
Abstract
There are much data transmitted from sensors in wireless sensor network. How to mine vital information from these large amount of data is very important for decision-making. Aiming at mining more interesting information for users, the skyline technology has attracted more attention due to its widespread use for multi-criteria decision-making. The point which is not dominated by any other points can be called skyline point. The skyline consists of all these points which are candidates for users. However, traditional skyline which consists of individual points is not suitable for combinations. To address this gap, we focus on the group skyline query and propose efficient algorithm to computing the Pareto optimal group-based skyline (G-skyline). We propose multiple query windows to compute key skyline layers, then optimize the method to compute directed skyline graph, finally introduce primary points definition and propose a fast algorithm based on it to compute G-skyline groups directly and efficiently. The experiments on the real-world sensor data set and the synthetic data set show that our algorithm performs more efficiently than the existing algorithms.
Keywords
Introduction
Wireless sensor network (WSN) is a kind of distributed sensor network, whose terminal is the sensors that can sense and check the external world. WSN uses sensors to collect information in the detection area and transmits data through wireless communication. Therefore, a lot of data can be collected through WSN, so how to mine vital information from these mass data for special purpose is very important.
As one of the important query mining techniques, skyline query 1 can return all the Pareto optimal points that are not worse than any other points in the same data set, and it is very useful in many applications, such as data mining and multi-standard decision-making. Although which points in skyline are selected depend on user’s decision and other factors, after all, skyline query reduces the size of the outstanding candidate set by pruning the mediocre points.
Assume there is a data set P of n points with d dimensions, p and q are two distinct points in P, we can say p dominates q, if p[i] <= q[i] for each i and at least p[j] < q[j] (1 ≤ i, j ≤ d), where p[i] indicates the value of p in the ith dimension. The skyline of data set P consists of all the points which are not dominated by any other points in P. We can say the skyline indicates the Pareto optimal points as the skyline points are better points and cannot dominate each other.
Take a case in forest fire warning system, for example, aiming at detecting fire hazard, thousands of sensors connected via a WSN are deployed throughout the forest. When the fire is about to burn or has broken out started, the nearby humidity will decrease, and the nearby temperature will increase sharply. As shown in Figure 1(a), there are 12 points in data set P, and each point represents a sensor with two attributes: the humidity and the inverse-temperature. The suspicious point with smaller humidity and inverse-temperature can be returned by skyline query on data set P, so the forest fireman can run to these skyline points to check for fire hazards. In this case, we find three points should be checked as soon as possible, p1, p6, p11, as these three dangerous points have smaller humidity or/and inverse-temperature. These three points are skyline points of P, as shown in Figure 1(b).

An example of skyline: (a) data set P and (b) skyline.
Motivation
In the above example, due to the limitation of fire fighting force, in order to effectively control fire hazards, the most effective method is to patrol some suspicious sensors in groups. If we planned to divide the fire forces into teams, each of which would patrol three trouble sensors as a group, traditional skyline queries would not be able to satisfy the demand. As the traditional skyline query can only return results in units of individual point, it is deficient for user to do query based on groups or combinations. In fact, this query is very practical and often used in WSN environment.
To remedy this deficiency, group-based skyline (G-skyline for short) query 2 is proposed to return candidate set which consists of better groups containing k points. This query is more useful than traditional skyline query in many applications which need to return some better groups from data set, such as sensors wireless network, data mining, and multi-criteria decision. In the above example, if there are four fire force teams and each plans to patrol two trouble spots once a time, we can do G-skyline query with two points, the result is {p1, p6}, {p6, p11}, {p1, p11}, {p11, p3}, {p11, p10}, {p11, p8}, so the fire force can select some groups from result for patrolling based on actual situation, and the query result can support the decision.
Although some existing algorithms can do group skyline query, they either need too much computation 3 or cannot get complete candidate groups.2,4 G-skyline is a complete candidate set since it contains all Pareto optimal groups, but a time-consuming algorithm returning an oversized candidate set is far from practical. 3 The group skyline with specific function can only return the result corresponding to the function, but it cannot contain all Pareto optimal groups. 4 So a complete and efficient algorithm is needed urgent.
Contributions
We summarize our main contributions in brief as follows.
We define the key skyline layers which are necessary for computing G-skyline and present a new method based on multiple query windows to compute key skyline layers efficiently.
We optimize the structure of directed skyline graph (DSG) and present a new method to construct DSG with less comparison.
We propose a fast algorithm to compute G-skyline. We define the primary points which play a major role in G-skyline and prove some key rules to prune useless data, then propose an efficient algorithm to compute group-based skyline as mentioned earlier.
The experiments are performed based on the real-world sensor data and three kinds of synthetic data.
Organization
The rest of this article is organized as follows. In section “Related works,” we review the related works to our research work. In section “Key skyline layers,” we give some basic definitions and theorems, define the key skyline layer, and present a new method to build it. Section “Directed skyline graph optimization” presents the optimized DSG and the algorithm to construct it. Section “Computing G- skyline groups” presents key rules and the efficient algorithm to computing G-skyline. Section “Experiments” shows the experimental results by comparing our algorithm with other existing algorithms. At last, we conclude our research work in this article and propose the future work.
Related works
In this section, the previous related work on skyline query is explored. After Borzsonyi et al.’s 1 original work to present the skyline operator in 2001, lots of researchers have done much work on skyline query in many filed, so many methods about skyline have been presented for different problems.
In article, 1 Borzsonyi presented BNL algorithm and D&C algorithm which were first to do skyline query. SFS 5 returned the skyline result by sorting the data set according to the monotone function. Bitmap 6 computed skyline by querying vectors mapped from points in data set. In NN 7 algorithm, the nearest neighbor points were filtered to compute the skyline result. Liu et al. 8 proposed a query window to compute skyline efficiently by pruning most useless data.
Besides, variants of improved skyline algorithms for the specific applications were presented. The sub-space skyline9–11 can return skyline based on user’s different preference. K-dominant skyline12,13 can return the candidate points when the points dominate each other with difficulty. Top-k skyline14–18 returned the first k points in ranking by a function, and it was suitable for queries that have specific requirements for the number of results. Kim et al. 19 and Zaman et al. 20 introduced MapReduce technology to do skyline query on distributed database efficiently. Not only that the probabilistic skyline21–23 was also presented to do query on uncertain data set which was different from data set in above algorithms. Previous articles24–27 proposed the skyline query in data stream in which the points had lifetime. Li et al. 28 studied the skyline query based on a road-social network consisting of a road network and a location-based social network.
Few articles4,29–32 discussed different skyline applications in WSNs, such as continuous reverse skyline, spatial skyline, distributed dynamic skyline, and probabilistic skyline query in the WSNs.
In recent years, group-based skyline query has been focused on by researchers increasingly.3,4,28,33–41 Previous articles33–36 computed top-k composition skyline. Few studies37–39 did combination skyline query based on composition function, which computes the value of the same attribute of k points. In these methods, each k points can be regards as a virtual point with the same attributes of the source data, and the composition functions were usually simple aggregate functions, such as SUM, MAX, or MIN. Guo et al. 40 proposed skyline group algorithms with composition function in data stream based on the algorithms in articles.37,38 Dong et al. 41 proposed G-skyline query over data stream in WSN. Zhu et al. 4 evaluated most existing algorithms based on two types of definitions in terms of time and space on various synthetic and real data sets.
However, there is an obvious flaw about such combination skyline query with function that is really hard to choose an exact composition function for group in practical application. In other words, the groups returned by these algorithms are not complete as not all Pareto optimal groups can be returned. In order to capture all Pareto optimal groups, Liu et al. 2 presented a new definition named group-based skyline (G-skyline), and it defined the dominance relationship between two groups by finding two permutations satisfying certain conditions. The G-skyline query can return all Pareto optimal groups which contain the result captured by previous algorithms with composition function. In fact, this method needs much computation and running time, so Yu et al. 3 proposed an approach to do the search concurrently on each dimension and investigated each point in sub-space, then presented a structure to construct G-skyline. However, there is still much work to do to improve the efficiency of computing G-skyline.
Key skyline layers
In this section, we will explain the basic definitions and theorems, then we define and prove key skyline layers which are important for computing G-skyline and propose the efficient construction method later.
Definitions and theorems
Definition 1 (dominate)
Given a data set P, point p dominates point q if p is not worse than q in each dimension and p is better than q in at least one dimension, where p and q are in P. 1 We can use symbol “≺” to present “dominate.”
Definition 2 (skyline)
The skyline of data set P consists of all the points not dominated by any other points in P. 1
Definition 3 (g-dominante)
For two different groups G1 = {p1, p2,…, pk} and G2 = {q1, q2,…, qk} constructing from the same data set P, we can say G1 g-dominates G2, if two arrays with k points for G1 and G2 are found, G1 = {pn1, pn2,…, pnk}and G2 = {qm1, q m2,…, qmk}, and pni ≤ qmi for each i (1 ≤ i ≤ k) and at least one j, pnj dominates qmj (1 ≤ j ≤ k). 2
Definition 4 (G-skyline)
G-skyline is a set which consists of all the groups not g-dominated by any other groups with the same size. 2 We use G-skyline(k) to denote the G-skyline with group size k.
Example 1
The G-Skyline is Pareto optimal skyline, and it is different from traditional skyline, composition skyline, 39 or skyline groups.4,38,40 In fact, the latter two case are same. We take an instance to illustrate the difference between G-skyline and them. In Figure 1, let G1 = {p6, p8, p11} and G2 = {p2, p3, p10}, according to g-domiante definition, we can find two enumerations {p6, p8, p11} and {p3, p2, p10} where p6 dominates p3, p8 dominates p2, p11 dominates p10, so we can say G1g-dominates G2; according to combination dominate definition, 39 G1={(8+20+16), (260+180+60)}= {44,500} and G2={(14+24+28), (340+380+100)} ={66, 820} if we set SUM as combination function, we can say G1 dominates G2. However, if G1 = {p3, p6} and G2 = {p1, p11}, we can get that G1 and G2 do not g-domiante each other, but G2 dominates G1 if we set SUM as combination function. So we can see that G-skyline can return all the Pareto optimal skylines but composition skyline cannot.
Definition 5 (skyline layers)
All the points in data set P can be divided into several skyline layers, where layer1 consists of all the traditional skyline points of P, and layeri is P.
2
We use
Theorem 1
If a group G = {p1, p2,…, pk} is a G-skyline group with size k, then all points in G belong to the first k skyline layers. 2
Theorem 2
If there is a non-G-skyline group G with k points, when another point from G’s tail set is added to it, this new group with k + 1 points is not a G-skyline either. 2
Theorem 3
For each point p of a G-skyline group G, all of its parents must be in G too. 2
Computing key skyline layers
Skyline layer is very useful for computing G-skyline, so much previous work focus on how to compute all the skyline layers. However, computing the first k skyline layers of P is more important, and it is indispensable for most of previous work about group skyline method.2,37,38 Several articles2,37,38 have proved that the G-skyline has nothing to do with other layers but the first k layers. But, very few articles do some deep research on the first k layers, even if the skyline layers are mentioned in some article, there is not much deep research work on them. So, in this subsection, we present the notion of “key skyline layers,” and propose an efficient method to construct the first k skyline layers which are key for computing G-skyline.
Definition 6 (key skyline layers)
According to Theorem 1, we find that if we want to compute G-skyline with group size k, we only test the points in the first k skyline layers, and the points in other layers have no effect on the query result. So we define these first k skyline layers as key skyline layers which can be written
Obviously, the KSL are indispensable. Different from the existing methods, we present a new method based on multiple sliding query windows to construct layers simultaneously.
Definition 7 (dominant region)
Given a data set P and a point p, dominant region of p is defined as: D(p) = {e| eϵP, p < e } . In a two-dimensional case, D(p) is a set of points in the upper right area of p.
Property 1
If a point eϵ D(p), the layer of e must be larger than that of p.
Proof
Assume that layer(e) is not larger than layer(p), then there are two specific cases: layer(e) < layer(p) or layer(e) = layer(p). If layer(e) < layer(p), then e maybe dominate p, or e and p do not dominate each other; if layer(e) = layer(p), then these two points are in the same layer, and they do not dominate each other. So, we can conclude that the hypothesis is false.□
Basic algorithm for layer
Through skyline layers’ definition we know that each layer is actually the skyline of the data set except the points in previous layers. In this subsection, we introduce a method to compute the traditional skyline. Liu et al. 8 propose an algorithm for skyline query based on sliding window. We use two-dimensional space to expound the method framework. The data set is stored in an R-tree based on MBR (Minimal Bounding Rectangle), where the MBR is an n-dimensional rectangle which is the bounding box of the spatial object. 42
Begin. The data are stored in R-tree. Such as the gray area shown in Figure 2, query window q is constructed from origin 0, and its length q. length is the distance from the MBR closest to the Y-axis to the Y-axis, and its width qwidth is the distance from the MBR which is the farthest from the X-axis to the X-axis.
Core process. The point which falls into the query window q will be inserted to skyline set L, L = {a}. Next, as shown in Figure 3(a), query window q is updated with point a as its left-top vertex and its width qwidth = |a.y,| then qlength increases from 0 to until any points fall into the query window. When point i falls into the query window, i.y≠a.y, so point i is inserted to L, and L = {a, i}. Query window q is constantly updated (such as the gray area in Figure 3) when a new skyline point returned and then continue to do the query. This process repeats itself to compute each skyline point.
End. As shown in Figure 3(d), when the right boundary of query window q reaches the right boundary of the rightmost MBR, the method stops and returns the final skyline points: a, i, m, and k.
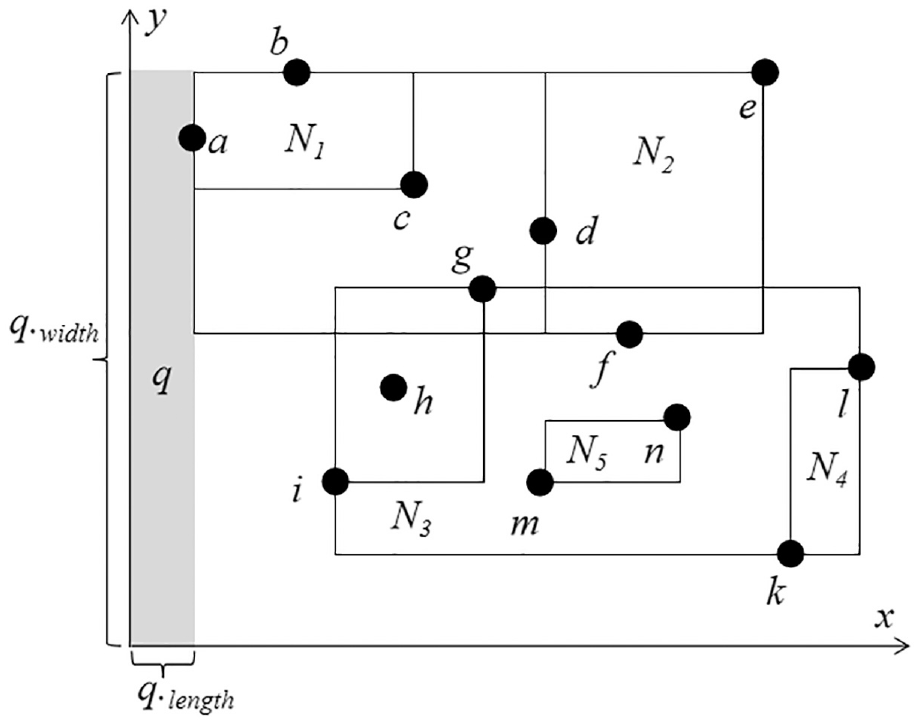
Sliding query window.

Query process.
This algorithm based on query window reduces the query area by changing the query window constantly and does not need to visit all points in the space, which greatly reduces the number of points to be visited.
Key skyline layers algorithm
The existing methods either compute all the layers 37 of the whole data set or needs much comparing computation 2 for getting the first k layers. Yu et al. 3 visit the points concurrently in each dimension, who used binary search and sub-space skyline to investigate each point, and each point needs to be compared with all the points visited by hyperplane, so the computation is much.
According to skyline layer definition, each layer is actually skyline of the data set except all the points in previous layers. Therefore, we propose a new algorithm to compute KSL by visiting less points with less comparison, more importantly, and our algorithm can return multiple layers simultaneously. The detailed procedure is introduced below, and the notations used in algorithm are shown in Table 1.
List of notations.

Our main idea is to create and slide multiple query window (one main window and some children windows) over the points concurrently, to determine which layer the point belongs to for every point visited. We show the detailed process in Algorithm 1. First, all the points are stored in R-Tree, and we initialize KSL(i) = null, each point qi.visited = false. Second, we construct the main query window (MQW) to find the first point of each layer, the MQW only visits the points not been visited by any query window, we use pvisited to denote whether point p has been visited by any query window (lines 1–4). When a point is visited by MQW, a new child query window (CQW) with this point as its left-top vertex will be born from MQW (lines 6 and 7), and this CQW will slide and visit the points for new layer. When a point e is visited by CQWi, evisited is set true to indicate this point has been visited by a query window, then if e.y is the smallest in the points visited by this window, it must belong to layeri (lines 9–12). The CQWs and MQW continue to slide (lines 13 and 14). The key is that CQW created later must slide after CQW created early, and the MQW is the last one. Each query window is independent, and the points visited by a query window must not be visited by any other query windows, as one point only belongs to one layer. Certainly, the query window created early will stop early too. With these query windows sliding, each layer can be returned, and the lower layer will be returned earlier than the higher ones. When the first point of the kth layer is visited by MQW, this window can stop as we only want to compute the first k layers.

Example
We show an example of Algorithm 1 in Figure 4 based on the data in Figure 1, we aim to compute KSL with k = 3. Figure 4(a) shows the MQW with point p1 as its right-top, and p1 is first visited by MQW, so it is inserted into KSL(1), KSL(1) = { p1}. Then a CQW 1 is born from MQW with p1 as its left-top, as shown in Figure 4(b), CQW 1 extends to the right until it visits point p6 which is inserted to KSL(1), KSL(1) = {p1, p6}. At the same time, MQW continues to slide the data set after CQW 1 .

Steps of computing skyline layers. (a) KSL = {{p1}}. (b) KSL = {{p1, p6}}. (c) KSL = {{p1, p6, p11},{p3}}. (d) KSL = {{p1, p6, p11},{p3, p8}}. (e) KSL = {{p1, p6, p11},{p3, p8, p10},{p2}}. (f) KSL = {{p1, p6, p11},{p3, p8, p10},{p2, p5}}. (g) KSL = {{p1, p6, p11},{p3, p8, p10},{p2, p5, p12,p9}}.
Figure 4(c) shows that CQW 1 visits p11 which belongs to KSL(1), and MQW visits p3 while p3visited = false, so at this time, CQW 2 is born from MQW with p3 as its left-top to begin computing KSL(2), KSL(2) = {p3}. There is an overlap between MQW and CQW 1 .
Next, as shown in Figure 4(d), the algorithm updates CQW 1 with p11 as its left-top to continue to slide the data set and updates CQW 2 with p3 as its left-top. When CQW 2 visits p8, KSL(2) = {p3, p8}, and from now on, there is no point to be visited by CQW 1 , so we can conclude KSL(1) = {p1, p6, p11}. There is an overlap between CQW 1 and CQW 2 .
In Figure 4(e), CQW 2 visits p10, and KSL(2) = {p3, p8, p10}, at the same time, MQW visits p2 and p2visited = false, so KSL(3) = {p2} and CQW 3 will be born. There is an overlap between MQW, CQW 1 and CQW 2 .
As shown in Figure 4(f), MQW stops as we only want to compute KSL with k = 3, so MQW needs not to continue, at the same time, three CQWs continue to slide the data set until they reach the right boundary of the rightmost MBR. There is an overlap between CQW 1 , CQW 2 , and CQW 3 . The final result is KSL(1) = {p1, p6, p11}, KSL(2) = {p3, p8, p10}, and KSL(3) = {p2, p5, p12, p9}. It is worth noting that the order of birth for query windows is CQW 1 , CQW 2 , and CQW 3 , and these windows do query in this order too, in other words, the window generated earlier is in the front of queue and MQW is the last one. The final skyline layers are shown in Figure 4(g).
Directed skyline graph optimization
Liu et al. 2 first proposed the directed skyline graph (DSG) to reflect the domination relationships between points. However, it must compute all the relations between points, and it needs lots of computation as one point should to be compared with all the points in the previous layers even though some relations are transitive or useless. In fact, the useless relationships are unnecessary to compute, and the transitive relationships can be derived by the existing relationships. In this subsection, we propose the new algorithm to optimize DSG construction to make the computing more effective.
Computing DSG for two dimensions
For two dimensional space, we present some properties for DSG which will be used for G-skyline.
Property 2
Given a point p in layeri and another point q in layeri + j , if p does not dominate q, then we can conclude that p.x < q. x and p.y > q.y, or p.x > q.x and p.y < q.y.
Proof
It is obvious and easy to prove. If p does not dominate q, and the layer of p is lower than q, then either p locates at left-top to q, or p locates at rightbottom to q.□
Property 3
Given a point p in layeri and another point q in layeri + j , if p dominates q, then all the parents of p must be q’s parents.
Proof
Point t, as a parent of p, certainly dominates p, so if p dominates q, then t must dominate q.□
Property 4
Assume that all the points in the same layer are sorted by x-coordinate, for a point q in layeri, the parents of q in the same layer are sequential in point index.
Proof
There are n points sorted in ascending order by x-coordinate in layerj (j < i), such as p1, p2,…, pn. If pk and pm dominate q (k < m), then pk.x < q.x, pk.y < q.y, and pm.x < q.x, pm.y < q.y. For any one point pa (k < a < m) in the same layer, there must be pa.x < pm.x and pa.y < pk.y, so we can conclude that pa.x < q.x and pa.y < q.y, so pa must dominate q.□
Based on the skyline layers, we compute the DSG from low layer to high layer, and we start at the second layer as the points in layer1 has no parent. For every point p in layeri, first it should be compared with the points in layeri–1, we should find the maximal index where the point is less than p in x axis, then scan each point in the opposite directions of the x axis, when a point not dominating q is visited, the scan stops and q’s parents in layeri–1 are returned (lines 3–6).
In order to find p’s parents in other layers, there is no need to compare p with all the points in each layer. As the DSG is built from low layer to high layer, so when the points in layeri are checked, DSG has been constructed in precious i–1 layers, we should first find the least parent pl in layeri–2 of the least parent of p in layeri–1, and the maximal parent pm of the maximal parent of p in layeri–1, then all the points between pl and pm are also p’s parents (lines 8–10). On the other hand, we should visit the points less than pl and bigger than pm with index in both two directions until a point not dominating p is visited respectively (lines 11–20).
Do the same computing as above until all the parents of p is found. We can use this method to construct DSG of all the points in the first k layers. In this way, when finding a point’s parents, we need not to compare it with all the points in previous layers. Doing it like this takes full advantage of intermediate result to avoid much redundant computations.
Example
We show an example of Algorithm 2 based on the data in Figure 1(a) and its skyline layers in Figure 4(g). The points in each layer are sorted in ascending order in x axis, such as: p1, p6, p11; p3, p8, p10; p2, p5, p12, p9. We begin the computation from the second layer. Point p3 is the first one to be visited, it should be compared with the points in layer1, we find that the maximal point which is less than p3 in x axis is p6, and p6 can dominate p3, we get p3.parent = {p6}. Then we continue to scan layer1 in the opposite directions of the x axis, when p1 is visited, we find that p1 cannot dominate p3, so this scan stops. The layer which is lower than layer2 is only layer1, so we can get p3.parent = {p6}. We use the same method to get p8.parent = {p11}, p10.parent = {p11}. In layer3, for point p2, we should compare it with the points in layer2 first, we find the maximal point which is less than p2 in x axis is p8, the minimum point is p3, we can get p2.parent = {p3, p8} in layer2, then we continue to find p2’s parents in layer1. The minimal parent of p3 is p6, and the maximal parent of p8 is p11, so the points between p6 and p8 in layer1 are also p2’s parents. Then we continue to visit points with index larger than p11 and the points with index smaller than p6, but there is no p2’s parent any more. So we can get p2.parent = {p8, p11, p3, p6}. We use the same method to get p5.parent = {p8, p11, p6}, p12.parent = {p8, p11}, and p9.parent = {p10, p11}. The final DSG is shown in Figure 5. We can see that our method can take full advantage of intermediate result about point’s parents and greatly reduces the amount of computation.

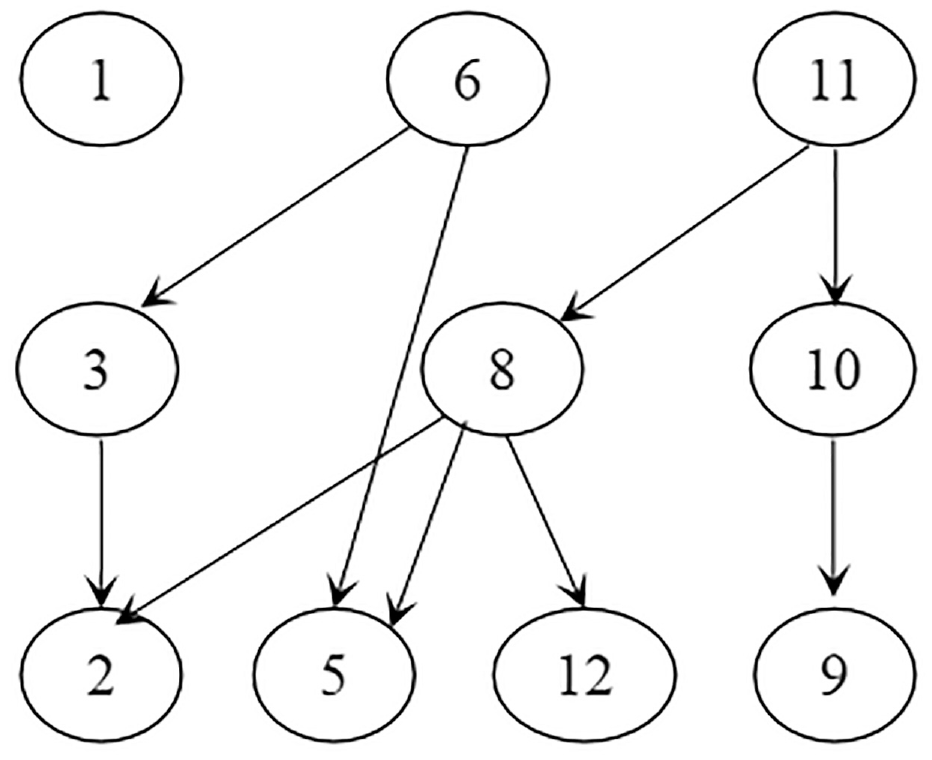
DSG.
High-dimensional space
For the data set with higher dimensional space, we can use a method similar to Algorithm 2 to compute DSG. The points are visited from layer2 to higher layers one by one. For each point p to be computed in layeri, we should compare it with points from layeri–1 to layer1. For the points in layerj(1 ≦ j < i), some parents can be returned directly by transitive relation, then the points except these parents are sorted by x-coordinate in ascending order, the points in front of p are selected to form a set D1, then all the points in D1 are sorted by y-coordinate in ascending, the points in front of p are selected to form a set D2, and then doing it like that in another dimension until Dd is returned where d is dimension size of the data set, and all the points in Dd are the parents of p. Similar to the Algorithm 2, as the DSG with first i–1 layers has been constructed, so when layerj is visited, the points which are already p’s parents by transitivity are no longer involved in the calculation.
Computing G-skyline groups
In this section, we present a new algorithm to compute G-skyline efficiently based on properties and methods above. First, we give some theorems and definitions.
Primary points
Theorem 4
A point in a G-skyline group cannot be dominated by a point outside this group. 2
Theorem 5
Given a point p, if p is in a G-skyline group, p’s parents must be included in this G-skyline group. 2
Theorem 6
As a G-skyline group c, it must satisfy one of two conditions: the points in c are either all traditional skyline points, or some are traditional skyline points and others are not, but for each point of these others in c, it must be dominated by some traditional skyline points in c and it cannot be dominated by any point outside c.
Proof
Given a G-skyline group c = {p1, p2,…, pn, q1, q2,…, qm}. If each point of c is traditional skyline point, we cannot find another point dominating it, so there is no group with same size can g-dominate group c; therefore, group c is G-skyline group according to definition 4. If p1, p2,…, pi are traditional skyline points and q1, q2,…, qx (x≦m) are not, according to Theorem 5, we get that for each point qj (1 ≦ j ≦ x), its parents must be in group c, and it will be dominated by at least one traditional point, and according to Theorem 4, it cannot be dominated by any point outside c. Any group not satisfying one of above conditions must not be G-skyline group.
For any other groups, there are other two kinds conditions: there is no traditional point in c, or c consist of some traditional skyline points and some other points whose parents are not in c. If a group satisfies one of these two conditions, we can easily find another group g-dominating it, and this group must not be G-skyline group.
Each G-skyline group consists of points in the first k layers, but these points are not evenly distributed across these k layers. In fact, the traditional skyline points have stronger domination and they play vital important in G-skyline.
Definition 8 (Primary points)
For G-skyline, the points in layer1 are primary points. According to Theorem 6, each G-skyline group must contain at least one point in layer1.
Definition 9 (Secondary points)
The points in G-skyline groups which are not primary points are secondary points.
Lemma 1
The higher the layer, the less role the data points in that layer play in computing the G-Skyline.
Proof
This lemma is easy to prove. When the layer is higher, the points in this layer will have less dominant power, and the number of points dominated by which will be less. For a G-skyline group, the point in which and all its parents are must in this group, so if a point has less dominant power, there is less chance for it to be in a G-skyline group, so this kind of point will play less role in computing G-skyline.□
Example
We use a synthetic data set containing 1000 points with three-dimensional space to show the proportion of primary point and secondary point in the G-skyline groups. When k = 3, there are 68 points in layer1, 126 points in layer2, 163 points in layer3, and 69,246 G-skyline groups. The number of times the primary points and the secondary points appear in G-skyline are respectively 197,975 and 9763. We find that the proportion of occurrences of primary points is 197,975/(197,975 + 9763) ≈ 95.3%, and the proportion of occurrences of the points in layer2 is about 4%, the proportion of occurrences of the points in layer3 is about 1%.
Table 2 shows the proportion of primary points in G-skyline on different data set with varying parameters, while data set size is 1000. From the statistical data we find that the proportion of primary points occurrence in G-skyline groups is very high, up to 90% most time. We can infer the conclusion: primary points play an important role in formation of G-skyline groups.
Percentage of primary points.

The primary points in layer1 have higher dominant power, the groups including some of them can dominate many groups composed by points in other layers based on above theorems. We find it is crucial and necessary to enumerate the groups composed by all primary points and propose a method to compute groups extended by primary points. On the contrary, the number of secondary points is relatively small, although it increases slightly with k increasing, these secondary points play a minor role in computing G-skyline groups all the time. That is to say, most groups composed by points in higher layers are useless for G-skyline and should be filtered directly.
Based on above motivations, we propose a new algorithm computing G-skyline groups directly by extending primary points according to our rules instead of visiting a large groups consist of lots of useless groups, and our algorithm needs not compute G-skyline (k) from G-skyline(k–1) recursively.
Highly-efficient method for G-skyline
In this subsection, we propose a highly effective algorithm to compute G-skyline. As the primary points play vital role in G-skyline groups, first, we enumerate all the groups composed of points in layer1, then each group is extended by adding its eligible children in next layer. For each candidate group G, we should test its every point to find eligible children in next layer, then enumerate these children and combine each enumeration with group G to construct new candidate group. How to find the eligible children to be combined with group G? Each eligible child p must satisfy—p.parent|< k and all of p’s parents are in group G. If—p.parent| ≧ k, we can prune p and its children directly according to Rule 1. How to enumerate the combinations consist of G’s children? Based on the eligible children, we enumerate all combinations with size not larger than k–|G,| and combine these combinations with G respectively. Thus, we check and extend each candidate group in the same way until we get all the G-skyline groups.
Besides the previous definitions and theorems, we present the key rules to be used in computing G-skyline groups.
Rule 1
We use p.parent to denote all parents of point p. If—p.parent—≥ k–1, the children of p can be pruned.
Proof
If—p.parent—≥ k–1, that is to say, for any child q of p, there must be—q.parent—≥ k. For any group containing point q with size k, it cannot contain all parents of q, so according to Theorem 5, we can conclude that q must not be in G-skyline group.□
Rule 2
For each point p in layeri, if—p.parent|≥ k–1, we should not check any other points in layerj where j > i.
Proof
From Rule 1, we find that if|p.parent| ≥ k–1, the children of p can be pruned, so if this condition is suitable for all points in layeri, we should not visit the points in higher layerj (j > i), and these points can be pruned directly.□
First, we should enumerate all the groups composing of primary points with group size not larger than k, and use symbol S to represent these groups (line 1). We use these groups as the starting for computing G-skyline. For each group gi in S, if it is G-skyline group with size k, it can be output directly (lines 3 and 4), or we will check if it has eligible children. For each point q of group gi, we should find all its children in next layer, and store these children in a set C (lines 6 and 7), then we check whether each point in C is eligible point. For a point p in C, if|p.parent|> k–1, it and its children can be pruned directly according to Rule 1 (lines 9 and 10), else if p’s parents are not all in C, it is not suitable to be combined with group gi according to Theorem 5 (lines 11 and 12). After doing it like this, if C is not null, then we enumerate all the combinations with size not bigger than k–|G,| then combine each with gi to construct new candidate group inserted into S (lines 13–16).
Example
Figure 6 shows an example of Algorithm 3 to compute G-skyline(3) based on the data set in Figure 1. Figure 6(a) shows the DSG of data set with solid arrow indicating dominant relationship, and each point has a tag to indicate the number of its parents. In Figure 6(b), the symbol “—” means stop, and the symbol “√” means the group is a G-skyline group.

An example to find G-skyline when k = 3: (a) DSG and (b) G-skyline.

First, All points in layer1 are enumerated to output groups which are basic to compute G-skyline, these groups are {p1}, {p6}, {p11}, {p1, p6}, {p1, p11}, {p11, p6} and {p1, p6, p11}. Next, we will check each group to output G-skyline groups, or combine it with some of their children groups.
For group {p1}, it has no child, so it does not need to be extended.
For group {p11}, the layer of its single point is layer1, it has two children p8 and p10 in layer2, because|p8.parent| and|p10.parent| are both smaller than 3, and their single parent is in group {p11}, so we enumerate and combine these two children with group {p11}, then get three groups {p11, p8}, {p11, p10} and {p11, p10, p8}. Obviously, {p11, p10, p8} is a G-skyline(3) group. Point p8 has three children, but only p12’s parents are all in group {p11, p8} and|p12.parent| = 2 < 3, while|p5.parent| = 3 and|p2.parent| = 4 > 3, so only p12 can be combined with {p11, p8} to construct new G-skyline group {p11, p8, p12}. Doing it like this, we can get a G-skyline group {p11, p10, p9} by combine {p11, p10} with p9 which is p10’s single child.
Such as group {p11, p6}, two points are in the same layer1, so we only consider their children in layer2. In layer2, we find the child of p6 is p3, and the children of p11 are p8 and p10. Point p3 with|p3.parent|< 3 can be combined with group {p11, p6} to construct {p11, p6, p3} as its parent is only p6 and p6 is in this group, so this new group is a G-skyline(3) group. Similarly, p8’s parent and p10’s parent are only p11, so p8 and p10 can be separately combined with group {p11, p6} to construct {p11, p6, p8} and {p11, p6, p10}, and these new groups are also G-skyline(3) groups.
Other original groups are processed in the same way, and the final result is shown in Figure 6(b), and each G-skyline group is marked by tick. In this way, we can quickly compute G-skyline groups gradually.
Experiments
In this section, we show the experimental test on our methods in efficiency and correctness. The test programs are written in Java, and run in a PC with Intel Core i7 processors, 512G SSD and 16G RAM. The synthetic data set and real sensor data set are used in the process of experiment.
Experiment preparation
In order to test and evaluate the algorithms in different aspects, and keep the universality of algorithms, we adopt synthetic data set and real-world sensor data set, respectively, to test our algorithms.
After the skyline query was proposed and the experiments were carried out based on three different kinds of synthetic data set, 1 most of experiments about subsequent skyline query algorithms are also carried out based on these three kinds of data set. So in our experiments, to test the processing effect of the algorithm on different types of data, three kinds of synthetic data sets are generated 1 for experiments: the correlated data set (COR), the independent data set (IND) and the anti-correlated data set (ANTI-COR). The examples of three kinds of synthetic data set with two dimensions are shown in Figure 7. We can find that their distributions are different from each other: the two coordinates of the correlated points have the same variation trend, and this kind of points which are good in one dimension are also good in other dimension; while the two coordinates of the anti-correlated points have the opposite variation trend, and this kind of points which are good in one dimension are bad in other dimension; however, the two coordinates of the independent points have no relation in the variation trend. For the correlated data set and the anti-correlated data set, the points are generated by selecting a plane perpendicular to the line from (0,…, 0) to (1,…, 1) using a normal distribution, while for the independent data set, all attribute values of points are generated independently using a uniform distribution. The real-world sensor data set is obtained from a forest environment monitoring project, which includes temperature, humidity, daily rainfall, daily evaporation and daily temperature range. In order to ensure the stability of the experimental results, each experiment is repeated 100 times and the average value is used as the final result.
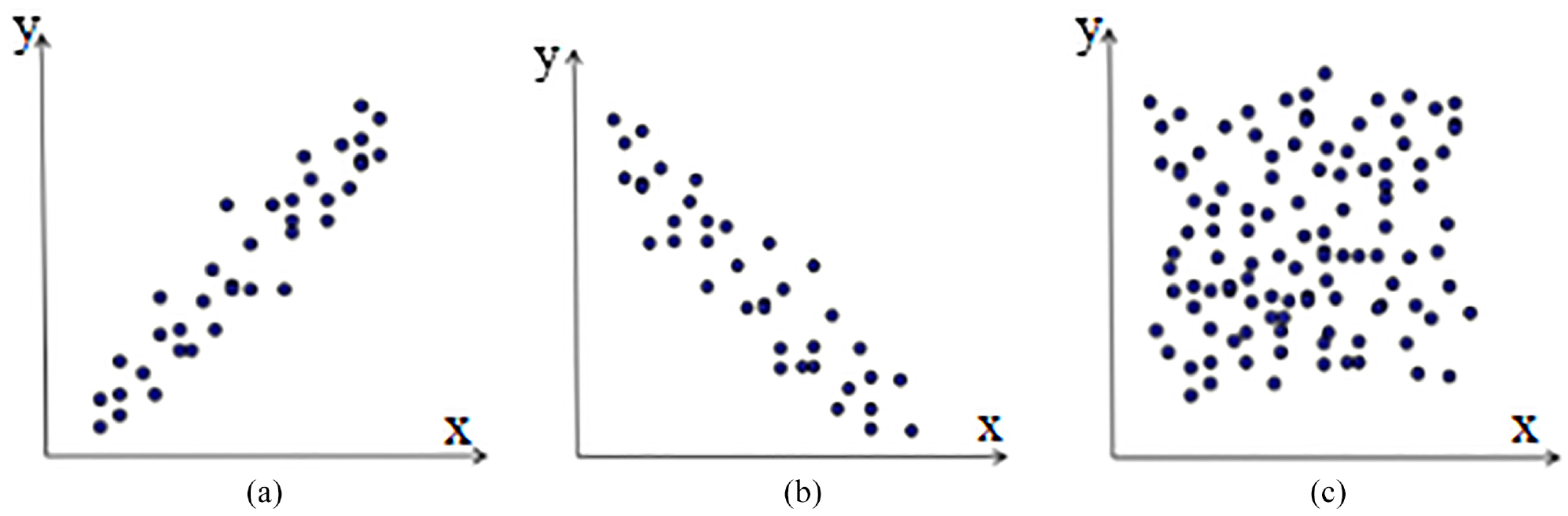
Example of synthetic data set: (a) COR, (b) ANTI-COR, and (C) IND.
In order to compare our algorithms with other existing algorithms presented in recent years, we select point-wise algorithm (PWA) and fast pwise algorithm (FPA) to participate in the comparison, as PWA is the first G-skyline query algorithm and FPA is the improvement based on PWA. Although FPA can prune the edge for DSG to make the algorithm more effective than PWA, it need much time to find each G-skyline groups by comparison yet. Our algorithm not only optimize the skyline layers and DSG computing, but also present a new method to find G-skyline groups directly based on skyline layers and DSG. We choose these two algorithms to compare with our algorithm in order to find out the superiority of our algorithm in execution efficiency. The algorithms to be tested in the experiments are as follows.
Key skyline layers on synthetic data
In this subsection, we test the methods for computing key skyline layers on synthetic data set. Figures 8–10 show the running time cost of computing key skyline layers by algorithm PWA, FPA and KSL.

Computing key skyline layers with different k: (a) COR, (b) IND, and (C) ANTI-COR.

Computing key skyline layers with different n: (a) COR, (b) IND, and (C) ANTI-COR.

Computing key skyline layers with different d: (a) COR, (b) IND, and (C) ANTI-COR.
Figure 8 shows the running time cost for computing key skyline layers by each method with varying group size k (n = 1000, d = 2). We find that the running time of PWA and FPA is bigger than KSL especially when the group size varies from 6 to 14; however, when k is not big (Figure 8, k = 2 and k = 4), there are not many points in first k layers, our method is not much faster than other two methods. But our method performs better with group size k increasing, as some query windows are working at the same time.
Figure 9 shows the time cost of computing key skyline layers by each method with varying data set size n (k = 6, d = 2). We find that the running time of these methods increases very fast with n increasing, the time growth trend is close to linear growth, as the amount of computation is closely related to the amount of data set. However, when n is larger than 104, our method performs much better than others as the query windows are smaller and smaller, so the number growth of points to be visited is slowing down.
Figure 10 shows the time cost of computing key skyline layers by each method with varying dimension size d (n = 10000, k = 4). We find that PWA and FPA algorithms needs much time with d increasing, the reason is that each point should be compared with all existing points in PWA, while FPA wastes some time to update the sub-space skyline. The chance for one point dominating another point will be smaller with d increasing, and the points in the first k layers will be more with d increasing, so each method will need much time. However, our method performs better than other two, as it can visit different layers by some query windows at the same time.
G-skyline on synthetic data
In this section, we show the experimental results of methods for computing G-skyline based on different synthetic data set. As the time cost of computing skyline layers is shown in 6.2, we only record the time cost except skyline layers time cost to compare the efficiency of methods for finding and outputting G-skyline groups.
Figure 11 shows the time cost and output size of three methods to compute G-skyline groups with varying data set size n (d = 2, k = 3). We find that the time cost increases faster and faster from COR data set, IND data set to ANTI-COR data set, the reason is that there will be much points in the first k layers for ANTI-COR data set, so the computation will be larger than other two data sets. The output size increases about linearly with the increasing of n.
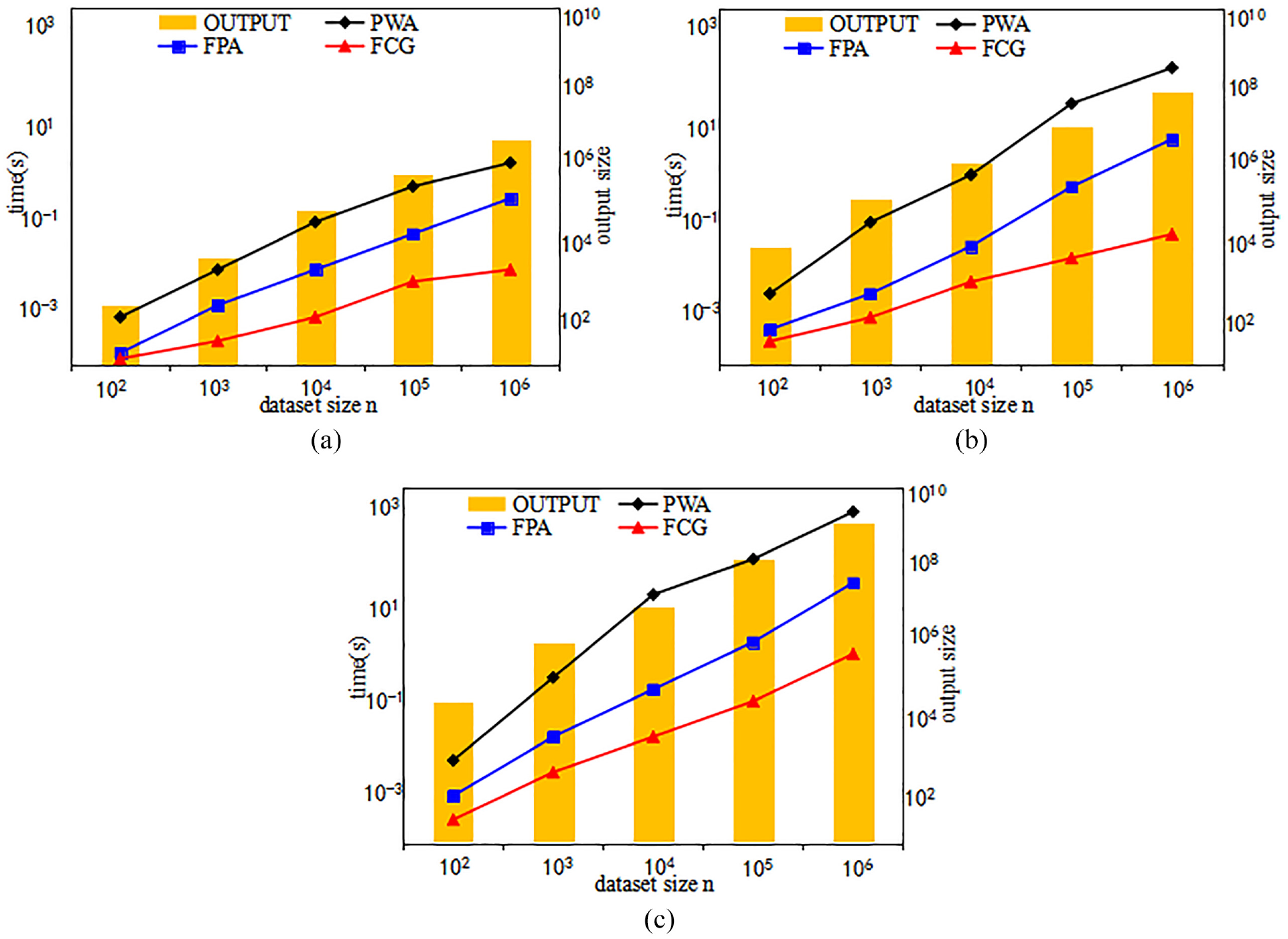
Computing G-skyline with different n: (a) COR, (b) IND, and (C) ANTI-COR.
Figure 12 shows the time cost and output size of three methods to compute G-skyline groups with varying group size k (d = 2, n = 10000). We find that the time cost is greatly influenced by varying k, as there will be more points to be computed with k increasing, at the same time, we find the output size increases fast with k increasing. However, our algorithm performs better, as our filtering policy is efficient to prune more useless data as early as possible.

Computing G-skyline with different k: (a) COR, (b) IND, and (C) ANTI-COR.
Figure 13 shows the time cost and output size of three methods to compute G-skyline groups with varying dimension size d (k = 3, n = 10000). We find that the time cost increases fast with d increasing, as the number of points in the first k layers will be more and more with d increasing, and the number of groups to be tested will be more accordingly. However, the growth rate of the time cost tends to slow down when d is larger than 6 approximately, as the most points locate in the first k layers when d increases, so even if d continues to increase, the number of points in the first k layers increases slowly.

Computing G-skyline with different d: (a) COR, (b) IND, and (C) ANTI-COR.
Key skyline layers on real sensor data
After all, experiments on synthetic data cannot reflect the processing effect in practical application environment. In this subsection, we do experiments on real sensor data to show the effect of processing real data by algorithms, the experiment results are shown in Figure 14.

Computing skyline layers with different parameters: (a) group size k, (b) data set size n, and (c) dimension size d.
Figure 14(a) shows the result of computing key skyline layers with varying group size k(n = 1000, d = 5), we find that k has obvious influence on the algorithm as the points increase a lot with k increasing while our algorithm performs better than other two methods. Figure 14(b) shows the impact of varying data set size n (k = 3, d = 5) on methods. The change of n does not have much effect on the time cost of methods. The time cost of methods with varying dimension size d(k = 6, n = 2000) is shown in Figure 14(c), they are influenced by d obviously due to most of points in the first k layers with d increasing.
G-skyline on real sensor data
In this subsection, the algorithms for computing G-skyline are implemented on real sensor data set and the result are shown in Figure 15.

Computing G-skylines with different parameters: (a) group size k, (b) data set size n, and (C) dimension size d.
Figure 15(a) shows the time cost for computing G-skyline with varying group size k(d = 5, n = 1000) and the output size. We find that the output size increase smoothly, but the time cost increase quickly with k increasing, the reason maybe that when k increases, there will be more points to be tested. It is worth noting that FCG algorithm is much better than other algorithms PWA and FPA, the reason maybe that the number of points in each layer is similar, so each query window will spend less time to visit points.
Figure 15(b) shows the time cost for computing G-skyline with varying data set size n (d = 5, k = 4) and the output size. An interesting phenomenon is that there is no significant fluctuation in the time cost and output size, and the values of these two parameters are big, the reason maybe that real sensor data set is anti-correlated, so many points locates in first k layers and the number of these points will not change much.
Figure 15(c) shows the time cost for computing G-skyline with varying dimension size d (k = 3, n = 1000) and the output size. We find that the time cost and output size both increase obviously with d increasing, the reason is that point’s domination ability will be weaker when dimension size is big, so more points will locate in the first k layers, and the computation complexity and the output size become bigger accordingly.
Conclusion and future work
In this article, we focused on the problem of finding G-Skyline groups over the data set in the WSN. In order to compute the G-Skyline groups efficiently, we presented a method based on multiple query windows to compute key skyline layers quickly. Then we optimize the DSG method by omitting most computation between the point and its parents in previous layer. Finally, we proved the primary points’ importance for G-skyline and proposed new method to compute G-skyline groups from the enumeration groups of primary points efficiently. The experiment results based on the synthetic data and real data show that our algorithms perform better than others. In the future, we will consider how to compute the G-Skyline groups based on data dispersion analysis in wireless network.
Footnotes
Acknowledgements
The authors thank all the members in database laboratory of Baicheng Normal University and Donghua University.
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Scientific Research Project of Jilin Province (grant nos. JJKH20210005KJ, JJKH20190621KJ, and JJKH20210012KJ), China; Natural Science Foundation of Heilongjiang Province (grant no. LH2019F039), China.