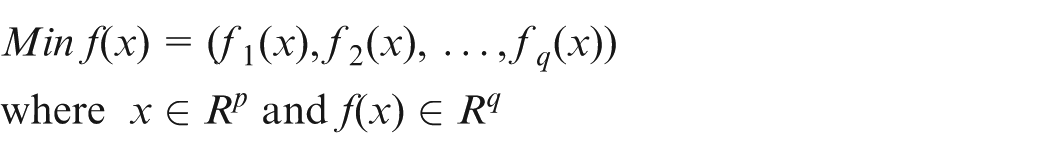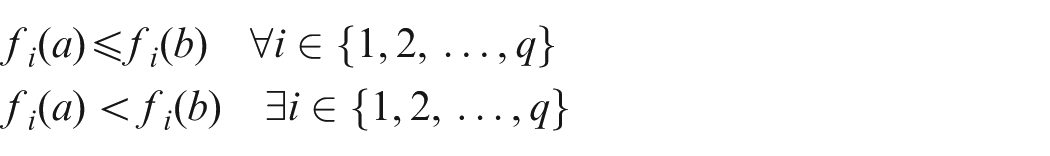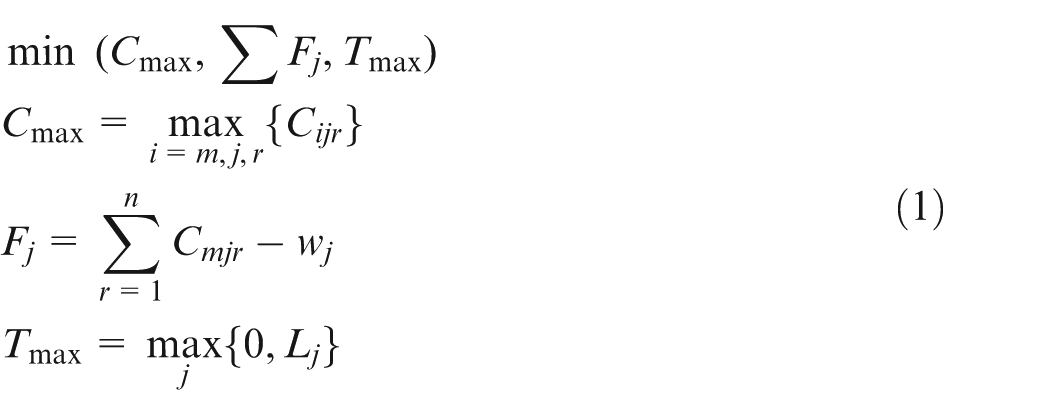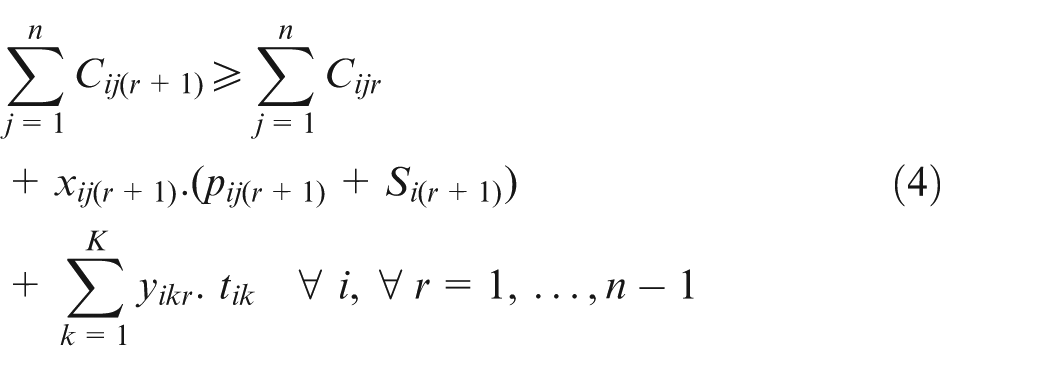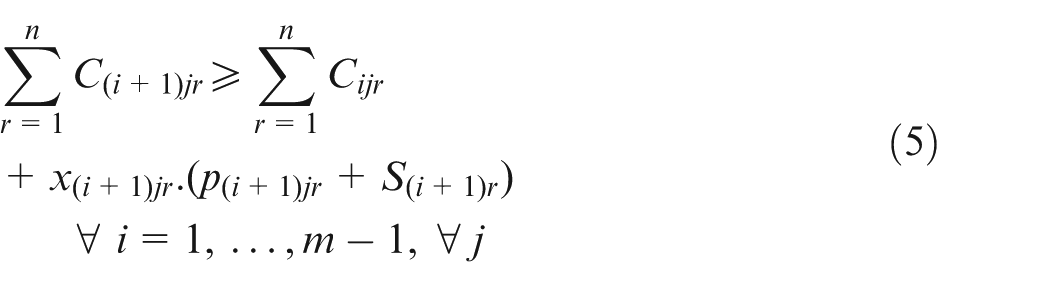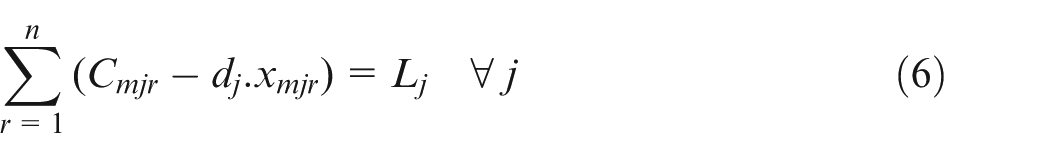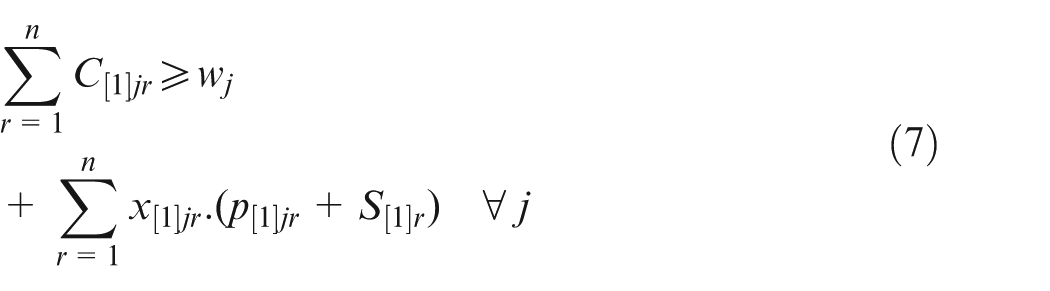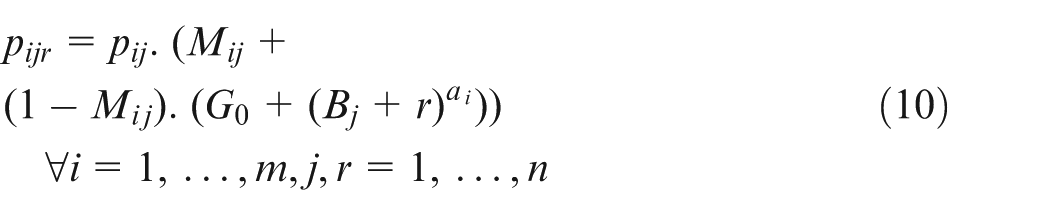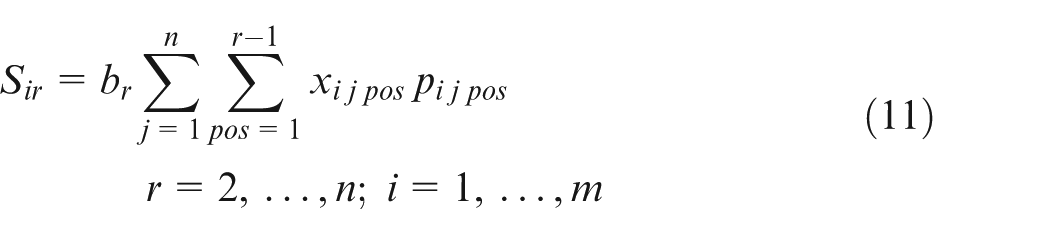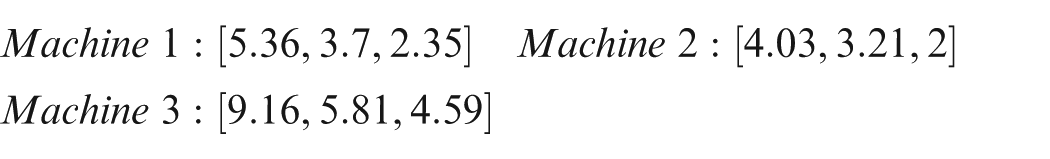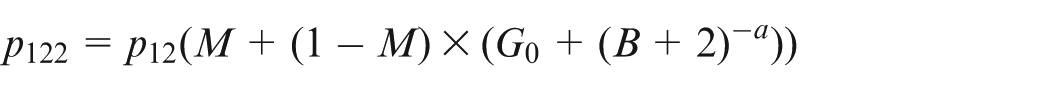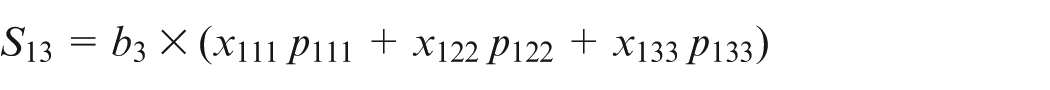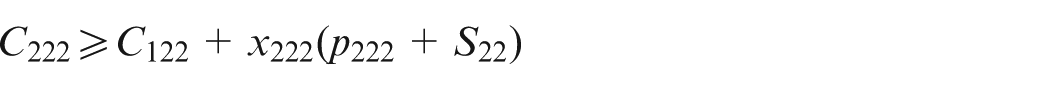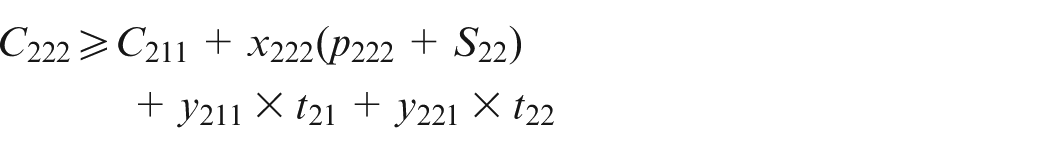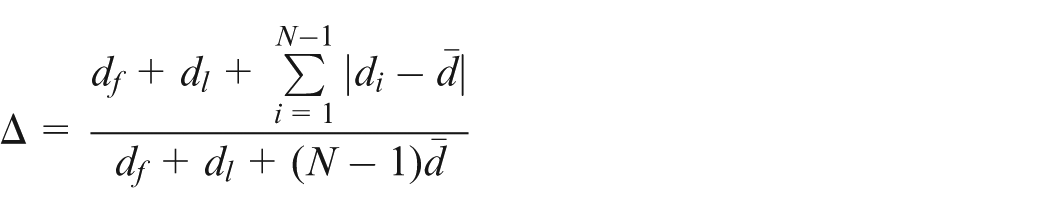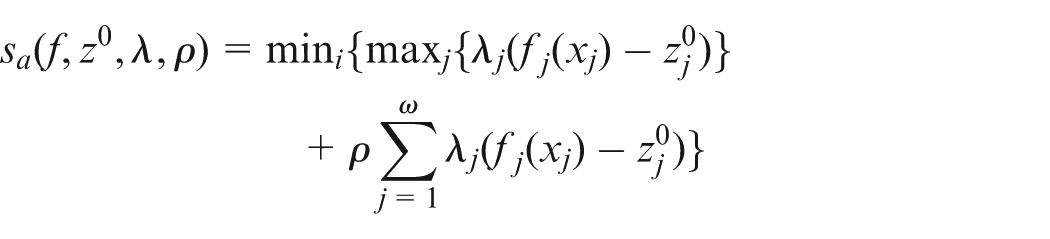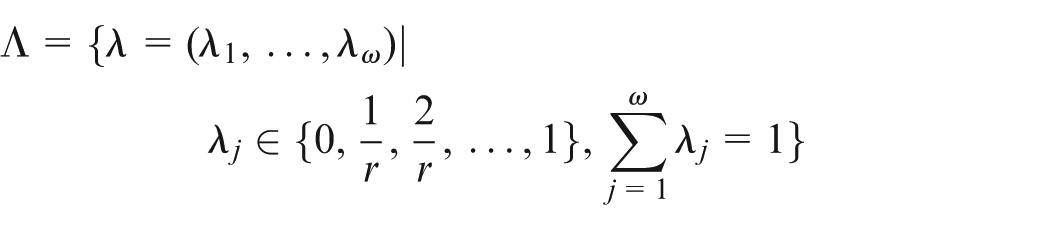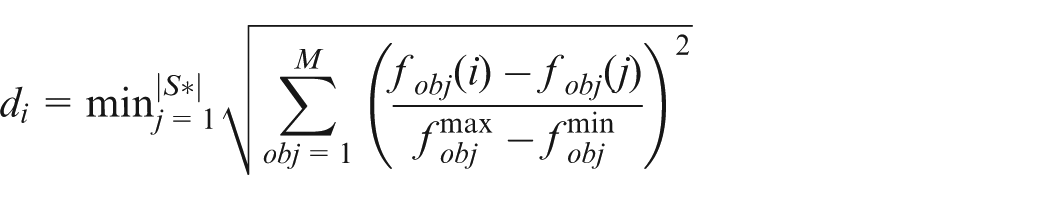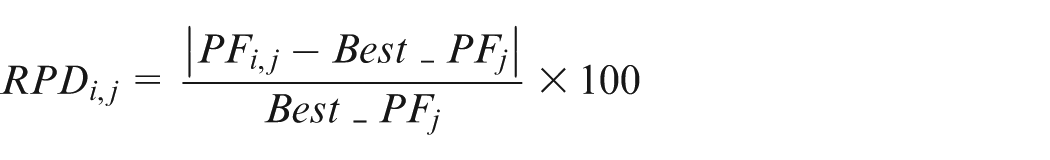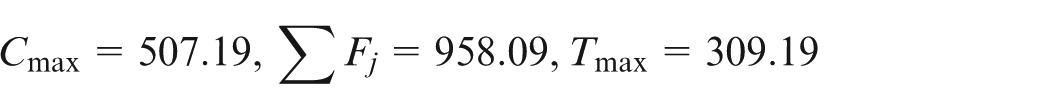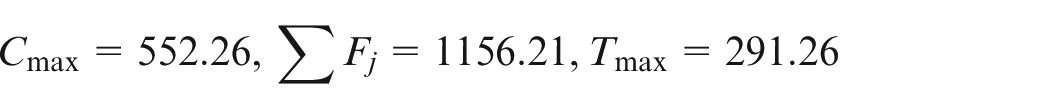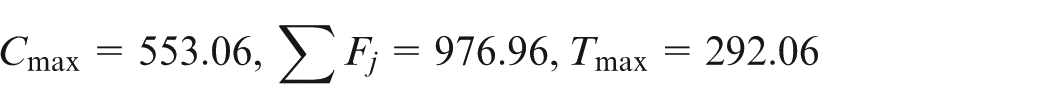In this article, a modification of multi-objective differential evolution based on simulated annealing is proposed to solve a general tri-objective non-permutation flow shop problem. The flow shop system considers the release dates, machine breakdowns, past-sequence-dependent setup times and learning effect for all the jobs. The algorithm proposed to tackle such a model combines the robustness of differential evolution with the rapid convergence and conditional diversification of simulated annealing. For small and medium low-sized problems, the solutions found by the proposed algorithm are compared with the exact solutions, achieved by augmented ε-constraint method. Due to the high complexity of the model, for medium high and large-sized problems, the algorithm is tested against the imperialist competitive algorithm and the multi-objective differential evolution scheduling. Comparisons of the results show a good balance between intensification and diversification in the proposed algorithm.
Flow shops are among the most attractive systems in scheduling. However, despite the progressive development of general flow shop models, there is still a noticeable gap between theory and practice.1,2 Thus, in this article, the following assumptions are considered. First, the truncated version of Dejong’s learning effect3 with operator’s prior experience considerations is added to the model. Learning effect in scheduling refers to the reduction in processing times due to the continuous improvement in the production performance. In other words, as the operator gains more skills, more shortcuts are found and the job is done in a shorter span of time. Moreover, the model considers the past-sequence-dependent (psd) setup times which is usually found in industries such as textile, metallurgical, printed circuit board and automobile manufacturing.4 This type of setup time relates the setup time of the current job under schedule to the sum of processing times of the jobs prior to it. The problem under study is a non-permutation flow shop system where the permutation of jobs on the machines is not necessarily the same. Hence, for n jobs and m machines, the solution space of a non-permutation flow shop has possible solutions instead of alternatives of its permutation counterpart. In reality, machines can be unavailable due to the changes in shifts, periodical maintenances or breakdowns. Thus, predetermined machine availability constraints are also considered.5 Moreover, most models in the literature are considered with a single objective despite the fact that real-world problems are multi-objective by nature.6,7 Considering several objectives in flow shop systems increases the complexity of an already NP-hard (i.e. non-deterministic polynomial-time hard) problem. As a result, most proposed solution techniques are practical up to a limited number of jobs or/and machines.3 Recently, meta-heuristics are proposed as alternative solution techniques.8,9 Differential evolution (DE) is a new meta-heuristic, famous for its robustness and fast convergence in continuous space.10 However, in discrete problems such as scheduling flow shop systems, DE can get trapped in the local valley, which arises the need for a diversification mechanism. Simulated annealing11 (SA) has been used to solve scheduling problems for many years. The logic behind SA can be used to find suitable and diverse solutions in flow shops. Inspired by these observations, a hybrid DE is proposed to tackle a tri-objective non-permutation general flow shop problem. The objectives under study are the maximum completion time of all jobs (i.e. the makespan), the sum of flow times and the maximum tardiness of all jobs. The rest of this article is organized as follows. In section “Brief introduction on multi-objective problems,” a brief introduction is given on multi-objective problems. In section “Mathematical formulation,” the system under study is presented and the proposed model of such a system is examined in details. In section “The proposed algorithm,” the proposed hybrid algorithm is explained. Section “Computational experiments” includes discussions on the comparison test results of the proposed algorithm. Finally, this article is concluded in section “Conclusion.” Note that the notation described in each section has the intended meaning in its own section and bears no relevance to the other parts of the article.
Brief introduction on multi-objective problems
The goal in a general multi-objective minimization problem is to find a set of Pareto optimal solutions within a feasible region which minimizes a vector of objective functions. The objectives are usually unrelated or in conflict with each other. Such a problem with q objectives and p decision variables has the following form
The Pareto optimal solutions (i.e. the set of non-dominated points) are the solutions that cannot be improved in one objective function without deteriorating their performance in at least one of the rest.12 The concept of domination for solutions can be defined as follows. Here, solution a dominates solution b if and only if
Mathematical formulation
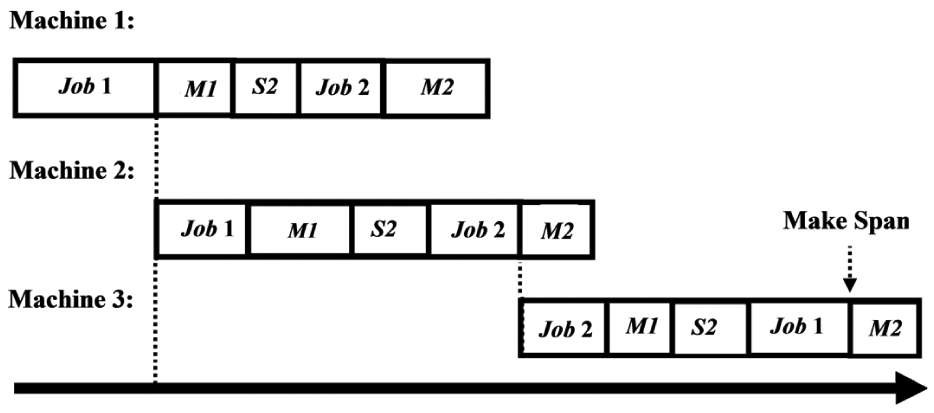
The current model is adapted from the authors’ latest research5 but with a modified learning effect. In addition to the learning effect, the model considers separate setup times, maintenance times, release times and due dates. Here, the flow shop problem for m machines, n jobs and K maintenance activities is formulated where all the jobs go through all the machines one by one and are subject to predetermined maintenances. A diagram of such a problem is illustrated in Figure 1 where two jobs on three machines are scheduled. In Figure 1, M1 and M2 are the first and second maintenance activities, respectively. Similarly, S2 refers to the second setup time. Note that for a psd setup time, S1 equals to zero for the first job on each machine and thus it is omitted. The sequences of jobs on different machines are not necessarily the same. For instance, the sequences of jobs on first and second machines are Job1-Job2 but this sequence changes to Job2-Job1 on the third machine. The makespan would be the completion time of the last job on the last machine. Note that a maintenance activity after the last job on each machine does not affect the makespan. First the parameters and decision variables, used in the model, are defined in Table 1. Then, the model is formulated in equations (1)–(8). Here, i, j, r and k are the machine, job, position and the maintenance activity indices, respectively.
An overview of the system.
Notation definitions.
Parameters
The normal processing time of job j on machine i
The actual processing time of job j on machine i in position r
psd setup time of the job in position r on machine i
Setup dependency parameter for job in position r
Release time of job j
Due date of job j
The learning index of machine i
The truncation parameter
Incompressibility parameter of job j on machine i
Operator’s experience parameter on job j
A predetermined matrix with binary values, where each value equals 1 if its corresponding machine i undergoes maintenance activity k after finishing the job in position r and 0 otherwise
The time length needed for maintenance k on machine i
H
A large positive number
Decision variables
A binary variable that is equal to 1 if job j is processed in position r on machine i and 0 otherwise
The completion time of job j on machine i if it is scheduled in the position r and otherwise it equals to 0
The lateness of job j
In equation (1), the objectives are defined as the makespan, sum of flow time and maximum tardiness, respectively
Equations (2) and (3) refer to the fact that on a particular machine, there is one job for each position and one position per job. Equation (4) states that the job in one position cannot finish before the completion of the job in the previous position. Additionally, if the maintenance activity k is scheduled on machine i for position r, then it should be done prior to the process of the job in the next position. Equation (5) is the concept of a flow shop problem, where a particular job should go through all machines one by one. Hence, the completion time of a job on the current machine is equal to or greater than its completion time on the previous machine plus its setup time and processing time on the current machine. Equation (6) defines the lateness of a job, that is, the difference between the completion time of a job on the last machine and its due date. Equation (7) defines the release date of each job. Note that this constraint is considered only on the first machine since when a job is about to start on the other machines, it has already surpassed its release date. Equation (8) ensures that the completion time of each job is either a logical positive number or it equals zero. That is, if a job is not processed in a certain position (i.e. if is zero), then its completion time on that particular position would be zero as well (i.e. its corresponding would be zero). On the other hand, if a job is processed in a specific position (i.e. if is one), then its completion time is a positive finite number smaller than the large number H. Finally, equation (9) states the decision variables.
Discussion on the model
In this section, the model presented above is examined in further details.
Learning effect
In the proposed model, the actual processing times of job j (i.e. ) is dependent on the machine i that it is processed on and its position r in the sequence of all jobs. This relation between the processing time and position of a job is due to the fact that positioning a (semi) manual job later in the sequence decreases the processing time of that job. This phenomenon is known as the learning effect. In other words, in a (semi) manual job, the operator gains experience with time and hence the time he or she needs to process a job gradually decreases up to a specific point. In this article, learning effect is formulated as follows
Here, shows the portion of machine times of a job, that is, refers to a completely manual job while indicates a full automatic job.3 Parameter B, imported from Stanford-B learning curve,13 indicates the operator’s prior experience. Once the operator has mastered a job, the decrease in processing times comes to a halt. This stop is formulated using a truncation parameter, , which controls the maximum reduction in processing times caused by learning effect. In equation (10), the values of , and should be given with care so that .
Setup time
In this article, in addition to the position, psd setup time of a job is also dependent on the machine that the job is processed upon as follows5
In equation (11), for a particular machine i and for a specific position r is a coefficient of the total processing times of all the jobs in previous positions on the same machine i. Hence, the later a job is processed, the longer its setup time. The example of such a case is in metallurgy industry where a certain high temperature is needed to operate a job. The temperature comes down with time so the longer a job is delayed, the longer it takes to increase the temperature back up again to the desired degree.
Discussion on the objectives
The key point in multi-objective problems is to choose the correct combination of objectives that can be considered together. The group of objectives selected cannot have direct relations with each other or else they are considered as one objective. In this article, the objectives are , and . Simply put, is the bottleneck time, is the total time of processing all jobs and is the maximum tardiness among the jobs. An increase (decrease) in leads to an increase (decrease) in , but the reverse is not necessarily true. Thus, the relation between the two is not direct. Similarly, an increase in does not necessarily effect since the bottleneck job is not necessarily the job that resulted in the maximum tardiness. The relation between and is not direct because might decrease, increase or stay indifferent to any changes in . Hence, the three objectives can be considered together in a multi-objective problem.
The proposed algorithm
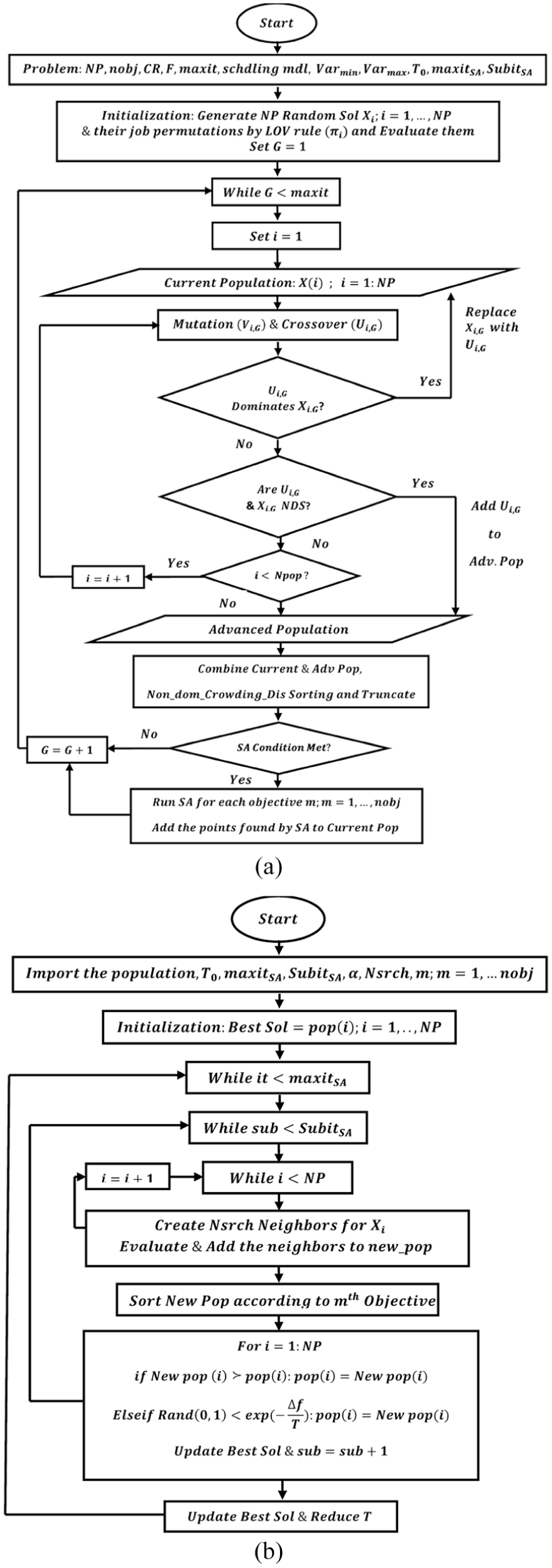
The proposed algorithm, namely, multi-objective simulated annealing differential evolution (MO-SADE), is a hybrid method which combines the multi-objective DE with the population-based SA. Similar to other evolutionary methods,14 the algorithm starts with a random population of real individuals from the continuous search region. Since the flow shop problem under study is discrete by nature, a technique is needed to convert the continuous solutions to job permutations and vice versa. After the initialization stage, the algorithm enters the main loop which includes an inner and outer loop. The inner loop uses strategy and two populations to find the non-dominated schedules. The outer loop utilizes the single-objective SA to find the extreme points in respect to each objective. Since SA is an additional search method, it is possible to run it conditionally for each generation, or for every 10 generation or just for the last generation. If this condition is met, the algorithm enters the SA loop; otherwise, it proceeds to the next DE generation. The framework of the algorithm can be outlined as follows. First, the problem and parameters should be defined: (a) set SA parameters: initial temperature , maximum number of SA iterations , number of iterations for the inner loop of SA with a constant temperature , the iterative reduction rate in temperature and the number of neighbors created for each individual . Here, is the temperature for each iteration G. (b) Set DE parameters: initial population size , the upper bound on population individuals and lower bound , number of objectives , maximum number of iterations scheduling model inputs for n jobs and m machines, crossover rate , mutation control parameter . Additionally, set as the best individual in generation G and set as an empty additional population.
Next step is the initialization phase, followed by the main loop. The procedures for these steps are summarized in Figure 2(a) and (b), respectively. The flowchart of the algorithm is also illustrated in Figure 3(a). Similarly, SA starts by importing the population from DE. The main loop of SA is explained in Figure 2(c). The insert, reverse or swap operators for job permutation are defined in Figure 2(d) where is the number of elements in the permutation , chooses two integer values from n, called and , and is the neighbor created from the original permutation . In the population-based SA, instead of conducting the search on a single individual, SA is repeated for a population of individuals. The flowchart of the proposed SA is shown in Figure 3(b).
(a) Initialization phase, (b) main loop of MO-SADE, (c) main loop of SA and (d) search operators of SA.
(a) Framework of the proposed algorithm(MO-SADE) and (b) framework of population-based SA.
Constraint handling in MO-SADE
Consider the problem of three jobs on three machines with two maintenance activities. MO-SADE commences by generating a random sequence for each machine. The length of each sequence is the same as the number of jobs.
Hence, three random sequences are generated using uniform distribution for and as follows
According to the Largest Order Value (LOV) rule, the largest value in a sequence gets the first position. Since the random values are sorted decreasingly on all machines, the corresponding permutations are achieved as for all the machines. This solution is the equivalent of for machine 1, for machine 2 and for the last machine.
Using the achieved values for , the processing times can be calculated using equation (10). For instance, can be achieved as follows
Similarly, setup times can also be calculated by equation (11). For instance, can be calculated as follows
Then, from constraints (4) and (5), would be achieved. For instance, according to equation (5), should satisfy the following equation
Simultaneously, should also consider the maintenance times mentioned in equation (4) as follows
So basically, the maximum value between these two equations would be . Once the completion time of each job on the last machine is determined, the lateness of each job can be calculated by equation (6). For instance, is calculated as follows
Since tardiness of a job is the maximum of zero and its lateness, then the tardiness of each job would be and from there the objective values can be calculated.
Computational experiments
In this section, first four performance metrics are suggested for evaluating the proposed algorithm. Then, MO-SADE parameters are calibrated with Taguchi method. Finally, MO-SADE is tested on random benchmark problems and the results are compared to those of other methods. The experiments are performed with CPU @ 1.70 GHz with 4 GB of RAM.
Performance metrics
Here, four performance metrics are suggested to evaluate the results.
Overall non-dominated vector generation
Overall non-dominated vector generation (ONVG) simply counts the number of solutions found in the true Pareto front.15 The idea behind this is that higher ONVG indicates better exploration.
Diversity metric (Δ)
This metric gauges the distance between the solutions of a Pareto set to see how well spread the achieved points are. For N solutions of a set, it is defined as follows16
where is the Euclidean distance between consecutive solutions in the Pareto set and the average of these points is . Here, and are the distances between the extreme solutions and the boundary solutions, respectively. The smaller Δ shows better performance.
Average quality metric
This performance metric measures the quality of the solutions achieved. It is formulated as follows15
where
Here, is the objective in the ω-dimensional objective space where and is defined by
where the reference point is set as and . A smaller average quality (AQ) metric indicates better quality.
Convergence metric (γ)
This metric measures the convergence of N individuals in the Pareto set toward a reference set . It is formulated as16
where for the solution is
and M is the number of objectives. Here, are the maximum and minimum values of the objective, respectively. Smaller indicates better performance.
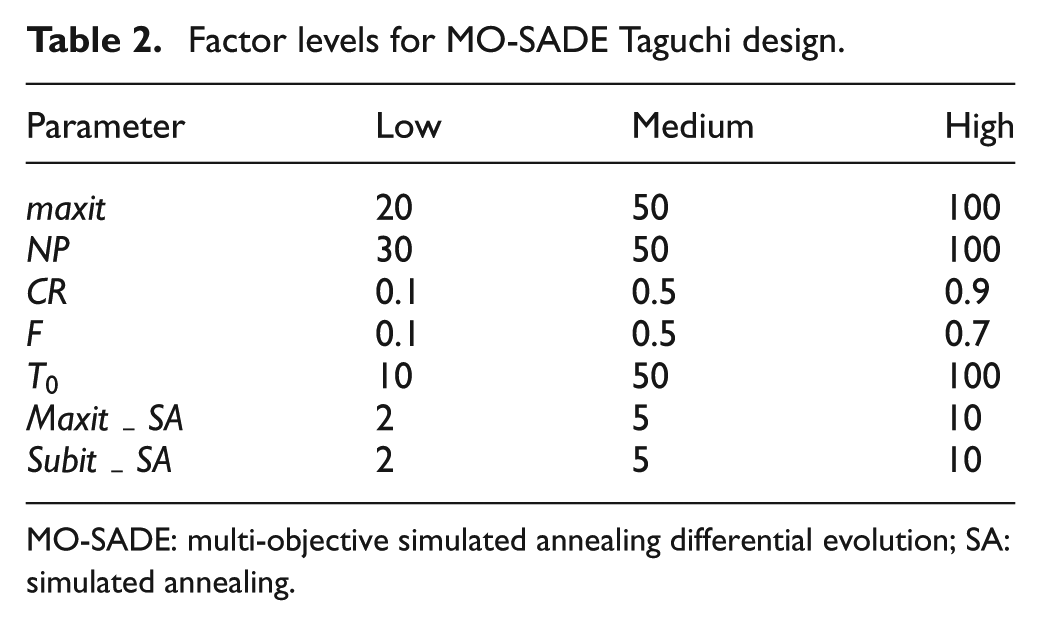
Parameter calibration
Similar to most meta-heuristics, MO-SADE is quite sensitive to its initial parameters. Here, the Taguchi method is used to determine the best combination of parameters in order to enhance the algorithm robustness. First seven factors are chosen and three levels are defined for each (Table 2). That returns orthogonal array for small and medium problems. Since the problem under study is multi-objective, first the experiments are carried out and then four performance metrics for each 27 experiments are calculated. Next, the values are scaled using the relative percentage deviation (RPD) concept as follows and the weighted average of them is used as a response
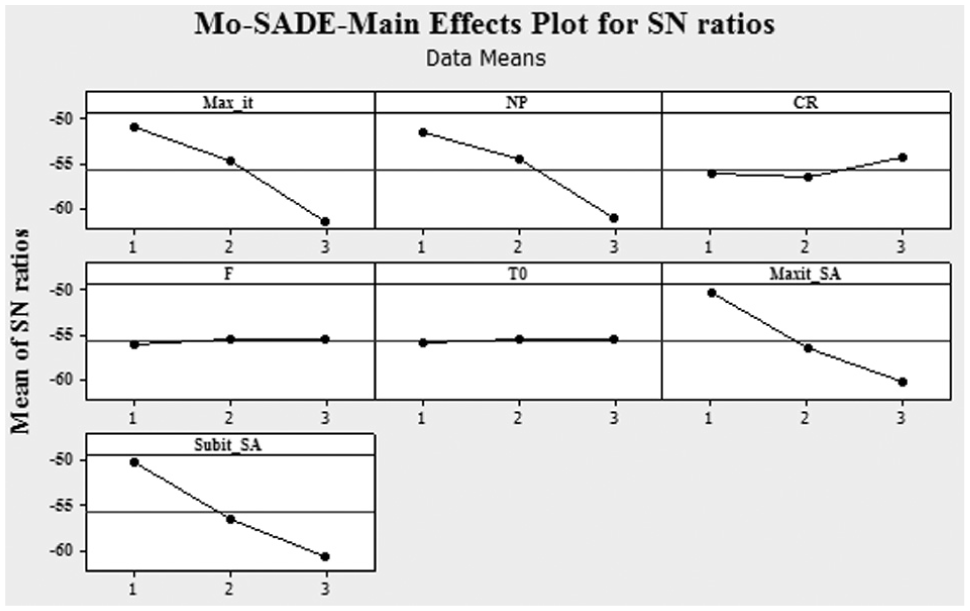
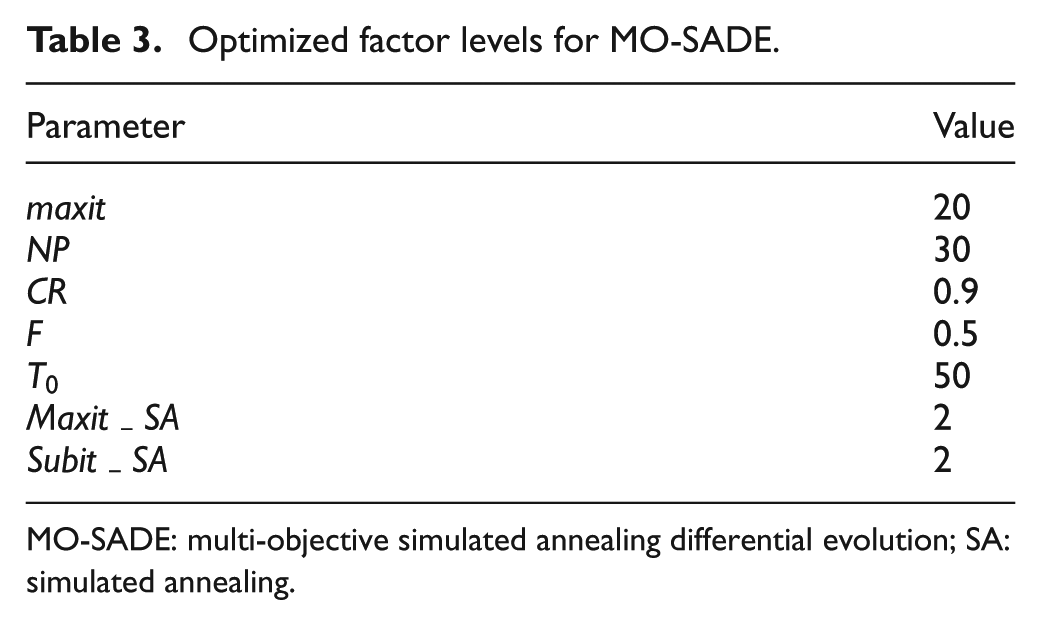
where is the scaled value for experiment i of performance metric . Similarly, refers to the value of performance metric of run and is the best value among the values achieved for the performance metric. Figure 4 shows the signal to noise (S/N) ratio achieved by the Taguchi analysis, respectively. The best level for each factor is the one with higher S/N ratio. Table 3 shows the optimized levels for each factor.
In this section, for small and medium low problems, the proposed MO-SADE is compared with the exact values achieved by solving the mixed integer model using augmented ε-constraint method.12,17 For medium high and large problems, MO-SADE is compared with two other meta-heuristics, that is, imperialist competitive algorithm (ICA) and multi-objective differential evolution scheduling (MDES).10 Problems are labeled as , where the possible solutions for a problem equal to . For example, the problem refers to a non-permutation flow shop problem with three machines, three jobs, two maintenance activities and possible solutions. For simplicity, all the tests are carried out with 70% of learning .
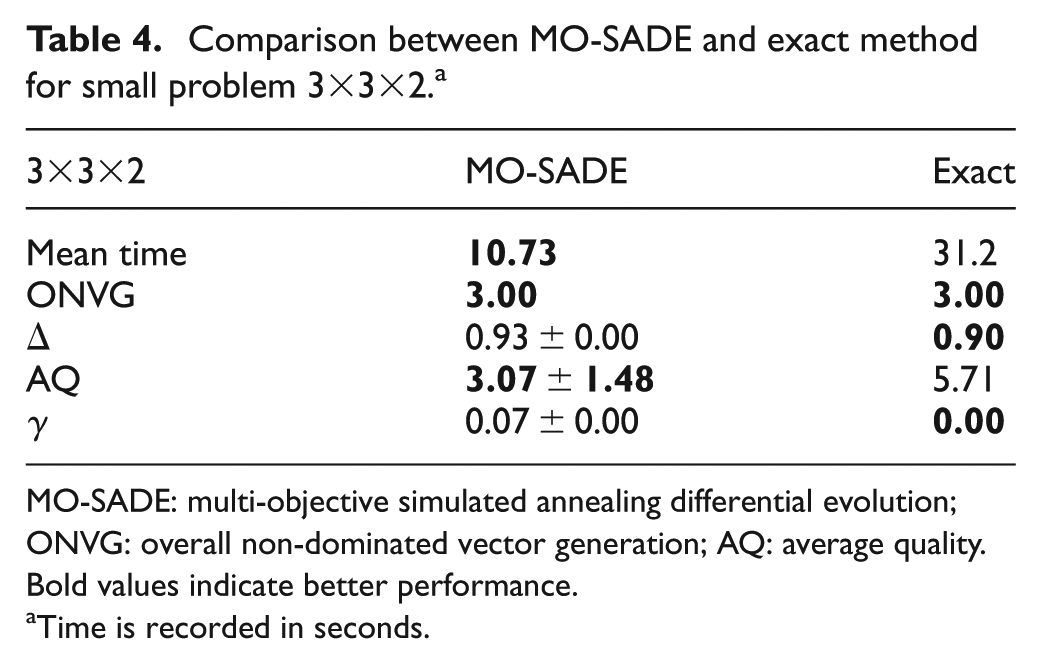
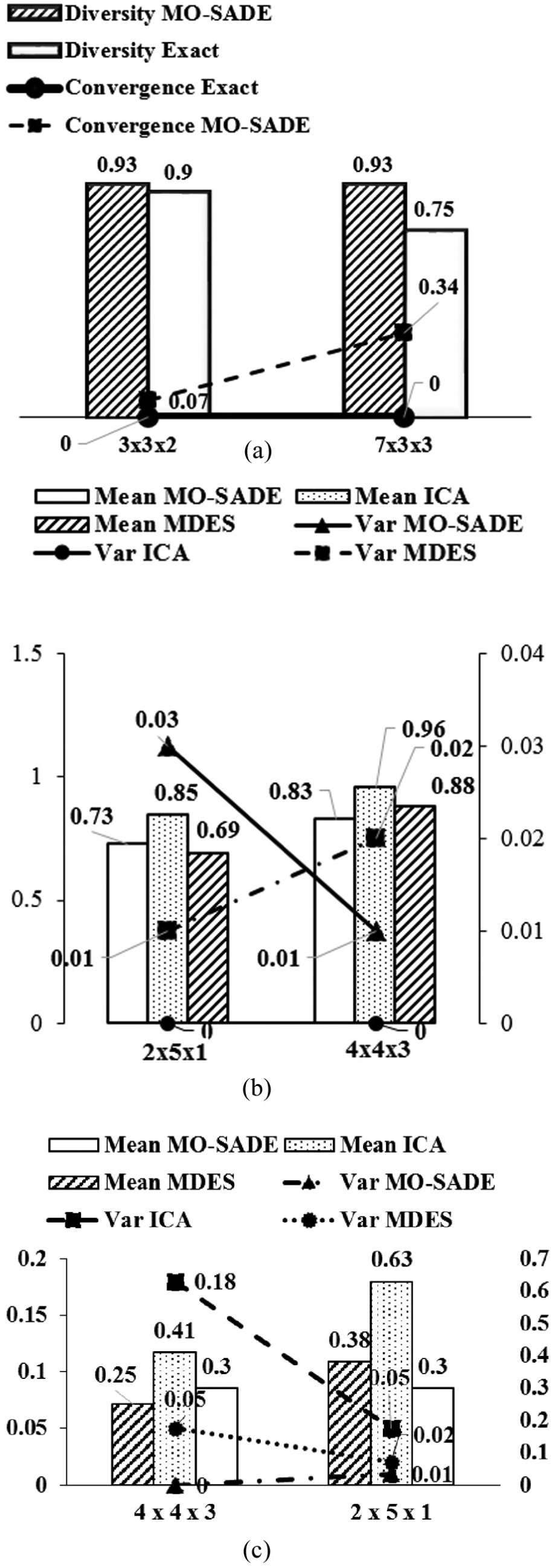
In this article, based on the time it takes to find a solution and the number of possible solutions, the problems are divided into four categories: (a) small: if the number of possible solutions does not have higher than three digits and a solution is found via the exact method under 1800 s; (b) medium low: if the number of possible solutions has between three and six digits and a solution is found via the exact method under 1800 s; (c) medium high: if the number of possible solutions has between three and six digits and a solution is not found by the exact method in 2400 s; (d) large: if the number of possible solutions has six digits or higher and a solution is not found by the exact method in 3000 s. One problem from each category is examined. Problem is a small problem which has 432 possible solutions and is solved in approximately 30 s by the exact method. Problem is medium low since it has 839,808 possible solutions but it is solved in 1120 s by the exact method. This is due to the fact that the run time is more sensitive to the number of jobs rather than the number of machines. Problem is an example of medium high problem with the possible solutions of 14,400 and it takes more than 2400 s to be solved by the exact method. Finally, problem is considered large with 995,328 possible solutions and run time of higher than 3000 s via the exact method (The specification of sample problems are available in the Appendix part at: http://le-scheduling.blogfa.com/page/JEM2016). The results are summarized in Tables 4–7 and illustrated in Figure 5. As can be seen in Table 4, for problem , ONVG has the same value for MO-SADE and the exact method, which means similar exploration performance. The exact method performs marginally better than MO-SADE in diversity (3% difference in ) and also in convergence (7% difference in ). On the other hand, MO-SADE performs faster than the exact method by approximately 20 s. Finally, MO-SADE has better balance between intensification and diversification than the exact method by 85% .
Comparison between MO-SADE and exact method for small problem .a
(a) Comparison between the exact method and MO-SADE for a small problem and a medium low problem , (b) mean and variance diversity metric comparison of medium high and large problem and (c) mean and variance convergence metric comparison of medium high and large problem .
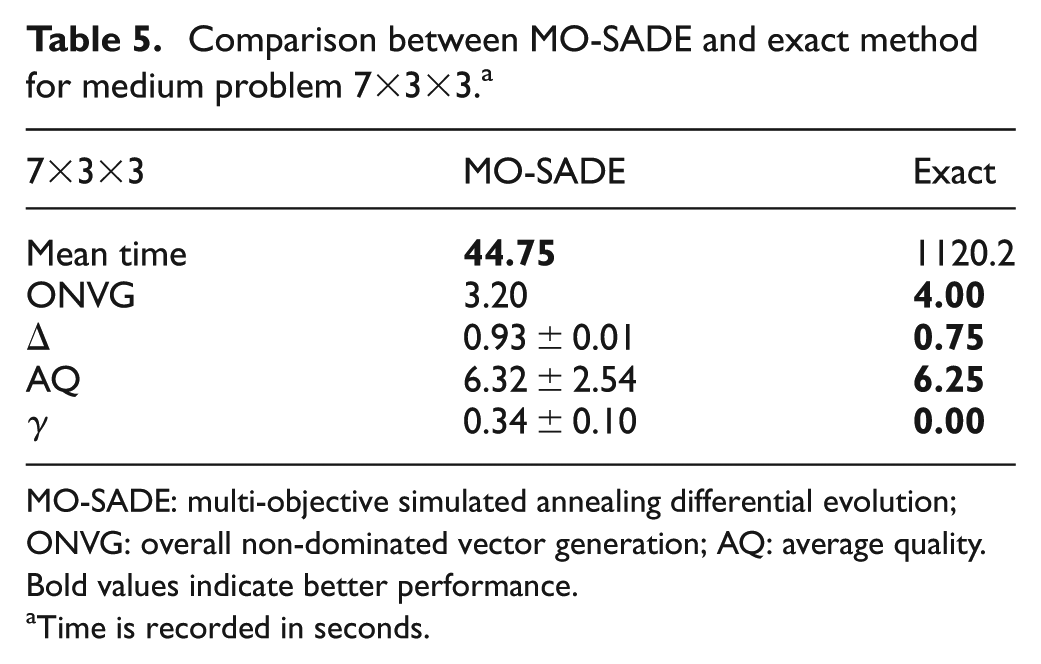
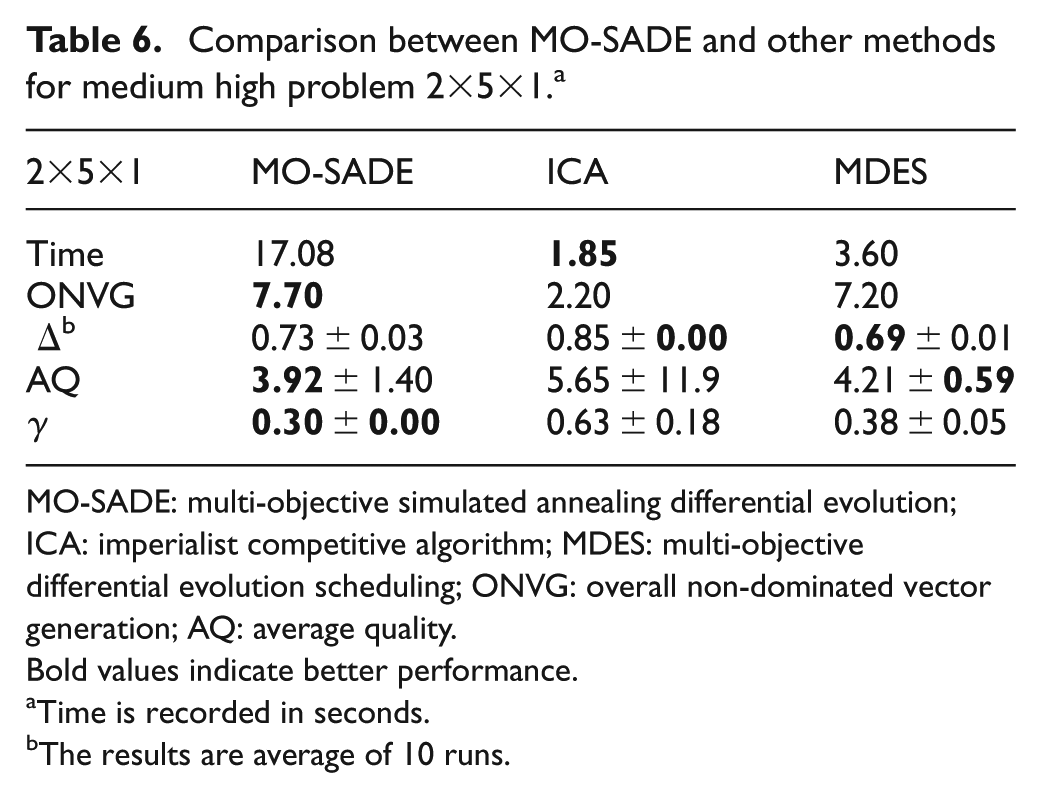
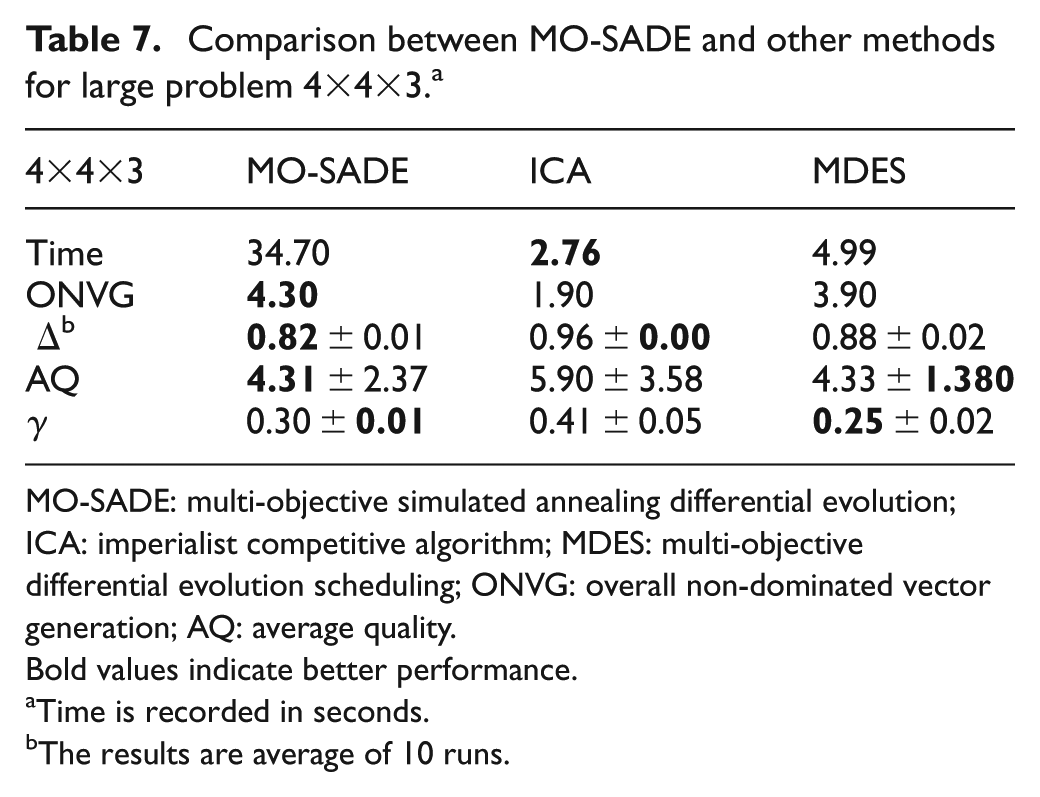
The test results on medium low problem are shown in Table 5. For this problem, the exact method performs better but it takes 25 times more seconds to solve the problem since MO-SADE takes 44.75 s to solve the problem while the exact method needs 1120.2 s to find similar results. The differences between the exact method and MO-SADE in regard to the exploration , diversity , convergence and quality of solutions are 8%, 18%, 34% and 7%, respectively, with the exact method being in the lead. These differences are relatively small in regard to approximately 1075 more seconds needed to achieve better results. In Figure 5(a), the differences in convergence and diversity of exact method and MO-SADE are illustrated for small and medium low problems, where the lower values are preferred. As can be seen, the exact method is slightly better than the proposed meta-heuristic both in convergence and diversity. However, exact method has high computational time, hence the use of MO-SADE in larger problems. For consistency, in medium high and large problems, the stopping criteria and population size for all algorithms are set to 20 iterations and 30 individuals, respectively. In Table 6, for the medium high problem , MO-SADE is compared with ICA and MDES. For this problem, from Table 6, it can be seen that ICA is the fastest method with run time of 1.85 s. However, the quality of solutions found by ICA is quite low. The ONVG achieved by ICA is 2.20 which is approximately 5 units less than the ONVG of MO-SADE (i.e. 7.70) and MDES (i.e. 7.20). Since higher ONVG is an indicator of better exploration, it can be concluded that MO-SADE has the best exploration among the methods, followed closely by MDES and with a wide gap by ICA. As for diversity metric , lower values are more desirable. As can be seen in the third row of Table 6, MO-SADE and MDES have nearly identical values in diversity metric (approximately 0.7) whereas diversity metric for ICA is quite high (i.e. 0.85) which shows the worst diversity. The quality metric AQ indicates overall quality of the solutions and lower values of this metric are desirable. As can be seen in Table 6, MO-SADE has the best quality (lowest AQ = 3.92), followed by MDES (AQ = 4.21) and finally ICA (AQ = 5.65). In other words, in regard to the quality of solutions, MO-SADE is superior to MDES and ICA by 7% and 44%, respectively. In regard to convergence , MO-SADE finds the lowest value which indicates the best precision among the algorithms. This means MO-SADE is superior to MDES and ICA with the differences of 10% and 50% , respectively. In Table 7, for the problem , ICA is once again the fastest algorithm with the run time of about 3 s, closely followed by MDES with run time of approximately 5 s. However, MO-SADE takes about 11 times longer than ICA and 7 times longer than MDES to find the solutions. This rise in computational time is justified by a rise in quality of achieved solutions.
On the account of exploration, MO-SADE has the highest ONVG , which shows better exploration of the search than MDES and ICA by 9% and 55%, respectively. As can be seen in the third row of Table 7, MO-SADE has the lowest which means the best diversity among the algorithms . This means MO-SADE is superior to MDES and ICA with the differences of 5% and 8% , respectively. The fourth row of Table 7 gauges the quality of solutions. MO-SADE and MDES have almost the same quality (4.31 and 4.33, respectively) which is much better than that of ICA with quality metric of 5.90 by 37%. However, MDES achieves a better convergence metric than MO-SADE and ICA with the difference of 5% and 16%, respectively. Figure 5(b) and (c) shows the comparison between the diversity and convergence of MO-SADE, MDES and ICA for medium high and large problems, respectively, where lower values are desired. As can be seen in Figure 5(b), MO-SADE and MDES have similar performance and ICA has the worst mean diversity among the methods. The difference in variances is at most 3% which is an inconsequential gap so it can be concluded that all the algorithms are relatively similar in robustness of diversity metric.
Similarly, in Figure 5(c), MO-SADE has the lowest variances, which means it is the most robust algorithm, followed by MDES and ICA, respectively. On mean convergence, MO-SADE and MDES have similar performance and ICA has the worst performance.
An example on effect of SA in MO-SADE
In this section, the behavior of the algorithm is examined for the small problem . This problem has three non-dominated solutions as follows:
Solution 1
Solution 2
Solution 3
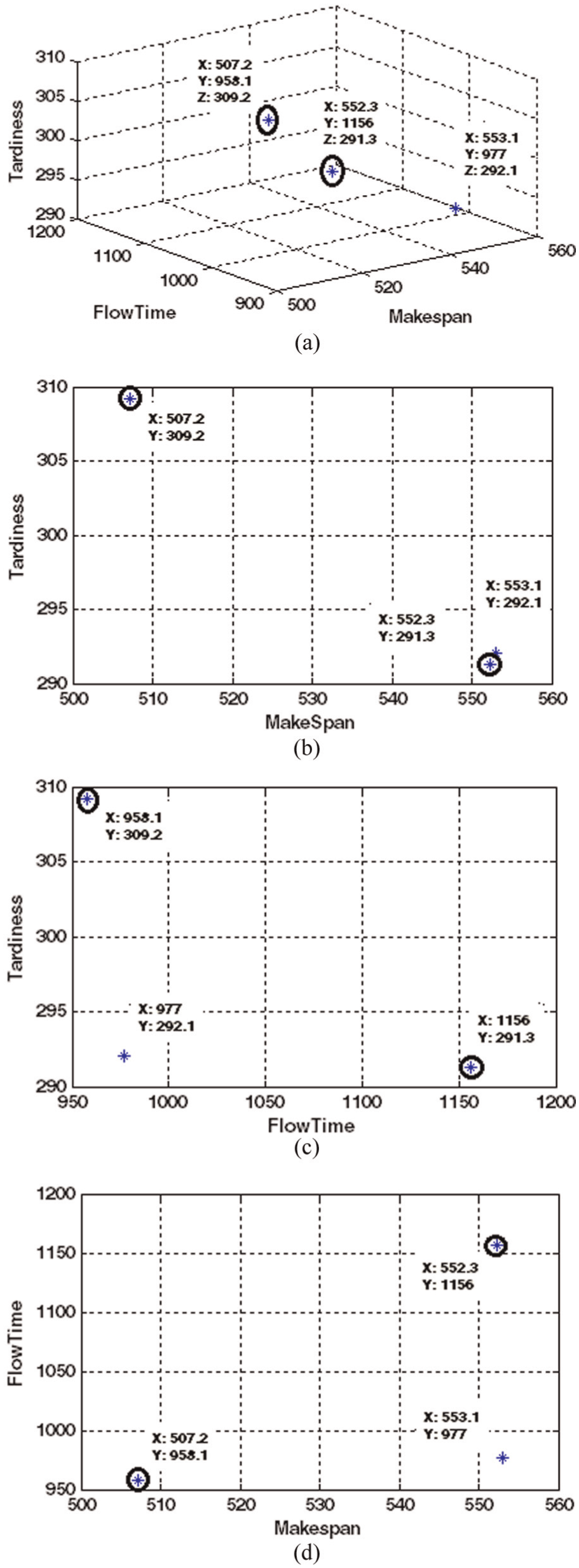
According to our computations, SA finds the extreme values of makespan, sum of flow time and maximum tardiness as 507.19, 958.09 and 291.26, respectively. These values are shown in solutions 1 and 2. Solution 3 is found by DE, which is quite similar to Solution 2. In other words, DE finds a non-dominated neighbor for the extreme points found by SA. This can also be seen in Figure 6, where the extreme points found by SA are circled and the rest are found by DE. The three side views help to see the location of each point in respect to different objectives. In the first side view (makespan vs tardiness), the circled point of and , found by SA, is quite near to the point above it, and , which is found by DE. In other words, DE has balanced the exploration between objectives by worsening and a little, while finding a better value for the third objective as follows and thus creating a third non-dominated point: . In summary, the idea behind inserting SA to DE is the fact that DE progresses with a balanced exploration. In other words, it finds a solution which minimizes all the objectives best. Consequently, it takes a long time to find the extreme points for each objective. On the other hand, since SA is run for a single objective, it can find the extreme values with ease. Note that extreme values of each objective are always included in the true Pareto front. Hence, by imbedding SA in DE, the extreme points are added to the population in each generation. Then, DE takes over and finds the neighbors of the extreme values, thus creating a converged and diverse Pareto front.
Points found by SA and DE for problem .
Conclusion
In this article, a general flow shop problem is addressed where the jobs’ processing times and psd setup times are affected by a modified learning effect. Since the problem is strongly NP-hard, it was tackled by a multi-objective DE algorithm based on simulated annealing (named MO-SADE). The population-based SA imbedded in the algorithm is run once for each objective with the solo minimization of that particular objective in mind. Adding SA to DE improved the exploration and resulted in a well-converged and diverse Pareto solution. When compared with other methods, MO-SADE showed better balance between convergence and diversity. An extension of the current problem in job shop or flexible flow shop scheduling might be an interesting topic for future research.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
References
1.
SeidgarHZandiehMFazlollahtabarH. Simulated imperialist competitive algorithm in two-stage assembly flow shop with machine breakdowns and preventive maintenance. Proc IMechE, Part B: J Engineering Manufacture. Epub ahead of print 18 February 2015. DOI: 10.1177/0954405414563554.
2.
BahalkeUDolatkhahiKDehghaniH. Formulation and heuristic algorithm for flow time minimization in a simple assembly line. Proc IMechE, Part B: J Engineering Manufacture2012; 226(3): 512–526.
3.
OkolowskiDGawiejnowiczS.Exact and heuristic algorithms for parallel-machine scheduling with DeJong’s learning effect. Comput Ind Eng2010; 59(2): 272–279.
4.
ZandiehMFatemi GhomiSMTMoattar HusseiniSM.An immune algorithm approach to hybrid flow shops scheduling with sequence-dependent setup times. Appl Math Comput2006; 180(1): 111–127.
5.
AmirianHSahraeianR.Augmented ε-constraint method in multi-objective flowshop problem with past sequence set-up times and a modified learning effect. Int J Prod Res2015; 53(19): 5962–5976.
6.
SunYZhangCGaoL. Multi-objective optimization algorithms for flow shop scheduling problem: a review and prospects. Int J Adv Manuf Tech2011; 55(5–8): 723–739.
7.
YeniseyMMYagmahanB.Multi-objective permutation flow shop scheduling problem: literature review, classification and current trends. Omega2013; 45: 119–135.
8.
DaiMTangDXuY. Energy-aware integrated process planning and scheduling for job shops. Proc IMechE, Part B: J Engineering Manufacture2014; 229(1): 13–26.
9.
RuiZShilongWZheqiZ. An ant colony algorithm for job shop scheduling problem with tool flow. Proc IMechE, Part B: J Engineering Manufacture2014; 228(8): 959–968.
10.
AmirianHSahraeianR.Multi-objective differential evolution for the flow shop scheduling problem with a modified learning effect. Int J Eng Trans C2014; 27(9): 1395–1404.
11.
KirkpatrickSGelattCDVecchiMP.Optimization by simulated annealing. Science1983; 220: 671–680.
12.
MavrotasG.Effective implementation of the ε-constraint method in multi-objective mathematical programming problems. Appl Math Comput2009; 213(2): 455–465.
13.
FogliattoFSAnzanelloMJ.Learning curves: the state of the art and research directions. In: JaberMY (ed.) Learning curves: theory, models, and applications, Boca Raton, FL, 2011, pp.3–15. Canada: CRC Press and Taylor & Francis Group.
14.
ZhouYJiangJYangZ. A hybrid approach for multi-weapon production planning with large-dimensional multi-objective in defense manufacturing. Proc IMechE, Part B: J Engineering Manufacture2014; 228(2): 302–316.
15.
QianBWangLHuangDX. An effective hybrid DE-based algorithm for multi-objective flow shop scheduling with limited buffers. Comput Oper Res2009; 36(1): 209–233.
16.
DebKPratapAAgarwalS. A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE T Evolut Comput2002; 6(2): 182–197.