
Abstract
Fabric image retrieval, a form of content based image retrieval, is a high value research with the potential to be applied in many fields, such as e-commerce and inventory management. However, this research hotspot is plagued by two major challenges, namely the high requirements for retrieval results and the peculiarities of fabric images. Unlike general image retrieval, fabric image retrieval systems have to pay more attention to texture and color features. To address these challenges, we propose a novel framework for fabric retrieval by using self-supervised and deep hashing techniques. The framework consists of two modules for feature learning and hashing learning. During the feature learning phase, the color and texture information in the image is decoupled under the drive of augmented based pretext tasks. In hashing learning, Bi-half layer is introduced to generate high-quality hash codes. The visualization results indicate that the proposed method performs well for the representation of fabric images. And the experimental results show that the proposed retrieval framework can achieve a good performance (best mAP 0.903) and outperforms other methods, including several deep hashing methods and our previous work.
Introduction
In order to cater to the rapidly changing needs of the fast fashion industry, the textile industry had evolved to favor a variety of fabric designs produced in small bulk, instead of the mass production of a single type fabric. This production mode has caused the textile industry to accumulate an extensive catalog of historical designs, making it increasingly difficult to search for similar fabric designs. The traditional method of finding and comparing fabric from a huge and ever-growing catalog is both time-consuming and labor-intensive, which can be alleviated with a Content-based Image Retrieval (CBIR) system.
When receiving a query image, the CBIR system is expected to output a list with the same visual content as the query. Technically speaking, there are two core components of CBIR: image representation and feature matching respectively. Image representation vectorizes the input images (queries and the images in the database), and the second component ranks the images in the database for similarity and outputs similar images. The most challenging task in CBIR is to associate pixel-based low-level features with human-perceived high-level semantic features. In many previous works,1 –3 some hand-crafted feature descriptors are often used to represent the visual content of images, such as Scale Invariant Feature Transform (SIFT),4 –6 Local Binary Pattern (LBP),7 –9 Global Image Structure (GIST).10 –12 Even though these pixel-level feature-based methods have achieved some success, they rely too much on feature engineering, which leads to their limitations in robustness. Recently Convolutional Neural Networks (CNN) have achieved outstanding performance in many vision tasks, such as image classification, object detection, which demonstrate its good performance in a visual feature description. Naturally, many researchers applied CNN model in image retrieval tasks. CBIR has achieved a significant breakthrough due to the replacement of earlier low-level feature-based algorithms with an end-to-end framework based on deep learning. Inspired by this trend, this study focuses on the use of deep CNN to solve the problem of fabric retrieval. Krizhevsky et al. 13 directly used the output of the convolutional layer in CNN as index for image retrieval, and its excellent retrieval performance demonstrated the superiority of deep CNN for image retrieval. However, the disadvantage of this method is in its high computational cost, which resulted in a long retrieval time.
To optimize retrieval efficiency, many feature dimensionality reduction methods have been introduced, of which the most commonly used approach is Approximate Nearest Neighbor (ANNS) search. Deep hashing is an emerging and efficient ANN search method designed to automatically learn optimal hash functions and generate image hash codes. Nearest neighbors are obtained by computing the Hamming distance of these hash codes. Recently, several deep CNN based deep hashing, that is, Convolutional Neural Networks Hashing (CNNH), 14 Central Similarity Quantization (CSQ), 15 Deep Supervised Discrete Hashing (DSDH), 16 have been proposed to improve image retrieval significantly.
Textile or fabric images do not contain rich discriminant features, like 3-D shapes, prevalent in natural images. Instead, fabric images are texture and color features are the dominant features, as shown in Figure 1. This difference in feature types is the reason why general image retrieval algorithm is ill-suited for fabric retrieval. To make matters worse, fabric images lack distinct objects that can be annotated. Take Figure 1(a) as an example, the mother swan and the baby swan can clearly identifiable, compared to Figure 1(b) where no distinct object can be annotated. Many previous research11,17 –20 represented the fabric images using low-level hand-crafted feature descriptors and achieved a good performance on fabric image retrieval. However, the success of handcrafted methods is limited to small dataset or specific fabric type. Our previous work21,22 tried to used annotation information (single-view and multi-view) to guide the model to learn fabric image representation. However, because the retrieval results are limited to the annotation classification, the proposed methods are difficult to apply in the textile industry. To address this problem, this paper proposed a novel deep learning framework which can simultaneously learn the texture and color representation of fabrics by using self-supervised learning. Self-supervision is a learning framework in which supervised signals for pretext tasks are automatically created in an effort to learn representations useful for solving real-world downstream tasks in an unsupervised manner.

General image and fabric image: (a) general natural image and (b) fabric image.
The motivation for designing the fabric retrieval framework come from two aspects: (1) Color and texture are the main features in the fabric images, and decoupling these two features can improve retrieval performance and robustness; (2) Rotation and scaling only slightly change the period the texture in the fabric images, while its structure is not changed. However, adjusting the hue of the image color can change the color type, as shown in Figure 3 below. In summary, this fabric retrieval framework is designed to take full advantage of the dominant feature types available in fabric images, while enforcing strict rotation and scale invariant.
The rest of this paper is organized as follows. Section II introduces the main technical components involved in this paper. Section III presents the experimental setup configuration, including introduction of the used dataset, evaluation metrics, comparison methods, and implementation details. Section IV analyzes and discusses the experimental results. Conclusion is presented in Section V.
Fabric image representation
Unlike general image retrieval, fabric image retrieval systems have to pay more attention to texture and color features. In this section, we propose a fabric image representation framework based on self-supervised learning with designed pretext tasks. The framework consists of three main components: image transformation, Convolutional Neural Network, and learning algorithm, as illustrated in Figure 2.

The overview of the proposed fabric representation framework. The framework consists of three main components: image transformation, Convolutional Neural Network, and learning algorithm. When receiving an input image I, first perform texture transformation and color transformation on I, and then input it into CNN for nonlinear transformation, and finally the parameters of the model are optimized under the supervision of the objective function.
Notations
Let
Fabric image augmentation
Since color and texture are the main features of fabric images, we consider two type of transformations for fabric image augmentation, color transformation and texture transformation, as illustrated in Figure 3. Generally, fabric retrieval systems are expected to output results with high similarity in texture, regardless of scale and rotation. So we adopt two type texture transformations: (1) crop the fabric image first and then resize cropped sample to a fixed size, as shown in Figure 3(b); (2) rotate the fabric image within a certain range first and then crop a fixed-size sample, as shown in Figure 3(c).

Fabric data augmentation. (a) Original image. (b) Crop-based augmentation. (c) Rotation-based augmentation. (d)–(f) Color-jitter-based augmentation.
However, the fabric is very sensitive to color. Due to the limitations of the commonly used RGB color space, the results of color transformation in this color space are often uncontrollable. HSV is closer to human perception of color than RGB. The hue in HSV is an important reference for many color classifications, as is the color feature classification of textile fabrics. This study considers three levels of color transformation by adjusting the hue
Feature learning
In the training phase of CNN, data augmentation is a trick commonly used to improve the generalization ability of target network by exploiting certain transformations that preserve its semantics, such as cropping, contrast enhancement, rotation, and flipping. The training objective
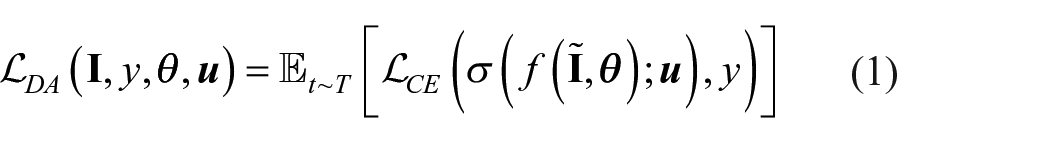
where T is the transformed distribution of data augmentation. The classifier
Our idea is to remove the unnecessary transformations and just use two type of transformations. The model, learns texture representation by using the invariance of the texture transformation to supervise the model, learns color representation by using the variance of the color transformation. The proposed feature learning model is called as SDA. We expect the trained model is invariant to subtle texture changes and is sensitive to drastic color changes. Then, the training objective can be written as
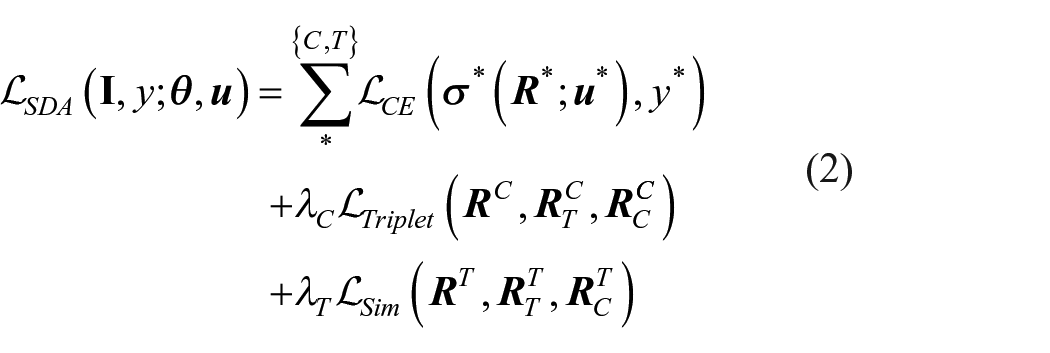
where


And the
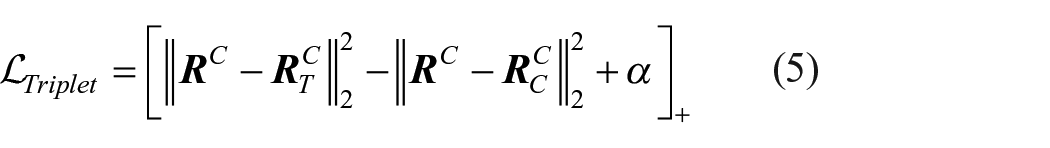
Here we use Euclidean distance to measure the distance between representations and set the margin
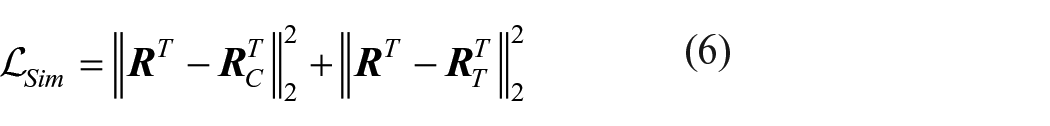
Then, we introduce a multi-loss collaborative gradient descent optimization for the above problem. In this work, the parameters, which need to be learned, contain the parameters

The partial derivative of the objective function for the parameters of neural network can be computed by:

There are six types of
The strong performance of CNN in feature learning has been demonstrated, so a compact CNN is designed as the base network in this study, as shown in Figure 4. To enhance the performance, the joint learning of multiple tasks adopts a parameter soft-sharing framework. It is well known that the larger the number of parameters, the more data is required. Therefore, we only intercept the first three convolution-pooling modules of VGG16 for visual feature abstraction, and their parameters are initialized with models pre-trained on ImageNet dataset. The motivation and rationale for this choice is that the dataset used has a relatively small number of fabric images and that training deep networks from scratch on this dataset is very sensitive to overfitting. However, an effective way to reduce data requirements is to use a pretrained model and reduce its depth. Furthermore, fabric images mainly consist of textures and colors. It has been proved that low-level features, that is, colors and textures, also appear in natural images and can be extracted by the first several layers of a convolutional neural network which is trained on natural images (ImageNet). On the other hand, features from deep layers capture more semantically relevant abstract features, so deep layers trained on natural image datasets may not be able to accurately represent fabric images. The architecture of the adopted CNN is presented in Figure 4. The trained model received a fabric image with the size of w×h and then output two feature embeddings: color feature embedding

The architecture of adopted CNN. We use a shadow CNN, which is intercepted from the first few layers of VGG-16, for fabric image representation. The reason for using this configuration is that the low-level features of the image often appear in the shallow layer of the CNN network.
Deep hashing for feature aggregation
The function of above proposed feature learning model is to extract the color feature embedding and texture feature embedding for fabric image representation. Generally, the high-dimensional feature directly used for retrieval will greatly increase the computational cost, thereby reducing the retrieval efficiency. Hashing is very efficient in terms of computation and storage. It converts original images features into compact binary codes by preserving the data structure in the original space. The transition from the continuous variable

where g is the hashing function and K is the length of the binary codes. Recently, Li et al. 24 presented a new parameter-free network layer which can minimize the optimal transport cost measured by the Wasserstein distance. Here we briefly introduce the principle of this method and how to graft it in our framework.
The principle of bi-half layer

where the maximum is taken over all possible input distributions p(r) and I(R;B) denotes mutual information between continuous variable U and binary variable B.

where

where
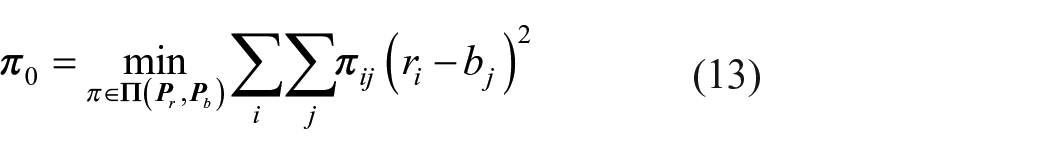
where

The idea is implemented as a new simple hash coding layer called bi-half layer which can be embedded into many architectures to generate binary codes. During training, the forward propagation and back propagation are concluded as:

where
The framework of hashing model
We graft the bi-half layer into our hashing model, as shown in Figure 5. The architecture of the hashing model consists of three layers: input



For the optimization, we adopt stochastic gradient descent algorithm to optimize hashing model. The hash model is trained in an unsupervised manner (also called self-supervised).

The framework of Hashing Model.
Experimental configuration
Dataset
Driven by the target task, learning-based methods learns and induces representation methods from data, so data is the basis for deep learning model learning. Besides, a standard dataset is also an indispensable component for evaluating the retrieval performance of different methods. In this study, a fabric image dataset named MFT-fabric-v1 is built. Specifically, the proposed dataset consists of 46,868 Mélange fabric (Mélange fabrics are directly woven from Mélange yarns without dyeing or printing. And Mélange yarn is made of two or more different color fibers which are spun after fully mixing, therefore creating a unique mixed color effect. http://www.e-huafu.com/) images as the training-set, and 3672 Mélange fabric images as testing-set. Also, all images in the dataset are annotated from three different viewpoints, namely color, texture, raw materials. This work mainly focuses on color and texture of fabric, so the raw material label of the fabric is ignored. The color of Mélange fabric is defined as the color of the special colored yarn or fiber (other than the basic color, such as white and black). This definition may cause the general hand-crafted based methods to be difficult to represent the color of Mélange fabrics. So this paper proposes to use the deep learning based method to describe the feature of Mélange fabric. According to this definition, there are a total of nine colors of Mélange fabric in the dataset, namely grey (8232), red (5241), orange (3928), yellow (5096), brown (6315), green (4751), blue (6894), purple (2867), and colorful grey (3544). With respect to texture, we divide the weft-knitted fabric into six levels (VOL47: 6593; VOL48: 6796; VOL49: 6729; VOL50: 8924; VOL51: 7939; VOL52: 9887) based on the thickness and weight of the yarn used. The testing-set contains a total of 72 sets (different sets of images belong to different categories) of Mélange fabric images, each of which consists of a query and 50 related images corresponding to it. To evaluate the robustness of the retrieval methods, the 72 queries are augmented with some transformations: rotation, flipping, and scaling. Each query image is expended to 10. To avoid the influence of capture conditions, the images in MFT-fabric-v1 are collected in a stable environment stable light box. The DigiEye system is equipped with a Nikon D7000 camera, a special pick-up head and a standard illumination D65, which has the advantages of small color difference and stable condition. Also, the resolution of collected images is 96 dpi.
Evaluation metrics
In this work, two metrics are used to evaluate the retrieval performance of different methods, namely, precision-recall curve and mAP (Mean Average Precision) value. To compute their value, it is necessary to introduce some definition of TP (true positive), FN (false negative), FP (false positive), and TN (true negative). As shown in Table 1, TP refers to the number of relevant images retrieved; FN refers to the number of relevant images not retrieved; FP refers to the number of non-relevant images incorrectly retrieved as relevant; TN refers to the number of non-relevant images correctly retrieved as non-relevant. Then the precision and recall of retrieval results are defined as:


mAP is the mean of average precision (AP), which can be calculated by:
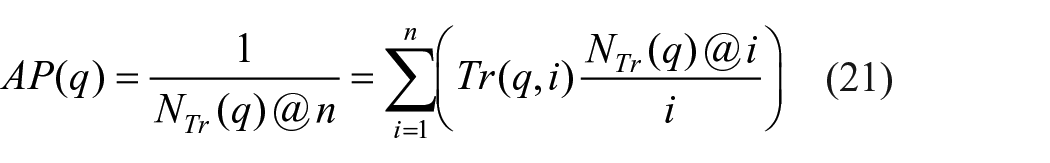

where

The definition of TP (true positive), FN (false negative), FP (false positive), and TN (true negative).

In evaluation, two images are considered semantically similar if they have the same annotation. For the two evaluation metrics used in this work, a larger area under the precision-recall curve and a larger mAP indicate better retrieval performance.
Implementation details
To avoid overfitting, the model pre-trained VGG16 on ImageNet is used to initialize the previous Convolutional layers of proposed model. The two hyperparameters,

where lrn is the learning_rate of the nth epoch and N is the total number of epochs configured. a denotes the starting epoch where the learning rate begins to decay.
With respect to the 3-layer hashing model, we simply adopt the following configuration: learning_rate = 1e-4 (fixed), weight_decay = 4e-5, optimizer = SGD. The proposed framework is implemented with the Pytorch (https://www.pytorch.org/) toolkit. To make fair comparison, all the compared methods are reimplemented by using Pytorch toolkit and based on the bone of VGG16. The hardware environment is as follows: CPU: E5-2623 V4@2.60GHz, RAM: 32G, GPU: GeForce RTX 3090 (24G).
Experimental results
The performance of fabric image representation
To demonstrate the effectiveness of the proposed framework for fabric image representation, we first visualize the extracted high-dimensional features by using T-SNE, which is unsupervised method. The trained feature learning model output two feature embeddings: color feature embedding

The visualization results of feature learning: (a) the representation effect of color features, (b) the representation effect of texture features formed by different organizational structures, (c) the representation effect of binarization color features, and (d) the representation effect of binarization texture features.
Then we visualize the binary codes (
Ablation experiments
In this section, we do some ablation experiments to verify the rationality of our model configuration, including MTL 21 + Bi-half layer (general multi-task learning framework + Bi-half layer), SDA + Sign layer (the proposed feature learning framework + Linear layer with Tanh + Sign layer). In addition, we also test the robustness of these configurations by evaluating the mAP on two testing-set: 72 queries and augmented queries (mentioned in Section 4.1).
Table 2 presents the ablation experimental results with different code-length (16, 32, 64, 128, 256). MLT + Bi-half adopt a multi-task learning framework to learn fabric image representation. It can achieve good performance on the 72-original-query testing-set, but it performs poorly on the augmented testing-set (a decrease of 0.138). This phenomenon shows that the MLT model is sensitive to rotation and scale, and then leads to its weak robustness. Comparing MLT + Bi-half and SDA + Sign, their performance on the 72-original-query testing-set is not much different, but there is a big gap in the augmented testing-set. This is exactly the result of the improved performance of the proposed SDA model for model generalization. When combining proposed SDA model and Bi-half layer, retrieval performance is improved to a certain extent. It is demonstrated that the Bi-half layer can automatically generate higher quality binary codes and the proposed SDA can improve retrieval performance.
Ablation experiments on MFT-fabric-v1.
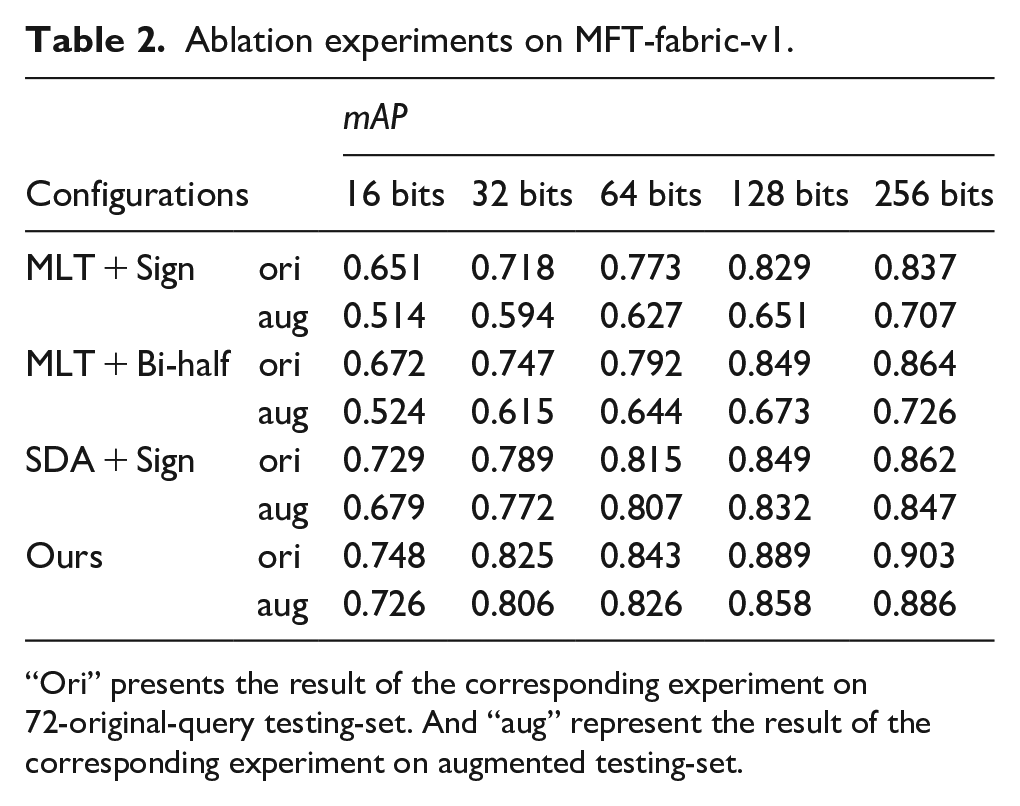
“Ori” presents the result of the corresponding experiment on 72-original-query testing-set. And “aug” represent the result of the corresponding experiment on augmented testing-set.
Comparisons and retrieval performance
In this section, we conduct comparative experiments with 10 state-of-the-art methods, including three unsupervised hashing methods, three supervised hashing methods, and four methods for fabric image retrieval. The mAP values of all method with various hash code length, including 16 bits, 32 bits, 64 bits, 128 bits, and 256 bits, are presented in Table 3. All experiments are all conducted on MFT-fabric-v1 dataset, and retrieval performances are all evaluated in 72-original-query testing-set and augmented-query testing-set.
mAP comparison results on MFT-fabric-v1 dataset.

The best result in each column is marked with bold. The three grids below the header present the results of three different types of methods, in order supervised methods, unsupervised methods, fabric image retrieval methods.
To make fair comparison, we employ VGG-16 network as the stem of all deep-learning based methods. With respect to implementation of three supervised deep hashing method, including CNNH, 14 DPSH 26 and CSQ, 15 we also apply the framework based on soft parameter sharing to build the feature learning network, then use the hashing method proposed by the authors to learn hash code from each view. It is stated here that the pairwise matrix S is generated by using the fabric annotations of each view. The three unsupervised hashing method, including UHBDNN, 27 SSDH 28 and SADH, 29 are all implemented by using pytorch according to the corresponding paper, and then trained on MFT-fabric-v1 dataset. We also compare with our previous work, FRHS 22 and FRMT, 21 on fabric retrieval. In addition, the two hand-crafted descriptor based fabric retrieval methods, CMGF 11 and MRI-LBP, 19 are implemented by using Matlab tools.
Table 3 presents the mAP comparison results on MFT-fabric-v1 dataset. It can be observed that, the retrieval method proposed in this paper achieves the best performance under different code lengths, especially in augmented testing-set. For example, when we set the code length to 128 bits, the proposed retrieval method achieves the mAP value of 0.889 in 72-original-query testing-set and 0.858 in augmented testing-set, which surpasses other comparison methods. And the results clearly demonstrate the superiority of the proposed method. In addition, we observe that the performance of all comparison methods improves as the code length increase from 16 bits to 256 bits. This phenomenon indicates that longer hash codes can bring more discriminative in most deep hashing model. Furthermore, when comparing the results on 72-original-query testing-set and augmented testing-set, there is a big difference in the performance of most methods. For example, CSQ can achieve a mAP value of 0.834 with a code length of 64 bits in the former testing-set, but it can only achieve a performance of 0.727 in the latter testing-set. However, the proposed method can achieve superior performance in both testing-sets, which demonstrates that the proposed feature learning model (SDA) has high robustness and generalization. The two hand-crafted descriptor based methods also have a certain degree of robustness, but due to the limitations of feature engineering, there performance on our dataset is poor. Finally, we clearly find that the supervised methods perform better than the unsupervised methods on MFT-fabric-v1 for fabric image retrieval.
In Figure 7, we present the precision-recall curves of the compared methods (learning based) on the two testing-sets. In the results, the area under the curve corresponding to the proposed method is larger than the curve corresponding to other methods, indicating that the retrieval performance of our method is better than other methods. Moreover, the results in Figure 7(b) again verify the robustness and generalization of our method. In Figure 8, We also present five retrieval examples using our method, in which retrieval results and queries are very similar in color and texture.
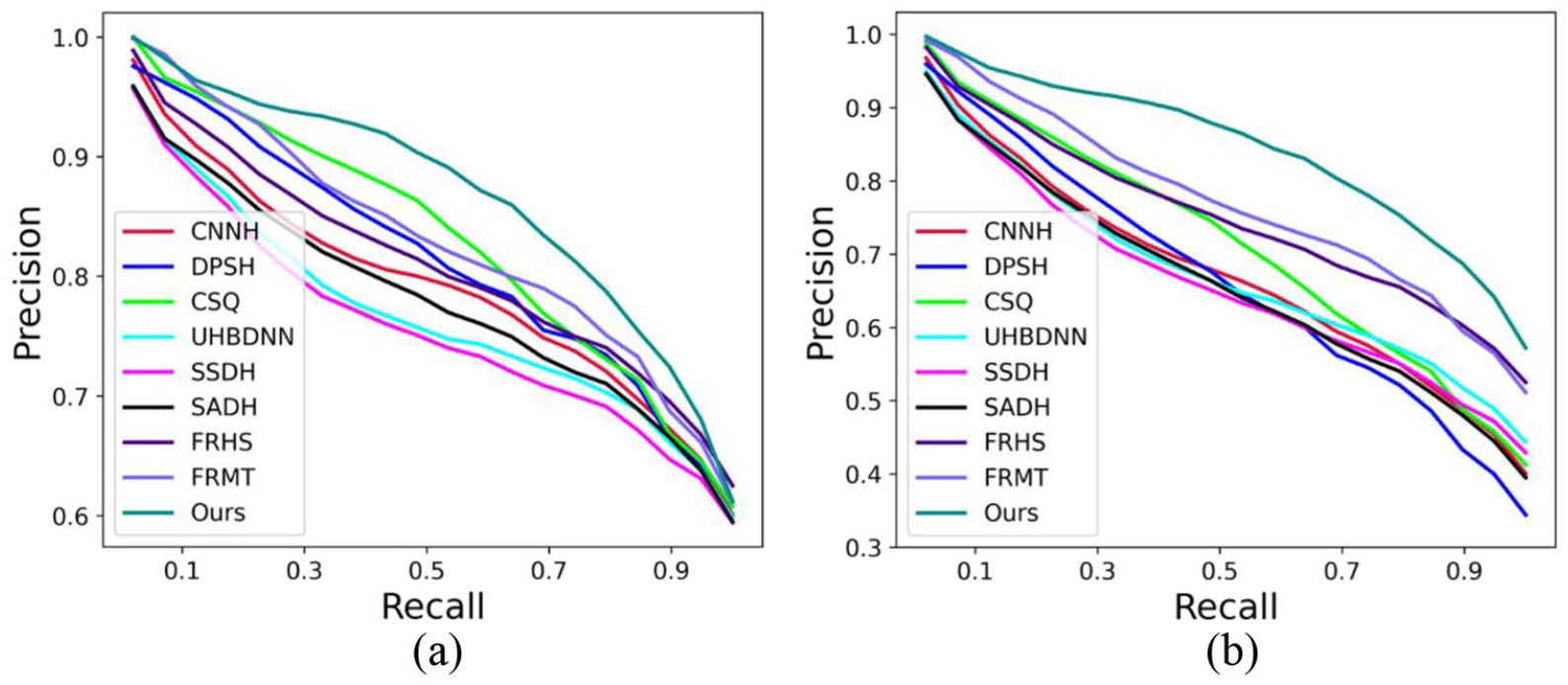
The Precision-Recall curve of the comparison methods on 72-original-query testing-set and augmented testing-set: (a) the PR curve on 72-original-query testing-set and (b) the PR curve on augmented testing-set.

Retrieval results of five samples.
Conclusion
In this paper, we present an efficient fabric retrieval framework based on our previous work. Texture and color are the main features in fabric images (2D). The proposed framework consists of two modules: feature learning and hashing learning. We try to decouple the color information and texture information in the image during feature learning. Decoupled task is driven in a self-supervised manner through several pretext tasks. There are two type of transformations used in this study, texture transformation (rotation and scaling) and color transformation (color jitter), respectively. Then we introduce a Bi-half layer for hashing learning. The visualization results of trained features and hash codes indicate that the proposed method performs well for the representation of fabric images. Experimental results demonstrate that our method outperforms other methods for fabric image retrieval with the best best mAP 0.903. In real applications, our method can be deployed on the information management platforms of fabric manufacturing or trading companies. Based on the given or provided fabric samples, it provides customers, engineers, or salespersons with similar historical fabric variety search, improving the efficiency of production design and trade interaction.
The proposed framework is suitable for most types of fabrics, due to its consideration of the common issues in fabric image representation: color and texture. However, for a broader range of fabric types beyond Mélange fabrics, additional validation is still required. In further research, we plan to collaborate with more textile manufacturing and trading companies to collect more images of different types of fabrics, and based on this, conduct more in-depth research and improvement on the universality of the fabric image retrieval framework.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors gratefully acknowledge the financial support from the National Natural Science Foundation of China ([grant number 62202202]), the Natural Science Foundation of Jiangsu Province ([grant number BK20221061]) and the Fundamental Research Funds for the Central Universities ([grant number JUSRP121030]).