
Abstract
Using historical cases’ solutions to obtain feasible solution for new problem is fundamentally to successfully applying case-based reason technique in parametric mechanical design. As a well-known intelligent algorithm, the formulation of support vector regression has been taken for case-based reason adaptation, but the standard support vector regression can only be used as a univariate adaptation method because of its single-output structure, which would result in the ignorance of the possible interrelations among solution outputs. To handle the complicated case adaptation task with large number of problem inputs and solution outputs more efficiently, this study investigates the possibility of multivariable case-based reason adaptation with multiple output by applying multiple-output support vector regression. Furthermore, inspired by the fact that training sample which contains two closer cases can provide more useful information than others, this study adds the similarity-related weight into multiple-output support vector regression and gives high weights to the information provided by such useful training sample during multi-dimensional regression estimation. The superiority of proposed multiple-output support vector regression with similarity-related weight is validated by the actual design example and quantitative comparisons with other adaptation methods. The comparative results indicate that multiple-output support vector regression with similarity-related weight achieves the best performance for large-quantity case-based reason adaptation because of its higher accuracy and relatively lower cost.
Keywords
Introduction
Case adaptation for parametric mechanical design
Parametric mechanical design1,2 is the key technology in realizing rapid development of mechanical product, but the massive parameters should be determined by designers in the process of complex machine design. Hence, case-based reasoning (CBR) methodology is proposed to figure out the solution parameter values of new mechanical product by referring the solution parameter values of existing cases in case base.3–6 So far, CBR has been employed successfully to design many mechanical products, such as micro-electromechanical device, 7 test turntable, 8 low power transformer, 9 extrusion die, 10 bearing device, 11 gear reducer 12 and welding fixture. 13 To obtain the feasible solution for new problem in CBR, finding a similar solution from existing case and further adapting this old solution are two main steps. Comparing with case retrieval, case adaptation is a more challenging issue, because in most situations, the old solution cannot be applied directly to the new problem.
Early CBR systems used in parametric mechanical design only focus on retrieving cases, and these systems commonly selected the solution of most similar case as the only candidate to be modified to satisfy the new problem.14–17 There are two main problems in classical case adaptation under 1-nearest neighbour (1-NN) principle: first, the adjustment of old solution values heavily depends on human subjective judgement, 18 and second, the solutions from other relative similar cases are ignored. Hence, the automatic case adaptation under K-nearest neighbour (KNN) principle, that is, using K (K > 1) similar cases to generate more accurate solution for new problem, is the greatest challenge for CBR researches.19,20
Early studies of CBR adaptation in the principle of KNN were based on the manual definition of adaptation rules, and engineers have to spend much effort on the acquisition of adaptation rules before adaptation process. 21 Thus, given a specific knowledge-light case adaptation method for CBR has significant practical implication. Statistical adaptation has been first proposed in the research of case adaptation since 1990s, such as the equal mean, 22 median, 23 weighted mean 24 and multivariate regression analysis (MRA). 25 The major shortcoming of statistical case adaptation is its relative low adaptation accuracy. Our previous studies26,27 have tried to extract various implicit knowledge hidden in similar case data to improve the performance of case adaptation based on weighted mean. Another way to overcome the shortcoming of statistical case adaptation is to perform case adaptation based on intelligent machine learning techniques, such as neural networks (NNs),28–30 decision tree 19 and hybrid method.31,32 These techniques have been introduced into CBR adaptation researches, which explore the utilization of inductive learning to acquire the differences between cases and their solutions, and apply the acquired knowledge to implement automatic case adaptation. 33 However, these enumerated intelligent case adaptation methods perform poorly when retrieved cases have a large number of attributes.
Support vector regression–based case adaptation
Recently, some scholars have paid attention to another intelligent algorithm, that is, support vector machine (SVM), because SVM shows its better performance in solving classification and regression problems. The formulation of SVM for solving regression problem is also called as support vector regression (SVR). Compared to other machine learning methods, SVR could generate a global optimal solution because of its optimum network structure and has better generalization performance for retrieved cases with many attributes.34,35 Hence, some studies have employed SVR to automatically perform CBR adaptation with various degrees of success.36–38
Despite the SVR has been employed preliminarily in CBR adaptation, the applications of SVR in CBR adaptation also expose a potential problem, namely, the standard formulation of SVR can only be used as a univariate modelling technique for CBR adaptation due to its inherent single-output structure. 39 Consequently, on one hand, SVR-based adaptation studies highlight the superiority of SVR for CBR adaptation. On the other hand, these studies have to construct different SVR-adaptation model for each solution feature separately, because of the inherent single-output structure of SVR, which would result in the ignorance of the possible interrelations among output solutions. If the parametric design case in case base has N solution values, then in traditional SVR-based adaptation, we have to build total N univariate adaptation engines for N solution features. To deal with the interrelations among solution outputs in CBR adaptation, one way is rule-based method, namely, recognizing and using these interrelations according to the predefined rules, and the other way is model-based method, that is, building multiple-output model which contains these relationships. Considering the complexity of interrelations among output solutions, the second way is a kind of feasible one. Hence, how to build a multivariable adaptation engine is a potential CBR adaptation research issue.
In other research areas, to generalize the SVR from regression estimation and function approximation to multi-dimensional problems, Pérez-Cruz et al. 40 first proposed a multi-dimensional SVR (multiple-output support vector regression (MSVR)) that uses a cost function with a hyper-spherical intensive zone, capable of obtaining better predictions than using an SVR independently for each dimension. Subsequently, the new SVR algorithm has become a viable tool for solving the multiple-input, multiple-output regression problem, such as nonlinear channel estimation, 41 biophysical parameter evaluation, 42 converter gas tank level prediction, 43 dynamic load identification, 44 stock price index forecasting 45 and multiple-step-ahead time series prediction. 46 Although past studies have applied MSVR in various fields, as far as we know, there have been very few, if any, efforts to examine the feasibility of MSVR for CBR adaptation. So, we think it is worth to investigate the utilization of MSVR to conduct the adaptation engine, and apply MSVR-based adaptation method in actual mechanical design.
Motivation and originality of this research
As mentioned in section ‘Support vector regression–based case adaptation’, an alternative way to improve the performance of SVR-based adaptation is to utilize the MSVR. So, we have proposed an MSVR-based adaptation approach in our previous study. 47 We adopt the differential heuristic36–38,48 to build the training sample of MSVR. By using differential heuristic, the training sample consists of the differences between extracted case and retrieved case, rather than a single case in case base. As mentioned in section ‘Support vector regression–based case adaptation’, if the design case in case base has M problem values and N solution values, then the training sample of MSVR has M + N-dimensional input vector (including M problem differences between extracted case and retrieved case plus N solution values of retrieved case) and N-dimensional output vector (N solution values of extracted case). The details of generation of training sample will be presented in section ‘Training sample generation’. However, like the conventional SVR-based adaptation, the empirical error of each training sample in MSVR is equally penalized, which means every sample affects the generalization ability equally. 37 However, actually, different training sample has different effect for MSVR modelization. That is, training sample which contains two closer cases is more useful for MSVR. Inspired by this, we attend to give higher similarity-related weight on the information provided by such useful sample in MSVR, and the new proposed method is named as MSVR with similarity-related weight (MSVR-SW). In MSVR-SW, the error penalty parameter of MSVR is given the similarity-related weight calculated between extracted and retrieved cases to show the impact of training sample. The detailed descriptions of MSVR-SW and corresponding practical application are introduced in the next sections. The breakdown of this research is divided into five sections. Section ‘Methodologies’ gives the specification of MSVR-SW, including the generations of training sample and similarity-related weight for MSVR-SW, and the construction of MSVR-SW-based adaptation engine. Section ‘Example’ gives an example to describe the process of MSVR-SW-based adaptation. A comparative experiment is carried out in section ‘Comparison’. Section ‘Conclusion’ concludes the article.
Methodologies
Training sample generation
Before building the MSVR-SW-based CBR adaptation engine, a set of training sample needs to be produced beforehand. As mentioned in section ‘Support vector regression–based case adaptation’, if the design case in case base has M problem values and N solution values, then the training sample of MSVR has M + N-dimensional input vector and N-dimensional output vector. Main et al.
49
argued that if only the closest cases are used to train the adaptation engine, it could cripple the learning of adaptation knowledge. To guarantee the sufficient data for adaptation engine construction, we use the leave-one-out approach to generate training samples. Suppose that the number of design cases in case base is H, each time one case is picked randomly as the extracted case, and K cases similar to extracted case are retrieved from case base, then total H × K training samples could be produced, enough quantity of data for MSVR-SW-based adaptation engine training. Let

where

where
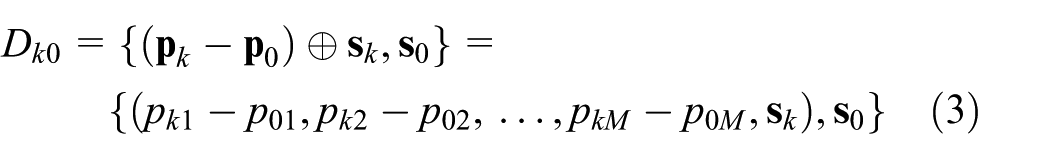
where
Similarity-related weight calculation
The key issue of similarity-based weight calculation is the similarity measurement (SM) of problem feature-values between extracted and retrieved cases. Referring to related SM studies,2,19,26,50 this article adopts multi-algorithm-oriented hybrid SM strategy to amplify the advantages of individual SM techniques and minimize their limitations. The hybrid SM strategy integrates four SM metrics, that is, Euclidian distance, Manhattan distance, Gaussian function and grey coefficient. The distance (Euclidian distance and Manhattan distance)-based SM metrics are in fact particular cases of the Minkowski measurement, expressed as follows

where
The third SM metric is SM based on Gaussian transformation function,
50
which transfers the differences between

where
The fourth SM method comes from the grey coefficient degree between
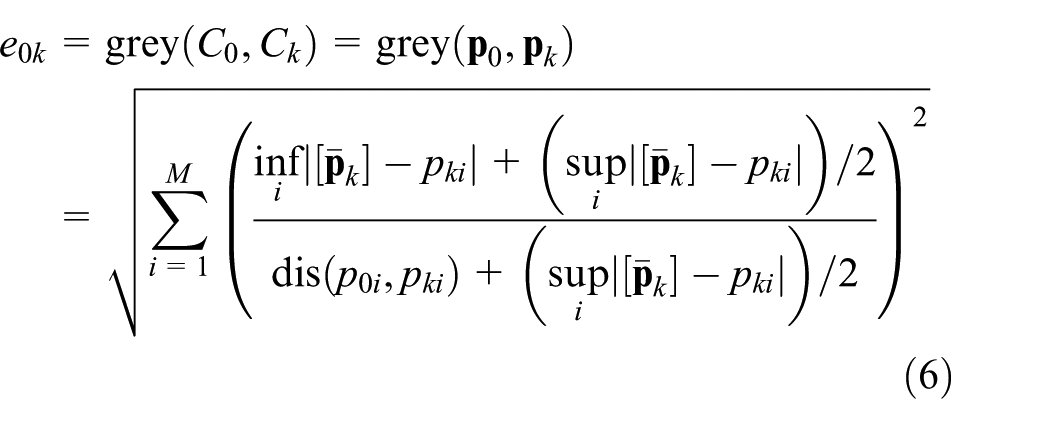
After the similarity between

where
MSVR-SW-based adaptation
Framework
The framework of multivariable CBR adaptation based on MSVR-SW is described in Figure 1. Sections ‘Training sample generation’ and ‘Similarity-related weight calculation’ have described the process of training sample and similarity-related weight generation. Training samples are used to conduct the MSVR model. Different from other MSVR researches, the proposed MSVR-SW introduces the

Framework of multivariable CBR adaptation based on MSVR-SW.
MSVR for case adaptation
Pérez-Cruz et al.
40
appointed out that ‘the key idea of MSVR is extending Vapnikε-insensitive loss function to multi-dimensional output situation, i.e. a hyper-spherical insensitive zone, which handles all the outputs together’. Some studies41–46 have proved that MSVR can improve generalization performance of decision model especially when only scarce samples are available. In the absence of adequate complex mechanical design cases, a common phenomenon in most industry companies, MSVR is an ideal option. Inspired by that, this study employs MSVR to CBR adaptation in mechanical design, and inventively introduces similarity-related weight into MSVR model. Given a set of training sample

where

In equation (9) when

where
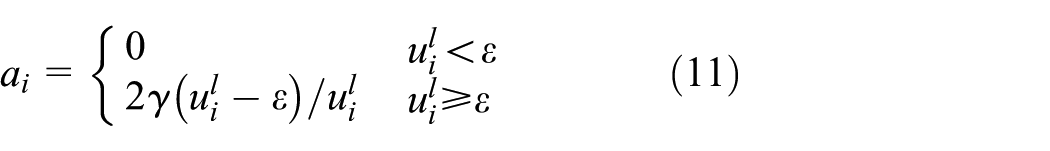
and CT is a constant term which does not depend on
To optimize equation (10), an IRWLS procedure is constructed which linearly searched the next step solution along the descending direction based on the previous solution. According to the representer theorem,
51
the best solution to minimization of equation (10) can be expressed as
Step 1. Set
Step 2. Compute the solution

where

Step 3. Use a backtracking algorithm to compute
The proof of convergence of the above algorithm is given by Sánchez-Fernández et al.
41
Because
Example
Training sample and weight generation
Referring to our previous study,
37
this article also uses the power transformer design with S1, S2, S3 and S4 series as a practical example to implement the MSVR-SW-based adaptation. Assume that each power transformer design case contains four problem features and four solution features, that is,
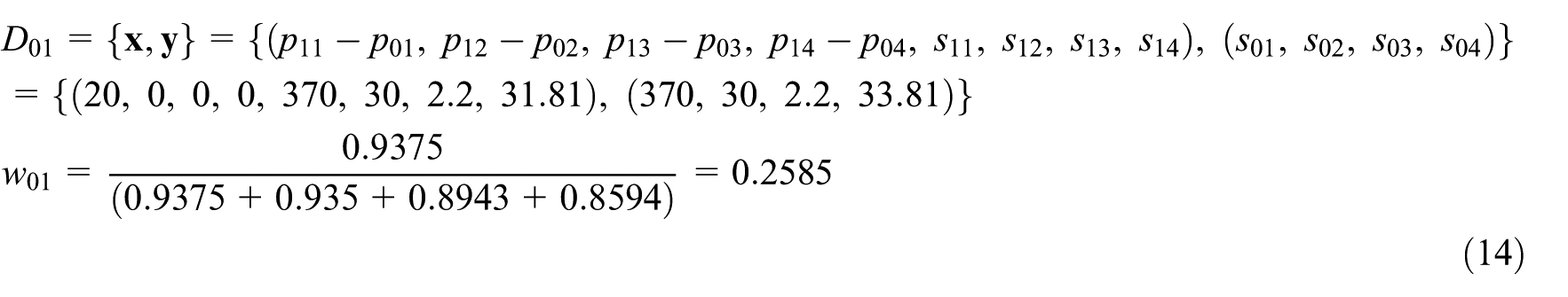
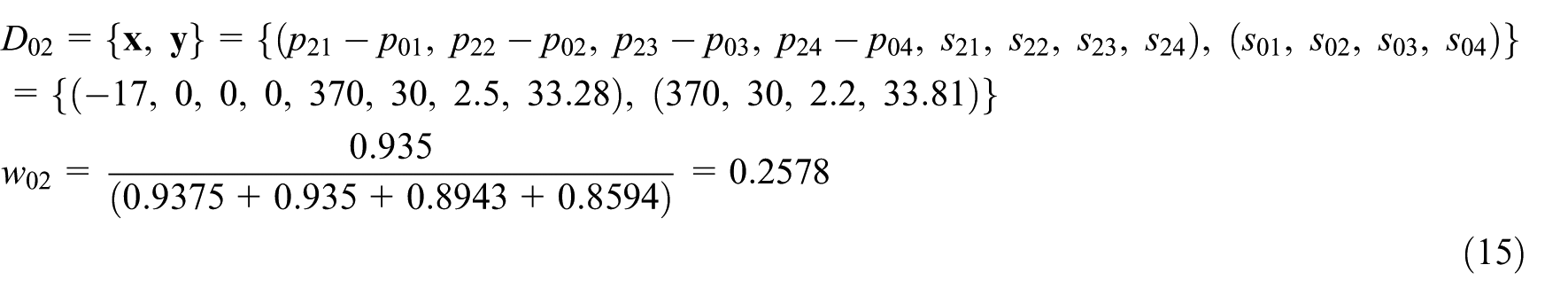
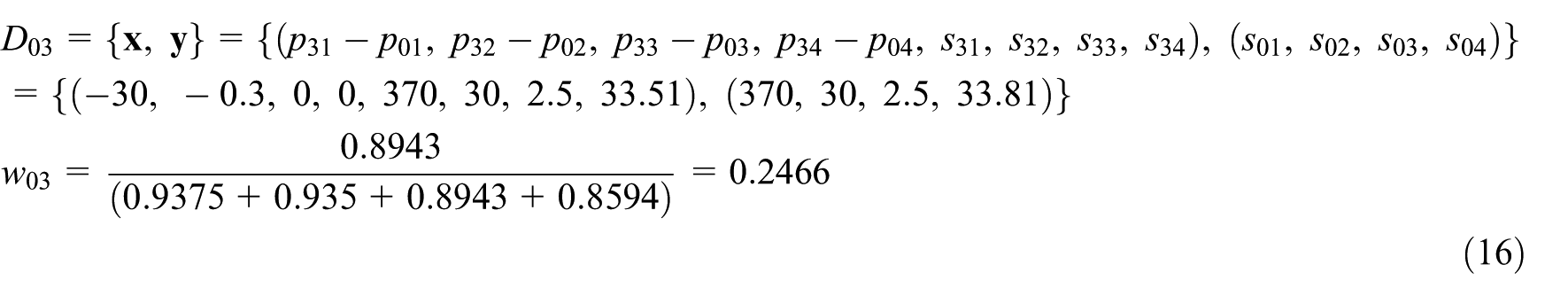
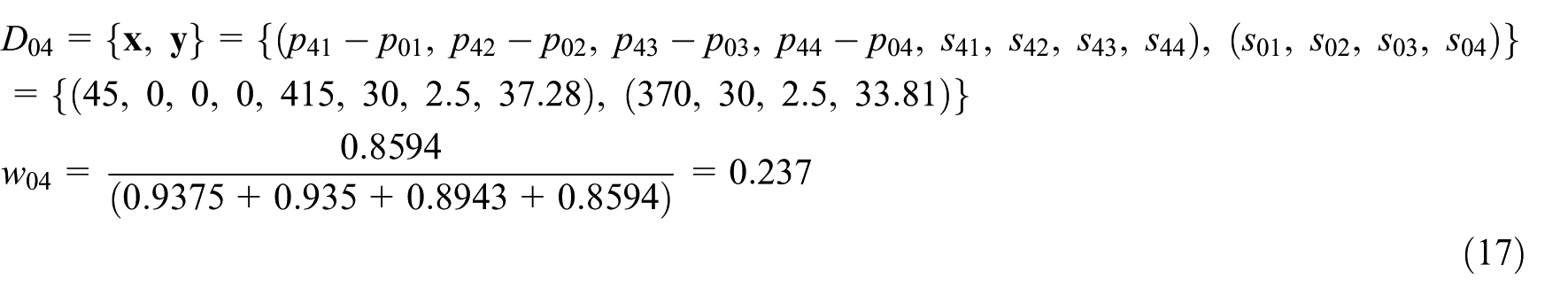
S1-80 and its four similar cases, that is, S1-100, S1-63, S1-50 and S1-125.






Adaptation engine construction
The parameter selection plays a crucial role on the adaptation engine construction. RBF
Meanwhile, Lee
56
suggested that an exponentially increasing sequence is a feasible method to obtain optimal parameters. Hence, the search spaces of

Parameter optimization results of MSVR-SW.
Comparison
Data description
We select 300 historical power transformer design cases from UCI Repository of ML Databases 57 as the raw data. The reasons for choosing such data are well-expressed parametrical case and moderate computational complexity. So, it is a representative data set for CBR adaptation researches.19,26,27,37,47 Furthermore, we would like to compare the performances between different SVRs with different number of inputs and outputs. Referring to Hu et al., 27 we collect a total of 16 problem features and 10 solution features and build three datasets for this comparison according to different problem and solution features. Table 2 describes the selection of problem and solution features in three datasets. For dataset I, there are four problem features and four solution features. For dataset II, there are 10 problem features and 6 solution features, and all problem and solution features (sixteen problem features and ten solution features) are selected in dataset III. Besides, we intend to carry out adaptation processes using various K values, namely, the comparative adaptation methods are performed under 3-NN, 5-NN, 7-NN, 9-NN, 11-NN and 13-NN principles. The objective of this experiment is to find out the influence of the number of retrieved similar cases for adaptation result and to obtain the reasonable K value for CBR adaptation in parametric mechanical design, because higher K value may increase the adaptation accuracy, but it also means requiring large amount of computational time and the reduction in calculative efficiency.
Three datasets with different problem and solution features. 27

To investigate the superiority of MSVR-SW in CBR adaptation, traditional adaptation methods are selected in this comparison. As mentioned in section ‘Case adaptation for parametric mechanical design’, the knowledge-light case adaptation falls into two categories: statistical adaptation and intelligent adaptation. One of the most used tools in intelligent adaptation is NNs. Therefore, two typical statistical methods, that is, MRA and median, and one NN, that is, back-propagation neural network (BPNN), are employed. In addition, classical SVRs, that is, standard SVR and MSVR, are also used as the comparative methods. So, there are a total of six examined methods, that is, MSVR-SW, MSVR, standard SVR, BPNN, MRA and median. Among them, MSVR-SW, MSVR-SW, MSVR and SVR are carried out using LIBSVM tool. 58 Meanwhile, BPNN and MRA are implemented using WEAK library 37 in this comparison.
Validation techniques
This comparison uses the hold-out methodology. In each dataset, two-thirds of the power transformer design cases are used as estimation samples, while reminders constitute the hold-out samples. Comparative adaptation methods were employed and trained on the estimation samples and produced the adaptations for the entire hold-out samples. The adaptation results were then compared to the hold-out sample set to evaluate the out-of-sample performance of each method. A five-fold cross-validation was used in the training phase to avoid over-fitting. To assess the adaptation abilities of the different methods, we compared the out-of-sample adaptations using two different approaches because it is generally impossible to specify an evaluation criterion that is universally acceptable. 45 First, we examined the adaptation accuracies of all comparative methods by calculating the mean absolute percentage error (MAPE), 46 as MAPE, rather than mean absolute error, can reflect the mean adaptation performance of all solution components. 37 The definition of MAPE is shown as follows

where
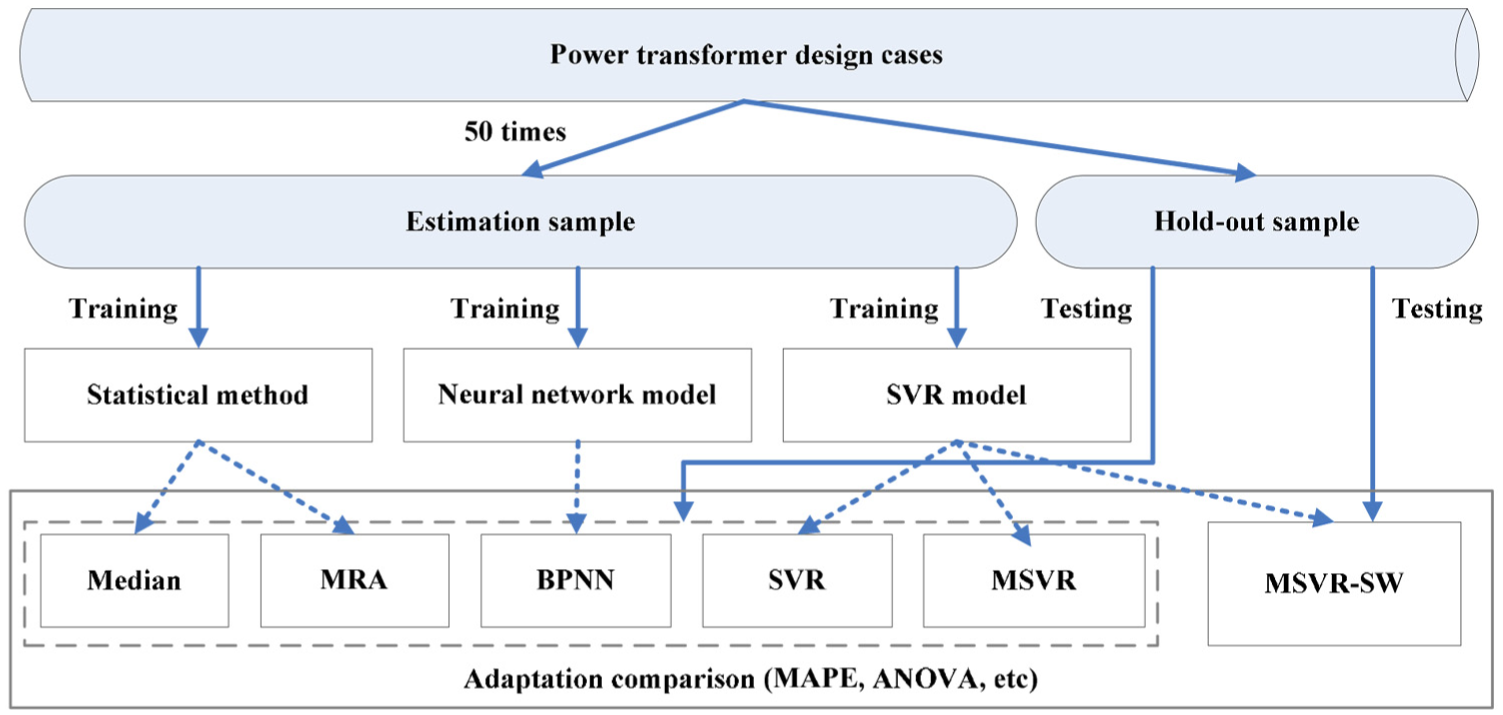
Process of comparative experiment.
Implementation of methodologies
Once the experimental dataset is set, the selected optimization method is employed for parameter space searching. Similar to MSVR-SW, the kernel functions of MSVR and SVR applied in this comparison experiment were RBF. Hence, the three hyper-parameters, namely,

where p and w are the problem value of existing case and related weight, and
Final parameters of SVR, MSVR and MSVR-SW in datasets I, II and III.

SVR: support vector regression; MSVR: multiple-output support vector regression; MSVR-SW: MSVR with similarity-related weight.
Results and discussion
Result
This section focuses on the out-of-sample adaptation abilities of MSVR-SW, MSVR, SVR, BPNN, MRA and median in terms of statistical accuracy and computational cost. Table 4 lists the mean MAPE values of examined methods on 50 times hold-out operations in three datasets to reflect the general adaptation performances, from which we can also abstract the change of accuracy of each method with increasing K values as shown in Figure 4. To figure out the statistical differences of adaptation performance among MSVR-SW, MSVR, SVR, BPNN, MRA and median methods for each K-NN principle and dataset, we also launched the ANOVA and Tukey’s HSD tests, and the calculation results are described in Tables 5 and 6. In Table 6, we rank the six methods from 1 (the best) to 6 (the worst). Besides adaptation accuracy, the computational load is another important and critical assessment criterion from a practical viewpoint, as case adaptation under K-NN principle may be used for assistant decision-making purposes in real-world design activities, and the low construction cost is a real advantage for the underlying approach. Therefore, it is reasonable to compare the examined methods for their computational costs. The required times of the six comparative methods in three datasets with different K values are presented in Figure 5.
MAPE values of six comparative methods with various K values in three datasets.

MAPE: mean absolute percentage error; MSVR-SW: MSVR with similarity-related weight; MSVR: multiple-output support vector regression; SVR: support vector regression; BPNN: back-propagation neural network; MRA: multivariate regression analysis.

Trends of adaptation accuracies of six comparative methods in (a) dataset I, (b) dataset II and (c) dataset III.
ANOVA test results for hold-out sample.

ANOVA: analysis of variance.
The mean difference among MSVR-SW, MSVR, SVR, BPNN, MRA and median is significant at the 0.05 level.
Comparison results with ranked comparative methods for hold-out sample.
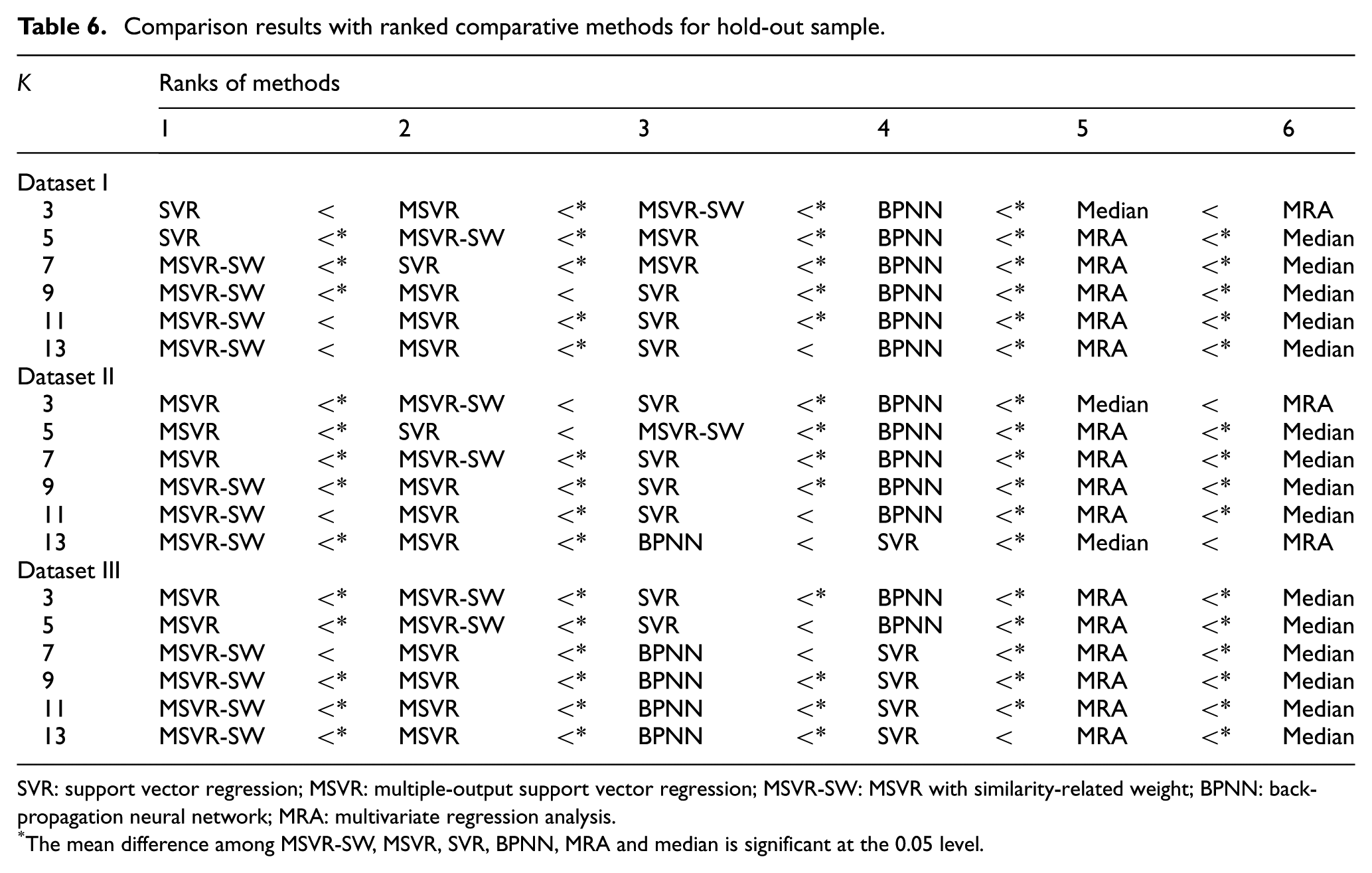
SVR: support vector regression; MSVR: multiple-output support vector regression; MSVR-SW: MSVR with similarity-related weight; BPNN: back-propagation neural network; MRA: multivariate regression analysis.
The mean difference among MSVR-SW, MSVR, SVR, BPNN, MRA and median is significant at the 0.05 level.

Required time of six adaptation methods.
Comparison of adaptation accuracy
When the comparative results of adaptation accuracy achieved by six methods are presented in Table 4, we can deduce the following observations. Overall, by increasing the number of problem and solution features, the performances of CBR adaptation based on machine learning techniques (i.e. MSVR-SW, MSVR, SVR and BPNN) also increase, because of more abundant data to be trained. Meanwhile, the adaptation methods based on SVRs (MSVR-SW, MSVR and SVR) outperform classical adaptation methods based on BPNN and statistic methods in across the three datasets and six K-NN principles, except for SVR and BPNN in dataset III. Considering the comparisons among MSVR-SW, MSVR and SVR, MSVR-SW is the best-performing method which ranks first in almost adaptation situations with different features and K values, followed by MSVR and SVR. SVR displays its superiority in dataset I with smaller K values; however, it is outperformed by MSVR-SW, MSVR and BPNN in datasets II and III. It is conceivable that the reason for the inferiority of the standard SVR-based adaptation in datasets II and III is that SVR ignores the possible mutual dependencies among solution values of design cases. Hence, MSVR-SW and MSVR are better than SVR in CBR adaptation with large number of problem and solution features and higher K values. It proves that multivariable CBR adaptation is an effective method to handle the complicated case adaptation task.
Figure 4 concludes the changes of adaptation accuracies of adaptation methods with different K values in three datasets. In all datasets, along with the increasing K, the performances of MSVR-SW, MSVR and SVR could increase. From Figure 4, we can also find out that the performances of MSVR-SW, MSVR and SVR tend to be stable and even decrease when the value of K exceeds 11 in all datasets. It means that the greater the K value, the more the training samples to be trained and the higher the probability of disturbed data existing in training samples. Thus, large K (> 11) may not improve the accuracy of adaptation method significantly. On the premise of making comprehensive consideration for the adaptation accuracy and computational cost, we prefer to selecting K = 9 or 11 as the favourable value for adaptation method in regular CBR adaptation operation.
Comparison of adaptation difference
To compare the adaptation differences that exist among the six methods, we performed the ANOVA procedure in this experiment. All of the ANOVA results listed in Table 5 are significant at the 0.05 level, which means that there are significant differences among MSVR-SW, MSVR, SVR, BPNN, MRA and median. To further identify the significant difference between any two comparative methods, we also used Tukey’s HSD test to compare all pairwise adaptation differences at the 0.05 level. Table 6 summarizes the results of Tukey’s HSD test, from which we can find that when MSVR-SW with K = 3, 5, 7 and 9 and MSVR with K = 11 and 13 in datasets are treated as the testing target, the mean difference between MSVR-SW and MSVR is significant at the 0.05 level (with the exception of the K = 11 and 13 in dataset I, K = 11 for MSVR in dataset II and K = 7 for MSVR-SW in dataset III), indicating that the MSVR-SW (K = 7, 9, 11 and 13) and MSVR (K = 3 and 5), respectively, perform the best in adaptation process under corresponding K-NN principles. Second, SVR yields better results than BPNN in dataset I, and the performance measures for SVR and BPNN are mixed in datasets II and III. BPNN outperforms SVR in dataset III when K values increase (with the exception of the K = 3 and 5).
Comparison of computation cost
It is important to note that the computational costs of six adaptation methods are different. From a practical viewpoint, the computational cost is an important and critical issue. Thus, the computational load of each method under K-NN principle was also compared in this study. Figure 5 shows the required time for case adaptation on the hold-out sample for a single replicate, from which we can deduce that the required time of all comparative methods could naturally increase when the number of inputs, outputs and retrieved cases increase, except for the required time of MRA and median with little change. Overall, comparing the machine learning methods (i.e. MSVR-SW, MSVR, SVR and BPNN) with the statistical methods, the statistical methods are less expensive.
SVR and BPNN, which use problem and solution feature-values directly and output only one adapted solution values, are computationally much more expensive than multivariable CBR adaptation methods (MSVR-SW and MSVR), and the differences of computational costs are enlarging with increasing number of inputs and outputs. When comparing MSVR-SW with MSVR on computational cost index, the MSVR-SW is the winner, because MSVR-SW adopts differential strategy to generate the training samples from K retrieved cases, and the number of input of MSVR-SW is smaller than MSVR’s.
Summation
According to the results of empirical comparisons, we can find that adaptation method using different number of inputs, outputs and retrieved cases could produce different adaptation results. In general, multivariable CBR adaptation with multiple output is more effective than univariate CBR adaptation with single output to handle the complicated case adaptation task from the views of the adaptation accuracy and computational cost. Furthermore, MSVR-SW improves the performance of MSVR-based adaptation by giving different weights to different training samples. Experiment results show that MSVR-SW is the best method among six comparative methods (MSVR-SW, MSVR, SVR, BPNN, MRA and median) across three datasets and six K-NNs, because of its higher adaptation accuracy and relative lower required time, and the reasonable K value can further increase its accuracy.
Conclusion
In this article, because of its inherent single-output structure, standard SVR is incapable of handling the possible interrelations among solution outputs in CBR adaptation under K-NN principle, which suffers from either low adaptation accuracy or expensive computational cost. Building a multiple-output model which contains these complex interrelations is a feasible alternative to SVR. As mentioned above, MSVR is an approach structured as multiple-input, multiple-output model, where the output value is not a scalar quantity but a vector of values. One of the advantages of MSVR for CBR adaptation is preserving the implicit stochastic dependency hidden in the adapted solutions. Therefore, in this article, we put forward a new multivariable case adaptation method by creatively employing MSVR model in the field of parametric mechanical design. Another innovation point of this article is considering the different contributions of different training samples for MSVR construction, and following the fact that training sample which contains two closer cases can provide more useful information than others. By taking the advantages of different SM algorithms, this article puts forward a similarity-related weight generation method, and gives more weights to the useful training samples. MSVR-SW model for multivariable CBR adaptation is built up by training these weighted training samples. Comparing with classical SVR-based adaptation, the new proposed MSVR-SW can not only output a vector of adapted solution values for new design problem but also improves the performance of multivariable CBR adaptation. Besides the theoretical descriptions, this article also gave an example to assess the feasibility of MSVR-SW in parametric mechanical design and carried out the quantitative and comprehensive comparisons between MSVR-SW and other methods in the three datasets to discuss the superiorities of MSVR-SW for case adaptation. According to the obtained results, the MSVR-SW is the promising techniques with high-quality adaptations and acceptable computational loads for multi-dimensional case adaptation.
In future, we intend to investigate the parameter optimization of MSVR-SW for CBR adaptation. For example, in this comparison experiment, we just performed the coarse grid search on
Footnotes
Handling Editor: Jolanta Tamosaitiene
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This research is supported by National Key Scientific Instruments and Equipment Development Program of China (No. 2016YFC0104104, 2016YFF0101602, 2013YQ03065105), the National Natural Science Foundation of China (No. 51675329), Special Program for Innovation Method of the Ministry of Science and Technology, China (No. 2018IM020100), the Cross Fund for medical and Engineering of Shanghai Jiao Tong University (YG2017QN61), and National Social Sciences Fund (17ZDA020).