
Abstract
This research investigates the optimal control problem of heavy haul train for the minimization of longitudinal forces. As the heavy haul train is much heavier and longer than ordinary train, the in-train forces should be carefully manipulated to reduce the train’s maintenance cost and, most importantly, to ensure operation safety. Specifically, the limitations of pneumatically controlled braking system increase the need for the optimal control strategy to accounting for future grades, speed restrictions and uncertain disturbances. In this article, the stochastic dynamic programming model is adopt to set up a rigorous mathematical formulation for heavy haul train control, and approximate dynamic programming algorithm with lookup table representation is introduced to find the optimal solution of the considered problem. By handling the existed uncertainties in a mathematical way, the post-decision state variable is utilized to represent the state of the heavy haul train after we have made a control decision but before any exogenous information has arrived. Finally, the computational results demonstrate the effectiveness and performance of the proposed model and algorithm.
Introduction
Background and literature review
As an efficient and reliable traffic mode, heavy haul railway transportation is currently one of the main methods that provide the services for transporting coals, petroleum, minerals and so on in many countries. In order to increase haulage capacity, trains have increased from a maximum of 10,000 to 20,000 ton on the Datong-Qinhuangdao and Shuohuang heavy haul railways in China. 1 Thus, the train control strategies will need to be developed and refined to heavier and longer trains accordingly.
In general, a desirable efficient operation strategy means the minimization of energy consumption, service quality in terms of punctuality and operation safety closely linked with in-train forces.2–4 Over the last few decades, a number of optimizing algorithms and advanced control techniques, such as fuzzy control, 5 coasting control6,7 and model predictive control (MPC),8–10 have been proposed for the improvement of the three performance indicators. Nevertheless, as pointed out by Zhang and Zhuan, 8 it is impossible to make any improvement on energy performance without making the two other performance indicators worse off, and we should choose the proper strategy regarding the desired performance in practice.
Since China’s two main heavy haul dedicated lines are responsible for transporting coal from west to east, the routes are mainly downwards. When the train is generally travelling downwards, both dynamic braking and the air braking are applied to keep the train speed within the required range. 11 As only the locomotives in the heavy haul train can supply dynamic braking forces, the air braking force is on the leading position in regulating train’s speed. Applying air braking will inevitably give rise to longitudinal forces within the train and lead to excessive tear-and-wear on braking unit. It is believed that the longitudinal coupler forces are the direct cause of coupler damages, which may lead to train operation disasters such as derailment. 12 Under this circumstance, the demand on a desirable train operation strategy to optimize the operation safety determined by in-train forces has escalated accordingly, combined with maintaining commercial punctuality. In this sense, finding the optimal control method for heavy haul trains to minimize the longitudinal forces is one of the core problems in both fields of theoretic research and practical operation.
Following this trend, substantial work has been done to optimize the operation safety determined by in-train forces,
13
designed an open-loop controller and took advantage of Lagrange multiplier approach to determine the power splitting between the neighbouring locomotives in order to minimize the longitudinal coupler forces. The authors of Nasr and Mohammadi
14
investigated the effects of the train brake delay time on longitudinal dynamic behaviour of the freight trains using simulation method and observed that the magnitude of the maximum tensile force relatively increased as brake delay time decreased. Zhang and Zhuan
To the best of our knowledge although the majority of the literature had paid more attention to the optimal operations of heavy haul train under various scenarios, for example, cruising control, 15 station stopping, 16 delay recovery, 17 considering the real-world operation environments such as input constraints, 18 communication delays, 19 the uncertain of some performance parameters 20 and so on, the optimal air braking control strategy when travelling on steep descent is not as thoroughly studied as others, but its importance for transportation safety and efficiency should not be underestimated.
Unfortunately, the pneumatic braking system of heavy haul train has a number of limitations such as brake delays throughout the train and minimum brake application duration. Some pneumatic braking systems even do not have the graduated release function. These disadvantages of air braking impose stringent requirements on safety, reliability and service quality, thereby reducing the flexibility to optimize both longitudinal in-train forces and travelling time, simultaneously, increasing the complexity of the corresponding optimization models. 4 It is worth noting that due to the uncertain environment of real-world operations, such as wind gust, weather and gradient resistance, the detailed characteristics of train dynamic model cannot be captured accurately.3,21 Recently, modelling the uncertainty has become a hot research issue in controller design, and adaptive robust control method is usually employed to achieve high-accuracy trajectory tracking performance.22,23
As far as I know, most solution methodologies in the literature, such as quadratic programming, linear quadratic regulator and MPC, have limitations in handling these real-life operational requirements under uncertainty. For this reason, some powerful algorithmic strategies are required to solve the constrained optimization problem in the presence of various forms of randomness.
Proposed approach
As an emerging technology for multistage stochastic, dynamic problems that arise in operations research, approximate dynamic programming (ADP) offers an extremely flexible modelling framework which makes it possible to combine the strengths of simulation with the intelligence of optimization.24,25 To handle the existed uncertainties in a mathematical way, the post-decision state variable is introduced to represent the state of the system after we have made a decision but before any exogenous information has arrived. Exogenous information referring to the sources of uncertain factors can be viewed as information that becomes available over time under practical circumstance. This means that the value function is a deterministic function of the state and action, a feature that makes it suitable for a wide range of problems spanning real-time planning of locomotives, 26 dynamic routing and scheduling,27,28 health resource deployment 29 and large-scale fleet management problems. 30
With the consideration of practical constraints associated with the optimal operation of heavy haul train on steep descent, we are particularly interested in finding the corresponding approximate optimal control strategies to both enhance safety and guarantee service quality. This research aims to provide the following contributions to the optimal heavy haul train controller design:
In this study, the optimal control problem with respect to the cascade mass point model of heavy haul train is transformed into a unified stochastic dynamic programming model. In the formulation, we can capture the impact of certain control action on the future, and then communicate this impact backward. By this way, decisions can be made more intelligently. Furthermore, operational regulations associated with the air braking are detailed and formulated as constraints on the possible solutions to ensure safety and punctuality.
A standard ADP algorithm with lookup table representation is formulated for finding the optimal operation strategy with the least in-train forces. Some critical algorithmic issues, such as such as post-decision state variable, exploration and exploitation, stepsize rules, are discussed to effectively solve the problem. By adopting different sets of parameters and simulation scenarios, the computational results show that the proposed approacher can efficiently generate optimal solutions for the considered problems within acceptable computational time.
The rest of this article is organized as follows. Section ‘Problem description’ gives a description for the non-linear dynamic model of the heavy haul train and then details the problem of running in a steep descent. In the next section, mathematical formulations of the optimal control problem are described. Section ‘ADP approach’ describes the algorithmic strategy, focusing primarily on the use of ADP to solve the problem of optimizing over time. Simulation results are discussed in section ‘Simulation results and discussions’ for demonstrating the validity and effectiveness of the proposed approaches. Some conclusions and further works are given in the final section.
Problem description
The dynamic model of heavy haul train
Essentially, heavy haul trains are distributed powered networked system constituted with many locomotives and wagons. Figure 1 is the sketch of the longitudinal motion. Assuming the train consists of n cars and

where

Longitudinal dynamics of heavy haul train.
In general,

The running resistance

Line resistance

where
Concerning curve resistance, the value of

where
As mentioned in Chou and Xia, 15 here we also assume that the coupler system is taken as a spring with damping. Thus, the in-train force can be established as follows

where
For a heavy haul train, the control inputs for locomotives can be either traction forces or braking forces, while the efforts of wagons are only braking forces. To address the braking control issue, there are basically two types of braking units equipped in heavy haul train including rheostatic unit and pneumatic unit. The rheostatic brake is also called regenerative brake, which can be fed back to power other locomotives. For rheostatic braking system, the series excitation resistor can be adjusted to control the braking current so that continuous braking forces can be produced to slow down or stop the train. In pneumatic braking system, braking forces are applied by reducing the air pressure in the train air braking pipe. 14
Additionally, the running train will inevitably suffer from the uncertain disturbance from real-world environments such as wind gust and weather condition, which may affect the transient longitudinal forces as well as service quality. 33 Thus, the parameter w can be expressed as the uncertain variable to characterize uncertain information. As air brakes are added as braking forces to all cars and rheostatic brake is equipped only to locomotives, the dynamic equation of n-cars heavy haul train (1) is equivalent to

where
Control problem on steep decent
Generally, locomotive operation involves four possible operation modes: accelerating, cruising, coasting and braking. In accelerating phrase, traction effort is applied to accelerate the train and overcome the running resistance. Under most conditions, running resistance is positive so that partial traction effort is applied to maintain a constant speed in cruising state. During coasting, both traction force and braking force are switched off, which present opportunities for energy saving. Braking is to slow the train or to bring it to a stop. However, on track with steep downward gradients, the power-hold-coast-brake strategy may not be feasible and it will be necessary to replace the hold phase with one or more coast phases on the steep downhill sections. 7
Definition 1
If the train speed increases on a grade when the maximum rheostatic brake is applied, then we say this grade is called a steep downhill. In this grade, we have
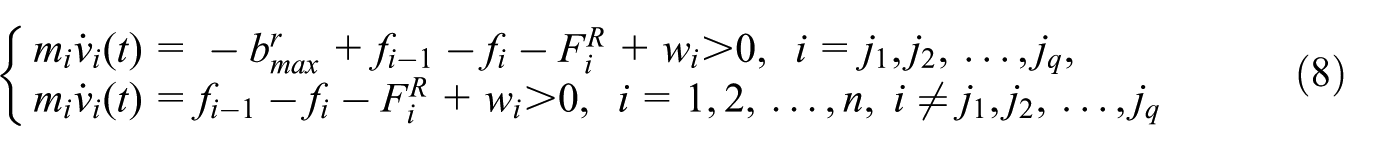
Remark 1
Obviously, on a steep downhill, it may need particle air braking to prevent train from over-speeding. Considering the braking pipe needs to restore pressure completely to achieve effective release, the speed profile has a definite cyclic nature. 34 Thus, constraints should be used to guarantee the safe operations of heavy haul train. First, air-filled time in periodic train braking should be ensured. Second, as altering braking rates frequently gives rise to longitudinal forces within the train and leads to excessive tear-and-wear on braking unit, each braking notch should maintain certain time before transferred to another one. In addition, the switching of notches has to satisfy several guidelines. For example, coasting must be applied as an intermediate step if a driver wants to switch between motoring and braking. One switching should not jump too many notches.
In practice, there are more than one possible set of control instructions, which enable an inter-station run under the same runtime and speed requirements, but the resulting longitudinal forces may vary significantly. A critical issue in above problem is the brake notches decision policy, that is, how to choose a brake notch, and when to perform or release the corresponding air brake. If these policies are not designed carefully, the longitudinal forces within the train may increase rapidly and the speed may exceed the limit, both of which will significantly affect the safety and efficiency of heavy haul train movement. Therefore, we focus on developing optimal control algorithms to achieve timely train speed adjustment with minimized in-train forces, which will be studied in the following section.
Mathematical formulations
This section will formulate the optimal control problem on steep downhill as a stochastic dynamic programming model with the minimized in-train forces criteria. In order to satisfy the requirements for punctuality, we should make sure that the train can cover the distance within the expected travel time
States
We regard each car in the heavy haul train as an intelligent agent. A policy defines the agent’s way of behaving at each decision epoch. We measure the state

where
Remark 2
For simplicity, only the position of the first car is considered in the state variable. At equilibrium state, the distances between the (i + 1)th car and the ith car
Actions
In the train control process, actions may affect not only the immediate reward, but also the rewards of the following states. When heavy haul train is travelling on steep downward slope, the maximum rheostatic brake is used on each locomotive and air brake is applied on every car. Without the loss of generality, we suppose

where
As the maximum rheostatic brake can be treated as a constant for certain type of locomotive, the decision variables are defined as follows

According to Rao, 35 calculation equation of the braking force can be written as follows

where
In general,
Heavy haul trains have a number of limitations that need to be carefully manipulated when determining the optimal action. In order to guarantee the requirements associated with safe operation and maintenance cost, constraints on decision variables
Braking force constraints
It is worth noting that although electronically controlled pneumatic (ECP) braking system has been developed to provide each car with different air braking efforts, this technology is not implemented in practical heavy haul train lines in China on a visible scale due to high operating cost. As a result, it is reasonable to assume that the braking force is identical for cars controlled by the same locomotive. The corresponding constraint is below

Air-filled time constraints
Considering the features of air braking, we should reserve enough time to fill the air tanks so that we can count on the air brakes. The following air-filled time constraints are formulated to capture this characteristic

where
Minimum hold on time constraints
In general, altering braking rates frequently not only gives rise to longitudinal forces within the train, but also leads to excessive tear-and-wear on braking unit. Therefore, switching forth and back between adjacent notches must be avoided. Once a braking notch is triggered, it should maintain certain time before transferred to another one.
If we use
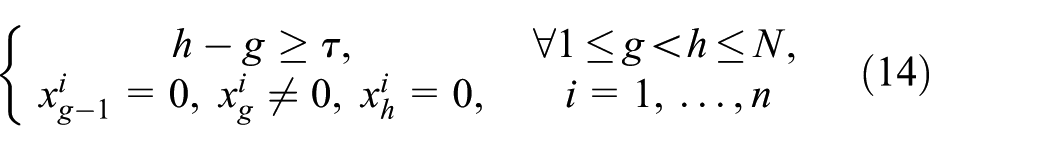
Graduated release constraints
At present, most heavy haul train pneumatic braking systems do not equip the graduated releasing function in China. As a result, coasting must be applied as an intermediate step if we plan to switch to a brake notch with smaller braking force from a bigger braking force notch. Then, the corresponding constraints can be formulated as follows

where
Let
Exogenous information
In practice, the running heavy haul train will inevitably suffer from the wind gust, weather condition and other real-world environment factors. These unfavourable factors could be treated as uncertain external disturbances to heavy haul train. To handle the existed uncertainties in a mathematical way, we use exogenous information to describe the disturbances that arrive to the train exogenously, representing the sources of randomness. The exogenous information consists of the realization of the disruption statuses of all the cars. As the disruption statuses may change as we proceed to the next stage, the systems exogenous information can be written as

where
State transition function
The transition function details the system state transition. Given the current state

As addressed above, we can derive from equations (6) and (8) that

where
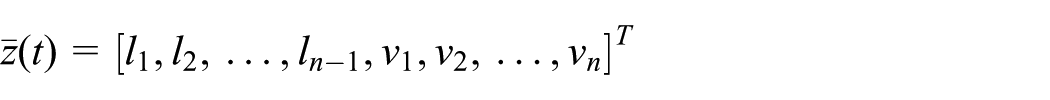
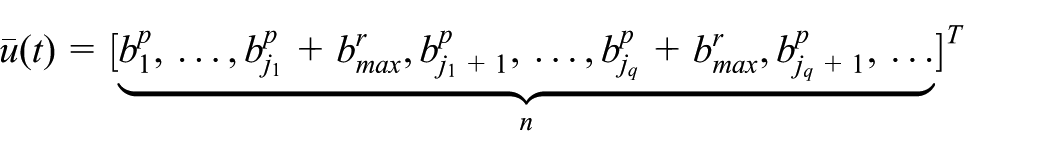
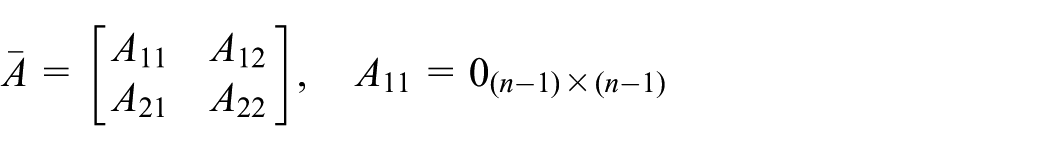

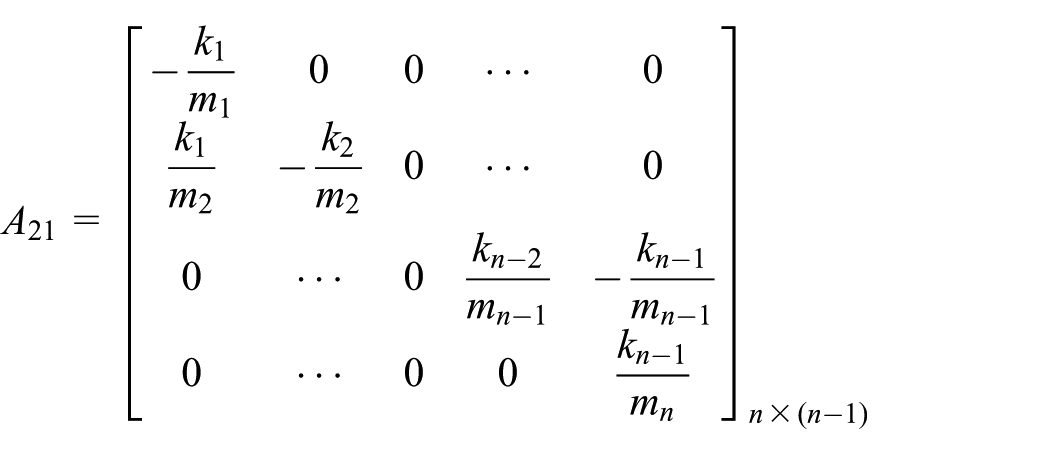



In order to apply the stochastic dynamic programming framework, the continuous time-domain state-space equation (18) is discretized by the zero-order hold method with a sampling period

where
Besides, according to Newton’s law,
Cost function
The actual in-train forces or cost for period
Objective function
The objective of the stochastic dynamic programming is to find the optimal policy

where
ADP approach
If the state, decision and outcome spaces are finite discrete, the stochastic dynamic programming equation (20) can be solved using the classical backward dynamic programming algorithm by Bellman’s equations

where
Nevertheless, solving equation (21) encounters three curses of dimensionality (states, decisions and outcomes), and the dynamic programming approach for solving Bellman’s equations becomes computationally intractable. As an alternative, the ADP approach is a powerful tool to overcome the curses of dimensionality, especially for complex and large-scale problems. 25
In essence, ADP replaces the exact value function
In the following sections, we first introduce the post-decision state variable and then describe ADP algorithm with lookup table representation. Furthermore, we discuss some key algorithmic issues that we encountered in the design of ADP algorithm to effectively solve the problem, such as exploration and exploitation strategy, stepsize rules and so on.
Post-decision state variable
Our algorithmic strategy differs markedly from what is presented in merging math programming with the techniques of machine learning, particularly in use of the post-decision state variable.
25
Note that


In the first step (22), we consider the pure effect of decision-making, while in the second step (23), we pay attention to the effect of exogenous information. Given our action

ADP algorithm
Rather than solving for the value of each state exactly, ADP steps forwards through time via simulation and proceeds by iteratively estimating and updating the approximate value of being in a state. Algorithm 1 outlines the steps of ADP algorithm for solving the optimal heavy haul train control problem. This algorithm uses a single pass to simulate a sample trajectory using the current estimates of the value functions, and both the calculation and updates of the value function take place as the algorithm progresses forward time.

With the approximate value function around post-decision state, we can solve for
Remark 3
The approximate value function
Exploration and exploitation strategy
If we constantly exploit the action with the minimum value, only the values of states with the minimum cost are updated, and the value of the rest states remains their initial values. This causes the approximate state values not improving as we do not explore other states. On the other hand, if we explore states and actions that may not look attractive, we could reduce the probability of being stuck in suboptimal solutions. In this sense, we should decide on the trade-off between exploration and exploitation when making a decision given a certain state.
One of the simple and intuitive ways of solving this problem is known as the ε-greedy policy, which guarantees that we will visit every (reachable) state infinitely often.
36
Under this policy, with probability ε we choose an action at random from the feasible region
Specifically, the ε-greedy policy is a fixed exploration rate strategy. It is worth noting that the value of being in a state is mostly dependent on the sample path and the initial solution in the early iterations. Therefore, it is reasonable to use the exploration strategy more frequently to improve the quality of the state values at the beginning, and the exploration rate decreases as the number of visits to the particular state increase. To do this, we introduce the exploration rate
Stepsize rules
After finding the next action with the exploration/exploitation strategy, we then confront the problem of approximating the current value of the visited state using proper stepsize rule, which plays an important role on the convergence performance. If we choose a too small stepsize, the rate of convergence will be slow. If the stepsize is too large, the performance will be unstable. Theoretically, there are two kinds of stepsize rules including deterministic stepsize rules and stochastic stepsize. Deterministic stepsize do not change with practical data in the process of approximating state values, while stochastic stepsize rules adapt to collected data. For computational convenience, we implement with a deterministic stepsize rule, that is, the harmonic stepsize rule, as in equation (25)

where a is a constant. Note that the stepsize depends on the number of visits to the state-decision pair
Simulation results and discussions
In this section, the detailed simulation results are provided to verify the effectiveness of the proposed control schemes. The routine of the optimal controller design can be categorized into two processes including the offline and online parts. For the offline part, the mathematical models described earlier are established according to practical conditions, and the proposed ADP algorithm is used to find out the optimal policy. Once the optimal policy is obtained, it is stored in a table format. Each entry in the table specifies the optimal action given the current train state. For the online part, the train looks up the policy table to find out the optimal action corresponding to its current state when running on railway lines, and then, it executes the action to get the next state. By this way, the optimal output is computed repeatedly until the train reaches the destination.
The simulation parameters given in Table 1 are based on the heavy haul train from Shuohuang heavy haul railways in China, where
Simulation parameters.

Without loss of generality, it is assumed that there are four locomotives which are evenly spaced in the heavy haul train. As mentioned in Gao et al., 19 the dynamics of wagons between locomotives are also neglected and regarded as rigid body for the sake of making the results explicit and reducing the unnecessary complexity. That is to say, the optimal control of four locomotive-wagon subgroups is considered. Noting that there are only a finite number control notches on-board to control the level of effort delivered by air braking, which are determined by the train pipe pressure reductions. According to experimental data collected from Shuohuang railways, two optional pressure reductions for heavy haul train are 50 and 70 kPa, and corresponding air braking forces could be calculated according to Rao. 35
To further coincide with the real-world conditions, we take comprehensive measures to capture the parameters with regard to constraints on practical operation, including questionnaires with experienced drivers about how to drive in a safe and efficient way, observations in the Shuohuang railway by ourselves and so on. The related parameters are described as
After performing several preliminarily tests, we set the constant in the harmonic stepsize rule to
Next, we present two different cases to test the algorithm. In Case 1, we consider the deterministic situation to test the performance of the ADP algorithm. In Case 2, associated with the real operation conditions, different speed limits and gradients are taken into consideration during the trip. Uncertain disturbance from real-world environment is also taken into account to verify the robustness of the proposed algorithm. Finally, to better illustrate the performance of the proposed method, we implement another set of experiments to compare the performances of the proposed algorithm with other approaches.
Case 1
For the convenience of describing trains movements, the length of relevant railway track section is given as 10 km, and the gradient is supposed to be −12‰ along the whole track. As the heavy haul train is treated as a cascade mass point model, we assume that the beginning location of the last car is at the initial site, and the initial coupler displacement between adjacent cars is 0. In other word, all cars are travelling on the same downward slope. Besides, the line limit speed and initial speed are set to be 80 km/h and
Figure 2 gives the velocity profiles of each locomotive-wagon subgroup with respect to the distance under the optimal policy derived from the ADP algorithm. As expected, heavy haul train traverses on its route without exceeding the speed limit. As the initial speed is far below the track permitted speed, a coasting operation is first obtained to allow the train accelerates due to the steep descent of the track. Next, braking force is applied to keep the train from over-speeding. Interestingly, a smaller pressure reduction (50 kPa) is selected to slow down the train instead of the bigger one to effectively control the in-train forces. It is obvious that the speed profiles have a cyclic feature to ensure the air-filled time, which are consistent with practice. In addition, it is worth mentioning that all the four locomotive-wagon subgroups adopt the same policy due to the similar operation conditions.

Travel trajectories of different subgroups under uniform track condition.
Figure 3 illustrates the learning procedure for the proposed scheme. Specifically, we plot the evaluated objective value of the ADP algorithm in every 2 × 103 iterations up to 2 × 105 iterations. At the beginning, the longitudinal in-train forces are far from the optimal one and gradually reduced from 1.432 × 105 to about 4.74 × 104 kN after 8 × 104 iterations. After about 1.6 × 105 iterations, the difference between adjacent objective values is zero, which means that the learned policy converges to the optimal one.
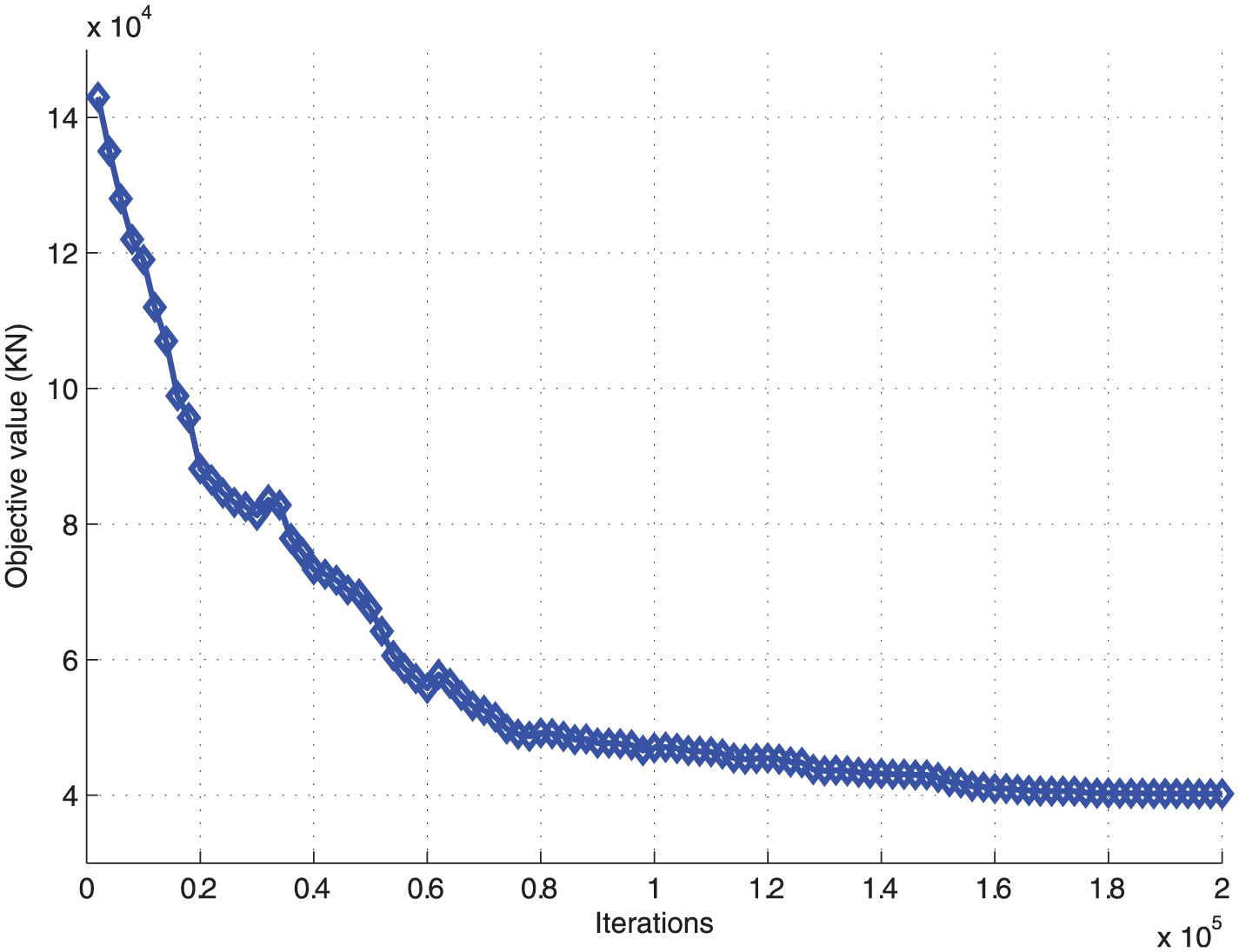
The convergence speed.
Case 2
To further test the effectiveness and robustness of the proposed approach, different speed limits and the gradients are considered as shown in Figures 4 and 5, respectively. For the sake of alleviating longitudinal damage to the coupler when releasing the air braking at low speed, the minimum allowable release speed is set to be 35 km/h. The planned trip time T = 650 s is longer than Case 1 due to the speed limits and initial speed is set to be

Speed limits.

Gradients.
Figure 6 shows the velocity/distance curves under our ADP policy. There is no doubt that the complexity of track conditions and speed limits make driving on steep descent more challenging. We can observe that our optimal policy can achieve safe driving as it never exceeds the speed limit, while maintaining the release speed bigger than minimum release speed. Thus, the train can run safely along such a continuous decent. Moreover, each locomotive-wagon subgroup follows a different optimal strategy compared to a unique one in case 1. This is because each intelligent agent needs to dynamically adapt the track condition to achieve the optimal performance. Given that the deceleration depends also on the gradient of the track, we observe that the on-board air braking notch with bigger pressure reduction (70 kPa) is chosen at certain decision epoch to balance the deceleration of different subgroups in order to reduce the longitudinal coupler forces. The results show that ADP policy is able to learn information from the uncertain environment and find an optimal policy with real-time data.

Travel trajectories of different subgroups under different track conditions.
Comparative analysis
As one of the most efficient algorithms from the reinforcement learning, Q-learning provides a nice mechanism using the value function.
36
The Q-factor

The comparisons of convergence.
We observe that Q-learning algorithm converges faster than ADP in early iterations, but ADP outperforms Q-learning after about 24,000 iterations. The optimal objective values obtained by the ADP and Q-learning algorithm are 4.02 × 104 and 4.14 × 104 kN, indicating that ADP algorithm has better performance in manipulating the in-train forces than Q-learning algorithm.
To the best of our knowledge, the optimal control action is either determined based on information of the leading locomotive (leading controlled strategy (LCS)) or calculated by each locomotive independently (independently controlled strategy (ICS)) in the majority of existing works. To show the advantages of the proposed method over LCS and ICS, we implement another set of experiments in the uncertain environment. We use the Monte Carlo simulation and run the simulation 100 times for all the mentioned approaches. The control parameters remain the same as those used in Case 2 unless otherwise noted. The performance values of different methods are shown in Table 2.
Performance comparison.

LCS: leading controlled strategy; ICS: independently controlled strategy.
As LCS and ICS mainly control the heavy haul train according to current information, future behaviours during the whole travel are usually not taken into consideration. Therefore, these two approaches are typical myopic ones, and they cannot accomplish an overall optimization for the heavy haul train movement due to the uncertainty during a long trip. It is shown from Table 2 that there are 17.8% and 30.3% gaps between the myopic objective values and the optimal one. On the contrary, our optimal policy, which captures the impact of decisions on the future and communicates this impact backwards, is capable of giving the best performance compared with other two methods in all indices. Therefore, it is safe to conclude that considering the future impact when making control decisions is crucial in practical heavy haul train operation, and the proposed method is effective in enhancing safety and punctuality.
Conclusion and future work
This article deals with the optimal air braking control problem of heavy haul train on steep descent. In order to minimize the in-train coupler forces, while keeping to schedule and enhancing safety, a multistage stochastic dynamic programming model is designed with consideration of operational constraints and uncertain disturbances to the practical train movement. The model is capable of capturing the impact of decisions on the future, and then communicating this impact backwards so that decisions can be made more intelligently. To search for an optimal control strategy, ADP algorithm is introduced to step forward in time by making decisions based on the approximate value function. The performance of the proposed model and algorithm is validated by numerical experiments.
For future work, we plan to extend approximate value function to other forms such as weighted sum of basis functions, piecewise linear functions and regression models, which may outperform the lookup table ADP in terms of both solution accuracy and time.
Footnotes
Academic Editor: Zheng Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article was partially supported by Beijing Laboratory of Urban Rail Transit and Beijing Key Laboratory of Urban Rail Transit Automation and Control, by Beijing Municipal Natural Science Foundation under grant L161006, by Technological Research and Development Program of China Railway Corporation under grant 2016X008-B, by Beijing Jiaotong University Technology Funding Project under grant 2016JBM005.