
Abstract
This study developed a dynamic principal component analysis (PCA)-based algorithm for adaptive data detection. The algorithm employs suitable STs on the basis of various data to achieve high accuracy. The scree test (ST) has long been criticized for its subjectivity because no standard applies for retaining the correct number of components or factors when identifying various types of data. This article proposes a novel dynamic ST-based (STB) PCA method wherein a suitable ST is selected in using a support vector machine (SVM) for determining the correct number of components in data detection. The dynamic STB PCA can be employed as a solution to effectively detect various types of data. The proposed detection system can bridge the gap between input data and suitable STs for solving problems encountered when implementing data detection. The experimental results show that the STB PCA provides a ST-selection tool for automatically selecting the most suitable STs, and effectively detected various data using the STs. In the data detection, the proposed method outperforms existing PCA methods that do not consider suitable STs.
Introduction
Fault diagnosis is an inevitable situation and of significance in industry. Feature extraction for intelligent diagnosis has been the undergoing work 1 in industrial automation. Some existing adaptive techniques2,3 can be applied to feature extraction. For feature extraction, measurement-data extraction plays an important role in automated systems. The systems can be controlled effectively because of the reliable measurement data. Measurement data provide information about current testing conditions in product manufacturing. Such data contain various types of inputs (including outliers) in a data sequence for data processing. Outliers processing requires considerable time and causes poor manufacturing performance. The process through which outliers are removed before principal component analysis (PCA) is conducted is difficult. To solve this problem, a dynamic PCA-based algorithm is introduced for adaptive data detection. In the PCA, those factors, which have a significant part of the variance and a high eigenvalue, should be extracted. The scree test (ST) technique is usually used to select the factors for obtaining meaningful and interpretable results. This decision based on a visual inspection of the ST plot may be ambiguous and difficult for adaptive data detection or learning, although ST is a well-known method. Scree tests (STs) have long been criticized because no standards are followed for retaining the correct number of components when identifying various types of data. The dynamic algorithm employs suitable STs that correspond to inputs for detecting various types of data. Therefore, this paper aims to develop a computational inspection of the ST plot to make the data detection more valid, informative, and interpretable. Some approaches have been developed to make progress in data analysis recently. Among them, novel probabilistic model, 4 hybrid enhanced Monte Carlo simulation, 5 novel fuzzy reliability analysis, 6 and particle swarm optimization-based harmony search algorithm 7 can be applied to analyze the detection data. For data classification, the detection can exhibit high performance if an efficient and robust feature selection method is applied to a classifier. Support vector machine (SVM) is an appropriate data classification technique combined with the feature selection that discards noisy, irrelevant and reductant data, while still retaining the discriminating power of the data. 8 Our proposed algorithm uses a dynamic ST-based (STB) PCA method coupled with the SVM algorithm to select suitable STs to conduct in data detection. The STB learning algorithm learns and trains the data sequence and then establishes STs for identifying various types of data. The STs can retain the correct number of components for PCA and be applied to adaptively detect data corresponding to various inputs in a data sequence.
Studies have reported on various PCA methods for measurement and classification.9–11 In PCA-based methods, strategies are employed to select the number of principal components or factors to retain in PCA. The criteria of these approaches complicate the determination of the appropriate number of components to preserve. For example, two distinct strategies can produce different criteria from the same data. Therefore, we developed the STB-PCA method on the basis of the STB learning algorithm for retaining the correct number of components and detecting various types of data. The learning algorithm employs a dynamic STB scheme combined with the SVM in selecting suitable STs in PCA. The dynamic technique can learn and train input data sequences and establish suitable STs for retaining the correct number of components.
When applying these PCA techniques mentioned above, insufficient or incorrect number of components usually leads to poor performance or failure in data detection. It is important to determine how many correct components to retain in the PCA detection. The motivation of this work is that a dynamic STB method was proposed as a solution to effectively detect various types of data. The proposed method involves using a STB learning scheme to establish suitable STs corresponding to input data to implement the PCA detection. The contributions of the study are summarized as follows: The STB method can adaptively select suitable STs and effectively classify different data in PCA detection. The detection system can solve problems associated with using ambiguous standards on STs and establish suitable ST schemes corresponding to different inputs for detecting various types of data. Finally, the proposed approach can be employed as a ST-selection tool for automatically selecting the most suitable STs for PCA detection.
In this paper, the dynamic selection of suitable STs for feature extraction in PCA was presented to extract and train measurement data. After training the data, the data detection system that uses a STB PCA algorithm was designed and constructed to detect the air pollutant measurement data. Then an adaptive data detection was conducted with manufacturing and air pollution data as inputs, and was employed to test the performance and accuracy of the STB PCA method.
Regarding the organization of the remainder of this paper, Section 2 presents an overview of relevant studies. In Section 3, the proposed method for learning and training the input data sequence and retaining the correct number of components in PCA is described. In Section 4, the results obtained by using the STB PCA detection system are examined, and a quantitative comparison of the proposed method and existing PCA approaches is made. Conclusions are drawn in Section 5.
Related work
Researchers have widely applied PCA in the resolution of problems in measurement and engineering. 12 They also pointed out a PCA-based method that can reduce the dimensions of an input set, thereby eliminating noise from measurement data and compressing transient signals for increasing computational efficiency. 13 For example, Asadur Rahman et al. 14 reduced signal dimensionality and selected appropriate features according to inferences from t statistics under spatial PCA. The approach outperformed several methods in emotion recognition. For reduction of signal dimensionality, the selection of key parameters or features has been applied to PCA-based techniques. For example, Pandey and Yadav 15 optimized process parameters for vibration-assisted electrical discharge drilling by employing PCA-based gray relational analysis. Wang et al. 16 fused multidimensional features on the basis of PCA to comprehensively characterize the operation state of rolling bearings. Priyanka and Kumar 17 extracted and selected features of kidney ultrasound images by using the gray-level co-occurrence matrix combined with PCA. Zhang et al. 18 used supervised machine learning and PCA in determining canopy parameters essential to the mass mechanical harvesting of apples. In addition to the PCA-based techniques, several authors have proposed improvements to PCA-based detection and classification methods. Li and Huang 19 presented a combined method of cross-correlation and PCA-based outlier algorithm for detecting damage caused by random wave excitation to the structure of a jacket platform. Papandrea et al. 20 identified three levels of surface roughness by employing acoustic signals and support vector machine. Allegretta et al. 21 integrated machine learning algorithms and PCA with the use of a portable energy-dispersive X-ray fluorescence spectroscopy instrument to classify meteorites. De Stefano et al. 22 constructed on-board sensor classifiers to detect contaminants in water.
On the basis of the PCA literature examined thus far, researchers usually have to consider both feature selections and classification issues when applying PCA in resolving problems in measurement. Hence, for the selection of suitable STs, a dynamic STB PCA method that is combined with the SVM algorithm was developed. This approach is designed to identify various types of data in data detection. The use of STB PCA has not been explored for retaining the correct number of components in PCA for adaptive data detection. In our learning approach, the input data sequence can be trained to dynamically select criteria on the basis of which components are preserved in PCA by using suitable STs.
Proposed method
Dynamic STB PCA method
An SVM-based learning method was proposed for the dynamic selection of suitable STs for feature extraction through PCA. Figure 1 displays the framework of the STB PCA method. Using this approach, measurement data are extracted using PCA and the data sequence is trained through STB PCA feature extraction in accordance with the results of SVM classification. The steps of STB PCA extraction are outlined as the following sections.

Dynamic STB PCA method.
PCA and the dynamic STB selection scheme
The method was conducted using 25,920 samples of air-pollution data. Each sample in locations {A, B, C} had a corresponding data set consisting of hourly information on air quality index (AQI) and concentrations of PM2.5, PM10, O3, and CO (µg/m3) recorded over 1 year. About 720 data sets recorded over 1 month in a single location were randomly selected as training samples. Others are employed in dynamic STB selection for accuracy evaluation.
In PCA, eigenvalue decomposition is performed to extract data features. Specifically, this process produces eigenvalues and eigenvectors to represent the variation the features contain. Next, the vectors are projected into the principal component subspace. Moreover, a residual subspace is generated, which is used to detect the measurement data. The ST is conducted such that the optimal principal components can be identified. In the following, the steps of STB PCA selection are presented.
Step 1: Input the number of features (n) and the eigenvalues
Step 2: Operate STB selection in dynamically selecting a suitable ST for feature extraction by implementing the following steps: (1) Give k a value from 0 to 2. (2) Implement the ST scheme if k is 0; otherwise, implement the slope-based ST (SST) and weight-based ST (WST) schemes sequentially. (3) Process the eigenvalues, which are selected by the schemes, through indicator establishment and SVM classification.
For the ST scheme, the optimal factors can be obtained by combining the ST with the SVM. The ST is expressed as follows:

where Scr is a parameter for lowering the number of component factors and determining the optimal factors and
For the SST scheme, the slopes S1 and S2 are defined as follows:
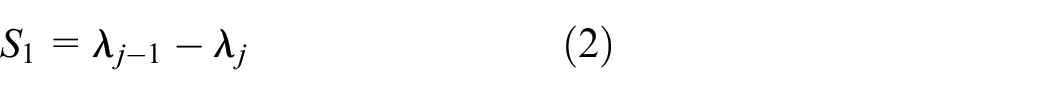

Next,

and

The optimal eigenvalues
For the WST scheme,

For
Next,

where the adjustable value ti in (7) corresponds to a sequential range between 0.01 and 0.99 (inclusive): {ti}={0.01, 0.02, 0.03, …, 0.99}, where i = 0, 1, 2, …98.
The new eigenvalues

where
And

Similarly, the ST scheme
STB PCA algorithm and SVM classification
Figure 2 illustrates the procedure of the STB PCA algorithm that combines STB selection with SVM to dynamically select suitable STs for adaptive data detection. Using this algorithm, the classification results can be obtained.

Flowchart of the STB PCA algorithm.
The STB PCA algorithm is described in terms of PCA and SVM. A previous study proposed a PCA/SVM-based method for identifying image features.
23
In the current study, a dynamic STB PCA was used and combined with SVM for data detection. The STB PCA contains original data, with rows and columns featuring m raw samples corresponding to n variable signals, respectively. The data matrix X (X

Exhibiting correlation, the covariance matrix C of matrix X is
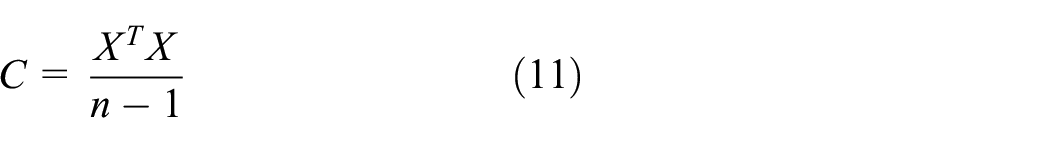
where X is the data matrix and n is the number of variable signals.
Next, C is subjected to eigenvalue decomposition. Projected into two subspaces, x can be expressed as

where xe and xr are the vectors of x projected into the principal component and residual subspace, respectively.
This results in xr being expressed as

where the load matrix
Correspondence is established between the column eigenvectors and the nonnegative real eigenvalues, which are arranged as

where n is the number of component factors. STB selection is then performed to select a suitable scree test (ST, SST, or WST) for feature extraction.
On the basis of STB selection, xr can be employed such that the test samples can be identified by indicator I, which is defined as

The hold-out procedure is employed by the SVM to determine the combination
24
: parameter C and radial basis function kernel parameter γ. The grid-search strategy is used to determine the two parameters in SVM. Wang et al.
25
suggested trying exponentially growing sequencies of C (2−5, 2−3, …, 215) and γ (2−15, 2−13, …, 23) to identify good input parameters when the grid-search method is adopted. The different exponential values of C and γ are given to determine the combination (Table 1). In this study, each sample class {A, B, C} had 8640 data sets in each run for training the SVM model. The training samples constituted 720 data sets, and the remainders were applied in classification accuracy assessment. Table 1 lists accuracy test for different combinations of the two parameters. The SVM model used the following combination: C = 29 and γ = 2−3 to obtain a high testing accuracy rate. The model with the combination was used for data detection because the classification outcomes would be optimal by using the proper parameter values in SVM.
26
For each training set, the eigenvalues
Testing accuracy for different combinations of parameter C and radial basis function kernel parameter γ, C (rows): value (5, …, 13) of log2C, γ (columns): value (1, …, −7) of log2γ.

Classification results obtained using the SVM for different ST schemes.

For adaptive data detection, the STB PCA algorithm applies the following steps:
Step 1: Input m samples and n features into the data sets X. Next, subject X to normalization (zero mean and unit variance).
Step 2: Subject the normalized X to PCA, thereby determining eigenvalues
Step 3: Perform STB selection in choosing a suitable ST for processing
Step 4: Establish the indicators I according to
Step 5: Classify I by using an SVM.
Step 6: Determine the accuracy rate, which is expressed as
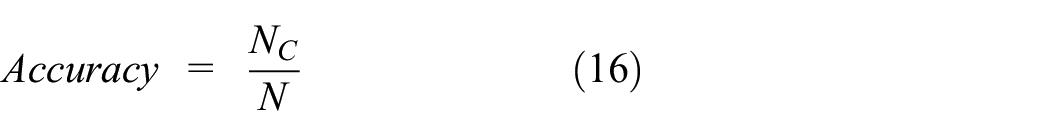
where NC is the number of sample classes in the test run that are correctly classified and N is the total number of test sets.
If the accuracy is greater than t [see (17)], then continue to step 7. If it does not exceed t, repeat steps 3–6.

where the threshold values THi are sequentially set to range from 0.84 to 0.99 (inclusive): {THi} = {0.84, 0.81, 0.82, …, 0.99}, where i = 0, 1, 2, …, 15.
Step 7: Terminate the process. Conduct a suitable ST such that the classification results can be obtained, including the optimal principal components. The algorithm stops when any class does not fulfill the condition in step 6.
Detection of data by using dynamic STB PCA
The design and construction of the adaptive data detection system are presented as follows. The system uses a STB PCA algorithm that combines STB selection with SVM classification to detect air pollutants (Figure 3). The air pollutants can result in the highest values of air quality index (AQI) in different locations. Table 3 lists the highest AQI values (denoted AQI*) detected in locations A, B, and C. Data detection was conducted using the following steps.
Input 25 920 samples from the air pollutant measurement data. 27 Each sample had a data set containing information on the AQI and concentrations of various air pollutions, namely PM2.5, PM10, O3, and CO (µg/m3), recorded hourly over 1 year in locations A, B, and C.
Detect the AQI* and the corresponding concentrations of PM2.5, PM10, O3, CO (µg/m3).
Pop the detection data set and perform PCA.
Obtain the eigenvalues of the air pollution concentrations and execute the STB selection scheme.
According to the results of suitable STs, develop indicators.
Classify the indicators on the basis of the database Ii by using an SVM.
Determine the location and determine the corresponding AQI* and feature pollutants.

Schematic of the steps taken by the detection system.
Highest AQI values (denoted AQI*) detected in locations A, B, and C. hj: time interval; j: {0, 1, 2, …, 23} represents {0–1, 1–2, 2–3, …, 23–24 h}.

The STB PCA detection system (Figure 3) enabled adaptive data detection through the dynamic selection of suitable STs from the STB PCA algorithm (steps 3–5). Using the proposed method, the AQI* and feature pollutants in various locations were detected (steps 6 and 7).
Experimental results and discussion
Adaptive data detection was conducted with manufacturing and air pollution data as inputs to assess the performance and accuracy of our dynamic STB PCA method. The STB-PCA algorithm was applied, and combines STB selection with SVM.
Adaptive detection of manufacturing data using the STB PCA method
The STB PCA method was applied to supercapacitor manufacturing data. As shown in Table 4, each supercapacitor sample class had 128 validation samples for data detection testing. To evaluate the qualifications of the sample classes, a life test was performed: (1) Using a 1-A current, charge the supercapacitor to 2.70 V. (2) Wait 15 s. (3) Using a 1-A current, discharge the supercapacitor to 1.35 V. (4) Wait 15 s. (5) Perform steps 1–4 again. In the cycle test, the capacitance (F) and equivalent series resistance (mΩ), denoted Cap and ESR, respectively, were determined. Changes in these values were expressed as △Cap (%) and △ESR (%), respectively.
Classes of supercapacitor samples used in data detection.

Results of the cycle test performed on the supercapacitor sample classes are displayed in Figure 4. The average values for the testing samples are denoted {Cap, ESR}. Difficulty was encountered in distinguishing between classes {A, B, C, D} by using the data. Figure 5 presents the ST results of {Cap, △Cap, ESR, △ESR} for classes {B, D}. By using the STB PCA method and the WST scheme, the eigenvalues of component factors {PC2} and {PC3} were differentiated. Under the STB PCA method, certain principal components and their corresponding indicators were obtained (Table 5). The optimal results were the principal components for pcj >1. Indicators Ii = {I0, I1, I2, I3} corresponded to the optimal principal components of classes {A, B, C, D}, namely {(pc3, pc4), (pc1, pc2, pc3, pc4), (pc2, pc3), (pc1, pc2, pc4)}. Accuracy rates calculated in the detection of classes {A, B, C, D} by using certain indicators are shown in Table 6. With the mean accuracy being 95%, classes {A, B, C, D} were distinguishable by the indicators.

Average (a) Cap and (b) ESR corresponding to classes {A, B, C, D} in the cycle test.

ST results for the classes {B, D} and {PC1, PC2, PC3, PC4}. {B, D}: class samples obtained using PCA and ST scheme. {B*, D*}: class samples obtained using the STB PCA method and WST scheme. {PC1, PC2, PC3, PC4}: component factors.
Principal components with indicators obtained using the STB PCA method. pcj: principal components; j: {1, 2, 3, 4} represents {Cap, △Cap, ESR, △ESR}, Ii (i = 0, 1, 2, 3): indicators for classes {A, B, C, D}.

Accuracy rates obtained using indicators {(pc3, pc4), (pc1, pc2, pc3, pc4), (pc2, pc3), (pc1, pc2, pc4)} to detect classes {A, B, C, D}. pcj: principal components; j: {1, 2, 3, 4} represents {Cap, △Cap, ESR, △ESR}.

In addition to the data detection, the method was applied to mechanical inspection. The visual inspection in the experimental setup 23 was conducted to test the performance and accuracy of the method. Table 7 lists the classes of eyeglass samples including 512 samples used for classifier training, and other 512 samples used for testing accuracy. For inspection, an eyeglass with unknown features was affixed to a target panel, and the target panel-telescope was 10.67 m. The STB PCA method was employed to detect the digital camera-captured telescopic image. The algorithm selected the scheme {WST} and employed the indicators Ii = {I0, I1, I2} (pcj >1) corresponded to {(pc1, pc2, pc3, pc4, pc5), (pc1, pc2, pc3, pc4, pc5), (pc1, pc2, pc3, pc4)} to classify classes {D, E, F} (Table 8). Statistical approaches based on ensemble method 28 and Bayes classifier 29 were used to analyze the experimental results of data detection and visual inspection respectively. The ensemble method is given by

where µj (x) is the confidence for each class. x is a given set of Ii. di,j(xRi) is the probability assigned by the building classifier Di. Ri is a rotation matrix of the features. L is the number of classifiers in the ensemble. c is the number of predicted classes. The unknown class can be identified as x assigned to the j class with the largest confidence. For Bayes classifier, the expression is given as follows

where x is a set of Ii derived from an unknown class. The mean vectors mj and covariance matrix Cj of the coefficients for the j class are then derived. The detection class can be recognized as the j class by minimizing the calculated value of D(x). The proposed method, in addition to attaining the highest accuracy rate in the data detection, exhibited superior classification performance in the visual inspection (Table 9).
Classes of eyeglass samples used in visual inspection.

Principal components with indicators obtained using the STB PCA method in visual inspection. pcj: principal components; Ii (i = 0, 1, 2): indicators for classes {E, F, G}.

Accuracy rates from the various methods in the experiments.

Detection system employing the STB PCA algorithm
The STB PCA algorithm was employed in assessing the performance and accuracy of the designed system (Figure 3). System evaluation was conducted using 25,920 samples of air-pollution data. Each sample in locations {A, B, C} had a corresponding data set consisting of hourly information on AQI and concentrations of PM2.5, PM10, O3, and CO (µg/m3) recorded over 1 year. As training samples, 720 data sets recorded over 1 month in a single location were randomly selected. System evaluation was conducted using the remainder.
AQI* data for {PM2.5, PM10, O3, CO} recorded in January, February, September, and October in locations {A, B, C} were subjected to a ST (Figure 6). For the data recorded in January and February (Figure 6(a) and (b)), the eigenvalues of component factor {PC2} could be differential from locations {A, B, C} by using the STB PCA algorithm. The algorithm selected the schemes {SST, WST} to distinguish between locations {A, B, C} for data recorded in {January, February}. Similarly, regarding the data recorded in September and October, the eigenvalues of component factor {PC2} were not distinguishable from locations {A, B, C}, as presented in Figure 6(c) and (d). The algorithm selected the schemes {SST, SST} to differentiate between locations {A, B, C} for the data recorded in {September, October}.

ST results of AQI* data recorded in (a) January, (b) February, (c) September, and (d) October in locations {A, B, C}. {PC1, PC2, PC3, PC4}: component factors.
Table 10 lists the principal components with the selected schemes and indicators obtained using the STB PCA algorithm. The algorithm selected the schemes {SST, WST, SST, SST} and employed the indicators Ii = {I0, I1, I2} (pcj >1) in {January, February, September, October} to classify locations {A, B, C}. The indicators Ii were {(pc1, pc4), (pc2, pc3, pc4), (pc3, pc4)}, {(pc1, pc3), (pc2, pc4), (pc1, pc3, pc4)}, {(pc3, pc4), (pc1, pc2), (pc1, pc2)}, and {(pc1, pc2), (pc3, pc4), (pc1, pc2)}. Furthermore, the algorithm used the selected scheme to detect the AQI* feature pollutants in the same locations (Table 11): {(PM2.5, CO), (PM10, O3, CO), (O3, CO)}, {(PM2.5, O3), (PM10, CO), (PM2.5, O3, CO)}, {(O3, CO), (PM2.5, PM10), (PM2.5, PM10)}, and {( PM2.5, PM10), (O3, CO), (PM2.5, PM10)}. The classification results of the 25 200 validation samples classified in locations A, B, and C are shown in Table 12. The mean accuracy was 95%, and the system used the algorithm to detect the samples (recorded hourly over 1 year). Due to the samples collected in only three locations, the performance of the classification model cannot be presented at all thresholds. For example, an ROC curve (receiver operating characteristic curve) can show the performance on a graph. This curve plots two parameters as (true positive rate, false positive rate). 30 In the study, (0.94, 0.023), (0.96, 0.025), and (0.95, 0.032) can be obtained by using the accuracy rate (equation (16)). To provide an aggregate information of performance across all possible classification thresholds, future works can employ the AUC (area under the ROC curve) 31 to measure the entire two-dimensional area underneath the entire ROC curve, and to evaluate the classification model when samples in more locations are collected. Figure 7 presents a quantitative comparison of the system when using various learning algorithms. System performance achieved with three learning algorithms, namely the self-organizing map (SOM), 32 backpropagation neural network (BPNN), 33 and K-nearest-neighbors (KNN), 34 respectively, was compared with that attained using our STB PCA approach. The procedures through which the algorithm parameters were selected are summarized as follows:
Principal components with the selected schemes and indicators obtained using the STB PCA algorithm. pcj: principal components; j: {1, 2, 3, 4} presents AQI* data {PM2.5, PM10, O3, CO}. Ii (i = 0, 1, 2): indicators for locations {A, B, C}.

AQI* feature pollutants detected in locations A, B, and C by using the selected schemes.

Classification results obtained using the STB PCA algorithm for classifying the air pollution samples in locations A, B, and C. T (rows): true values, P (columns): predicted values.


Accuracy rates (in percentages) for various learning algorithms: SOM, KNN, BPNN, and SVM.
(1) Convert the input data of {I0, I1, I2}. That is, the input vector, data set, and three neurons corresponding to {SOM, KNN, BPNN}. (2) Run the learning algorithms. The SOM network is trained using the Kohonen algorithm, 35 yielding an output layer consisting of three neurons ({A}, {B}, {C}). By taking a majority vote of the five nearest neighbors, the input data set is classified using the KNN algorithm. The class membership ({A}, {B}, {C}) constitutes the output layer. The BPNN trains a neural network with an input layer, hidden layer, and output layer containing three neurons, four neurons, and three neurons ({A}, {B}, {C}), respectively. (3) Obtain the accuracy rates corresponding to the output layers. For {SOM, KNN, BPNN, SVM}, they were 88%, 90%, 87%, and 95%, respectively. The results demonstrate that the proposed method has the highest accuracy. This is attributable to maximization of the distance between two classes within a feature space by the SVM. The performance of the BPNN on a certain issue depends on the data input. 36 The BPNN for detecting air pollutants may be sensitive to the input with noisy data and exhibits the worst performance. The computational complexity of learning algorithm was introduced in the experiment. 37 The amount of time necessary for an algorithm to complete binary searches is quantified by T(n). T(n) is given as
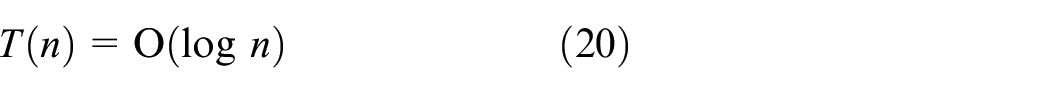
where O(log n) is the logarithmic time. The time that an algorithm requires for all inputs of size n is expressed in big O notation which excludes coefficients and lower-order terms. Using a time-cost function O(log n), the system evaluated various PCA-based methods, including the ST, SST, and WST schemes and the dynamic STB PCA approach. This function places a limit on the logarithmic time needed by a system for all n-sized inputs in big O notation. Moreover, it computes how much time an algorithm requires to execute binary search tree operations. The time-cost function and classification accuracy rates obtained are shown in Figure 8. The accuracy rate for our proposed method was highest among all PCA-based methods. For all the methods examined, the time-cost functions were lower than 45 μs. Overall, the dynamic STB PCA approach outperforms the ST, SST, and WST schemes.
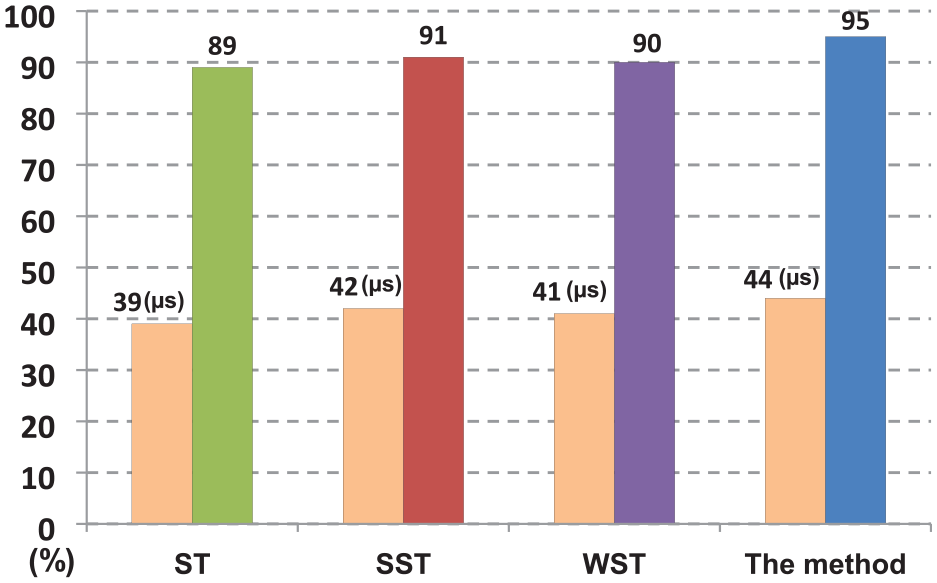
Comparison of algorithm performance under various PCA-based methods.
Conclusions
Herein, a dynamic STB PCA method was proposed for retaining the correct number of PCA components and for detecting various types of data. The proposed method was presented to improve PCA-technique performance when using insufficient or incorrect number of components. The proposed STB PCA learning algorithm employs a dynamic STB scheme combined with SVM for adaptive data detection, learning and training the input data sequence, and dynamically selects suitable STs through which the appropriate number of principal components was preserved. It is noted that the STB method provides suitable STs in PCA detection and improves the performance when classifying different data. The proposed detection system solves problems associated with using ambiguous standards on STs and effectively detects various types of data using the established suitable ST schemes. The results demonstrate that the designed system can successfully retain the correct number of PCA components, and adaptively detected manufacturing and air pollution data. The proposed method attained a data detection rate of 95%, 98%, and 95% for supercapacitor manufacturing data, visual inspection data, and air pollution data respectively. The proposed algorithm outperforms approaches in which ST, SST, and WST schemes are employed. To evaluate the classification model across all possible classification thresholds, further works on an aggregate measure of performance will be conducted based on the current study.
Footnotes
Appendix
Handling Editor: Chenhui Liang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part from National Kaohsiung University of Science and Technology.