
Abstract
This article focuses on how to effectively make full use of the storage resources in vehicular cloud. A trust mechanism called DI-Trust (Trust Model Based on Dynamic Incentive Mechanism) is proposed to schedule vehicular cloud storage resource. The discussion is under the scenario of the parking lot where vehicle nodes are in static state. The model can reasonably arrange the suitable scheduling algorithm according to the attribute characteristics of different kind of service requirements. The trust value of a vehicle is updated according to the model to fully utilize the vehicle idle storage resources. The simulation experiment results show that the model can work effectively. It can objectively evaluate trust values of vehicle nodes, and construct the effective resource schedule of the vehicular cloud storage resource to meet needs from users.
Introduction
The new development in the field of VANET (Vehicle Ad hoc Network) is the integration of cloud computing and VANET, namely, the Vehicular Cloud (VC), which is similar to the system architecture of mobile cloud computing. The structure of VC 1 can be defined into three layers: the vehicle interior, communication, and cloud layer. The vehicle interior layer is responsible for monitoring or collecting all kinds of information in vehicle through various sensors to send information to cloud for storage. The communication layer involves two basic communication modes of VANET: Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communication. V2V communication takes charge of transmitting vehicle information to surrounding vehicles and clouds in a timely manner. V2I communication is able to accurately understand the traffic conditions within the communication range and improve the safety of vehicles. Cloud layer can not only meet the real-time requirements of vehicle users but also integrate information data to provide users with a variety of services, such as Network as a Service (NaaS), Storage as a Service (SaaS), and Information as a Service (IaaS). It is of great significance to excavate the potential of vehicle resources for the development of the VANET.
The important issues affecting vehicle cloud services are the same as the VANET 2 and mobile ad hoc network (MANET), 3 including data security, user privacy, and access control; the customer’s main desire for a cloud is to get quality service according to his needs and security. Trust mechanism will be helpful to solve these two problems. While there are many challenges to building trust model in a VC. First, the high mobility of the vehicle makes it difficult for a vehicle to evaluate the received data in real time, and then it is difficult to confirm the credibility of a vehicle. Second, decentralized architecture and open environment of the VC make it difficult to collect sufficient information about a vehicle being evaluated and to establish a long-term stable relationship between the vehicles. 4 Third, linking trust to vehicles and the data they may report is important for the VC. 5 Generally, it is a challenge to add trust mechanism reasonably and effectively to ensure the security and integrity of resource scheduling in the process of inter-vehicle resource scheduling. 6
The vehicle cloud resource management strategy of trust mechanism can help the resource scheduling system to operate effectively in an open and dynamic environment. Many scholars have done a lot of research in this field. The proposed trust models are mainly based on vehicle entity-centered trust model, 7 incentive model for suppressing malicious nodes, 8 hybrid trust model for vehicle reliability evaluation, 9 solution for virtual machine migration of vehicle cloud, 10 cooperative adaptive resource scheduling method for vehicle cloud, 11 alliance game model based on bilateral matching theory, 12 and so on.
This article mainly studies two problems. One is the application scenario based on the parking environment, which combines the vehicle node in the parking lot with the cloud server to construct the vehicle cloud platform, and the vehicle node can communicate with the cloud server when providing the service and obtaining the service. However, a trust model is designed to guarantee the scheduling of vehicle node storage resources, and the corresponding algorithm is designed to improve the operational efficiency and network security of the vehicle cloud platform.
Trust model based on dynamic incentive mechanism
Trust model based on dynamic incentive mechanism architecture
This article mainly studies the trust model under the centralized network architecture in the vehicle cloud environment. The application scenario is a large parking lot. There is a public cloud server installed in the parking lot. As shown in Figure 1, wireless communication is used between vehicle nodes and a roadside unit (RSU), and wired communication is used between the RSU and the public cloud. RSUs are responsible for forwarding data communication between the public cloud server and vehicle nodes.

The architecture of DI-Trust model.
Initial trust values of vehicle node
When a new vehicle node enters the environment, it has no transaction record in the cloud server, and in order for it to be added to the environment to provide services, it must be given an initial value of trust. We need to choose an initial value that is appropriate for the entire scenario to avoid the adverse effects of too high or too low. In this article, the value range of the trust value is (0,1). 13 When there are fewer vehicle nodes, the initial service value of the newly added vehicle node is 0.4. When the vehicle node reaches a certain number, the initial trust value of the newly added node will be given to the average value of all exists vehicle’s trust values, which can give the new node a fair chance.
Calculation of trust values
This article synthesizes the characteristics and the interaction scale of the service providing vehicle node to calculate and update its trust value. The calculation of a node’s trust value can be expressed as formula (1)
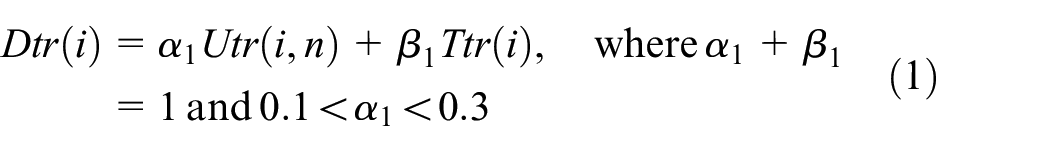
where Dtr(i) represents the total trust value of the service providing vehicle node i, Utr(i,n) represents the characteristic property value of the node i in the last n days, Ttr(i) represents the interactive scale value of the node i.
Calculation of characteristic property value
The characteristic property value is used to count the vehicle node’s recent stay in the parking lot. The longer the stay time, the more regular the parking period, the better it is. In the parking environment, each vehicle node will record its parking time in the public Cloud Server. In the time record table, a day will be divided into four time periods depending on the busyness situation: 0 to 6 o’clock for night parking time period, 6 to 12 o’clock for morning parking period, 12 to 18 o’clock for afternoon parking time period, and 18 to 24 o’clock for evening parking period. With the most recent n days as the cycle, the parking status of a vehicle node in these most recent n days is recorded in the parking schedule. When the public cloud server wants to select service vehicle nodes, it will calculate the parking time coverage of all vehicles in the current time period and the next time period through the parking schedule. As shown in Figure 2, several days parking time information for the vehicle node i is listed. The red block indicates that the vehicle is parked in the parking lot during this time period.
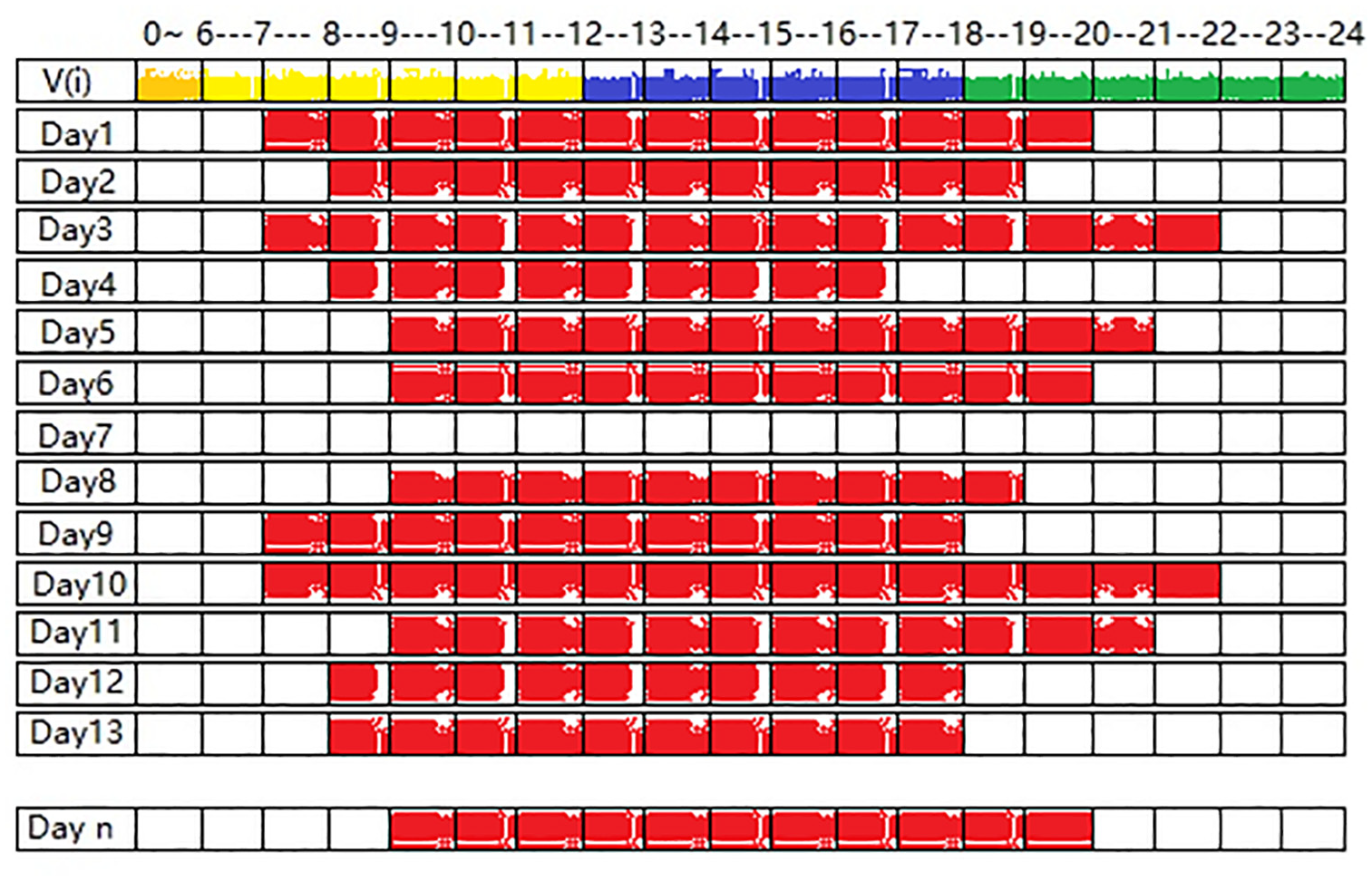
Parking time chart of vehicle node i in the last n days.
The derivation of all formulas in the following and the background of the environment are assumed that the current time is 10:00, and that the other time calculation methods are consistent with the method described below.
Assuming that the current time is 10 o’clock and a vehicle node in the parking lot requests a storage resource service. Then, the public cloud server starts calculating the parking time coverage of all vehicles in the parking lot immediately after receiving that request. And as the current time is 10 o’clock, it is the morning parking period. Therefore, the public Cloud Server only needs to calculate the morning parking period and the afternoon parking time period of the parking data. The advantage of this is that the public cloud server calculates only half of the data in the parking schedule. The calculation method is expressed in formula (2)

In the above formula, η(i,n) means the parking time coverage of the vehicle node i on the nearest n-days,
Here, we add the concept of parking service completion rate to effectively improve the time decay of trust values. There are records in the cloud server that the number of services each vehicle node has provided and the number of services that are finally completed. For example, for the most recent n days, the vehicle node i has provided vtotal services during the morning and afternoon parking periods. The service deposited on node i would be terminated if i left halfway. Then, those terminated services would be regarded as failing services. Mark the number of failed services as vfalse, so the number of services completed by node i in these two time periods is

In summary, the parking service completion rate can be expressed as formula (4)

where φ(i,n) represents the parking service completion rate of the vehicle node i in the last n days, and
By combining the above-mentioned parking time coverage and parking service completion rate, the characteristic property value Utr(i,n) of node i in the recent n days is expressed as formula (5)

where
Calculation of interaction scale value
When the service providing by the vehicle node i ends, node i will obtain the interaction scale value Ttr(i) based on the size of the storage resource it provides and the time length of services. The storage resource is divided into virtual machines in blocks, which can make each piece of storage independent of each other and reduce the damage caused by malicious attacks. Combined with previous history, the size of storage resources provided by a node is expressed as formula (6)

Here,
The time length of services vehicle node i provides will also be synthesized according to its historical record, which is expressed as formula (7)

The symbolic description of formula (7) is similar to formula (6), replacing the storage size with the length of time. According to the actual situation, when a vehicle node provides more services in those two periods in the recent n days, the higher its reliability. The maximum threshold of the interaction frequency is set here to limit the value, which is denoted as
In summary, the interaction scale value Ttr(i) of node i can be expressed as formula (8)

Here
Considering that μ(i, fn) and ρ(i, fn) represent different physical meanings with different units, simply synthesizing from numerical will have a negative effect on the final result
After normalization,

In the above formula, smin and smax represent the minimum and the maximum number of virtual machines provided by node i once a service in the recent n days, respectively. The value of
After normalization, ρ(i,fn) can be calculated as formula (10)
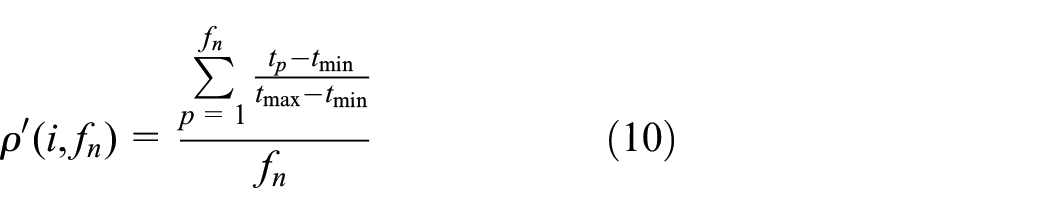
In the above formula, tmin and tmax represent the minimum and the maximum service time length provided by node i once a service in the recent n days, respectively. The value of
In summary, the interaction scale value Ttr(i) of the service vehicle node i providing can be finally expressed as formula (11)
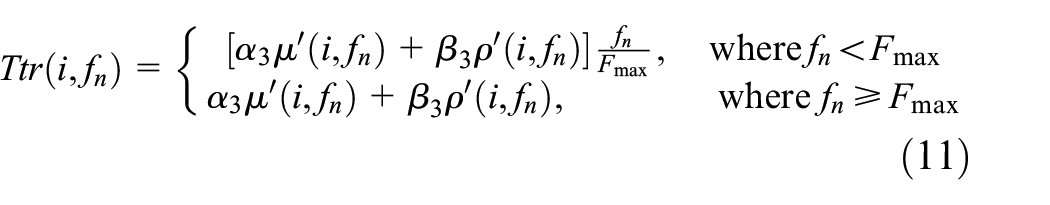
The trust value calculation method described above provides assistance for the screening of vehicle nodes and the evaluation of services in a certain application.
Obviously, the time complexity of this method depends on the number of days n under statistics and the average number of vehicle nodes in the parking lot among n days. And the time complexity of the method is O(n*m).
Table 1 gives the comparison of trust model based on dynamic incentive mechanism (DI-Trust) and other models such as Eigen-Trust/Power-Trust and Peer-Trust. The Eigen-Trust reputation management system can isolate malicious peers in P2P sharing networks. It uses global trust values and a peer node i will compute and store other peer nodes’ trust values according to its own computation. 14 Peer-Trust model is a kind of coherent adaptive model. It introduces three basic trust parameters and two adaptive factors to compute trust values. The main feature of this trust model is that the feedback obtained from other nodes is used while calculating a node’s trust value. 15
Comparison of DI-Trust model and other models.

Storage resource management and scheduling mechanism
The storage resource management and scheduling mechanism proposed in this article synthesize four factors of a candidate service providing vehicle node. They are the trust value, the parking time coverage, the virtual machine utilization rate, and the number of tasks carried by the node. This article divides storage requirements into three levels: high, medium, and low. According to three different level requests, the mechanism calculates to get a reasonable scheduling scheme. It should be noted that when the value of “last n days” is determined, all calculations adopt the same n value. For the sake of simplification, the following calculation formula does not include the parameter n.
High-level event scheduling method
After comprehensively calculating the above four factors, the composite value W(i) of a candidate service providing vehicle node i is calculated as formula (12)

Here, meanings of symbol Dtr(i) and η(i) are the same as in formulas (1) and (2) except that parameter n is ignored. Vu(i) represents the proportion of virtual machines being occupied in the candidate service providing node i. Ta(i) represents the number of storage tasks currently carried by node i.Tmax represents the maximum number of tasks that a node is allowed to undertake. Therefore, P(i) can be calculated as formula (13). P(i) indicates the ratio of the number of virtual machines that the candidate service providing vehicle node i needs to provide compared with the total number of virtual machines needed in this task

In formula (13), k indicates that the number of candidate vehicle nodes in the task. Values of Dtr(i), h(i), Vu(i), W(i), and P(i) are all among (0,1] and Ta(i) is among (0,Tmax].Then, the number of virtual machines

The candidate service providing vehicle nodes are sorted from high to low according to the trust value Dtr(i). Select a virtual block from the node with the highest trust value, and then select a virtual machine block from the node with the second highest trust value, and so on until select a block from the kth node. Then, again select a virtual machine block from the vehicle node with the highest trust value and repeat the process until the storage task is completed. In this procession, when the number of virtual blocks assigned to a node reaches the number it should provide (as specified in formula (14)), the vehicle node exits the selection. If the number of idle virtual machines of a vehicle node is less than the number required by the task, the excess virtual machines will be placed on other nodes one by one from high trust value nodes to low trust value nodes. After a total of
Medium-level and low-level event scheduling methods
Medium-level and low-level event scheduling methods are almost the same as the high-level event except the calculation method of W(j)

As medium-level event, the value of W(j) can be calculated according to formula (15). Then, P(i) and Nu(i) can be got according to formulas (13) and (14). If the number of idle virtual machines of a vehicle node is less than the number required by the task, the excess virtual machines will be placed on other nodes one by one from high parking time coverage nodes to low nodes.
As low-level event, the value of W(j) can be calculated according to formula (16). If the number of idle virtual machines of a vehicle node is less than the number required by the task, the excess virtual machines will be placed to other nodes one by one from nodes that have more idle virtual machines (i.e. they have more storage space) to nodes whose idle virtual machines are not so sufficient

The time complexity of the scheduling method is only related to the vehicle nodes number m, and it is O(m).
Simulation experiments and result analysis
This part introduces some simulation experiments. These experiments focus on aspects of sub-task interruption rate, the load balance of the whole environment, and the change of a vehicle node trust value.
Simulation environment
Simulation experiments in this article are carried out by MATLAB R2014a. The application scenario of storage resource scheduling on the parking lot is simulated. Suppose there are up to 500 vehicle nodes in the parking lot. The characteristic attributes of a vehicle node include the ID of the vehicle node, the parking position, time of entering the parking lot every day, parking time coverage of four time periods in the recent n days, the total number of virtual machines that the node can afford, the number of virtual machines that have already been occupied of the node, and the value of trust of the node. One simulation experiment is run 10 times and takes the average value as the final result. In the above introduction, the relationship and range of α and β are given. On this basis, we determine the value of this parameter according to the best results in the experimental process. The global parameters in simulation experiments are shown as Table 2.
General simulation parameters for simulation experiments.

VM: virtual machine.
The value range of node trust value is among [0, 1], with 0.4 as the initial trust value of a newly added vehicle node. Simulation experiments set up 300 storage tasks belong to the three level events, and the start time of each task is set. The end time of a task is set randomly. It corresponds to the leaving time of the vehicle node that publishes this task. A service providing node vehicle does not know how long will be the task need to last. The proportion of three level event tasks is shown as Table 3.
Proportion of three level event storage tasks.

Simulation results and performance analysis
Sub-task interruption rate
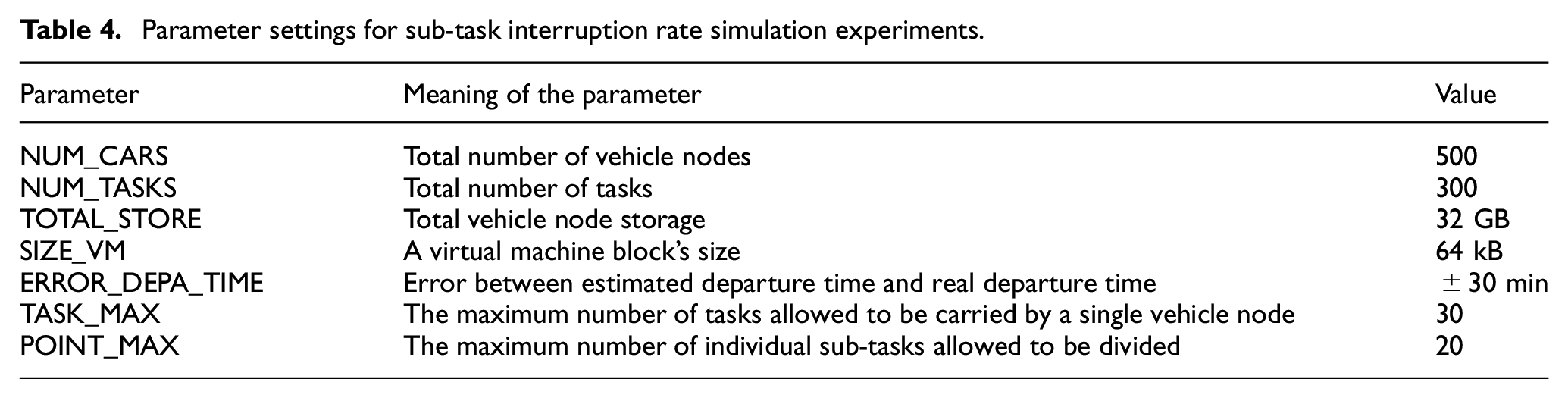
The departure of a vehicle node that carrying the storage task will result in the forced interruption of the carrying task. As mentioned earlier, a storage task is split into multiple sub-tasks in virtual machines for scheduling. This article studies the variation of sub-task interruption rate under storage resource scheduling method based on DI-Trust model. The parameter settings for the simulation experiment are shown in Table 4.
Parameter settings for sub-task interruption rate simulation experiments.
Here, this article uses a performance indicator: sub-task interruption rate, that is, the ratio of the number of sub-tasks interrupted to the number of total sub-tasks. The lower the sub-task interruption rate is, the less the service providing vehicle nodes leave before the task is finished, and the better service experiences a user gets. The experiment simulates the DI-Trust model–based storage resource scheduling method proposed in this article and compares with the sub-task interrupt rate based on the Peer-Trust model, Eigen-Trust model, and None model. The results are shown in Figures 3–6.

Comparison of interruption rate of sub-tasks under high-level events.

Comparison of interruption rate of sub-tasks under medium-level events.

Comparison of interruption rate of sub-tasks in low-level events.

Comparison of interruption rate of high-, medium-, and low-level events under DI-Trust model.
The None model in Figures 3–5 refers to the random designation of vehicle nodes to provide service when there is a task request without using any trust model. It can be seen from figures that the sub-task interruption rate of the None model is much higher than that of other trust models. When the number of tasks is small, the DI-Trust model shows better service performance than other models. As the number of tasks increases, the gap between the three trust models is gradually narrowing in the comparison of sub-task interruption rate. This is because more good status nodes are occupied and choice becomes less as the number of tasks increases. DI-Trust model is always a trust model with good performance of storage resource scheduling in a parking lot.
Figure 6 gives the comparison of sub-task interruption rate of high-, medium-, and low-level event under DI-Trust model. The abscissa of the figure is the number of tasks and the ordinate is the sub-task interruption rate. Each level event is experimented with 150 random tasks. It can be seen from the figure, for high-level event, the sub-task interruption rate keeps low, the change range is smooth, and after 150 tasks are finished, the sub-task interruption rate is still less than 10%. This is in line with our goal of minimizing the interruption rate of high-level event to ensure users’ information security and service experience.
Load balance among vehicle nodes
In the scheduling of storage resources, a problem that needs to be considered is to make the vehicle node undertake the task equilibrium as far as possible. The standard deviation of space usage is used to evaluate vehicle nodes’ load status. This value can reflect the degree of dispersion of all nodes’ space usage in the parking lot. The lower the standard deviation is, the more balanced the load of nodes is. Parameter settings for this simulation experiment are shown in Table 4. Experiments’ results are shown in Figure 7.

Comparison of standard deviation of space usage for different trust models.
In Figure 7, as the number of tasks increases, the standard deviation of space usage shows a downward trend under the DI-Trust model and the Peer-Trust model. However, when the number of tasks reaches 300, there is a rebound of the standard deviation obtained by the Peer-Trust model. The standard deviation under the DI-Trust model has been always in a decreasing trend, although the trend decreased with the number of tasks increases. In contrast to those two models, the standard deviation keeps increasing as the number of tasks increases under the Eigen-Trust model. Therefore, the DI-Trust model has a more prominent contribution to the improvement of load balance of vehicle nodes in the parking lot.
Figure 8 presents a comparison of vehicle nodes’ space usage before and after task assignment using the DI-Trust model to do scheduling. Tasks in the experiment are high-level task events. The experiment randomly selects 50 nodes for task carrying. The horizontal coordinates in the figure represent the node sequence number, and the vertical coordinates are the node storage space usage. The spatial usage of 50 nodes varied and fluctuated greatly at the beginning. After 150 storage tasks scheduling finished, the space usage among nodes tends to about 70%. It can be seen in the figure that the fluctuation of the space usage rate of each node after carrying the task is greatly reduced (marked with red color) compared with that before the task scheduling (marked with blue color), and the purpose of load balancing is achieved.
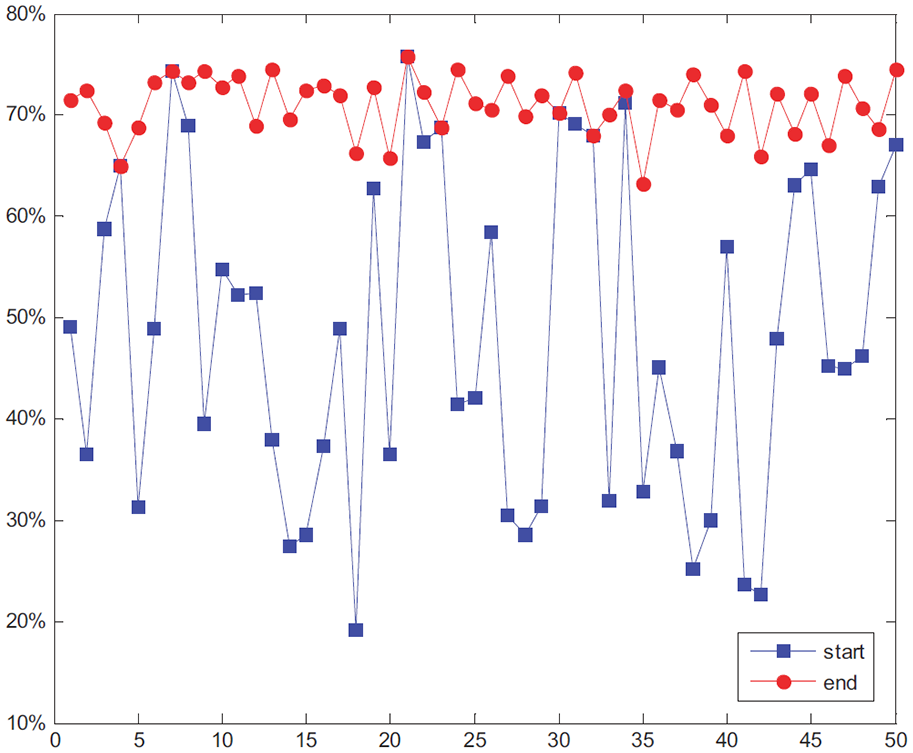
Comparison of node space usage under the DI-Trust model.
Observation of nodes’ trust value
In this experiment, three vehicle nodes are randomly selected from the parking lot to observe the variation of their trust values under the DI-Trust model. The characteristic properties of three nodes are shown in Table 5.
Characteristic properties of three nodes under trust value experiment.

In the experiment, three nodes completed a high-level storage service for 10 days. Changes of their trust values over 10 days are shown in Figure 9. The horizontal coordinates in the figure represent days, and the vertical coordinates represent the node trust value. The three nodes are marked with three colors: blue, green, and red.

Trust values of three nodes over 10 days.
The task completion rate (not be interrupted) of each node, the average number of virtual machines, and the average service time provided by each node per day are shown in Table 6.
Observation of key parameters of three nodes.

In Figure 9, the trust values of the three nodes show an increasing trend with the passage of time and the number of services, but as time goes on, the increase is smaller and smaller. The initial trust values of the three nodes are the same. Values start to change after nodes begin to provide service, and the trust value gap among nodes becomes obvious with the increase in providing service.
Combined with the data in Table 6, we can find that the initial gap of parking time coverage of three nodes is obvious, which leads to the difference of service completion rate. The higher the parking time coverage of the node, the lower the probability of the vehicle leaving, and the lower the possibility of interruption during the service task, so the higher the service completion rate will be correspondingly. It can be seen from the figure that the average number of virtual machines provided by node H2 and the average length of service per day are higher than that of node H1, but in the final trust value comparison, the trust value of H2 is lower than that of H1. Although H2 offers many virtual machines and long service time, its service completion rate is low. And the service completion rate is the focus of concern. That is the reason why the final trust value of H2 is lower than that of H1.
Conclusion
This article mainly discusses the storage resource scheduling of vehicle nodes in the parking lot, and proposes a vehicle cloud storage resource scheduling method based on DI-Trust model. The model considers a variety of dynamic elements that will affect the trust value of a vehicle node. Based on the trust model, a virtual machine scheduling method based on storage resource requirement is proposed for virtual machine scheduling among vehicle nodes. Simulation experiments are carried out on the interruption rate of sub-task, the load balancing, and the change of vehicle node trust value. These experiments verify the function and performance of the mode.
Because there are some differences between the simulation platform and the actual vehicle cloud environment, the vehicle cloud storage resource scheduling method based on the DI-Trust model proposed in this article also needs to be tested in the real vehicle cloud. On the basis of scheduling storage resources, we can further study other types of resource scheduling of vehicle nodes.
Footnotes
Acknowledgements
The authors also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Science Foundation of Nantong of Jiangsu Grants (JC2018131) and the National Natural Science Foundation of China (62002179).