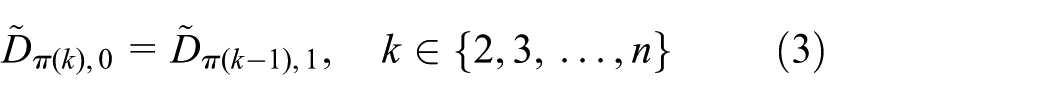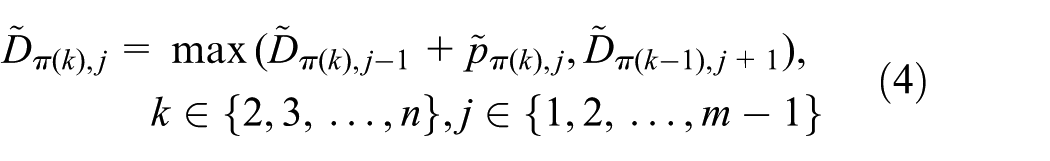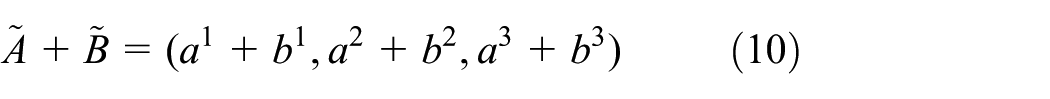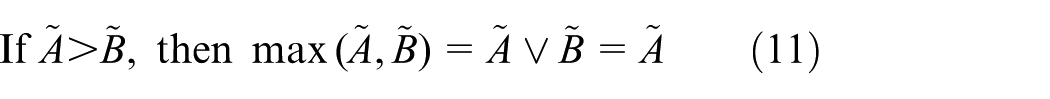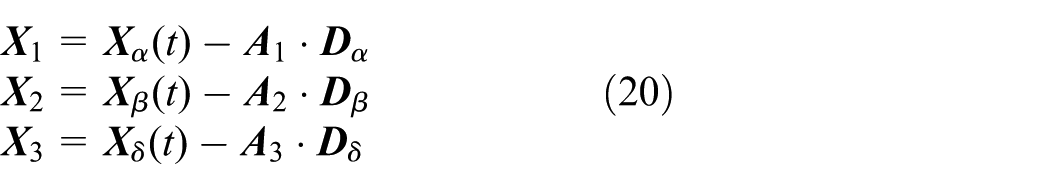Blocking flow shop scheduling problems have important applications in manufacturing. Because of the imprecise and vague temporal parameters in real-world production, this article formulates a fuzzy blocking flow shop scheduling problem with fuzzy processing time and fuzzy due date in order to minimize the fuzzy makespan and maximize the average agreement index. To solve this combinational optimization problem, a hybrid multi-objective gray wolf optimization algorithm is proposed. The hybrid multi-objective gray wolf optimization utilizes the largest position value rule for solution representation, employs a dynamic maintenance strategy to maintain an archive, and develops a thorough mechanism for leader selection. In the hybrid multi-objective gray wolf optimization, a novel heuristic process is designed to generate initial solutions with a certain quality, and a local search strategy is embedded to improve the exploitation capability. The performance of the hybrid multi-objective gray wolf optimization is tested on the production instances of panel block assembly in shipbuilding. Computational comparisons of the hybrid multi-objective gray wolf optimization with two other well-known multi-objective evolutionary algorithms demonstrate the feasibility and effectiveness of the hybrid multi-objective gray wolf optimization in generating optimal solutions to the bi-criterion fuzzy blocking flow shop scheduling problem.
In the classical flow shop scheduling problem, an assumption is made that there are intermediate buffers of infinite capacity between two consecutive machines where jobs can be stored to wait for subsequent operations. However, some production environments, such as concrete block production,1 steel manufacturing,2 and panel block assembly in shipbuilding, lack intermediate buffers between machines, mainly because of technical requirements, process characteristics, or some other constraints. The flow shop scheduling problem without intermediate buffers is known as the blocking flow shop scheduling problem. It considers that a set of jobs are to be processed on machines in the same order, from machine 1 to machine ; moreover, a job which has completed processing on a machine must remain on and block the machine until the downstream machine is available for processing. This problem has received increasing attention in the literature, and the majority of the studies on this topic consider minimizing the makespan, that is, the maximum completion time of all jobs. The blocking flow shop scheduling problem with a makespan criterion is usually denoted as . The problem with more than two machines has been proved to be non-deterministic polynomial-time (NP)-hard in the strong sense.3
For more than a decade, various heuristics have been proposed for the problem. For example, McCormick et al.4 developed the profile fitting (PF) heuristic, which attempts to arrange jobs for a minimum sum of the idle and blocking time on machines. Based on the makespan properties proposed by Ronconi and Armentano,5 Ronconi6 presented the MinMax (MM) heuristic and constructed the MME and PFE heuristics by combining MM and PF with the enumeration procedure of the Nawaz–Enscore–Ham7 (NEH) heuristic. The MME and PFE heuristics were subsequently shown to be superior to the NEH, MM, and PF heuristics. A growing number of meta-heuristics have also been developed for this type of problem, such as the genetic algorithm (GA),8 tabu search approaches (TS and TS + M),9 discrete particle swarm optimization (DPSO) algorithm,10 and discrete self-organizing migrating algorithm (DSOMA).11 Recently, Shao et al.12 proposed an estimation of distribution algorithm with path relinking technique (P-EDA) and compared it with other meta-heuristics, such as the hybrid discrete differential evolution (HDDE) algorithm,13 iterated greedy (IG) algorithm,14 revised artificial immune system (RAIS) algorithm,15 memetic algorithm (MA),16 and modified fruit fly optimization (MFFO) algorithm.17
In most previous works, including those mentioned above, scheduling problems were considered in deterministic environments where the parameters, such as the processing time and due date, were taken as crisp values. However, the assumption of precise temporal parameters is frequently violated in practice. During production, the processing time is often affected by uncertainty arising from both machine and human factors. The due date is expected to be met; however, certain earliness and tardiness limits can be tolerated, and extended limits will have lower values. Thus, modeling scheduling problems with imprecise and vague temporal parameters is more reasonable in real-world production. Fortunately, based on the concept of fuzzy sets,18 uncertain processing time and due date can be represented as fuzzy parameters to model a fuzzy scheduling problem.19,20 For instance, Wu21 formulated a fuzzy flow shop scheduling problem in order to minimize the weighted sum of fuzzy earliness and fuzzy tardiness. Lai and Wu22 considered a fuzzy flow shop scheduling problem with the fuzzy makespan objective function. Because simultaneously optimizing the makespan and due date satisfaction is usually involved in decision-making, Sakawa and Kubota23 proposed a GA for a multi-objective fuzzy job shop scheduling problem that maximized the minimum agreement index and average agreement index and minimized the fuzzy makespan. Lei24 developed a Pareto archive particle swarm optimization (PAPSO) algorithm for a multi-objective fuzzy job shop scheduling problem that maximized the minimum agreement index and minimized the fuzzy makespan and mean fuzzy completion time. Behnamian and Ghomi25 proposed a bi-level algorithm for a bi-objective fuzzy hybrid flow shop scheduling problem that minimized the makespan and the sum of earliness and tardiness. Wang et al.26 designed an MA for a multi-objective fuzzy flexible job shop scheduling problem that simultaneously optimized the fuzzy makespan, minimum agreement index, and average agreement index. In consideration of the vague temporal parameters as well as the simultaneous optimization of the makespan and due date satisfaction, this article formulates a bi-criterion fuzzy blocking flow shop scheduling problem with fuzzy processing time and fuzzy due date in order to minimize the fuzzy makespan and maximize the average agreement index.
The gray wolf optimizer (GWO) developed by Mirjalili et al.27 is a new population-based and easy-to-implement meta-heuristic that has been successfully applied to various engineering problems, such as unmanned combat aerial vehicle path planning28 and economic load dispatch.29 Importantly, the GWO was employed to solve a flow shop scheduling problem and exhibited high competitiveness.30 Recently, Mirjalili et al.31 proposed a multi-objective GWO for continuous multi-objective problems, and Lu et al.32 designed an effective multi-objective discrete GWO for a scheduling problem in welding production. In this article, a hybrid multi-objective gray wolf optimization (HMOGWO) algorithm is proposed to solve the bi-criterion fuzzy blocking flow shop scheduling problem.
The remainder of this article is organized as follows. Section “Fuzzy blocking flow shop scheduling problem” describes the bi-criterion fuzzy blocking flow shop scheduling problem. Section “Operations on fuzzy numbers” introduces the operations on fuzzy numbers that are required to formulate the scheduling problem. Section “HMOGWO for the fuzzy blocking flow shop scheduling problem” elaborates the proposed algorithm for solving the scheduling problem. Computational analysis based on real-time production data is reported in section “Computational analysis,” followed by the conclusions in section “Conclusion and future studies.”
Fuzzy blocking flow shop scheduling problem
Problem description
The fuzzy blocking flow shop scheduling problem can be defined as follows. A set of jobs are to be processed sequentially on machine 1, machine 2, and so on until the final machine. All machines are continuously available, and all jobs are ready for processing at time zero. At any time, each machine can process at most one job, and each job can be processed on at most one machine. The processing of a job on a machine cannot be interrupted. A job that has completed processing on a machine cannot leave the machine until the downstream machine is free. The fuzzy processing time and fuzzy due date are represented by fuzzy numbers.
Problem formulation
The notations of the fuzzy blocking flow shop scheduling problem are defined as follows:
is the number of jobs;
is the number of machines;
is the index of jobs, ;
is the index of machines, ;
is the fuzzy processing time of job on machine ;
is the fuzzy due date of job ;
is the fuzzy departure time of job on machine ;
is the fuzzy completion time of job ;
is the agreement index of job .
In this study, the fuzzy processing time is a triangular fuzzy number denoted by , which includes the following three parameters: the optimistic value , the most plausible value , and the pessimistic value . The membership function of the triangular fuzzy processing time is shown in Figure 1(a). The fuzzy due date is considered a trapezoidal fuzzy number denoted by , where and are the lower and upper bounds of the fuzzy due date, respectively, and and represent the expected due date interval . The membership function of the trapezoidal fuzzy due date, which is shown in Figure 1(b), represents the degree of satisfaction with respect to the completion time.
(a) Membership function of the triangular fuzzy processing time; (b) membership function of the trapezoidal fuzzy due date; and (c) agreement index (AI).
Let denote a processing sequence of jobs. Suppose that job is allocated at the kth dimension of . Then, the fuzzy completion time of each job can be calculated using the following formulas
where denotes the starting time of job on the first machine, and represents the fuzzy departure time of job on machine . The fuzzy completion time, which is denoted by , includes three parameters: the optimistic value , the most plausible value , and the pessimistic value .
The completion time is always expected to meet the due date. The agreement index 23 of job , which is defined in equation (7) and is shown in Figure 1(c), indicates the degree of compliance between and .
This article formulates the fuzzy scheduling problem with the bi-objective of minimizing the fuzzy makespan and maximizing the average agreement index
Operations on fuzzy numbers
Several operations, including the addition operation (+), max operation , and ranking method for two or more fuzzy numbers, are essential for the formulation of the scheduling problem.
For two triangular fuzzy numbers and
With respect to the max operation, an approximation proposed by Lei33 is applied in this article. According to Lei’s criterion, the approximate max is either or , as given below
Equations (4), (8) and (11) show that a ranking method for fuzzy numbers is required. This article uses the following three criteria to rank triangular fuzzy numbers:23
Criterion 1.
The greatest associate ordinary number
is used as the first criterion to rank the triangular fuzzy numbers.
Criterion 2.
If does not rank the fuzzy numbers, then the best maximal presumption
is selected as the second criterion.
Criterion 3.
If and do not rank the fuzzy numbers, then the difference of the spreads
is utilized as the third criterion.
HMOGWO for the fuzzy blocking flow shop scheduling problem
GWO
The GWO27 is inspired by the social hierarchy and hunting behavior of gray wolves. To mimic the social hierarchy of gray wolves when developing the GWO, the fittest solution is regarded as the alpha wolf. In addition, the second and third best solutions are expressed as the beta and delta wolves, respectively. The remaining candidate solutions are deemed as the omega wolves. The search (hunt) process is guided by , , and , which are concomitantly followed by the wolves. Gray wolves habitually encircle prey during the hunt. The equations that simulate this encircling behavior are presented as follows
where denotes the current iteration, represents the position vector of the prey, and represents the position vector of a gray wolf. and are coefficient vectors that are calculated from the following equations
where the elements of are linearly decreased from 2 to 0 during the search process, and and are random vectors in the interval [0, 1]. As the position of the optimum (prey) in an abstract search space is not known, the GWO supposes that the , , and wolves have better knowledge of the location of the prey. Thus, in the GWO, the potential solutions are required to update their positions according to the positions of , , and , using the formulas given below
The GWO starts with a random population of gray wolves and is easy to implement because of its simple parameters and simple mechanism.
HMOGWO
This article proposes a HMOGWO algorithm for the fuzzy blocking flow shop scheduling problem. As a multi-objective algorithm, the HMOGWO is developed based on the concept of Pareto optimality. It is described in detail below.
Solution representation
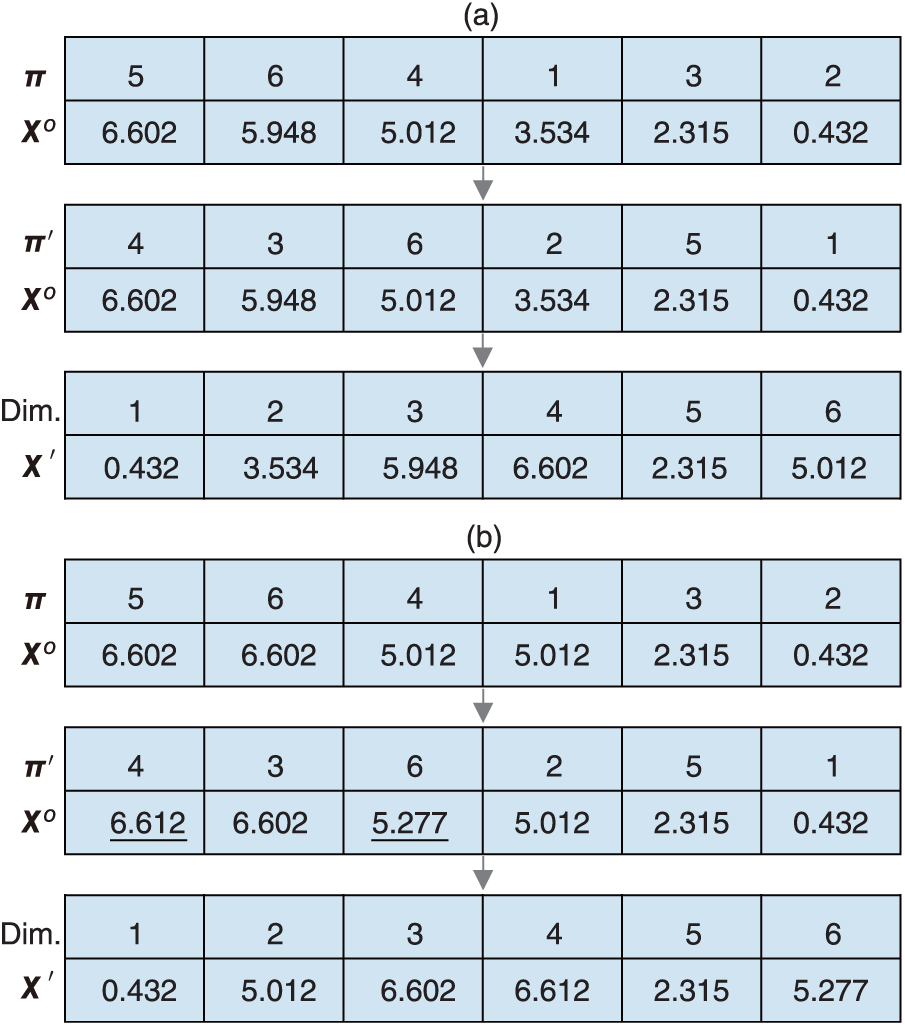
, the position of a gray wolf in the GWO, is an n-dimensional real number vector. In the HMOGWO, the largest position value (LPV) rule34 is utilized to convert the continuous position of a potential solution into a discrete n-job permutation . A simple example is illustrated in Figure 2. Each dimension is represented as a typical job, and the permutation is generated by sorting the position values of in non-increasing order. is the vector of the non-increasingly ordered position values.
Example of the mapping between the position and the job permutation.
Population initialization
The PFE heuristic6 is an effective heuristic for a blocking flow shop scheduling problem with makespan criterion. To produce initial solutions with a certain quality for the bi-objective scheduling problem considered in this article, a variant of the PFE heuristic denoted by PFE-Pareto and a simple yet effective heuristic termed AAI-Pareto are designed. The PFE-Pareto is used to produce non-dominated solution(s) that are biased toward minimizing the makespan, whereas the AAI-Pareto is for the non-dominated solution(s) that are biased toward maximizing the average agreement index . The procedures of the PFE-Pareto and AAI-Pareto are presented in Figures 3 and 4, respectively. In these figures, denotes the number of jobs, represents the number of machines, denotes the fuzzy processing time of job on machine , and denotes the fuzzy departure time of job on machine .
Pseudocode of the PFE-Pareto heuristic.
Pseudocode of the AAI-Pareto heuristic.
Forming a set of non-dominated individuals by gathering all the solutions obtained by these heuristics is an indispensable step in the heuristic process. Subsequently, the member(s) of the set with the largest crowding distance35 is (are) selected as the heuristic initial solution(s). To ensure the diversity of the initial population, the rest of the individuals are randomly generated, and the position of a solution, , is produced using the following equation
where and for each dimension , and is a uniform random number in the interval [0, 1]. Because a heuristic initial solution is a job permutation , it needs to be converted into a position vector. Fortunately, this conversion can be easily accomplished using the following equation
where and are the minimum and maximum values in the original position vector obtained by equation (22), respectively.
Archive and its maintenance
In the HMOGWO, an archive is used to store the non-dominated solutions that are produced during the search process. The predetermined maximum archive size limits the number of non-dominated solutions in the archive. The archive is maintained at each iteration, and the procedure of archive maintenance is presented as follows
Add every non-dominated solution obtained in the current iteration to the archive and then remove the dominated member(s) from the archive.
If the number of the non-dominated individuals in the archive does not exceed the , then keep the current archive; else, go to (3).
Apply a dynamic crowding distance-based maintenance strategy to the archive, as provided below:
Calculate the crowding distance of each non-dominated solution in the archive.
Assign a fitness value to each non-dominated solution according to equation (24).
Select a non-dominated solution using a roulette wheel selection based on the fitness values and remove it from the archive, then go to (2)
where represents the crowding distance of an archive member and , the deletion selection pressure coefficient, is a positive constant that takes the value of 4 in this article. It can be inferred that the solution with the smallest crowding distance is preferably removed. Since deleting a member will change the crowding distances of its neighbors, only one non-dominated solution is removed at each turn and then the crowding distances are recalculated. The dynamic maintenance strategy not only improves the distribution of non-dominated solutions but also prevents optimal solutions from being removed when removing several individuals located in a crowded region at a time.
Leader selection
The leaders (, , and wolves) in the HMOGWO tend to be selected from the archive. The leaders are selected using a fitness value-based roulette wheel, as defined in equation (25)
where denotes the crowding distance of an archive member and , the leader selection pressure coefficient, is a positive constant that is set to 2 in this article. This equation implies that a member possessing a larger crowding distance has a higher probability of becoming a leader. In the leader selection procedure, is first selected, followed by and . The member selected as a leader will not participate in the next selection. Importantly, three leaders might be selected in certain special cases. If there are fewer than three members in the archive, the other leader(s) are selected from the second non-domination level using the abovementioned roulette wheel. Similarly, if there is only one solution in the second level, and it is , then would be selected from the third level.
Local search strategy
Various studies have shown that incorporating a local search into an evolutionary optimization algorithm improves the exploitation capability of the algorithm. In addition, the insert neighborhood structure is recognized as being superior for yielding neighboring solutions for flow shop scheduling problems.36 Thus, two local search procedures based on the insert neighborhood structure are incorporated into the HMOGWO. To perform the local search strategy, each gray wolf (potential solution) is assumed to possess four attributes: current position, best previous position, and their corresponding job permutations. A potential solution whose current job permutation does not dominate its best previous job permutation is treated as unimproved. The local search procedure I shown in Figure 5 is implemented on each unimproved potential solution with a certain probability to produce an improved permutation that dominates the best previous one. The local search procedure II is applied to all archive members, that is, the candidate selected leaders, with a certain probability . As illustrated in Figure 6, the local search procedure II can yield one or more improved permutations for each archive member.
Pseudocode of local search procedure I.
Pseudocode of local search procedure II.
After the local search strategy is implemented, the position of an improved solution should be adjusted accordingly. Let be the vector of non-increasingly ordered position values, be an improved permutation, and be its corresponding position vector. As illustrated by the example in Figure 7(a), the adjustment can be easily achieved using the following formula
Note that the above adjustment can be used only if , . However, during the evolution of the HMOGWO, a position vector with some identical values might be yielded. If the adjustment is applied to such a position vector, the permutation implied by may differ from . To overcome this drawback, a simple revision process34 for is adopted to modify some of its position values. As shown by the example in Figure 7(b), the revision process can be easily performed using the procedure presented in Figure 8.
(a) Example of the adjustment of in the local search; (b) example of the revision process for with some identical values ( and ).
Pseudocode of the revision process for .
Outline of the proposed HMOGWO
In summary, the HMOGWO utilizes the LPV rule for solution representation, introduces a heuristic process for population initialization, applies a dynamic maintenance strategy for archiving, develops a thorough mechanism for leader selection, and incorporates a local search strategy based on the insert neighborhood structure. The pseudocode of the HMOGWO is provided in Figure 9, where denotes population scale, represents the current number of function evaluations, represents the maximum number of function evaluations, and is a uniform random number in the interval [0, 1].
Computational analysis
In this study, the performance of the HMOGWO is tested on real-time production data of panel block assembly in shipbuilding. A typical assembly line for panel blocks consists of seven main processes: baseplate splicing, baseplate welding, longitudinal assembly, longitudinal welding, girder and floor assembly, girder and floor welding, and checking and carting. Each process is implemented at its corresponding station. The panel blocks are usually of large size. Accordingly, no intermediate buffer between two consecutive stations exists, mainly because of a lack of space. In addition, the processing time of each process is often affected by uncertainty due to both machine and human factors, and the due date takes the form of an interval that is related to the satisfaction degree of the demand side. Therefore, the scheduling problem of panel block construction should be considered as a fuzzy blocking flow shop scheduling problem. The real-time data of the fuzzy processing time and the fuzzy due date of panel blocks to be constructed originate from a large shipyard in Shanghai, China. An example of the data is shown in Table 1. The most plausible value of the fuzzy processing time is established as the mean value of the historical processing times of the same or very similar panel blocks. The optimistic value and the pessimistic value are randomly obtained from and .19 In this study , , , and are set to 0.85, 0.90, 1.10 and 1.25, respectively, according to historical data and the advice of experienced engineers. The fuzzy due date of each panel block is provided by the hull block assembly shop, which is the demand side. The dataset used for performance evaluation comprises 40 instances grouped into four sets by (the number of jobs), where . In the performance evaluation experiment, the proposed HMOGWO is compared with two well-known population-based multi-objective evolutionary algorithms, the non-dominated sorting genetic algorithm II (NSGA-II)35 and the multi-objective particle swarm optimization (MOPSO) (constriction factor version37). This experiment is implemented in MATLAB R2015b on a computer with an Intel Core i5 2.50 GHz CPU and 4 GB RAM.
Example of fuzzy processing time and fuzzy due date.
Processing time/due date (min.)
Panel block Pb1
Panel block Pb2
121 139 174
87 97 122
206 240 271
150 172 191
118 131 161
87 97 110
124 146 182
103 114 143
143 166 199
106 120 135
204 240 300
139 164 200
111 125 145
72 80 94
1000 1300 2000 2500
2000 2200 2700 3000
Performance metrics
To evaluate the performance of multi-objective optimization algorithms, inverted generational distance (IGD),38 spread,35 and coverage39 are used as the metrics.
IGD
IGD measures the distance between each point composing the optimal Pareto front and the obtained front and is defined as
where is the number of points in the , and denotes the Euclidean distance between each point in the and its nearest neighbor in the obtained front. Because the of the scheduling problem is not known, a reference front established by gathering all obtained fronts of all the compared algorithms is used as a replacement. The indicator is used to evaluate convergence; a front with a lower value is desirable.
Spread
measures the extent of spread achieved in the obtained front. This indicator is defined as follows
where is the number of points in the obtained front, represents the Euclidean distance between consecutive points in the obtained front, is the average of these distances, and and are the Euclidean distances of boundary points of the obtained front to the extreme points of the . This indicator is 0 for an ideal distribution.
When calculating the and indicators, the objective values are normalized into values in the interval [1, 2]. Here, the makespan, which is assumed to be a triangular fuzzy number, is defuzzified using equation (12). Lower and indicators correspond with better obtained fronts.
Coverage
is a binary indicator. Let and represent two sets of approximate Pareto optimal solutions that are generated by algorithm A and algorithm B. , which is defined in equation (29), measures the fraction of the members of that are covered by members of , reflecting the dominance and equivalence relation between the two sets
The indicator maps the ordered pair to the interval [0, 1]. indicates that all of the solutions in are covered by individuals in , whereas implies that none of the solutions in are dominated or equaled by the members of .
Parameter tuning
The NSGA-II has three inherent parameters, namely, population scale , crossover probability , and mutation probability . and determine how often the crossover and the mutation operators will be performed, respectively. The MOPSO has five parameters: population scale , the maximum archive size , constriction factor , and two learning factors ( and ), where is set to one-fourth of , and . is used to alleviate the swarm convergence issue. and determine the influences of personal best and global best positions, respectively. Typically, and are set to 2.05, and is thus 0.7298.37 The HMOGWO has four parameters: population scale , the maximum archive size and two local search probabilities ( and ), where is set to one-fourth of . As population-based multi-objective evolutionary algorithms, the NSGA-II, MOPSO, and HMOGWO have a common parameter, that is, population scale . It is set to be 40, 60, 80, and 80 for the instances with 20, 30, 40, and 50 jobs, respectively. The maximum number of function evaluations is used as the stopping criterion, and all the algorithms are executed with for a n-job instance.
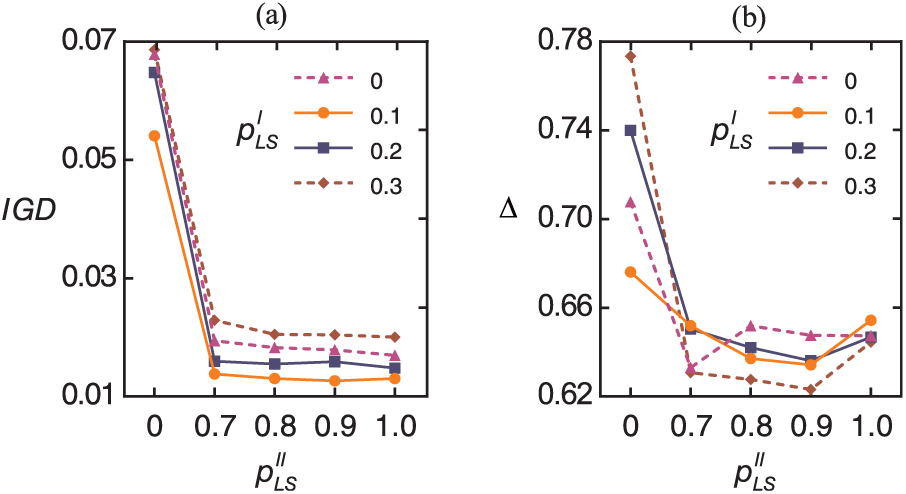
The performance of an algorithm is significantly affected by the values of parameters. The parameters and of the NSGA-II and and of the HMOGWO need to be tuned. Full factorial experiments are conducted to tune these parameters. The considered levels of these parameters are as follows: and ; and . and are for investigating the effects of the absences of the two parameters. Different combinations of parameters result in different configurations of an algorithm, each of which is independently run 30 times against all instances of the dataset for parameter tuning. Importantly, the dataset for parameter tuning is different from the dataset for performance evaluation. The former dataset consists of 20 instances divided into four groups by (the number of jobs), where . The and indicators are employed to evaluate each parameter combination. The parameter combinations that exhibit better performance are presented in Table 2. Figure 10 depicts the estimated marginal means of the and indicators for and of the HMOGWO over 20 instances. It can be seen that is always better than for both the and indicators and that yields a better indicator than . This observation indicates that the introduction of and in the HMOGWO is necessary and rewarding. Considering both the and indicators, and are established as 0.1 and 0.9, respectively (Figure 10).
Main parameter settings of NSGA-II, MOPSO, and HMOGWO.
Estimated marginal means of the and indicators for and : (a) IGD and (b) Δ.
Experimental evaluation of HMOGWO
In the performance evaluation experiment, the NSGA-II, MOPSO, and HMOGWO are configured by the parameters listed in Table 2. Each algorithm is independently run 30 times against all 40 instances of the dataset for performance evaluation. The means of the and indicators of each algorithm for each instance are computed from 30 replicates. Table 3 summarizes the mean values of the and indicators for the 10 instances in each group and indicates that on average, the HMOGWO outperforms the NSGA-II and MOPSO regarding the two indicators. To compute the indicator of two algorithms for each instance, a two-step procedure is proposed. First, form three sets that are, respectively, denoted as , , and by gathering all the non-dominated solutions produced by the corresponding algorithm in 30 runs. Second, compute , , , and using equation (29). Table 4 lists the mean values of the indicator for the 10 instances in each group. It can be observed that for each group, few optimal solutions of the HMOGWO are covered by those of the NSGA-II or MOPSO, whereas most or almost all optimal solutions of both the NSGA-II and MOPSO are covered by the individuals of the HMOGWO. This observation demonstrates that the HMOGWO is superior concerning the indicator compared to the other two algorithms. Figure 11 illustrates the distributions of the solutions in , , and in objective space for four instances with different number of jobs, that is, instance 20–10, 30–6, 40–3, and 50–1. The instance label, for example, 20–10 represents the 10th instance in the group of 20 jobs. The coverage of the optimal solutions obtained by different algorithms can be seen from this figure.
Results of the and indicators for the instances grouped by .
Distributions of the gathered solutions of each algorithm for four instances: (a) 20–10, (b) 30–6, (c) 40–3, and (d) 50–1.
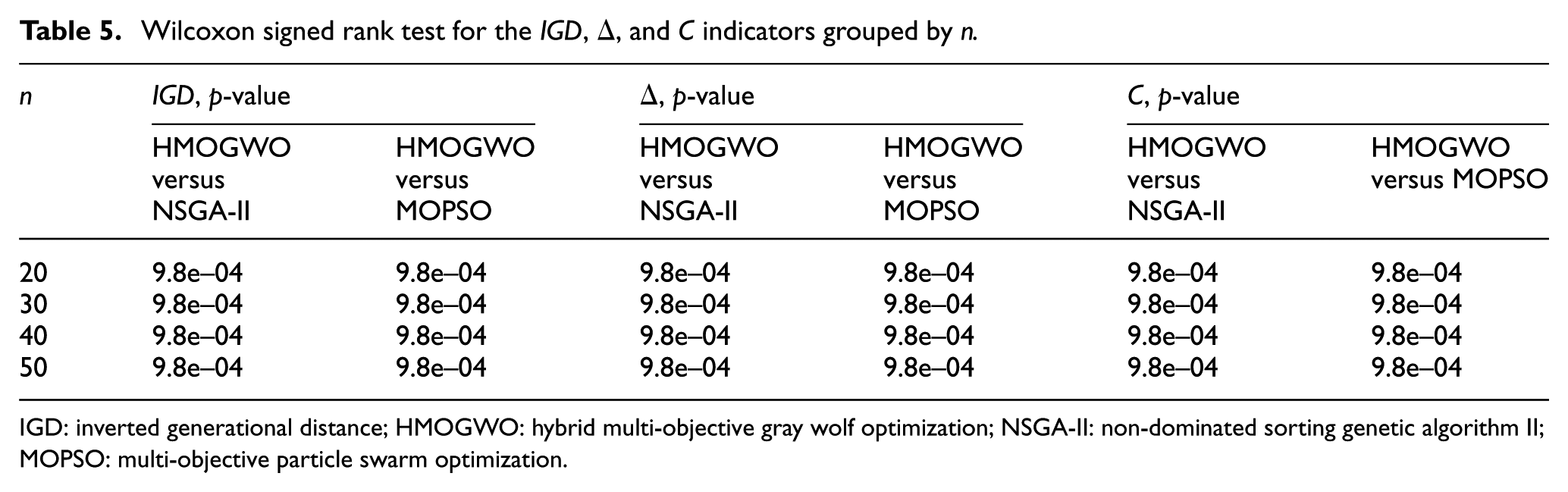
To test if the outperformance of the HMOGWO is statistically significant, for each group, pairwise comparisons of HMOGWO versus NSGA-II and HMOGWO versus MOPSO are performed by applying the Wilcoxon signed rank test to the , , and indicators for the involved instances. The Wilcoxon test which is a non-parametric test and does not require the assumption of normal distributions has been widely used to analyze the obtained results of evolutionary algorithms.32,40,41 The function wilcox.test(HMOGWO, NSGA-II or MOPSO, paired = TRUE, alternative = “less”) implemented in R version 3.2.4 is applied to the and indicators, and wilcox.test(HMOGWO, NSGA-II or MOPSO, paired = TRUE, alternative = “greater”) is used for the indicator. The statistical results in Table 5 suggest that for each group, the HMOGWO provides statistically better , , and indicators than the other algorithms. Moreover, Tables 3–5 show that the HMOGWO outperforms the other two algorithms and exhibits robust superiority for different problem sizes. In summary, the results of the , , and indicators demonstrate that the HMOGWO is competitive and effective in solving the fuzzy blocking flow shop scheduling problem in terms of the convergence, spread, and coverage of the optimal solutions.
Wilcoxon signed rank test for the , , and indicators grouped by .
Effects of the heuristic process and local search strategy
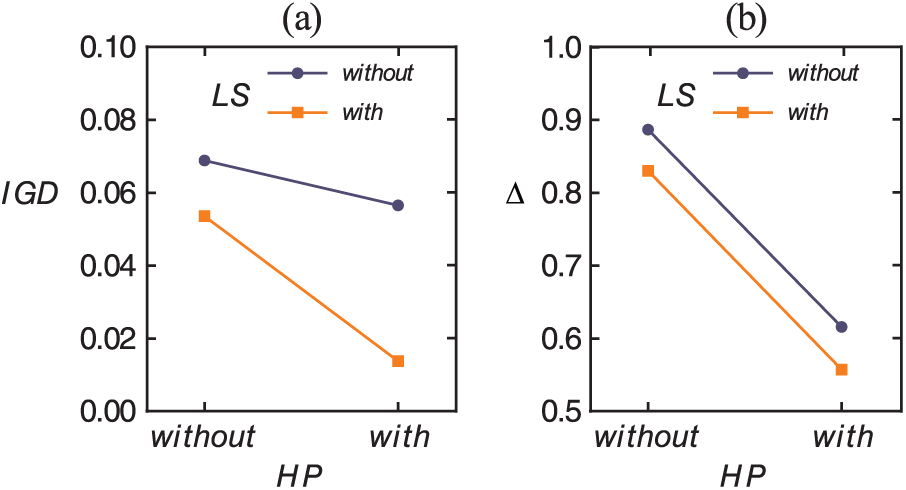
The heuristic process and local search strategy are two important components of the HMOGWO. An experiment is conducted to investigate the effects of them. For simplicity, hereafter denotes heuristic process and represents local search strategy. In this experiment, the levels of and are as follows: and . Therefore, four algorithms denoted by MOGWO-B, MOGWO-HP, MOGWO-LS, and HMOGWO (i.e. MOGWO-HP-LS) can be assembled, where MOGWO-B denotes basic MOGWO. The parameters, namely, the maximum number of function evaluations , population scale , the maximum archive size and two local search probabilities ( and ) follow the values presented in Table 2. Each algorithm is independently run 30 times for each instance of the dataset for performance evaluation. The and indicators of each algorithm are computed for performance evaluation. The estimated marginal means of the and indicators for and over 40 instances are shown in Figure 12. Clearly, is always better than , and is always better than , demonstrating that the heuristic process and the local search strategy are effective and contribute to improving the performance of the proposed algorithm.
Estimated marginal means of the and indicators for and : (a) IGD and (b) Δ.
Conclusion and future studies
This article formulates a fuzzy blocking flow shop scheduling problem with fuzzy processing time and fuzzy due date and considers simultaneously minimizing the fuzzy makespan and maximizing the average agreement index. The HMOGWO algorithm is proposed to solve this combinational optimization problem. It utilizes the LPV rule to convert the continuous position of potential solutions into discrete job permutations, employs a dynamic maintenance strategy to maintain the archive, and develops a thorough mechanism to select the leaders. In addition, the HMOGWO introduces a novel heuristic process to initialize population and generate a portion of initial solutions with a certain quality, and incorporates a local search strategy to improve its exploitation capability. Computational experiments are conducted on instances of panel block assembly in shipbuilding. Computational comparisons of the proposed HMOGWO with the NSGA-II and MOPSO demonstrate the effectiveness of the HMOGWO in solving the bi-criterion fuzzy blocking flow shop scheduling problem in terms of the convergence, spread, and coverage of the optimal solutions. Moreover, the heuristic process and the local search strategy are verified as being effective and improving the performance of the HMOGWO.
Future studies focus on the following aspects: (1) extending the HMOGWO to more complex fuzzy blocking flow shop scheduling problem considering other restrictions, such as sequence-dependent setup times; (2) investigating the hybridization of the HMOGWO with other algorithms to achieve even better results; and (3) studying the fuzzy blocking flow shop scheduling problem from the view of green manufacturing.
Footnotes
Handling Editor: Xichun Luo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
1.
GrabowskiJPemperaJ.Sequencing of jobs in some production system. Eur J Oper Res2000; 125: 535–550.
2.
GongHTangLDuinCW.A two-stage flow shop scheduling problem on a batching machine and a discrete machine with blocking and shared setup times. Comput Oper Res2010; 37: 960–969.
3.
HallNGSriskandarajahC.A survey of machine scheduling problems with blocking and no-wait in process. Oper Res1996; 44: 510–525.
4.
McCormickSTPinedoMLShenkerSet al. Sequencing in an assembly line with blocking to minimize cycle time. Oper Res1989; 37: 925–935.
5.
RonconiDPArmentanoVA.Lower bounding schemes for flowshops with blocking in-process. J Oper Res Soc2001; 52: 1289–1297.
6.
RonconiDP.A note on constructive heuristics for the flowshop problem with blocking. Int J Prod Econ2004; 87: 39–48.
7.
NawazMEnscoreEEHamI.A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega1983; 11: 91–95.
8.
CaraffaVIanesSBagchiTPet al. Minimizing makespan in a blocking flowshop using genetic algorithms. Int J Prod Econ2001; 70: 101–115.
9.
GrabowskiJPemperaJ.The permutation flow shop problem with blocking. A tabu search approach. Omega2007; 35: 302–311.
10.
WangXTangL.A discrete particle swarm optimization algorithm with self-adaptive diversity control for the permutation flowshop problem with blocking. Appl Soft Comput2012; 12: 652–662.
11.
DavendraDBialic-DavendraM.Scheduling flow shops with blocking using a discrete self-organising migrating algorithm. Int J Prod Res2013; 51: 2200–2218.
12.
ShaoZPiDShaoW.Estimation of distribution algorithm with path relinking for the blocking flow-shop scheduling problem. Eng Optimiz2017; 50: 1–23.
13.
WangLPanQKSuganthanPNet al. A novel hybrid discrete differential evolution algorithm for blocking flow shop scheduling problems. Comput Oper Res2010; 37: 509–520.
14.
RibasICompanysRTort-MartorellX.An iterated greedy algorithm for the flowshop scheduling problem with blocking. Omega2011; 39: 293–301.
15.
LinSWYingKC.Minimizing makespan in a blocking flowshop using a revised artificial immune system algorithm. Omega2013; 41: 383–389.
16.
PanQKWangLSangHYet al. A high performing memetic algorithm for the flowshop scheduling problem with blocking. IEEE T Autom Sci Eng2013; 10: 741–756.
17.
HanYGongDLiJet al. Solving the blocking flow shop scheduling problem with makespan using a modified fruit fly optimisation algorithm. Int J Prod Res2016; 54: 6782–6797.
WuHC.Solving the fuzzy earliness and tardiness in scheduling problems by using genetic algorithms. Expert Syst Appl2010; 37: 4860–4866.
22.
LaiPJWuHC.Evaluate the fuzzy completion times in the fuzzy flow shop scheduling problems using the virus-evolutionary genetic algorithms. Appl Soft Comput2011; 11: 4540–4550.
23.
SakawaMKubotaR.Fuzzy programming for multiobjective job shop scheduling with fuzzy processing time and fuzzy duedate through genetic algorithms. Eur J Oper Res2000; 120: 393–407.
24.
LeiD.Pareto archive particle swarm optimization for multi-objective fuzzy job shop scheduling problems. Int J Adv Manuf Tech2008; 37: 157–165.
WangCTianNJiZet al. Multi-objective fuzzy flexible job shop scheduling using memetic algorithm. J Stat Comput Sim2017; 87: 2828–2846.
27.
MirjaliliSMirjaliliSMLewisA.Grey wolf optimizer. Adv Eng Softw2014; 69: 46–61.
28.
ZhangSZhouYLiZet al. Grey wolf optimizer for unmanned combat aerial vehicle path planning. Adv Eng Softw2016; 99: 121–136.
29.
PradhanMRoyPKPalT.Grey wolf optimization applied to economic load dispatch problems. Int J Elec Power2016; 83: 325–334.
30.
KomakiGMKayvanfarV.Grey wolf optimizer algorithm for the two-stage assembly flow shop scheduling problem with release time. J Comput Sci2015; 8: 109–120.
31.
MirjaliliSSaremiSMirjaliliSMet al. Multi-objective grey wolf optimizer: a novel algorithm for multi-criterion optimization. Expert Syst Appl2016; 47: 106–119.
32.
LuCXiaoSLiXet al. An effective multi-objective discrete grey wolf optimizer for a real-world scheduling problem in welding production. Adv Eng Softw2016; 99: 161–176.
33.
LeiD.Fuzzy job shop scheduling problem with availability constraints. Comput Ind Eng2010; 58: 610–617.
34.
WangLPanQKTasgetirenMF.Minimizing the total flow time in a flow shop with blocking by using hybrid harmony search algorithms. Expert Syst Appl2010; 37: 7929–7936.
35.
DebKPratapAAgarwalSet al. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE T Evolut Comput2002; 6: 182–197.
36.
RuizRSttzleT.A simple and effective iterated greedy algorithm for the permutation flowshop scheduling problem. Eur J Oper Res2007; 177: 2033–2049.
37.
ClercMKennedyJ.The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE T Evolut Comput2002; 6: 58–73.
38.
Van VeldhuizenDA. Multiobjective evolutionary algorithms: classifications, analyses, and new innovations. PhD Thesis, Department of Electrical and Computer Engineering, Graduate School of Engineering & Management, Air Force Institute of Technology, Dayton, OH, 1999.
39.
ZitzlerEThieleL.Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE T Evolut Comput1999; 3: 257–271.
40.
DurilloJJNebroAJ.jMetal: a java framework for multi-objective optimization. Adv Eng Softw2011; 42: 760–771.
41.
GarcaSMolinaDLozanoMet al. A study on the use of non-parametric tests for analyzing the evolutionary algorithms’ behaviour: a case study on the CEC’2005 special session on real parameter optimization. J Heuristics2009; 15: 617–644.