
Abstract
It is very difficult to schedule a single-arm cluster tool with wafer revisiting such that wafer residency time constraints are satisfied. This article conducts a study on this challenging problem for a single-arm cluster tool with atomic layer deposition process. With a so-called p-backward strategy being applied, a Petri net model is developed to describe the dynamic behavior of the system. Based on the model, the existence of a feasible schedule is analyzed, schedulability conditions are derived, and scheduling algorithms are presented if there is a schedule. A schedule is obtained by simply setting the robot waiting time if schedulable, and it is very computationally efficient. The obtained schedule is shown to be optimal. Illustrative examples are given to demonstrate the proposed approach.
Introduction
In semiconductor manufacturing, cluster tools that adopt single-wafer processing technology are widely used in wafer processing for better quality control and lead time reduction. A typical cluster tool is configured with several process modules (PMs), a wafer handling robot, and two loadlocks for wafer loading and unloading. According to the number of arms equipped for the robot, a cluster tool is called a single-arm or dual-arm cluster tool as shown in Figure 1.
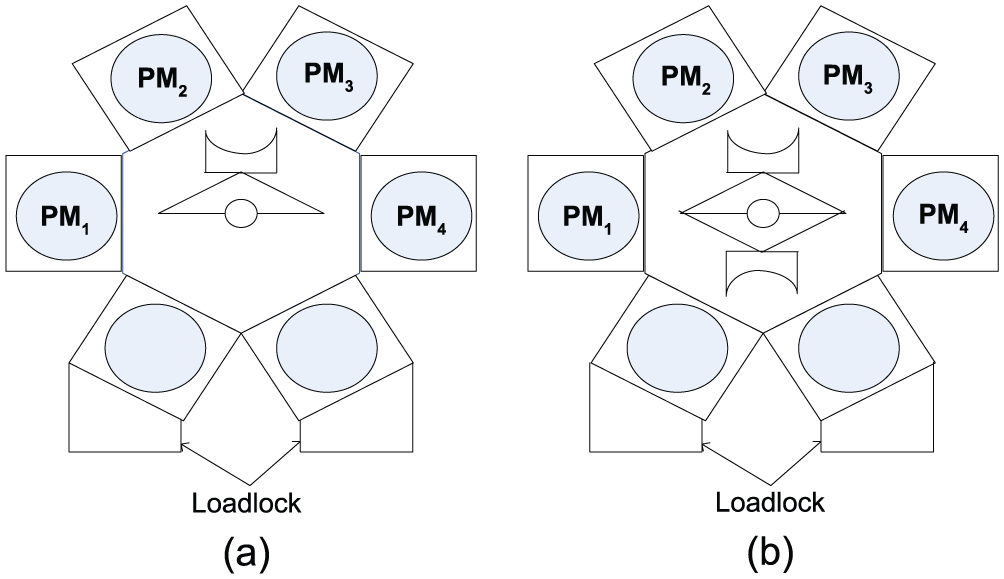
Cluster tools: (a) single-arm robot and (b) dual-arm robot.
With two loadlocks, a cluster tool can operate uninterruptedly under steady state. Under the steady state, extensive studies have been done for modeling, performance evaluation, and scheduling of both cluster tools1–7 and multi-cluster tools.8–13 Under the steady state, if wafer processing time dominates the process, then a cluster tool is called to be process-bound, while it is called to be transport-bound if the robot is always busy. According to Kim et al., 14 the time taken for the robot to move from one step to another can be treated as the same and is much shorter than the wafer processing time. In this case, a cluster tool operates in the process-bound region such that a backward scheduling strategy is optimal for a single-arm tool15,16 and a swap scheduling strategy is optimal for a dual-arm tool. 5
The afore-mentioned studies are conducted under the assumption that there is no constraint on the wafer sojourn time in a PM. For some wafer fabrication processes, such as low-pressure chemical-vapor deposition, there are strict wafer residency time constraints which require that a wafer should be removed from a PM within a given time after it is processed.14,17–23 Without any intermediate buffer between the PMs, the scheduling problem of cluster tools with residency time constraints is very complex and challenging. The scheduling problem of cluster tools with wafer residency time constraints is studied and techniques are developed to find an optimal periodical schedule.14,17 To improve computational efficiency, this problem is further tackled for both single-arm and dual-arm cluster tools using schedulability analysis and closed-form solution methods are presented.24,25 They present a so-called robot waiting method. By this method, a schedule is parameterized by robot waiting time and can be obtained by setting the robot waiting time.
The above-mentioned work is done for wafer fabrication processes with no wafer revisiting. Some wafer fabrication processes, such as the atomic layer deposition (ALD) process, require that a wafer should be processed by some processing steps more than once, leading to a revisiting process.26–31 With wafer revisiting, a cluster tool is no longer a flow-shop and methods developed for scheduling tools without wafer revisiting are not applicable. As shown in Wu et al., 26 for a dual-arm cluster tool with wafer revisiting, a three-wafer cyclic schedule is obtained if a swap strategy is applied and the system may never reach a steady state. Furthermore, with wafer revisiting, a cluster tool is deadlock-prone, which further complicates the scheduling problem of a cluster tool. Lee and Lee 28 pioneer the study of scheduling single-arm cluster tools with wafer revisiting. They model the system by a Petri net (PN) and the scheduling problem is then formulated as a mixed integer programming to find an optimal periodical schedule. Following the work in Lee and Lee, 28 Wu et al. 29 develop a maximally permissive deadlock-avoidance policy for a single-arm cluster tool with the ALD process. Based on the model and the control policy, it is shown that, to find an optimal schedule, one needs to examine several schedules only. Based on this finding, analytical expressions are proposed to find the optimal schedule by selecting the best one from these schedules. For dual-arm cluster tools with wafer revisiting, a method is presented to obtain a two-wafer cyclic schedule that is better than a three-wafer schedule. 27 Since a one-wafer cyclic schedule is easy to implement and control, this problem is further investigated and a modified swap strategy is proposed to obtain a one-wafer periodical schedule. 30 It is shown that such a schedule can reach the lower bound of cycle time. The scheduling problem of dual-arm cluster tools with both wafer revisiting and residency time constraints is studied and effective techniques are proposed to find an optimal one-wafer cyclic schedule. 31
However, to the best knowledge of the authors, up to now, no study has been done on the scheduling problem of single-arm cluster tools with both wafer revisiting and wafer residency time constraints. Note that it is more difficult to avoid deadlock for a single-arm cluster tool with wafer revisiting than for a dual-arm tool. Thus, scheduling single-arm cluster tools with both wafer revisiting and wafer residency time constraints is more complicated. The aim of this work is to cope with this challenging problem for a single-arm cluster tool. The problem is modeled by a PN using a p-backward strategy explained later. With the model, analysis on the existence of a feasible schedule is carried out and conditions under which a schedule exists are presented. If it is schedulable, a schedule is very efficiently obtained by simply setting the robot waiting time. The obtained schedule is shown to be optimal in terms of cycle time.
In the next section, we develop the PN model for the system. Based on it, Section “System scheduling” carries out the schedulability analysis, establishes the schedulability conditions, and presents scheduling algorithms to obtain the optimal schedule. Then, in the following section, illustrative examples are used to demonstrate the proposed method. Finally, Section “Conclusion” concludes this work.
Modeling by PN
PNs are recognized as a powerful tool for dealing with concurrent activities and resource allocation. They are widely used for modeling, analysis, and control of manufacturing systems.32–38 This work adopts PN to model the dynamic behavior of a single-arm cluster tool with both wafer residency time constraints and wafer revisiting.
Finite capacity PN
Scheduling a cluster tool is to effectively allocate its limited resources to tasks. To do so, this work adopts the resource-oriented PN (ROPN)39–42 to model the system. It is a finite capacity PN and its basic concept is based on Wu and Zhou
42
and Murata.
43
It is denoted as PN = (P, T, I, O, M, K), where P and T are finite sets of places and transitions with P∩T = ∅ and P∪T ≠ ∅; I: P × T →
Let •t = {p: p ∈ P and I(p, t) > 0} be the pre-set of transition t and t• = {p: p ∈ P and O(p, t) > 0} be its post-set. Similarly, p’s pre-set •p = {t ∈ T: O(p, t) > 0} and post-set p• = {t ∈ T: I(p, t) > 0}. Then, the transition enabling and firing rules are defined as follows.
Definition 2.1
A transition t ∈ T in a finite capacity PN is said to be enabled if the following conditions are satisfied

and

By Definition 2.1, when Condition (1) is met, t is said to be process-enabled, and while Condition (2) is met, t is said to be resource-enabled. Thus, t is enabled if it is both process- and resource-enabled.
An enabled t ∈ T at marking M can fire. The firing of t transforms the PN from M to M′ according to
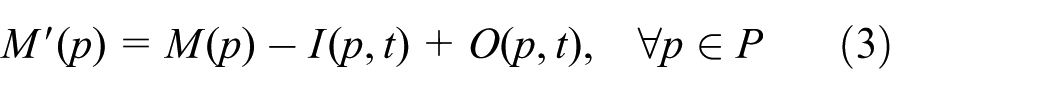
Modeling activity sequences
In wafer fabrication, ALD is a typical revisiting process and, as done in Wu et al., 29 this work focuses on the ALD process. In an ALD, a wafer visits Step 1 first and then it goes to Steps 2 and 3 sequentially for processing. After being processed by Step 3, it goes back to Steps 2 and 3. This process is repeated for several times. To control the quality, every time the wafer visits Steps 2 and 3, the exactly same processing environment is required. To ensure the processing environment requirement, each step is configured with only one PM. We assume that PM i is configured for Step i. Thus, as presented in Wu et al., 29 the wafer flow pattern for this process can be denoted as (PM1, (PM2, PM3) h , PM4) with (PM2, PM3) h being the revisiting process and h ≥ 2. For the simplicity of presentation, this work focuses on the case when h = 2. Note that the obtained results with h = 2 can be extended to cases with h > 2. Then, a single-arm cluster tool with both wafer residency time constraints and wafer revisiting is modeled by an ROPN as follows.
Let

PN model for the system with wafer flow pattern (PM1, (PM2, PM3) h , PM4).
With the resources in the system being modeled, transitions are used to model the material flows. Timed transition tij, i, j ∈
With the developed PN structure, by putting a V-token representing a virtual wafer, the initial marking M0 is set as follows. Set M0(pi) = 1, i ∈
With wafer revisiting process, there are two ways for a token in q33 to go, one is to q21 by firing t32 and the other is to q41 by firing t34, leading to a conflict. To eliminate such a conflict, colors are introduced to the model to form a colored PN as follows.
Definition 2.2
Transition ti in the PN is defined to have a unique color C(ti) = ci.
By Definition 2.2, the colors of t32 and t34 are c32 and c34, respectively. Let Wd(g) be the dth wafer released into the system and being processed for the gth time by a PM. Then, we can define the color of a token as follows.
Definition 2.3
Define the color of a token Wd in q33 as C(q33, Wd) = c3j if it will go to Step j for processing when it leaves q33.
By Definition 2.3, we have C(q33, Wd(q)) =C(t32) = c32, 1 ≤ q < h, and (q33, Wd(h)) = C(t34)= c34. Note that in the model, only q33 has multiple output transitions. Hence, by Definitions 2.2 and 2.3, conflict is eliminated. Besides conflict, deadlock is an important issue for operating a single-arm tool with wafer revisiting. To avoid deadlock, we present a control policy by the following definition.
Definition 2.4
At any marking M, transition y20 is control-enabled only if the transition firing sequence t12 → s21 has just been performed; y03 is control-enabled only if s01 has just fired; y14 is control-enabled only if s11 has just fired; y42 is control-enabled only if s41 has just fired; y22 is control-enabled only if the transition firing sequence t32 → s21 has just been performed; y33 is control-enabled only if the transition firing sequence y42 → s22 → t23 → s31 has just been performed; and y31 is enabled only if the transition firing sequence t32 → s21 → y22 → s22 → t23 → s31 has just been performed.
Let M = (S1, S2, S3, S4) represent the marking of the system, where Si represents the state at Step i, i ∈
Task time modeling
In order to schedule the process, it is necessary to model the time taken for performing each activity. From the PN model, both transitions and places represent tasks that take time. As done in Lee and Lee
28
and Wu et al.,
29
we assume that the time taken for each activity is deterministic and known. The time taken for the robot to move from Steps i to j, i ≠ j, with or without holding a wafer is assumed to be same
14
and denoted by µ, that is, it takes µ time units to fire tij and yij. Note that in the revisiting process, after loading a wafer into p3/p2, the robot waits there for the completion of the wafer and it does nothing and takes no time. Similarly, the time taken for the robot to unload (firing si2)/load (firing si1), a wafer from/into a step is assumed to be the same as well and it is denoted by λ. The time taken for processing a wafer in pi, i ∈
Let δi be the longest time for which a wafer can stay in a PM at Step i without being scrapped after being processed. Then, with wafer residency time constraints, the wafer sojourn time at Step i should be within [αi, αi+δi], that is, a token should stay in PM
i
for at least αi time units and no more than αi+δi time units. We use τ1 and τ4 to denote the wafer sojourn time at Steps 1 and 4, respectively; and τ2j and τ3j, j ∈
Time durations associated with transitions and places.

From the above analysis, for a single-arm cluster tool with wafer revisiting and residency time constraints, according to Wu et al.24,29 we have the following schedulability definition.
Definition 2.5
Given the wafer sojourn time interval [αi, αi+δi] for Step i, i ∈
System scheduling
In Wu et al., 29 a p-backward strategy is proposed to schedule a single-arm cluster tool for the ALD process without taking wafer residency time constrains into account. Based on the PN model, this work adopts this strategy to explore the schedulability and scheduling problem of a single-arm cluster tool with residency time constraints for the ALD process. If schedulable, efficient algorithm is developed to find an optimal schedule.
P-backward scheduling
To make the scheduling analysis, we need to present the p-backward scheduling strategy for a single-arm cluster tool with wafer revisiting. Based on the PN model, we show how a p-backward strategy works. Since a single-arm cluster tool with wafer revisiting is deadlock-prone, to avoid deadlock, the system must start from a proper state. We assume that the system starts from marking M1 = ({null}, {W3(1)}, {W2(2)}, {W1(1)}) and, at the same time, the robot is idle, or M1(r) = 1. Note that this marking is consistence with M0 that is set in the last section and can be reached by applying a p-backward strategy. By starting from M1 with a p-backward strategy being applied, the system evolves as follows.
Step 1: Transition firing sequence σ1 = 〈firing y20 → s02 → t01 → s11〉 (the robot goes to the loadlocks from PM2 → waits in q02 → unloads W4 there → moves to PM1 → loads W4 into PM1) is performed such that W4(1) is put into Step 1. By doing so, it transforms the system from M1 to M2 = ({W4(1)}, {W3(1)}, {W2(2}, {W1(1)}).
Step 2: Transition firing sequence σ2 = 〈firing y14 → waiting in q42 → s42 → t40 → s01〉 (the robot goes to PM4 from PM1 → waits in q42 → unloads W1 there → moves to the loadlocks → loads W1 into the loadlocks) is performed such that M3 = ({W4(1)}, {W3(1)}, {W2(2)}, {null}) is reached.
Step 3: Transition firing sequence σ3 = 〈firing y03 → waiting in q32 → s32 → t34 → s41〉 (the robot goes to PM3 from the loadlocks → waits in q32 → unloads W2 there → moves to PM4 → loads W2 into PM4) is performed such that M4 = ({W4(1)}, {W3(1)}, {null}, {W2(1)}) is reached.
Step 4: Transition firing sequence σ4 = 〈firing y42 → waiting in q22 → s22 → t23 → s31〉 (the robot goes to PM2 from PM4 → waits in q22 → unloads W3 there → moves to PM3 → loads W3 into PM3) is performed such that M5 = ({W4(1)}, {null}, {W3(1)}, {W2(1)}) is reached.
Step 5: Transition firing sequence σ5 = 〈firing y33 → waiting q32 → s32 → t32 → s21〉 (the robot stays at PM3 → waits in q32 → unloads W3 there → moves to PM2 → loads W3 into PM2) is performed such that M6 = ({W4(1)}, {W3(2)}, {null}, {W2(1)}) is reached.
Step 6: Transition firing sequence σ6 = 〈firing y22 → waiting q22 → s22 → t23 → s31〉 (the robot stays at PM2 → waits in q22 → unloads W3 there → moves to PM3 → loads W3 into PM3) is performed such that M7 = ({W4(1)}, {null}, {W3(2)}, {W2(1)}) is reached.
Step 7: Transition firing sequence σ7 = 〈firing y31 → waiting in q12 → s12 → t12 → s21〉 (the robot goes to PM1 from PM3 → waits in q12 → unloads W4 there → moves to PM2 → loads W4 into PM2) is performed such that M8 = ({null}, {W4(1)}, {W3(2)}, {W2(1)}) is reached.
Note that marking M8 is equivalent to M1 in the sense of dynamic behavior of PN. Hence, by transforming M1 to M8, a cycle is completed. This is what a p-backward strategy does. With the PN model, it is easy to understand the scheduling strategy.
Cycle time analysis
With the above discussion, we can analyze the cycle time for the system. Let φj be the time taken for the robot to perform σj, j ∈
Since σ1–7 form a robot cycle, the robot cycle time is as follows
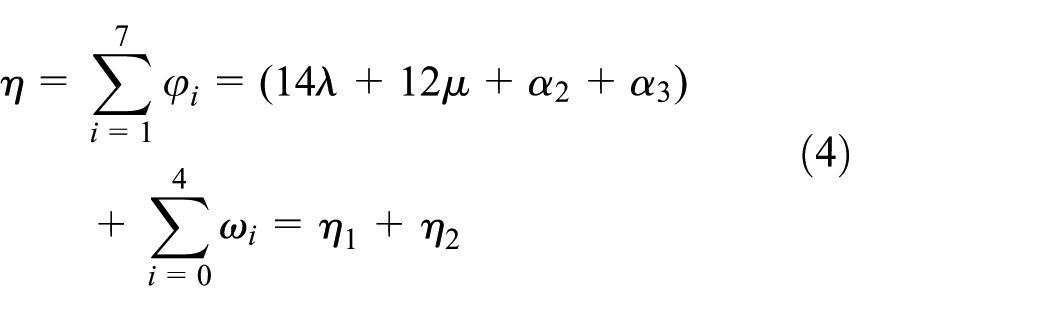
where η1 = 14λ+12µ+α2+α3 is the robot task time in a cycle and
Based on the fact that the cycle time of the entire system must be equal to the robot cycle time, 24 with the robot cycle time obtained, we can analyze the wafer sojourn time at each step. It follows from the above analysis that the wafer sojourn time at Step 1 is equal to the robot cycle time minus the time taken for performing σ1 and the time for firing s12, t12, and s21 in σ7, that is, we have

Similarly, for Step 4, we have

For Step 2, the sojourn time taken for a wafer to visit the step for the first time is different from that for a wafer to visit the step for the second time. We use τ21 and τ22 to denote them, respectively. It follows from the above transition firing analysis that τ21 is equal to the robot cycle time minus the time taken for σ5–7 and the time taken for firing s22, t23, and s31 in σ4. Thus, we have
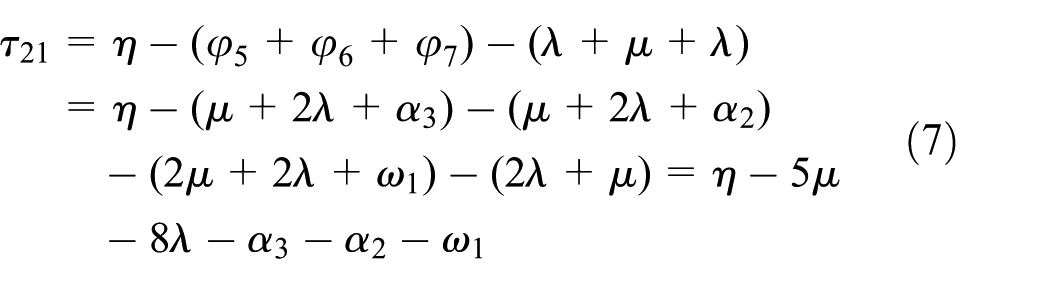
When a wafer visits Step 2 for the second time, the robot loads it into PM2 and waits here for its completion. Thus, we have

Similarly, we can calculate the wafer sojourn time for Step 3 and we have
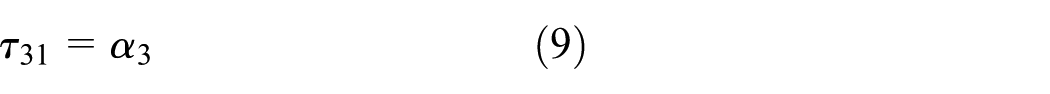

With wafer residency time constraints, to make a schedule feasible, the cycle time for each step should be in a permissive range. Thus, we analyze such a range for each step as follows. For Step 1, it follows from the above analysis that to complete a wafer requires three robot moving tasks between steps (t01, t12, and y21), two wafer unloading tasks (s02 and s12), and two wafer loading tasks (s11 and s21). Thus, with the wafer staying time in Step 1, the time taken for this process is as follows

To be feasible, we have τ1 ∈ [α1, α1+δ1]. Hence, the permissive shortest cycle time at Step 1 is as follows

and the permissive longest cycle time at Step 1 is as follows

Similarly, the cycle time for completing a wafer at Step 4 is as follows

The permissive shortest cycle at Step 4 is as follows

and the permissive longest cycle time at Step 4 is as follows

For Step 2 in the revisiting process, we analyze the wafer cycle as follows. By firing s21 (σ8 = 〈s21 (λ)〉), a wafer is loaded into Step 2 for processing for the first time, which is followed by transition firing sequence σ9 = 〈y20 → s02 → t01 → s11 → y14 → s42 → t40 → s01 → y03 → s32 → t34 → s41 → y42〉. During the time for performing σ9, the wafer just loaded into Step 2 is being processed. Hence, the time taken for performing σ9 is the wafer sojourn time for the first visiting Step 2, that is, τ21. Then, transition firing sequence σ10 = 〈t23 (µ) → s31 (λ) → y33 (0) → waiting for the completion at Step 3 (α3) → s32 (λ) → t32 (µ) → s21 (λ) (loading the wafer into Step 2 to be processed for the second time) → y22 (0) → waiting for the completion of the wafer at Step 2 (τ22) → s22 (λ) → t23 (µ) → s31 (λ) → y31 (µ) → waiting in q12 (ω1) → s12 (λ) → t12 (µ)〉 is performed. By performing σ8–10, a cycle is completed at Step 2. Thus, the time taken for completing a wafer at Step 2 is as follows
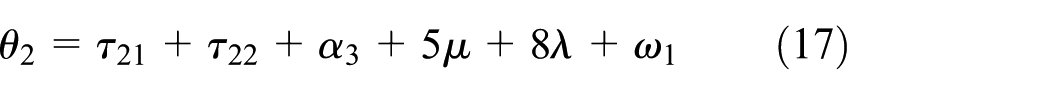
With τ21 ∈ [α2, α2+δ2] and τ22 = α2, the permissive shortest cycle at Step 2 is as follows
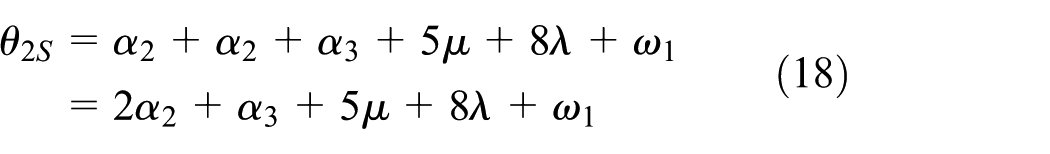
and the permissive longest cycle time at Step 2 is as follows

For Step 3, similar to Step 2, we analyze the process as follows. We have the following transition firing sequence σ11 = 〈s31 (a wafer is loaded into Step 3 to be processed for the first time, λ) → y33 (0) → waiting for the completion of the wafer at Step 3 (τ31) → s32 (λ) → t32 (µ) → s21 (λ) → y22 (0) → waiting for the completion of the wafer at Step 2 (α2) → s22 (λ) → t23 (µ) → s31 (λ)〉. Then, transition firing sequence σ12 = 〈y31 → s12 → t12 → s21 → y20 → s02 → t01 → s11 → y14 → s42 → t40 → s01 → y03〉 is performed. During the time for performing σ12, a wafer for its second visiting of Step 3 is completed. Thus, the time taken for doing so is τ32. Finally, to complete a cycle, transition firing sequence σ13 = 〈s32 (λ) → t34 (µ) → s41 (λ) → y42 (µ) → waiting in q22 (ω2) → s22 (λ) → t23 (µ)〉 is performed. Thus, the cycle time for Step 3 is as follows

With τ31 = α3 and τ32 ∈ [α3, α3+δ3], the permissive shortest cycle at Step 3 is as follows

and the permissive longest cycle time at Step 3 is as follows
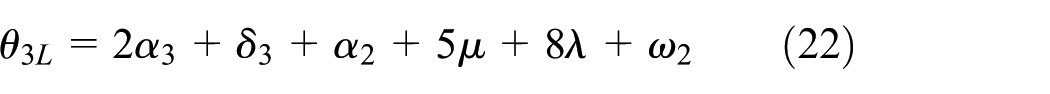
With the above timeliness analysis, we discuss the scheduling problem next. Note that the above-derived expressions are functions of robot waiting time. Hence, the scheduling problem is to decide the robot waiting time ωi’s to obtain a schedule if it exists.
Schedulability and scheduling algorithm
Let θ be the production cycle time of the system. Then, the production cycle time for all the steps must be θ. Also, the robot cycle time should be equal to the production cycle time too, that is, we have

Based on the above analysis, to make equation (23) hold, we need to decide ωi’s in η2. Also, to schedule a cluster tool, the production rate should be maximized, which requires to minimize η2. Furthermore, with wafer residency time constraints, schedule feasibility is essential. To be feasible, a schedule should ensure that θi is in an acceptable interval. Let πiL and πiU denote the lower and upper bounds of θi. It follows from the above analysis that when ω0 = ω1 = ω2 = ω3 = ω4 = 0, θiS and θiL are the lower and upper bounds of θi, respectively. Thus, by removing the robot waiting time from equations (12), (13), (15), (16), (18), (19), (21), and (22), we have the following lower and upper bounds of θi

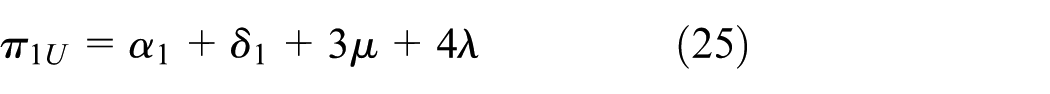


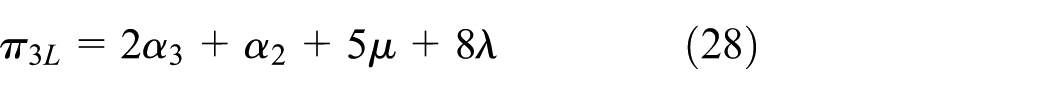


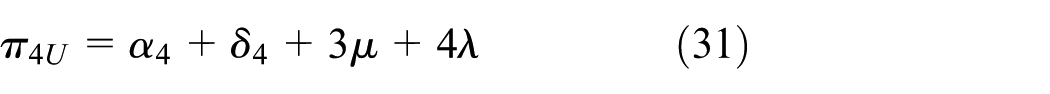
Let πLmax = max{πiL, i ∈
Lemma 1
If η1 > πUmin, the system is not schedulable.
Proof
It follows from the above discussion that θ = η ≥ η1. When η = η1, we have ω0 = ω1 = ω2 = ω3 = ω4 = 0. In this case, if πUmin = πkU, k ∈ {1, 4}, by equations (5) and (6), we have τk = η1 − 3µ − 4λ > πkU − 3µ − 4λ = αk+δk+3µ+4λ − 3µ − 4λ = αk+δk. This implies that the wafer residency time constraints are violated for Step k, k ∈ {1, 4}. If πUmin = π2U, by equation (7), we have τ21 = η1 − 5µ − 8λ − α3 − α2 > π2U − 5µ − 8λ − α3 − α2 = 2α2+δ2+α3+5µ+8λ − 5µ − 8λ − α3 − α2 = α2+δ2. Hence, the wafer residency time constraints are violated for Step 2. If πUmin = π3U, by equation (7), we have τ32 = η1 − 5µ − 8λ − α3 − α2 > π3U − 5µ − 8λ − α3 − α2 = 2α3+δ3+α2+5µ+8λ − 5µ − 8λ − α3 − α2 = α3+δ3. The wafer residency time constraints are violated for Step 3.
Then, we discuss the case when η > η1. In this case, we have
This lemma shows that if the robot cycle time is longer than the upper bound of cycle time for any step, then the system is not schedulable. Next, we discuss the schedulability and scheduling problem when η1 ≤ πUmin. We have the following two cases
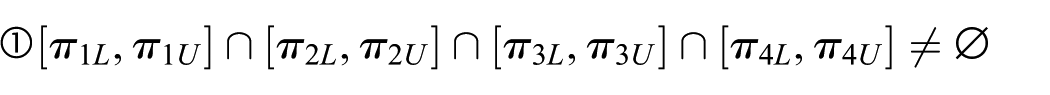

For Case 1, we have the following lemmas.
Lemma 2
If η1 < πLmax, let ω0 = ω1 = ω2 = ω3 = 0 and ω4 = πLmax − η1, the obtained schedule is feasible.
Proof
By the obtained schedule, the cycle time for the tool is θ = η = πLmax. In this case, we have πiL ≤ θ = η = πLmax ≤ πiU, i ∈
For the case that there is an overlap for the permissive cycle time ranges of all the steps, Lemma 2 shows that if the robot cycle time is shorter than the lower bound of cycle time for the step that has the largest lower bound of cycle time, then the system is schedulable. In this case, the robot has idle time and it should wait at the loadlocks.
Lemma 3
If πLmax ≤ η1 ≤ πUmin, set ω0 = ω1 = ω2 = ω3 = ω4 = 0, the obtained schedule is feasible.
Proof
In this case, the cycle time θ = η = η1. Then, for Step i, i ∈ {1, 4}, we have τi = η1 − 3µ − 4λ ≥ πiL − 3µ − 4λ = αi and τi = η1 − 3µ − 4λ ≤ πiU − 3µ − 4λ = αi+δi. For Step 2, we have τ21 = η1 − 5µ − 8λ − α3 − α2 ≥ π2L − 5µ − 8λ − α3 − α2 = α2 and τ21 = η1 − 5µ − 8λ − α3 − α2 ≤ π2U − 5µ − 8λ − α3 − α2 = α2+δ2, and τ22 = α2. For Step 3, we have τ31 = α3, and τ32 = η1 − 5µ − 8λ − α3 − α2 ≥ π3L − 5µ − 8λ − α3 − α2 = α3 and τ32 = η1 − 5µ − 8λ − α3 − α2 ≤ π3U − 5µ − 8λ − α3 − α2 = α3+δ3. Thus, for all the steps, the wafer residency time constraints are satisfied and the obtained schedule is feasible.
For the case that there is an overlap for the permissive cycle time ranges of all the steps, Lemma 3 shows that if the robot cycle time is in the overlap range, the system is schedulable and the robot do not need to wait anywhere.
For Case 2, there must exist at least one i ∈

Then, we have the following lemma.
Lemma 4
For the case of [π1L, π1U]∩[π2L, π2U]∩[π3L, π3U]∩[π4L, π4U] = ∅, let
Proof
We first show that when ω4 ≥ 0, the obtained schedule is feasible. It follows from equation (32) and
Now we show that the system is not schedulable if ω4 < 0. When ω4 < 0, the obtained schedule is meaningless, or we cannot find a feasible schedule such that θ = η = πLmax. Then, there are two choices: (1) η < πLmax and (2) η > πLmax.
If η < πLmax, we assume that πiL = πLmax, i ∈
If η > πLmax, we assume that η = πLmax+Δη and φi − 1 = ωi − 1+Δωi − 1, where ωi − 1 is obtained via equation (32), i ∈

If πiL = πLmax, i ∈
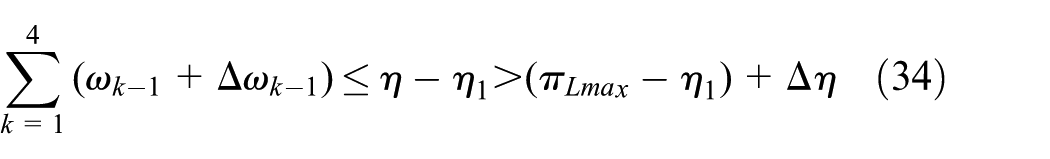
This contradicts to equation (33), that is, a feasible schedule cannot be found.
For the case that there is not an overlap for the permissive cycle time ranges of all the steps, Lemma 4 shows that if the robot has enough idle time (ω4 ≥ 0), the system is still schedulable, otherwise it is not schedulable.
Up to now, we present the conditions under which a feasible schedule can be found for a single-cluster tool with wafer revisiting and residency time constraints. Note that, by above analysis, for each case, we present a schedule, and then check its feasibility. Thus, if a feasible schedule exists, a feasible schedule can be found by simply setting the robot waiting time. In summary, an algorithm is presented as follows to find a schedule if it exists.
Algorithm 1
Find a feasible schedule for a single-arm cluster tool with wafer residency time constraints for an ALD process as follows:
Step 1: Let Q = 1 and calculate the value of η1, πiL, and πiU, i ∈
Step 2: For the case of [π1L,π1U]∩[π2L,π2U]∩[π3L,π3U]∩[π4L,π4U] ≠ ∅ do If η1 < πLmax, set ω0 = ω1 = ω2 = ω3 = 0 and ω4 = πLmax − η1 to obtain a feasible schedule; If πLmax ≤ η1 ≤ πUmin, set ω0 = ω1 = ω2 = ω3 = ω4 = 0 to obtain a feasible schedule.
Step 3: For the case of [π1L, π1U]∩[π2L, π2U]∩[π3L, π3U]∩[π4L, π4U] = ∅, set ωi, i ∈ If ω4 ≥ 0, a feasible schedule is obtained; If ω4 < 0, set Q = 0.
Step 4: Stop and return Q and a schedule if one is found.
By Algorithm 1, only simple calculation is needed such that the proposed method is computationally very efficient. Another issue for scheduling problem is its productivity. The following theorem shows the optimality of the proposed method.
Theorem 1
If the system is schedulable, the obtained schedule by the methods given in Lemmas 2–4 is optimal in terms of productivity.
Proof
Let πiL = πLmax, i ∈
Illustrative examples
This section uses examples with wafer flow pattern (PM1, (PM2, PM3)2, PM4) to show the proposed method.
Example 1
The wafer processing time at PM1–4 is α1 = 120 s, α2 = 40 s, α3 = 45 s, and α4 = 125 s, respectively. After a wafer is completed, it can stay in PM1–4 for at most δ1 = 30 s, δ2 = 20 s, δ3 = 20 s, and δ4 = 30 s, respectively. The robot task time is λ = µ = 3 s.
For this example, we have π1L = 141 s, π1U = 171 s, π2L = 164 s, π2U = 184 s, π3L = 169 s, π3U = 189 s, π4L = 146 s, π4U = 176 s, πLmax = 169 s, and η1 = 163 s. We can check that [π1L, π1U]∩[π2L, π2U]∩[π3L, π3U]∩[π4L, π4U] ≠ ∅ and η1 ≤ πLmax. Then, according to Lemma 2, we set ω0 = ω1 = ω2 = ω3 = 0 and ω4 = πLmax − η1 = 6 s and a feasible schedule is obtained with cycle time θ = η = πLmax = 169 s. The Gantt chart for the obtained schedule is shown in Figure 3.

Gantt Chart for the schedule of Example 1.
Example 2
The wafer processing time at PM1–4 is α1 = 95 s, α2 = 35 s, α3 = 30 s, and α4 = 100 s, respectively. After a wafer is completed, it can stay in PM1–4 for at most δ1 = 30 s, δ2 = 20 s, δ3 = 20 s, and δ4 = 30 s, respectively. The robot task time is λ = µ = 3 s.
We have π1L = 116 s, π1U = 146 s, π2L = 139 s, π2U = 159 s, π3L = 134 s, π3U = 154 s, π4L = 121 s, π4U = 151 s, πLmax = 139 s, and η1 = 143 s. Thus, [π1L, π1U]∩[π2L, π2U]∩[π3L, π3U]∩[π4L, π4U] ≠ ∅ and πLmax ≤ η1 ≤ πUmin hold, and it is schedulable. Then, according to Lemma 3, we set ω0 = ω1 = ω2 = ω3 = ω4 = 0 s and a feasible schedule is obtained with cycle time θ = η = η1 = 143 s. The Gantt chart for the obtained schedule is shown in Figure 4.

Gantt Chart for the schedule of Example 2.
Example 3
The wafer processing time at PM1–4 is α1 = 115 s, α2 = 40 s, α3 = 45 s, and α4 = 125 s, respectively. After a wafer is completed, it can stay at PM1–4 for at most δ1 = 30 s, δ2 = 20 s, δ3 = 20 s, and δ4 = 30 s, respectively. The robot task time is λ = µ = 3 s.
For this example, we have π1L = 136 s, π1U = 166 s, π2L = 164 s, π2U = 184 s, π3L = 169 s, π3U = 189 s, π4L = 146 s, π4U = 176 s, πLmax = 169 s, and η1 = 163 s. It can be checked that [π1L, π1U]∩[π2L, π2U]∩[π3L, π3U]∩[π4L, π4U] = ∅ and
From γ0 = 0 to γ1 = 15, task sequence 〈y20 → robot waits in q02 → s02 → t01 → s11〉 is performed such that M1 = ({W1(1)}, {W0(1)}, {W0(2)}, {W0(1)}) is reached.
From γ1 = 15 to γ2 = 30, task sequence 〈y14 → robot waits in q42 → s42 → t40 → s01〉 is performed such that M2 = ({W1(1)}, {V0(1)}, {V0(2)}, {null}) is reached.
From γ2 = 30 to γ3 = 42, task sequence 〈y03 → robot waits in q32 → s32 → t34 → s41〉 is performed such that M3 = ({W1(1)}, {V0(1)}, {null}, { V0(1)}) is reached.
From γ3 = 42 to γ4 = 54, task sequence 〈y42 → robot waits in q22 → s22 → t23 → s31〉 is performed such that M4 = ({W1(1)}, {null}, {V0(1)}, {V0(1)}) is reached.
From γ4 = 54 to γ5 = 108, task sequence 〈y33 → robot waits at Step 3 → s32 → t32 → s21〉 is performed such that M5 = ({W1(1)}, {V0(2)}, {null}, {V0(1)}) is reached.
From γ5 = 108 to γ6 = 157, task sequence 〈y22 → robot waits at Step 2 → s22 → t23 → s31〉 is performed such that M6 = ({W1(1)}, {null}, {V0(2)}, {V0(1)}) is reached.
From γ6 = 157 to γ7 = 169, task sequence 〈y31 → robot waits in q12 → s12 → t12 → s21〉 is performed such that M7 = ({null}, {W1(1)}, {V0(2)}, {V0(1)}) is reached.
Through the above sequence, a cycle of the system is formed, which demonstrates that the cycle time is 169 s. The Gantt chart for the obtained schedule is shown in Figure 5.
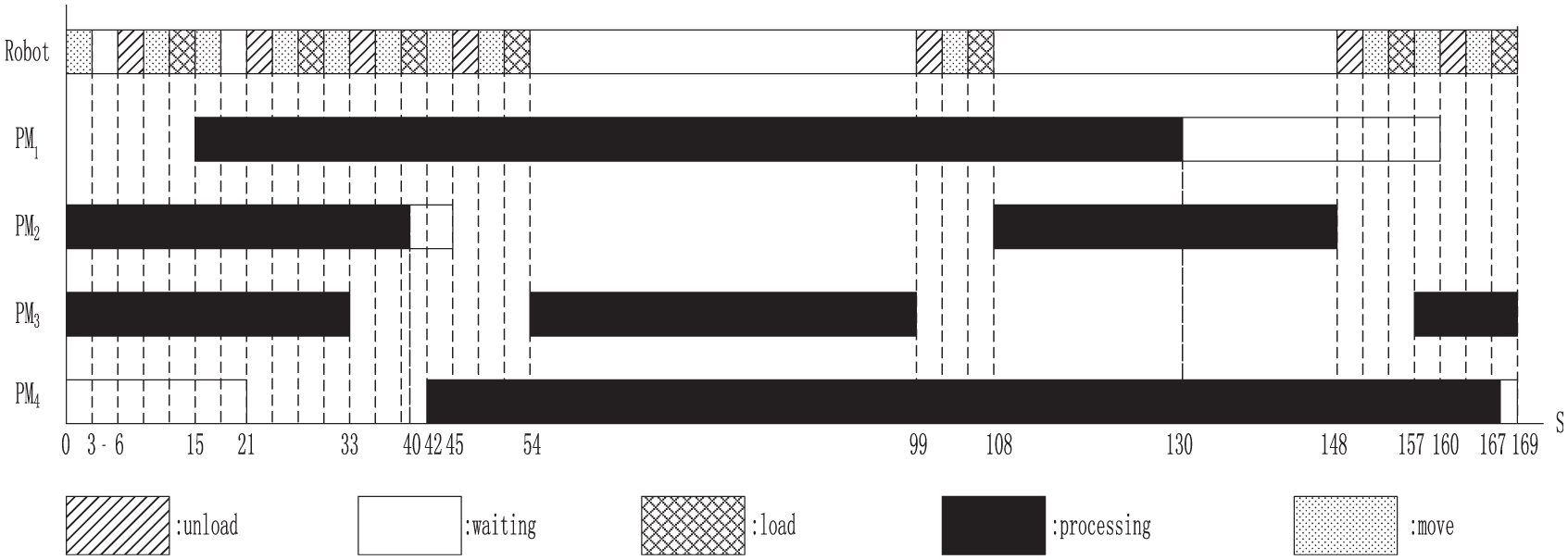
Gantt Chart for the schedule of Example 3.
Conclusion
With wafer revisiting, a single-arm cluster tool is deadlock-prone and it is very difficult to schedule such a tool to satisfy wafer residency time constraints. Thus, scheduling single-arm cluster tools with wafer revisiting and residency time constraints is very challenging. Up to now, there are studies on scheduling single-arm cluster tools with wafer revisiting or wafer residency time constraints, but not both. This work conducts a study on scheduling single-arm cluster tools with both of them for the ALD process. Based on a p-backward strategy, a PN is developed to model the process. With the model, analysis on the existence of a feasible schedule is done and schedulability conditions are established. By the proposed method, a schedule is parameterized as robot waiting time. Hence, if a feasible schedule exists, a schedule can be found very efficiently by simply setting the robot waiting time. The obtained schedule is shown to be optimal in terms of productivity.
In this article, the study is done under the assumption that wafer processing time and robot task time are deterministic. However, they may subject to random variation, which may result in infeasibility of a schedule obtained under deterministic activity time. Thus, further research is necessary to cope with this problem.
Footnotes
Academic Editor: Jiacun Wang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by FDCT of Macau under Grants 102/2013/A and 065/2013/A2, and in part by NSF of China under Grants 61273036 and U1401240.