
Abstract
The fatigue evaluation of the bogie frame is an important part of the structural health monitoring of the vehicle. During the dynamic stress monitoring, some signal spikes, which are much larger than the normal fluctuation range due to the interference of the complex electromagnetic environment, affect the accuracy of the structural damage assessment and need to be accurately detected and replaced. Aiming at the drawbacks of traditional detection methods that are overly dependent on engineering experience and not universal, a novel spike detection model is proposed in this paper. By the process of data transformation, spike region features are effectively separated. Based on the isolation forest algorithm, the normalized anomaly score of each point is calculated, and the threshold is determined adaptively. The spike detection rate and damage sensitivity are proposed as the evaluation indices of the detection effect of the method. The results show that the spike detection rate is improved by 7.86% on average, and the damage sensitivity is improved by 15.59% on average. The spike detection model in this paper is significantly improved compared to the existing methods.
Keywords
Introduction
As a key structure of the rail vehicle running part, the bogie frame is subjected to a variety of loads such as floating, rolling, braking, traction, and other coupling effects in the process of application, while the frame is an all-welded structure, and the fatigue strength of the weld region is much smaller than that of the base material due to the influence of the residual stresses, stress concentrations, and weld defects, which results in frequent cracks in the frame before it reaches the design life,1,2 and brings a great challenge to the vehicle operation safety.
In terms of structural health monitoring of the bogie frame, to accurately evaluate the damage level of the frame under the current operating conditions, the real dynamic stress of the frame can be obtained by sticking strain gauges in the key regions. The monitoring quality of the real dynamic stress signal determines the accuracy of the final structural damage evaluation, in which the factors affecting the signal monitoring quality mainly focus on two aspects. On the one hand, at the beginning of the actual monitoring process, the strain gauges need to be preheated, and the external ambient temperature may change greatly during the monitoring process, resulting in a significant zero drift of the real dynamic stress signal. 3 On the other hand, the connecting cables of the dynamic stress monitoring system are in a complex electromagnetic compatibility environment, for example: a large number of electromagnetic radiation interferences are generated by lifting and lowering pantographs and over-phase operations, and conductive interferences are also generated by electrical equipment under the vehicle through cables,4–6 which result in a large number of randomly located outliers, that is, spikes, in the dynamic stress signals. When the real dynamic stress signal is mixed with the above two interfering components, especially the signal spikes, the accuracy of the structural damage assessment will be greatly affected. Specifically, since the spike signal in the time domain shows high frequency and large amplitude oscillations in a short time, if the measured stress spectrum is constructed for the dynamic stress data containing signal spikes, the frequency of the stress spectrum block with large range cycles will be significantly increased, which will lead to the damage value being too large and the fatigue evaluation results being distorted. Due to the duration, fluctuation range, frequency distribution, and other characteristics of the signal spike in the dynamic stress data are not consistent, the detection of dynamic stress signal spike has a high degree of complexity. At present, in the actual engineering application, the spike detection method for the measured dynamic stress signal has not yet been formed, and it generally relies on the engineering experience of the researchers to mark and process manually, and the quality and efficiency of the data processing need to be improved urgently.
Signal spikes are typical time series anomalies, which are usually characterized by the following features as defined in the literature.7–9 The different types of anomalies can be divided into point anomalies, collective anomalies, and contextual anomalies, of which signal spikes correspond to the first two types of anomalies according to different causes. The signal spike detection problem generally consists of a forward problem and an inverse problem. The forward problem is to locate the signal spike location based on the original data in the time domain, and a typical application is the electroencephalogram (EEG) signal spike determination. 10 The inverse problem, that is, estimating and reconstructing the physical information and characteristics in the original data based on the inclusion of noisy signals or images represented by signal spikes, involves the process of sparse deconvolution. 11 Good results have been achieved with Gaussian mixture models, 12 non-negative Bayesian learning, 13 and non-convex sparse regularization. 14
For the forward problem, in recent years, researchers have carried out extensive studies on the problem of anomaly detection, and this paper classifies the basic algorithm models, as shown in Table 1.
Classification of anomaly detection models.

Although a series of time series outlier detection models with good results have been developed in various fields, especially in the field of SHM, there are still the following challenges in applying them to the problem of frame dynamic stress signal spike detection.
(1) In the existing literature, the experimental data used in the outlier detection models are mainly derived from test stand tests (e.g.15,24,29) or publicly available data sets (e.g.25,26,37), which do not require complex pre-processing of the data for the application of these detection models. However, the frame dynamic stress signals are affected by the field environment and contain specific internal interference components, such as 50 Hz power-line interference, zero drift, and signal oscillation due to vehicle start-stop transients may cause local peaks in the signal due to the superposition of these interfering components, which may lead to a large number of misjudgments in the model during the spike detection process. Since there are many types of interference components and the causes of interference components are closely coupled with the field test conditions, the various types of interference components in the pre-processing stage have not yet been strictly classified, and the time-frequency characteristic law of each type of interference component lacks a specific mathematical description, so it is difficult to solidify the processing flow corresponding to each type of interference component. In addition, for each type of interference component, there is no appropriate index to quantitatively judge the quality of the pre-processing results, and it is difficult to control the accuracy of the forward link of signal spike detection.
(2) The duration of the dynamic stress monitoring process of the bogie frame is long, the signal sampling rate is above 1000 Hz, and the number of single-channel data points is usually above ten million, which is much larger than the scale of the test data in the literature, whereas the algorithm complexity of the detection algorithms in the literature is generally high, and the computational time overhead is too large when facing the task of detecting long-time sequence outliers.
(3) In order to quantitatively evaluate the detection effect of model outliers, different literatures have constructed a variety of evaluation indices according to the characteristics of the data to be detected, for example, MCC, F0, 37 elastic loss, vulnerability and duration. 16 The calculation method of these evaluation indices is closely related to the type of data to be detected, the way of anomaly statistics, etc., and cannot be directly applied when evaluating the effectiveness of dynamic stress signal spike detection.
To solve the above problems, this paper proposes a detection model for signal spikes oriented to the dynamic stresses of bogie frames, and its main contributions can be summarized as follows:
(1) The trend removal method (TRM) is constructed for the zero-point drift phenomenon in the original signals of dynamic stress based on the segmented linear assumption and Mann-Kendall hypothesis test. The method removes the zero-point drift without introducing oscillations and adaptively removes the trend term component in dynamic stress by quantitatively calculating the drift degree of the trend term and establishing the judgment condition for the iteration abort of the algorithm.
(2) The recursive form of instantaneous rolling weighted standard deviation calculation method is proposed, introduces the residual contribution function to determine the range of values of initial weight coefficients, and effectively separates the signal spike region from the non-spike region. The normalized anomaly scores corresponding to each point of the instantaneous rolling weighted standard deviation sequence are calculated by using the isolation forest algorithm, and the threshold is adaptively determined by combining the kernel density estimation (KDE) method.
(3) The spike detection rate as well as the damage sensitivity are constructed as the evaluation indices of the signal spike detection effect. Using the above two indices, the detection model proposed in this paper is validated on five datasets, and it is better than several major algorithms that are currently established.
Data pre-processing
During the long time dynamic stress tracking experiment, the output of the strain bridge under no load condition will change over time due to the strain gauge preheating process or when there is a significant change in the ambient temperature, at this time, the dynamic stress contains an obvious trend term, that is, the phenomenon of zero-drift. Zero-drift will lead to the existence of one or more large-value stress cycles in the rainflow counting results, so it is necessary to remove the zero-drift in the pre-processing stage.
In order to avoid causing oscillations and at the same time quantitatively represent the degree of zero drift, this paper proposes a zero-drift suppression algorithm based on the segmented linear drift assumption, called the trend removal method (TRM), in which the segmented linear drift assumption has two main points:
The baseline drift over a short period of time is linear, and the overall zero-drift can be considered to be approximated by a set of fold lines.
The zero-drift component of the dynamic stress and the normal fluctuation are linearly superposition.
Based on the above assumptions, the TRM calculation process is shown in Figure 1(a).
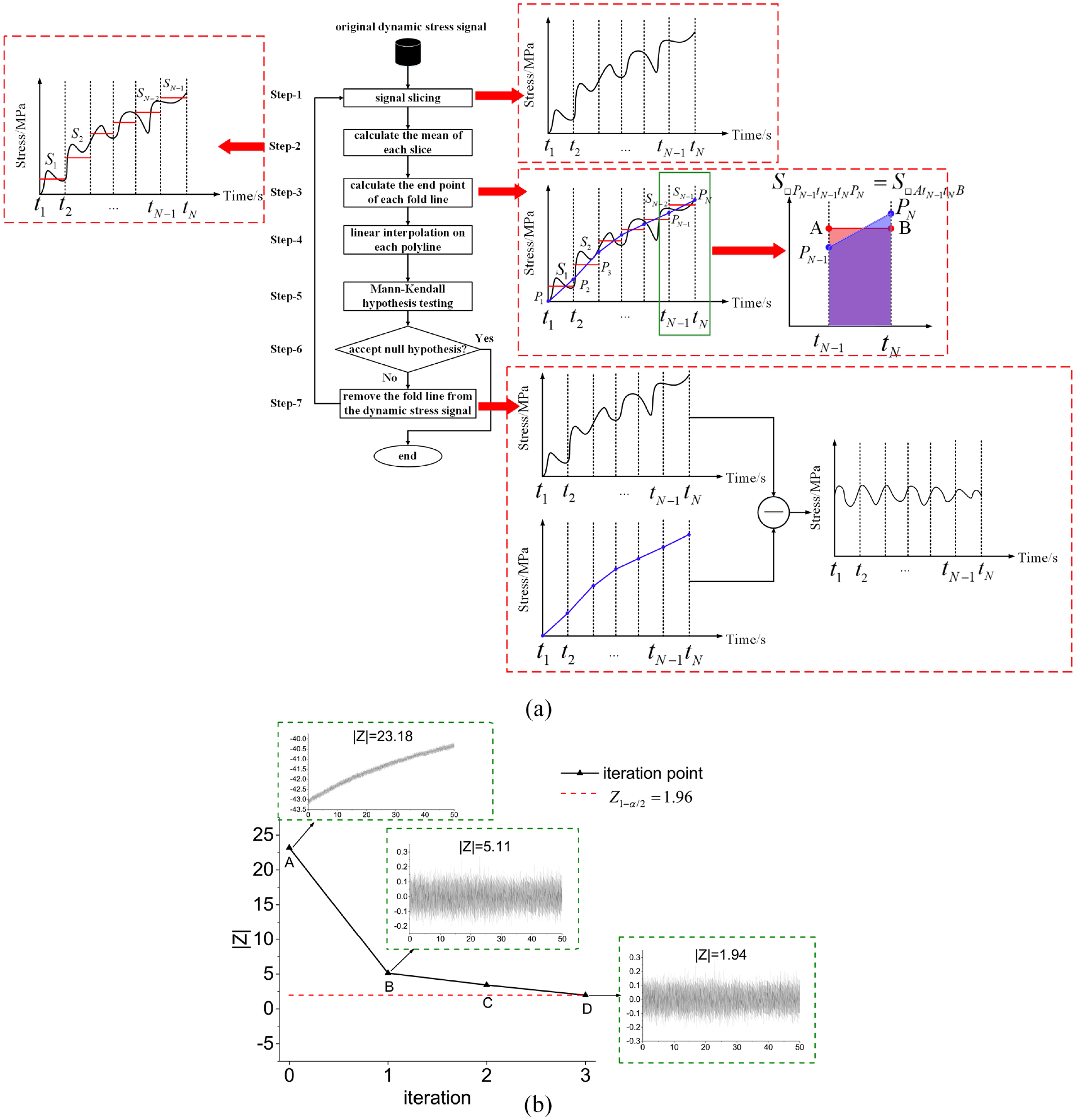
Trend removal method: (a) TRM calculation process, (b) TRM iterative process.
The TRM first slices the original signal of length

In formula (1),
Based on the linear drift assumption, the sequence of endpoint values is linearly interpolated to obtain a trend line of equal length to the original dynamic stress signal. A Mann-Kendall trend test was performed on the trend line to define the statistics
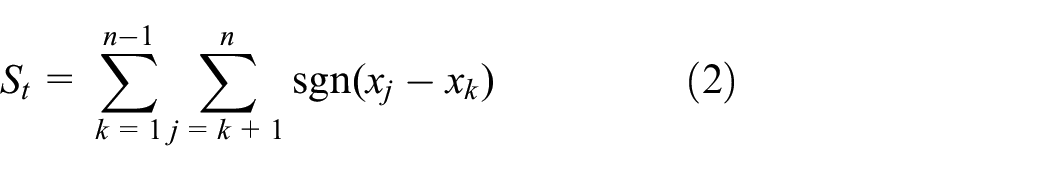
Where

Then the Mann-Kendall trend test statistic
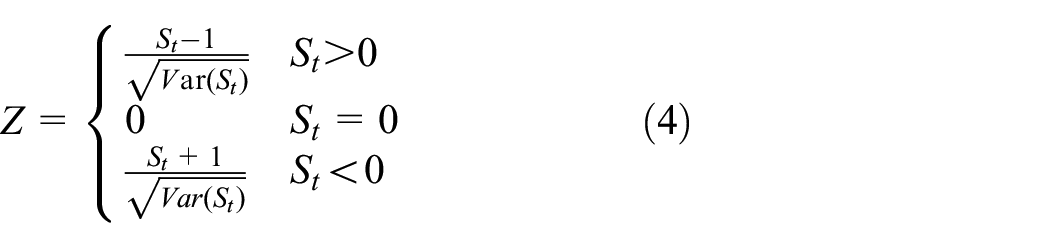
In formula (4),
In the process, the iteration abort is determined as follows: at a given confidence level
Taking confidence level 95% as an example, at this time,
In Figure 1(b), point A represents the original dynamic stress signal, and point B to point D represent an iteration process. It can be seen that after performing three iterations using TRM, the zero-drift trend is completely removed.
Signal spike detection
Signal spike duration can be divided into two types, one is a short duration (within 10 ms) discrete spike, and the other is a long duration (within 0.2 s) continuous spike. For the above two types of signal spikes, the detection model proposed in this paper consists of two stages, as shown in Figure 2.

Signal spike detection process.
Data transformation
Rolling weighted standard deviation is a statistical indicator used to calculate the volatility of a time series by introducing a weight coefficient and assigning higher weights to recent observations to effectively capture the impact of newer data on the overall volatility. The rolling weighted standard deviation is usually calculated using a sliding window, each window contains

Where:
According to the weighted average definition, there is:

Substitute formula (6) into formula (5), there is:

According to formula (7), the rolling weighted standard deviation is affected by the distribution of window length and weight coefficient, which are fixed and cannot be adjusted adaptively according to the signal spike duration. In this section, a recursive method for calculating the instantaneous rolling weighted standard deviation is proposed. The specific calculation steps are as follow.


Where:

Define the residual contribution function

Substitute formula (10) into formula (11), there is:

Take the derivative of formula (12), there is:

For any
Under different weight coefficients, the relationship between

Data transformation: (a) residual contribution function with different initial weight coefficients, (b) minimum number of points with different initial weight coefficients, (c) comparison of computation time for different forms, (d) data transformation result.
When
The minimum number of calculation points required to decay the residual contribution function to 0.01% at
With the increase of
A comparison of the computation time of the rolling weighted standard deviation series based on the recursive form and based on the sliding window form is shown in Figure 3(c). As the scale of the data points of the sequence to be computed increases, the computation time of the recursive form is gradually shortened compared with that of the sliding window form, and the larger the scale of the data points is, the more obvious the improvement of computational efficiency is. Compared with the rolling weighted standard deviation in the form of sliding window, the algorithm complexity is reduced from
The original dynamic stress signal data transformation results are shown in Figure 3(d). Overall, the process of transforming the original dynamic stress signal into IRWSD contains a filtering effect, the effect of which is that the stable signals are suppressed to zero, while the non-stationary signals are enhanced, with the highest degree of enhancement at the point of the signal spike. Therefore, according to the final transformation result, the IRWSD sequences are divided into three regions, which are nonstationary spike region, nonstationary non-spike region, and stationary region.
Spike detection
Anomaly score sequence
Isolation forest is an unsupervised anomaly detection method proposed by Liu et al. 36 It is often used in anomaly detection tasks for large-scale data due to its linear time complexity and high accuracy.32,34–36
When detecting outliers in isolation forests, it is considered that the population with sparse outlier distribution and high distance density is far away, and it is easiest to be separated in the process of multiple division. The anomaly score

In formula (14),
Normalization of the sequence of anomaly scores is available:

To ensure randomness,

Anomaly score threshold
Typically, the anomaly score of non-spike points remains below 0.5. However, in some line sections, due to wheel-rail excitation like rail undulatory wear and wheel out-of-roundness, the excitation frequency coincides with the natural modal frequency of some structures of the bogie frame, leading to structural resonance. During this time, the dynamic stress response increases significantly, causing more violent signal fluctuations. Therefore, the threshold of anomaly score should be dynamically adjusted according to the signal fluctuation.
From a statistical point of view, the number of points corresponding to the non-spike regions is much larger than that of the spike regions, and if the anomaly score threshold is chosen reasonably, the cumulative probability of the anomaly score in the non-spike region should be much larger than that in the spike region, and the anomaly score threshold, that is, the anomaly score corresponding to a cumulative probability larger than a specified value. In order to determine the anomaly score cumulative distribution function (CDF), it is necessary to first calculate the probability density function (PDF) of the anomaly score.
To overcome the limitations of traditional parameter estimation methods, the kernel density estimation (KDE) method is used in this section to fit the IRWSD sequence distribution.
The probability density function

In formula (17),

The bandwidth coefficient determines the accuracy of probability density estimation. In this section, the optimal bandwidth coefficient is calculated with the minimum of asymptotic mean integrated square error (AMISE) as the constraint condition, there is:

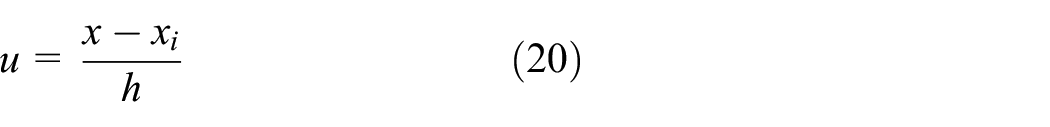
Formula (19) is derived for

The kernel estimate of the cumulative distribution function is:
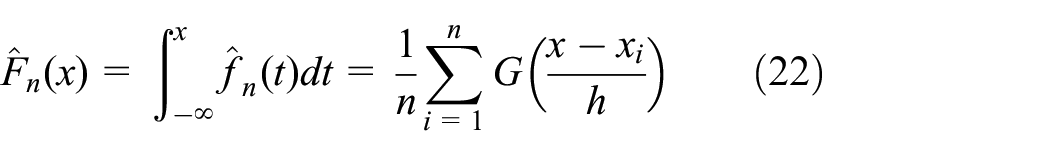
In formula (22),
Then, the anomaly score threshold is:

In formula (23),
Taking

Anomaly score threshold under different signal lengths (
In Figure 4, it can be found that there are some differences in the CDF corresponding to different lengths of the anomaly score sequences, and the thresholds are adaptively adjusted according to the different signals to be detected. Among the anomaly score sequences of different lengths, the anomaly scores corresponding to spike regions are all above the threshold, while the anomaly scores corresponding to non-spike regions are all below the threshold except for very few points.
Experimental verification
Experimental dataset
The experimental measurement system is shown in Figure 5(a). The system mainly includes host computer, switch, data acquisition equipment and stress measurement point. Among them, each stress measurement point corresponds to a strain gauge, which is connected to a channel of the data acquisition system. At the same time, based on TCP/IP protocol, the collected data is sent to the host computer in real time by the switch for monitoring and analysis.
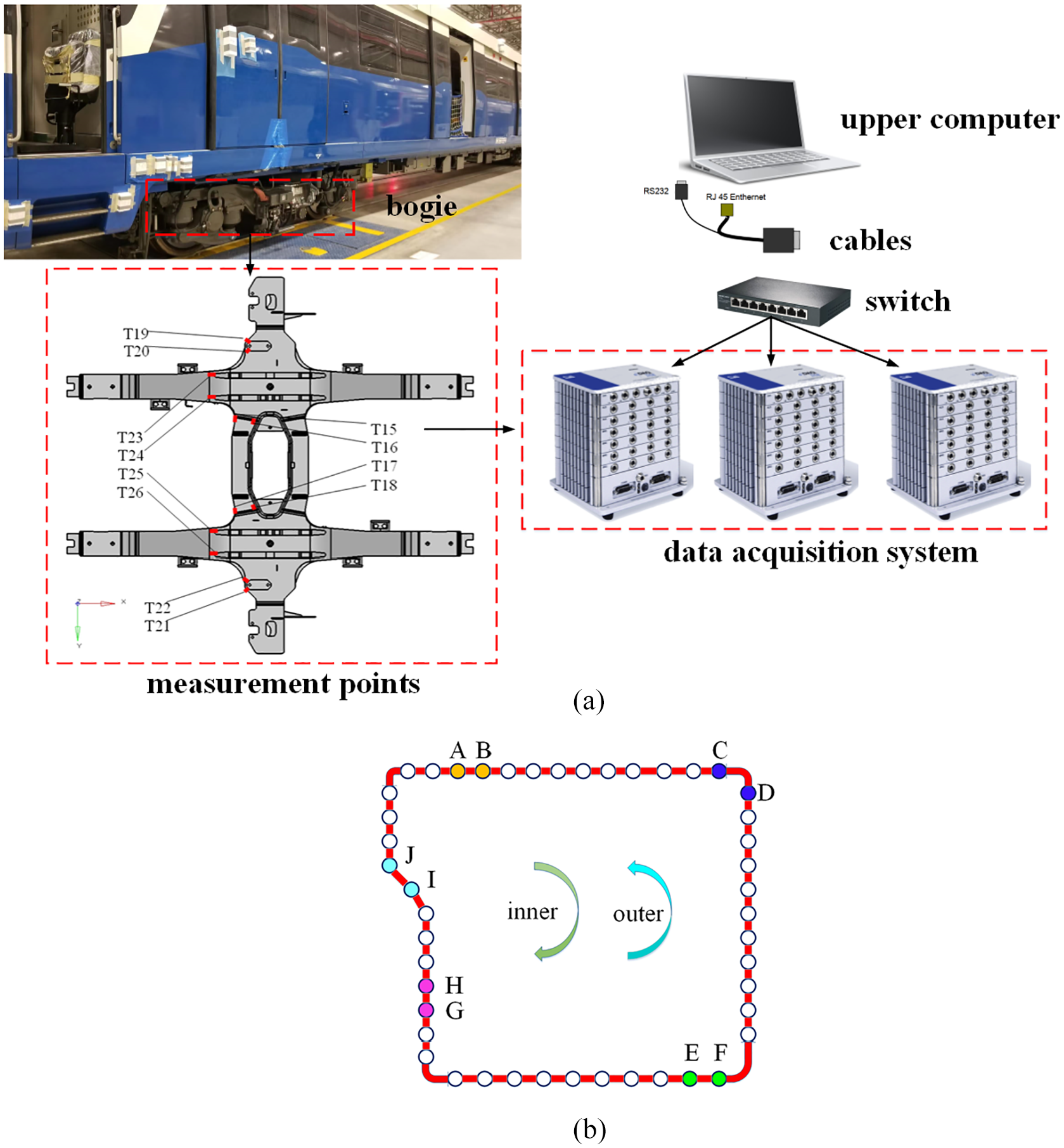
Metro dynamic stress experiment: (a) experimental measurement system, (b) experimental line schematic.
The experimental line schematic is shown in Figure 5(b), which includes an inner loop and an outer loop.
For the above experimental line, a 5-days experiment was carried out. It is statistically found that within the line sections A–B, C–D, E–F, G–H, and I–J, the signals of the measurement points in the different areas of the bogie frame contain more signal spikes, so this section constructs five datasets by the different dates of the experiment, and the detailed information is shown in Table 2.
Experimental detailed information.

The dataset construction process involves manual labeling of each sample. This is done by slicing the samples at a length of 2 s and observing the anomalies within each slice. The anomalies are typically five times greater or more than the average value within the slice. If the duration of the anomalies is less than 0.2 s, all the points within 0.2 s are labeled as anomalies. On the other hand, if the duration is greater than 0.2 s, they are considered nonstationary non-spike signals and are left unlabeled.
Experimental evaluation indices
Spike detection rate
Spike detection rate (SDR) is used to evaluate the degree of overlap between algorithm detection results and manually labeled results in a continuous dynamic stress signal. When manual labeling results are presented as a continuous interval and algorithm detection results are given as discrete signal spike points, it becomes difficult to compare the two directly. To overcome this challenge, we have divided the sample into multiple detection units and treated the occurrence of a signal spike within a unit as a random event. In case a signal spike occurs within a unit, it is considered positive, and the position and frequency of the spikes are ignored. This paper sets the detection unit length to 0.2 s in combination with manual labeling rules.
Therefore, the SDR is calculated as follows.

Damage sensitivity
Damage sensitivity (DS) is used to evaluate the severity of signal spikes detected by the algorithm, and is described by the difference in structural damage before and after signal spike labeling and replacement. Ideally, the damage change based on algorithmic labeling and replacement should be consistent with the manual method, in which case the damage sensitivity is close to 1. When the algorithm is too severe, the damage sensitivity is less than 1. Conversely, damage sensitivity is greater than 1. The specific calculation process is as follows.

In formula (25),
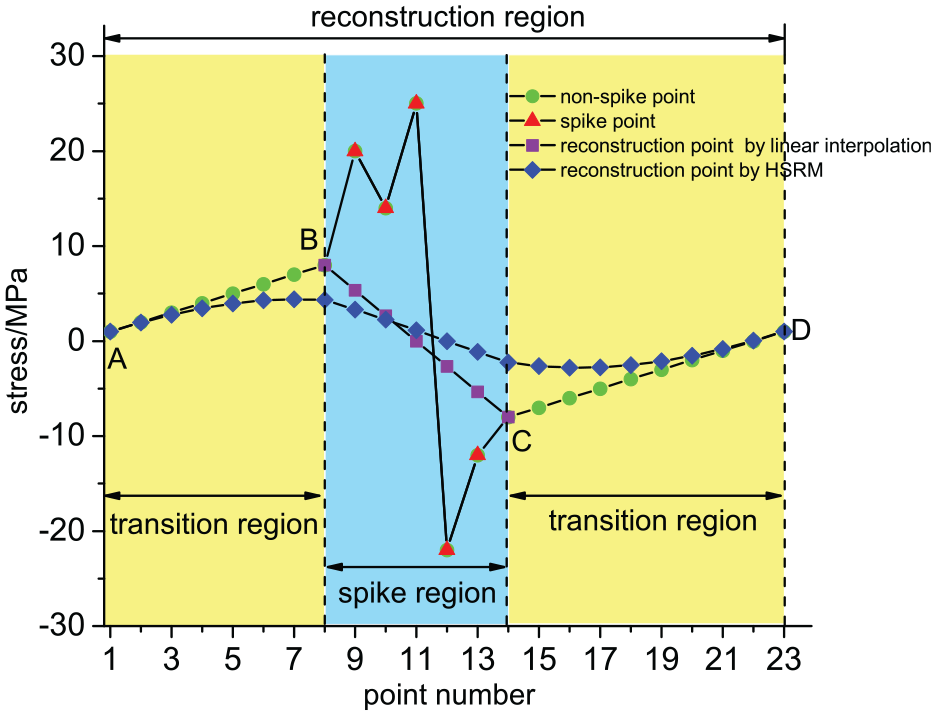
Signal spike reconstruction.
The reconstruction region contains two parts, namely the transition region and the spike region, in which the transition region is extended forward and backward according to the first and endpoints B and C of the spike region, respectively, until the first and endpoints A and D of the reconstruction region are equal, the transition region A–B and C–D are obtained.
To smooth the reconstruction region, the half-sine reconstruction method (HSRM) is established in this section, which removes the gradient discontinuity in the reconstruction region with the help of two half-sine functions, and the points within the reconstruction region are calculated as:

In formula (26),

In formula (27),
In Figure 6, the reconstruction result using HSRM is smoother and introduces less stress cycle amplitude than the linear interpolation method.

In formula (28),

Discussions
The detection effects of different model parameters and detection algorithms were evaluated on five datasets, using spike detection rate and damage sensitivity as evaluation indices. The comparison results are shown in Figure 7.
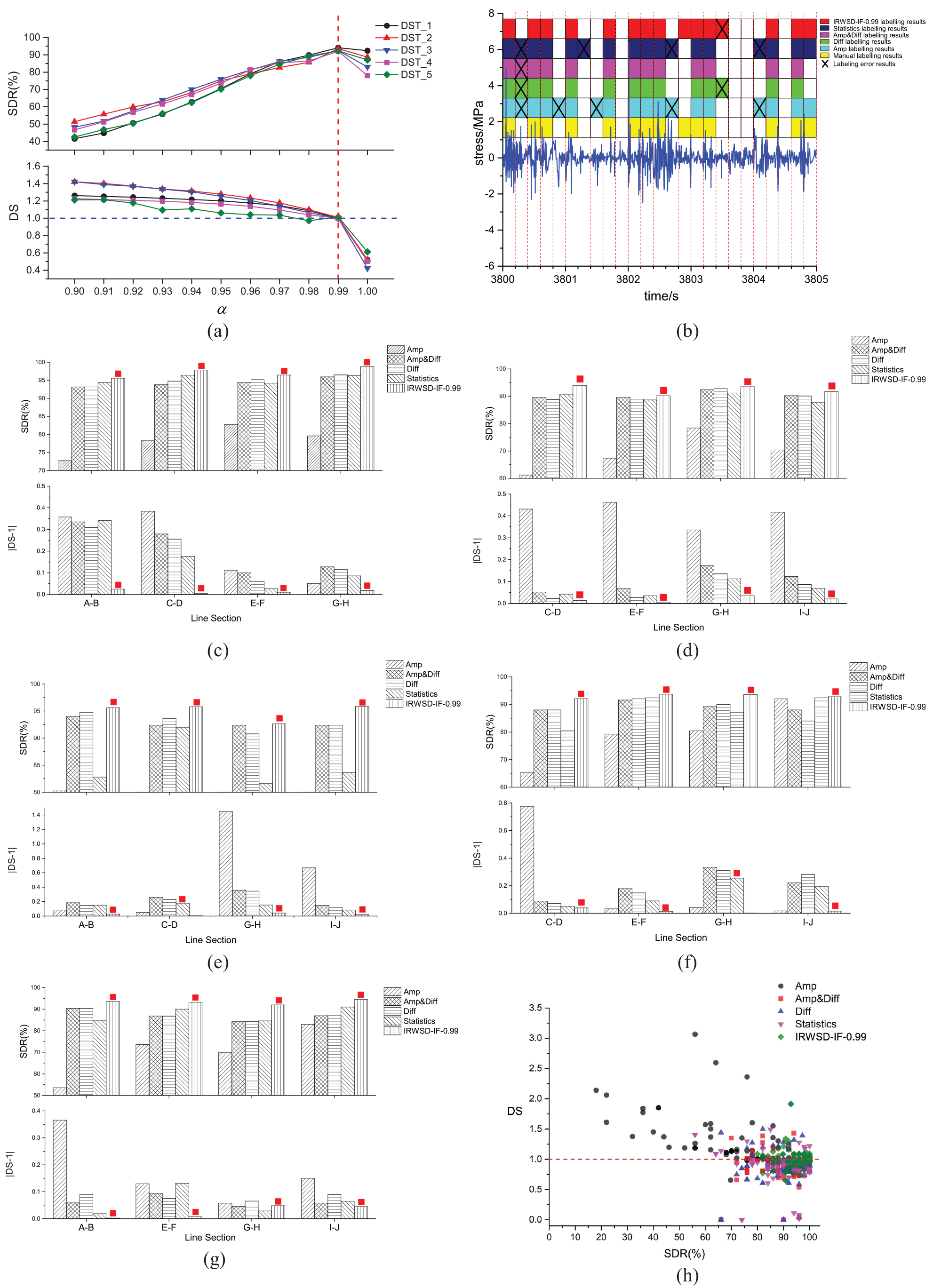
Experimental comparison results: (a) changes in evaluation indices at different values of
In Figure 7(a), the changes of SDR and DS of the detection model proposed in this paper are compared under different
Facing the large-scale task of dynamic stress signal spike detection for bogie frames, the four main methods in the literature 42 are commonly used as the core methods. Take a sample in DST_1 as an example, the results of different methods’ labeling are shown in Figure 7(b).
In Figure 7(b), the length of each detection unit is 0.2 s. The labeling results reflect the ability of different methods to continuously determine the signal spikes in the time series, and through comparison, it is found that the labeling results of the detection model proposed in this paper are the most consistent with those of manual labeling.
The results of the comparison of the average SDR and DS for different line sections in each dataset are shown in Figure 7(c)–(g).
The results presented in Figure 7(c)–(g) demonstrate that the detection model proposed in this paper achieves the highest SDR in different line sections across the five datasets. Additionally, it has been found that the DS of this model is closest to 1 when compared to other methods. The results of different line sections in the same dataset have been averaged and are provided in Table 3.
Comparison of spike detection methods in different datasets.

In Table 3, in terms of the SDR, the average SDR of the five methods are 74.53%, 90.80%, 90.80%, 89.21%, and 94.17%, respectively, and the model proposed in this paper has the highest SDR. In terms of DS, the average values of the five methods in different datasets are 1.32, 0.86, 0.89, 0.91, and 1.01, respectively. Among them, the average DS of the method in this paper is the closest to 1. The results indicate superior generalization across line sections for the proposed model in this paper.
In Figure 7(h), a correlation can be observed between two indices. When the SDR is higher, the DS is closer to 1. A higher SDR means that more signal spike points are detected and labeled, consequently, the frequency distribution of the stress spectrum block of rainflow counts after these spike points have been reconstructed is closer to the manual labeling process. Furthermore, when both detection methods have the same SDR, it means that the number of times and positions of the labels are the same in the same number of detection units, however, it is essential to measure the exact number of correctly labeled spike points in each detection unit with the help of the DS index.
In addition, the results of the comparison of the total computation time of different algorithms in each dataset are shown in Figure 8(a)–(e).

Comparison of the total computation time of different algorithms in each dataset, (a) comparison results in DST_1, (b) comparison results in DST_2, (c) comparison results in DST_3, (d) comparison results in DST_4, (e) comparison results in DST_5.
According to Figure 8(a)–(e), the total computation time of the model proposed in this paper is basically minimized in all the above five datasets. Among them, the evaluation indices are more time-consuming to compute compared to other datasets because DST_5 contains the most manual labeling results. On this dataset, the performance difference between the model proposed in this paper and the other models is the most obvious, and the efficiency is improved by about 16.7% compared with the other models, which indicates that the efficiency of spike detection and evaluation can be improved through the recursive complexity reduction and the acceleration of the linear time complexity of the isolation forest algorithm.
However, it should be pointed out that although the model proposed in this paper has a significant improvement in computation efficiency and spike detection accuracy compared to existing methods, the start point of the detection model kernel is the isolation forest algorithm. When the training samples contain a relatively dense signal spike, it will lead to deviations in the computation of the anomaly scores of the points, which will affect the distribution of the sequence of anomaly scores. In this case, the threshold needs to be optimized and adjusted again, and there is a certain degree of decline in computation efficiency. In addition, in the process of large-scale signal spike detection, the construction of isolation forests requires the establishment of a large number of iTrees, which is very easy to be limited by the maximum memory. Therefore, in future research work, we can take the lead in establishing a high-dimensional feature library of typical signal spikes and forming an apriori knowledge, use the apriori knowledge to correct the results of anomaly score computation, and at the same time, adopt incremental learning to construct and adjust the isolation forest, to reduce the computational resources and memory consumption.
Conclusions
This paper addresses the issue of signal spike detection in the dynamic stress monitoring of bogie frames. To solve this problem, a signal spike detection model based on isolation forest is proposed in this paper. The model effectively enhances the efficiency of signal spike detection and the accuracy of structural damage calculation.
In the data pre-processing stage, for the zero-drift problem in the original signal, this paper proposes a trend removal method (TRM) based on the assumption of segmented linear drift, which does not introduce signal oscillations, quantitatively describes the degree of zero drift, and combines iterative abort conditions to realize adaptive removal of zero-drift components.
In the signal spike detection stage, utilizing the difference between the instantaneous fluctuations of the signal spike region and the non-spike region, the IRWSD calculation in recursive form is proposed, which, combined with the monotonicity determination of the residual contribution function, effectively separates the signal spike region when the initial weight coefficients are less than or equal to 0.5, and at the same time, reduces the algorithm complexity from
Two indices, spike detection rate, and damage sensitivity, are constructed for evaluating the quality of signal spike detection. In the process, the half-sine reconstruction method (HSRM) is proposed to reconstruct the spike region, which has a continuous gradient and does not reintroduce a wide range of stress cycles compared to linear interpolation.
Finally, five datasets are constructed to compare the different detection methods with the field experimental data, and the results show that, compared with the existing methods, the detection model proposed in this paper improves the SDR by an average of 7.86%, and the DS by an average of 15.59%, which effectively improves the detection efficiency of the signal spikes, and ensures the accuracy of the subsequent structural damage evaluation.
Footnotes
Acknowledgements
The authors would appreciate the anonymous reviewers and the editor for their valuable comments.
Handling Editor: Tiago Alexandre Narciso da Silva
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by National Natural Science Foundation of China (No. 62277001, 61877002) and China Academy of Railway Sciences Fund Project (No. 2022YJ145).