
Abstract
Human activity recognition using depth videos remains a challenging problem while in some applications the available training samples is limited. In this article, we propose a new method for human activity recognition by crafting an integrated descriptor called multi-level fused features for depth sequences and devising a fast broad learning system based on matrix decomposition for classification. First, the surface normals are computed from original depth maps; the histogram of the surface normal orientations is obtained as a low-level feature by accumulating the contributions from normals, then a high-level feature is acquired by sparse coding and pooling on the aggregation of polynormals. After that, the principal component analysis is applied to the conjunction of the two-level features in order to obtain a low-dimensional and discriminative fused feature. At last, fast broad learning system based on matrix decomposition is proposed to accelerate the training process and enhance the classification results. The recognition results on three benchmark data sets show that our method outperforms the state-of-the-art methods in term of accuracy, especially when the number of training samples is small.
Keywords
Introduction
Human activity recognition (HAR) is a research hotspot in the field of computer vision and pattern recognition with wide applications such as intelligent video surveillance, 1 human computer interaction, 2 ambient assisted living, 3 virtual reality, 4 and so on. Early researches on HAR have mainly focused on recognizing activities from RGB videos and many successful approaches have been proposed.5,6 However, the effectiveness of RGB cameras deteriorates because of illumination changes, surrounding clutters and disorder. 7 The inventions of the cost-effective depth sensors such as Microsoft Kinect and Asus Xtion Pro have triggered the imagination of many researchers about activity recognition. Abundant structure information captured by depth sensors is insensitive to illumination variations, robust to complex background, and valuable for obtaining geometric information. 8 Many researches have been carried out with depth maps for HAR.9–11 However, when the depth training samples are limited because of the cost-intensive collection of depth data of human activity, most of these methods cannot achieve required accuracy due to weak descriptors and rough classifiers.
Current researches have investigated a number of human body representations including skeleton joints, 12 cloud points, 13 local interest points, 14 projected depth maps, 15 and surface normals. 10 In Luo et al., 16 a skeleton-based discriminative dictionary learning approach is proposed though utilizing group sparsity and geometry constraints. Vemulapalli et al. 12 took skeletons as points and actions as curves in a Lie group by using the three-dimensional (3D) relative geometry between body parts. However, skeletons are usually noisy due to the difficulty in localizing body parts, self-occlusions, and sensor range errors. 17 In contrast to skeleton joints, cloud points are more robust to occlusions and noise. In Wang et al., 13 local occupancy patterns (LOP) were designed to subdivide the local 3D subvolumes related with skeleton joints into a group of spatial grids, then the number of cloud points falling into each grid was calculated. Rahmani et al. 18 designed the histogram of oriented principal components (HOPC) to capture the local geometric information around each point in 3D cloud point videos, which is robust to viewpoint, scale, and temporal variations. To effectively suppress noise in the depth sequences, local spatiotemporal interest points (STIPs) were extracted from depth videos by a delicate filter to find out task-related interest points in Xia and Aggarwal. 14 In order to transform the depth data from 3D to two-dimensional (2D), Yang et al. 19 proposed depth motion maps (DMM) generated by projecting the depth maps onto three orthogonal planes and thresholding the difference of consecutive depth frames for each projected view, then applied the histogram of oriented gradients (HOG) to each 2D projected view to extract the features. However, the DMM features employed in Chen et al. 15 and Yang et al. 19 cannot capture the temporal information and thus suffered from the temporal disordering.
Surface normal has already been proved that it can extract valuable shape and structure information from depth maps. 20 In Oreifej and Liu, 10 histogram of the surface normal orientation in four-dimensional (4D) space (HON4D) in terms of time, depth, and 2D viewing planar was designed to capture the complex joint shape-motion cues at pixel level. Although as a low-level feature, it can capture motion and geometry cues effectively while being robust to occlusion. Yang and Tian 21 proposed a new and high-level representation called super normal vector (SNV) by aggregating the low-level polynormals and concatenating the feature vector extracted from each adaptive spatiotemporal grid to encode spatiotemporal information. SNV is robust to noise; it can not only capture spatial and temporal order but also provide more distinguished local motion and appearance information for complex activities. In this article, data fusion is employed to gain robust and discriminative features to take the advantages of the both above features.
In recent years, deep learning methods have been widely used to automatically learn features from raw data and make successful computer vision applications,22,23 especially in HAR.24–26 Nonetheless, deep learning methods usually need large-scale training set, which is difficult because of economic and technical limit. Some recent works exploited transfer learning27–29 to deal with the lack of training samples. Nevertheless, the chosen parameters and models of deep learning methods still remain a challenging problem.
Broad learning system (BLS) 30 is proposed as an improvement of the random vector functional link neural network (RVFLNN).31,32 Compared with the deep schemes of neural network models, RVFLNN dramatically reduces the training time and provides comparable generalization ability through combination of random functions. In BLS, the mapping features generated from the input data form the feature nodes of the network, then they are enhanced as enhancement nodes (EN) by randomly generated weights. Finally, all mapped features and EN are directly connected to the output, the corresponding output coefficients can be derived from pseudoinverse. 30 BLS has been successfully applied to some specific image classification tasks,30,33 which outperformed common classifiers with limited labeled samples, such as k-nearest neighbor (KNN), 34 support vector machine (SVM), 35 and extreme learning machine (ELM). 36 However, most of the real problems relevant to regression and classification are complex and need very broad-scale feature nodes, leading to extremely long training time. Therefore, we proposed a fast BLS based on matrix decomposition (FBLS-MD) to resolve this problem.
To handle the HAR tasks with limited training samples, in this article, we develop a robust descriptor of depth sequences called multi-level fused features (MLFF). In order to fully explore the MLFF’s validity, a FBLS-MD is further proposed. MLFF are generated by concatenating two different features extracted from low and high levels respectively. Since the low-level feature can capture the statistical patterns of shape changes of human activities while the high-level feature gives out a more comprehensive representation of spatial and temporal variations, MLFF are strongly robust to noise and occlusion. Principal component analysis (PCA) is further adopted to obtain lower dimensional features. Finally, FBLS-MD is carried out to classify activities and relieve the problem of heavy computation. The main contributions of our work are listed as follows:
We propose a new descriptor which is more discriminative and effective due to the complementarity between low-level and high-level features.
It is the first trial that introduces BLS into HAR classification. The proposed FBLS-MD can relieve the time-consuming training process caused by the large number of nodes.
The rest of this article introduces the detailed framework of our proposed method in the “Proposed method” section. In the “Experiments” section, we conduct experiments on three well known data sets and analyze the results. Finally, the “Conclusion” section summarizes the article.
Proposed method
Our proposed method has two major steps. First, MLFF of depth sequences are acquired by concatenating HON4D and SNV; then we employ PCA for dimensionality reduction. Second, FBLS-MD algorithm is introduced for efficient training and classification. The overview of our method is shown in Figure 1.

The overview of the proposed method. A new descriptor (i.e. MLFF) is designed for depth images representation. Then FBLS-MD is adopted as the classifier.
MLFF
All features in our work are calculated in 4D space (i.e. 2D images
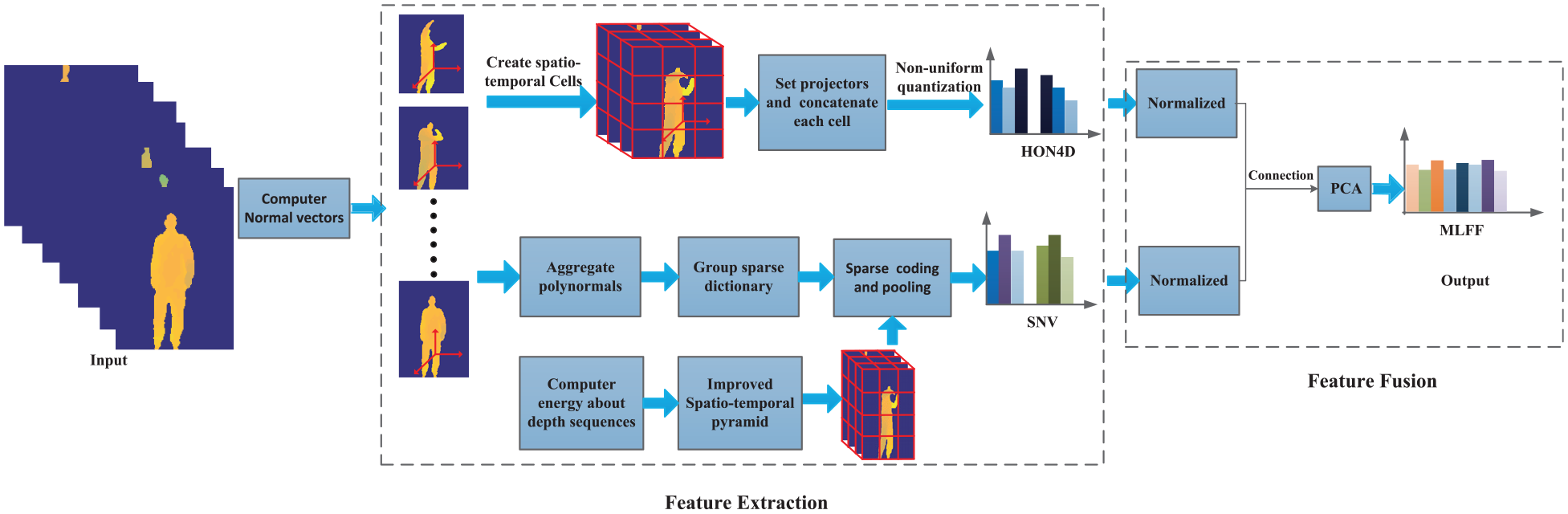
The various steps of obtaining MLFF. The low-level feature HON4D and high-level feature SNV are normalized and concatenated first. Then PCA is adopted to reduce the dimensionality of the joint features so as to acquire MLFF.
Feature extraction
First, we extract HON4D in the same way as in the study by Oreifej and Liu.
10
Depth sequences of human activities can be viewed as a hypersurface in 4D space

Second, we extract the aggregated spatial-temporal features based on an improved spatial-temporal pyramid as in the study by Yang and Tian.
37
The method generated the polynormal by clustering normals from a local spatiotemporal neighborhood to form the high-level features. N normals in the local neighborhood

The neighborhood
Then sparse coding 38 is utilized to find a set of dictionary vectors encoding polynormals. And then the average pooling is applied spatially to aggregate the coefficient-weighted differences

where
In order to exercise energy and characterize movement changes accurately, the tth frame
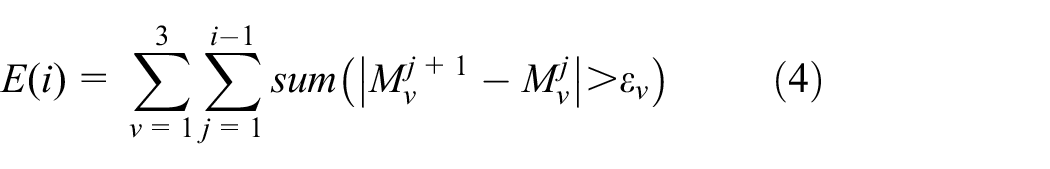
where
In order to obtain information in the spatial dimensions, each frame is divided into

The diagram of spatiotemporal pyramid. We use three-level pyramid in the time dimension.
Finally, the feature
Feature fusion
Feature fusion has been demonstrated to be an effective method to boost the performance in HAR system.39–42 And it is usually conducted through feature normalization and feature selection or transformation due to the highly correlated feature set and the curse of dimensionality. 43
In our method, HON4D 10 of one cell has been extracted and the final features are denoted as

where N represents the number of spatiotemporal cells. The final high-level descriptors
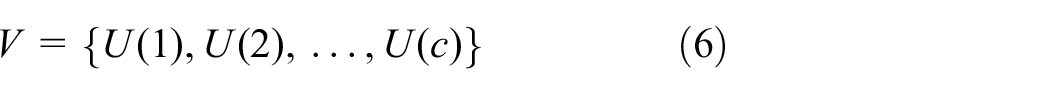
where c indicates the number of space-time grids from the spatiotemporal pyramid.
We mark the normalized H and V as
Feature fusion usually produce representations in a higher dimensional space. Although pooling can eliminate data redundancy, its dimensionality reduction usually is a by-product rather than a direct goal. PCA 44 is useful for dimensionality reduction, increasing interpretability and as the same time minimizing information loss; it can maximize variance by creating new uncorrelated variables. PCA has become an adaptive data analysis technique. Therefore, we employ PCA to reduce the dimension of the features thus improving the efficiency of the algorithm in this article. Finally, we can get the MLFF as the representation of a depth sequence.
The MLFF descriptors have the following obvious advantages. (1) Our descriptors are more robust and discriminative than previous representations. (2) With a lower dimension, MLFF can greatly improve the running speed of the algorithm while also increase the recognition rate.
Classification
In order to perform classification with the designed features, we feed the MLFF to FBLS-MD classifier, which can accelerate the training speed by making use of block matrix inversion lemma to decompose the large matrix inversion process. Next, the details of the algorithm will be introduced.
Given the input data set

where

Finally, the broad learning model can be defined as follows
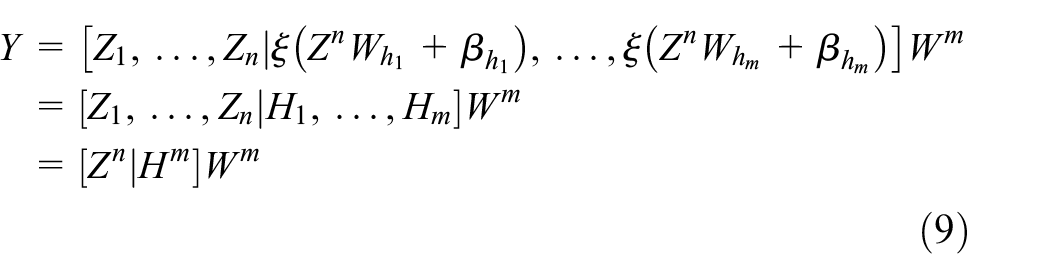
where

where
In FBLS-MD algorithm, the connecting weights

where
Hence, the coefficient matrix

where
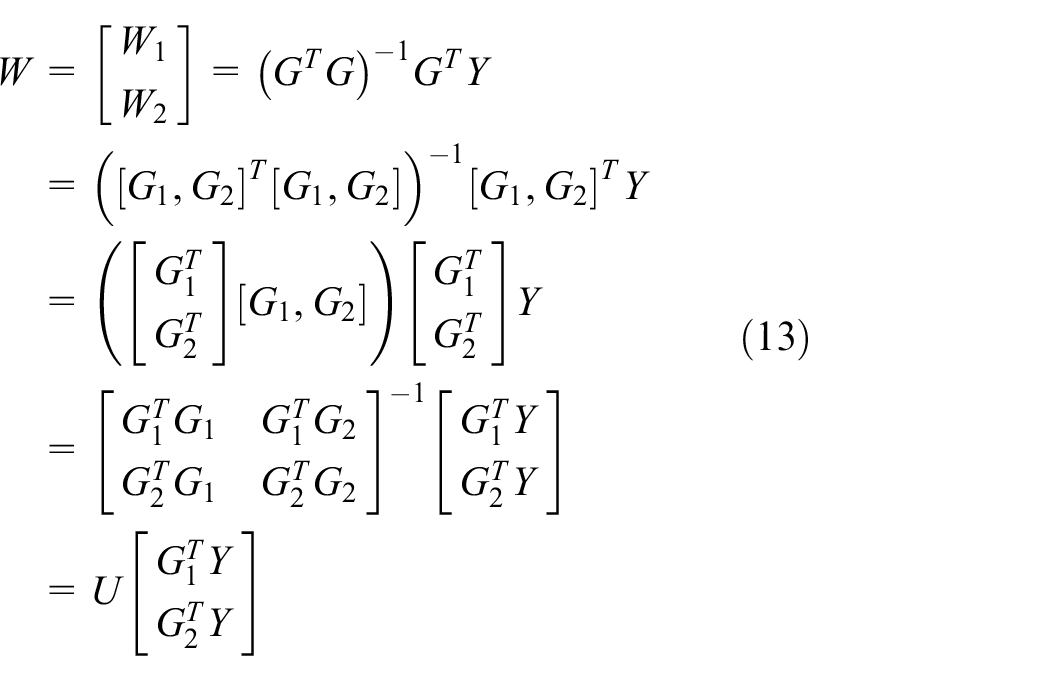
where

Through block matrix inversion Lemma, 45 we can computer formula (14), then the connecting weights W can be written as follows
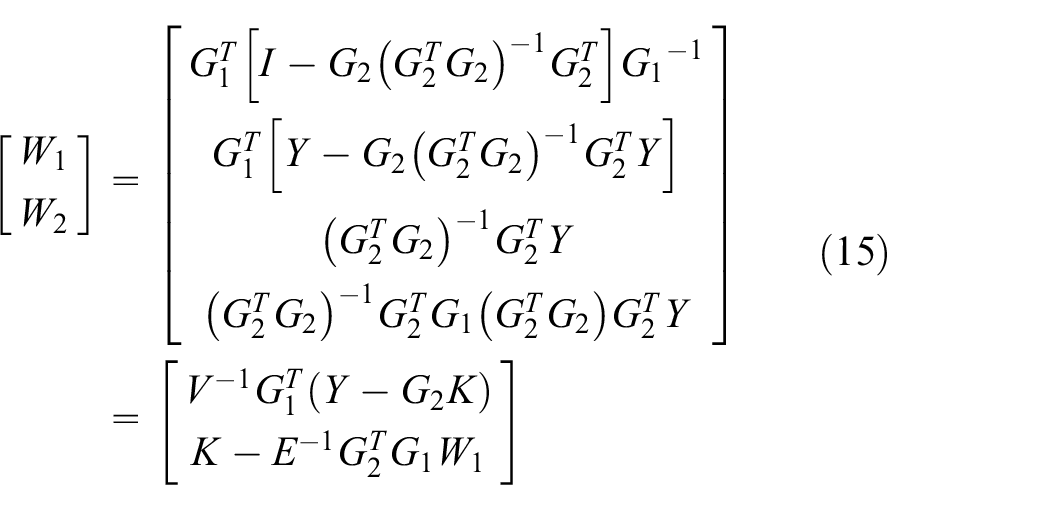
where




where

The structure of FBLS-MD.
In summary, the training steps of FBLS-MD algorithm are shown in Table 1.
The training steps of the proposed FBLS-MD algorithm.

FBLS-MD: fast broad learning system based on matrix decomposition.
Experiments
Experimental setup
The proposed method is extensively evaluated on three benchmark data sets, including MSR Action 3D data set, MSR Hand Gesture 3D data set, and 3D Action Pairs data set. For each activity, we extract its MLFF descriptors.
In the experiments, each video sequence is divided into space-time grids, which are
We evaluate the performance of our proposed method comparing with the state-of-the-art methods using the same experimental settings in Yang and Tian. 37 For three data sets, s (s = 1, 2, 3, 4, 5) randomly chosen actors’ activities are used for training, while the remaining samples are used for testing. The selections of s are conducted randomly five times in each case to get the average results as the final recognition rate. In addition, the performance of FBLS-MD is compared with original BLS in term of the training time when the MN and EN increase gradually, which is verified on whole data set. It is worth noting that the experimental results about BLS and FBLS-MD algorithms are acquired by taking the average of 10 results. Our experiments are all performed using MATLAB on a computer with a 3.60 GHz Intel Core i7-4790 CPU and 16 GB RAM.
Experimental results and analysis
MSR Action 3D data set
MSR Action 3D 46 is one of most classical data sets for HAR as recorded in related research literatures. It includes 20 different actions. Each action is performed by 10 actors for two or three times. Inevitably, there are some missing and wrong depth sequences. It is a challenging data set for HAR due to the similar actions. The specific actions in this data set are shown in Figure 5.

The specific actions in MSR Action 3D data set.
With the same experiment setup as in Wang et al. 46 (first five actors for training, and the rest for testing), we compare our results with the state-of-the-art methods on this data set and present the results in Table 2. This setting is much more challenging than which has been used in Li et al., 48 because evaluation on whole action set increases the chance of confusion which often occurs in recognizing similar actions. As the result shows, our method is superior to other classical methods. The confusion matrix is demonstrated in Figure 6. It can be observed that our method has significant improvement on recognizing “hand catch” and “forward punch” actions by comparing with the results of Yang and Tian. 37
Performance comparison of the proposed method with the state-of-the-art methods on MSR Action 3D data set.

HPM: human pose representation model; TM: temporal modeling; HOJ3D: histograms of 3D joint locations; STOP: space-time occupancy patterns; ROP: random occupancy patterns; DMM: depth motion maps; HON4D: histogram of the surface normal orientation in four-dimensional space; DSTIP: spatial-temporal interest points from depth video; GLAC: gradient local auto-correlations; JSG: joint spatial graph; JSGK: joint spatial graph top-K; LBP-DF: local binary patterns-decision level fusion approach; SNV: super normal vector; MLFF: multi-level fused features; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
The highest two classification accuracies are marked in bold respectively.

Confusion matrix of the MSR Action 3D data set results classified by the proposed method.
Then, we evaluate the performance of our proposed descriptors. Table 3 compares MLFF descriptors with the single-feature methods on this data set. The results show our descriptors have a more powerful representation than HON4D or SNV. When the training samples are fewer, the improvements of the recognition rate are more observable. MLFF show a significant gain in classification accuracy by nearly 10% when s is 1 or 2. In addition, we find that the standard deviations of our method are smaller than other methods, which means MLFF are more robust.
Performance comparison for SNV, HON4D, and MLFF features on MSR Action 3D data set.
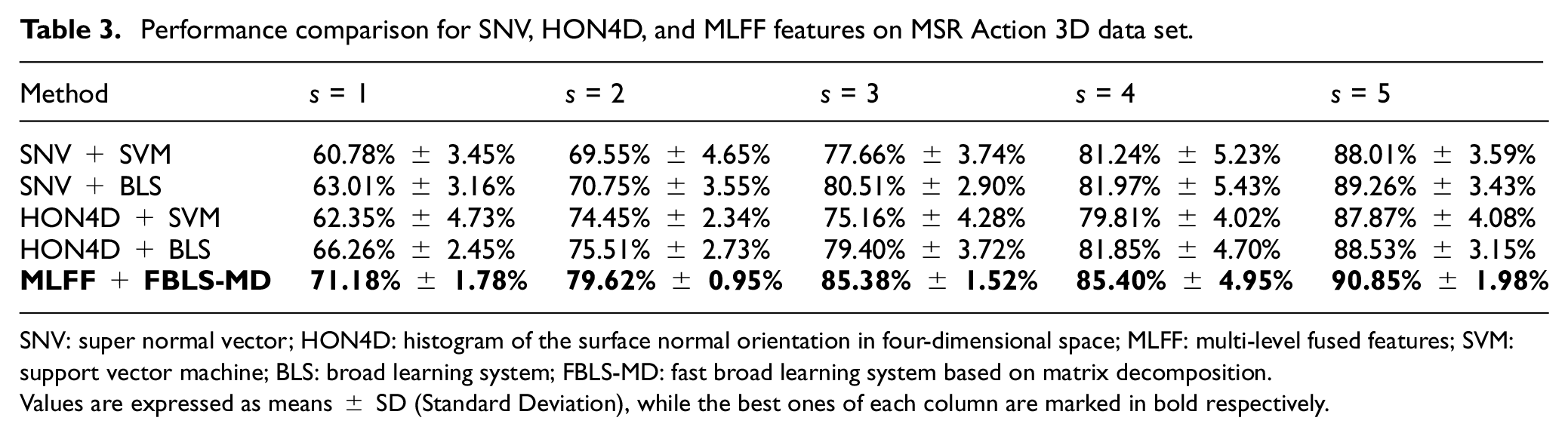
SNV: super normal vector; HON4D: histogram of the surface normal orientation in four-dimensional space; MLFF: multi-level fused features; SVM: support vector machine; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
Values are expressed as means ± SD (Standard Deviation), while the best ones of each column are marked in bold respectively.
Next, we verify the validity of FBLS-MD classifier. In the third experiment on this data set, we compare the performances of FBLS-MD classifier with the other four classifiers. The results are shown in Table 4 and Figure 7. From the experimental results with the same feature set and varied classifiers, we can see that the BLS and FBLS-MD turn out to be remarkably good at distinguishing activities. Obviously, only the result of our method exceeds 90% when s is 5.
Performance comparison under different classifiers on MSR Action 3D data set.

MLFF: multi-level fused features; KNN: k-nearest neighbor; SVM: support vector machine; ELM: extreme learning machine; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
Values are expressed as means ± SD, while the best ones of each column are marked in bold respectively.
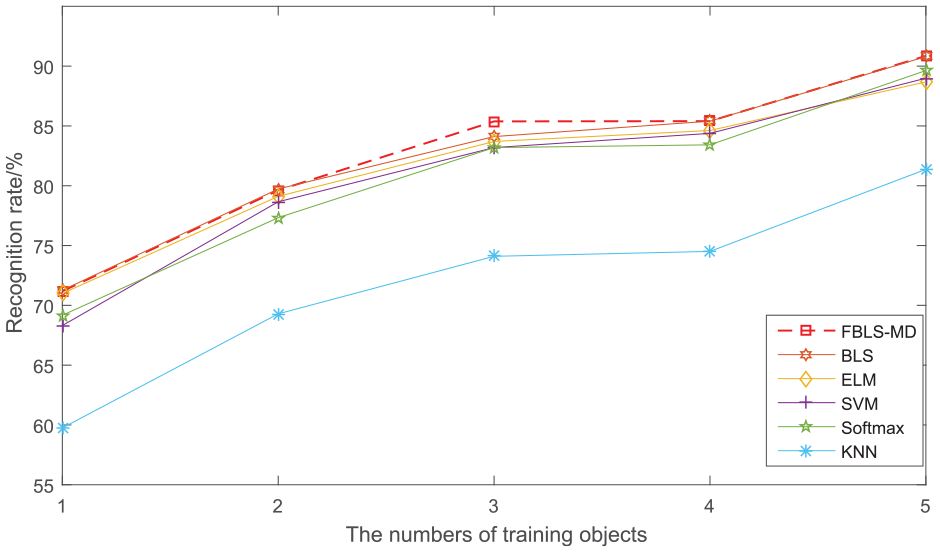
Recognition rates of different methods with different numbers of training sample on MSR Action 3D data set.
At the final stage, the performance comparison of BLS and FBLS-MD on MSR Action 3D data set is shown in Table 5 (where Ratio refers to the time reduction proportion). When the feature nodes are small, the reduction of the training time is not obvious. But as the number of mapping nodes increases, the training time shrinks greatly meanwhile maintaining the recognition rate. As can be seen, when the feature nodes reach a certain number, the action recognition rate will reach the highest value and then slightly decrease.
Performance comparison of BLS and FBLS-MD algorithms on MSR Action 3D data set.

BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition; MN: mapped nodes; EN: enhancement nodes.
MSR Hand Gesture 3D data set
MSR Hand Gesture 3D 24 consists of 12 dynamic American Sign Language (ASL) gestures captured by a Kinect device. The whole data set contains 333 depth sequences and bears self-occlusions. Each gesture is performed for two or three times by 10 actors; the depth map size of each gesture is varied. Some samples are shown in Figure 8.

The sample gestures in MSR Hand Gesture 3D data set.
In the experiments, we conducted the leave-one-subject-out cross-validation (LOO-CV) as in the study by Wang et al. 51 to evaluate the performance of our algorithm. Table 6 shows the comparison of our proposed method with the state-of-the-art methods on this data set. We can see that our method has improved 4.49% and 2.19% compared with the single-feature methods in terms of HON4D and SNV, respectively. Moreover, our method outperforms all compared approaches.
Performance comparison of the proposed method with the state-of-the-art methods on MSR Hand Gesture 3D data set.

HON4D: histogram of the surface normal orientation in four-dimensional space; DMM: depth motion maps; SNV: super normal vector; MLFF: multi-level fused features; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition; LBP-FF: local binary patterns—feature level fusion approach; HOG3D: histogram of oriented 3D; LLC: locality-constrained linear coding.
The two highest classification accuracies are acquired with our methods, which are marked in bold.
Furthermore, our method achieves a high recognition rate of 96.05%. The confusion matrix is showed in Figure 9 with the experimental setup as in the study by Wang et al., 46 which refers to the first five actors for training and the rest for testing. Figure 10 gives the confusion matrix constructed through the method in Yang and Tian 37 under the same experimental setup. From the two confusion matrices, it is clear that “blue,”“finish,”“green,”“hungry,”“milk,”“j,” and “z” gestures are more precisely identified, and the overall recognition rate was increased by nearly 7%.

The confusion matrix obtained by our method.

The confusion matrix obtained by the SNV feature.
We compare our proposed method with single-feature methods. We can find that our method is better than the single-feature methods presented in Table 7 with a large margin in small samples. Comparing with the best of the other methods, our method achieves a 2.59% recognition rate improvement when s = 4 and more than 4% improvement in other cases.
Performance comparison for SNV, HON4D, and MLFF features on MSR Hand Gesture 3D data set.
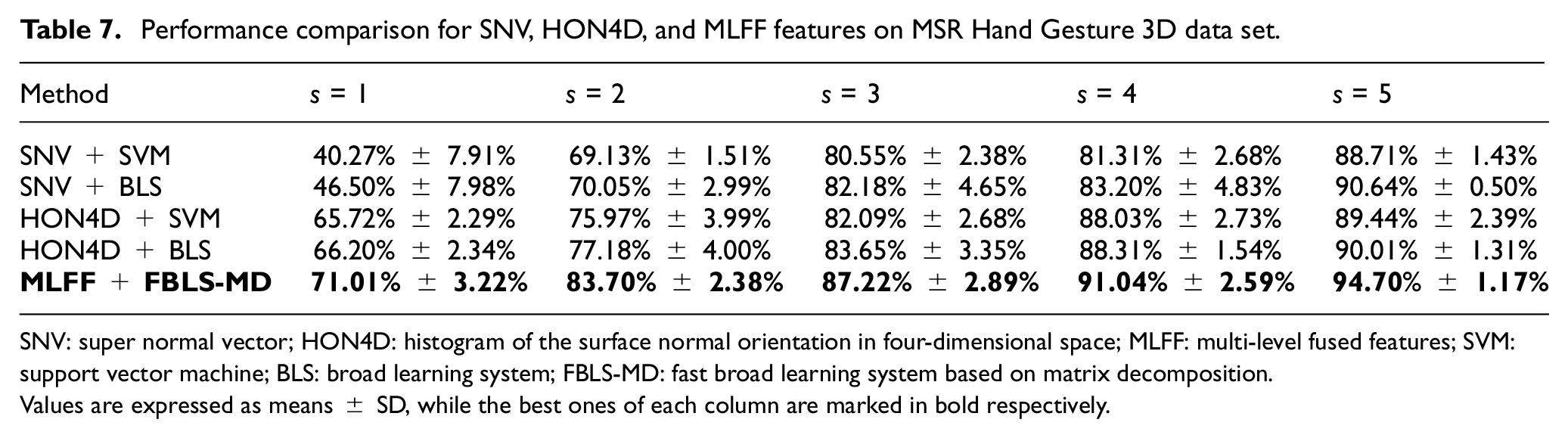
SNV: super normal vector; HON4D: histogram of the surface normal orientation in four-dimensional space; MLFF: multi-level fused features; SVM: support vector machine; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
Values are expressed as means ± SD, while the best ones of each column are marked in bold respectively.
Table 8 and Figure 11 show the performance comparison of the five classifiers. Although the result of ELM is slightly higher than that of BLS and FBLS-MD when s equals 3, the overall results show that FBLS-MD significantly outperforms the other classifiers. The performance comparison of BLS and FBLS-MD algorithms on MSR Hand Gesture 3D data set is given in Table 9, which has also shown that FBLS-MD is useful for elevating the training speed.
Performance comparison under different classifiers on MSR Hand Gesture 3D data set.

MLFF: multi-level fused features; KNN: k-nearest neighbor; SVM: support vector machine; ELM: extreme learning machine; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
Values are expressed as means ± SD, while the best ones of each column are marked in bold respectively.

Recognition rates of different methods with different numbers of training sample on MSR Hand Gesture 3D data set.
Performance comparison of BLS and FBLS-MD algorithms on MSR Hand Gesture 3D data set.

BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition; MN: mapped nodes; EN: enhancement nodes.
3D Action Pairs data set
The actions in 3D MSR Action Pair data set 10 are the paired-activities captured by a depth camera. This data set contains 12 activities which were performed by 10 actors with each actor performing three times. Part of them are shown in Figure 12. Every couple of activities has similar movements and shapes. The challenge of this data set is that some activities differ only on sequences’ order, such as picking and dropping. Therefore, the temporal order of frames is one of the most important factor in the activity recognition of this data set.

The specific actions in 3D Action Pairs data set.
As shown in Table 10, our proposed method outperforms the state-of-the-art methods on this data set. Table 11 indicates that the single-feature methods are still inferior to our method on the third data set. When the training samples are smaller, our method achieves a great improvement. The accuracies of our method are 5.25%, 2.36%, 0.95%, 0.64%, and 0.89% higher than the single-feature method in the best cases when s is 1, 2, 3, 4, and 5, respectively. From Table 11, we can find that HON4D feature is more suitable than SNV feature on 3D Action Pairs data set. Accordingly, this also proves the complementarity of this two features for different data sets.
Performance comparison of the proposed method with the state-of-the-art methods on 3D Action Pairs data set.

LOP: local occupancy patterns; DMM: depth motion maps; HON4D: histogram of the surface normal orientation in four-dimensional space; SNV: super normal vector; MLFF: multi-level fused features; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
The highest two classification accuracies are marked in bold respectively, showing the advantage of our proposed methods.
Performance comparison for SNV, HON4D, and MLFF on 3D Action Pairs data set.
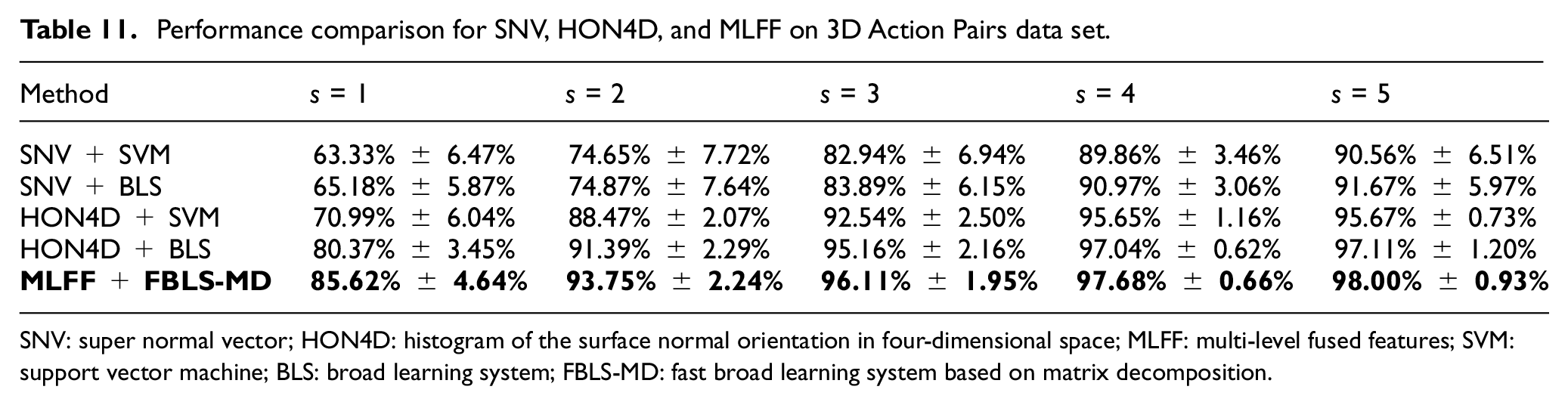
SNV: super normal vector; HON4D: histogram of the surface normal orientation in four-dimensional space; MLFF: multi-level fused features; SVM: support vector machine; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
It is obvious that our method is superior to the other five classifiers as presented in Table 12 and Figure 13. However, with the third data set, Softmax, SVM, ELM, BLS, and FBLS-MD classifiers have slight differences in classification performance. The differences of the recognition rate are within 3%.
Performance comparison under different classifiers on 3D Action Pairs data set.

MLFF: multi-level fused features; KNN: k-nearest neighbor; SVM: support vector machine; ELM: extreme learning machine; BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition.
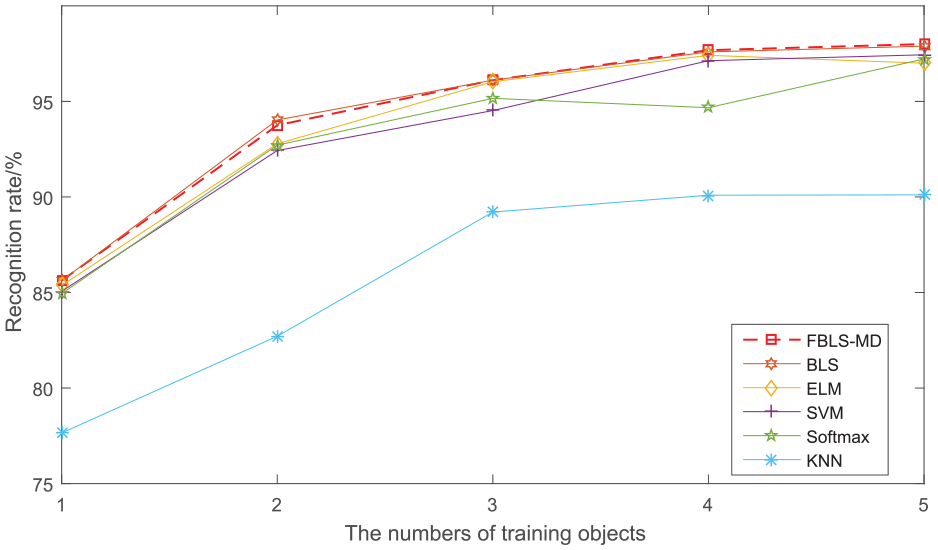
Recognition rates of different methods with different numbers of training sample on 3D Action Pairs data set.
Table 13 shows the comparison of BLS and FBLS-MD algorithms’ performances on 3D Action Pairs data set. On this data set, as the feature nodes continue to increase, the training time has decreased significantly, simultaneously the recognition rate has reached maximum and no longer drops. It also proves FBLS-MD’s value when large-scale feature nodes are required to train models.
Performance comparison of BLS and FBLS-MD algorithms on 3D Action Pairs data set.

BLS: broad learning system; FBLS-MD: fast broad learning system based on matrix decomposition; MN: mapped nodes; EN: enhancement nodes.
Discussion
Our proposed method obtains the highest performance while the training samples are small. It may be attributed to two factors. First, our fused features are complementary to HON4D and SNV, thus increasing recognition accuracies. Second, the comparison experiments show that FBLS-MD performs very favorably against other commonly used classifiers. In addition, FBLS-MD is demonstrated to effectively shorten the training time in case that the computation burden is increased by a large number of feature nodes. With increasing feature nodes, the computation burden of inverse of the growing matrix will be huger and matrix decomposition will play a vital role. There are large standard deviations for some random experimental results, which is attributed to the large individual differences in the data sets and the missing data in the first two data sets.
The adjustable parameters in FBLS-MD include the following: the feature nodes per window, number of windows of the feature nodes, number of EN, the
As MN and EN increase, we can see that the recognition results also boost. However, when the number of nodes reach a certain value, the recognition rate will reach a maximum, then it will gradually decline.
It will lead to low recognition rate with limited EN and MN. Meanwhile, the excessively abundant EN and MN will lead to additional computation. Therefore, we set MN and EN as 800–6000, 400–3000, and 400–6000 for the three data sets respectively. In addition, the

The relationship between recognition rate, MN and EN. (a) MSR Action 3D data set, (b) MSR Hand Gesture 3D data set, and (c) on 3D Action Pairs data set.
Conclusion
In this article, we have presented a new method for HAR with depth videos. It consists of our proposed features called MLFF and a FBLS-MD. MLFF descriptors are designed to describe spatiotemporal and motion information more abundantly. Moreover, it is robust to noise and occlusion. FBLS-MD is proposed to effectively reduce the training time and obtain satisfied classification results. Extensive experiments have been performed on three benchmarks data sets to verify the effectiveness of our method. Experimental results have shown that our method outperforms state-of-the-art methods. It has also been demonstrated that our method holds an advantage with a small training set.
Footnotes
Handling Editor: Wei Wang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been financially supported by the National Natural Science Foundation of China under Grant 61502195, the Natural Science Foundation of Hubei Province under Grant 2018CFB691, the Fundamental Research Funds for the Central Universities under Grants CCNU19QN023 and CCNU18QN020, and the Humanities and Social Sciences Foundation of the Ministry of Education under Grant 19YJC880079.