
Abstract
Radio frequency identification is a developing technology that has recently been adopted in industrial applications for identification and tracking operations. The radio frequency identification network planning problem deals with many criteria like number and positions of the deployed antennas in the networks, transmitted power of antennas, and coverage of network. All these criteria must satisfy a set of objectives, such as load balance, economic efficiency, and interference, in order to obtain accurate and reliable network planning. Achieving the best solution for radio frequency identification network planning has been an area of great interest for many scientists. This article introduces the Ring Probabilistic Logic Neuron as a time-efficient and accurate algorithm to deal with the radio frequency identification network planning problem. To achieve the best results, redundant antenna elimination algorithm is used in addition to the proposed optimization techniques. The aim of proposed algorithm is to solve the radio frequency identification network planning problem and to design a cost-effective radio frequency identification network by minimizing the number of embedded radio frequency identification antennas in the network, minimizing collision of antennas, and maximizing coverage area of the objects. The proposed solution is compared with the evolutionary algorithms, namely genetic algorithm and particle swarm optimization. The simulation results show that the Ring Probabilistic Logic Neuron algorithm obtains a far more superior solution for radio frequency identification network planning problem when compared to genetic algorithm and particle swarm optimization.
Keywords
Introduction
In recent decades, the advancement in technology and the use of modern engineering systems in industries from the production to transportation sector have inspired the need to track and identify materials, products, and even live subjects. 1 Radio frequency identification (RFID) technology can be addressed as one of the most reliable and efficient solutions for tackling this problem. RFID technology is known as an automatic identification technology because it uses wireless radio frequency waves that are produced by an electromagnetic field to transfer data for tracking and identifying objects. This technology can be implemented in different fields such as tracking and identifying patients in hospitals, 2 warehouse items tracking, 3 tracking pallets and cases in shipment, 4 monitoring production line, 5 and manufacturing control system. 6
In many applications, the deployment of RFID systems has generated a radio frequency identification network planning (RNP) problem 7 which needs to be resolved, in order to efficiently operate a large-scale network. However, RNP is one of the most challenging problems that has to meet many requirements of the RFID system.8,9 In general, the RNP aims to optimize a set of objectives (coverage, load balance, economic efficiency and interference between antennas, etc.) simultaneously; this is achieved by adjusting the control variables (the coordinates of the readers, the number of antenna, etc.) of the system. As a result, in a large-scale deployment environment, the RNP problem is a high-dimensional nonlinear optimization problem that has a vast number of variables and uncertain parameters.
Tracking and identifying objects in these applications require the deployment of several RFID antennas in the RNP, and the numbers of these antennas are calculated through the use of a mathematical model.10–12 In the past, one of the typical ways to address the RNP problem was using a trial-and-error approach, which was an inaccurate and inefficient solution for such an important issue.7,13,14 In addition, this approach could only be used on small-scale RNP problems. 10 Nowadays, with the developments in computer technology, and software engineering, the conventional trial-and-error approach has been replaced with modern computational techniques that provide such important criteria like coverage of objects, collision of antennas, and number of antenna. 15 Computational evolutionary techniques, such as artificial neural networks, 16 fuzzy logic, 17 genetic algorithm (GA),10,11,18 particle swarm optimization (PSO),13,19,20 differential evolution (DE), 9 and hierarchical artificial bee colony algorithm, 8 are points of interest for many scientists working with the RNP problem. In this respect, H Feng et al. 21 proposed a novel optimization algorithm, namely, the multi-community GA-PSO for solving the complicated RNP problem. H Chen et al. 7 developed an optimization model for planning the positions of the readers in the RNP based on PSO. Nawawi et al. 22 proposed solution based on the PSO correlation between RNP parameters. S Lu and S Yu 23 proposed an approach based on k-coverage for RFID network planning, a k-coverage model is formulated from a multi-dimensional optimization problem and plant growth simulation algorithm, this is used to optimize the RFID networks by determining the optimal adjustable parameters. Y-J Gong et al. 13 used the PSO algorithm with redundant reader elimination for optimizing the RNP.
The literature review by the authors indicates that the majority of the studies that have been conducted take into consideration the number of antennas as predefined by experts; however, this cannot be changed during the optimization process. Therefore, the ultimate goal of RNP is to calculate the number of antennas in a cost-efficient manner. In order to plan a cost-efficient RFID network, it is necessary to minimize the number of antennas, minimize the interference of antennas, and maximize the coverage area of objects.11,16 Therefore, in this article, the Ring Probabilistic Logic Neuron (RPLN) is introduced as an efficient optimization technique to deal with the complex RNP problems; also, the RPLN has an inherent capability to adjust number of embedded RFID antennas in the network. In addition, to enable the RFID network model to be flexible with the number of antennas as well as reduce the optimizing process, redundant antenna elimination (RAE) is used before starting the optimization process. In each step of the optimization, all redundant antennas will be eliminated, and the optimization of the network will be applied to only non-redundant antennas.
The rest of this article is organized as follows: first, the RFID network model is introduced; next, the GA optimization technique is utilized to solve and optimize the RNP; third, the PSO approach is used to deal with RNP; following this is optimization of the proposed RNP by RPLN optimization technique; and finally, the results are compounded and compared.
RNP
An RFID system is made of four major elements, which are tags, readers, antennas, and computer unit. RFID configuration system is shown in Figure 1. It should be noted that the antenna could be a part of the reader; in that case, more than one antenna could be connected to one reader. Readers through antennas collect the data sent by tags and relay this to a host computer to process for further implementations. In essence, the RFID is the technology of processing data, which are radio frequency signals omitted from mounted tags on subjects and sent by readers to a host computer unit. 24 There are three types of tags: passive, semi-passive, and active. Differences between these three types of tags are based on their power source; in the sense that active and semi-passive tags are battery-powered, while passive tags do not have internal power. 25
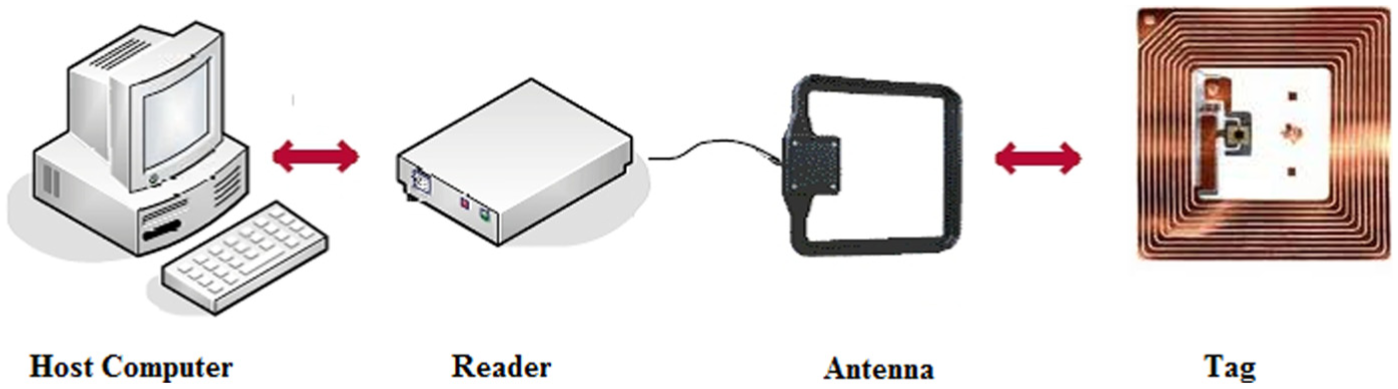
Components of RFID network.
It should be noted that passive tags have several advantages over semi-passive and active tags. First, passive tags are highly cost-effective and, second, they have a very long life cycle; 26 therefore, in this research, passive tags are used.
The distance between tag and antenna plays a major role in establishing communication between them. This problem exists because of the limit placed on the interrogation ranges of the antennas. 27 A reader can receive the information of a tag through antenna only in a limited range; because of this limitation, more than one antenna is used in many RFID systems to establish communication between tag and antenna. In such systems, many important objects like the number of antennas and their positions need to be thoroughly calculated. Answering such questions leads to an important concept named RNP.13,23
Mathematical modeling of RFID network planning
A reliable RFID network model must be able to calculate coverage percentage of the tags, total transmitted power by antennas, and total interference of the network. The Friis transmission equation 28 is a well-known equation to formulate RFID network and has been used by many researchers to solve the RNP problem.13,29,30 In this article, a developed model of this equation, which was proposed by Gong et al., 13 is utilized to calculate the main parameters of an RFID network such as the number of antennas, coverage area, and collision of antennas.
In order to define an RFID network model, the following steps should be taken:
Defining a working area;
Illustrating the number of distributed tags in this working area;
Defining the number of utilized antennas in this area.
In this article, the working area is defined as a square, that is, 100 × 100-m2 rooms, where 20 passive tags are distributed in the room. It should be noted that the number of antennas here is arbitrary and can be chosen as any numbers. Predefined number of antennas, which are randomly distributed in the room, is assumed to be 20 at least, which is equal to the number of tags. Figure 2 shows the working area.

Working area and distributed 20 tags.
After defining the parameters of the RFID network, the next step is calculating the properties of the network, which is the percentage of the covered tags by the antennas, number of redundant antennas, interference amount of antennas, and the total transmitted power by antennas.
Coverage
Coverage of a network is defined as the percentage of the tags, which are covered by deployed antennas, and so the ultimate goal of RNP is to achieve a 100% coverage of tags. As stated earlier, the tags considered in this article are passive tags, so they lack a power supply to produce radio frequency (RF) waves to communicate with antennas. Passive tags have internal circuits, which are activated when they receive electromagnetic waves that are greater than their power threshold, and so the activated tags start sending a backscatter signal and commence communication with the antennas. 31
It can be said that a passive tag is covered by an antenna in the following manner:
A tag receives a signal from an antenna with the power of PTa,t which is greater than the threshold value of the power of the tag (Tt).
This signal activates the tag, and then, the tag starts sending a backscatter signal to antennas with power of PAt,a.
If the power of the backscatter signal is greater than the threshold value of the antenna power (Ta), then it can be said that the tag is covered by the antenna (Figure 3).

Example of tag coverage.
The mathematical representation of the coverage of a tag is defined by following formula

If there are N tags in a network, then the total percentage of coverage of the RFID network is defined as follows

where Nt = 20 and
Figure 3 shows an example of tag coverage if
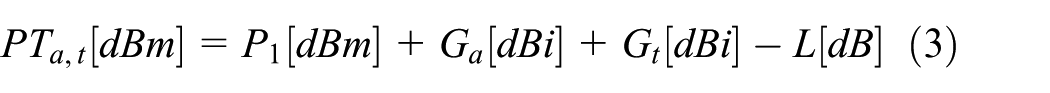



where P1 is the transmitted power of the antenna, Ga is the gain of the antenna, Gt is the gain of the tag, L represents loss, λ is the wavelength, d is the distance between tag and antenna, and n depends on environment. This varies from 1.5 to 4; δ represents other losses, Pb is the backscatter power transmitted by tag which is reduced by multiplying it by the reflection coefficient Γtag.
The number of antennas
Deploying each antenna to a network has a cost. It is possible that few deployed antennas in an RFID network will not have an effect on the network coverage; as a result, they are redundant and are not efficient. These antennas impose an unnecessary cost to the network, and so it is an important criterion in the RNP to calculate the most efficient number of antennas. The mathematical representation of this concept is shown as follows

where Nmax is the maximum number of antennas that is deployable in the network, which is calculated through optimization algorithm in each step. However, it should be noted that for the first step, it is a random number that is used; in this article, it is assumed that 20 is equal to the number of tags. Nred is the number of redundant antennas, and Na is the efficiency of the antennas.
RAE
It is necessary to eliminate redundant antennas from the network. In order to distinguish the redundant antennas, a RAE algorithm32–35 is executed and utilized. Once again, it should be mentioned that in this article, the total number of redundant antennas is calculated using the RAE algorithm before the optimization process at each step takes place; this is done in order to make the optimization process shorter and time-effective. The implementation flowchart of the RAE algorithm is shown in Figure 4.

Flowchart of proposed redundant antenna elimination algorithm.
After calculating the total coverage of the network, the next step is to eliminate the deployed antennas in the network one by one. After eliminating each of the antennas, the total coverage of the network should be calculated again. Now, if the result is less than the total coverage of the network, then the antenna should be recovered and not be eliminated; however, if the coverage of the network after elimination does not change, then the antenna is redundant, and therefore, must be eliminated. In this case, the total coverage of the network is the one that arises after the elimination of the antenna takes place. Figure 4 illustrates the flowchart of the proposed RAE algorithm.
Interference
The third important criterion in RNP is calculating the amount of collision that occurs between the available efficient antennas. Collision occurs when more than one antenna interrogate the same tag, and so when the tag starts to transmit backscatter signals after receiving the induction signals from more than one antenna, these received power signals result in an interference within the network. The interference (ITF) of the network is calculated as follows

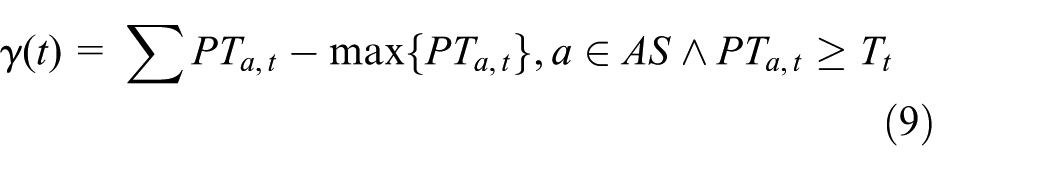
The sum of the transmitted power
The transmitted power of each antenna is directly related to the interrogation range, and so by reducing the amount of transmitted power, a decrease in the coverage of the network can occur. This has the lowest criteria in the RNP. The sum of transmitted power of the network is calculated as follows

where PSa is the amount of transmitted power by antennas.
Optimizing RNP
The ultimate goal of optimization here is to find the optimum number of antennas that should be deployed on the RFID network in order to achieve the maximum network coverage as well as minimum interference of antennas. In this article, three different artificial intelligent techniques are utilized to perform the optimization process: GA, PSO, and RPLN.
GA
GA is part of an evolutionary computing that is used for optimizing complex problems.36,37
The GA operates through the following steps: 38
Creation of a random population (normally this population size is taken as 100);
Evaluation of the fitness function of each individual;
Reproduction or selection of the best chromosomes;
Applying crossover;
Applying mutation;
Repeat steps 2–5.
The first step involves the creation of a population of chromosomes. Each population of the chromosome is known also as an individual; this is an answer to the problem. Based on the optimization problem, each chromosome contains different parameters that need to be found and optimized; these parameters are known as the genes. It should be noted that the length of genes depends on the required precision of the various problems. 39
To perform the first step and create a population of answers, it is necessary to learn how to encode a chromosome. There are different types of encoding which can be chosen depending on the problem’s structure. This can be a string of real numbers or binary bit string. 40
Chromosomes in binary encoding are strings, which are made of 0s and 1s; this kind of encoding is less complicated than the other methods and is normally used as a routine methodology.
The binary encoding makes use of exciting problem to define the position of the antennas and their status, that is, whether it is “on/off” or “0/1” in each chromosome.
The workspace is defined in terms of the x–y coordinate system, and so the position of each antenna can be defined as (xr,yr) in the workspace. The characteristics of these chromosomes depend on the length, width, and segment number of the workspace (see Figure 5).
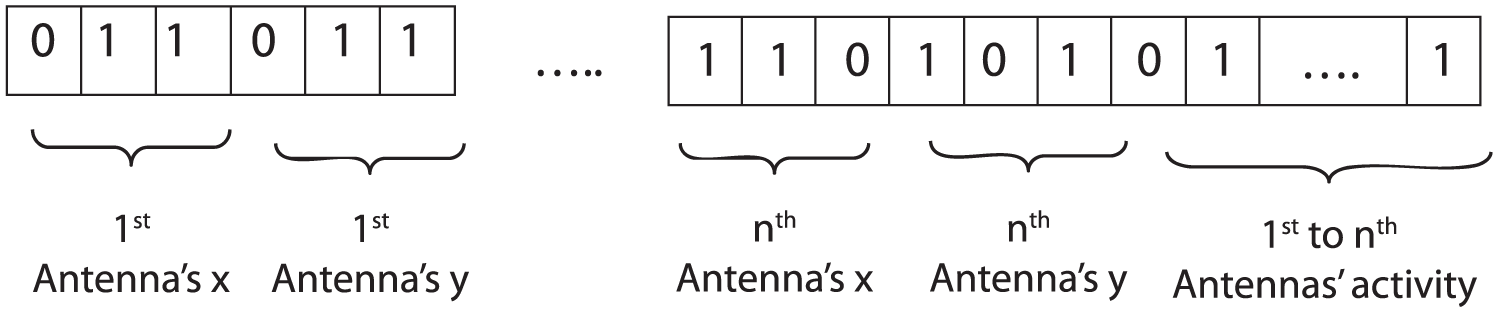
Encoding a chromosome.
The next step requires the evaluation of these individuals f(xi). The number of antennas, coverage, and ITF should be calculated based on the position and activity of the antennas. It should be noted that in this article RAE is used to compute number of redundant antennas Nred. To implement RAE, the following steps should be taken: the antennas in each individual population should be eliminated one by one, by converting 1 to 0, that is, in the place of activity of each antenna in each chromosome. Next, the coverage should be calculated; if the calculated coverage in each step, after elimination, in the sense that an antenna remains equal to its initial state before elimination, the antenna becomes redundant and needs to be eliminated; otherwise, the activity condition of the eliminated antenna should remain as 1. This procedure needs to be implemented for the entire antenna, and so at the end, the number of antennas Nr can be calculated by counting the number of active antennas in each chromosome.
After evaluating the whole individual’s performance, the fitness function of each individual can be calculated as follows

The goal is maximizing coverage and minimizing inference of the network.
Fractional fitness function of each individual is calculated as follows 41

The third step involves using the current population to produce the next generation of the population, which will have a higher objective function. This step is called the reproduction. In this step, each chromosome is copied a number of times to the next generation; this is with respect to its fractional fitness function. To select which chromosome is the fittest, different selection types have been put forward.41,42 In this article, a roulette wheel method is utilized to perform the selection step. The main principle is that the fittest individuals, the individuals with the greatest fitness functions, have a better chance to survive. 42
For this purpose, the cumulative probability of each chromosome should be calculated by computing the fractional fitness function of each individual. Then, n random probability ranging from 0 to 1 should be produced; where n indicates the population size. Then it is necessary to find where each random probability is located, and which two cumulative probabilities of chromosomes it is in between. Finally, the chromosome which has the highest cumulative probability will be selected for the new population. In summary, a roulette wheel will spin n times, and each time, a chromosome will be selected for the new population.
The next step incorporates one of the GA’s operators named the crossover. The crossover makes it possible to exchange the parts of two different chromosomes, in which the production of new chromosomes takes place. In essence, the crossover forms new chromosomes (solutions) by decomposing two different chromosomes and randomly mixing the decomposed parts. In order to know the chromosomes that will participate in crossover n, a random probability number ranging from 0 to 1 should be selected; where n is the population size. When comparing the randomly produced probability of each chromosome with the probability of the crossover, which is commonly considered to have a higher probability value (Ex. 0.7), if the generated probability is equal or less than crossover probability, then that chromosome will participate in crossover. The selected crossover point, that is, a random number in range of [1 chromosome length] for each selected chromosome will be generated; the generated number indicates the crossover point. Bits, that is, to the right of the crossover point (single-point crossover), or bits located in between the generated crossover points (two-point crossover), will be exchanged with bits of another chromosome. 43
The final step incorporates another genetic operator named mutation. Mutation occurs randomly in one of the genes of an individual and changes its value to prevent evolutionary dead ends from occurring. If the gene value is 0, it will be changed to 1, and if it is 1, it will be changed to 0. Mutation tool is one of the nature’s most powerful survival tools. To perform mutation, n random probability number in range of [0 1] should be generated, where n is the length of the chromosome. These randomly generated probabilities will be compared to the mutation probability, which is generally a small value and can be calculated as Pm = (chromosome length)/1000. If the generated probability is less than or equal to mutation probability, then the gene value will change as follows. 44
After mutation, the new population is generated and a repetition of steps 2–5 is done. Typically, these steps are repeated 100 times, and as the property of GA is an evolutionary technique, the final outcome will be the best outcome.
Particle swarm
Eberhart and Kennedy, 45 in 1995, while observing the swarm behavior of birds flocking and fish schooling proposed a population-based stochastic optimization technique; this is known as the PSO technique. PSO like GA starts with a population of random solutions known as particles. The algorithm continues searching for the fittest value in problem space by updating the generations. In PSO, the potential solutions fly through the problem space by following the current optimum particles. However, unlike GA, PSO has no evolution operators such as crossover and mutation. 46
The canonical form of PSO, which is utilized for the optimization of the RNP in this article, is represented below 11


where vi and xi are, respectively, represented by the velocity and position vectors of each particle. pbesti is the previous best position vector, and gbesti is the global best position vector. Population size is presented by i, and just like the GA, it is assumed to be 100. χ is called the constriction coefficient (here, χ = 0.8), c1 and c2 are the learning rates (here, c1 = c2 = 2), and r1 and r2 are the random numbers that are uniformly distributed in [0, 1].
The overall procedure of the PSO algorithm can be described in the following steps:
Randomly generate the velocities and positions of particles.
For each particle, evaluate the fitness function which is proposed in equation (11) for each particle.
If the fitness is better than particle’s previous best fitness, update and then further compare the fitness with the global best fitness that has be found so far. Then, update accordingly.
Particles update their velocities and positions according to equations (13) and (14).
Loop to step 2 until a stopping criterion is reached, and in this scenario, it is completing 100 iterations.
The RPLN
RNP can be optimized using the RPLN.47–49 Nowadays, this technique is widely used in computer engineering, especially when the concept of random-access memory (RAM) is considered. It is referred to as RPLN because each step will be done repeatedly until the desired outcome is achieved.50,51
A PLN consists of a node and a truth table, inputs are given as 0 or 1, and the output is in the form of 0 or 1. These numbers are obtained through a decoding function and if the answer is acceptable, the truth table will be saved; otherwise, the random value will be replaced, and the operation will start from the beginning. 52
In other words, the PLN optimization technique is trained and learned based on pure random searches. Figure 6 shows a schematic of the PLN. This random search algorithm is known as an A-learning rule. In pattern reorganization PLN, networks can be used using A-learning rule algorithm.53,54
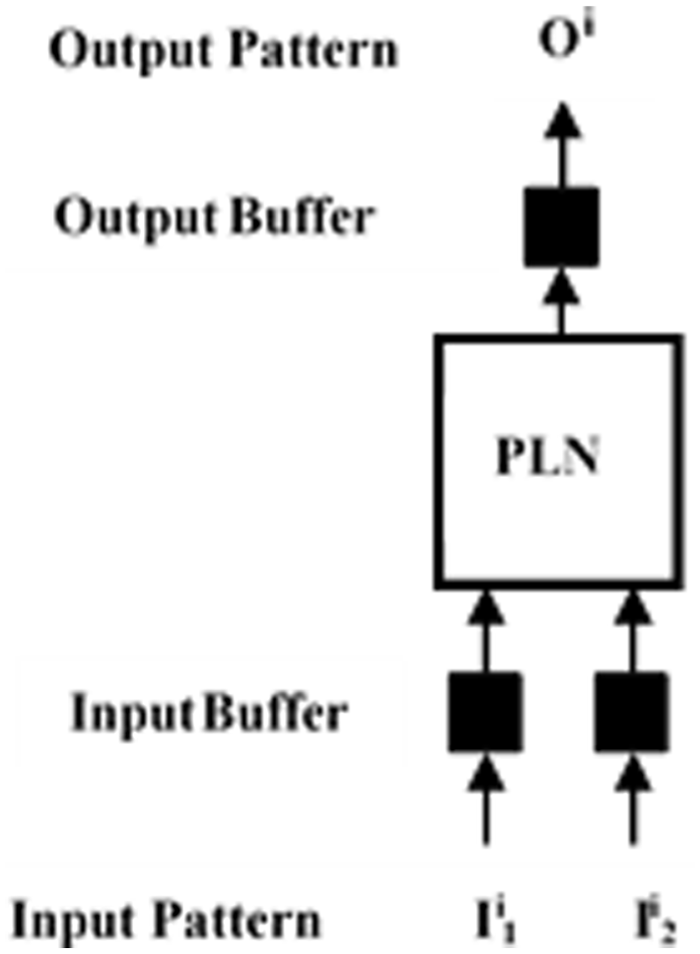
Probabilistic Logic Neuron (PLN).
The steps taken for an A-learning rule can be summarized as follows:
Encode an initial population like that discussed in GA.
For each gene in every individual (called chromosome in GA) assign a PLN with random inputs and outputs (random values).
Calculate the fitness function for each individual.
If the calculated fitness function is equal to the desired value, save the value of the inputs and outputs.
If the fitness function is not equivalent to the desired value, reset the inputs and outputs values, and then calculate the fitness function again and train the network for m times, where m is a positive non-zero integer (we assume m = 10).
If the calculated fitness function is equal to the desired value, save the value of inputs and outputs.
If the calculated fitness function is not equal to the desired value, go to the calculation for nest individual.
Repeat these steps until all the random values will be changed to the fixed values.
PLN networks can be formed in different structures, and there are no exact patterns to select which architecture should be used (see Figure 7).

Example of structure of PLN network.
The structure shown in Figure 8 is used as a layer RPLN optimization structure case to optimize the RNP problem. Optimization using the RPLN is a novel technique for solving the RNP problem, and it has an advantage of simplicity in calculations and obtaining better results in less time over other computational optimization techniques. 55

The Ring Probabilistic Logic Neuron, RPLN.
Results and discussion
For the purposes of this study, a 100 × 100-m2 room is considered and divided into four equal segments. A total of 20 tags and 20 antennas are randomly distributed in these segments. The exact position and number of antennas are calculated through the implementation of optimization techniques (GA, PSO, and RPLN) for 100 iterations. It should be noted that the first population for all the three algorithms are considered the same, and so the results obtained are represented and compared as follows.
As seen in Figure 9, the coverage of the RNP network improves from 75% at the beginning of all GA, PSO, and RPLN optimization processes to 100%. And so, all these three algorithms can achieve the solution which gives the full network coverage; regarding to coverage of the network result that is illustrated in Figure 9, the RPLN reaches its solution faster than the other two.

Calculated coverage of the network by RPLN, PSO, and GA in each iteration.
Figure 10 shows the number of calculated deployed antennas in the network, within each step of the optimization processes. This figure indicates that the number of antennas at the end of the GA optimization process is calculated as 5; however, this number is reduced to 4 in PSO and even to 2 in RPLN.

Calculated number of deployed antennas in the network by RPLN, PSO, and GA in each iteration.
The combination of the results of Figures 9 and 10 can be interpreted in the following statement: since the proposed RFID network achieves full network coverage in all three optimization processes, the calculated positions of the antennas by RPLN are more efficient than the GA’s and PSO’s, because with fewer antennas, the RNP network coverage in the RPLN like GA reaches 100%.
The interference of the proposed RNP network, based on the number and position of antennas, which are calculated through GA, PSO, and RPLN optimization techniques, is shown in Figure 11. The ITF of the network at the end of the GA and PSO optimization processes, respectively, are calculated as −71.34 and −39 dBm; however, this amount through the RPLN optimization process is calculated as −23.34 dBm. Therefore, this result indicates that utilizing RPLN gives more reliable antennas positioning when compared to GA and PSO optimization techniques.

Calculated ITF of the network by RPLN, PSO, and GA in each iteration.
Overall, the results indicate that utilizing the RPLN optimization technique, compared to the GA and PSO techniques, optimizes an RNP. This makes it more cost-effective and time-efficient, since the RFID network can reach full network coverage in lesser time due to fewer deployment of antennas and lesser interference on the network.
Conclusion
In this article, a pure random-based optimization technique called the RPLN has been introduced as an efficient optimization technique for dealing with a complex RNP problems. This optimization technique is capable of adjusting any number of embedded RFID antennas in the network. The simulation-based performance assessment has been performed for investigating the effectiveness of the RPLN algorithm over the GA and PSO. The simulation results show that the RPLN has superior performance over the GA and PSO. However, it should be noted that in order to prevent antenna redundancy deployment in the network, all three optimization techniques have been enhanced with an additional algorithm named the RAE. It should be observed that the RPLN technique for optimizing the RNP is more enhanced than GA and PSO as explained below:
RPLN has faster convergence speed and lesser iterations than GA and PSO.
RPLN has lesser complexity in computations than GA and PSO.
The results given by the RPLN are more precise and cost-effective.
In future studies, with an innovation in the proposed mathematical models of the RNP, it will be possible to model an RFID network that involves more criteria such as the quality of the network. A valuable future study would involve the utilization of more optimization techniques for static and dynamic networks to generate RFID networks.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers for their valuable comments and feedbacks to enhance the quality of the paper.
Academic Editor: Shengyong Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.