
Abstract
In the textile industry, surface defects can greatly damage the value of fabric, but the coexistence of subtle defects and elongated defects poses a significant challenge to the localization of them. Existing convolutional neural networks-deep learning methods, especially the YOLO series, can present promising fabric defect detection. However, their performance is limited in simultaneously learning local and global features, leading to inaccurate localization results. To address this issue, this paper proposes a Fabric Defect Detection Network (FDDNet) based on Spatial Depth-Transforming Convolution (SDTC) and Multiscale Dilated Self-attention Fusion Module (MDSFM). Firstly, to enhance the local feature characterization capability of the backbone network, our FDDNet proposes spatial depth-transforming convolutions to preserve more fine-grained information. Subsequently, to effectively integrate global and local information and enhance global-local modeling capability, the multiscale dilated self-attention fusion module is introduced by combining self-attention mechanisms and dilated convolutions, thus enabling the model to percept scale changes and achieving multi-scale defect localization. Experiment results conducted on the publicly available Tianchi fabric dataset and a self-made denim dataset show that, the proposed FDDNet can achieve the AP50 of 54% and 56.8% respectively, which outperforms mainstream state-of-the-art methods.
Keywords
Introduction
The textile industry, as one of the traditional pillar industries in China, holds an important position in the national economy. With the improvement of people’s living standards and the intensifying of market competition, there is an increasing demand for high-quality textiles. Fabric defects (such as Loose warp, Thick bar, Flower of error, etc.) are one of the crucial factors affecting the quality of textile products, as illustrated in Figure 1. Fast and accurate detection of defects in fabrics is of great significance for improving product quality, reducing production costs and enhancing the enterprise competitiveness. Early fabric defect detection relies mainly on manual visual inspection, which is not only inefficient but also susceptible to the subjective influences of inspectors, making it challenging to ensure the accuracy and reliability of the inspection results. Furthermore, prolonged manual inspection can lead to inspector fatigue, which will further affect the detection quality. Therefore, developing an efficient, accurate, and automated fabric defect detection method has become an urgent issue in the textile industry.

Visualization of typical fabric defects in denim (a) and Tianchi (b) datasets.
Currently, most fabric defect detection methods are based on computer vision technologies, including traditional algorithms and deep learning algorithms. Traditional algorithms include spectral detection,1,2 mathematical statistics,3,4 image differencing, 5 image texture analysis, 6 etc. These traditional methods can only detect specific types of defects in simple textures, and are sensitive to noise and lack robustness. However, fabric defects often appear in multi-scale forms and the background textures are complex and diverse. Currently, fabric defect detection includes two specific challenges: (1) Small defects: as shown in Figure 1(a), these are defects of small size in the textile industry process with weak contrast, making it difficult to accurately differentiate them during detection. (2) Multi-scale defects: In the textile industry production process, defects of different scales coexist in the same surface, mainly in the form of points and lines. The coexistence of these subtle defects and elongated defects often leads to feature confusion or information loss, increasing the difficulty of detection, as shown in Figure 1. Therefore, it is a challenging and urgent task to solve the above two problems in fabric defect detection.
With the rapid development of computer technology and the enhancement of hardware processing capabilities, deep learning methods in computer vision have reached highly advanced levels in recent years. In the field of fabric defect detection, convolutional neural network (CNN) 7 -based detection methods have been proven to more effective in handling complex scenarios, gradually replacing traditional detection methods. To improve the defect detection accuracy, Li et al. 8 proposed FD-YOLOv5 as an enhancement over YOLOv5. By introducing a coordinate attention module in YOLOv5 to replace bottleneck structures, they improved the network’s feature extraction capabilities, enhancing the detection of small defects. Meanwhile, they utilized a smooth Mish activation function, SIoU loss function, as well as a combination of focal loss and GHM loss functions to address dataset sample imbalance issue. To enhance time efficiency, Zhao et al. 9 introduced the Dynamic Inference Network (DI-Net), which dynamically allocates computational resources based on image complexity. This network includes an “AND” gate control network module for adjusting network depth. The inference unit allows for early network exit under specific conditions to enhance efficiency. However, DI-Net is primarily suitable for plain textile designs, and its performance may degrade with complex textures and backgrounds, with limitations in extracting complex features and defect sample training. Moreover, Wan et al. 10 proposed the unsupervised high-frequency feature mapping model for fabric defect detection, addressing the challenges of a lack of labeled fabric images and difficulty in finding discriminative features. Despite its impressive performance, the uneven distribution of high-frequency information in defect areas may impact pixel-level segmentation. Additionally, the imbalance between foreground defects and background textures can affect the accuracy of detection and segmentation. Li et al. 11 introduced PEI-YOLOv5 for fabric defect detection, which incorporates the Particle Depth Convolution method to reduce redundant computations and memory access, thus improving detection speed and feature extraction efficiency. Through the Enhanced-BiFPN structure, they enhanced attention to spatial and channel feature mapping as well as the fusion of information at different scales. However, due to its lightweight design, PEI-YOLOv5 may have insufficient capabilities in detecting certain defects. To address the issue of weak feature representation in traditional autoencoders, Zhang et al. 12 proposed an unsupervised method called the Triple Attention Multi-Scale U-Shape Denoising Convolutional Autoencoder. By introducing a triple attention mechanism and using noisy defect-free samples during training to reconstruct and repair defective areas, they aimed to enhance the feature representation capability of the autoencoder. Nonetheless, there is still room for improvement in detection performance due to the limitations of convolutional neural networks in capturing long-range dependencies.
To address these issues, a Fabric Defect Detection method based on spatial depth-Transforming convolution and multiscale dilated self-attention fusion network, named FDDNet, is proposed in this paper. Specifically, the feature extraction backbone network is improved by using spatial depth-wise transforming convolution to replace the convolution downsampling layer. The spatial depth-wise transforming convolution can extract more fine-grained information, enabling the network to better detect small defects with low-contrast characteristics. Then, dilated convolutions and self-attention mechanism are combined to propose the multiscale dilated self-attention fusion network. The dilated convolutions can expand the receptive field without increasing the parameters, thus better capturing defect features of various sizes. The self-attention mechanism captures dependencies between global information and different regions, which enhance the ability to percept scale variations and further improve model performance.
Our contributions can be summarized as follows:
(1) We proposes a novel fabric defect detection method FDDNet, which can achieve the top performance on public and self-made datasets.
(2) The SDTC is proposed to enhance fine-grained feature extraction with lower computational cost, allowing better detection of small defects with low-contrast features.
(3) The MDSFM is proposed to enhance global-local modeling capability, highlight defects of different scales and improve multi-scale defect detection capability.
In the following paper, we first introduce related work on fabric defect detection, as well as a review of relevant technologies. Then, the proposed network is described in detail. Next, the experimental section provides a thorough validation of the feasibility of the proposed method. Finally, the conclusion of this paper is presented.
Related work
Fabric defect detection methods
In the field of fabric defect detection, many researchers have proposed various innovative methods and technologies. Lu et al. 13 introduced the texture-aware single-stage fabric defect detection network, which explicitly considers fabric texture during defect detection through defect texture recognition tasks. However, there are still undetected defects, especially long and thin linear structural features and small region-based defects. To address these issues, Lu et al. 14 proposed the channel-wise adaptive feature pyramid network, which integrates the anchor-free detection strategy AutoAssign to introduce a flexible anchor-free detector CA-AutoAssign. Zhao et al. 15 proposed a multi-scale feature fusion method based on attention to guide the model to focus more on defects rather than the background. Guo et al. 16 introduced a method that captures multi-scale information by using dilated convolution pooling and introduced the convolutional compression excitation module Wu et al. 17 proposed a lightweight network structure based on Faster R-CNN, utilizing dilated convolutions and multi-scale anchor boxes for fabric detection. Liu et al. 18 employed Generative Adversarial Networks to develop a fabric defect detection system capable of adapting to various fabric textures. Zeng et al. 19 introduced a reference-based defect detection network by incorporating template and context references. Lastly, Mo et al. 20 presented a weighted double low-rank decomposition method to preserve the most salient features of fabric images. The above studies collectively represent frontier work in the field of fabric defect detection, and provides important references and insights for related research and applications. However, the current methods still have considerable room for improvement in detecting small defects and elongated defects. This paper introduces a new fabric defect detection network, FDDNet, to further integrate global and local information and enhance perception of scale variations, thus achieving multi-scale defect localization.
Small object detection methods
Small object detection has always been a challenging task in object detection, especially in fabric defect detection. Existing small object detection methods tend to integrate well-designed strategies into state-of-the-art frameworks, and show outstanding performance in general object detection tasks. To address the issue of information loss about small objects as the network depth increases, Kong et al. 21 proposed a multi-scale fusion network HyperNet, that enhances object detection performance by combining shallow high-resolution features, deep semantic features and intermediate features. To solve the challenge of limited training samples for small objects, Zhang et al. 22 utilized partitioning and size functions to augment the dataset. RRNet 23 introduced an adaptive enhancement strategy called AdaResampling. CRANet 24 proposed an algorithm for adaptive search clustering regions. TridentNet 25 constructed a parallel multi-branch architecture where each branch has an optimal receptive field for objects of different scales. QueryDet 26 designed a cascaded query strategy to avoid redundant computation of low-level features, achieving efficient detection of small objects. To optimize detection efficiency and reduce computational costs, DS-GAN 27 proposed a novel data augmentation pipeline for generating high-quality synthetic data for small objects. Most small object detection methods often struggle to fully leverage contextual information around the target. Moreover, challenges such as the interference from complex backgrounds and the inadequate representation of tiny objects in images remain unresolved. In this paper, from the perspective of backbone network feature extraction, the STDC method is employed to enhance the feature extraction capability of the model for small defects.
Self-attention
The vanilla Vision Transformer28,29 has been successfully applied in various tasks such as natural language processing28,30 and visual tasks.31 –40 In Transformers used for visual tasks, self-attention is employed to aggregate extensive contextual features between image patches, where images are divided into multiple patches that are fed into the transformer. Currently, there are many methods that have been improved based on Transformers. For instance, CrossFormer 41 utilized different convolution operations or patch sizes to design patch embeddings. Parallel Transformers 42 employed multi-scale token aggregation to acquire keys and values of various sizes. MPViT 43 consisted of multi-scale patch embeddings and multi-path Transformers blocks. Conformer, 44 Mobile-Former 45 and ViTAE 33 incorporated additional convolution branches inside and outside the self-attention block to integrate multi-scale information. The aforementioned methods require intricate designs, which inevitably introduces additional parameters and computational costs. While the proposed MDSFM extracts multi-scale features by setting different dilated rates, which can offer a simple approach without the need for introducing extra parameters and computational costs.
Proposed network
In this section, the proposed fabric defect detection network FDDNet based on SDTC and MDSFM is detailed introduced. As shown in Figure 2, it consists of a backbone network, a neck network, and multiple detection heads. The backbone network uses spatial depth-transforming convolution for downsampling feature extraction, thus generating three different-level feature maps (P5, P4, P3) on the backbone. Subsequently, through the multiscale dilated self-attention fusion network in the neck network, Feature Pyramid Network (FPN) first enhances multi-scale representation by transferring high-level semantic features, and then Path Aggregation Network (PAN) combines the bottom-level localization information to the high-level using dilated self-attention mechanism, thus obtaining discriminative feature maps at different scales (N3, N4, N5). Then, based on the feature maps N3, N4, N5, three detection heads are derived for defect localization and classification of three scales, thus enhancing the multi-scale defect detection capability.

The overall framework diagram of FDDNet.
Enhanced backbone
The object detection algorithms usually start by extracting multi-scale features of input images. Thus, its structure directly affects the quality of feature extraction and has a great impact on the detection results. YOLOv8 is widely used in the field of object detection due to its effectiveness and efficiency, which mainly consists of five basic versions: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x, with the network depth increasing in sequence. As the number of network layers increases, the network also has more potential for feature representation, but the model efficiency decreases. And, when training data is limited, deeper networks may lead to overfitting, thus reducing the defection performance. In the textile factory, the number of fabric defect images is usually small, and these images mainly exhibit low-level texture features and contain less deep semantic information. Moreover, there is often a requirement for real-time performance in practical applications. Therefore, DarkNet53 of YOLOv8n is chosen as the backbone network, due to the optimum balance between performance and efficiency. The specific network structure of the enhanced backbone DarkNet53 is shown in Table 1. It can be seen that the enhanced DarkNet53 similarly comprises five stages. In the Stage 1, besides the one convolutional layer from the original DarkNet53, it also includes the proposed SDTC to extract more detailed and intricate information. Meanwhile, building upon the original model, the proposed SDTC has been incorporated into Stages 2, 3, 4 and 5 to merge feature maps of different stages. The last feature map of Stages 3, 4 and 5 is used as the input for the neck network, named P3, P4 and P5. These feature maps have different resolutions, and preserve local features and semantic information at different hierarchical levels, which is conducive to detecting defects of different scales.
The specific structure of the enhanced DarkNet53.

s means the image size.
Spatial depth-transforming convolution (SDTC)
Currently, although CNN-based fabric defect detection algorithms have achieved outstanding results, there are often limitations in handling small targets due to inaccurate extraction and information loss. To address this issue, the proposed SDTC serves as a substitute for traditional convolution, functioning as a pivotal component within the backbone network to extract more intricate and detailed features. The structure of the spatial depth transforming convolution is shown in Figure 3. A spatial-to-depth transformation is applied on the feature map X (with a size of S×S×C1) through slicing operations on the feature map, resulting in a series of sub-feature maps that can be represented as:

where

The specific process of SDTC: (b and c): Implement equidistant sampling of feature maps (a). (c and d): Implement spatial-to-depth transformation. (d and e): Use point convolution to merge features from different channels.
Then, these sub-feature maps are concatenated along the channel dimension to obtain the feature map
Next, after transforming the feature map
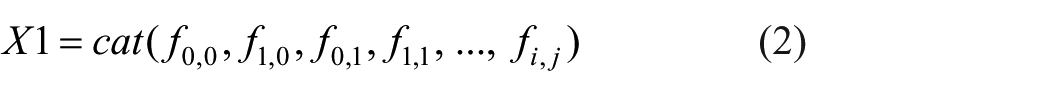
Finally, the 1 × 1 convolutions are used to compress the channel dimension of feature map X1–C2, thus enhancing information interaction and reducing model computation. This non-stride convolution is able to preserve as much discriminative feature information as possible, thus allowing the model to learn more fine-grained information.
Multiscale dilated self-attention fusion module (MDSFM)
The feature maps generated from different stages of the backbone network have varying resolutions. High-resolution feature maps contain more local detailed information and richer fine-grained details. As the resolution decreases, the information encapsulated in the feature maps becomes more abstract and semantic. Therefore, for the defect detection across varying size, both local detailed information and global semantic information are required. To achieve this, MDSFM is designed to merge feature maps of different scales, thus enhancing the multi-scale defect detection capability. Based on the FPN, we aggregate information from feature maps with different resolution sizes to enrich their fine-grained and high-level semantic information. Subsequently, employing PAN, we design a MDSFM that combines dilated convolutions and attention mechanisms to capture context semantic dependencies at different scales. The feature maps generated by MDSFM contain rich fine-grained information and high-level semantic features, further enhancing the model multi-scale detection capability. The following section will provide a detailed introduction of the MDSFM.
As shown in Figure 4, the feature maps P3, P4, P5 output by the backbone network are input to the MDSFM. Firstly, the Feature Pyramid Network achieves top-down multiscale information fusion, producing feature maps P′5, P′4, P′3. Subsequently, the bottom-up pyramid results from PAN pass the strong localization features of the lower layers and gradually fuse multiscale features to obtain output feature maps (N3, N4, N5). In addition, as shown in Figure 4, before obtaining the output feature maps, the multiscale dilated self-attention is used for multiscale information aggregation. The proposed multiscale dilated self-attention module applies a local attention mechanism to the feature maps and utilizes varying dilated rates to capture defect information at different scales within a local context, which can enhance the model ability to learn multiscale object information. The specific design structure of our MDS is depicted in Figure 5. Firstly, the channels of the feature map are divided into multiple heads. Then, a self-attention operation is performed between the colored patches around the red query patch and the window patches, using different dilated rates for different heads. Additionally, the features from different heads are concatenated together and then fed into a linear layer. By default, a kernel size of 3×3 and dilated rates r = 1, 2, 3, 4 are used. In this way, the effective receptive field sizes for different heads are 3×3, 5×5, 7×7, and 9×9 respectively. Specifically, the output feature vector of MDS can be expressed as:

where Q, K and V denote the tensors of query, key and value respectively and r controls the local scope of the self-attention mechanism.

The specific structural of the MDSFM.

Illustration of multiscale dilated self-attention.
By controlling the dilated rate
Experiment
Experimental settings
All experiments in this study are conducted on a server running the Ubuntu operating system. The CPU model is AMD EPYC 7H12 64-Core Processor and the GPU used is NVIDIA A100. During training, the SGD optimizer with a weight decay of 0.0005 is adopted for model optimization, and the initial learning rate is set to 0.01. The entire training process is composed of 300 epochs with an initial batch size of 32. The input images are uniformly resized to 640 × 640.
Experimental dataset
The Alibaba cloud Tianchi fabric dataset and a self-built denim fabric dataset are used for model training and testing. The Alibaba Cloud Tianchi Fabric Dataset is created and released by the Alibaba Tianchi Competition Team in 2019 at the Nanhai Textile Factory in Foshan, China. This dataset contains 5913 images, with 5413 images for training and 500 images for testing. Each image has a resolution of 2446×1000 and includes 34 defect categories, encompassing various small defect points such as Kont head, Broken spandex, Capillus, as well as longer and thinner defects like Check Jump, Wavy crotch, Double Welf, among others. In the self-built denim dataset, 8000 images are adopted for training and the remaining 1000 images for testing. The resolution of each image is 3072×2048, all taken from the denim production line of a textile company in Foshan, Guangdong. The defect types in the self-built dataset mainly include Nep, Cotton kernels, Warp knot, Loose warp, Thick bar, Flower of error, Strain Barre, etc. The variable scale of surface defects makes it challenging for accurate defection.
Evaluation metrics
Six common object detection evaluation metrics are employed to assess the model performance, including precision, recall, mean average precision (mAP), model parameters (Params), theoretical computational complexity (FLOPs) and frames per second (FPS). Precision refers to the proportion of samples that the model identifies as positive correctly. Recall is the proportion of actual positive samples that the model correctly identifies as positive. Average precision (AP) is the area under the precision-recall curve and mAP is the average of the AP values for all tested classes. These metrics are defined by the following formulas:


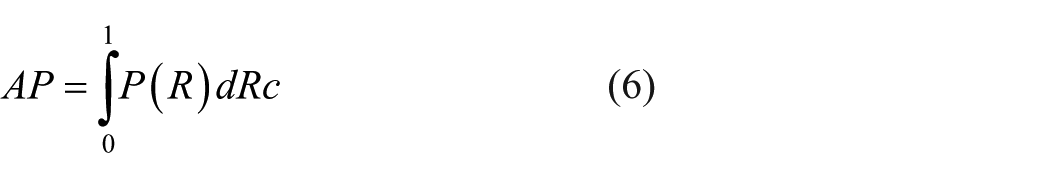

Experimental results
To verify the rationality of the scale parameter in the SDTC module, we evaluated different settings (1, 2, 3, 4) on the Tianchi dataset. Table 2 show that scale = 2 achieves the highest mAP of 26.0%, outperforming scale = 1 by about 2%. Increasing the scale beyond 2 leads to a consistent decline in mAP, AP50, Precision and Recall, with scale = 4 dropping to 22.1%. This demonstrates that too small a scale restricts feature representation, while an excessively large scale introduces redundancy and weakens detail extraction. Therefore, scale = 2 is adopted as the final configuration in this study.
Results under different scale settings on the Tianchi dataset (%).

Performance comparison of MDSFM with different parameters on Tianchi dataset (%).

Note. The bold entries mean the best performance.
Next, to validate the contribution of each component in our FDDNet, a series of ablation experiences are conducted on the Tianchi dataset. We take YOLO v8n as the baseline model, and integrate one component upon the baseline at a time, that is, SDTC and MDSFM.As shown in Table 4, when applying SDTC to the baseline, the mAP and AP50 increase by 2% and 0.8%, respectively. Using MDSFM alone result in an increase of 3.2% in mAP and 7.6% in AP50. When combined with SDTC and MDSFM, the best performance is achieved, with mAP and AP50 reaching 27.9% and 54%, respectively. The above results represent an improvement of 3.9% and 7.8% over the baseline.
Performance comparison of ablation experiments on the Tianchi dataset (%).


Visualization of Typical Fabric Defects and Feature Maps. (a) Displays typical fabric defects. (b and c) Show the visualized feature maps obtained by YOLOv8n and our FDDNet, respectively. It can be observed that the defect features extracted by FDDNet are more prominent and easier to distinguish.

Visualization comparison of different models on the Tianchi dataset (a-f).
The YOLO series models are widely used in industrial inspection due to their high precision and efficiency. To further validate the superiority of our algorithm, we conducted comparisons with other models within the YOLO series, as well as some other mainstream models. As shown in Table 5, our FDDNet performs the best among all YOLO models. The mAP and AP50 are 27.9% and 54%, respectively, which obviously surpasses the second-best YOLOv8s in the YOLO series by 0.5% and 3.1%.
Performance comparison of different models on the Tianchi dataset (%).

Note. The bold entries mean the best performance.
Performance demonstration of the model under different parameter settings on the denim dataset (%).

Note. The bold entries mean the best performance.
Demonstration of ablation experiments on the denim dataset (%).


Visualization heatmap demonstration of typical features on the denim dataset. Here (a) represents the original image, while (b and c) depict the feature heatmaps obtained by YOLOv8n and FDDNet, respectively.
To further illustrate the superiority of the proposed method in this paper, we conducted comparative experiments using other lightweight YOLO models and several mainstream models on our self-built dataset, as shown in Table 8. The performance of the proposed network in terms of the mAP metric is the best, with a value of 31.2%, which is 2.2% higher than the baseline YOLOv8n network. This improvement is attributed to the enhanced model’s detection capabilities for small and elongated defects. Of note, while the AP50 metric of YOLOv8s reaches the same value of 56.8% as our method, considering its model size and computational complexity, the proposed model remains optimal.
Comparison demonstration of different models on the denim dataset (%).

Note. The bold entries mean the best performance.
Subsequently, a visual comparison of the detection results between the proposed method and other methods is conducted to validate the effectiveness of FDDNet on the denim dataset, with representative sample images shown in Figure 9. The results clearly indicate that our FDDNet outperforms the baseline network YOLOv8n in both the classification and localization of defect regions. This advantage is particularly pronounced in cases where the contrast is weak and the defect regions are tiny and elongated. 54

Visualization comparison on the demin dataset.
Efficiency analysis
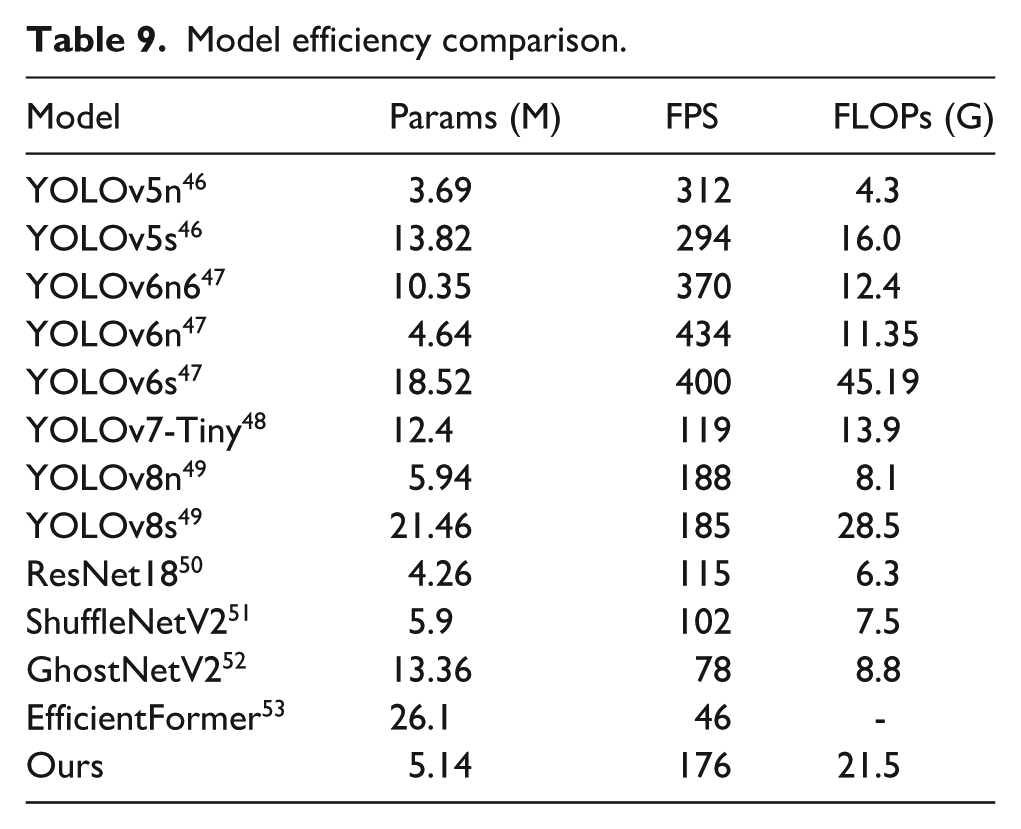
Apart from the above analysis on model accuracy, model efficiency is also a crucial factor in assessing algorithm performance, especially in the textile industry where production speeds are high. Therefore, FLOPs, parameters, and FPS are employed to compare the model efficiency of our FDDNet with other models. As shown in Table 9, the proposed model has 5.14M parameters, ranking just behind YOLOv5n and YOLOv6n, making it highly lightweight and suitable for online deployment. In terms of detection speed, although our method may not be the fastest, it still achieves an FPS of 176, which can meet the requirements for real-time detection. Additionally, the FLOPs of 21.5G are slightly lower compared to YOLOv6s and YOLOv8s. Consequently, the proposed algorithm achieves a good balance between efficiency and accuracy, making it more suitable for practical applications.
Model efficiency comparison.
Model generalization analysis
To further verify the generalization performance of the proposed method, in addition to the experiments conducted on the denim dataset, supplementary comparisons with the baseline method YOLOv8n were carried out on the ZJULEAPER 58 (patterned fabric) dataset. Since the original annotations of this dataset are in segmentation format, they were first converted into YOLO-compatible detection labels. A total of 14,233 images were selected for the training set and 4,742 images for the test set, with the experimental settings kept consistent with those used on the denim dataset. As shown in Table 10, the proposed method outperforms YOLOv8n by 3.8% and 0.5% in terms of mAP and AP50, respectively. Moreover, the visualization results in Figure 10 demonstrate that FDDNet exhibits stronger defect recognition capability. In summary, the proposed method can better adapt to the feature variations of different types of fabrics, shows strong generalization ability, and has the potential to be applied to diverse fabric defect detection tasks in complex production environments.
Performance demonstration of FDDNet on the ZJULEAPER dataset (%).

Note. The bold entries mean the best performance.

The performance demonstration of FDDNet and YOLOv8n (baseline) on the ZJULEAPER dataset.
Limitations
Although the proposed method demonstrates promising results in fabric defect detection, there are certain limitations that need to be addressed in future work. One key limitation is the reliance on a fixed set of feature extraction techniques, which may not be optimal for capturing all defect types, particularly in fabrics with highly variable textures. This can limit the model’s ability to generalize across diverse defect types and fabric materials. Additionally, the method may face challenges in handling rare or unseen defect patterns due to the limited diversity of the training data, which can impact its performance on less common defect types. Moreover, factors such as lighting conditions, fabric texture, and image noise can affect the robustness of the model in real-world applications. To improve detection accuracy in the future, several methodologies could be explored. Multi-source information fusion 55 and image representation 56 offer techniques for combining diverse data sources, which could enhance the performance of defect detection. Additionally, latent features and graph neural networks 57 could be used to model complex relationships and incorporate additional information, leading to improved detection accuracy. Finally, self-paced semi-supervised learning 58 addresses the common challenge of limited labeled data, and its integration could enhance the model’s performance in scenarios where labeled data is scarce.
Conclusion
In the textile industry, the coexistence of subtle defects and elongated defects poses a significant challenge to fabric defect defection. This paper introduces a novel fabric defect detection model FDDNet, which leverages SDTC and MDSFM to enhance defect feature characterization capabilities and multi-scale defect localization performance. FDDNet successfully overcomes the limitations of traditional methods in learning local and global features, resulting in more accurate defect localization. The STDC enhances local feature characterization by preserving fine-grained information, which aids in the accurate identification of subtle fabric defects and elongated defects. The MDSFM effectively integrates global and local information through a combination of self-attention mechanisms and dilated convolutions, which enables the model to adapt to scale variations and enhance multi-scale defect localization. Experimental results show that on both the public Tianchi fabric dataset and a self-made denim dataset, FDDNet demonstrates significant advantages over mainstream methods, outperforming the baseline model by 3.9% and 2.2% in mAP values, respectively.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by NSFC (No.62472463, 61873293, 62301623), Leading talents of science and technology in the Central Plain of China (234200510009), Henan Key Research and Development Projects (241111220700), China National Textile and Apparel Council Technology Guiding Projects (2025055, 2025010).