regression basis function, gh(x) (h = 1, 2, …, p), is generally set to be constant or multivariate polynomial. Gaspar et al.5 assess the accuracy of Kriging model with different basis functions. The effect of the order of basis function shown to be negligible if there are enough DoE points. Higher order of gh(x) appears rewarding to the Kriging model in case that the number of points in SDoE is low, which usually occurs during structural reliability analysis if the performance function is time consuming. However, the number of terms of basic function increases dramatically with the size of X and the order of polynomial, which makes the high order (e.g. cubic) almost unavailable for the Kriging model during reliability analysis. To address such problem, this article constructs the basic function with sparse polynomial, during which LAR32 and AIC are adopted.
Let (j = 1,2, …) denotes the complete orthonormal basis of the Hilbert space , which means that (j = 1,2,…) is an orthonormal function series in the sense of
where is the PDF of Xi (mth component of X).
A possible complete orthonormal basis of the Hilbert space L2(R, f) (f is the joint PDF of X) is
where α = [α1, α2, …, αM] is a M-dimension vector of natural number. Here, the terms whose total degree |α| = α1 + α2 + … + αM does not exceed a given threshold value T0 are retained as candidates of the basic function of the Kriging model. The set of candidates of the basic function is denoted by
The number of the elements in is P
Then, the “complete” design matrix that considers all candidates of the basic function is
where and xn ∈ SDoE (n = 1, 2, …, N).
According to equation (15), the least number of calls to the performance function increases extremely with T0 if employing all terms in as the basic function of the Kriging model. To overcome the problem, only a part of terms in are retained to build up the sparse polynomial basic function. LAR is employed to provide a number of possible polynomial basis sets that can explain the performance function, and AIC is used to decide which is the optimal. The main steps of the selection of the Kriging basic function are listed as follows:
Step 1. Set values of parameters concerned, that is, the maximal order of retained polynomial T0 and the maximal number of terms of the basic function pmax. In this article, T0 = 3 and pmax = 0.5 card (SDoE)
Step 2. Initialize all the coefficients of the candidate terms to (i = 0, 1, …, P − 1). According to LAR theory, the initial residual equals to the structural response Y.
Step 3. Find the vector that maximizes the correlation coefficient between (i = 0, 1, …, P – 1) and the current residual
Step 4. h = 2. Adjust in the direction defined by the least square coefficient of the current residual on G1, until another vector has the same correlation coefficient with the current residual as does G1
Step 5. h = h + 1. Move jointly a toward its joint least square coefficient of the current residual on Gh – 1 until a vector has the same correlation coefficient with the current residual as does Gk – 1
Step 6. Repeat step 5 until h = H.
Step 7. Compute AIC values of Gh (h = 1, …, H)
where
Step 8. Find the minimum of AICh (h = 1, …, H)
Then, for SDoE and Y, the optimal basic function of the Kriging model reads
Figure 1 shows the procedure above. Efron et al.32 provide more details about LAR.
Flowchart of the selection of Kriging basis.
The Isomap-Clustering strategy
Just like what G(x) does, divides the X space into two domains, that is, and . is the estimate of the limit state. According to equation (11), the accuracy of the estimate of Pf mainly depends on how close is to G(x) = 0. xMC,i disturbs the accuracy of only when the Kriging model wrongly predicts the sign of G(xMC,i), that is
It is obvious that equation (17) equals to its maximum value (i.e. 0.5) if and only if . In another word, points on the estimated limit state are disturbing the accuracy of reliability analysis with the maximal probability. Besides, equations (1) and (11) illustrate that for reliability analysis, the Kriging model just needs to well fit G(x) = 0 rather than the whole X space. One efficient approach to obtain an accurate Kriging model with calling to the performance function fewer times is to make most of the DoE points located in the vicinity of G(x) = 0. However, G(x) = 0 is unknown in engineering.
Therefore, the proposed DoE strategy refreshes the DoE with points in the vicinity of and iteratively improves the accuracy of as well as the Kriging model until it is acceptable. Furthermore, to remarkably reduce the iterations of reliability analysis method, the proposed strategy adds a few representative points into DoE each iteration. Isomap technique and k-means clustering algorithm are employed to avoid any two of the representative points too close to each other. The proposed adaptive DoE strategy is generalized as follows.
Step 1. For the Kriging model already constructed, generate K random points on or almost on . They are treated as the candidates of the representative points to refresh the current DoE. It is theoretically impossible that samples from random simulation method are exactly located on . Hence, the less-than-ideal alternative is to make them satisfy equation (18)
where ε0 > 0. The lower ε0 is, the closer x is to . This article sets ε0 = 0.1, as . Let denotes the i.i.d. point set as well as the candidate set of the representative points mentioned above
Both MCS and Markov chain Monte Carlo (MCMC) are suitable to generate . And the latter is adopted here. The conditional PDF for generating is
The domain defined by equation (18) is very cabined. It is almost sure that its proportion in the whole X space is below that of the estimated failure domain, that is, the estimate of the failure probability
According to equation (13), the coefficient of variation of approximates to . In another word, (, the number of the random samples located in ) is available to measure how well the dispersion of the estimated failure samples is. Similarly, this article employs to measure the dispersion of the i.i.d. points in the vicinity of
As () is enough for most of the engineering problems, this article proposes K = 3 × 103 ∼ 104.
Step 2. Reduce the dimension of points in from M to d (d < M) with Isomap technique. is mapped to a d-dimension point set
where is corresponding to in (i = 1, 2, …, K). Isomap is used to straighten the “curve” (M = 2) and spread out the “surface” (M = 3) or the “hyper-surface” (M > 3). This article sets d = M–1 for simplification (determining the optimal d during dimensionality reduction is a complicated problem).
Step 3. Pick k representative points in . Group into k clusters by clustering algorithm and get k centers (i = 1, …, k). In , approximate inverse images of (i = 1, …, k) are the representative points mentioned above.
Step 2 and step 3 are illustrated in detail in sections “Framework of MSFA–SVR” and “Pre-adaptation results integration.”
According to equations (18) and (19), the area where points are with larger values of (which is proportional to f(x) and quantifies the importance of x to Pf) and (which measures the epistemic uncertainty of G(x)) tends to gather more random points. Therefore, the representative points are more likely to locate in the area(s) of interest, as a result of which the Kriging model could be directly improved.
Dimensionality reduction of with Isomap
Isomap is one of the most widely applied nonlinear dimensionality reduction techniques. It performs low-dimensional embedding based on the geodesic distance which is the sum of edges along the shortest path between points. The main steps of Isomap algorithm are summarized as follows:
Step 1. Define neighbor set of each point. The neighbor set of in consists of its nearest neighbors.
Step 2. Construct the neighborhood graph over all points and compute the pairwise geodesic distance to get the squared geodesic distance matrix D2. Geodesic distance is the sum of edge length which is equal to the Euclidean distance along the shortest path between points
where is the geodesic distance between and in .
Step 3. Perform lower dimensional embedding by applying multidimensional scaling to the acquired pairwise geodesic distances and get the d-dimension point set
where is the pth eigenvalue of matrix Q and is the corresponding eigenvector of .
Cluster analysis with k-means clustering algorithm
k-means clustering is a cluster analysis method whose aim is to group a set of objects into several clusters while guaranteeing that the objects in the same cluster are more similar to each other than to those in any other clusters. Given the point set , k-means clustering groups into k clusters so as to minimize the within-cluster sum of squares (WCSS)
where is the mean of points in . The M-dimension point corresponding with is not unique because of d < M. Moreover, as the iterative procedure goes and converges to G(x) = 0 gradually, representative points may be too close to some points in current DoE and result in ill-condition design matrix (G in equation (6)) and worse quality of DoE points. To overcome the awkward situations, the representative points of are acquired according to equations (23) and (24)
whereas in this article
The proposed reliability analysis method
This section constructs an adaptive structural reliability analysis method, which is mainly based on the proposed Isomap-Clustering strategy in section “Specification on proposed method.” In the proposed method, the surrogate model of the performance function is based on the sparse polynomial-Kriging illustrated in section 2, and the proposed Isomap-Clustering strategy in section “Specification on proposed method” is employed to iteratively improve the Kriging model until its accuracy meets the stopping criterion defined by derivation. The main steps of the adaptive method are listed as follows:
Step 1. t = 0. Generate the initial DoE with Latin hypercube sampling (LHS) and call to the performance function to calculate the performance values at the initial DoE points. The hyper-rectangle of LHS is [−nσ, nσ]M, and the initial number of points is N0. This article sets nσ = 5
Step 2. Construct the Kriging model and based on sparse polynomial-Kriging and compute the estimated failure probability (). Section “Research background” details the theory of the Kriging model and method for selecting the basic function with LAR and AIC. The integral of equation (11) is approximately performed with MCS, and denotes the estimation of
According to the central limit theorems, converges in distribution to a normal distribution
Then
where e > 0. is the cumulative distribution function (CDF) of the standard normal distribution. The failure probability is generally with small magnitude, so in the denominator is neglectable. It is set that the relative error of is no larger than 3% with confidence level 0.95
is the expectation of failure number among random samples, so this article sets that MCS terminates until the number of failure random samples is above 4300.
Step 3. Judge whether the iterative procedure is convergent. If and satisfy equation (28), terminate the procedure. is the estimate of the target failure probability. Otherwise, continue and go to step 4.
When both and , approximate G(x) = 0 well enough, and they satisfy that
Therefore, the reliability analysis procedure is regarded as convergent if the relative error between and is less than 4%
Step 4. t = t + 1. Carry out the Isomap-Clustering strategy and refresh the current DoE. Search the representative points in the vicinity of by employing the Isomap-clustering strategy proposed in section “Research background” and compute their performance function values. Refresh the current DoE and Y and return to step 2.
Numerical applications
In this section, three examples are analyzed to demonstrate the advantage of the proposed Isomap-Clustering strategy. Two of them have explicit performance functions and the other one is implicit.
Example 1: an analytical example with two input variables
The first analytical example with two input variables has already been analyzed in Roussouly et al.33 It is adopted here to visualize the Isomap-Clustering strategy. The performance function is
where X = [X1, X2]T subjects to standard bivariate normal distribution and X1 and X2 are mutually independent. The failure domain G(x) ≤ 0 is equivalent to
The target failure probability is
where
According to equation (30), the target reliability index () is 2.686
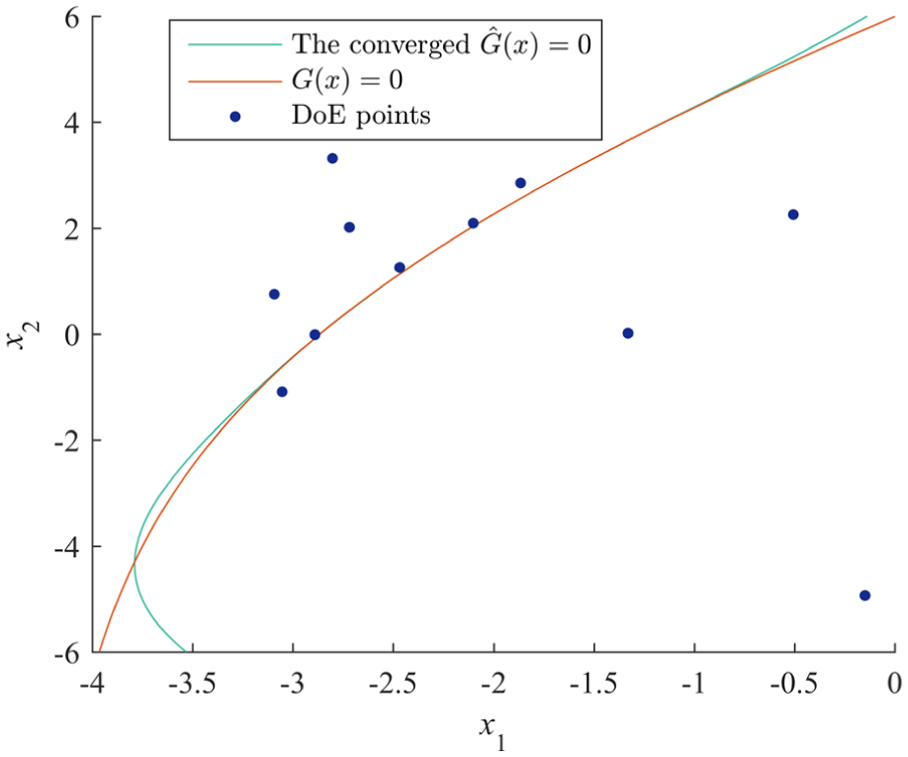
The method constructed in section “The proposed reliability analysis method” is applied to this example with N0 = 6, K = 300, and k = 3. The proposed reliability analysis method based on Isomap-Clustering strategy satisfies the stopping criterion defined by equation (28) when t = 3. Figure 2 visualizes the DoE points from the Isomap-Clustering and the Kriging-based of each iteration. Figure 3 compares the convergent and G(x) = 0 and shows the DoE points to construct the convergent Kriging model. Figures 2 and 3 demonstrate that most of the DoE points from Isomap-Clustering strategy are located in area of interest and that the concentration of DoE points is successfully avoided. Results are summarized in Table 1.
The process of iterations for example 1. Subfigure (a), (b) and (c) correspond with the 1st, 2nd and 3rd iteratives of the proposed method, respectively. The legend shown in subfigure (a) is also valid for subfigure (b) and (c).
The comparison between the convergent and G(x) = 0.
Results of example 1.
Ncall
3.62 × 10−3
3.63 × 10−3
2.686
2.685
15
Example 2: an analytical example with six input variables
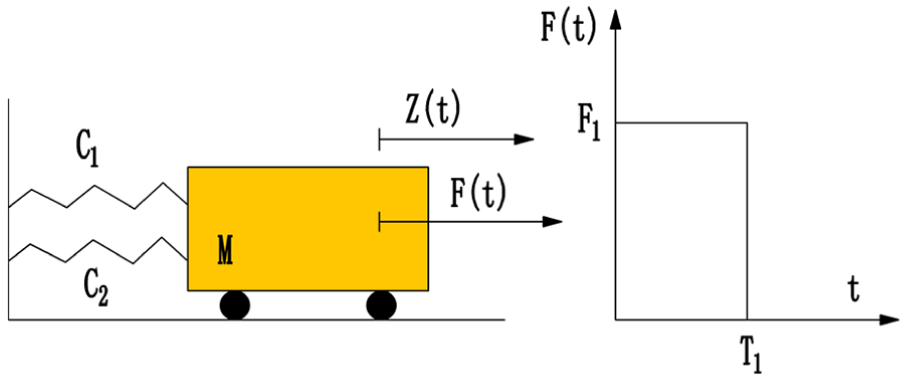
The second analytical example with six input variables handles the nonlinear undamped single degree of freedom system shown in Figure 4. It has already been studied in literatures.13,17,34 Its performance function is defined as
where
The nonlinear undamped single-degree-of-freedom system.
All input variables are mutually independent and subject to normal distribution. Their means and standard deviations are listed in Table 2. The referential failure probability obtained from MCS with 106 simulations is 2.87 × 10−2.
Distribution parameters of variables in example 2.
Variable
C1
C2
M
R
T1
F1
Mean
1
0.1
1
0.5
1
0.45
Standard deviation
0.1
0.01
0.05
0.05
0.2
0.075
First, all inputs are transformed to the standard normal distribution according to equation (32). To investigate the influence of k on efficiency of the Isomap-Clustering strategy, the reliability analysis method proposed in section “Empirical comparison and discussion” is run five times with N0 = 10, K = 3000, and different values of k (k = 4, 5, 6, 7, 8)
Results from the proposed method and AK-MCS-based methods are summarized in Table 3. Ncall, , δ, and ε% listed in Table 3 stand for the number of calls to the performance function (equation (31)), the estimate of the target failure probability, the coefficient of variation of , and the relative error of compared with the reference value, respectively. According to Table 3, it seems that k affects Ncall of the proposed method slightly. With acceptable accuracy (ε%), the number of calls to performance function (Ncall) is lower than other methods listed in Table 3. Moreover, the iterations of the proposed method is much fewer than the Kriging-based methods AK-MCS+U and AK-MCS+EFF because the Isomap-Clustering strategy refreshes the Kriging model with a few points, while they do it with only one point each iteration.
Comparisons of results of example 2.
Method
Ncall
Iterations
(10−2)
δ (%)
ε (%)
MCS
106
–
2.87
0.59
–
AK-MCS + U
57
47
2.85
1.85
<0.1
AK-MCS + EFF
55
45
2.86
1.80
0.39
The proposed method
46 (k = 4)
9
2.85
0.67
0.63
40 (k = 5)
6
2.87
0.67
<0.1
40 (k = 6)
5
2.84
0.66
0.58
38 (k = 7)
4
2.85
0.65
0.61
42 (k = 8)
4
2.86
0.68
0.29
MCS: Monte Carlo simulation; EFF: expected feasibility function.
Example 3: truss structure with 10 dimensions
This truss structure has already been studied in Roussouly et al.33 and Blatman and Sudret.35 As shown in Figure 5, it contains 11 horizontal bars and 12 sloping ones. A1 and E1 denote horizontal bar’s cross section and Young’s moduli, respectively, while A2 and E2 denote sloping bars: six loads, from P1 to P6, are applied on nodes of horizontal bars. These 10 random variables are independent of each other, and their distribution information is listed in Table 4.
The truss structure (unit meter).
Distribution information of variables in example 2.
Variable
Distribution
Mean
Standard deviation
P1–P6
Gumbel
A1
Lognormal
A2
Lognormal
E1
Lognormal
E2
Lognormal
The deflection of node 1 in Figure 5 denoted by s(x) is the response of the structure. The threshold of |s(x)| is 0.14m in accordance with Roussouly et al.33 The performance function of the truss structure is
According to Roussouly et al.33 and Blatman and Sudret,35 the referential failure probability () and reliability index () are and 3.98, respectively, which is from IS with 500,000 simulations.
After transforming the variables in Table 4 to the standard normal distribution, apply the proposed method to the truss structure 10 times with N0 = 15, K = 3000, and different values of k (k = 4, 5, 6, 7, 8) to test its stability. Results are summarized in Table 5. Figure 6 shows the convergent process of and . The stopping criterion proposed in Tong et al.19 is employed as the condition of convergence of AK-MCS-based methods, as the one proposed in Echard et al.17, is apparently too rigorous and equation (28) is not available for AK-MCS.
Comparisons of results of example 3.
Method
Ncall
Iterations
(10−5)
δ (%)
IS
5 × 105
−
3.45
1.5
3.98
AK-MCS + U
145
130
3.35
1.51
3.99
AK-MCS + EFF
160
145
3.33
1.53
3.99
The proposed method
115 (k = 4)
25
3.39
1.51
3.98
107 (k = 4)
23
3.44
1.45
3.98
120 (k = 5)
21
3.32
1.47
3.99
115 (k = 5)
20
3.31
1.50
3.99
105 (k = 6)
15
3.40
1.49
3.99
117 (k = 6)
17
3.32
1.50
3.99
99 (k = 7)
12
3.30
1.47
3.99
106 (k = 7)
13
3.36
1.50
3.99
111 (k = 8)
12
3.35
1.48
3.99
103 (k = 8)
11
3.38
1.49
3.98
MCS: Monte Carlo simulation; EFF: expected feasibility function.
The convergence procedure of and . AK-MCS+EFF means that the corresponding results (i.e. the estimates of the targer failure probability and reliability index) are from AK-MCS+EFF, and other lines are in a similar way. Subfigures (a) and (c) correspond to subfigures (b) and (d), respectively. All the subfigures share the legend shown in subfigure (a).
Conclusion
This article proposes an innovative DoE strategy for Kriging-based reliability analysis method. The strategy, named as Isomap-Clustering strategy, is able to refresh the Kriging model with several representative points in the vicinity of the estimate of the limit state each iteration. In the innovative strategy, Isomap method andk-means clustering algorithm are employed to determine the representative points among hundreds, even thousands, of candidates. A Kriging-based active reliability analysis method which employs sparse polynomial-Kriging model and Isomap-Clustering strategy is also constructed. As a modification of original Kriging model, sparse polynomial-Kriging is more flexible in terms of basic regression function. To validate the proposed DoE strategy and the reliability method, three examples are analyzed. From the results, the following can be concluded:
Most of the Isomap-Clustering strategy–based points to refresh DoE and the Kriging model are well-proportioned located in the area of importance to the accuracy of the estimate of failure probability, which makes the Kriging model efficiently improved and the Kriging-based estimate of failure probability convergent with calling to the performance function fewer times.
As the DoE of the Kriging model is refreshed by a few points each iteration, the proposed Isomap-Clustering strategy is able to remarkably reduce the iterative times of Kriging-based reliability analysis method. By employing parallel computing or distributed computing, the efficiency of structural reliability analysis with time-consuming performance function is surely enhanced.
According to the results of the second and third examples, the efficiency of Isomap-Clustering strategy is not sensitive to the number of the representative points (k in equation (22)) in the vicinity of the Kriging-based , which means that k could be determined mainly according to the parallelizability capacity.
The basic idea of the proposed strategy is to refresh the Kriging model with a few representative points in the vicinity of , and Isomap technique and k-means clustering algorithm are used to achieve the goal. Theoretically, the efficiency of the Isomap-Clustering strategy suffers no loss if generating more random candidates of the representative points. Besides, increasing the number of the initial DoE points apparently benefits the initial Kriging model as well as the iterative times of reliability analysis. Therefore, both values (K and N0) are not discussed in section “Conclusion.” Different Kriging-based methods are fairly compared with the same values of N0. The performance function of the third example is implicit, which often occurs in engineering. As numerical model of structures in engineering becomes more and more time-consuming, minimizing the number of calls to performance function and iterations directly reduce the time cost of reliability analysis. The success of the proposed method in the third example demonstrates its potential to engineering applications.
As Isomap is a wonderful method to map points on a hyperplane into lower dimension, the proposed Isomap-Clustering strategy may be not suitable for reliability analysis problems with more than one failure sub-domain.
Footnotes
Handling Editor: Yangmin Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is funded by the National Natural Science Foundation of China (Grant No. 51775097). The financial support is gratefully acknowledged.
ORCID iD
Yu Zhenliang
References
1.
ZhaoYGOnoT.A general procedure for first/second-order reliability method (FORM/SORM). Struct Saf1999; 21: 95–112.
2.
MorioJBalesdentMJacquemartDet al. A survey of rare event simulation methods for static input-output models. Simul Model Pract Th2014; 49: 287–304.
BucherCMostT.A comparison of approximate response functions in structural reliability analysis. Probabilist Eng Mech2008; 23: 154–163.
5.
GasparBTeixeiraAPSoaresCG.Assessment of the efficiency of Kriging surrogate models for structural reliability analysis. Probabilist Eng Mech2014; 37: 24–34.
6.
BaldeauxJPlatenE.Monte Carlo and Quasi-Monte Carlo methods. Berlin: Springer, 2013, pp.343–358.
7.
OrsakGCAazhangB.A class of optimum importance sampling strategies. Inform Sciences1995; 84: 139–160.
KoutsourelakisPSPradlwarterHJSchuëllerGI.Reliability of structures in high dimensions, part I: algorithms and applications. Probabilist Eng Mech2004; 19: 409–417.
10.
KoutsourelakisPS. Reliability of structures in high dimensions. Part II. Theoretical validation. Probabilist Eng Mech2004; 19: 419–423.
11.
AuSKBeckJL.Estimation of small failure probabilities in high dimensions by subset simulation. Probabilist Eng Mech2001; 16: 263–277.
12.
XiongFLiuYXiongYet al. A double weighted stochastic response surface method for reliability analysis. J Mech Sci Technol2012; 26: 2573–2580.
13.
GaytonNBourinetJMLemaireM.CQ2RS: a new statistical approach to the response surface method for reliability analysis. Struct Saf2003; 25: 99–121.
14.
AlibrandiUAlaniAMRicciardiG.A new sampling strategy for SVM-based response surface for structural reliability analysis. Probabilist Eng Mech2015; 41: 1–12.
15.
SchueremansLVan GemertD.Benefit of splines and neural networks in simulation based structural reliability analysis. Struct Saf2005; 27: 246–261.
16.
KaymazI.Application of Kriging method to structural reliability problems. Struct Saf2005; 27: 133–151.
17.
EchardBGaytonNLemaireM.AK-MCS: an active learning reliability method combining Kriging and Monte Carlo simulation. Struct Saf2011; 33: 145–154.
18.
LvZLuZWangP.A new learning function for Kriging and its applications to solve reliability problems in engineering. Comput Math Appl2015; 70: 1182–1197.
19.
TongCSunZZhaoQet al. A hybrid algorithm for reliability analysis combining Kriging and subset simulation importance sampling. J Mechl Sci Technol2015; 29: 3183–3193.
20.
JonesDRSchonlauMWelchWJ.Efficient global optimization of expensive black-box functions. J Glob Optim1998; 13: 455–492.
21.
BichonBJEldredMSMahadevanSet al. Efficient global surrogate modeling for reliability-based design optimization. J Mech Design2013; 135: 011009.
22.
KersaudyPSudretBVarsierNet al. A new surrogate modeling technique combining Kriging and polynomial chaos expansions—application to uncertainty analysis in computational dosimetry. J Comput Phys2015; 286: 103–117.
23.
NechakLGillotFBessetSet al. Sensitivity analysis and Kriging based models for robust stability analysis of brake systems. Mech Res Commun2015; 69: 136–145.
24.
BichonBJEldredMSSwilerLPet al. Efficient global reliability analysis for nonlinear implicit performance functions. AIAA J2008; 46: 2459–2468.
25.
EchardBGaytonNLemaireMet al. A combined importance sampling and Kriging reliability method for small failure probabilities with time-demanding numerical models. Reliab Eng Syst Safe2013; 111: 232–240.
26.
HuangXChenJZhuH.Assessing small failure probabilities by AK-SS: an active learning method combining Kriging and subset simulation. Struct Saf2016; 59: 86–95.
27.
YangXLiuYGaoYet al. An active learning Kriging model for hybrid reliability analysis with both random and interval variables. Struct Multidiscip O2015; 51: 1003–1016.
28.
YangXLiuYZhangYet al. Probability and convex set hybrid reliability analysis based on active learning Kriging model. Appl Math Model2015; 39: 3954–3971.
29.
YangXLiuYZhangYet al. Hybrid reliability analysis with both random and probability-box variables. Acta Mech2015; 226: 1341–1357.
30.
SunZWangJLiRet al. LIF: a new Kriging based learning function and its application to structural reliability analysis. Reliab Eng Syst Safe2017; 157: 152–165.
31.
MatheronG.The intrinsic random functions and their applications. Adv Appl Probab1973; 5: 439–468.
32.
EfronBHastieTJohnstoneIet al. Least angle regression. Ann Stat2004; 32: 407–499.
33.
RoussoulyNPetitjeanFSalaunMet al. A new adaptive response surface method for reliability analysis. Probabilist Eng Mech2013; 32: 103–115.
34.
LiJWangHKimNH.Doubly weighted moving least squares and its application to structural reliability analysis. Struct Multidiscip O2012; 46: 69–82.
35.
BlatmanGSudretB.An adaptive algorithm to build up sparse polynomial chaos expansions for stochastic finite element analysis. Probabilist Eng Mech2010; 25: 183–197.