
Abstract
In this study, we aim to comprehensively explore the application of principal component analysis (PCA) and independent component analysis (ICA), considering their practical utility. We compare these two methods theoretically and practically, using both real data and simulated data. PCA and ICA algorithms are often treated as black boxes, therefore they are often seen as complex algorithms. In this research, we’ll break down some of the theory behind ICA. Subsequently, we compare principal component regression (PCR) and independent component regression (ICR) in both real and simulated datasets. Our objectives include data analysis and explanation of the superiority of each method (ICA and PCA) across different datasets. We will propose solutions to improve the performance of ICR and PCR regressions for datasets with structures suited to ICA and PCA.
Keywords
Introduction
One of the most common methods for dimensionality reduction is principal component analysis (PCA). Using PCA, a large number of correlated (dependent) explanatory variables can be replaced with a few new variables called principal components, which are uncorrelated with each other. This significantly reduces the dimensionality without losing much information. However, one drawback of this method is that no information is obtained about the variables that are removed. Therefore, instead of removing features, we try to extract them using another method called independent component analysis (ICA). In this method, each new independent variable is a combination of all the old independent variables. In fact, ICA is an advanced multivariate statistical method, primarily employed for blind source separation, and it can be regarded as an extension of PCA. The term ‘‘blind source separation’’ means separating source signals even when there is little information about them. The goal of ICA is to extract useful information or source signals from the data.
Most ICA algorithms work by minimizing a contrast function, which measures the dependency between components. There are several ICA algorithms, such as FastICA, Infomax, Jade, and others. The main goal of these algorithms is to extract independent components (ICs) by maximizing non-Gaussianity, minimizing mutual information, or using maximum likelihood estimation methods. The well-known FastICA algorithm is based on maximizing non-Gaussianity using measures such as kurtosis and negative entropy.
So far, many efforts have been made to expand the concept of ICA, for example: Dolati and Rahmani-Shamsi (2017), 1 used a loss function based on mutual information rank as a contrast function and introduced a new ICA algorithm called RLICA, Shi and Yu (2020), 2 introduced a fast ICA algorithm based on stochastic gradient descent with an adaptive step size. This method improves both the speed and accuracy of the algorithm simultaneously, Moghadam and Keshavarz (2021), 3 proposed a novel ICA algorithm that leverages deep neural networks to enhance blind source separation performance. Zhang and Sun (2023), 4 developed an ICA algorithm that utilizes cumulant tensors and maximizes non-Gaussianity to effectively separate ICs, Wang and Li (2022), 5 presented a robust ICA algorithm featuring adaptive outlier detection, specifically designed for biomedical signal processing applications. In this research we study the IC regression models and compare these models with the traditional regression models. In multiple regression models, if the explanatory variables are associated, the evaluation of regression coefficients is very inaccurate. Also as the number of explanatory variables increases, the dependence between the variables is created. To solve this problem, the principal component analysis can be used to reduce the dimensions and PCR can be used. In IC analysis, there is a kind of regression model based on ICs, this regression model is known as ICR. The ICs can explain more than the main components (PCs), because the independence of a statistic is a stronger condition than being orthogonal. Here are some fundamental differences between ICA and PCA.
PCA and ICA are both linear transformation techniques used in vector spaces, primarily aimed at dimensionality reduction and revealing hidden structures in multivariate data. While both methods provide new representations of the data, they differ in the statistical assumptions they rely on and the goals they pursue. PCA focuses on second-order statistics, especially variance, and extracts linear combinations of variables that exhibit the greatest spread in the data. These components, which are orthogonal in the new space, enable dimensionality reduction while preserving as much variance as possible (Smith et al., 2022). 6 This method is particularly suitable for data that follows or approximates a normal distribution, where linear correlations exist among variables. In such cases, variance serves as a meaningful indicator of data structure. In contrast, ICA seeks linear combinations of the data that are statistically independent (Johnson and Lee, 2023). 7 Unlike PCA, which is limited to maximizing variance, ICA employs higher-order statistics such as kurtosis, entropy, and other measures of nonlinear dependency to identify hidden and statistically independent sources within the data. Importantly, ICA requires non-Gaussian data to successfully separate ICs, as Gaussian variables cannot be distinguished based on statistical independence alone. Therefore, non-Gaussianity is a fundamental requirement for the effectiveness of ICA. Zhang and Huang (2024) 8 found that ICA outperforms PCA in certain contexts, as it can separate mixed signals, such as audio sources or image components. This capability makes ICA particularly valuable in fields like signal processing, image analysis, and bioinformatics.
According to this study, sometimes, the structure and initial distribution of the data, as well as the interdependence of variables, indicate better performance of ICA over PCA. However, when comparing regression of PCs and ICs, the opposite result may be observed, indicating that PCR performs better than ICR. In such cases, factors like the presence of outliers or the type of regression chosen for ICR may contribute to this issue.
To resolve this issue, we first examine the data status. If ICA proves to be more suitable, in order to improve the results of ICR, we need to adjust the method of conducting ICA according to the data structure. For instance, to extract ICs, instead of using the conventional FastICA method after whitening the data, we can employ a custom FastICA method. In this custom method, FastICA should use a distribution aligned with the distribution of the whitened data rather than a normal distribution. This approach can be effective in reducing outliers. If we still don’t achieve the desired result, we can change the regression method used in ICR, because there might be nonlinear relationships between the extracted ICs and the dependent variable, and using conventional linear regression may not be suitable for the data structure. In the section “Preliminaries,” we start by explaining the theory behind ICA. We also compare PCA and ICA both theoretically and practically with examples using real data. We’ll also compare PCR and ICR. Additionally, we explain the data whitening steps in detail and apply them to real data.
In section “Our approach,” we present solutions to improve PCR and ICR for datasets with structures suitable for performing ICA and PCA. Furthermore, the corresponding algorithms for these strategies are presented. Also, we compare the performance of ICR and PCR in both the simulated and real datasets and we apply the proposed algorithms to improve the performance of the regression models. Finally, in the fourth section, we will present the results and conditions of this study.
Preliminaries
In the following, we present some necessary preliminaries and definitions required in this research.
Pearson’s correlation coefficient ( Suppose Spearman’s Rank Correlation Coefficient For a set of ranked vectors Kendall’s Given a set of Multivariate Normal Distribution If


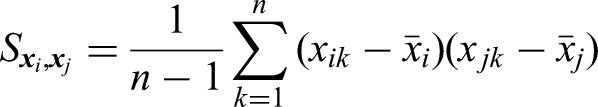




Where
The key idea in PCA is to maximize the variance along the selected components, and all PCA algorithms focus on this. In the following example, we use real-world data to explain the steps involved in performing PCA in detail. Then, we fit several regression models to both the original data and the PCA-transformed data, and compare the results.
The following mathematical derivations may not be essential for all readers but provide important intuitive and structural insights for researchers interested in developing or adapting ICA algorithms.
These data come from 17 hospitalized patients who have used an excessive amount of Amitriptyline .These data were collected from Johnson (2007, Table 6-7, page 426). 9 The dependent variable is:
The five predictor variables are
By estimating the covariance matrix
and the eigenvectors corresponding to the eigenvalues are obtained as



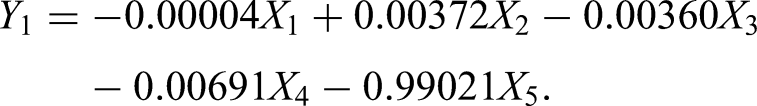
Table 1 presents the results of various regression analyses on both raw data and PCs.On the right-hand side of the table, the outcomes of employing different regression models in PCR and ICR are displayed. Given the presence of some noise in the initial data, we will also examine Ridge and Lasso regression models in addition to the OLS model. However, based on the values in this Table, using ridge and lasso regressions resolves this problem effectively. Additionally, the results of ICR are better than those of PCR and Multiple Linear Regression (MLR). The weaker results of PCR compared to MLR may be due to the removal of all less important principal components.
The main objective in the ICA process is to optimize this contrast function. This means applying optimization techniques to adjust the parameter values in such a way that the contrast function reaches its maximum or minimum, indicating the desired level of independence between the components has been achieved. The general equation for ICA is:

The matrix
There are several ways to achieve this approximation: non-Gaussian maximization of
For ICA, in many studies, the details of the data whitening method are not explained. In the following, we will examine the data whitening process step by step with an example.
To continue, we implement ICA on this data.
The vector of eigenvalues 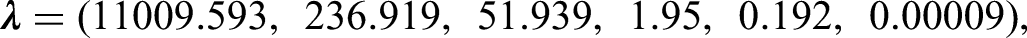

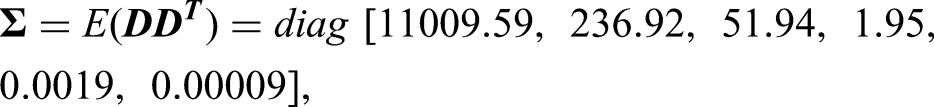
The data on both sides of the main diagonal are almost zero, so we considered their values are equal to zero. This means that the covariance between two mixture signals is zero. For rescale of the signals with a unit variance, we use equation: 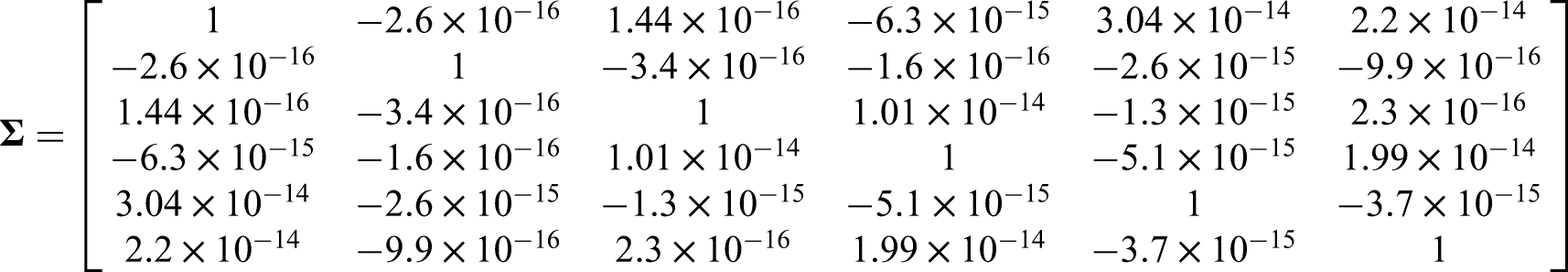
Our approach
There are different algorithms available for performing PCA and ICA. For example, PCA can be done using classical algorithms or methods like Kernel PCA, Sparse PCA, Incremental PCA, and more. For ICA, algorithms such as FastICA, JADE, Infomax, ProDenICA (projection pursuit), RLICA (rank-based loss ICA), and others can be used. In many studies, the specific details and challenges of using PCA and ICA are often overlooked. If we have a set of real-world data, the question arises: without considering a specific goal and based solely on the properties and characteristics of the data, is it more appropriate to apply ICA or PCA?
In PCA, the main goal is to reduce the data dimensions while keeping as much variance as possible in the principal components. This is done by calculating the eigenvalues and eigenvectors of the covariance matrix, with the eigenvectors corresponding to the largest eigenvalues chosen as the principal components.
In ICA, our goal is to find combinations of the observed data that are statistically independent from each other. To achieve this, we use a function called the contrast function. The contrast function is a measure used to evaluate the level of statistical independence between the extracted components. In other words, this function helps us identify the components that are most independent from one another.
Diagonastic
If we have a dataset, should we use PCA or ICA for it? The answer to this question depends on our goal. However, sometimes we want to evaluate which method is more suitable for our data based solely on the initial structure of the data without any specific goal. Additionally, in some cases, the data structure indicates that ICA is more appropriate, but PCR performs better than ICR, and vice versa. Sometimes ICR performs better than PCR even though the initial data structure is more suited to PCA. What factors cause this issue?
As noted by Hyvärinen et al., 10 ICA is not efficient for Gaussian data. In our algorithm, the nature of the data is first assessed to determine whether its structure is more compatible with PCA or ICA. Subsequently, for each case, steps such as noise removal, outlier elimination, and selection of an appropriate regression model are performed to mitigate the inherent limitations of each method. Therefore, even in situations where the data are theoretically more suitable for ICA or PCA, our proposed algorithm can create conditions under which the corresponding regression (ICR or PCR) achieves better performance. This is precisely where our work introduces novelty compared to previous studies: rather than accepting the intrinsic limitations of ICA or PCA, we provide a framework that, through data preparation, alleviates these limitations to some extent and improves regression outcomes.
In this study, we have examined this issue in detail by drawing several flowcharts. The general flowcharts are as follows and a detailed diagram are depicted in appendix.
General algorithm for improving ICR and PCR.

Numerical study
In this section, we test our approximation using simulations and real-world data analysis.
Simulation
In this simulation study, we first generate data from multivariate Normal distribution.
We assume that, 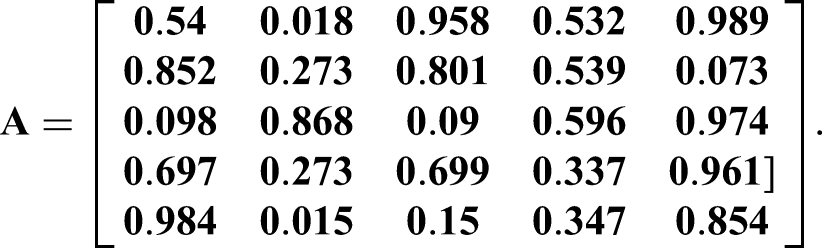
The choice of simulation parameters was guided by the dual objective of maintaining sufficient linear structure for PCA and creating conditions in which ICA could reveal hidden dependencies more effectively. Specifically, the mean vector
Also the response variable is:
To compare ICR and PCR, we use two criteria: MSE (mean square error) and MRE (mean relative error), which are defined as
The simulation results in Table 2 show that the values of all three error criteria are lower in ICR than in PCR in most cases. According to the values of all three indicators for each iteration, when the sample size is high enough, the regression of ICs is more accurate than the regression of principal components. The simulated data structure is more suited to PCA than ICA, so PCR results are usually expected to be better than ICR. However, as seen in Table 2, ICR performs better than PCR with larger sample sizes. To resolve this, we followed steps from Algorithm 1, detailed further in Algorithm 2.
MSE and MRE for ICR and PCR in simulated data.
Given that after running Algorithm 2, the values obtained for MSE, AIC, and BIC in Table 3 for the Lasso regression model in PCA are lower than those in ICA, we conclude that to improve PCR regression, it is better to use Lasso regression instead of simple linear regression to achieve the desired results.
MSE, AIC and BIC for simulation data.

The results in Tables 3 indicate that by following Algorithm 2, we can improve the PCR regression model.
Improving ICR and PCR for simulated data

Real data
In the following, we perform PCA and ICA on real data and compare these two methods. We want to discuss which of the two types of component analysis, ICA or PCA, is better suited for our data based solely on the initial structure of the data without considering the goals of PCA and ICA.
Concrete data
These data correspond to 1030 observations of the complete compressive strength of a mixture of different raw materials. This dataset includes eight predictor variables, which are as follows:
1- Cement (kg), 2- Blast furnace slag, 3- Fly Ash, 4- Water, 5- Super plasticizer,
6- Coarse Aggregate, 7- Fine Aggregate, 8- Age (According to the day).
The dependent variable is: the compressive strength of concrete.
At first, we performed ICA using the Fastica method on the data and illustrated the linear trend and histograms of each original variable (mixture) in Figure 1 and the linear trend and histograms of the ICs extracted from ICA in Figure 2. According to the histograms, the distribution of the ICs was non-normal, while the original data followed a normal distribution. This indicates that the initial conditions for ICA are met.

Eight mixtures in Real data, and their histograms.

Eight sources in real data, and their histograms.
Given that our raw data are non-normal and exhibit weak nonlinear relationships, performing ICA is more appropriate than PCA. After ICA on the data, the results of regression on the ICs were found to be unsatisfactory, with an R2 value of
To further investigate this difference, scatter plots of each IC against concrete compressive strength (

Nonlinear patterns between independent components and concrete compressive strength.
To further investigate the difference between the
We will now provide some explanations regarding the algorithm.
Comparison of descriptive and dependency indices for raw variables, PCA, and ICA.

There were a lot of outliers in the extracted ICs (211 in total), and it didn’t make sense to just get rid of them because we’d lose some important information about how the independent variables relate to the dependent one. So, we tried to reduce the effect of the outliers by using a customized FastICA method and swapping the usual normal distribution with a Truncated normal distribution. This helped reduce the outliers, but it didn’t really change the
To lessen the impact of outliers in the extracted ICs, we can swap the normal distribution with the Laplace or t distribution. These distributions have heavier tails than the normal one, which means they handle outliers better.
Improving ICR for Concrete data

Therefore, using the Akaike criterion, we compared the whitened data distribution with normal, exponential, gamma, beta, Presence of noise in the data extracted by ICA: our data contained 28 noise points, which we removed before conducting the regression. However, the regression results worsened. With the decrease in the The independent variables extracted by ICA do not contain much information about the dependent variable Nonlinear Relationship: The relationship between the independent variables obtained from ICA and the dependent variable To recognize nonlinear relationships between independent variables and In this model, the Lack of Fit and Overfitting: This model may be too simplistic to capture the complexity of the relationship between the data obtained from ICA and the concrete compressive strength. Therefore, to improve the i- Feature engineering: Meaning, during the extraction of ICs, extracting additional informative features from the data that have better correlation with the compressive strength of concrete. By employing this method, ii-Ridge regression and Lasso regression: Because there is some correlation among several of the extracted ICs, and non-random patterns are observed in the scatter plots of residuals against predicted values, our regression model exhibits some degree of both linearity and overfitting. To resolve this issue and also the presence of noise in the data, we employ Ridge regression and Lasso regression for conducting ICR.The values of

Plot of residuals versus predicted values for ICA data.
Heart data
This dataset, collected from the Kaggle website, contains medical records of 299 patients with heart failure. The records were gathered during their follow-up period, and each patient’s file includes 12 clinical features and a response variable, which are:
To analyze the data structure, we first conducted the Kolmogorov–Smirnov test and examined the
Additionally, by calculating Pearson and Spearman correlation coefficients for each variable, we identified nonlinear dependencies among the variables. Therefore, the data appeared suitable for applying ICA. The heart failure dataset also exhibited strong non-Gaussian structures: variables such as creatinine phosphokinase and serum creatinine showed extreme skewness and kurtosis (above 20), while others such as time and serum creatinine revealed substantial nonlinear associations (as captured by Spearman correlation and mutual information). These nonlinearities limit PCA, which relies on linear correlations and variance, whereas ICA, by leveraging higher-order statistics, can extract components with stronger predictive power (as reflected by larger AbsContribution and
The
Based on the software output, since the FastICA algorithm did not fully converge, we applied the Box–Cox transformation to the data, normalized them, and removed outliers. Then, we re-applied the FastICA method to extract ICs and performed ICR. With the convergence of the FastICA algorithm after these steps, the ICR results showed slight improvement, and the R-score reached 0.454.
To further improve the regression performance of ICR, we removed noise from the raw data and repeated the ICA and ICR processes. This led to an increase in the R-score to 0.470.
After performing cross-validation, slight overfitting was observed in the extracted ICs. Therefore, instead of using standard linear regression in ICR, we used Ridge and Lasso regression. The R-scores for Ridge and Lasso regression were 0.4703 and 0.221, respectively, indicating no significant improvement in the regression results.
In the next step, to explore possible nonlinear relationships and more complex dependencies in ICR regression, we used polynomial (second-degree) and spline regression. The R-scores for polynomial and spline regression were 0.622 and 0.643, respectively. These results show that using more suitable regression models can significantly improve the performance of ICR. In Table 5, we show the ICR regression results for different regression model selections: According to the data in Table 5, after removing noise and outliers and normalizing the data, the use of polynomial and spline regression significantly improved the performance of the ICR regression. Based on the
All the steps of this process are summarized in Algorithm 4.
MSE &

Improving ICR for Heart data

Results
In this article, we aimed to explore the results of ICR and PCR using practical examples on both real and simulated data, with detailed explanations. Additionally, we demonstrated how to preprocess data for performing ICA using a practical example on real data. Sometimes, we may want to know which method, ICA or PCA, works better based solely on the data’s structure, without a specific goal in mind. Suppose ICA performs better than PCA and all necessary conditions for ICA are met. However, when comparing the regression results of ICR with PCR, we might find that PCR performs better than ICR. In this article, we provided several practical examples where we examined these contradictions in detail, step by step. Based on the results obtained, the initial structure of the data plays a significant role in both ICA and PCA. After whitening the data in ICA, it’s advisable to first analyze the resulting whitened data structure (
In the following part of this study, advanced optimization algorithms can be used for feature selection and improving model performance. Additionally, dimensionality reduction techniques (such as PCA) can be combined with various regression methods to increase prediction accuracy.
This study demonstrates that the targeted application of ICA in regression modeling can lead to significant improvements under non-Gaussian data conditions. However, the choice between ICA and PCA should be based on the nature of the data distribution, structural complexity, and modeling objectives.
Discussion and conclusion
In this study, we first examined the preprocessing steps involved in ICA, with a particular focus on data whitening. We then compared the performance of ICR and PCR using both real-world and simulated datasets, supported by practical examples. The results underscored the critical role of the underlying data structure in shaping the effectiveness of both ICA and PCA. While ICA may outperform PCA under ideal conditions (and vice versa), the practical outcomes are often influenced by factors such as noise, outliers, and non-ideal data distributions.
Preprocessing, especially the whitening stage in ICA, was emphasized as a key step. Careful analysis of the whitened data is recommended to select the most suitable method (potentially a customized variant) based on the specific properties of the dataset, rather than assuming normality. Additionally, mitigating noise and handling outliers effectively were found to significantly enhance the performance of both ICA and PCA, as well as their respective regression models.
The choice of regression technique also plays a vital role in the performance of ICR and PCR. In scenarios where overfitting is a concern, regularization methods such as Ridge and Lasso regression can be effective. For datasets exhibiting nonlinear relationships, models like polynomial regression may yield superior results.
Future research should aim to develop more robust ICA and PCA algorithms that are less sensitive to outliers, along with adaptive systems that can recommend the most appropriate regression model based on data structure. Furthermore, designing algorithms based on statistical tests that automatically determine whether ICA or PCA is more suitable for a given dataset could provide a valuable decision-making tool for method selection.
Although the case studies used in this research (such as concrete strength and heart disease data) demonstrate the effectiveness of the algorithms, further analysis on a broader variety of datasets is needed to generalize the findings to other data structures.
Footnotes
Acknowledgments
The authors would like to express their sincere appreciation to the Department of Statistics and the Faculty of Mathematics at Shahid Bahonar University of Kerman for their support and provision of research facilities. The authors also thank the esteemed reviewers for their valuable comments and constructive suggestions. This research was supported by funds from the Afzalipour Research Institute, Shahid Bahonar University of Kerman.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix
The complete Python codes used in the experiments are provided as supplementary files and can also be accessed via GitHub: https://github.com/M-Ghasemnejad/Improving-Icr-and-Pcr/blob/main/Paper%20codes-%20Improving%20Icr%20and%20Pcr.py
The diagram of general algorithm for improving ICR and PCR: