
Abstract
A surge in social media research recruitment has led to increased fraudulent participation, impacting studies such as our sequential mixed methods research (MMR) study on peer loneliness among adolescents with chronic pain during COVID-19. The purpose of this paper is to describe the challenges and subsequent strategies implemented to prevent and identify fraudulent participants during a MMR study that used online data collection methods. The results of the various mitigation strategies implemented are provided along with recommendations for future research. This article makes a valuable contribution to MMR literature by highlighting the threat to data integrity and detailing various mitigation strategies for different phases of MMR. These strategies should be proactively implemented by researchers to increase data integrity.
Keywords
Background
The use of social media recruitment in health research has increased considerably in recent years, especially since the COVID-19 pandemic, where social distancing requirements posed challenges to traditional in-person recruitment and data collection procedures (Ali et al., 2020; Lobe et al., 2020). Additionally, facilitated access to hard-to-reach populations in diverse geographic regions, cost-effectiveness, and shorter recruitment periods have also contributed to the popularity of online recruitment and data collection in health research (Brøgger-Mikkelsen et al., 2020; Oudat & Bakas, 2023; Sanchez et al., 2020). Unfortunately, as the use of online research methods increases, so does fraudulent research participation (Godinho et al., 2020; Jones et al., 2021; Roehl & Harland, 2022).
The broad term fraudulent participants has been used to refer to human participants intentionally engaging in online surveys (Griffin et al., 2022; Storozuk et al., 2020) and in synchronous virtual qualitative interviews, who are not eligible to participate in a study (against its inclusion/exclusion criteria) (Jones et al., 2021; McLachlan et al., 2025; Ridge et al., 2023), or who participate repeatedly in a single study (impersonating multiple identities) (McLachlan et al., 2025; Pullen Sansfaçon et al., 2024). The term fraudulent participants also refers to the employment of bots, software applications designed to perform automated tasks such as finding and completing online surveys en masse (Godinho et al., 2020; Storozuk et al., 2020).
Despite the availability of built-in automated protective measures in commonly used survey platforms (e.g., Qualtrics, SurveyMonkey, and REDCap) (Teitcher et al., 2015), it remains challenging to protect health research data from bot infiltration. Additional strategies such as study advertisements that generally refer to the study without specific population to decrease fraudulent participants from researching the characteristics of the population of interest, no mention of monetary compensation, specific eligibility criteria, enabling of CAPTCHA, links to surveys sent to eligible participants’ emails have been used despite limited success (Pozzar et al., 2020). Nevertheless, it is essential that researchers acknowledge this potential threat to data integrity from the study design stage, creating robust recruitment protocols to mitigate the presence of bots (Griffin et al., 2022), while also manually and constantly overseeing the recruitment process to identify fraudulent responses that bypass the preventive strategies in place (Godinho et al., 2020). Nonetheless, as researchers attempt to learn about bots, “they learn about us” (Storozuk et al., 2020, p. 477), adapting rapidly and becoming more sophisticated as technology advances (Griffin et al., 2022), requiring researchers to continually be aware of developing best practice to manage bots (Teitcher et al., 2015). Fraudulent participants misrepresenting their identities and volunteering for virtual interviews also pose a threat to qualitative data integrity (McLachlan et al., 2025). It can be surprisingly challenging and time-consuming for researchers to identify participants who fake or exaggerate their responses or impersonate multiple identities in a single study (Ridge et al., 2023; Roehl & Harland, 2022). Like quantitative research, establishing a baseline level of suspicion from the planning stages of qualitative studies is fundamental (Ridge et al., 2023) and screening of data for verbal and nonverbal cues of potential mischievous behavior is needed throughout the research process (Roehl & Harland, 2022). Additionally, participants who do not use their video camera during virtual interviews should raise suspicion (Roehl & Harland, 2022).
While financially compensating participants for their time is ethically justified and good practice (Gelinas et al., 2018), it has also become a major incentive for fraudulent participants in quantitative (McLachlan et al., 2025; Roehl & Harland, 2022) and qualitative studies (Godinho et al., 2020; Storozuk et al., 2020). McLachlan et al. (2025) highlight other potential motives for participants to misrepresent their identities in studies such as curiosity, mere entertainment, and attempts to influence study outcomes in controversial research topics. Beyond the risk of accidentally employing research funds (e.g., federal grants subsidized by taxpayers and association grants subsidized by membership fees) to compensate fraudulent participants (Griffin et al., 2022), emerging research reports have also illustrated the impact fraudulent participants can have in quantitative and qualitative data integrity. In a cross-sectional study investigating the impact of COVID-19 on the LGBTQ+ population in the United States, nearly 50% of the recruited participants were identified as fraudulent participants (Griffin et al., 2022). Authors conducting a longitudinal study on an intervention to reduce alcohol consumption and depression symptoms also reported that 20% of their preliminary data set could have been compromised by fraudulent participants (Cunningham et al., 2021; Godinho et al., 2020). High rates of fraudulent activity in quantitative studies, such as these, are extremely concerning since even as little as 5% random responding by eligible participants to survey items may significantly influence statistical inferences from studies (Credé, 2010). Fraudulent participants have also jeopardized data trustworthiness in qualitative studies conducted by both novice researchers, such as graduate students, and experienced research teams (McLachlan et al., 2025; Ridge et al., 2023; Roehl & Harland, 2022). Beyond vague or exaggerated descriptions of health conditions, McLachlan et al. (2025) described an alarming situation experienced by a researcher during an online interview, where older adults deliberately engaged in a study targeting the adolescent population. Roehl and Harland (2022) also suspected that a fraudulent participant completed multiple interviews, under distinct identities, in a study exploring how educators use social media to influence students’ empowerment skills.
Likewise, our sequential mixed methods research (MMR) study designed to understand the types and impact of peer loneliness amongst adolescents with chronic pain in the context of the COVID-19 pandemic faced the challenge of fraudulent participation, with 95% participants in the quantitative phase and 21.4% in the qualitative phase of the study being flagged as fraudulent. Rates higher than this have been experienced by other health researchers despite using a survey recruitment process that included not sharing the compensation information until the consent form and emailing passcodes to enter the survey (Pozzar, et al., 2020). The prevalence of fraudulent participants led our team to streamline a process to identify and exclude them from our study’s quantitative and qualitative phases to support data integrity.
There is a paucity in the availability of information on fraudulent participation in MMR research, particularly in the context of research involving the adolescent population, meaning that it is imperative that researchers share and discuss positive and negative methodological experiences to alert each other about these issues, improve knowledge on how to mitigate these challenges to ultimately ensure data integrity. Therefore, the purpose of this paper is to describe the challenges and strategies implemented to prevent and identify fraudulent participation during a MMR study using online and virtual data collection methods with adolescents, report our results of implementing these strategies, and provide recommendations for future research based on interprofessional collaboration amongst healthcare researchers, computer scientists, and patient partners.
Methods
The study’s procedural diagram in Figure 1, illustrates the flow of the study’s fraudulent participant mitigation strategies and data removed as a result at each stage of our MMR study. Procedural diagram: Sequential MMR design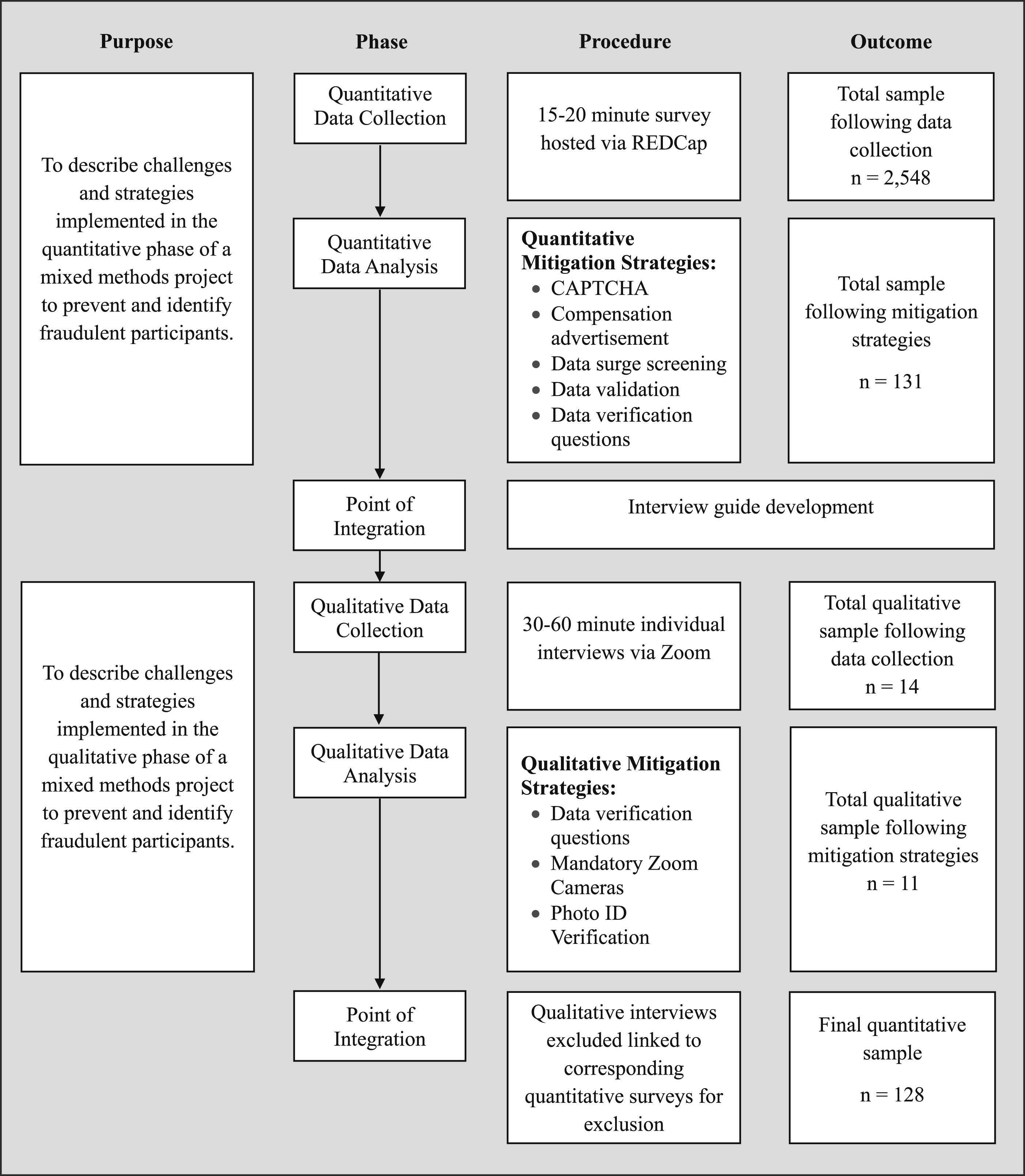
Quantitative Strategies
The first phase of our sequential MMR study comprised a quantitative online survey hosted on the REDCap platform at one of our participating academic health centers. REDCap is a secure, web-based software platform designed to facilitate data collection in research (Harris et al., 2019). The study’s first phase aimed to recruit 130 adolescents between 12 and 18 years of age with chronic pain. The survey spanned 23 pages and contained 172 questions with an estimated completion time of 15-20 minutes based on pilot testing within the research team including five patient partners. Despite the time estimated to complete the survey participants could take as long as needed. However, they were unable to go back and forth between pages of the survey and if they exited the survey, they could not regain access. Participants were informed in the study recruitment materials and in the information and consent letter that they would receive a gift card valued at $30 CAD to compensate them for their time and effort. Study recruitment was launched via a social media campaign on Instagram, Facebook and X (formerly known as Twitter) and within the first three hours of launch, 1,139 survey responses were received. This immense number of responses raised concern and was believed to be predominantly from fraudulent participants given our experiences with recruiting this population for other studies, including one where fraudulent participation often took place in mass surges around the same time as this study was launched (Kelly et al., 2023). Thus, following this significant surge in responses, the online survey was paused, and the following quantitative mitigation strategies were implemented. These mitigation strategies were developed in consultation with other members of the research team, the limited articles on the subject matter, and in collaboration with our institutional Research Ethics Board.
Pre-Survey Strategies
CAPTCHA
The survey hosted on the REDCap platform was protected by a Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA), a short task designed to be easy for humans but too complex for bots (Godinho et al., 2020; Jones et al., 2021; McLachlan et al., 2025). Traditionally, the CAPTCHA involves identifying distorted text, selecting images that meet certain criteria, or solving simple puzzles prior to gaining access to content online. This feature can be enabled at the beginning of surveys hosted on major platforms, such as REDCap, Qualtrics, and SurveyMonkey.
Compensation Advertisement
Given the overwhelming traction from suspected fraudulent participants after the social media posting, all study recruitment posts were removed and replaced with recruitment advertisements that omitted any mention of compensation (McLachlan et al., 2025; Roehl & Harland, 2022). Though compensation information remained outlined in the study’s consent letter displayed at the onset of the survey as part of ethical disclosure, it was not readily advertised to reduce the appeal of compensation to fraudulent participants. For example, if bots were used to scan for keywords such as “compensation” or “gift card” in social media posts, this study would not be identified.
Post-Survey Strategies
The following three post-survey strategies were used to screen the data every few days as batches of surveys were received, starting with the mitigation strategies found to be most time-effective, followed by those found to be more time-consuming. Surveys eliminated using the first strategy were not subjected to review at the subsequent strategy. The following mitigation strategies are in the order used.
Data Surge Screening
Following data collection, the dataset was screened for surges of survey submissions. Data surge criteria, defined as multiple survey submissions within a short period of time, were established and consisted of (1) five or more responses where each submission is no more than 5 minutes apart from the last; or (2) 10 or more responses where each submission is no more than 10 minutes apart from the last (Kelly et al., 2023). This algorithm was developed by one of the co-principal investigators’ team in a separate study during the same time frame and was successful in screening for data surges with a high suspicion of fraudulent participants in pediatric chronic pain research (Kelly et al., 2023). However, there are no studies of the reliability and validity of this approach currently.
Data Validation
Once data surges were identified and affected surveys were removed, the remaining dataset underwent screening for incomplete submissions and invalid data (Kelly et al., 2023). All surveys where participants did not continue past the sociodemographic questions, but were not part of data surges, were excluded as recommended by (Kelly et al., 2023), no other surveys were removed for missing data. Additionally, one of the study’s inclusion criteria required that adolescents reside in Canada, therefore, postal codes that did not conform to the Canadian postal code alphanumeric structure (e.g., K1S 5L5) or that were in the correct format but were not linked to a residential address (e.g., schools, community centers, churches and parks) were removed.
Data Verification Questions
The third quantitative mitigation strategy was the use of data verification questions. These questions consisted of asking participants select sociodemographic questions at the beginning of the survey for analysis purposes and then again at a second time point towards the end of the survey to ensure consistency (Kelly et al., 2023). In the context of this study, participants were asked to confirm their age, postal code, and ethnicity on the last page of the survey. These questions were specifically chosen as postal codes were our only sociodemographic question set as an open-text field, while the age and ethnicity questions offered the highest number of answer options from a drop-down menu, thus having the highest potential for error by fraudulent participants. Participants were not informed of data verification questions in the survey information and consent letter or at the beginning of the survey. This decision was made with the support of research ethics boards to ensure that participants could not prepare for these questions if they were fraudulently taking part.
Qualitative Strategies
The second phase of our sequential MMR study consisted of 30-to-60-minute individual interviews via Zoom to capture experiences of loneliness amongst adolescents with chronic pain. All adolescents who participated in the quantitative phase of the study and indicated their interest in the qualitative phase were invited to participate. To compensate participants for their time they were informed in an email invitation and accompanying recruitment documentation that they would receive a gift card valued at $50 CAD following their participation. Though quantitative mitigation strategies were implemented and suspected fraudulent participants whose data failed the screening process were excluded, there were still challenges with suspected fraudulent participation in the study’s qualitative phase. All qualitative mitigation strategies were implemented prior to interview launch, except for photo identification (ID) checks, described below, which were launched in response to specific issues encountered.
Pre-Interview Strategies
Data Verification Questions
Prior to the start of the interviews, participants were asked to confirm their age and postal code, this information was then compared to the participant’s survey data. If a discrepancy was found between the participant’s survey data and answers before the interview, they were asked follow-up questions without informing them of the discrepancy in the information provided to balance participation and trust with data integrity. In the case of a postal code discrepancy, participants were asked if they had recently moved. In the case of an age discrepancy (e.g., participant was now 16 but was 15 at the time of the survey), they were asked if they celebrated a birthday since their survey participation. If no explanation was found to explain the discrepancy, the interview did not take place and the participant’s corresponding survey response was excluded.
Mandatory Zoom Cameras
Use of personal cameras during Zoom interviews were mandatory and this requirement was included in the interview email invitation and the information consent letter provided prior to interviews. This strategy targeted participants who may try to participate multiple times with their cameras off, who used deliberate disguises (Noyes & Jenkins, 2019; Roehl & Harland, 2022), or who were adults attempting to impersonate adolescents. If the participant refused to turn their Zoom camera on for the entirety of the interview, the interview did not take place and the participant’s survey response from the quantitative phase was excluded.
Photo ID Verification
Photo ID verification took place prior to starting interviews to deter individuals from attempting to participate more than once using different names and demographic information and ensure participants were who they stated to be. Photo ID checks took place before the start of interviews and Zoom recordings so that no records of their ID were kept. Given the young age of some participants, the research team was flexible regarding the acceptability of the types of photo IDs, often encouraging participants to bring a student card or bus pass if they did not have a government-issued photo identification card (e.g., healthcare card, driver’s licence, passport) as long as their photograph and name were on the ID. All of these forms of ID have dates of validation, which were checked along with the participant’s name and picture. This requirement was included in the interview email invitation and the information and consent letters.
Post-Interview Strategies
Interview Screening
In instances where participants were suspected of participating twice, post-interview screening of interviews took place. The screening process consisted of viewing interview recordings side-by-side and analyzing participants’ facial features, linguistic expressions and hesitation markers (Noyes & Jenkins, 2019).
Results
The initial survey was launched on January 16, 2023, and closed the same day due to 1,139 surveys being completed in 3 hours. The survey was reopened on January 23, 2023, after fraudulent detection and mitigation strategies were designed and implemented. The survey was closed on June 19, 2023. A total of 128 surveys remained in the final quantitative survey dataset, and 11 individual interviews in the final qualitative dataset. Overall, 2,417 surveys were removed using mitigation strategies in the quantitative phase, and 3 were removed using strategies in the qualitative phase. The results of the systematic screening process are illustrated in Figure 2. Fraudulent participant MMR systematic screening process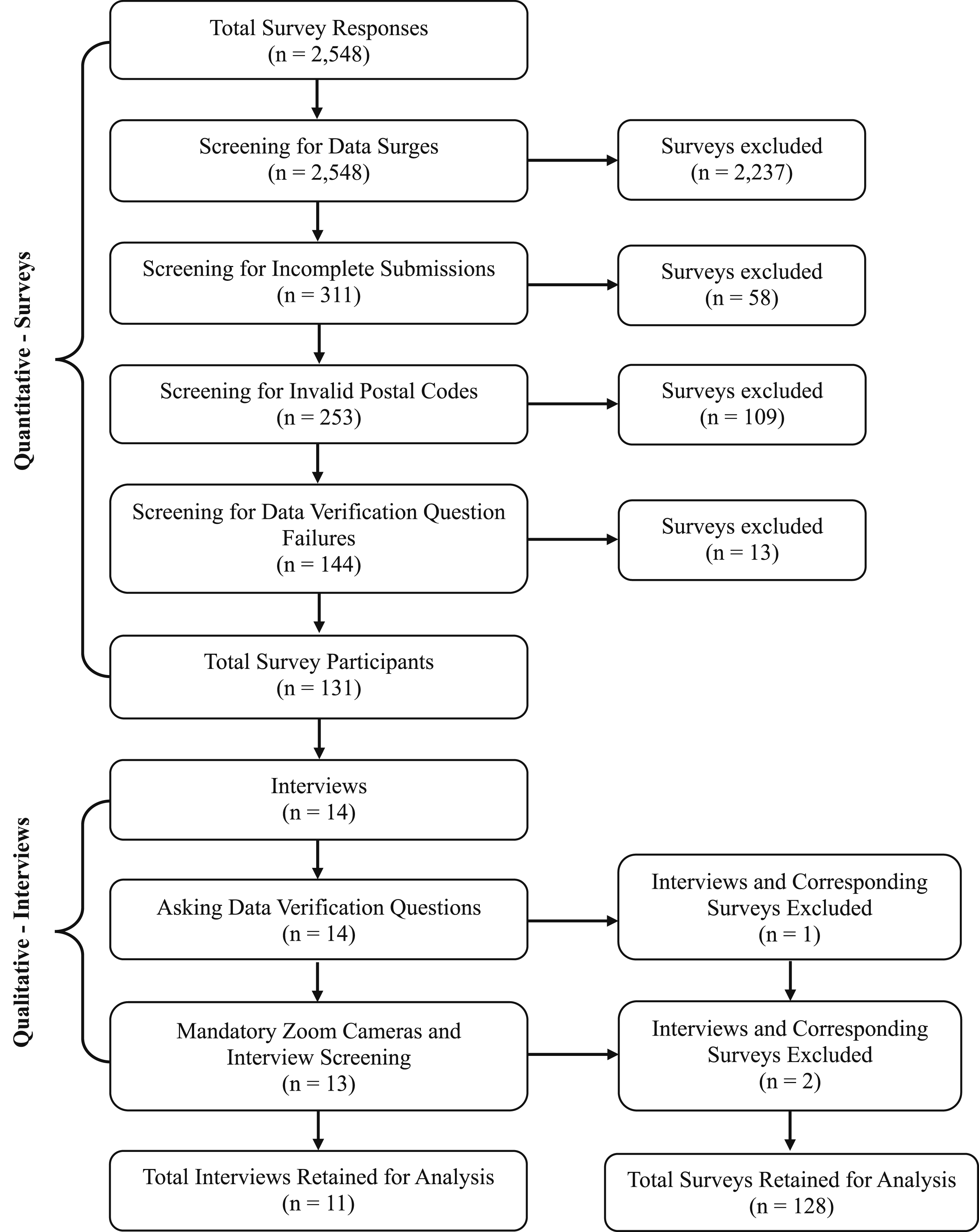
Quantitative Mitigation Strategies
Pre-Survey Strategies
CAPTCHA
Although we cannot quantify the outcome of this strategy, a CAPTCHA was enabled at the initiation of the REDCap survey and significant data surges were experienced throughout the hosting of the survey with large surges (e.g., over 1000 within 3 hours) suspected to be due to bot activity.
Compensation Advertisement
Before the removal of compensation advertisement, 1,139 survey responses were received within the first 3 hours of opening the survey. This rapid response rate did not occur after the removal of compensation in the advertisements. Thus, in the final analysis, removal of the compensation in the advertisement resulted in 44.7% (1,139/2,548) of surveys being excluded and 55.3% (1,409/2,548) of the surveys were excluded due to mitigation strategies following the removal of compensation in the advertisements.
Post-Survey Strategies
Data Surge Screening
Though surges were usually easily discernible (e.g., exclusion of 26 survey submissions within 1 minute), Kelly et al.’s (2023) algorithm was useful in screening for smaller surges (e.g., exclusion of 7 survey submissions received within the span of 23 minutes at intervals of less than 5 minutes apart). Data surge screening took place first due to the large volume of survey responses received in surges. Screening for data surges excluded 87.8% (2,237/2,548) responses of survey responses. All surveys linked to a data surge were excluded from the study analysis.
Data Validation
Common Trends Among Invalid Canadian Alphanumeric Postal Codes

Data Verification Questions
Finally, participants were asked to confirm their age, postal code and ethnicity at the beginning of the survey and on the last page of the survey. This information was compared for consistency amongst the surveys that remained after the two quantitative mitigation strategies noted above were implemented. An example of a failed set of data verification questions is as follows: At survey onset, the participant self-identified as 13 years old, residing in the K1S 5L5 postal code and identified their ethnicity as Korean. At the end of the survey, the participant self-identified as 15 years old, residing in the K1S 5L5 postal code and identified their ethnicity as Latin American. If discrepancies such as the one above were observed, this was considered a data verification question failure, and the survey submission was excluded. Screening for data verification question failure excluded a total of 13/2,548 surveys.
Qualitative Mitigation Strategies
Pre-Interview Strategies
Data Verification Questions
One (n = 1) participant was excluded due to data verification question failure prior to the start of their interview as their responses did not match the survey answers to the same questions. At the time of the interview, they stated they were a year younger than stated in the survey and provided a different postal code. When asked if they had moved since their survey completion, the participant stated that they had not moved. Subsequently, the participant was informed by the interviewer that we could not move forward with the interview due to inconsistencies in the information provided, and the participant did not provide any form of explanation for the inaccuracies of the data. As a result, the participant’s corresponding quantitative survey response was excluded. The participant was not compensated for interview participation, though they had already been compensated for participation in the survey.
Mandatory Zoom Cameras
Although we are unable to directly quantify the effect of this strategy, it is possible that it deterred those attempting to participate fraudulently. Moreover, this strategy did allow us to do post-interview screening and exclude two (n = 2) interviews suspected of involving the same person.
Photo ID Verification
This strategy was implemented after a participant was suspected of participating twice (noted above). Consultation with the Research Ethics Board regarding the suspected fraudulent participant resulted in an approved modification allowing photo ID verification for subsequent interviews. All subsequent interview participants presented photo ID to the interviewer before starting the interview, and none voiced discomfort or showed any signs of hesitation upon being asked to present photo ID. It may be that participants were comfortable with providing a photo ID as this requirement was conveyed to participants prior to interviews, and an explanation for why this was needed was provided to participants at the time of the interview. Although we are unable to quantify the effect of this strategy, it is possible that it would deter adults attempting to impersonate an adolescent or individuals trying to participate under multiple identities. If a participant would have been unable to provide photo ID, the interview would not take place and the participant’s survey response would be excluded.
Post-Interview Strategies
Interview Screening
In the instance described above where two (n = 2) interviews were excluded due to the same individual suspected of taking part twice, post-interview screening was employed by two team members. The suspected participant reported different names, emails and demographic information, and their data verification questions (ages and postal codes) matched their respective surveys. However, both interviews were conducted by the same interviewer who raised this concern.
In side-by-side screening of the video-recorded interviews, significant concern was raised. In the first interview, the participant wore no makeup, wore a sweater with their hood on, and was sitting in front of a black curtain. In the second interview, the participant wore makeup with their hair down and was sitting in front of a brick wall. Participants had identical facial features (e.g., piercings, dimples) and used the same linguistic expressions (e.g., “most times”) and hesitation markers. In both cases, the description of their chronic pain was vague (e.g., unsure when it started, unsure how to describe it [pounding, stabbing, aching], unable to describe intensity, location and treatment), uncommon for this population who have taken part in other qualitative studies by team members.
Discussion
Like other studies (Lei, 2024; Pozzar et al., 2020), we experienced an unexpected survey response rate following a social media recruitment post. The rate of surges slowed after the removal of the advertisements that discussed compensation, but they did continue, suggesting that compensation alone is not the sole driver of all data surges. There is little published on the success of pre-data collection mitigation strategies and what is published raises the need for research to evaluate the success of these strategies. For example, despite the implementation of pre-survey strategies including CAPTCHA, not advertising compensation, including a study eligibility checklist with country of participation, and an automated survey invitation sent to participants via email, Pozzar and colleagues (2020) experienced a significant data surge (576 responses within 7 hours), noting that many of these were completed in the middle night if completed in the geographic location of eligibility. However, without these strategies in place (e.g., country of participation) they may not have been alerted to potential fraudulent participants whose timing of survey completion was irregular. Although these strategies were limited in success, they were favorable compared to our initial data surge of 1,139 surveys in 3 hours. Given that several of these strategies are easy to employ, especially not advertising compensation, it is advisable to do so, but only in addition to post-survey mitigation strategies.
After receiving the initial data flood, further strategies were implemented at pre- and post-survey and pre- and post-interview data collection to improve data integrity. Although these strategies resulted in excluding 2,417 probable fraudulent participants at the quantitative phase and 3 at the qualitative phase of the study, the actual reliability and validity of these mitigation strategies in detecting fraudulent participants from genuine participants are difficult to quantify. For example, three surveys were removed from the final dataset based on detection of fraudulent participation in the qualitative phase despite these three surveys escaping the quantitative detection and mitigation strategies. Similarly, one survey was identified as belonging to a genuine participant despite occurring during a data surge and initially removed.
Of note, our approach to deter fraudulent participants was reactive, not proactive, resulting in study delays, increased workload, and loss of funds, not only by compensating research assistants for additional work hours, but also compensating some fraudulent participants. Thus, developing mitigation strategies at the study design stage using protocols or frameworks (e.g., Dewitt et al., 2018 ; Lawlor et al., 2021; Salinas, 2023) may decrease researchers’ burden, inappropriate use of resources, and timeline delays (Kumarasamy et al., 2024). In addition, collaborating with an interdisciplinary team is recommended. For this paper, we collaborated with computer scientists as technology advances are rapid and their unique expertise enables further understanding surrounding fraudulent participant’s infiltration in research (e.g., bypass strategies, data surge process). Furthermore, working with patient partners from diverse backgrounds as well as associations representing underrepresented populations can provide unique perspectives about how additional mitigation strategies may increase the burden for genuine participants (McLachlan et al., 2025) or create additional barriers to participation. Their insight helps determine how to balance mitigation strategies while also maintaining the trust of the genuine participants (Pullen Sansfaçon et al., 2024; Storozuk et al., 2020), which is essential as vulnerable individuals who participate in research may feel like “imposters or fraudsters about their lived experiences” (Pullen Sansfaçon et al., 2024, p. 2).
MMR Strategies for Mitigating Fraudulent Participants

Contribution to Mixed Methods Research
Despite the increasing use of social media recruitment in MMR (Darko et al., 2022; Goodyear et al., 2021), most of the literature focuses on fraudulent participants in quantitative (Bybee et al., 2022; Salinas, 2023) or qualitative (Jones et al., 2021; Sefcik et al., 2023) studies. This article adds a unique contribution to MMR literature as it discusses how fraudulent participants can jeopardize MMR data integrity, the extent of the problem using a real MMR example, and various strategies that can be used to mitigate fraudulent participants at different MMR phases. Unlike single design studies, MMR has additional benefits for detecting fraudulent participants. For instance, in a sequential design, the detection of fraudulent participants in one phase (e.g., survey) can restrict their participation in the second phase (e.g., interview). Similarly, detection in the second phase (e.g., interview) can help identify fraudulent participants who may have bypassed the detection and mitigation strategies used in the first phase. Further, in studies with linked data between phases, researchers can use data verification questions from one phase to cross-reference participants’ answers in the other phase. To enable this bidirectional detection strategy, we encourage researchers using a sequential approach to pause between study phases to examine whether compromised data exists and use this information to decrease fraudulent participation in the next phase.
Limitations
While this article has strengths such as the quantification of the degree of fraudulent participation in a MMR study, it also has limitations. First, as mentioned, we are unable to determine the actual reliability and validity of the strategies we implemented. For example, one eligible participant was unintentionally excluded during a data surge in the survey phase. This exclusion was discovered as the participants asked their clinician, who had advertised this study, to contact the research team as they had not received compensation for their participation. After verification, their data was added to our dataset and compensation was provided, though it is unknown if this was the only participant excluded in error. Therefore, despite implementing diverse mitigation strategies (McLachlan et al., 2025; Roehl & Harland, 2022), fraudulent participants can be missed, and eligible participants may be excluded.
Second, it is difficult to know if our strategies were effective at removing all fraudulent participants. About halfway through data collection, recruitment in clinical settings was initiated instead of relying solely on social media recruitment as a strategy to gather reliable data. A preliminary analysis of the main outcomes was conducted before instituting this change using the survey data that had been retained using the mitigation strategies and there were no changes to the main outcomes (e.g., variation in the types of loneliness, impact of specific sociodemographic and pain characteristics on loneliness) which provided a degree of evidence that the online survey strategies were effective at mitigating fraudulent data. However, how to handle data that had significant discrepancies is unclear, as it may be due to fraudulent participants or actual differences because of not reaching the required sample size for power analysis in preliminary analysis.
An inherent concern of reporting on mitigation strategies is that it may potentially publicize them to fraudulent participants, improving their ability to go undetected (Storozuk et al., 2020). For this reason, we caution researchers from publishing articles, posters, and abstracts related to fraudulent participation in open access repositories and journals.
Conclusion
Fraudulent participants can be detrimental to data quality and integrity in MMR studies and are an increased risk when using online data collection methods. Mitigating fraudulent participants requires both pre- and post-data collections strategies at both phases of MMR studies, yet researchers must remain mindful of genuine participants. The sophistication of fraudulent participation is ever evolving, researchers need to work within an interdisciplinary team to develop effective mitigation strategies as this can lessen the guilt, doubt, and stress that fraudulent participants can instill in research teams (Kumarasamy et al., 2024; Pullen Sansfaçon et al., 2024). By examining our experiences and providing recommendations, researchers can work to prevent and detect fraudulent participants and improve data integrity. However, further research is warranted to determine the success of these strategies in identifying fraudulent participants from genuine participants.
Footnotes
Acknowledgments
The authors gratefully acknowledge the support received from the University of Ottawa’s Research Ethics Board and commend their ongoing commitment to fostering collaboration with research teams. Additionally, the authors extend their gratitude to the patient partners who contributed their time, insights, and lived experiences to this research, for which their perspectives were invaluable.
ORCID iDs
Ethical Considerations
This study was approved by research ethics boards at the three sites across Canada, including the University of Ottawa (H-07-22-8129), the Hospital for Sick Children (1000079873), and the Stollery Children’s Hospital (Pro00128531).
Consent to Participate
Informed consent was obtained from survey participants by checking a box prior to starting the survey and was obtained verbally from interview participants prior to commencing interviews.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by research grant 740 from the Canadian Institutes of Health Research aimed at addressing the wider health impacts of COVID-19. Funding reference number: [W12—179947].
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.