
Abstract
This article presents a multi-objective discrete group search optimizer for blocking flow shop multi-objective scheduling problem. The algorithm is designed to search the Pareto-optimal solutions minimizing the makespan and total flow time for the flow shop scheduling with blocking constraint. In the proposed algorithm, a diversified initial population is constructed based on the Nawaz–Enscore–Ham heuristic and its variants. Unlike the original group search optimizer in which continuous solution representation is used, the proposed algorithm employs discrete job permutation representation to adapt to the considered scheduling problem. Accordingly, operations of producer, scrounger, and ranger are newly designed. An insertion-based Pareto local search is put forward in producer procedure, a crossover operation is introduced in scrounger procedure, and a local search based on the insert neighborhood is designed in ranger procedure. A bunch of computational experiments and results show that the proposed algorithm is superior to two existing powerful meta-heuristics in terms of both inverted generational distance and set coverage.
Introduction
Scheduling problems play an important role in industrial engineering and operation research and have attracted widespread scientific attention these years. Two common problems which frequently appear in the scheduling literature are the permutation flow shop scheduling problem (PFSP)1,2 and job shop scheduling problem (JSP).3–5 The PFSP assumes that there are enough intermediate buffers for jobs between two consecutive machines, whereas the buffers are limited in real production. If there is no buffer for a job and the next machine is busy, then the job has to stay on the incumbent machine and block itself. Assume that the buffer size is zero between any two consecutive machines, a job is easy to block itself and hence the production is greatly delayed. Such a problem is called the blocking flow shop scheduling problem (BFSP). The BFSP extensively exists in all sorts of industrial environments, such as petrochemical process, batch process, plastics molding, and steel manufacture.6,7
A great deal of research work has been done on the BFSP. It was proved to be non-deterministic polynomial-time (NP)-hard for minimizing makespan for the case of more than two machines. 8 In 2007, Companys and Mateo 9 proposed a branch and bound method for makespan minimization in the BFSP, and they solved the problem instances with small sizes. Hybridizing the dynamic programming and branch and bound methods, Bautista et al. 10 presented a bounded dynamic programming method, and the method was effective for small-size instances but powerless to solve instances with large sizes. As regards the heuristic, there were profile fitting (PF), 11 Nawaz–Enscore–Ham (NEH), 12 minmax (MM), the hybridization of MM and NEH (MME), and the hybridization of PF and NEH (PFE). 13 In recent years, meta-heuristics have been an extensively used method for the scheduling field. To minimize the makespan in the BFSP, a genetic algorithm was proposed by Caraffa et al., 14 and a tabu search was presented by Grabowski and Pempera. 15 Besides, some other algorithms, including the hybrid discrete differential evolution algorithm, 16 the iterated greedy algorithm, 17 and the hybrid harmony search algorithm, 18 were put forward. To minimize the total flow time in BFSP, Deng et al. 19 introduced a hybrid discrete artificial bee colony algorithm which achieved good performance.
The above existing researches are oriented to a single criterion, while multi-objective scheduling problems have gained increasing focus since multiple criteria are usually encountered in real-life scheduling problems. For the multi-objective JSP, Gao et al. 20 proposed a Pareto-based grouping discrete harmony search algorithm and a discrete harmony search algorithm. 21 For the multi-objective PFSP, Yenisey and Yagmahan 22 provided an extensive review. Although the multi-objective PFSP is widely studied by many researchers, there are less research reports for the multi-objective optimization in the BFSP. This article considers the minimization of both makespan and total flow time and presents a multi-objective discrete group search optimizer (MDGSO) to search the Pareto-optimal solutions.
Multi-objective BFSP
In BFSP, there are n jobs (job j, j = 1, 2, …, n) and m machines (machine Mi, i = 1, 2, …, m). Each job has to be processed first on machine M1, then on machine M2, …, and finally on machine Mm. The processing time of job j on machine Mi is known as p(j, i). The blocking constraint exists in the production process, which means there is no buffer between any two consecutive machines. To be specific, the following assumptions are given: (1) at any time, a machine is able to process at most one job, and a job is able to be processed on at most one machine; (2) no job splitting is allowed; (3) all the jobs and machines are available at time zero; and (4) the set-up time, release time, and transfer time are omitted.
A Gantt chart of BFSP with four jobs and three machines is shown in Figure 1, where the blocking time is marked as shadow rectangles. In Figure 1, the job sequence is 1-2-3-4, which consequently results in the makespan 22 and total flow time 62. It is worth noting that a job sequence different from 1-2-3-4 probably causes the changes of makespan and total flow time, and there is contradiction between these two objectives. Assuming that we have two different schedules
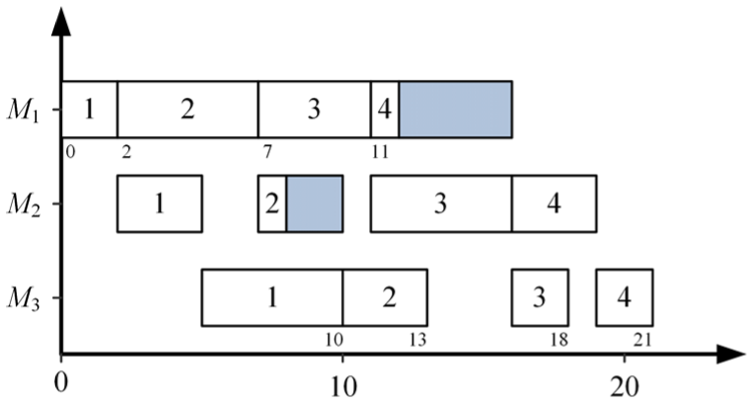
Gantt chart of a BFSP example.
The minimization criteria in this article are makespan and total flow time. For the considered multi-objective BFSP, the feasible solution is represented as job permutation




where
Let


These two objective values can be computed in O(mn) time. Let

Pareto domination states that solution
This article aims to solve the multi-objective problem by Pareto-optimal approach and propose a newly designed algorithm for the considered problem.
MDGSO
The group search optimizer (GSO) was first presented for the continuous function optimization. 23 The population of the GSO consists of three roles: producers, scroungers, and rangers, and each role has its specific updating mechanism. Producers perform producing strategy by simulating the animal scanning mechanism, scroungers perform scrounging strategy by joining resources uncovered by others, and ranger search for the resources by random walks. In each generation, the best member is selected as the producer, and certain individuals in the group are treated as scroungers, while the other individuals are handled as rangers.
Since the scheduling problem is different from the continuous function optimization problem, here individuals in GSO are designed as job permutations
Population initialization
In each generation, the proposed MDGSO maintains a population with size ps, which is denoted as PL = {L1, L2, …, Lps}. To get an initial PL with good performance, both the NEH and NEH_WPT
24
heuristics are applied. Specifically, we use the NEH heuristic to construct a permutation
The algorithm also maintains a set of non-dominated solutions, which is denoted as NS = {S1, S2, …, Snb}, where nb is the incumbent size of NS. The set NS is an independent set which stores the non-dominated solutions found by the algorithm so far. After the initialization of PL, the NS is initialized by the non-dominated solutions of PL. Besides, each solution in PL is initially marked as “unsearched.” An example of PL and NS is shown in Figure 2, where ps = 20 and nb = 6.

Solutions in population and non-dominated set.
Producer procedure
The purpose of producers is to explore the neighborhood region of a relatively better solution. For the multi-objective problem, the relatively better solutions are non-dominated solutions stored in NS. So the producer is designed as follows:
Step 1. If there exists an “unsearched” solution Sk in NS, then let X = Sk, and go to Step 3.
Step 2. Randomly select a solution Sh from NS, and let X = Sh. Apply d insert moves to X and perform an insertion-based Pareto local search (IPLS) on X.
Step 3. Perform IPLS on X. If X is not updated, mark the corresponding Sk in NS with “searched.”
In Step 1 of the above procedure, the solution Sk is selected as follows: if there exists one and only one “unsearched” solution in NS, then the solution is assumed as Sk; if there exists more than one “unsearched” solutions in NS, then a randomly selected one among them is assumed as Sk.
In Step 2 of the above procedure, the insert move means randomly selecting a job from the permutation and inserting it to another position of the permutation. The IPLS searches the insert neighborhood of X in the way that X is updated if and only if a neighbor dominates X. The searching process does not stop until a local optimum is found. The steps of IPLS are as follows:
Step 1. Randomly generate a permutation
Step 2. Find the position of job
Step 3. If there exists an
Step 4. Let j = (j + 1) % n, update NS using LNS and mark all the newly added solutions in NS as “unsearched.”
Step 5. If i < n, go to Step 2; else update NS using X and mark all the newly added solutions in NS as “unsearched.”
Note that the producer procedure is applied for one time in each generation, and whenever a solution is newly added in NS, the algorithm does not apply the producing operation on it immediately, just marking it as “unsearched.”
Scrounger procedure
In each generation, all the individuals in the population are either selected as scrounger (with probability p) or ranger (with probability 1 − p). In MDGSO, the scrounger is designed by introducing the crossover operator in genetic algorithm. Specifically, we randomly select a solution in NS and apply partially mapped crossover to it and the current scrounger individual. Then, the current scrounger individual is updated according to the dominance relations of parent and offspring. The steps of scrounger procedure are as follows:
Step 1. Randomly select a solution (denoted by Sk) in NS and perform partially mapped crossover on Sk and the current scrounger individual (denoted by Li). Denote the obtained offspring as X1 and X2.
Step 2. Update NS using X1 and X2 and mark all the newly added solutions in NS as “unsearched.”
Step 3. If

The dominance relation of offspring solutions (a) Li dominates both x1 and x2, (b) Li dominates x1 but not dominates x2, (c) Li does not dominates x1 or x2 while x1 dominates x2, (d) Li does not dominates x1 or x2 while no domination relation exists between x1 and x2.
Ranger procedure
In GSO, ranger is designed to perform random search; however, in the proposed MDGSO, the search procedure of ranger is not completely random but based on the solution set NS. For a ranger Li, first a solution in NS is randomly selected. Then, the insert neighborhood (denoted as Nb(X) for solution X) is searched and a descend direction is selected. The search process iterates until the solution could not be improved in that descend direction. At the end of ranger procedure, the incumbent ranger individual Li is replaced by the final solution found by the search process. The whole steps are as follows:
Step 1. Randomly select a solution Sk in NS, and let X = Sk.
Step 2. If there exists a solution
Step 3. Nb(X) = Nb(X)\X′, update NS using Nb(X) and mark all the newly added solutions in NS as “unsearched.”
Step 4. Nb(X) = Nb(X)\X′, update NS using Nb(X) and mark all the newly added solutions in NS as “unsearched.”
Step 5. Update NS using X. If X is newly added in NS, denote it as “searched.” The incumbent ranger individual Li is replaced by X.
Procedure of MDGSO
In the proposed MDGSO, the iteration is executed after the initial population PL and non-dominated solution set NS is generated. In each iteration, first the producer procedure is performed, then for each individual in PL, either scrounger procedure (with probability p) or ranger procedure (with probability 1 − p) is performed. There are only three parameters, ps, d, and p, to be determined in MDGSO, and the whole procedure is illustrated in Figure 4.

The flow chart of MDGSO.
Computational experiments and results
To validate the effectiveness of the proposed MDGSO, the well-known Taillard benchmark set which can be downloaded from the OR library (http://people.brunel.ac.uk/∼mastjjb/jeb/info.html) was used. This article tackled 90 instances, in which job number is from 20 to 100, and machine number is from 5 to 20. It should be noted that all tested algorithms were programmed in C++ language, and a PC with Window 7 operating system, Intel(R) Core(TM) i7-2600 CPU @3.06 GHz and 4 GB RAM was used to execute the algorithms.
Performance measures
There are various performance measures for multi-objective optimization to compare the performance of different algorithms. We use the following two measures:
1. Inverted generational distance (IGD). 25 Let P* be a set of reference solutions and A be the non-dominated solution set found by an algorithm. The generalized distance of point x and point y is

where
The IGD for A is computed as
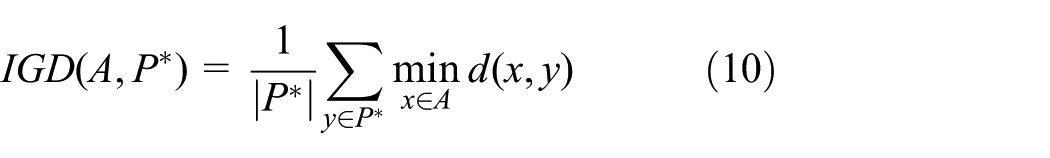
The IGD index reflects the average value of the minimum distance of A and all solutions in P*.
2. Set coverage. 26 Let A and B are two non-dominated solutions, the set coverage C(A, B) represents the percentage of solutions in B that are dominated by at least one solution in A, computed as

Computational results
In our computational experiments, the MDGSO was applied to solve each of the 90 instances with 10 replicates. Note that for each instance, we could obtain a solution set for each run. For convenience, all the solution sets of 10 replicates were gathered and a non-dominated solution set A was obtained. Two existing powerful meta-heuristics, non-dominated sorting genetic algorithm (NSGA-II) 27 and bi-objective multi-start simulated annealing algorithm (BMSA), 28 were adapted for the considered problem here for comparison. For each instance, we obtained the non-dominated solution set for each algorithm and then the performance measures were computed. Note that since the Pareto front for each instance was not known, the reference solution set P* was formed by gathering all the non-dominated solution sets for all tested algorithms. Regarding the parameter calibration for the MDGSO, the bigger the population size ps, the better the results are expected to be. However, a bigger ps value will inevitably cause more computational expense. Parameter d also affects the performance of the proposed algorithm. If it is too big, the solution obtained by d insert moves in producer procedure will possibly lose good characteristics of the original solution. If it is too small, the obtained solution will be possibly not able to escape the original local optimum. As for parameter p which determines the probability that an individual is treated as scrounger, a relatively bigger value is a better choice since the ranger usually uses lower probability in GSO. After some pilot experiments, we found that when the parameters were set as ps = 15, d = 6, and p = 0.8, the algorithm achieved relatively better performance. Thus, in the computational experiments, the above parameter setting was used for the MDGSO while the parameters of the other two algorithms were set as the original papers in the literature. The stopping criterion was set as 30mn ms.
The statistical results are given in Tables 1 and 2, showing IGD values and set coverage values, respectively. In the tables, the results are grouped by instance size for convenience, and bold numbers denote the better values.
The IGD values of the algorithms for instances grouped by different sizes.

IGD: inverted generational distance; MDGSO: multi-objective discrete group search optimizer; BMSA: bi-objective multi-start simulated annealing algorithm; NSGA: non-dominated sorting genetic algorithm.
The set coverage values of the algorithms for instances grouped by different sizes.

MDGSO: multi-objective discrete group search optimizer; BMSA: bi-objective multi-start simulated annealing algorithm; NSGA: non-dominated sorting genetic algorithm.
From Table 1, we can see that for the instances with 20 jobs, the differences between the MDGSO and the other two algorithms are not significant, which is probably because of the simplicity of the small-size instances. However, for the instances with 50 and 100 jobs, the IGD values of the MDGSO are clearly greater than the other two algorithms, which indicates the superiority of the MDGSO. We note that for some groups, the IGD values of the MDGSO are nearly zero, which means that the solution sets obtained by the MDGSO are very close to the reference solution sets. Table 1 also indicates the superiority of the BMSA over the NSGA-II.
Table 2 shows the differences of the algorithms’ performances in another facet. For the comparison between the MDGSO and the BMSA, the C(A, B) value is greater while the C(B, A) value is smaller, which indicates that the MDGSO is superior to the BMSA. Similarly, the values in the other two columns validate the superiority of the MDGSO over the NSGA-II.
To show the differences among the algorithms more clearly, we draw the non-dominated solution set of each algorithm for instance Ta36 and Ta86 in Figures 5 and 6, respectively. Note that the non-dominated solution set of each algorithm is formed by the results of 10 replicates. It is seen from these two figures that the non-dominated solutions found by the MDGSO have better diversity as well as better quality than those found by any of the other algorithms. As an example, the Gantt chart of a non-dominated solution for instance Ta01 is shown in Figure 7, where the makespan is 1380 and the total flow time is 15,042.

The non-dominated solutions obtained by the three algorithms for Ta36.

The non-dominated solutions obtained by the three algorithms for Ta86.

Gantt chart of a non-dominated solution for instance Ta01.
Conclusion
This article has presented an MDGSO for the multi-objective optimization in blocking flow shop scheduling. A population initialization method based on NEH heuristic and its variants has been designed to generate diversified solutions. Besides, we have designed the strategies of producers, scroungers, and rangers by hybridizing some local search methods, and we have conducted a multitude of experiments minimizing both the makespan and total flow time objectives in blocking flow shop scheduling. The computational results have shown that the proposed algorithm is superior to both the NSGA and BMSA in terms of IGD and set coverage. In future, we will focus on adapting the discrete GSO to other complex scheduling problems, such as the no-wait job shop problem, the flexible flow shop problem, and stochastic scheduling problem.
Footnotes
Academic Editor: Xichun Luo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors appreciate the support of National Natural Science Foundation of China (Grant No. 61403180), the Project for Introducing Talents of Ludong University (LY2013005), National Natural Science Foundation of China (Grant No. 51407088), and Promotive Research Fund for Excellent Young and Middle-aged Scientists of Shandong Province (Grant No. BS2015DX018).