
Abstract
Case adaptation is crucial for a good and reasonable case-based design which is a common method in computer-aided design, because the solution of old case is not always the exact answer for the encountered new designing problem. Recently, a statistical feature-oriented adaptation method in the principle of k-nearest neighbors has been employed widely in case-based design because of its easily understandable mechanism for designers, but its adaptation accuracy is relatively low compared with knowledge-intensive method. This article presents a new method by integrating with multiple adaptation values from statistical feature-oriented adaptation methods to improve the adaptation accuracy. First, two simple statistical feature-oriented adaptation methods including mean and median approaches and other four statistical feature-oriented adaptation methods based on Euclidean distance, Manhattan distance, Gaussian transformation, and gray coefficient are used as individual statistical feature-oriented adaptation mode in this article, and each statistical feature-oriented adaptation method generates pre-adapting value under k-nearest neighbor. Then, support vector regression is utilized to make a combined adaptation which takes pre-adapting values as its inputs, and the new multiple statistical feature-oriented adaptation method integration based on support vector regression is named as MSFA-SVR. Furthermore, to validate the feasibility and superiority of MSFA-SVR, it was applied to the power transformer design and was compared with the classical statistical feature-oriented adaptation methods. Empirical comparison results indicated that MSFA-SVR achieves the better adaptation performance under k-nearest neighbor than other statistical feature-oriented adaptation methods in terms of adaptation accuracy.
Keywords
Introduction
Supporting the design of new mechanical product by recalling past experiences and adapting them to the current design requirement is the long cherished desire of designers, as designers rely heavily on past design experiences in actual design, rather than designing everything from scratch. 1 This kind of approach is known as case-based design (CBD), 2 derived from the methodology of case-based reasoning (CBR). The concept of CBD focuses on the general idea of retaining a memory of previous design requirements and their solutions. It solves new problems by analogical reasoning on such retained information, 3 and the term ‘case’ captures representation of a previous problem-solving situation. However, real-world problems are dynamic and uncertain processes where idealistic modeling assumptions are rarely met. Accordingly, CBD has three challenging issues: (1) organization of case base, (2) case-retrieval technique, and (3) adaptation of past solutions to the current problem. Among these, the case adaptation has a significant effect on the success of CBD that plays a fundamental role in problem solving, because the solution in the retrieved case is not always appropriate for the encountered designing problem. However, most of the classic CBD systems are retrieval-only systems or act primarily as retrieval and reuse systems.4,5 They merely perform adaptation process in the principle of 1-nearest neighbor (1-NN), namely, the solution of most similar case is the only candidate for new design problem, and the generation of new solution values heavily depends on human subjective judgement. 5 So, how to perform adaptation by reference to k similar cases without having to excessively rely on manual adaptation still remains as challenging obstacles to the CBD system.
To search for more accurate adaptation performance under k-NN, researchers of CBD in 1990s or so began to employ statistical feature-oriented adaptation (SFA) methods such as the closest analogy, 6 the equal mean (EM), 7 the median, 8 and weighted mean (WM). 9 Nowadays, they are also regarded as the baseline modes, whose advantages are the domain independence and easily to be implemented, but a potential drawback of CBD based on statistical adaptation is its low adaptation precision.2,10,11 Moreover, the development of CBD-based intelligent techniques and soft computing has led mainly to two types of researches. One is intelligent feature-oriented adaptation (IFA) based on various machine learning models; the other is hybridization of intelligent techniques with statistical adaptation methods. Typical approaches for the first case are gene adaptation12–17 and neuroadaptation.18–22 For the second case, Huang et al. 13 and Qi et al. 23 introduced the adjusting parameters in statistical adaptation models and used genetic algorithm and decision tree, respectively, to obtain the optimized adjusting parameters. Our previous work 24 also adopted gray relational analysis to explore the hidden relational information in statistical adaptation model.
In fact, there is a belief in the area of computational intelligence that combining-modes system tends to minimize the disadvantages of single modes and maximize their advantages. 25 This idea has already been applied into the area of financial analysis, 26 housing value estimation, 10 cost prediction, 27 and process determination28,29 with satisfying results. Enlightened by these, this study presents a new methodology to improve the performance of SFA for case-based mechanical design, namely, integrating multiple adaptation results provided by independent statistical adaptation methods to the combined solution. Support vector regression (SVR), developed by Vapnik,30,31 is utilized as a combiner to hybridize the results from different individual adaptation methods because of SVR’s good performance in combining scheme. 32 The contribution of this study is to take the advantages of SFA’s characteristics of easily being calculated and SVR’s characteristics of high generalization and propose a new multiple SFA integration based on SVR (MSFA-SVR) method, which is different from classical SFA and IFA studies. Furthermore, this research also investigates whether or not the proposed hybrid SFA adaptation method can produce higher performance than single SFA method. The next section gives a description on literature review of adaptation studies. Afterwards, the proposed MSFA-SVR method is discussed in detail in section “Specification on proposed method.” In section “Empirical comparison and discussion,” the empirical results are analyzed and discussed. Section “Conclusion” presents conclusion.
Research background
This section provides a brief introduction to the case adaptation in CBD, especially the statistical case adaptation. Several classical SFA methods are introduced in detail.
Case adaptation in CBD
When CBD systems are applied to real-world design problems, the retrieved design solutions can rarely be directly used as suitable solutions for a new problem. Retrieved solutions usually require a set of adaptations in order to be applied to new contexts. An adaptation can be considered as a situation/action pair. The situation contains the differences between the new and retrieved design requirements. The action captures the update for the retrieved design solution: solution components to be added, deleted, or changed 33 or new feature values for the reused solution. 21 Accordingly, the case adaptation in CBD can be divided into two categories: component-oriented adaptation and feature-oriented adaptation. In early implementation of CBD, the most widely used form of adaptation strategy employs hand-coded adaptation rules, which demands a significant effort of knowledge acquisition for case adaptation.15,34 When a new problem is presented to CBD system, it retrieves a similar case and sends it to the adaptation engine. The engine, in turn, selects an adaptation rule and starts a search in the memory for components able to substitute parts of the retrieved solution or for features able to modify values of the retrieved solution.
In this study, we focus on the feature-oriented adaptation in case-based mechanical design, as the parametric design is a common way for mechanical companies to rapidly develop new mechanical products within a short period of time, 35 and designers are able to make a comparatively reasonable decision by inputting some easy-to-assess parameters into the parametric design system. However, the parametric design is a complex problem when there are massive parameters in the process of design, and the utilization of classical rule-based adaptation method in this situation demands a significant knowledge engineering effort to capture abundant adaptation rules. This prompted some studies to research machine learning–based adaptation under k-NN principle, and several learning methods have been employed in this area, for example, neural networks,19–22,36,37 SVR, 38 genetic algorithm,12,14–16 and partial-order planning. 39 But insufficient knowledge badly affects the selection of an appropriate machine learning algorithm and its performance in feature-oriented adaptation.
An alternative to overcome these limitations in insufficient adaptation knowledge has been the use of a domain-independent statistical adaptation approach. So far, it has been employed widely in CBD system without considering the insufficient knowledge problem.13,23,24 But, statistical adaptation deriving from techniques employed in standalone mode has been proven to be low adaptation accuracy compared with machine learning–based adaptation. 23 As a combining mode system tends to minimize the disadvantages of single mode and maximize their advantages, it is worthwhile to combine several statistical adaptation results together to obtain the combined solution, such as the issue we intent to highlight and research in this article.
Statistical case adaptation research
The early algorithm of statistical adaptation used in the 90s is the mean method6,7 and the median method.
8
Mean method is the average of the feature values of k-nearest neighbors (k-NNs), where k > 1. It is a classical measure of central tendency and treats all design cases as being equally influential on the feature-oriented adaptation. Median is the median of the feature values of k-NNs, where k > 2. It is another measure of central tendency and a more robust statistic when the number of cases increases. After that, an inverse distance weighted mean (IDWM) framework was developed, which allows more similar cases to have more influence than less similar ones. Suppose that there are k design cases retrieved from case base, and the hth (h ≤ k) case consists of design requirement part

where

where
Specification on proposed method
This section makes specification on MSFA-SVR method. First, the framework of MSFA-SVR is illustrated. Then, the SVR for SFA integration is formulated in detail. Finally, an application example is given to show the feasibility of MSFA-SVR.
Framework of MSFA-SVR
The proposed adaptation integration is an approach to combine the adaptation results of different SFA methods to generate a joint adaptation, which is accomplished through the use of SVR. The new method is named as multiple statistical adaptation integration based on SVR (abbreviated as MSA-SVR). In MSFA-SVR, all the single SFA method are employed to solve the same adaptation task, and this article utilizes mean,
7
median,
8
Euclidean distance,
23
Manhattan distance,
40
Gaussian function,
25
and gray coefficient degree
25
to construct the six single SFA models, expressed as SFA-MA, SFA-ME, SFA-ED, SFA-MD, SFA-GF, and SFA-GC, respectively. Each SFA can generate pre-adapting values under k-NN, and then, these values are treated as inputs of SVR to make a secondary adaptation. The framework of MSFA-SVR is shown in Figure 1, where
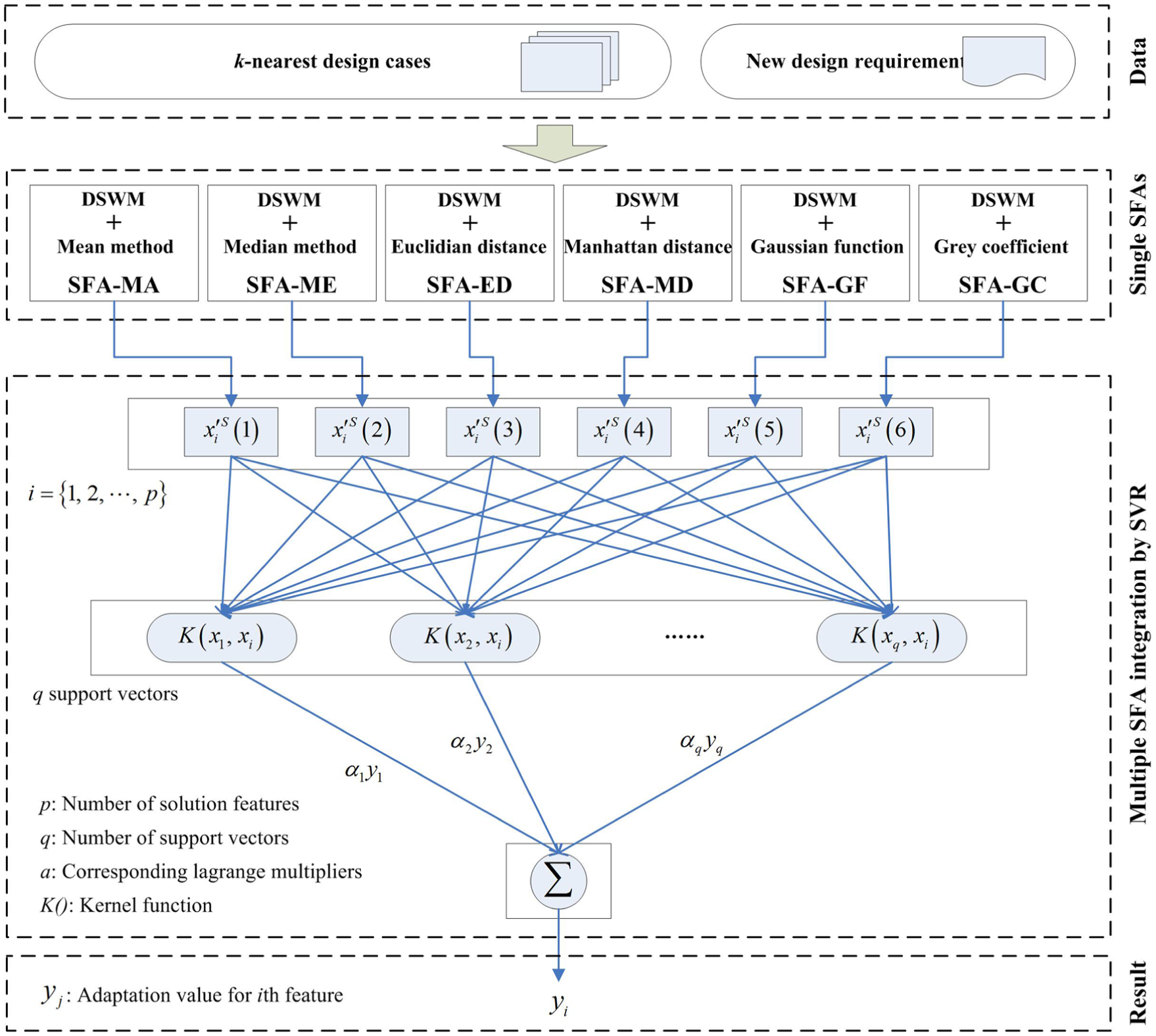
Framework of the proposed MSFA-SVR.
Pre-adaptation results’ integration
The statistical adaptation methods are introduced in this section. The training sample of SVR and the mechanism of SVR for statistical adaptation integration are presented as well.
Independent statistic adaptation
As shown in Figure 1, this article puts forward independent SFA-MA, SFA-ME, SFA-ED, SFA-MD, SFA-GF, and SFA-GC to make pre-adaptation with k retrieved cases. Among them, SFA-ED, SFA-MD, SFA-GF, and SFA-GC adopt DSWM framework as shown in equation (2), but they use different similarity measurement metrics which are expressed in Table 1. In Table 1, g is the number of problem features of each case. For SFA-GF,
Mechanisms of six statistical adaptation modes.

SFA: statistical feature-oriented adaptation method; ED: Euclidean distance; MD: Manhattan distance; GF: Gaussian function; GC: gray coefficient degree; DSWM: direct similarity weighted mean.
Construction of training sample in SVR
After SFAs are implemented successfully, it is possible to utilize SVR to combine the six SFA modes. Pre-adaptations of independent SFAs for each solution feature could be treated as inputs of SVR, and the final adaptation result of the solution feature for new design requirement could be viewed as outputs of SVR. Thus, the new training sample set of the supervised learning of SVR is formed, and outputs of six independent SFAs are transformed as inputs of SVR through min–max normalization process. The mathematic formula is expressed as

where
Mechanism of SVR for adaptation integration
The basic idea of SVR for SFA integration is to map the pre-adapting values into a higher dimensional space via a nonlinear mapping and then to do linear regression in this space with the unknown function in the following form:


The first term
To obtain the estimation of

Finally, by introducing the Lagrange multipliers and exploiting the optimality constraints, the decision function

In equation (7),

with the following constraints

Based on the Karush–Kuhn–Tucker (KKT) conditions of the quadratic programming, only a number of coefficients
Implementation of MSFA-SVR
An application example of MSFA-SVR is presented in this section to illustrate the procedure of hybrid statistical adaptation.
Application example
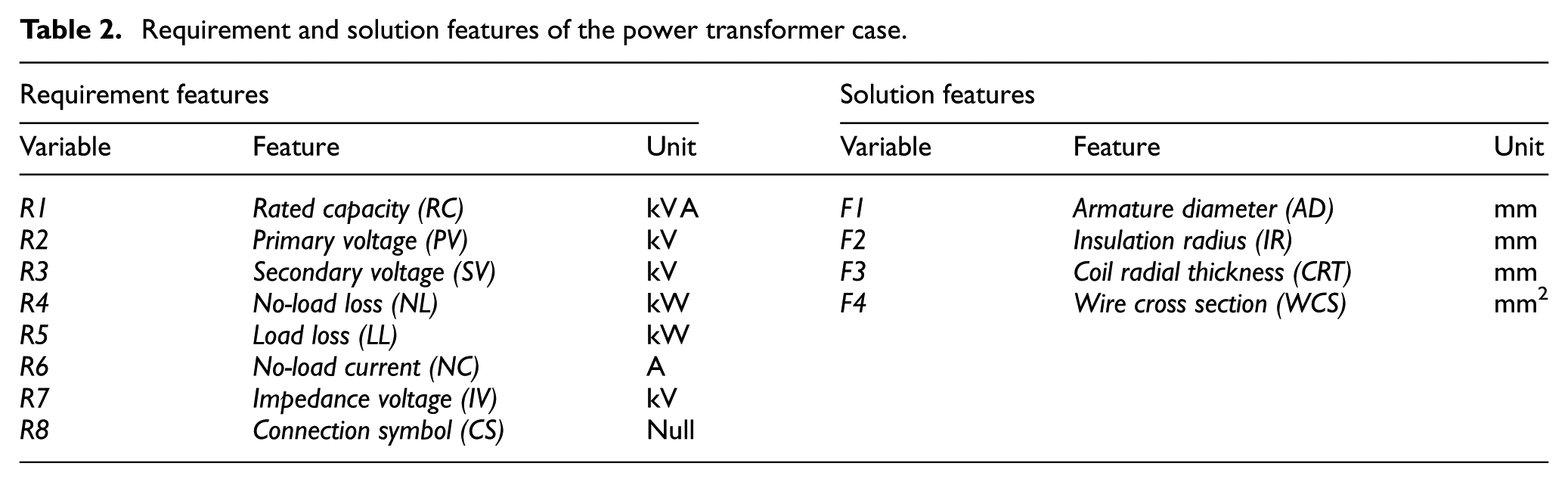
In this study, a total of 55 power transformer cases from S1, S2, S3, and S4 series with eight requirement features (R1–R8) and four solution features (F1–F4) are selected to construct MSFA-SVR model as listed in Table 2 and Appendix 1 (Table 10). Actually, how to determine the representative features of design cases and remove irrelevant ones is an important issue during the real SFA process. Feature selection (FS) technique is crucial for large-sized design case in SFA to strengthen the adaptation efficiency and accuracy by eliminating redundant features. Recently, many related data-driven FS methods have been proposed. Chakraborty and Pal 44 utilized neural networks to conduct two connectionist FS schemes that able to simultaneously select the useful features and learn the relationships between input and output features. Che et al. 45 presented a novel mutual information FS method based on the normalization of the maximum relevance and minimum common redundancy (N-MRMCR-MI) which shows superior performance by comparing with other state-of-art FS algorithms. Our previous studies46,47 also tried to use neighborhood rough set algorithm to obtain the minimal set of features and extracted the hidden relationships between problem and solution features of design cases. In this example, to simplify this implementation, we select small-size power transformer case (R1–R8 problem features and F1–F4 solution features) without applying FS method. Among R1–R8, R8 (connection symbol (CS)) belongs to non-numerical feature, so 0–1 textual similarity measure metric 48 is applied to figure the similarity, that is, 1 means two symbolic values are same, otherwise 0. For other numerical features (R1–R7 and F1–F4), min–max normalization is applied to scale all data into the range of [0,1], which helps SFA and SVR to improve the calculation performance. The formula of min–max normalization is given by equation (3). We implement the proposed method using support vector machine (SVM) toolbox available in MATLAB R2008b environment.
Requirement and solution features of the power transformer case.
SVR model construction
Inspired by the empirical findings,49–51 radial basis kernel
Results of SVR parameters via grid search and 10-fold cross-validation.
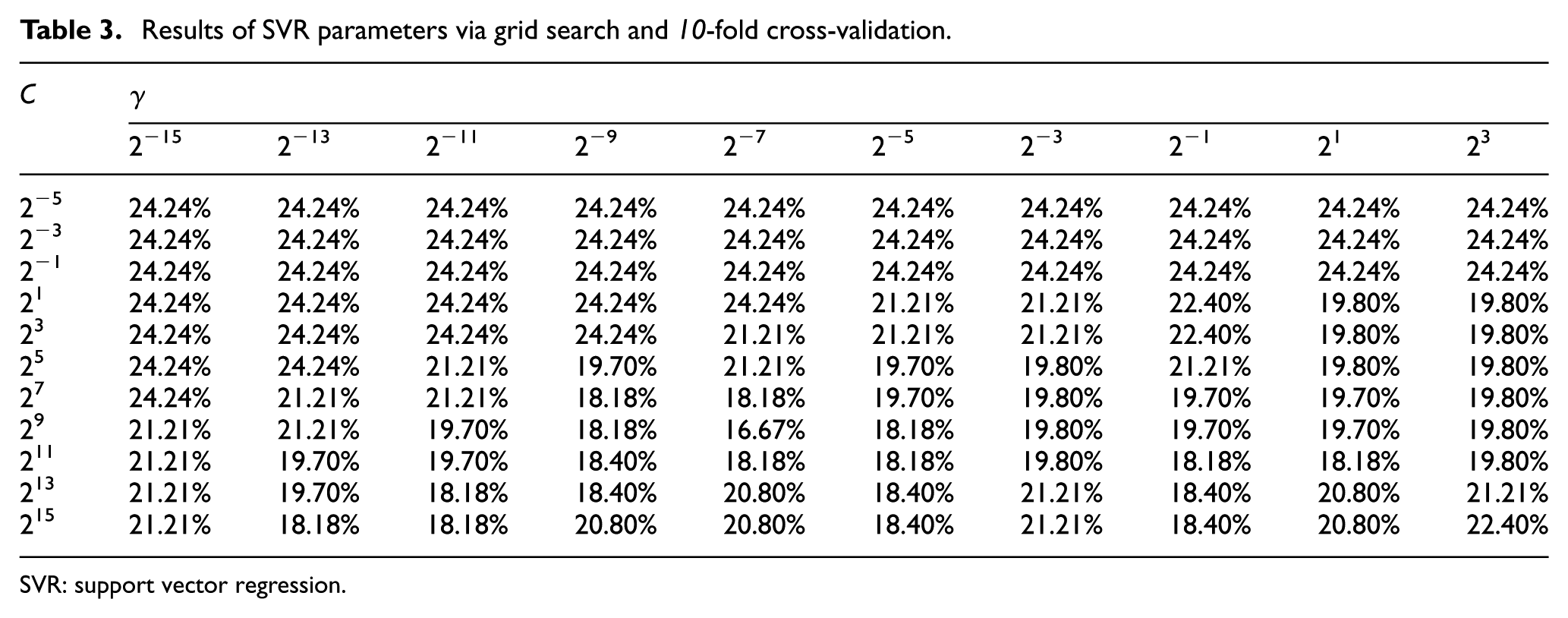
SVR: support vector regression.
SFA results integration
According to Table 2, the initial solution feature values can be figured out using SFA-MA, SFA-ME, SFA-ED, SFA-MD, SFA-GF, and SFA-GC, as shown in Table 7. Then, the adaptive results of each independent SFAs are also considered as inputs of SVR (represented as X_AD, X_IR, X_CRT, X_WCS) under the framework of MSFA-SVR. After that, in terms of the ready-built SVR model and the handbook of power transformer design, the solution feature values for the new design requirement can be obtained. For simplicity, this study implements MSFA-SVR under 5-NN and employs ED metric to select the similar cases. The results of application example including the new design requirements for R1–R8 features, five design cases with highest similarities, feature adaptation results of SFAs and final adaptation values produced by MSFA-SVR are listed in Appendix 2.
Empirical comparison and discussion
This section focuses on the comparison of adaptation ability of the examined methods in terms of adaptation accuracy. Some discussions are presented based on empirical results, considering different k-NNs.
Objective and comparative methods
The objective of this empirical comparison is to compare the adaptation abilities of the proposed method and other SFA methods. The experimental design is shown in Figure 2.
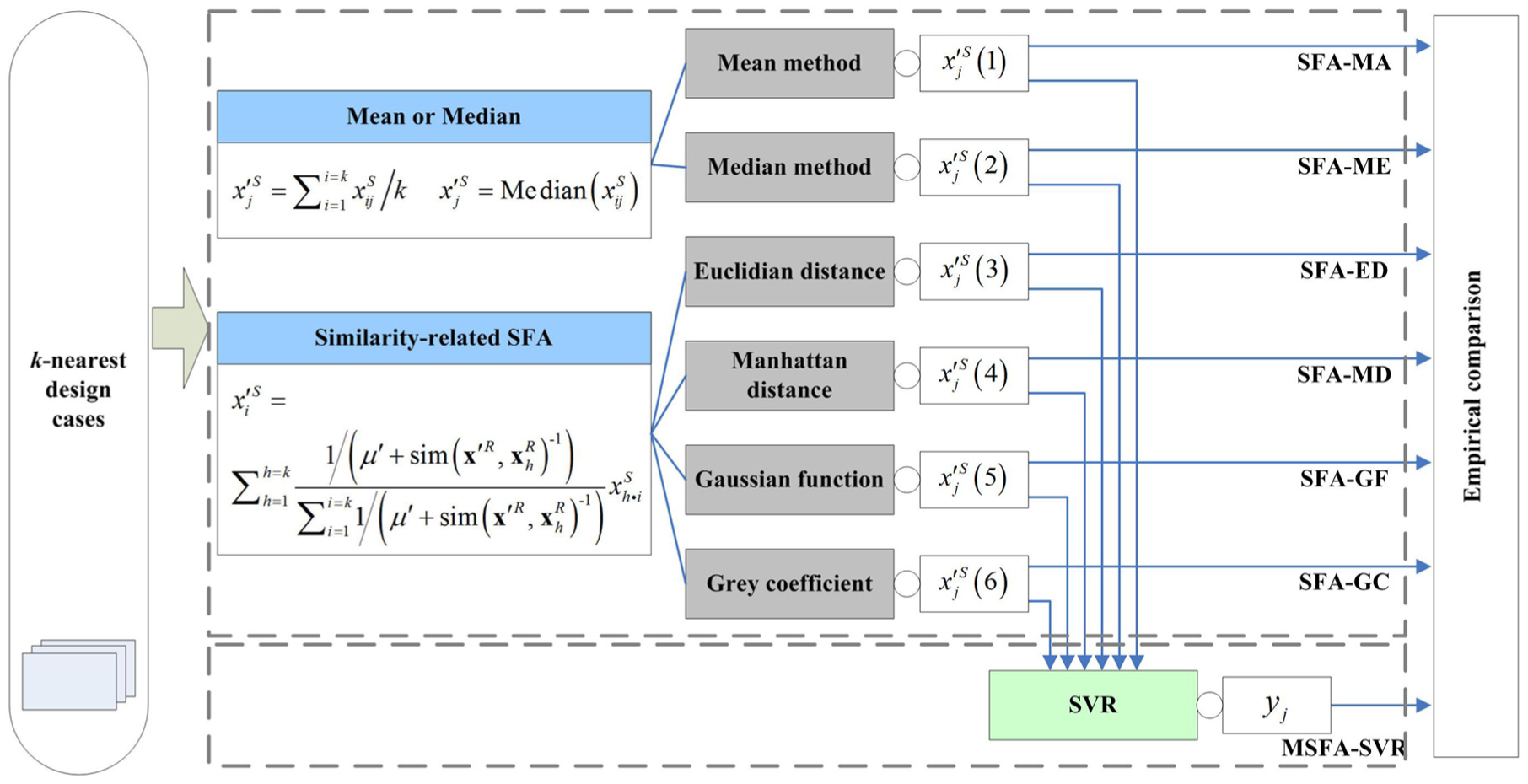
Experimental design.
Two types of classic SFAs, namely, simple SFA (i.e. SFA-MA and SFA-ME) and similarity-related SFA (i.e. SFA-ED, SFA-MD, SFA-GF, and SFA-GC), are employed as comparative methods to perform the empirical comparison. Furthermore, we would like to investigate the performances of MSFA-SVR under different numbers of design cases. Therefore, the adaptation performance of MSFA-SVR would not only be compared with its opponents but also be compared inside MSFA-SVR under 1-NN, 3-NN, 5-NN, 7-NN, 9-NN, and 11-NN.
Testing data and evaluation
In addition to the 55 cases mentioned above, other 30 power transformer cases are applied to compose testing data listed in Appendix 1 (Table 11). So, there are three types of data employed in the empirical comparison of MSFA-SVR, that is, training data, validating data, and testing data. Training data are used to train SFAs, validating data are used to determine the parameters of SFAs, while testing data are used as unseen data, and leave-one-out cross-validation is utilized to assess the performances of adaptation. Every time one case was selected from testing data in order as a testing case, the requirement feature values of testing case were considered as the new requirement problem and its corresponding solution feature values were used to compare with the adaptation results produced by adaptive modes. So, there were 30 empirical results in this empirical comparison. To compare the performances, this article employed the MAPE 38 and the root mean square error (RMSE) 53 as measurements of derivation between actual and adapted values. Compared with mean absolute error, MAPE can be utilized to measure the relative error (0–1) of adaptation computation by normalizing the error calculation. RMSE displays the variance of predicted adaptation for candidate adaptation methods in terms of millimeter. They are formulated as
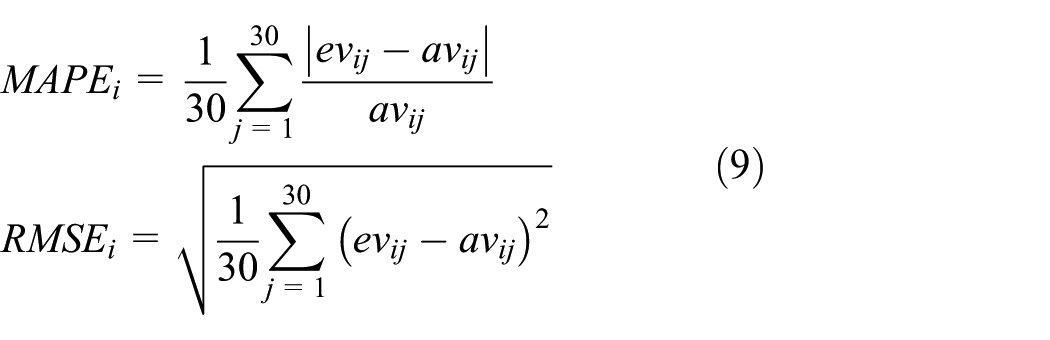
where
Results
First, to compare the adaptive performances of MSFA-SVR, SFA-MA, SFA-ME, SFA-ED, SFA-MD, SFA-GF, and SFA-GC, the MAPE and RMSE values of such adaptation methods under 1-NN, 3-NN, 5-NN, 7-NN, 9-NN, and 11-NN for four solution features (AD, IR, CRT, and WCS) adaptation are listed in Tables 4–7. Second, to abstract the changes of performances of MSFA-SVR with different k values, the adapted solution values for testing case generated by MSFA-SVR in 30 times leave-one-out cross-validation and the corresponding real values of testing case are depicted in Figures 3–6. Furthermore, to determine the statistical differences of performance measures among seven adaptation methods for each k-NN principle and solution feature adaptation, we carried out the ANOVA and Tukey’s HSD tests, and the corresponding results are described in Tables 8 and 9. In Table 9, we rank the seven methods from 1 (the best) to 7 (the worst) to show the comparison results more clearly.
MAPE and RMSE values of seven adaptation methods under different k-NNs for AD adaptation.
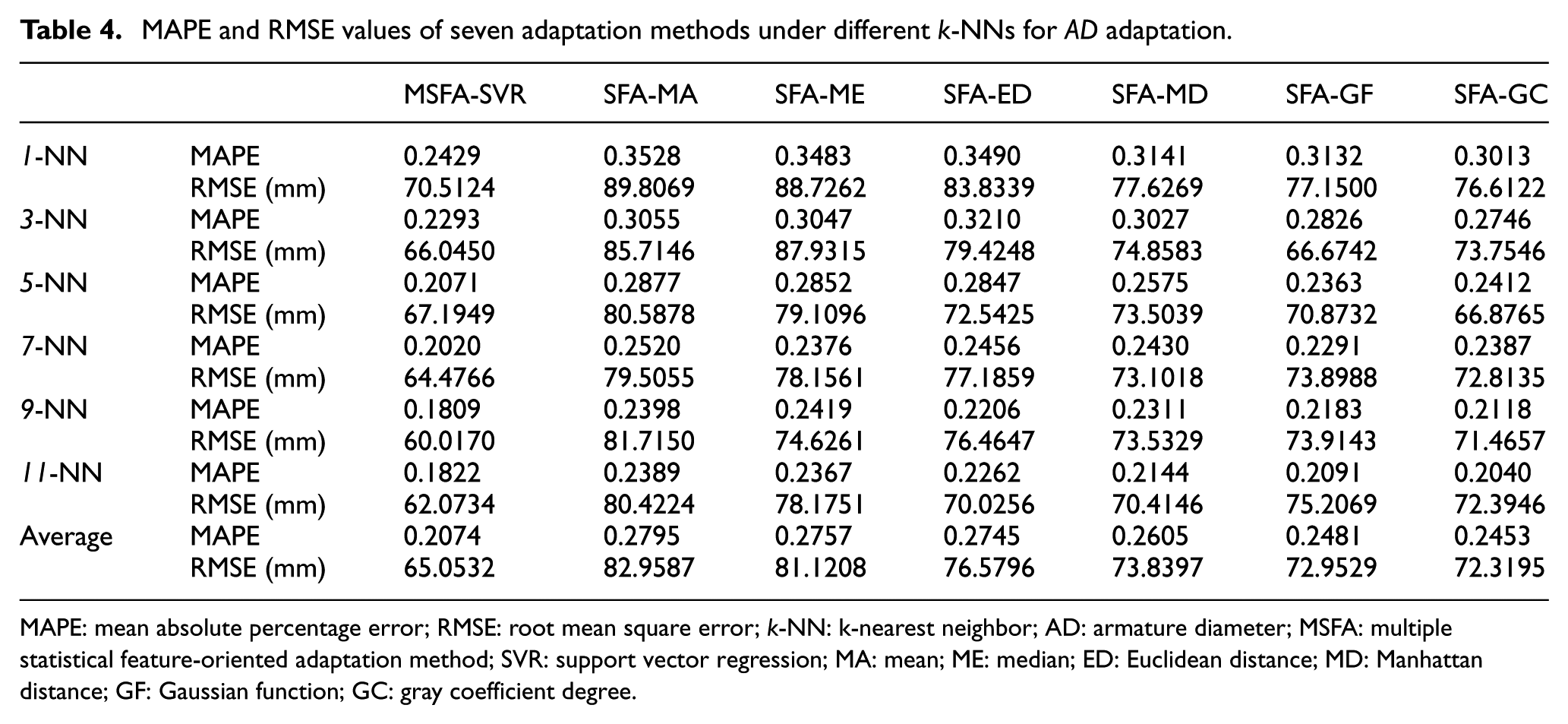
MAPE: mean absolute percentage error; RMSE: root mean square error; k-NN: k-nearest neighbor; AD: armature diameter; MSFA: multiple statistical feature-oriented adaptation method; SVR: support vector regression; MA: mean; ME: median; ED: Euclidean distance; MD: Manhattan distance; GF: Gaussian function; GC: gray coefficient degree.
MAPE and RMSE values of seven adaptation methods under different k-NNs for IR adaptation.

MAPE: mean absolute percentage error; RMSE: root mean square error; k-NN: k-nearest neighbor; AD: armature diameter; MSFA: multiple statistical feature-oriented adaptation method; SVR: support vector regression; MA: mean; ME: median; ED: Euclidean distance; MD: Manhattan distance; GF: Gaussian function; GC: gray coefficient degree; IR: insulation radius.
MAPE and RMSE values of seven adaptation methods under different k-NNs for CRT adaptation.
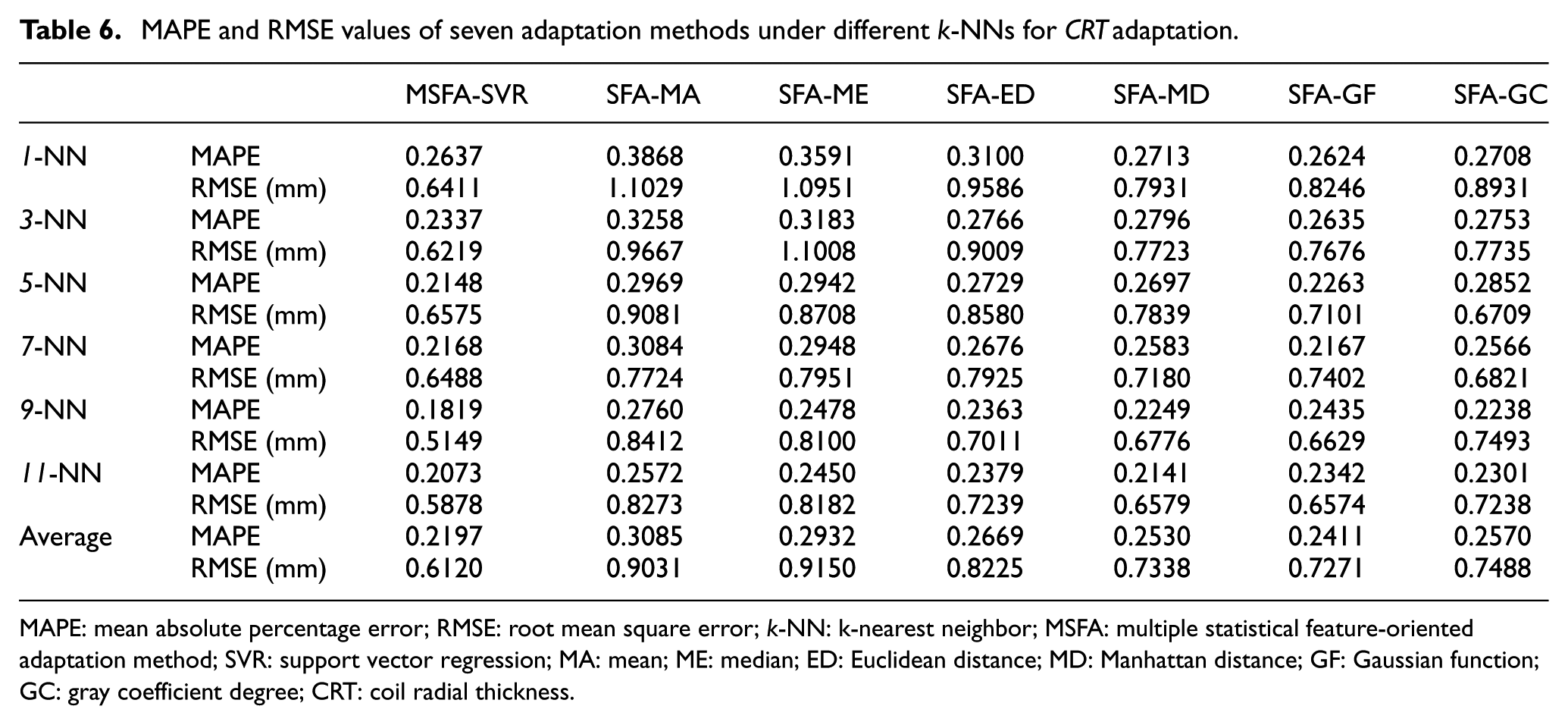
MAPE: mean absolute percentage error; RMSE: root mean square error; k-NN: k-nearest neighbor; MSFA: multiple statistical feature-oriented adaptation method; SVR: support vector regression; MA: mean; ME: median; ED: Euclidean distance; MD: Manhattan distance; GF: Gaussian function; GC: gray coefficient degree; CRT: coil radial thickness.
MAPE and RMSE values of seven adaptation methods under different k-NNs for WCS adaptation.

MAPE: mean absolute percentage error; RMSE: root mean square error; k-NN: k-nearest neighbor; MSFA: multiple statistical feature-oriented adaptation method; SVR: support vector regression; MA: mean; ME: median; ED: Euclidean distance; MD: Manhattan distance; GF: Gaussian function; GC: gray coefficient degree; WCS: wire cross section.
ANOVA test results for hold-out sample.

k-NN: k-nearest neighbor; ANOVA: analysis of variance; AD: armature diameter; IR: insulation radius; CRT: coil radial thickness; WCS: wire cross section.
The mean difference among the six adaptation methods is significance at the 0.05 level.
Comparison results with ranked comparative methods for hold-out sample.

AD: armature diameter; MSFA: multiple statistical feature-oriented adaptation method; SVR: support vector regression; MA: mean; ME: median; ED: Euclidean distance; MD: Manhattan distance; GF: Gaussian function; GC: gray coefficient degree; NN: nearest neighbor; SFA: statistical feature-oriented adaptation method; IR: insulation radius; CRT: coil radial thickness; WCS: wire cross section.
The mean difference among the six adaptation methods is significance at the 0.05 level.

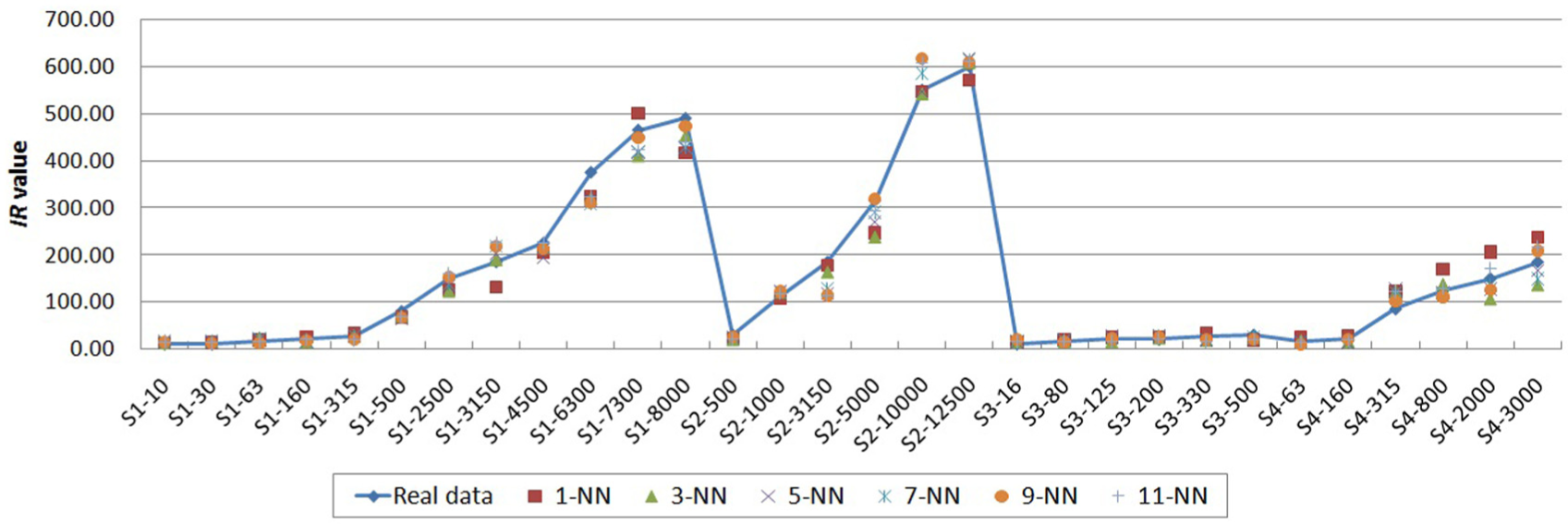
The adapted AD values and real values of testing case generated by MSFA-SVR in 30 times leave-one-out.
The adapted IR values and real values of testing case generated by MSFA-SVR in 30 times leave-one-out.
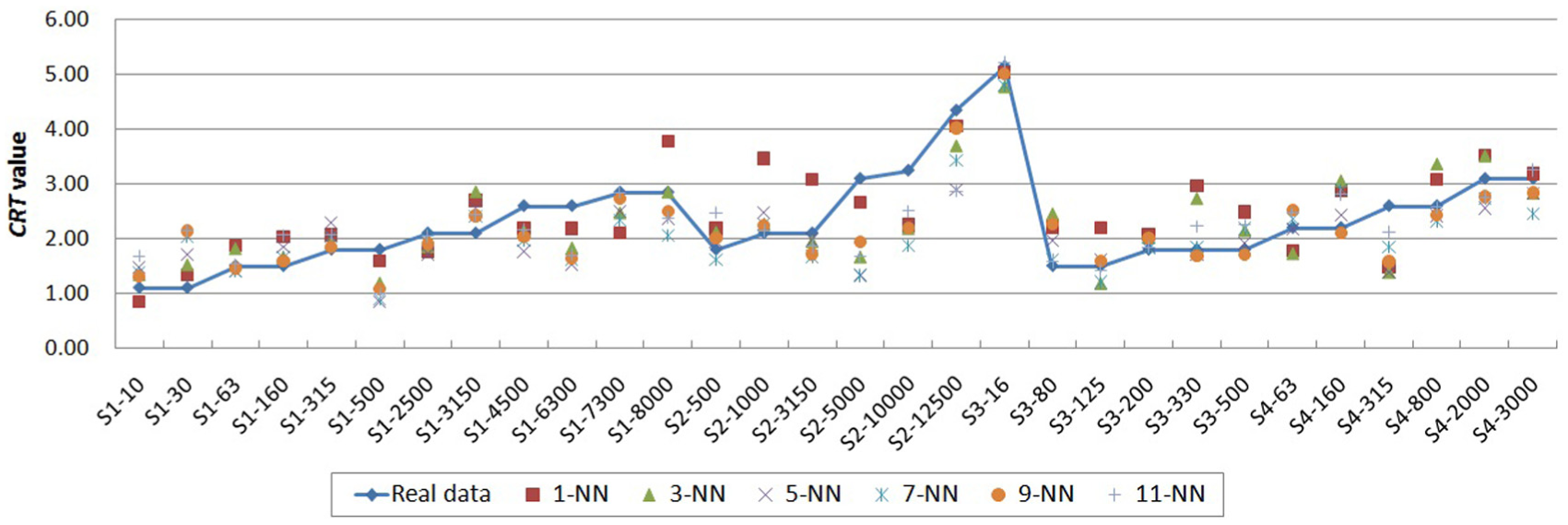
The adapted CRT values and real values of testing case generated by MSFA-SVR in 30 times leave-one-out.

The adapted WCS values and real values of testing case generated by MSFA-SVR in 30 times leave-one-out.
Discussion
This section analyzes the comparative results from three perspectives, including comparison between MSFA-SVR and other SFAs, comparison inside MSFA-SVR, and comparison of adaptation difference.
Comparison between MSFA-SVR and other SFAs
Tables 4–7 show the MAPE and RMSE values of four solution feature (AD, IR, CRT, and WCS) adaptation achieved by MSFA-SVR, SFA-MA, SFA-ME, SFA-ED, SFA-MD, SFA-GF, and SFA-GC with different k-NNs. Taking the average MAPE and RMSE indices of all k-NNs into account, MSFA-SVR achieves better adaptation performance than other SFA methods, because of its relative lower average MAPE and RMSE values of four solution feature adaptation. Among classical SFAs methods, SFA-GF marginally outperforms SFA-GC and SFA-MD and significantly outperforms SFA-ED, SFA-ME, and SFA-MA. This means that the performances of similarity-related SFAs (SFA-ED, SFA-MD, SFA-GF, and SFA-GC) are better than those of simple SFA (SFA-ED and SFA-MD). However, the minor differences of adaptation performance among SFA-MD, SFA-GF, and SFA-GC demonstrate that the improvement of adaptation performance is insignificant only changing the similarity measurement metrics. So, it is a meaningful attempt to probe into new adaptation model from the point of view of SFA integration, as this article has done. However, the larger MAPE and RMSE values of comparative methods under 1-NN, 3-NN, and 5-NN indicate that there are several noises and uncertainties, so it is necessary to select more training cases and data pre-processing to help the statistical adaptation methods improve the adaptation performance. Furthermore, for MSFA-SVR, as it contains several similarity measurement metrics and SVR algorithms, which results in having more parameters than other SFAs, we also need additional example data to optimize these parameters to improve the stability of MSFA-SVR results.
Comparison inside MSFA-SVR with various k-NN
Figures 3-6 show the adapted solution values generated by MSFA-SVR under various k-NNs and the corresponding real values of test cases. As mentioned above, in each time of leave-one-out cross-validation, the requirement feature values of one testing case were considered as the new requirement problem and its corresponding solution feature values were used to compare with the adaptation results produced by adaptive modes. From Figures 3 to 6, we can find that MSFA-SVR under 1-NN achieves the lowest adaptive performance among all MSFA-SVR models. This phenomenon provides some evidences on the assumption that adaptation performance of 1-NN is sensitive to noise and is not robust, because only the most similar case is selected to generate the adapted value. In general, the MSFA-SVR with larger k could produce more accurate adapted results which are much closer to the real data, as shown the adapted values of MSFA-SVR under 1-NN, 3-NN, 5-NN, 7-NN, and 9-NN. However, when k is larger than 10, several irrelevant cases with related lower similarities could also be selected, which result in the fluctuations of adaptive performances. For example, MSFA-SVR under 11-NN generates large deviation data when S3-200 is test case in Figure 3, S3-330 is test case in Figure 4, S2-500 is test case in Figure 5, and S2-10000 is test case in Figure 6. Moreover, the MAPE and RMSE values of MSFA-SVR under 11-NN in four solution adaptation experiments, that is, (0.1822, 62.0734 mm, AD adaptation), (0.1997, 26.7316 mm, IR adaptation), (0.2073, 0.5878 mm, CRT adaptation) and (0.2129, 7.3986 mm, WCS adaptation), are also larger than those of MSFA-SVR under 9-NN, that is, (0.1809, 60.0170 mm, AD adaptation), (0.1870, 24.2353 mm, IR adaptation), (0.1819, 0.5149 mm, CRT adaptation) and (0.1838, 6.1268 mm, WCS adaptation), as listed in Tables 9–12. In a word, considering the MAPE and RMSE indices, the suitable value of k for MSFA-SVR is 9.
Comparison of adaptation difference
Beside MAPE and RMSE indices, we also performed an ANOVA procedure to determine whether the statistically significant differences exist among the seven comparative methods under each k-NN principle in the hold-out sample. All of the ANOVA results listed in Table 8 are significant at the 0.05 level, suggesting that there are significant differences among all comparative methods. To further identify the significant difference between any two methods, Tukey’s HSD test was used to compare all pairwise differences simultaneously at the 0.05 level in this comparison. Table 9 summarizes the results of Tukey’s HSD test, from which we can find that when MSFA-SVR in all four feature adaptation experiments is treated as the testing target, the mean difference between the two adjacent methods are significant at the 0.05 level (with the exception of the 1-NN and 5-NN in IR adaptation; 1-NN, 5-NN, and 7-NN in CRT adaptation and 11-NN in WCS adaptation), indicating that the MSFA-SVR performs the best in most adaptation tasks. Table 9 also shows that simple SFA methods (SFA-ME and SFA-MA) achieve the poor performances at a 95% statistical confident level, which explains the relative low performance of simple statistical case adaptation.
Conclusion
To improve the adaptation performances of classic SFAs, this article presents a hybrid adaptation method called as MSFA-SVR. In MSFA-SVR, six SFAs generate pre-adapting values under k-NN principle, and these values are further integrated by SVR to make a combined adaptation. To describe the possibilities of the methodology, the proposed method is applied to power transformer design. Moreover, the empirical comparisons are carried out to validate the superiority of MSFA-SVR. From the view of design example and comparison test, we can draw the conclusion that MSFA-SVR achieves the better performance compared with classical single SFAs. In future, we try to upgrade the proposed hybrid adaptation method from the following aspects. First, this study mainly concerns the comparison between MSFA-SVR and classical statistic adaptation methods. We will make more comparisons on adaptation performances between MSFA-SVR and other IFA methods based on pure SVR, neural networks, genetic algorithm, and so on. Besides adaptation accuracy, the computational cost will be another criterion for comparison between MSFA-SVR and IFA methods. Second, as the parameter configuration could influence the performance of MSFA-SVR, we will try to introduce new optimization methods such as artificial immune algorithm,
56
simulated annealing,
57
and firefly algorithm54,58 into MSFA-SVR to determine the
Footnotes
Appendix 1.
Appendix 2
Handling Editor: Ismet Baran
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the National Natural Science Foundation of China (No. 51675329, 51605302) and National Key R&D Program of China (No. 2016YFF0101602, 2016YFC0104104).