
Abstract
Selecting and using an appropriate structural reliability method is critical for the success of structural reliability analysis and reliability-based design optimization. However, most of existing structural reliability methods are developed and designed for a single limit state function and few methods can be used to simultaneously handle multiple limit state functions in a structural system when the failure probability of each limit state function is of interest, for example, in a reliability-based design optimization loop. This article presents a new method for structural reliability analysis with multiple limit state functions using support vector machine technique. A sole support vector machine surrogate model for all limit state functions is constructed by a multi-input multi-output support vector machine algorithm. Furthermore, this multi-input multi-output support vector machine surrogate model for all limit state functions is only trained from one data set with one calculation process, instead of constructing a series of standard support vector machine models which has one output only. Combining the multi-input multi-output support vector machine surrogate model with direct Monte Carlo simulation, the failure probability of the structural system as well as the failure probability of each limit state function corresponding to a failure mode in the structural system can be estimated. Two examples are used to demonstrate the accuracy and efficiency of the presented method.
Keywords
Introduction
During the past few decades, structural reliability methods have been gained increasing interest for rational treatment of the uncertainties in engineering structures. Despite the structural reliability community has achieved many advanced development on the theoretical research, serious computational obstacles arise when involving practical problems. For example, it usually involves the reliability assessment of multiple limit state functions (LSFs) in reliability-based design optimization (RBDO) of a structure, and many structures may have multiple failure modes which result in multiple LSFs. A structural reliability method capable of dealing multiple LSFs from the same system with a single run is more preferable for RBDO problems and multiple-LSF problems. When one examines the existing structural reliability methods, an importance fact is found that most of them are developed for a single LSF, for example, the most commonly used first-order reliability method (FORM) and second-order reliability method (SORM).1–5 Although one may repeat to apply the existing structural reliability methods on each LSF, the computational and development effort cannot meet the demands in many practical cases. Therefore, the study of structural reliability methods which can deal with multiple LSFs simultaneously has progressively attracted attention recently, especially on computer-based simulation methods. Due to its excellent universality, direct Monte Carlo simulation (MCS) is suitable for a problem with multiple LSFs. However, the huge computational effort for small reliability level hinders its applications, just like the situation for a single LSF.6–8 Based on subset simulation (SS), 6 Hsu and Ching 9 developed a simulation algorithm for the failure probabilities of multiple LSFs. In their algorithm, a principle variable is proposed to correlate with all LSFs of interest and drive the simulation to gradually approach the multiple failure regions. However, it is a non-trivial task for the determination of a proper principle variable. Li et al. 10 proposed a generalized SS to use unified intermediate events to resolve the sorting difficulty in the original one. In general, the generalized SS is much easy to carry out a reliability analysis of multiple LSFs simultaneously, compared with Hsu and Ching’s method. Like MCS, SS is also very time-consuming when structural analyses involve large numerical models, for example, finite element models. 11
In practical problems, LSFs are established based on certain structural failure mechanism, for example, stress, displacement, and fatigue, and do not have analytical expressions. Furthermore, the failure regions usually possess complicated geometry and boundaries. In order to reduce the computational effort of structural reliability analysis, surrogate models, for example, response surface method (RSM),12–20 artificial neural networks (ANNs),21–24 and support vector machine (SVM),25–29are generally suggested to approximate the actual LSF in a structural reliability problem. RSM may be the most popular methods among them. It aims to fit an LSF around the so-called design point as near as possible. However, its approximate precision is greatly influenced by an LSF’s complexity, polynomial form and order, and location of supporting points.11,21 It has been proved that even a response surface with accuracy as one wish may produce an erroneous estimation for failure probability. 30 Moreover, RSM is not applicable to the situation of multiple LSFs. ANN is one of the popular alternatives to RSM. Various kinds of ANNs may estimate the failure probabilities of multiple LSFs simultaneously with the aid of its high parallelism. However, in the case of a small number of training samples, the estimated results are greatly influenced by the initial parameter setting, and the training process is easy to fall into local optimum because ANN is mainly based on the principle of empirical risk minimization (ERM).31–33 Recently, Chojaczyk et al. 22 provided a comprehensive review on the application of ANN in structural reliability analysis.
SVM was first proposed by Cortes and Vapnik 31 in 1995, which reveals many unique advantages in pattern recognition with small samples, nonlinear and high dimensions. It was further extended for nonlinear regression by Vapnik.32,33 From the point of view of statistical learning theory, SVM has several advantages over RSM and ANN for the approximation of an LSF. 25 SVM adopts the structural risk minimization (SRM) principle rather than the ERM principle so that SVM has better generalization ability. In addition, there is no local optimal issue when searching the algorithm parameters in an SVM. Due to its superior performance, SVMs have been developed to combine with conventional structural reliability methods to establish new structural reliability methods. Those advantages mentioned previously can inhere in the structural reliability methods based on various SVMs. Hurtado and Alvarez 25 proposed an interesting method composed of SVM and stochastic finite element method to deal with structural reliability analysis by means of regarding the problem of structural reliability analysis as a pattern recognition problem. By combining SVM with FORM and MCS, the two approaches, SVM-based FORM and SVM-based MCS, were proposed by Li et al. 26 for structural reliability analysis. Guo and Bai 27 suggested a method that combines the least square SVM with MCS. It indicates the method based on the least square SVM is superior to the method based on traditional SVM. Dai et al. 28 developed a SVM-based importance sampling to perform structural reliability analysis, in which SVM is used to construct the sampling density for the optimal important sampling density to reduce the number of training samples. Jiang et al. 29 paid a special attention to generating uniform support vector for the SVMs’ application on structural reliability analysis.
Although SVMs have been widely used in reliability community, a series of traditional SVM models which only have one output are needed to be constructed when dealing with multiple LSFs simultaneously. 34 This strategy may have very low computational efficiency, because both actual LSFs and their surrogate models are required to be called for a large number of times during surrogate model construction and reliability estimation.
As an alternative to the traditional SVMs, multiple-input multiple-output SVMs (MIMO-SVMs)35–38 are good choice since they can model the multiple-input multiple-output relationship between the input random variables and the multiple failure modes in a structural system and have been applied in many engineering and science fields. The newly developed multiple-task least-squares SVMs (MTLS-SVMs) which is proposed by Xu et al.35,36 aims for establishing a surrogate model between input parameters and multiple outputs for multiple classification and regression problems. This article presents a new method for structural reliability analysis of multiple LSFs, which utilizes the recently developed MTLS-SVM. To our best knowledge, this is the first attempt to employ MTLS-SVM for structural reliability analysis of multiple LSFs. A new random sampling method, combining the Latin hypercube sampling (LHS) and uniform sampling (US), is also developed to generate the training data (supporting points) set with a good coverage of the input random space. Then, the MTLS-SVM is trained to be a single surrogate model for all LSFs in the problem of interest. Finally, based on the trained MTLS-SVM model, MCS is employed to estimate the failure probabilities of all LSFs simultaneously. The computational efficiency and accuracy of the presented method are also studied in this article.
SVM technique
In this section, some basic concepts of SVM are briefly reviewed. More details of SVM can be referred to Vapnik. 32 It is well known that SVM is a statistical learning algorithm based on SRM, which can be used for classification and regression problems. Here, we focus on the regression problems, that is, function fitting problems.
Considering a training data set

where l is sample size,
The nonlinear relationship between the inputs and output can be described by a regression function obtained from SVM theory

where

where c is a regularization parameter used to measure the complexity and the loss of compromise, and ε is a linear insensitive loss function. According to the Karush–Kuhn–Tucker (KKT) complementary conditions, equation (3) has a global optimal solution because SVM converts a regression problem into a quadratic optimization problem.
The kernel function
The least square MIMO-SVM
The above-mentioned SVM technique is able to be applied to a system with a single output only. Thus, it cannot be used for dealing with a complex system with multiple outputs, for example, the demand of dealing with multiple LSFs in an RBDO problem as in this study. To overcome this issue, various MIMO-SVM techniques have been proposed to meet this demand.35–38 In this article, a MTLS-SVM35,36 is employed to build up a single surrogate model which can approximate multiple LSFs.
Considering a system has m outputs, the training sample size is l. The training data set in equation (1) becomes as

where n is the dimension of input parameters. According to the Hierarchical Bayesian,39,40 the control parameter
To solve the regression problem of multiple outputs system, MIMO-SVM determines

where λ and c are two positive real regularized parameters,
The Lagrange function is introduced to solve the optimization problem in equation (6)

where

The following linear equations are obtained

where

where
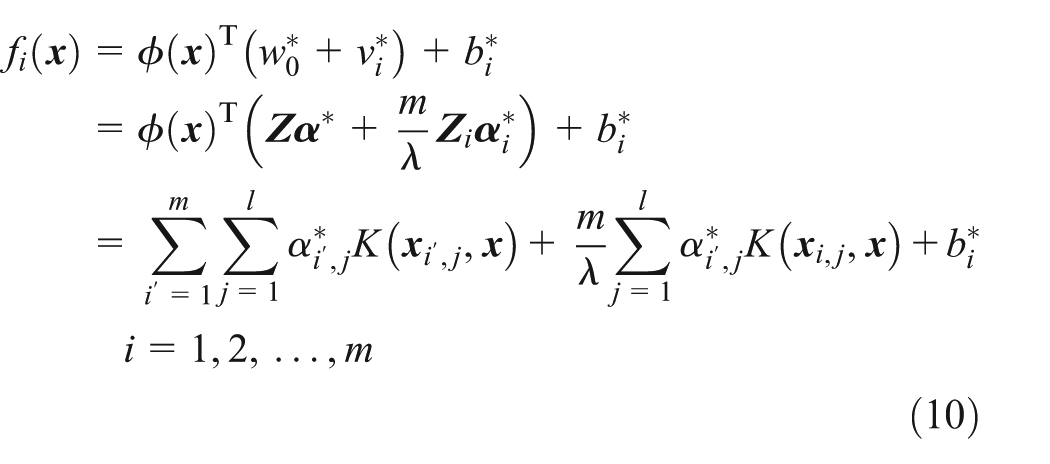
More details about the MIMO-SVM algorithm can be seen in Xu et al.35,36
Structural reliability analysis based on MIMO-SVM
It is well known that LSF is the foundation of the structural reliability analysis. In this article, MIMO-SVM is used to construct a single surrogate model of all multiple LSFs through a single run. On the basis of this surrogate model, MCS is then employed to calculate the failure probabilities of all LSFs simultaneously. This section starts with the development of a new random sampling method. Then, the implementation procedure of the presented method is provided.
The generation of training samples
For most of surrogate model methods, the training sample size and position are critical to construct an appreciate surrogate model which can meet the requirements of efficiency and accuracy. Although SVM techniques possess a good generalization performance compared with other machine learning algorithms, a small number of training samples is always preferable to construct a high accuracy surrogate model. From a general sense, MCS may be used to generate a training data set. However, random samples, generated according to the underlying probability distribution of random variables in MCS, usually cluster in a local domain and cannot completely represent the input space well. Moreover, MCS is not easy to obtain failure samples which represent structural characteristics in the failure domain, especially for small failure probability levels. The training data set without failure samples still may be used to train a surrogate model. However, its precision and generalization cannot be guaranteed. Thus, MCS is not suitable to generate the training data set for the purpose of training a proper surrogate model.
An LHS technique41,42 is employed to generate the training samples in this article. In essence, LHS is a kind of multi-dimensional stratified sampling method in order to obtain a good coverage of input space and reduce the statistical uncertainty associated with MCS. Suppose that N training samples are required, the accumulative probability interval [0,1] of a random variable is divided into N non-overlapping subintervals

where u is a uniform random number in the interval [0,1] and

where
If the associated failure probability of an LSF is too small, the training data set generated by LHS technique may not include any failure points. In order to address this issue, an improved sampling method, combining LHS technique and uniform sampling (US), is proposed to provide a good coverage of the whole input random space. This new method is denoted as LHS + US in this article. After generating

where
Figure 1 shows 20 samples generated by LHS and LHS + US separately. Figure 1(a) presents the samples obtained by LHS technique. It can be seen that these 20 samples do not contain any failure samples and then cannot cover the input space well. Figure 1(b)–(d) shows the training samples obtained by LHS + US. It can be seen that the higher the value of k, the more the failure points will be generated and the better the coverage of random samples.

Random sampling by LHS and LHS + US: (a) LHS, (b)LHS + US with k = 3, (c) LHS + US with k = 6, and (d) LHS + US with k = 9.
To select a proper value for k, a practical way is to start with k = 6 and check the percentage of failure samples. If this value is larger than 20%, the generation of training samples can be terminated. Otherwise, a larger value of k needs to be set.
Procedure of the presented method
Considering a structural system with m LSFs
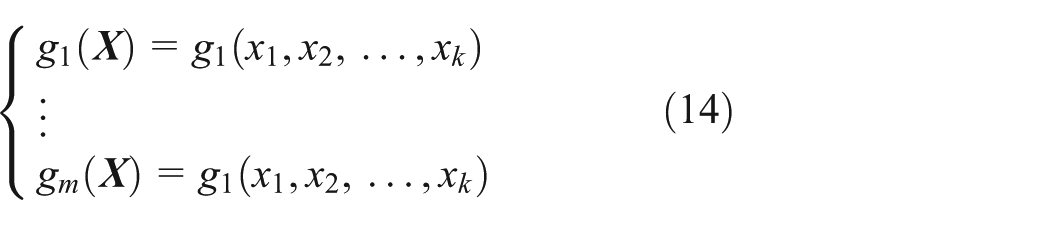
The general procedure of the presented method is given below. First, the training samples required to construct a surrogate model are generated by LHS + US. Then, in order to select an appropriate kernel function, the corresponding parameters are determined by a grid-search method 43 according to the selected kernel function and the training samples. After that, the sole surrogate model of all m LSFs is trained, based on the above information and the sampling algorithm presented in section “The generation of training samples.” Finally, MCS is employed to estimate the failure probabilities of all m LSFs based on the MIMO-SVM surrogate model. For the jth LSF, its failure probability is estimated as

where

Flowchart of the presented method.
Numerical examples
Two examples are used to illustrate the accuracy and efficiency of the presented method in this section, including one numerical example and one engineering problem. Example 1 is a two-dimensional structural system with four LSFs. It gives a visual representation of the effect of MIMO-SVM and the impact of training sample size and kernel function. Example 2 has 11 seven-dimensional LSFs, which is used to demonstrate the capacity of dealing with multiple LSFs by MIMO-SVM.
Example 1
Considering a reliability analysis problem of a structural system with 4 two-dimensional LSFs, it was taken and modified from Waarts.
11
System failure is defined as

where

The LSFs fitted by MIMO-SVM with different kernel functions and different sample sizes: (a) Poly-2 with 10 samples, (b) Poly-3 with 10 samples, (c) Poly-2 with 20 samples, (d) Poly-2 with 40 samples, (e) RBF with 10 samples, (f) RBF with 20 samples, and (g) RBF with 40 samples.
The failure probabilities of all LSFs in Example 1 (× 10–3).

LSF: limit state function; MCS: Monte Carlo simulation; SVM: support vector machine; RBF: radial basis function; MIMO-SVM: multi-input multi-output support vector machine.
M is MIMO-SVM.
The numbers in the parentheses are the sample size.
It can be seen from Figure 3 that the MIMO-SVM model possesses highly approximated precision when an appropriate number of failure samples is included in the training data set. However, the sample size seems to have a small influence on the approximated precision of the MIMO-SVM model when it is larger than 10. For this example, the MIMO-SVM models with different kernel functions may have similar precision. The simulation results from MCS (the second row in Table 1) are considered as “actual” ones, and they are used to compare to the computational results obtained by the proposed method. Table 1 indicates the presented method is as accurate as MCS. It is more efficient than the latter because it only needs a small number of training samples.
It is worth noting that the MIMO-SVM model is constructed only by one training run, while the number of training runs of a single-output SVM is identical with the number of LSFs in a system. Furthermore, a single-output SVM may require a different training data set for each LSF in the system. In this example, the MIMO-SVM model and the single-output SVM model have very similar precision, while the former needs as less as 10 training samples and the latter needs 40 training samples.
Example 2
As shown in Figure 4, a speed reducer 44 has been designed to minimize its weight. There are 11 probabilistic constraints, and they represent bending, contact stress, longitudinal displacement, stress of the shaft, and geometry constraints. This design optimization problem has seven design variables: gear width (x1), teeth module (x2), number of teeth in the pinion (x3), distance between bearings (x4, x5), and axis diameters (x6 and x7). Input random variables x1–x7 are mutually independent normal random variables with a standard deviation of 0.005. The objective function and the formulae of the probabilistic optimization are given by
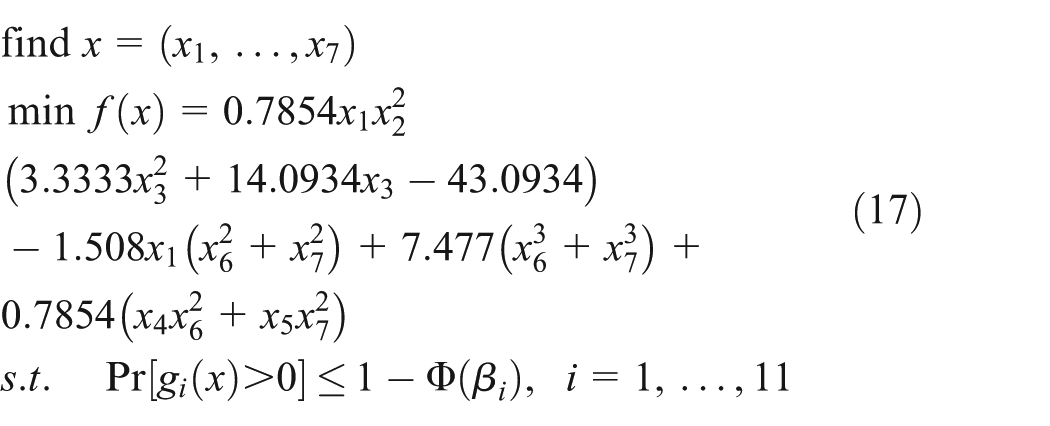
and


Schematic speed reducer configuration.
It is obvious that all these 11 probabilistic constraints are required to be estimated in each iteration during the optimization process regardless of the usage of a double-loop or a single-loop optimization algorithm. Here, this study focuses on how to solve 11 probabilistic constraints simultaneously based on the presented method to reduce the total computational cost. Table 2 summarizes three groups of optimization results reported in the literature, 44 and these optimization results are selected to perform our illustration.
The optimization results given by Lee and Lee. 44

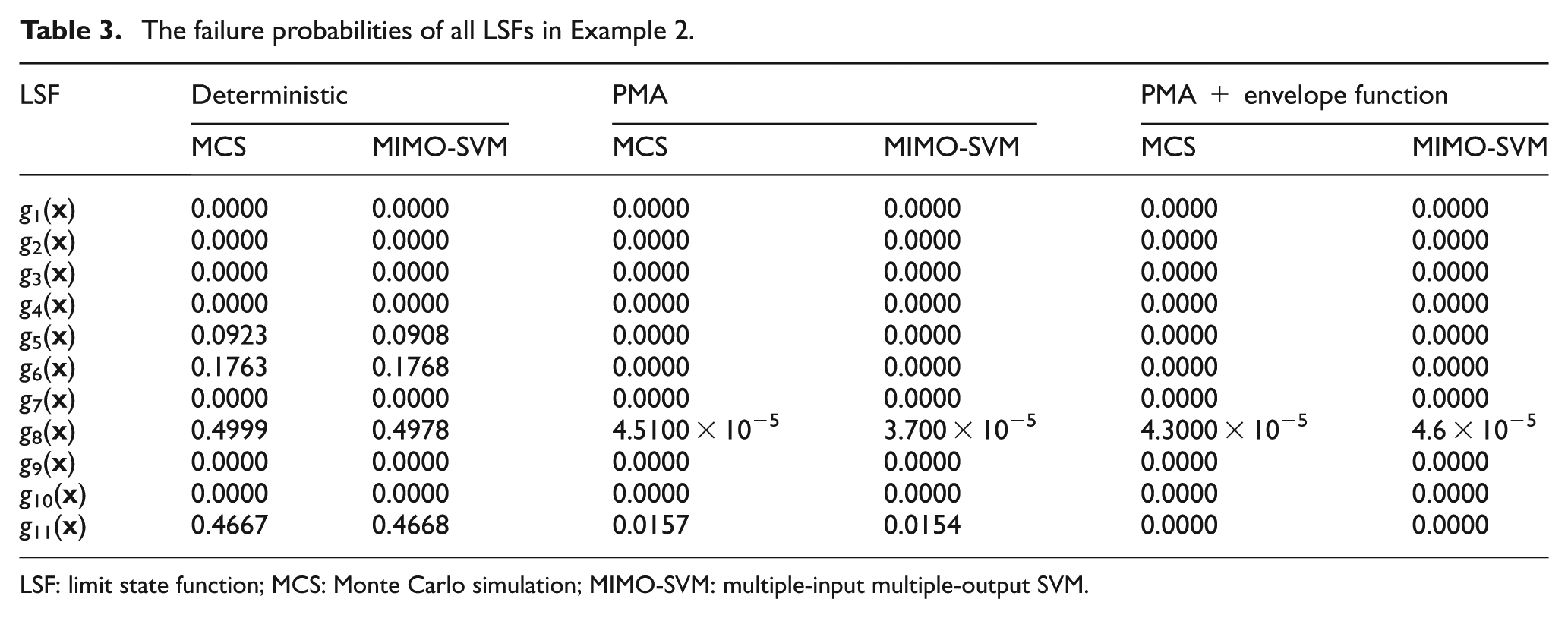
In this numerical example, 10 training samples are generated by LHS. Radial basis kernel function is chosen and the corresponding parameters are determined by grid-search method. The single MIMO-SVM surrogate model is trained according to the above information. Then, based on the trained MIMO-SVM model, MCS with 105 samples is employed to estimate the failure probabilities of all 11 LSFs. In this article, the failure probabilities of all 11 probabilistic constraints for the three optimization cases are verified, that is, deterministic optimum, performance measure approach (PMA), and PMA + envelope function. 44 The computational results are summarized in Table 3.
The failure probabilities of all LSFs in Example 2.
LSF: limit state function; MCS: Monte Carlo simulation; MIMO-SVM: multiple-input multiple-output SVM.
Similar to Example 1, a single MIMO-SVM surrogate model is constructed for all 11 LSFs, while 11 SVM surrogate models with one output are needed to be constructed in a traditional way. The training sample size is only 10 for the presented MIMO-SVM surrogate model, while at most 110 samples may be needed when using a single-output SVM model. It can be seen from Table 3 that the computational results obtained by the presented MIMO-SVM surrogate model with MCS are very close to those obtained directly by MCS. This indicates that the presented MIMO-SVM model has high accuracy under the condition of small number of samples and moderate dimensions.
Conclusion
It is well known that most of traditional structural reliability methods cannot be applied to deal with multiple LSFs simultaneously, when the failure probability of each LSF is of interest. A new structural reliability method using MIMO-SVM is presented to handle multiple LSFs for this issue which may arise in an RBDO problem and/or a problem with multiple failure modes. The main idea of the presented method is to construct a single surrogate model for all multiple LSFs using MIMO-SVM because all LSFs share the common input parameters and model (numerical or physical one). In order to obtain a good coverage of input parameter space, LHS and LHS + US are proposed to generate a training data set with a portion of failure samples. Finally, the failure probabilities of all LSFs are estimated by MCS based on the trained MIMO-SVM surrogate model. The most attractive advantages of this presented method are that all LSFs are approximated only using one training data set and the training operation is only run one time. These will be benefited for the estimation of probabilistic constraints in RBDO and structural reliability analysis with multiple failure modes. Numerical examples indicate that that the presented method needs a small amount of computational cost to achieve an accurate reliability analysis. Thus, it is suitable for RBDO with multiple probabilistic constraints and multiple modes reliability analysis.
A limitation of this study is the passive way of generation of training samples. Future work will involve combining the active learning techniques and MIMO-SVM to further reduce the computational cost and then apply it in practical RBDO.
Footnotes
Academic Editor: Yongming Liu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors are grateful for the supports by the National Science Foundation of China (Grant No. U1533109 and 11102084), Fundamental Research Funds for the Central Universities (Grant No. NS2015007), and a Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions.