
Abstract
Cluster tools are used for semiconductor wafer fabrication. A cluster tool consists of several loadlock modules, processing modules, and material handling armed robots to transfer wafers between loadlocks and processing modules. Most conventional scheduling methods consider a cyclic schedule to minimize makespan. We consider noncyclic scheduling of dual-armed cluster tools. In practice, it is important to minimize wafer residency time in processing modules to maintain the surface quality of wafers. In the noncyclic operations, the cluster tool causes deadlock which may lead to excessive loss in the wafer fabrication process. We propose an efficient deadlock-free scheduling method for the noncyclic scheduling problem of a dual-armed cluster tool to minimize the residency time and makespan. The proposed method is applied to a dual-armed cluster tool with a non-revisiting process and a revisiting process. Computational results demonstrate the effectiveness of the proposed method.
Introduction
In the semiconductor industry, manufacturers utilize cluster tools to produce silicon wafers. A typical cluster tool comprises loadlock modules (LL), several process modules (PM), and a dual-armed transfer module (TM) to transfer wafers between LL and PM. The scheduling of cluster tools has received considerable attention due to increasing demand for silicon wafers. In cluster tools, deadlocks occur due to the absence of an intermediate buffer. Therefore, it is extremely important to generate a deadlock-free schedule to maximize throughput of cluster tools.
Generally, most studies on scheduling cluster tools focus on finding the optimal cyclic schedules1–11 when the cluster tools are operated in a steady state. A dual-armed cluster tool is often operated at a constant cycle by employing swap strategies. 3 With a swap strategy, the sequence of operations is repeated, that is, a processed wafer is unloaded from a module into an empty robot arm and the subsequent wafer from another robot arm is immediately loaded into the module. Task sequencing is simplified using swap strategies. Cyclic scheduling is easier for analyzing the model because a swap strategy reduces the computational complexity of combinatorial problems.
However, in practice, the optimal schedule is not always cyclic when the operations include transitive situations such as start-up, processing time variations, cleaning, lot-switching, and maintenance. Noncyclic scheduling is often required to deal with non-steady states. In those situations, it is difficult to measure throughput in only one cycle. 12 Several studies have reported noncyclic scheduling of dual-armed cluster tools13–18 and multi-cluster tools.19,20 The optimal transient cycles of a single-armed cluster tool with parallel chambers have been derived. 13 These studies showed that a generalized backward sequence has the minimum makespan for single-armed cluster tools with parallel chambers. To minimize makespan, branch and bound algorithms have been developed for the noncyclic scheduling problem when cluster tools handle consecutive small lots, that is, less than 25 identical wafers.14,15 A schedulability analysis was conducted for noncyclic scheduling of time-constrained cluster tools with processing time variation, 16 for example, start-up transient processes with wafer revisiting. 17 In addition, the Petri net decomposition approach has been applied to noncyclic scheduling of dual-armed cluster tools. 18
In chemical vapor deposition for processing the wafer surface, a wafer must be unloaded immediately after processing by PM. Otherwise, the quality of the wafer’s surface is immediately deteriorated by gas and heat within the PM if the residency time increases. Many related articles about the scheduling of cluster tools consider the residency time constraints of wafers.1,5–8,21 To the best of our knowledge, no attempts have been made for bi-objective minimization of residency time and makespan in the noncyclic scheduling of dual-armed cluster tools. Practitioners always choose the appropriate schedule by considering the tradeoff between makespan and residency time. For example, they attempt to minimize makespan when demands are high to maximize throughput. On the other hand, they attempt to minimize residency time when customers’ demands are low or they are specific orders to satisfy high-quality specification. This is the main motivation of this article. However, the minimization of residency time in the noncyclic scheduling of cluster tools has been extremely difficult due to the increased number of alternative operations. In addition, noncyclic operations may cause a deadlock depending on the controller. The occurrence of deadlock results in seriously reduced throughput and deterioration of product quality. Deadlock-free scheduling is also a key issue in noncyclic scheduling. Noncyclic scheduling methods have been studied based on dispatching rules without considering deadlocks. The authors have addressed a mixed-integer linear programming model for bi-objective optimization of makespan and total wafer residency time. 22 In this article, we propose a mixed-integer formulation of noncyclic scheduling of dual-armed cluster tools that requires less computational effort. A heuristic algorithm to minimize the weighted sum of makespan and total residency time is developed to find a near-optimal solution. The proposed method is applied to the noncyclic scheduling problem with revisiting processes to minimize makespan and residency time. Computational experiments are conducted to demonstrate the performance of the proposed method. The performance of these methods is investigated from computational experiments.
The remainder of this article is organized as follows. We first define the problem description for multi-objective noncyclic scheduling problem for dual-armed cluster tools. The problem is formulated as a mixed-integer linear programming problem. Then, we propose a heuristic algorithm to solve the problem. We show the application to the noncyclic scheduling of cluster tools with revisiting processes. Computational experiments are conducted. Finally, we conclude the article and state future research.
Noncyclic scheduling problem of dual-arm cluster tool with residency time
The scheduling problem of a general structure of dual-armed cluster tool is described in this section.
Scheduling problem of dual-armed cluster tools
We consider a dual-armed cluster tool consisting of four processing modules (PM1-PM4), two LL (LL1, LL2), and a dual-armed TM with fixed 180° angle double picking. A wafer can be transferred between LL and PM or between the PMs. If a wafer is loaded into LL or unloaded from LL, a wafer requires a certain period of duration for changing its pressure. The TM can rotate 360° in two ways where it can hold at most two wafers. We assume that unloading and loading of the TM contain the rotation to its specified target.
For example, for unloading a wafer in PM1, first, the robot arm with no wafer is rotated in front of PM1, and then, it holds a wafer by extending the arm. The series of operations is called unloading. Furthermore, the time required for loading/unloading is assumed to be constant since the difference of the robot arm rotation time is sufficiently small with respect to the processing time of PM. Figure 1 shows one of wafer flow patterns of the dual-armed cluster tools with two LLs, four PMs (PM1–PM4), and a dual-armed TM. All wafers have an identical wafer flow pattern. The wafer flow patterns are classified into a single flow, revisit flow, multi-flow, and so on. We assume a single-wafer flow pattern—LL1 → PM1 → PM2 → LL2 (flow pattern (1))—and a revisiting process—LL1 → PM1 → PM2 → PM1 → PM2 → LL2 (flow pattern (2)). Each LL and each PM can hold only one wafer at the same time. Deadlock is the situation when no wafer can be loaded or unloaded due to lack of resources. A wafer can be transferred between LL and PM or between the PMs. When a wafer is loaded into LL or unloaded from LL, a certain period of time, denoted by

The structure of a dual-armed cluster tool and wafer flow patterns: (a) wafer flow pattern (1) and (b) wafer flow pattern (2).
In a cyclic operation, each TM repeats the identical operational sequence of unloading from PM, loading into PM, unloading from LL, and loading into LL. This is called a swap operation. In noncyclic scheduling, the swap operation is not assumed, but the operational sequence of the TM is derived to minimize the objective function. Once a wafer is loaded in PM, the processing time of
According to the wafer flow pattern, the operational sequence of the TM for one wafer is as follows. A wafer is moved by the TM between modules. For example, when a wafer is transferred from LL1 to PM1, first the wafer is unloaded from LL1 and then the wafer which is held in the TM is loaded to PM1. As explained above, for flow pattern (1), there are six operations by the TM which is performed: unloading from LL1, loading into PM1, unloading from PM1, loading into PM2, unloading from PM2, and loading into LL2.
Formulation of mixed-integer linear programming problem
We develop the mixed-integer linear programming formulation of the noncyclic scheduling problem of a dual-armed cluster tool with two objectives to minimize the makespan
Indices
s: processing order of operations of TM
The operations of the TM for wafer i
The precedence relation between the operations of
Sets
V: set of nodes in the directed graph representing the arm operations.
E: set of arcs in the directed graph representing the sequence of TM operations.
Parameters
N: the number of wafers
Decision variables
Directed graph representation of the operational sequence of the TM
In order to represent a feasible operating sequence of the TM, we construct a directed graph
An example of a directed graph of two wafers is shown in Figure 2. First, all nodes in V are connected with vertical and horizontal arcs as shown in Figure 2(a) by the precedence relations between these operations. Then, each node is connected to the set of nodes that satisfies the feasibility condition with all possible operations. In this case, node

Directed graph representation of the operational sequence of the TM: (a) vertical and horizontal arcs and (b) directed graph of activity sequence for transfer module (TM).
Problem formulation
The mixed-integer programming (IP) formulation of the noncyclic scheduling problem for dual-armed cluster tool is written as follows
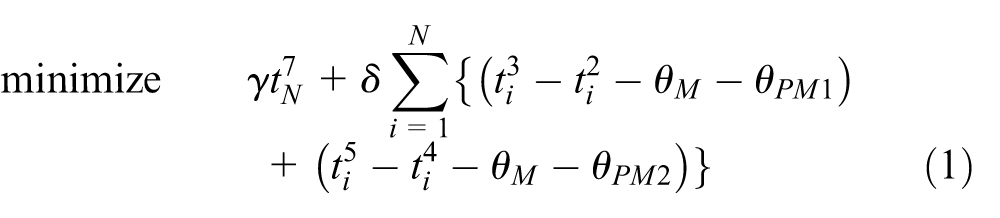
Subject to equations (2)–(21)



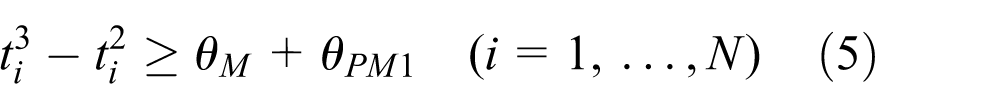

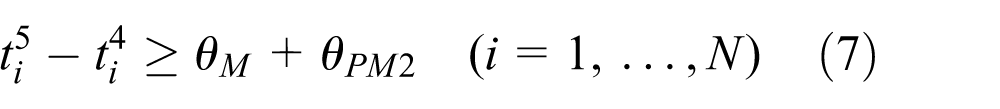







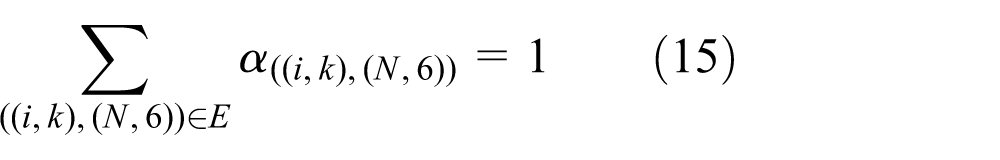




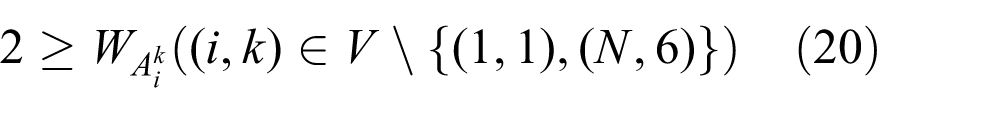

ℕ is the set of nonnegative integers. The objective function (1) is the weighted sum of the makespan and the residency time.


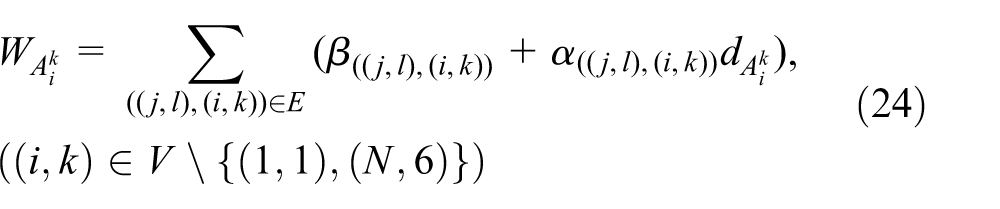
Heuristic algorithm for deadlock-free scheduling problem of cluster tools for minimization of residency time and makespan
General-purpose solvers for solving the mixed-IP formulation can solve only small-scale problems. Because the exact algorithms such as branch and bound cannot solve large-scale instances, we propose a heuristic algorithm to derive a near-optimal solution efficiently. The main idea of the heuristic algorithm is to construct a candidate of solution by two phases. The one is to generate a deadlock-free operational sequence of wafers by Petri net modeling. After a feasible sequence is derived, an optimal schedule is generated by solving linear programming problem with a fixed operational order. In the following sections, the Petri net modeling and deadlock prevention policy are introduced.
Petri net modeling and deadlock prevention policy
Petri net model can be easily applied to any wafer flow and it can prevent deadlock situations by analyzing the specific construction of the Petri net model (siphons, for example). 23 Hence, we use a Petri net model for flow pattern (1). The purpose is to obtain feasible operating sequences of the TM.
Definition of state and events of Petri net
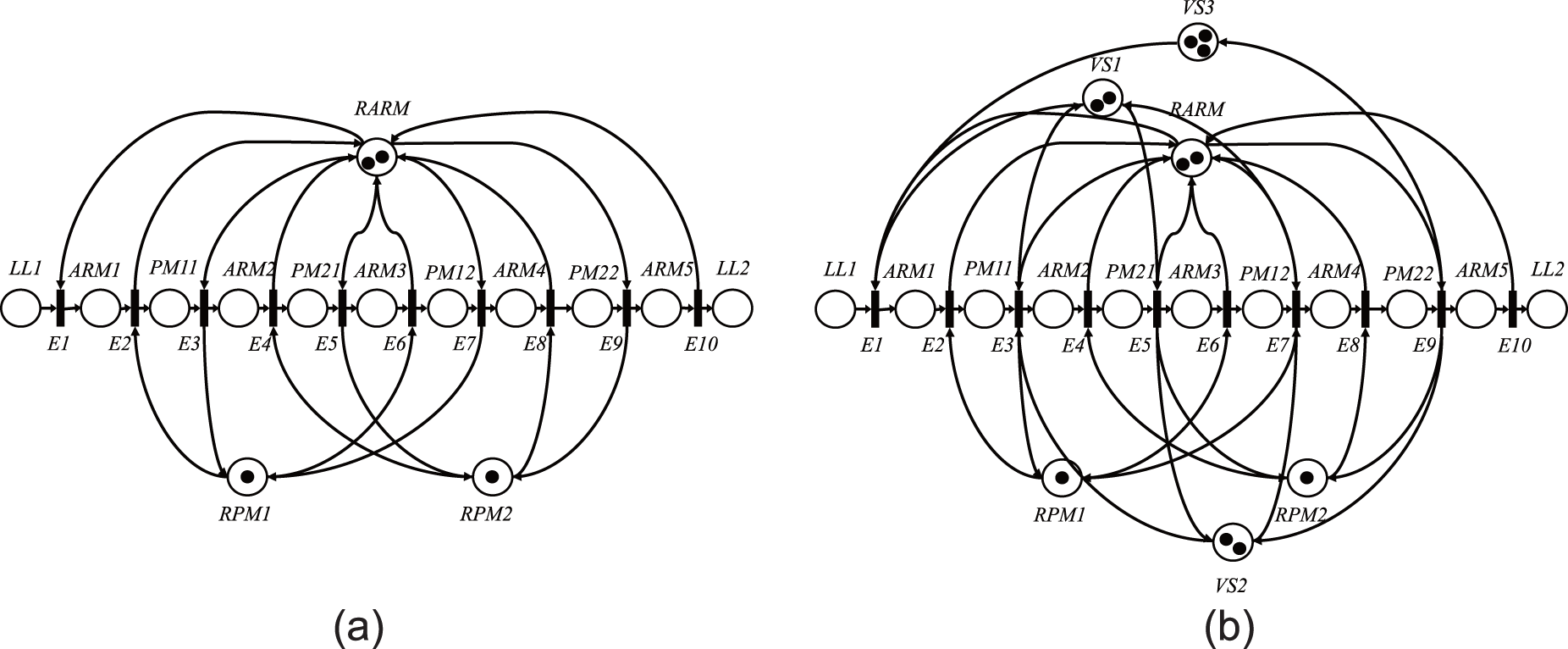
Places, events, and transitions for wafer flow pattern (1) are defined as follows (Table 1).
Symbols of places and transitions for flow pattern (1).

PM: process modules; LL: loadlock modules.
The Petri net model for wafer flow pattern (1), which is denoted by

Deadlock prevention policy
The strict minimum siphon that might lose all tokens is called potential deadlock. If all of the strict minimum siphons of Petri net have no possibility to lose all tokens, the Petri net is deadlock-free. In Zhong and Li,
24
siphons are detected by solving the mixed-integer linear programming problem and the monitor places are introduced to prevent a potential deadlock from losing all tokens in the siphons. It is possible to prevent deadlock of the cluster tools by adding monitor place for all empty siphons of the Petri net model. We apply the deadlock detection policy proposed by Li et al.
25
to our Petri net model
Heuristic algorithm with Petri net simulations
The heuristic algorithm repeats the generation of one feasible operational order of the TM and an optimal timing of operations when the order of operations is fixed. The proposed algorithm is as follows.
Step 0. Set
Step 1. Select the set of the enabled transitions. Then, one transition is randomly chosen and it is fired.
Step 2. Set
Step 3. Fix the feasible operational order of the TM and then determine an optimal timing of firing such that the objective is minimized.
Step 4. Obtain the value of the objective function from the obtained schedule. Save the best one and the best solution.
Steps 1–4 are repeated a specified number of times and then output the best solution. It is the random search, so there is a possibility to obtain the same solution many times, and the resulting solution is not always optimal.
Formulation of starting time calculation when the operation sequence of the arm is fixed
If a feasible operational order of the TM is fixed, then we can obtain the sequence of state transitions. Then, we can define the ith operation of TM as follows.
The formulation is simply written as follows

Subject to equations (26)–(35)
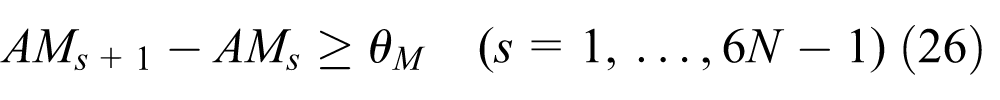



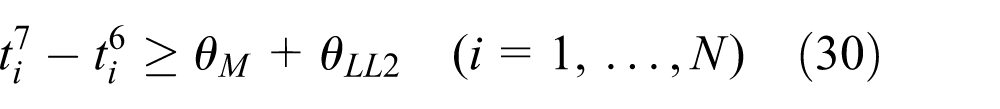





The objective function (25) is the weighted sum of the total completion time and the total residency time.
Reduction of arcs in the directed graph in section “Formation of mixed-integer linear programming”
We consider the redundancy of the directed graph for configuring IP formulation. The directed graph represents all feasible operational sequences of the TM. However, in order to obtain only the optimal solution efficiently, we restrict the number of diagonal arcs in the graph. The diagonal arcs in the graph of Figure 2(b) can be reduced. If the arcs are not adopted in a number of solutions, we do not have to connect them from the beginning of the graph construction phase because these solutions using these arcs are not optimal. From the exact solutions obtained from the IP, the arcs to be adopted as a solution are analyzed. A node
Application to noncyclic scheduling problem with revisiting processes
We apply the proposed method to the noncyclic scheduling problem of dual-armed cluster tools with revisiting process. In the revisiting process, wafer visits some processing modules for multiple times. It is more challenging to solve the noncyclic scheduling problem with revisiting process.
Petri net modeling
We consider the wafer flow pattern
Symbols for places and transitions for flow pattern (2).

PM: process modules; LL: loadlock modules.
The Petri net
The number of reachable states for

From the results of Table 3, the number of reachable markings for
Formulation of starting time calculation for revisit process
The starting time of operations are computed by solving the linear programming problem
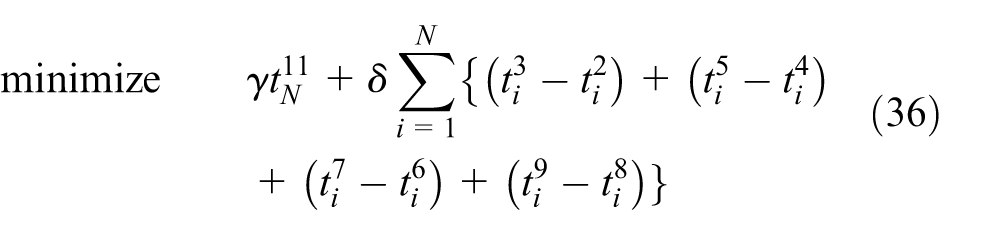
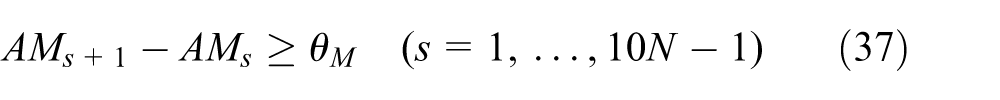





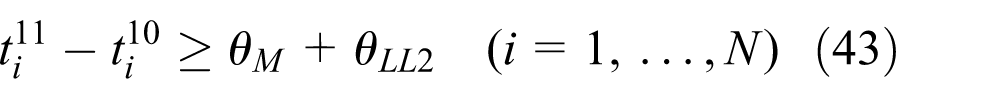
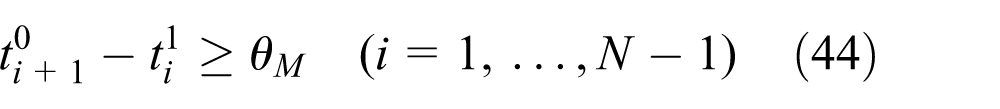


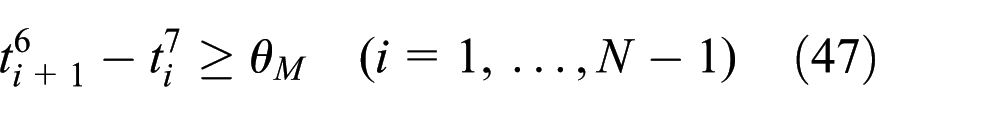



where
Computational experiments
Computational experiments are conducted to show the performance of the proposed method. The parameters are selected as
Effects of multi-objective optimization
First, we compare the solutions of the heuristic algorithm to minimize only
Computational results of the proposed method.

For flow pattern (1), the total residency time of CASE 2 is significantly decreased from that of CASE 1 by the minimization of both objectives
Effects of reduction of arcs in the exact algorithm
The IP formulation and the reduced IP formulation are compared. The computational results are shown in Table 5. We set parameters to
Computational results of IP and reduced IP for flow pattern (1).

IP: integer programming.
From Table 5, we can see that the reduced IP can obtain an optimal solution in a short computation time less than that of IP. Moreover, although IP cannot obtain a solution of eight wafers in CASE 2, the reduced IP can obtain an optimal solution of eight wafers. The reduced IP can reduce the computation time and the application ranges.
Comparison of the performance of IP and the proposed method
The computational results of flow patterns (1) and (2) by the heuristic method in the previous section (hereafter called proposed method) and IP are compared. In IP, a general-purpose solver (CPLEX 12.6) was used to solve the mixed-IP models. Tables 6 and 7 show the comparison of the performance of those methods for flow patterns (1) and (2) when the number of wafer is changed from 4 to 25. The number of iterations is 10,000 in the proposed method.
Computational results of IP and the proposed method for flow pattern (1) (CASE 1:

IP: integer programming.
Computational results of IP and the proposed method for flow pattern (2) (CASE 1:

IP: integer programming.
For both wafer flows, the makespan obtained by CASE 2 is nearly the same as that of CASE 1. It is worthwhile to minimize makespan and residency time in the objective function. The computation time of the exact algorithm with CPLEX increases drastically with an increasing number of wafers. Therefore, IP cannot obtain even a feasible solution for 25 wafer problems in both cases due to insufficient memory. For wafer flow (2), CPLEX cannot solve the problems with greater than six wafers because there are too many binary variables in the IP models. The proposed method can derive solutions that are close to optimal for small-scale problems. The total computation time of the proposed method is independent of the number of iterations and even an increasing number of wafers. We can obtain a better solution without requiring a large amount of computation time. The performance of the solutions obtained by the proposed method is close to the optimal solution derived by CPLEX. The formulation of the proposed method is simple because the operating sequence of the TM is obtained by Petri net simulation. Then, the total computation time of the proposed method is less sensitive to the influence of the number of wafers. From these results, the effectiveness of the proposed method is confirmed.
Conclusion
In this study, we have proposed a heuristic algorithm for noncyclic scheduling of dual-armed cluster tools with revisiting processes to minimize wafer residency time and makespan. A Petri net model was used to generate a feasible operational order without deadlocks. The maximally permissive deadlock prevention policy has been derived from the original Petri net models. If the operational order is fixed, the scheduling problem is formulated as a linear programming problem to minimize makespan and total residency time. In the proposed method, the generation of a feasible sequence and solving the linear programming problem are repeated with Petri net simulations to minimize the objective functions. The performance of the proposed method was compared to that of CPLEX. The results demonstrated that total residency time can be reduced without reducing the performance of the makespan. The computation time of the proposed method is much less than that of CPLEX. Thus, the effectiveness of the proposed method has been confirmed. In future, we will investigate the proposed method for more complex cluster tools such as multi-cluster tools.
Footnotes
Acknowledgements
The authors would like to thank anonymous reviewers for their valuable suggestions and comments to improve this article.
Academic Editor: Wu Naiqi
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is partially supported by TEPCO Memorial Foundation.