
Abstract
Large language models (LLMs)-driven robotic systems have become a focal point. However, current methodologies predominantly rely on auxiliary components such as pre-defined motion primitives or pre-trained skills to facilitate physical environment actions, which constitutes the primary limitation for such approaches. This study presents the SeIn framework that breaks through this limitation by leveraging prompt-conditioned sequential generation capability of LLMs to directly output control actions for dual-arm nursing robot—specifically, sequences of 14-DoF target joint positions. Firstly, the LLMs were grounded in a MuJoCo physics environment, enabling the dual-arm nursing robot to generate control actions while receiving corresponding environmental observations. Subsequently, task-specific textual prompts were designed to guide the LLMs in task reasoning, observation processing, and generation of target joint position sequences. Finally, the framework was evaluated through comprehensive MuJoCo simulations, including: ablation experiments on prompt design; expressive action experiments across seven action types spanning three operational categories; performance evaluation experiments querying four distinct LLMs at 4- and 60-s execution durations; and a functional action experiment involving Reach-to-Object. Experimental results demonstrated that SeIn framework achieved 100% success rate in generating joint sequences for actions using task-specific text prompts and pre-trained LLMs (specifically, GPT-4o and DeepSeek-V3.1), without requiring auxiliary components.
Introduction
Dual-arm nursing robots have garnered extensive research interest.1–4 They can enhance the quality of life for disabled/semi-disabled individuals with mobility impairments while addressing caregiver shortages. Current implementations predominantly utilize teleoperation, requiring continuous operator involvement. Recent advances in large language models (LLMs) have demonstrated significant capabilities in high-level semantic comprehension and logical reasoning.5,6 Building on these capabilities, researchers have extended LLMs to robotics by driving robots with pre-trained LLMs for high-level task interpretation, task planning, and behavior selection.7–13 Nevertheless, low-level action implementation remains dependent on auxiliary components including pre-defined motion primitives and pre-trained behavioral skills. Existing methodologies, constrained by the limited repertoire of available primitives and skills, prove inadequate for fulfilling the operational demands of nursing robots requiring diverse action execution.
Recent studies explore extending LLMs to the low-level control of robots. For example, VoxPoser 14 employs LLMs for end-effector trajectory planning, yet necessitates an external trajectory optimizer for motion calculation. Similarly, Prompt2Walk 15 applies LLMs to learn a walking feedback policy for a quadruped robotic dog, but it relies on a pre-trained RL policy to provide contextual history examples. Despite related research advances, insufficient robotic data of LLMs impedes direct low-level robot control. Prevailing academic consensus holds that pre-trained LLMs cannot directly generate robot low-level actions without auxiliary components. 16
Current research inadequately verifies this hypothesis. In this work, the potential of leveraging pre-trained LLMs was examined to provide low-level control solutions for robots. A novel SeIn framework was facilitated to guide pre-trained LLMs to directly generate dense sequences of target joint positions for a dual-arm nursing robot through task-specific textual prompts. The operational principle of the SeIn framework is illustrated in Figure 1, with its core workflow as follows. Firstly, to make the LLMs useful for low-level robot control, the models are grounded in the MuJoCo physical environment. The textual prompts are considered key for controlling the nursing robot via LLMs. Task-specific textual prompts are designed, comprising four components: Task Description, Prior Knowledge of Action, Observation Information, and System Configuration. Through these operations, the SeIn framework invokes pre-trained LLMs to generate dense sequences of target joint positions, enabling physical environment action and environmental observations acquisition. Simulation experiments in MuJoCo test the execution effect of the SeIn framework across seven expressive actions in three categories and one functional action.

LLMs generate low-level control actions. The SeIn framework grounds LLMs in the MuJoCo physical environment so that observations can be obtained and actions can be sent. Task-specific textual prompts guide the LLMs to reason the task of generate the normalized target joint position sequences. Subsequently, the target joint position sequence is tracked by the PD controller to update the robot’s state.
As a summary, the main contributions of this work are threefold:
(1) SeIn framework guides pre-trained LLM using only textual prompts to output dense sequences of target joint positions (normalized) at each inference step. These sequences undergo inverse normalization and are tracked by PD controller, enabling low-level action execution from text to motion without auxiliary components.
(2) Task-specific textual prompts are designed to guide LLMs in understanding the task, acquiring observations, and generating low-level control actions for the robot. Notably, the ablation experiments further revealed which settings in the prior knowledge and observation information facilitated the emergence of SeIn framework capabilities.
(3) A 14-degree-of-freedom (DoF) dual-arm nursing robot is simulated in a MuJoCo environment, demonstrating that the SeIn framework can be generalized to the execution of multiple actions.
Related work
Dual-arm nursing robot
Dual-arm nursing robots adopt humanoid arms connected to a torso and equipped with a mobile chassis. Representative systems include Twendy one, 1 RIBA-II, 2 RoNA, 3 RescueBot, 4 etc. These robots can perform a variety of tasks, including expressive actions (such as waving, hugging, etc.) and functional actions (such as cleaning the table, etc.). 17 Nursing robotic systems primarily use teleoperation, and the operator comprehends and plans the tasks through the “human-in-the-loop” strategy. As for action execution, researchers have utilized latent embeddings of language commands as multi-task input context18,19 and trained by behavior cloning,20–22 offline reinforcement learning, 23 and goal-conditioned reinforcement learning. 24 However, these methods demand significant professional knowledge and lack task understanding and planning at the task level.25–28
LLMs-based robots
LLMs trained on web-scale data demonstrate strengths in high-level semantic understanding and logical reasoning.29–35 Researchers have applied pre-trained LLMs to robotic systems enabling robots to understand tasks, plan tasks, and choose behaviors. For example, Inner Monologue 9 and Say-Can 10 utilize LLMs for behavior selection to solve high-level planning problems. In ChatGPT for Robotics, 11 Code as Policies, 7 ProgPrompt, 36 and Demo2Code, 37 researchers have utilized the code generation capabilities of LLMs to map high-level instructions into the code format for robot policies. Works including Text2Motion 38 and AutoTAMP 39 combine LLMs with traditional Task And Motion Planning (TAMP). However, these studies based on pre-trained LLMs typically rely on pre-defined motion primitives or pre-trained skills to perform low-level actions.20,21,40
As shown in Figure 2, researchers have begun to explore the intersection between LLMs and low-level control of robots. VoxPoser 14 and Language to Rewards 41 explore the use of LLMs to generate high-reward regions for robots trajectory planning. However, they require an external trajectory optimizer to generate trajectories. Kwon et al. 42 utilized LLMs to generate Python code that is executed by an interpreter and outputs a sequence of end-effector poses. The code generated by LLMs is prone to syntactic and semantic errors. Mirchandani et al. 43 employed LLMs as a general pattern machine and provided a controller for CartPole through sequence improvement techniques. 44 Subsequently, Prompt2Walk 15 collected observations and actions from the RL controller to initialize prompts, employing LLMs as the walking feedback policy for the quadruped robot dog. However, it relies on a pre-trained RL policy to provide contextual history examples, and its performance is constrained by this RL policy.
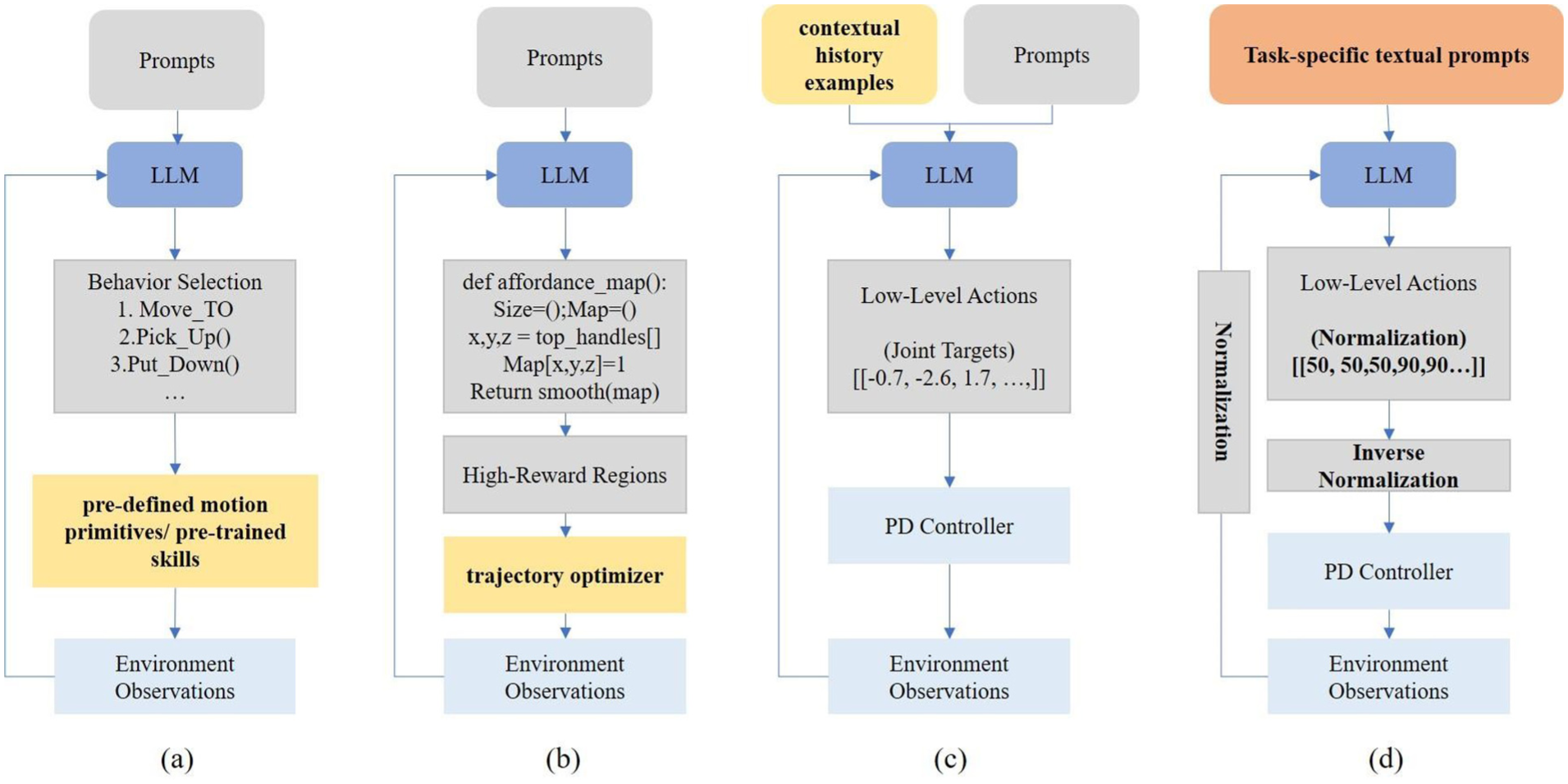
Comparison of the SeIn framework with existing robot research based on pre-trained LLMs. Existing studies primarily relies on auxiliary components, such as (a) pre-defined motion primitives or pre-trained skills, (b) trajectory optimizer, and (c) contextual history examples, to execute low-level actions. This work explores whether LLMs can directly generate target joint position sequences using textual prompts for robot low-level control, as shown in (d).
Despite the progress in related research, existing research still relies on auxiliary components other than LLMs for low-level control of the robot, and has not verified the potential for LLMs to directly generate low-level controls. This study investigates the application of pre-trained LLMs to generate dense sequences of target joint positions, enabling low-level control implementation in dual-arm nursing robot. Our research eliminates the need to fine-tune LLMs using specialized robot data, while getting rid of reliance on auxiliary components such as pre-trained skills, pre-defined motion primitives, trajectory optimizer, and contextual history examples.
Proposed method
This section describes the SeIn framework in detail with its pipeline overview shown in Figure 3. The SeIn framework grounds the LLMs in the MuJoCo, and guides the pre-trained LLMs through the task-specific textual prompts to generate dense sequences of target joint positions, which are tracked by a PD controller to execute of the dual-arm nursing robot.
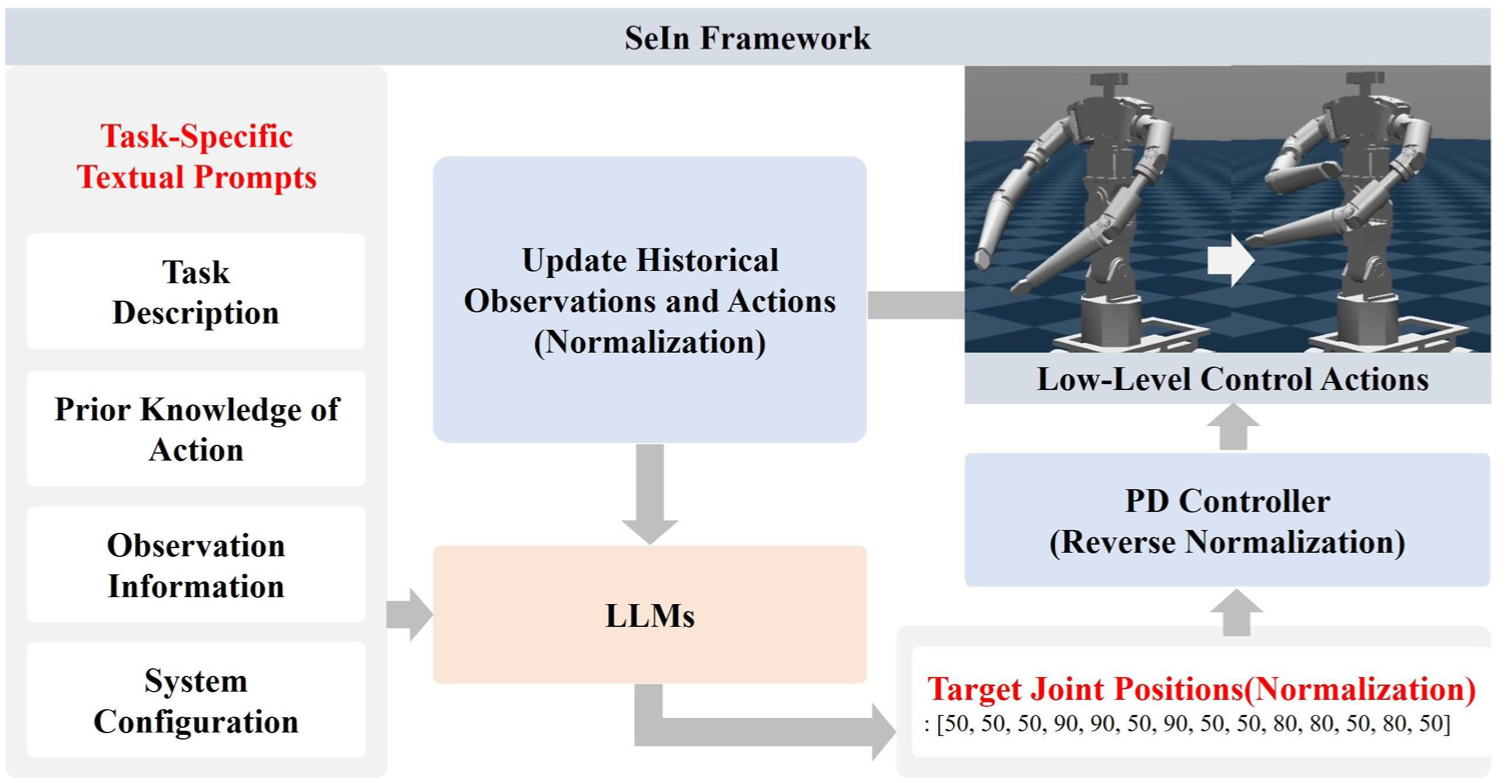
Overview of the pipeline. The task-specific textual prompts direct the pre-trained LLMs to understand the task, obtain the observations, and generate the normalized target joint positions. Subsequently, the denormalized target joint positions are followed by the PD controller. After each LLMs inference loop, the textual prompts are updated based on historical observations and actions.
Problem formulation
First, this section explains the assumptions and constraints of this study. Then, the robot control hierarchy corresponding for the low-level action execution is presented. Finally, this section explains how to perform normalization operations on observation and action. Building upon this foundation, subsequent sections will detail the grounding of LLMs and the design of task-specific textual prompts.
Assumptions and constraints
The SeIn framework is designed to investigate the ability of LLMs, to perform low-level robot control, with the following assumptions:
(1) No pre-defined motion primitives, pre-trained skills, RL policies, or trajectory optimizer. The use of textual prompts is investigated to invoke pre-trained LLMs to output a dense sequence of target joint positions necessary for the action execution.
(2) No contextual history examples. The ability of LLMs is investigated to invoke their internal knowledge for task reasoning and textual sequence generation.
(3) No need for robot data to train or fine-tune LLMs. This study focuses on invoking pre-trained LLMs. Consequently, the framework can be deployed and run even if local computational resources are limited.
(4) LLMs interact with the physical environment. Through grounding the LLMs in the MuJoCo physical environment, the SeIn framework can obtain historical observations and actions from MuJoCo, and subsequently, the LLMs are required to derive the desired action sequences.
Motion level planning
It is worth noting that the low-level control interface mentioned in studies related to LLMs-based robots is quite different from that in traditional robot control. In order to clarify the specific reference level of low-level control, Firoozi et al.
45
classifies the control level of robots into four levels: (1) Task Level: task goals, for example, tasks such as hugging, waving, etc.; (2) Skill Level: pre-trained skills such as
In this work, the term “low-level control” refers to motion-level planning. It entails the direct generation of a dense sequence of target joint positions by the LLMs, which serves as the reference trajectory for the robot’s actuators. Specifically, in the configuration of dual-arm nursing robot, the robot consists of a mobile chassis, torso, left and right arms, etc., with a total of 14 degrees of freedom (DoF). Therefore, LLMs are required to output a 14-dimensional vector representing the target positions for all joints at each control step, for example: [50, 50, 50, 90, 90, 90, 50, 90, 50, 50, 80, 80, 80, 50, 80, 50]. They refer to the joint data corresponding to the torso (2-DoF), left arm (6-DoF), and right arm (6-DoF), respectively. This sequence of vectors constitutes the low-level control actions in SeIn framework.
Observation and action normalization
When processing numerical data, LLMs decompose the numerical input into a series of tokens, linguistic units that cannot directly correspond to the mathematical meaning of the numerical value. For example, the floating-point number 3.14 may be decomposed into several tokens, thus affecting the LLMs understanding of the numerical value. Meanwhile, the control data of the robot, such as joint position and joint velocity, are mainly floating-point numerical data, resulting in LLMs are not sensitive enough to the floating-point values of the robot. The core objective of normalization is to transform a robot’s continuous state space into a structured discrete representation. This converts complex regression problems—predicting continuous floating-point values—into discrete decision problems that are more manageable for LLMs. In the work of Prompt2Walk,15,43 the researchers discretize the output of LLMs into non-negative integers from 0 to 200, and experiments show that this approach is effective because these integers are represented by individual tokens in the tokenizer of LLMs.
Building upon Prompt2Walk, the normalization operation is employed in this work to map all possible numerical values of the observations and actions of robot to non-negative integers ranging from 0 to 200. The corresponding mathematical expression for the normalization operation is:
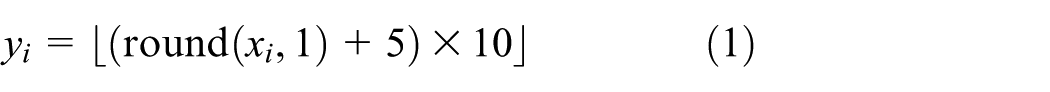
Where
Grounding LLMs
LLMs have difficulty comprehending and capturing causal relationships in the physical environment, fundamentally limiting their capability in low-level motion control and other functional tasks.46–48 This is due to the lack of interaction data-based learning in pre-trained LLMs, where the training process involves LLMs learning by predicting the next token rather than through interaction-driven learning with environments. Their training goal makes LLMs limited in understanding and processing concepts from the real world or physical environment. Consequently, they lack grounded understanding of real-world dynamics, preventing direct environment interaction.
To enable LLMs for low-level robotic motion control, the Functional Grounding methodology 49 is employed to build the SeIn framework to ground the LLMs in the physical environment. The LLMs can obtain observations from MuJoCo, including the robot’s joint positions and joint velocities.
The SeIn framework enables the symbol processing inside the LLMs to interface with the external physical environment. So that SeIn is capable of simulating, predicting, and controlling external physical processes. The implementation comprises through three key steps. Firstly, based on the current observations, the LLMs directly generate Actions, which are sequences of target joint positions (normalized) required for the execution of action by the dual-arm nursing robot. The Action data is then tracked by a set of joint-level Proportional Differential (PD) controllers operating at a higher frequency to update the state of the dual-arm nursing robot in MuJoCo. Subsequently, the LLMs generate the next round of Actions based on historical observations and actions. The above process is repeated until the requirements of the target action are reached.
In this case, the joint-level PD controller is executed with the following equation:

Prompt engineering
Unlike traditional learning-based and model-based controllers, textual prompts serve as the key to utilizing LLMs to drive the low-level control of a dual-arm nursing robot. The task-specific textual prompts are designed, which consist of four components: Task Description, Prior Knowledge of Action, Observation Information, and System Configuration, as illustrated in Figure 4.
(1) Task Description. Describe the basic information required for the task, including the role of LLMs in the task and the target action. LLM Role. Defining the role of the LLMs in the task, enabling the LLMs to understand its responsibilities and to generate task-relevant responses. Additionally, the control frequency of the LLMs policy is defined to ensure that the LLMs adjust its actions according to that frequency. Action Name. Specifying the task to be performed by the dual-armed care robot, in this case the hugging action. Providing an action name provides the LLMs with clear objectives to adapt its output to achieve this particular action.
(2) Prior Knowledge of Action. Defining prior knowledge about the target action, comprising two components: Action Execution Process and Target Joint Position. Action Execution Process. Describing the Action Execution Process required for the dual-arm nursing robot to accomplish the target action. By decomposing the target action into intuitive sub-steps, it enables the LLMs to understand the details of the action and directs the LLMs to generate an action-consistent output. Target Joint Position. Specifying the target position of a particular joint during action execution. By providing an accurate target joint position to the LLMs, it ensures that the LLMs outputs a joint angle that corresponds the target pose, thereby achieving the correct hugging configuration.
(3) Observation Information. Describing the observation information provided to the LLMs, comprising joint positions and joint velocities. The SeIn framework requires observation information to provide feedback to the robot during the execution of actions. Input Space. Defining the state representation of the robot, including joint positions (q) and joint velocities (dq). Input space provides the LLMs with the necessary observations required for understanding the current state of the robot. Output Space. Specifying the output structure for LLMs needs to generate, namely a 14-dimensional vector describing the target joint positions. Explicit output specification ensures LLMs-generated a specific data format, ensuring that the output is consistent with the requirements of the low-level controller.
(4) System Configuration. Defining the system configuration of the dual-arm nursing robot, including Joint Order, Control Pipeline, and Reasoning Constraints. Joint Order. Listing the specific sequential arrangement of robotic joints guiding the LLMs in understanding the mechanical configuration of robot. Requiring the LLMs needs to strictly follow these joint orders when generating outputs, so that the data generated by LLMs can correspond to the correct joints. Control Pipeline. Providing an overview of the whole control flow, specifically describing the use of the PD controller to track outputs. The control pipeline provides the LLMs with how the various components are handled and interconnected. Reasoning Constraints. Establishing guidelines for LLMs output generation, including smooth motion transitions between states, strict adherence to specified output formats. It is important to note that all values processed by the LLMs are raw data; these values have been normalized. These constraints ensure LLMs to produce physically plausible, controller-compatible outputs while maintaining consistency and predictability.

Task-specific textual prompts. It consists of four components: Task description, prior knowledge of Action, observation information, and system configuration. These components enable LLMs to reason about the task, receive observations and generate the desired output. The final output comprises target joint positions.
Algorithmic details
The pseudo-code of the algorithm is shown in Algorithm 1, where

In each loop, SeIn framework first retrieves the current state of the robot from the MuJoCo environment, which includes 14-dimensional joint positions (
Experiments
In this paper, the simulation model of a dual-arm nursing robot is developed in SolidWorks. 50 Simulation experiments were conducted in the MuJoCo 51 physical environment, and three categories (totaling seven actions) were tested. Through extensive experiments, we aim to answer the following questions:
Question 1: How does the prior knowledge in the task-specific textual prompts affect the execution of actions in the SeIn framework?
Question 2: How should observation information be configured to achieve optimal performance in the SeIn framework?
Question 3: Can the SeIn framework be generalized to multiple action executions?
Question 4: What is the optimal normalization range for Observation and Action?
Question 5: How stable is the SeIn framework in the long-term when querying different LLMs to perform expressive actions?
Action design
ELEGNT 17 categorizes robotic actions into functional actions and expressive actions. Expressive actions (e.g. waving and hugging) play a supporting role in the caregiving process. These types of actions can convey comfort, encouragement, and provide emotional support to the care recipient. Critically, this type of action does not require interaction with objects, the difficulty of executing the action is relatively low, and it is insensitive to the speed requirement. Based on these considerations, this study focuses on expressive actions for experimentation, covering a total of seven distinct actions, as illustrated in Figure 5.

Seven expressive actions. Three categories are involved: single-arm execution of actions, dual-arm cooperative execution of actions, and dual-arm and torso cooperative execution of actions. The SeIn framework is validated for its execution performance across multiple movements.
Based on the motion patterns of the left and right arms, expressive actions are categorized into three types, as shown in Table 1 from left to right:
Single-arm execution of actions. Wave arm: Either the left or right arm performs the waving action separately while the opposite arm maintains its initial posture.
Dual-arm cooperative execution of actions. Hugging, Turn Left and Turn Right actions: The left and right arms need to execute different actions when executing. Arm Exercises: the left and right arms execute the same actions.
Dual-arm and torso cooperative execution of actions. Arms Up and Bend Down to Welcome: requiring both arms to perform the same movement, that is, the torso finishes bending after simultaneously raising the right and left arms.
Categorization of expressive actions.

Experimental set-up and evaluation metrics
Based on the structure of the prototype of the dual-arm nursing robot, the simulation model of the robot is developed in SolidWorks. The simulation model consists of mobile chassis, torso, left and right arms, etc., with a total of 14-DoF. The left and right arms adopt a symmetric structure, and each arm incorporates shoulder, elbow and wrist joints, and each joint has 2-DoF. The torso is composed of lumbar and hip joints, with 1-DoF for each joint.
Experiments were conducted in the MuJoCo physical environment. The PD control parameters for the controller are specified in Table 2. First, we conducted ablation experiments using GPT-4o-2024-08-06 for prompt design, along with expressive action experiments covering seven action types across three categories, to preliminarily evaluate the performance of the SeIn framework. The success rate was set as an evaluation metric to evaluate the performance of the SeIn framework. Five trials were performed for each action, and each trial lasted 4 s. Within 4 s, the experiment was deemed successful if the dual-arm nursing robot executed the set target action.
PD control parameters.

Note. Units are Nm/rad for Kp and Nms/rad for Kd.
Subsequently, experiments were conducted to determine the optimal normalization range, and the framework’s performance was evaluated when querying different LLMs under execution durations of 4 and 60 s. Finally, experiments were conducted on functional action involving Reach-to-Object. The specific experimental settings for each of these will be detailed within their respective experiments.
Analysis of experimental results
First, we try to answer Question 1: How does the prior knowledge in the task-specific textual prompts affect the execution of actions in the SeIn framework?
The Action Execution Process and The Target Joint Position in the prior knowledge were selected for the experiment, and two configurations were set up: (1) Contains only the Action Execution Process. (2) Contains both the Action Execution Process and the Target Joint Position. In the experiment, the Hugging action was selected for testing, and the observation information included joint position and joint velocity. The results are shown in Table 3.
The effect of prior knowledge on action execution.

Experiments incorporating only Action Execution Process in the prior knowledge achieved 0% success rate (all experiments failed). In contrast, trials combining both Action Execution Process and Target Joint Position in the prior knowledge, achieved 100% success rate. Comparative analysis between failed experiments and the successful experiments to visualize how prior knowledge affects the execution of embracing movements.
As shown in Figure 6, the visualized Action Execution Process indicates that when only relying on (1) the Action Execution Process as the prior knowledge of LLMs, although the robot attempts the hugging action, but collisions occurred between the arms during the movement, and joint positions cannot be attained the Target Joint Position needed for the hugging action. However, with the addition of (2) the Target Joint Position, the arms did not collide during the movement, and the hugging action was successfully completed with a success rate of 100%.

Comparison of the visualized execution process of the hugging action. In the first and second rows of pictures, the robot’s left and right arms collide during the lifting process. In contrast, in the third row, the robot’s left and right arms do not collide during the lifting process. Finally, both arms reach the target positions and successfully completed the hugging action.
Question 1 is answered through the ablation experiments. The synergistic collaboration between the Action Execution Process and the Target Joint Position is the key to achieving the low-level motion (action execution) using LLMs to drive the dual-arm nursing robot. Specifically, the Action Execution Process helps LLMs understand the sub-steps required for the action, while the Target Joint Position ensures that the LLMs output the joint position corresponding to the desired target pose.
Subsequently, we attempted to answer question 2: How should observation information be configured to achieve optimal performance in the SeIn framework?
We evaluated the following four types of observation information: (1) no observation, (2) joint position, (3) joint velocity, (4) joint position + joint velocity. Similarly, the hugging action was selected for the experiment. Based on the previous experimental results, the prior knowledge contains both the Action Execution Process and the Target Joint Position.
Experimental results are summarized in Table 4. Among them, in the experiments with no observation information, all five experiments failed. In the experiments where the observation information was either joint position or joint velocity, both achieved a success rate of 40%. Finally, the SeIn framework achieved the best performance with 100% success rate in the case where joint position and joint velocity were observed simultaneously.
Experimental results for different observation information.

Question 2 is answered through observational ablation studies. The configuration of observation information is crucial. Although the incorporation of prior knowledge provides LLMs with essential information such as sub-steps and target joint positions required for the action, the SeIn framework requires both joint positions and joint velocities as simultaneous observation information to provide feedback to the robot during the execution of the action. And one cannot be used without the other.
Then, we try to answer question 3: Can the SeIn framework be generalized to multiple action executions?
To investigate this, seven expressive actions (e.g. Hugging and Wave Arm) were designed, as shown in Figure 5. Consistent with empirical protocols, the prior knowledge integrates both the Action Execution Process and the Target Joint Position, and the observation information contains both the joint position and the joint velocity. Quantitative results are shown in Table 5. The SeIn framework can be applied to a wide range of actions.
Results of the seven actions.

As shown in Table 5, the SeIn framework executes seven distinct actions, covering three categories: single-arm execution, dual-arm-cooperative execution, and dual-arm-torso cooperative execution, achieving 100% success rate across all categories. This demonstrates that the SeIn framework is able to accurately generate the required joint position sequences for target actions, ranging from single-arm actions with 6-DOF to full-body motions involving 14-DOF.
The execution process of the seven actions is shown in Figure 7. Three critical outcomes are observed: (1) the target joint successfully reached their target position at the completion of the action. (2) There is no collision of the left and right arms during the execution process. (3) There is no confusion between the left and right arms during the execution process.

Execution process of the seven actions.
Based on the above experiments and analysis, we can now answer question 3. The SeIn framework extends to the execution of seven distinct actions, and the experimental results demonstrate the full kinematic feasibility of the SeIn framework. At the same time, the task-specific textual prompts can be rapidly reconfigurable to different action requirements, demonstrating the potential of the SeIn framework to extend to a number of different actions.
Next, we attempted to answer question 4: What is the optimal normalization range for Observation and Action?
To determine the optimal normalization range, we systematically compared four ranges: [0–100], [0–200], [0–500], and [0–1000]. Experiments were conducted with GPT-4o-2024-08-06 and Qwen2.5-72B-Instruct using identical prompts. The experimental setup is as follows: LLM inference frequency (5 Hz), evaluation duration (4 s), all seven expressive actions, repetition count (5 repetitions per action). Decoding parameters are uniformly set to temperature = 0.0. Outputs employed structured constraints (JSON + regular expression validation) to minimize failures caused by format mismatches. Success is determined by the robot achieving the target pose without collision and without confusion between left-right arms.
As shown in Figure 8. When handling Single-Arm Execution, GPT-4o and Qwen2.5 achieved higher success rates across all four normalization range. Notably, When performing Arm Exercises in Dual-Arm Execution, both models encountered challenges: Qwen2.5 achieved 60% success in the [0–200] range and 0% in [0–500]; GPT-4o performed best at 100% success in [0–200]. Finally, when processing Arms Up and Bend Down to Welcome: Qwen2.5 achieves a 60% success rate in [0–200], [0–500], and [0–1000], while its success rate drops to 0% in the [0–100]; GPT-4o achieved 100% success rate in [0–200] range, demonstrating optimal performance. Overall, the [0–200] normalization range demonstrated superior performance.

Normalization range evaluation results in seven expressive actions. The experiment systematically compared four ranges: [0–100], [0–200], [0–500], and [0–1000].
Finally, we try to answer question 5: How stable is the SeIn framework in the long-term when querying different LLMs to perform expressive actions?
To investigate this, we extended the evaluation duration from the 4 to 60 s. We selected the following models for comparative experiments: (1) Closed-source models: GPT-4o-2024-08-06; (2) Open-source models: LLaMA-3.3-70B-Instruct, Qwen2.5-72B-Instruct, DeepSeek-V3.1. The experimental setup is as follows: identical prompts, LLM inference frequency (5 Hz), all seven expressive actions, repetition count (5 repetitions per action), with the normalization scale set to [0–200].
As shown in Table 6, where 4-SR and 60-SR represent the success rates of the SeIn framework during evaluation durations of 4 and 60 s, respectively. Both GPT-4o and DeepSeek-V3.1 models achieved 100% success rates across all 7 actions and 35 trials, maintaining stable performance in both short-term (4 s) and long-term (60 s) tests. Qwen2.5-72B-Instruct demonstrated strong performance in low-DoF tasks (DoF ≤ 7), with its 60-SR performance matching or slightly fluctuating around its 4-SR performance. However, its performance declined in high-DoF tasks, indicating bottlenecks in long-term temporal reasoning and error correction for complex actions. LLaMA-3.3-70B-Instruct’s performance is closely tied to task complexity. For high-DoF tasks (DoF ≥ 12)—namely Hugging, Arm Exercises, and Arms Up and Bend Down to Welcome—the model completely fails (achieving 0% success in both 4-SR and 60-SR), unable even to execute short-term control for these high-DoF actions.
Evaluation results for querying various LLMs under 4- and 60-s durations.

Through the above experiments and analysis, we can answer Question 5. While the long-term stability of the SeIn framework correlates with the inherent capabilities of the selected LLMs. It is crucial to emphasize that for top-tier LLMs, the SeIn framework actively suppresses error accumulation through its observation information feedback, demonstrating its potential for achieving long-term stability.
Reach-to-object
To further test the potential of the SeIn framework in handling more complex, functional actions requiring interaction with the environment, we introduced the Reach-to-Object task. The task execution flow is as follows: The robot must first obtain the world coordinates of the red block in the MuJoCo in real-time, generating a target point with a fixed safety margin (+2 cm along the X-axis). Subsequently, it dynamically selects the arm closest to the target to execute the task. Then, it solves for the full target joint position in the robot base coordinate system. Finally, the arm selection decision, red block coordinates, discretized target q, and observation segments are provided to the LLM, which outputs a smooth intermediate joint sequence for the approach.
Experimental setup: GPT-4o-2024-08-06 and DeepSeek-V3.1 were selected for the experiment. Each arm performed 5 trials. Within 10 s, the robot arm end must reach within the target offset area without collisions or confusion between the left and right arms.
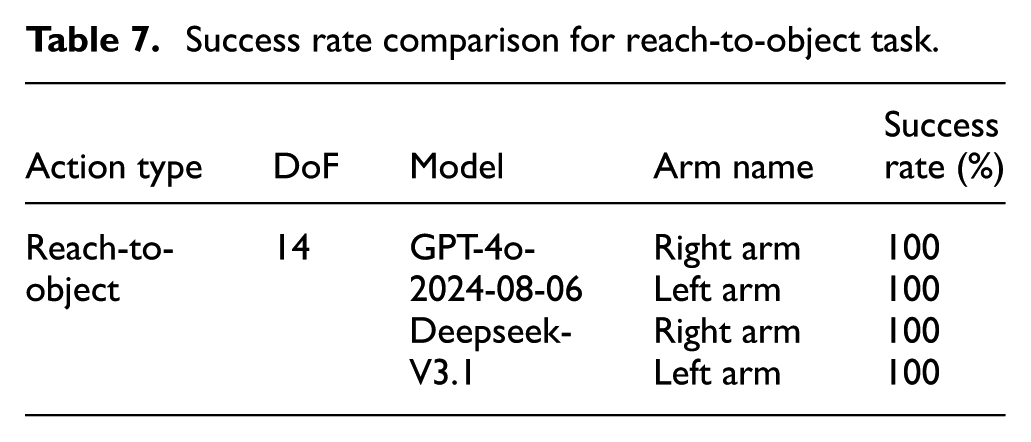
The execution process is illustrated in Figure 9. The robot’s left/right arm starts from a stationary position and gradually extends toward the red block placed on its left/right side. The entire execution process exhibits smooth and natural motion, with the robotic arm’s endpoint ultimately positioning within the target object area. No collisions or confusion between the left and right arms occurred during the execution. Performance metrics are presented in Table 7. When SeIn framework queried GPT-4o-2024-08-06 and Deepseek-V3.1, both achieved a 100% success rate. This shows that when handling more complex, environment-interactive functional actions (Reach-to-Object), the SeIn framework successfully generates the required target joint position sequences to guide the arm to the target location area.
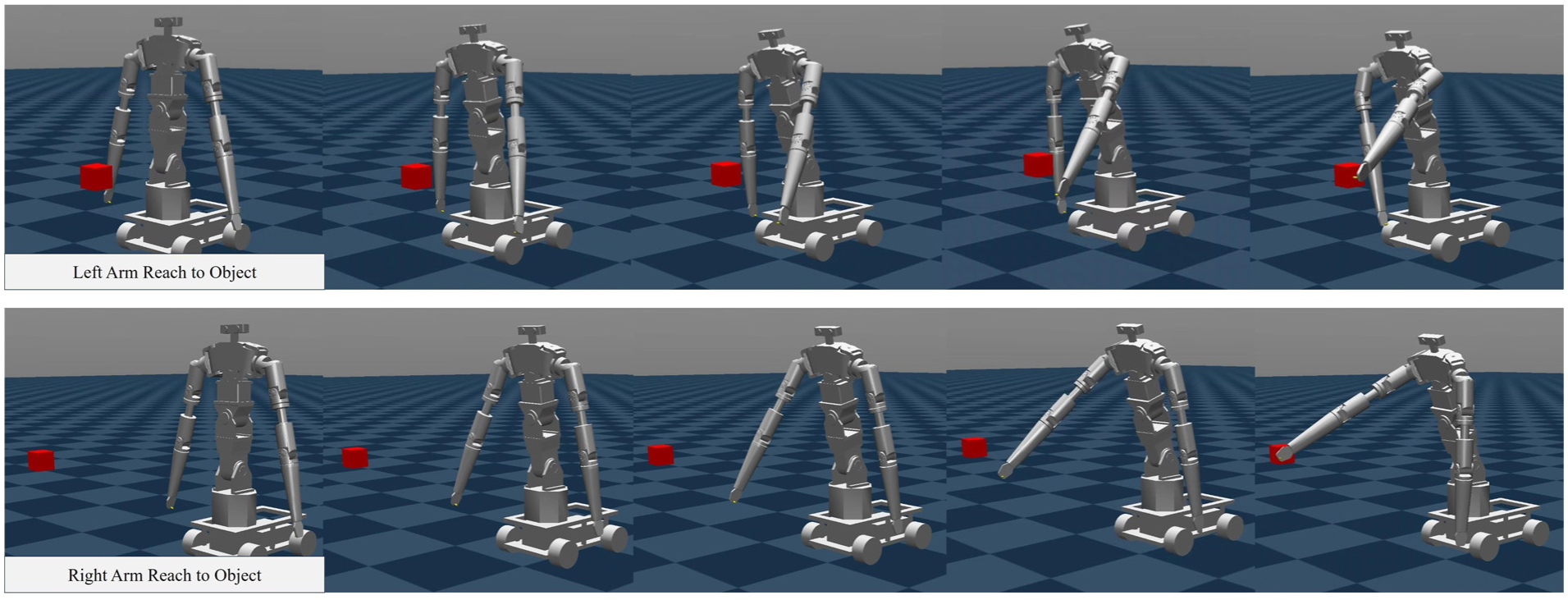
Execution process of the reach-to-object. The first and second rows of images show the motion of the left and right arms as they approach the red object area, respectively.
Success rate comparison for reach-to-object task.
Experimental Summary: The SeIn framework generates target joint-position sequences by invoking pre-trained LLMs through task-specific textual prompts to accomplish multiple action executions. Specifically, the prior knowledge embedded in the task-specific textual prompts helps the LLMs precisely decode action kinematics, resulting in generating more accurate target joint positions. The observation information consisting of joint positions and joint velocities guarantees stability during execution. Such task-specific textual prompts are rapidly reconfigurable for heterogeneous action specifications to different action requirements. Ultimately, the SeIn framework accomplished the execution of seven expressive actions and demonstrated potential for handling one functional action in a simulated physical environment.
Limitations and future work
The inference speed of the SeIn framework is limited
The SeIn framework exhibits constrained inference speeds due to LLMs response latency (5 Hz inference rate) and PD controller tracking frequency (100 Hz). Simulation experiments indicate that the SeIn framework is currently best suited for expressive actions and task with lower real-time requirements. Although demonstrated in simulation, enhanced LLMs inference rates could enable accelerated execution in physical systems.
The textual prompts are still relatively fragile
Although the SeIn framework can perform seven actions, these actions are relatively simple. Empirical evidence confirms that the design of prior knowledge and observation information can greatly influence the final performance of the SeIn framework. Therefore, crafting more refined and optimized textual prompts may further exploit the potential of the SeIn framework to execute more complex actions (e.g. actions involving interaction with environmental objects or requiring multi-step coordination).
Conduct research on optimization and convergence
Subsequent studies will delve into the convergence properties of generated sequences and explore optimization frameworks to enhance their accuracy. For instance, optimization methods such as co-evolutionary neural dynamics (incorporating dual gradient accumulation) 52 can be introduced.
This study was conducted solely in simulation
The real-world experiments have not yet been carried out. Future deployments will focus on the SeIn framework on a dual-arm nursing robot for real-world experiments to test its performance in real prototypes and scenarios.
Conclusion
The SeIn framework is proposed to integrate LLMs with MuJoCo simulations, leveraging for dense target joint-position sequences generation. Task-specific textual prompts are engineered with four components: Task Description, Prior Knowledge of Action, Observation Information, and System Configuration. Subsequently, ablation experiments systematically quantify prompts component impacts of task-specific textual on the SeIn framework. Through experiments with four distinct LLMs at execution durations of 4 and 60 s, the framework’s long-term stability was validated.
This work empirically validates that properly architected frameworks and optimized prompts enable LLMs to demonstrate task comprehension and low-level robotic control capability. It holds promise for simplifying the complex “high-level planning + low-level execution” separation architecture currently employed in LLM-driven robotic systems.
Footnotes
Handling Editor: Fernanda Coutinho
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Consent for publication
The authors confirm.
Author contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Zhendong Zhao, Jiexin Xie, Yang Li and Shijie Guo. The first draft of the manuscript was written by Zhendong Zhao and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by National Natural Science Foundation of China under Grant 62303154.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Code availability
The authors confirm.