
Abstract
Fabric image retrieval, a special case in Content Based Image Retrieval, has high potential application value in many fields. Compared with common image retrieval, fabric image retrieval has high requirements for results. To address the actual needs of the industry for Mélange fabric retrieval, we propose a novel framework for efficient and accurate fabric retrieval. We first introduce a quantified similarity definition, soft similarity, to measure the fine-grained pairwise similarity and design a CNN for fabric image representation. An objective function, which consists of three losses: soft similarity loss for preserving the similarity, cross-entropy loss for image representation, and quantization loss for controlling the quality of hash code, is used to drive the learning of the model. Experimental results demonstrate that the proposed method can not only achieve effective feature learning and hashing learning, but also effectively work on smaller datasets. Comparative experiments illustrate that the proposed method outperforms the compared methods.
Introduction
Mélange fabric, also known as color-spun fabric, 1 is a fabric directly woven from Mélange yarns, in which Mélange yarns are made by fully mixing two or more fibers of different colors to have a unique color mixing effect. However, its proofing process is extremely complicated. When the textile company receives a fabric sample from the customer, the company first needs to repeat the proofing and comparison, which is a very time-consuming and laborious task. In this study, we propose to use image retrieval technology to reduce the times of proofing. The specific steps are: (1) First establish the database of images of historical production products; (2) When receiving samples from customers, use the images of the samples to retrieval similar historical production products; (3) Analyze the production process of similar products to guide proofing process. This is the main motivation for this research. Besides, with the improvement of people’s living standards, consumer demands for goods is no longer limited to its practical performance, but tends to be beautiful and diversified. Therefore, the “small-batch and multi-variety” has increasingly become a new production mode for the textile industry. Under this mode of production, companies have accumulated a large amount of historical production data, which make the search task more difficult. Image retrieval plays a very important role in product search work, the key to this idea is how to establish an accurate retrieval system.
The Keywords Based Image Retrieval (KBIR) system1,2 is often used for product management in the textile industry. However, the KBIR system used in the textile industry builds indexes for fabric images through manually annotated keywords and users search for relevant fabrics through the annotated keywords. Although this system has the characteristics of high retrieval speed and easy construction, the search method can provide limited functions. Moreover, manual labeling of fabric images is also highly subjective, leading to instability of retrieval results, and further leading to the inefficiency and inaccuracy of KBIR. As the characteristics of Mélange fabrics are difficult to describe, the use of KBIR technology cannot solve our problem.
On the contrary, the Content-Based Image Retrieval (CBIR) system3–7 is more objective. Many researchers in this field have also shifted their research8–16 focus to CBIR. Compared with KBIR, CBIR uses image content to index images, which can avoid the influence of human subjectivity on the result. Image retrieval methods have gone through significant development in the last decade, starting with descriptors based on hand-crafted features, first organized in Bag-of-Words (BoWs), 17 and further expanded by spatial verification, 18 hamming embedding, 19 and query expansion. 20 Generally, a CBIR system is expected to output the list of images similar of related to the query. Technically speaking, the CBIR system consists of two key issues, namely image representation, and similarity measurement. The first phase converts the image into a vector and the second phase measures the similarity between the query and the images from the dataset. The traditional methods usually employ hand-crafted descriptors, such as SIFT, 21 GIST, 22 etc., to represent the feature of the image. Although having achieved certain success, these methods depend heavily on feature engineering, which leads to their limitation.
Recently, a significant breakthrough has been achieved on image analysis by moving from the early hand-crafted feature based methods to deep learning based end-to-end framework. Even though, the most challenging issue is still associating the pixel-level feature to high-level semantic feature from human perception, which is called “semantic gap.” Nowadays, the Convolutional Neural Network (CNN) based methods have been proved to be the most effective. Krizhevsky et al. 23 first used a CNN model driven by classification task to extract image features for retrieval and achieved good performance on ImageNet. Recently, many methods of jointly learning image representations and similarity metrics or distances have been proposed, which can be seamlessly used for retrieval. Specifically, these methods use metric learning embedding to train CNN. There are two simple but effective methods for metric learning: pair embedding and triplet embedding. Both methods learn the similarity by bringing samples with same labels closer to each other, and pulling samples with different labels apart. These discriminative model can learning semantically meaningful metrics while learning the image representation. Therefore, these methods are more robust inter-class confusion and intra-class changes.
Fabric image retrieval, as a special case of generic image retrieval, is a meaningful issue, due to its potential values in many areas, such as textile product design, e-commerce, and inventory management. However, due to the particularity of the fabric itself, the commonly used retrieval methods are difficult to directly apply to fabric retrieval. The main reason is that textile fabric images do not contain 3-D shape features, but only contain texture and color features. As shown in Figure 1, we present a natural image and two Mélange fabric images. In Figure 1(a), we can clearly observe a black swan with obvious outline and shape. While Figure 1(b) and (c) present two fabric samples with no obvious 3D shape or contour information. Comparing Figure 1(d) to (f), we can find a huge difference in periodicity and texture complexity between the fabric and natural images. Because of the fundamental differences, retrieval methods suitable for general images may perform poorly for fabric images.

A natural image and two Mélange Fabric images: (a) natural image, (b and c) two fabric images, (d) the spectrogram of image shown in (a), (e) the spectrogram of image shown in (b), and (f) the spectrogram of image shown in (c).
The main features in fabric images are color and texture, which are all global features. The goal of fabric image retrieval is to find fabrics with similar textures, colors, and materials. However, the pairwise and triple embedding methods crudely define images with completely similar labels as positive samples, and all others as negative samples, which seems to be unfair to those samples with partially similar labels. Furthermore, these approaches ignore the relationship between labels, and some information will be lost during model training.
In this paper, we propose a novel embedding method, which can easily be unified into a CNN for joint optimization. In particular, the proposed method aims to learn the similarity from fabric images with multi-dimensional labels. The contributions of this work mainly include:
For fabric images rich in color and texture features, we propose to use the output of shallow layers of VGG to represent fabric image content;
A more fine-grained similarity is defined to measure the similarity between fabric images with multi-label. To embed fine-grained similarity in the output features, we propose to use covariance to facilitate the model to learn the similarity matrix between the mini-batch input;
We formulate an end-to-end deep hashing model which can generate high-quality hash codes for fabric image retrieval.
The rest of this paper is organized as follows. Section 2 reviews the related works. Section 3 introduces the proposed framework in detail. The results and discussion are presented in Section 4. And Section 5 concludes the whole works.
Related works
According to different technical components, there are two topics most relevant to this research, namely fabric image retrieval and similarity learning. The two topics will be reviewed in this section.
Fabric image retrieval
Fabric image retrieval pays more attention to color and texture features, while more shape and contour features in common retrieval algorithms. According to the different feature extraction mechanisms, the previous works of fabric image retrieval can be divided into two categories: hand-crafted based methods and learning based methods.
Hand-crafted based methods commonly adopt pixel-level descriptors, such as image color histogram (CM), Scale-Invariant Feature Transform (SIFT) keypoint descriptor, Histogram of Oriented Gradient (HoG) descriptor, Color Moment (CM), and Local Binary Pattern (LBP) 24 to fabric images. However, most traditional methods use a combination of two or more feature descriptors to represent fabric images. Jing et al.9,10 proposed two methods for fabric image retrieval, both of which combine color and texture features to describe the image. Recently, Zhang et al. 14 tried to combine LBP and Fourier Transform to extract features of fabric images for retrieval. In follow-up research, 13 they also used to describe the fabric completely using color feature descriptors, namely dominant color and color moment. Tadi Bani and Fekri-Ershad 25 proposed a image retrieval method based on a combination of texture and color feature. Although achieving certain success, these methods are limited to small datasets. Moreover, the small jitters in scale or details have a great impact on the retrieval results, which demonstrates the less robustness of these methods.
Learning-based methods have been demonstrated to have stronger generalization performance when labeled data is available. Some previous works14,16,26 have used classification tasks to driven CNN models to learn fabric image representation. Xiang et al., 14 proposed a two-strategy with the idea that deep CNN can learn binary codes and features from the labeled data. And Xiang et al. 16 presented a multi-task learning model to learn fabric image representation from four views: coarse texture, fine texture, fabric style, and pattern forming method respectively. In addition, Cai et al. 27 used a Triplet-CNN to learning fabric image representation under similarity metrics in a supervised manner. Deng et al. 11 proposed an embedding method called focus ranking for fabric image retrieval. Although the previous works can achieve good performance on relatively large datasets. However, when there is not enough labeled data to train the CNN model, these methods may not work well.
Similarity learning
Similarity learning, also called distance metric learning, plays an important role in many visual tasks, such as face recognition and image retrieval. Xing et al. 28 proposed to learn a similarity metric from a given example of similar pairs, and the experimental results proved that the learned distance metric can significantly improve clustering performance. Mignon and Jurie, 29 proposed a novel similarity learning method, which is based on sparse pair constraints. Recently, the successful application of deep learning in various fields has inspired researchers to use neural network models to solve similarity learning problems.
Then, we review the recent works related to our work, concerning deep similarity learning. Hu et al. 30 proposed a novel similarity learning method based on a discriminative deep CNN for face verification in the wild. Bell and Bala 31 proposed a contrast embedding method to learn the depth metric of visual search in interior design. Chen et al. 32 proposed a novel similarity learning approach, which is combined with space constraint, for person re-identification. Pinheiro 33 proposed a neural network model fur unsupervised domain adaption using a similarity-based classifier. Kordopatis-Zilos et al. 34 presented a network that learns to compute the similarity between pairs of videos. Recently, deep hashing methods have shown great retrieval accuracy and efficiency in image retrieval. The key of hashing methods is to preserve similarity35–37 into the generated hash codes. Wu et al. 38 presented a novel unsupervised deep video hashing for fast large-scale similarity search, which integrates feature learning and hash function learning in a self-taught manner. To reduce the information loss in hash code generation, many researchers introduce quantization loss.39–41 Miao et al. 42 proposed a bottom-up learning strategy, termed Adversarial Constraint Module, where low-coupling binary codes are introduced to guide the learning of binary local descriptors.
As mentioned in Section 1, there are two embedding methods related to our study, namely pair43,44 and triplet45–47 embedding. The two methods push the samples with the same label closer to each other and pull the samples with different labels apart from each other. However, their optimization and training are quite different. The pair embedding constructs its energy function on a training set composed of image pairs and optimizes it to assign small distances to similar pairs and large distances to different pairs. While triplet embedding mainly uses the Triplet-Loss function for training. However, these two methods cannot solve the challenging problem of fine-grained fabric image retrieval when the number of fabric images is limited. Instead of simply dividing the sample into positive and negative samples, in this paper, we make full use of the multi-dimensional labels of Mélange fabric to define different degrees of similarity for learning the representation of fabric images.
Soft similarity learning
Problem definition
Given a training set of N images

As shown in Figure 2, the similarity matrix M has six different situations when D = 3. According to equation (1), the similarity of pairwise images can be passed into four levels: completely similar (S = 1), very similar, a little similar, and dissimilar (S = 0). For Approximate Neighbor Nearest (ANN) search, the generated hash codes should preserve the similarity of the pairwise fabric images. To be specific, for a pair of generated binary codes bi and bj, if Sij = 0, which means the pairwise images do not share any label, the Hamming distance should be large; if Sij = 1, which means the pairwise images completely share the same labels, we expect the Hamming distance should be small; otherwise, the binary codes bi and bj should have a suitable Hamming distance complying with the soft definition of similarity Sij.

The similarity matrix when D = 3.
We present the pipeline of the proposed framework for similarity learning in Figure 3. The proposed model learns the similarity of fabric images in a supervised manner. The model receives a mini-batch of fabric images and then processes them through deep CNN. It consists of several convolution/pooling layers to abstract the feature of fabric images, the fully connected layer to approximate optimal dimension-reduced presentation and the hash layer to generate hash codes. In this study, the soft similarity loss is introduced to the objective function for similarity learning, the quantization loss is used to adjust the quality of generated hash codes, and the Cross-Entropy loss is used to improve the representation learning. Next, the main components of the framework are introduced.

The pipeline of the proposed deep hashing network for soft similarity learning. The top part shows the deep architect of the neural network, which is extracted from the first half of pre-trained VGG-16. The bottom shows the processing pairwise quantified similarity and objective function construction.
Network architecture
It has been proved that low-level features, that is, colors and textures, always appear in natural images and can be extracted by the first several layers of a convolutional neural network which is trained on natural images (ImageNet 48 ). As shown in Figure 1, the main features in fabrics are texture and color. So, in this paper, we simply adopt VGG-16 49 model as the stem network for soft similarity learning. The proposed scheme does not use the entire VGG-16 model, and just uses the first three convolution/pooling layers, whose parameters are initialized with the weights CNN pre-trained on the ImageNet. Such a choice can avoid overfitting on a relatively small dataset. Note that the output of the last pooling layer is flattened after Local Response Normalization (LBN) 23 and then input to the fully connected layer, instead of being max-pooled. We connect to the Dropout layer (with a probability of 0.6) to eliminate the redundant information. There are five fully connected layers in the proposed network, where the number of nodes in each layer is (28 × 28 × 256, 4096, 1024, q). q is the length of output hash codes. The proposed method can be easily extended to other deep networks (entire or part), such as ResNet50, 50 AlexNet, 23 and GoogLeNet. 51 The detailed discussion will be presented in the Experiments (Section 5). In order to realize hash coding, we use the tanh activation to map the output o the number of relevant imagef the last fully connected layer to be within [−1, +1].
Objective function
The goal of this study is to train a non-linear mapping function f that encodes each fabric image into q-bit hash codes with the similarity been preserved. In particular, the output codes of the similar images should be close in Hamming space, while the output codes of dissimilar images should be far apart in Hamming space. For this purpose, we design the objective function of the proposed model, which consists of three parts.

where L is the total Loss, Ls is the similarity loss defined in this study for preserving the similarity, Lc is the cross-entropy loss for image representation, and Lq is quantization loss for controlling the quality of hash code. There are three weighting parameters:
For a mini-batch

The two subscripts of l respectively represent the index of the corresponding image in the mini-batch and the index of the label dimension. S denotes the soft similarity of the pairwise images, and its two subscripts are the index of the corresponding image in the mini-batch. The proposed model receives the mini-batch and then outputs a matrix O of n × q. The similarity matrix of the output can be computed by:

where Eij represents the Euclidean distance between Oi and Oj, which can be calculated by the following equation:

To preserve the similarity, we propose to use covariance to facilitate the model to learn the similarity matrix of the input. In our design, the soft similarity loss Ls can be expressed as:

For efficient nearest neighbor search, the similarity of fabric images should be preserved in the Hamming space. The model receives a mini-batch with n fabric images and converts them into n q-bits hash-like codes. The model only generates approximate hash codes that have the values within [−1, +1]. To finally get the hash codes, we need to convert the hash-like codes into binary codes by using sgn function, as shown in equation (7).
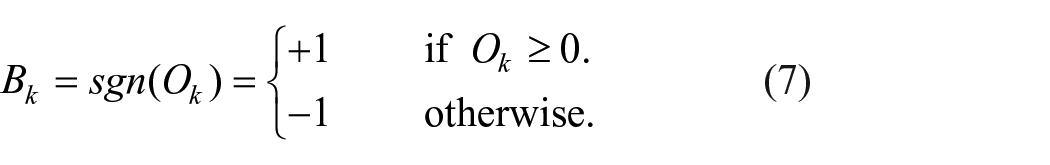
The sgn function is not continuous and is not included in the network to propagate back. Part of the information will be lost in the hashing process. Here we reduce the information loss by adding quantization loss to improve the quality of the hash codes. The quantization loss Lq can be written as:

where i is the index of the corresponding image in the mini-batch, and j is the index of this element in the q-bit output. We use the tanh activation to map the output of the last fully connected layer to be within [−1, +1]. Quantitative loss is used to encourage numbers less than 0 to be closer to −1, and numbers greater than 0 to be closer to +1. This configuration can fundamentally reduce the loss of information in the hashing process. In addition, the cross-entropy loss is used to enhance the image representation. For specific implementation methods, refer to citation. 16
The standard back-propagation algorithm with the mini-batch gradient descent method is used to optimize the pairwise loss function during the training process. The objective function L is differentiable, so we just use Stochastic Gradient Descent (SGD) to optimize the parameters of the model in a standard manner. As shown in equation (2), the proposed method involves three loss function, in this paper, we adopt joint training to optimize the parameters of the model. Note that, after the learning procedure, we have not obtained the corresponding binary codes of input images yet. The binary codes are generated by using equation (7).
In this way, we can train the proposed deep CNN in an end-to-end manner, and then any new input images can be encoded into binary hash codes by the trained model. By ranking the distance of these binary hash codes in the Hamming space, we can obtain effective retrieval.
Experimental configuration
Dataset
For evaluating the performance of the proposed method, we build a fabric image dataset named MFT-fabric-v1, which consists of 46,868 Mélange fabric images as the training-set, and 3672 Mélange fabric images as testing-set. All images in the dataset are annotated from three views: color, raw materials, and texture. The fabrics in the dataset are weft-knitted. The raw materials for woven these fabrics include polyester (T), rayon (R), and cotton (C). There are three types of cotton: common cotton (C), semi-combed cotton (SC), and combed cotton (CC). The Mélange fabrics in the dataset main are formed from 10 different material combinations (one or two raw materials), and the amount of each is shown in Table 1. The color of Mélange fabric is defined as the color of the special colored yarn or fiber (other than the basic color, such as white and black). Figure 4 shows three kinds of blue Mélange fabrics, which have very different percentages of blue fibers. This definition may cause the general hand-crafted based methods to be difficult to represent the color of Mélange fabrics. So this paper proposes to use the deep learning based method to describe the feature of Mélange fabric. According to this definition, there are a total of nine colors of Mélange fabric in the dataset, namely gray, red, orange, yellow, brown, green, blue, purple, and colorful gray. With respect to texture, we divide the weft-knitted fabric into six levels based on the thickness and weight of the yarn used. The testing-set is used to evaluate the performance of the image retrieval methods and contains a total of 72 sets (different sets of images belong to different categories), each of which consists of a query and 50 related images corresponding to it. To evaluate the robustness of the retrieval methods, the queries are augmented with some transformations: rotation, flipping, and scaling. To avoid the influence of capture conditions, the images are collected in a stable environment: DigiEye stable lightbox, which is equipped with a Nikon D7000 camera, a special pick-up head, and a standard illumination D65. Also, the resolution of the collected images is 96 dpi.
Type and amount of fabric by raw materials.


Three kinds of blue Mélange fabric.
Evaluation metrics
In this work, we evaluate the performance of retrieval methods by using widely-used metrics: precision-recall curve and mAP (Mean Average Precision) value. The mAP is a typical evaluation method for CBIR, which is computed by sorting images in descending order of relevance per query and averaging AP of individual queries. The average precision (AP) can be calculated by:

where

For precision and recall, we first introduce the definition of TP, FN, FP, and TN which are clearly shown in Table 2. Then the precision and the recall of retrieval results are defined as:


The definition of TP (True Positive), FN (False Negative), FP (False Positive), and TN (True Negative).

In evaluation, two images are considered to be semantically similar if they have the same annotations. For both evaluation metrics used in this work, a larger value indicates better retrieval performance. Generally, the precision will decrease as the recall increases.
Implementation details and compared methods
In the proposed learning framework, there are three parameters:

where lrn is the learning_rate of the nth epoch and N is the total number of epochs configured. a denotes the starting epoch where the learning rate begins to decay. p is a parameter used to control the intensity of each decay within (0, 1). In this work, we set a = 20, N = 60, p = 0.7, respectively. In this paper, we implement the proposed model by using the Pytorch toolkit. The hardware environment is as follows: CPU=E5 2623V4@2.60GHz, RAM=DDR4 32G, GPU=GeForce RTX 3090(24G) × 2. It is stated here that all compared deep learning-based methods are implemented using the Pytorch toolkit and based on the bone of VGG-16. And the other methods, which are based on the hand-crafted descriptor, are implemented by using MATLAB 2018b.
Results and discussion
In this section, we do several experiments to demonstrate the superiority of the proposed method, including parameters analysis, ablation experiments, comparison with state-of-the-art methods.
Parameters analysis
The parameters
Table 3 shows the results of the proposed method by using different values of
Results of mean average precision (mAP) for the different parameter values of

Ablation experiments
In the proposed model, we introduce three objective functions. The results of the third and fourth rows in Table 3 have proved that Cross-Entropy has greatly improved the performance of the proposed model. Figure 5 shows the effect of the quantization loss on the fabric image dataset. Notice that the larger the area under the pr curve, the better the retrieval performance. As we can see, there is a significant performance improvement when we add quantization loss to the objective function of the model. In the proposed method, the sgn function (as shown in equation (7)) is employed to generate the binary hash codes. Generally, there is a great loss of information in this hashing process. The quantization loss is used to reduce the loss of information, and thus improve the quality of hashing process. The results in Table 3 and Figure 5 together illustrate the effectiveness and necessity of the three proposed objective functions.

The precision-recall curves of retrieval performance with and without quantization loss.
Comparison with different settings
To justify the rationality of the proposed configuration, we conduct some comparison experiments. Specifically, we compare the following different network configurations (as the stem network): entire VGG-16, ResNet50, AlexNet, and GoogLeNet.
Table 4 presents the results of mAP metric of the proposed method and its modifications with different code-length, respectively. For fair comparison, all compared methods are trained under the supervision of our proposed objective function with the same weight parameter settings:
Results of different network configurations on the fabric dataset.

Efficiency analysis
The efficiency issue is addressed in this part because it prevents such methods from being widely deployed in more retrieval applications. As mentioned in the related work, FRHS and FRMT are specifically designed for fabric image retrieval in those baselines (both of them are deep hashing methods). Consequently, the training and query expenses on MFT-fabric-v1 dataset at various code lengths when using those methods are summarized in Table 5. Here, we compare two metrics: network training time (NT) and query time (QT). The experiments are conducted on the same hardware configuration reported previously. As can be seen, the proposed hashing method takes less time, both in training time and query time. In particular, the training time of the proposed model is much less than the others, indicating that the objective function and learning method proposed in this paper have high efficiency. Moreover, it is worth nothing that the query time of proposed method only costs 0.25 s (128 bits), which can expand the application scope of fabric image retrieval, such as mobile applications.
Time complexity analysis at various code lengths on MFT-fabric-v1.

Comparison with SOTA methods
In this section, we compare the retrieval performance of the proposed method with three supervised methods, three unsupervised methods, and four methods dedicated to fabric image retrieval. To make a fair comparison, we employ VGG-16 as the stem of all deep learning based methods. With respect to the implementation of three supervised methods, including CNNH, 52 DPSH, 53 and CSQ, 54 and three unsupervised methods, including UHBDNN, 55 SSDH, 56 and SADH, 57 we simply follow the author’s public code and implement it with PyTorch. The four methods, which are dedicated to fabric image retrieval, are FRHS, 14 FRMT, 16 CMGF, 10 and MRI-LBP, 12 in which FRHS and FRMT are our previous works.
Table 6 presents the mAP comparison results on MFT-fabric-v1 dataset. It can be observed that the retrieval method proposed in this paper achieves the best performance under different code lengths. For example, when we set the length of the code to 128 bits, the proposed method achieves the mAP value of 0.915, which surpasses other comparison methods. The comparison results also reflect that, from 32 bits to 128 bits, as the length of the hash codes increase, the retrieval performance has improved. To a certain extent, this phenomenon indicates that the longer hash codes can capture more discriminative information from the image in deep hashing models. However, an excessively long code length may result in feature redundancy, resulting in performance degradation. So, in this study, we set the length of hash codes q to 128. Moreover, we clearly find that the supervised methods perform better than the unsupervised methods on MFT-fabric-v1 dataset. The two hand-crafted descriptor based methods cannot achieve good performance due to the limitation of feature engineering. In Figure 6, we also present the precision-recall curves of the compared methods on the testing-set. The area under the curve corresponding to the proposed method is larger than the curve corresponding to other methods, which indicates the retrieval performance of our method is better than other methods.
mAP comparison on MFT-fabric-v dataset. The best result in each column is marked with bold.


The precision-recall curve of the comparison on the testing-set.
Table 7 presents the results of the compared methods at 128 bits on MFT-fabric-v1 dataset using a different number of training images. The results demonstrate that the proposed model can be trained on a smaller data set and achieve good results. Four retrieval samples using our method are shown in Figure 7, in which retrieval results and queries are very similar in color and texture. Moreover, the retrieved results have good visual continuity, precisely because we use soft similarity to drive model learning.
The comparison results with different number of training fabric images.


Retrieval results of four samples.
Conclusion
In this paper, we present an efficient fabric retrieval framework based on our previous work.14,16 To drive the model to learn fabric image representation, we introduce a quantified similarity definition, soft similarity, to measure the fine-grained pairwise similarity. In view of the characteristics of the fabric, we use the first several layers of the pre-trained VGG-16 as the bone of the model. The objective function consists of three parts: soft similarity loss for preserving the similarity, cross-entropy loss for image representation, and quantization loss for controlling the quality of hash code. Extensive experiments on MFT-fabric-v1, a multi-label dataset, demonstrate that the proposed method outperforms the compared methods. And the retrieval results show that the proposed method achieves effective feature learning and hash learning. In our future works, we will try to extend this approach to other fabric types.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Key R&D Program of China under Grant 2017YFB0309200, in part by the Fundamental Research Funds for the Central Universities under Grant JUSRP52007A, in part by the National Natural Science Foundation of China under Grant 61976105.