
Abstract
Reconfigurable security protocols, with dynamic protocol configuration and flexible resource allocation, have become a state-of-the-art technology to guarantee the security of space-ground integrated network. However, reconfiguration decision-making for reconfigurable security protocols remains a major challenge in order to adapt to diverse secure service requirements and deploy higher security level but more complicated security strategies in nodes with limited resources and computing abilities. To handle this problem commendably, a hierarchically collaborative ant colony–based reconfiguration decision-making model called HiCoACR is proposed. This model, inspired by the ideas of hierarchical reinforcement learning and population collaboration, decomposes the reconfiguration decision-making problem into two sub-problems by introducing a two-level hierarchy ant colony consisting of the Explorer and the Worker. The Explorer controls directions of protocol reconfiguration and generates abstract scheduling sub-goals which are conveyed from the Worker. While the Worker schedules most suitable cryptogram resources for each sub-goal received and produces the optimal reconfiguration solution which is verified and re-optimized by a Lévy process–based stochastic gradient descent algorithm. Both the Explorer and the Worker adopt a modified version of ant colony algorithm to fulfill its targets, where a hierarchical pheromone is defined to reinforce positive behaviors of each ant colony. Experiment results suggest that HiCoACR outperforms baseline algorithms and possesses well model transferability.
Keywords
Introduction
Security protocol is a primary means for guaranteeing the security of network services, such as network communication, data transmission, and authentication. However, no one security protocol could sufficiently cater to all the diverse security requirements, especially in space-ground integrated network (SGIN), where severely limited resource further decreases the possibility of fulfilling diverse security requirements and deploying higher security level but more complicated security strategies. Reconfigurable secure protocol (RSP), with adaptively dynamic protocol reconfiguration and flexible cryptogram resource configuration,1,2 offers a great possibility of alleviating resources constrains, improving resources utilization and enhancing network security in SGIN. Security protocol reconfiguration (SPR) generates protocols by determining proper protocol flow and its components, picking cryptogram resources that satisfy the functional requirements and performance indexes for each component, and then assembling these selected resources in terms of the protocol flow. Since the performance of all components determines the efficiency of the generated target protocol, one of the key issues in SPR is to determine the corresponding protocol reconfiguration flow and its components and schedule optimal cryptogram resources so as to form the target security protocol, which is defined as reconfiguration decision-making problem (RDMP) in this article.
Generally, the scales of cryptogram resources and the diversities in design standards, cryptosystem, and application situations of cryptogram resources enlarge the solution space of RDMP. What is worse, the uncertainty of protocol flow caused by reconfiguration granularity, further intensify this situation. In addition, RDMP is a combinatorial optimization problem, a nondeterministic (NP)-hard problem, where the optimal solution relies on both reconfiguration protocol flow and cryptogram resources. However, previous works mainly focus on resources scheduling and ignore the role of reconfiguration flow in RDMP. Thus, designing an accurate and efficient reconfiguration decision-making mechanism is of great significance to RSP.
To address this problem, a hierarchically collaborative ant colony-based reconfiguration decision-making model called HiCoACR is proposed. The HiCoACR model takes inspiration from hierarchical reinforcement learning3,4 and collaborative behaviors of biological populations, 5 where the RDMP is decomposed into two sub-problems including sub-goal generation for resource scheduling and resource scheduling for sub-goals. And a hierarchical coordinated ant colony consists of the Explorer and the Worker is introduced to address these two sub-problems, respectively. In details, the Explorer controls directions of protocol reconfiguration and explores abstract resources scheduling sub-goals at lower temporal resolution in a latent state space, while the Worker schedules proper cryptogram resources for the sub-goals deriving from the Explorer and generates optimal solution for the target protocol. Both the Explorer and the Worker operate with an improved ant colony algorithm and a hierarchical pheromone is defined to reinforce the positive behaviors of the Explorer and the Worker. In addition, a Lévy theory 6 –based stochastic gradient algorithm is adopted to verify and re-optimize the solution produced by the Explorer and the Worker so as to generate the best reconfiguration solution.
The key contributions of this article include (1) a reconfiguration decision-making model HiCoACR for reconfigurable security protocol that decouples RDMP into scheduling sub-goal generation and resources scheduling for sub-goals; (2) a hierarchical pheromone that indicates the reconfiguration policies of HiCoACR and its updating mechanism; (3) a Lévy flight–based stochastic gradient algorithm to verify and re-optimize the optimal solution.
Related works
Naturally speaking, the core of RDMP lies in optimization scheduling, which can be classified into static scheduling and dynamic scheduling. Conventional methods for static scheduling include genetic algorithm,7–9 particle swarm,10,11 heuristic search,12,13 and so on. Dynamic scheduling algorithms include load balancing,14–16 fuzzy stochastic optimization,10,17 deep reinforcement learning,18,19 and so on. A heuristic search algorithm is adopted to find the optimal reconfiguration scheme for the target security protocol in given solution space. 20 A multi-objective evolutionary algorithm (MOEA)–based reconfigurable optimization algorithm is introduced to address energy-saving issues in reconfigurable sensor network, where a specific MOEA framework is applied to make a reasonable trade-off choice from the set of Pareto-optimal solutions according to their preferences and system requirements. 21 A quality of service (QoS)-aware service composition algorithm is proposed to handle dynamic web service composition problem by taking the advantages of both global optimization and local optimization. In this article, mixed integer programming is adopted to find the optimal decomposition of global QoS constraints into local constraints and distributed local selection is introduced to find the best web services that satisfy these local constraints. 22 A cuckoo’s breeding behavior–based heuristic method and a natural gene evolution–based heuristic method are proposed to find the best solution or near best solution of service composition, where the former applies a 1-OPT (algorithm that could reaches the solution by changing a single element in the current solution) heuristic to expand the search space in a controlled way and the later uses two memory structures to avoid the stagnation in a local optimum solution, and to ensure that exploitation and exploration are properly performed. 23 A heuristic algorithm T-HEU (a trust-based heuristic algorithm) combining trust-based selection, convex hulls, and global optimization is proposed to cope with the service composition problem. In T-HEU, the trust-based selection method is used to filter untrustworthy component services, the convex hulls to reduce the search space in the process of service composition, and the heuristic global optimization approach to obtain the near-optimal solution. 24 A systematic approach based on a fuzzy linguistic preference model and an evolutionary algorithm is put forward to solve the service level agreement (SLA)-constrained service composition problems. Specifically, the weighted Tchebycheff distance is introduced first to model this problem, and a fuzzy preference model for preference representation and weight assignment is presented, two evolutionary algorithms proposed for service composition. 25
Meanwhile, RDMP may also belong to the sequential decision tasks, 26 where multi-step problems have been solved and the consequences of a step may unfold gradually over many subsequent steps and choices. Multi-objective problems have been widely examined in many areas of decision-making. 27 In general, model-free reinforcement learning and model-based reinforcement learning are the main solutions. A FeUdal network, a novel architecture for hierarchical reinforcement learning, is proposed to solve sequential decision task such as playing computer games (such as Montezuma’s revenge), which provides great inspiration for method proposed in this article. 3 All aforementioned works serve as inspiration for the computational methods developed in this article.
Formalization of RDMP
Definition 1. Reconfiguration model for SPR is defined as a quadruples
Definition 2. RG denotes functional requirements and minimum performance indexes of the target protocol.
As complex protocols are formally derived from basic security components,
28
RG could be decomposed into a sub-goal set
Definition 3. Cryptography reconfigurable cell (CRC) are independent cryptogram components which are reconfigurable in functional, structural, and temporal dimensions.
For each CRC, its attribute set is defined as a quintet
Definition 4. RE refers to overall performance of cryptogram resource or a security protocol. Efficiency of security protocol
Definition 5. Reconfiguration solution (RS) depicts the result of reconfiguration decision-making for SPR, which consist of a protocol flow and a set of cryptogram resources constituting the flow.
Based on Petri Net model,
29
RS could be formulated as
Problem 1. RDMP for SPR is defined as follows: given reconfiguration resource There exist a sub-goal set
According to the above definitions, RDMP is to find the best solution with highest RE under the condition of meeting basic functional requirements and performance index. Figure 1 briefly illustrates the RDMP, where dotted lines with different colors represent different reconfiguration solutions and the green dotted line is the best solution.

Reconfiguration decision-making procedure of security protocol.
The HiCoACR model
HiCoACR is a two-level hierarchy architecture consisting of two modules—the Explorer and the Worker, each of which implements certain sub-tasks of reconfiguration decision-making. The Explorer points out the reconfiguration directions of protocol flow and generates scheduling sub-goal, while the Worker implements the cryptogram resources scheduling sub-tasks, where both together generate an optimal solution of RDMP coordinately.
In details, at time
Both the sub-goal generation process in the Explorer and the resource scheduling process for sub-goal in the Worker are trained by a modified version of ant colony algorithm. Meanwhile, a hierarchical pheromone
The overall design of HiCoACR model is illustrated in Figure 2 and equations (1)–(6) depict the forward dynamics of HiCoACR model
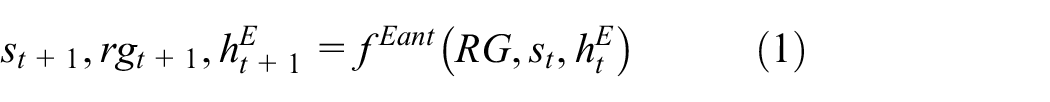





where

Reconfiguration decision-making model based on hierarchically collaborative ant colony algorithm.
Sub-goal generation
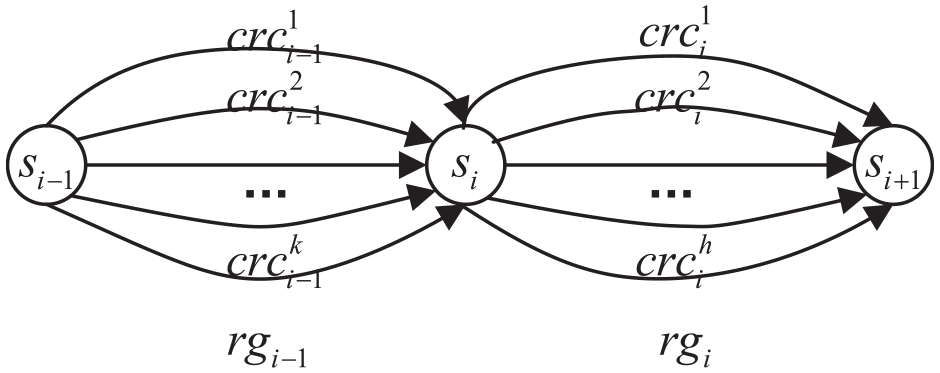
The intention of the Explorer is to produce a sequence of sub-goals guiding the directions of reconfiguration. Each sub-goal represents a component of the protocol flow. As mentioned above, there may be multiple flows corresponding to the target protocol due to difference in reconfiguration granularity. Taking protocol flows in Figure 3, for instance, there are seven distinct flows between state

Protocol flows and state transition.
Given certain security protocol, its RG could be expressed as a goal vector
To generate proper sub-goal, the Explorer adopts an ant colony algorithm with Q-learning, which combines the advantage of optimization theory, non-linear control, and reinforce learning. The Explorer takes current system state


where
Cryptogram resources scheduling
Once receiving a sub-goal conveyed from the Explorer, the Worker first computes best cryptogram resource matching the sub-goal. And then, cryptogram resources for all sub-goals together constitute the candidate optimal solution for RDMP. Finally, candidate optimal solution is verified and optimized to obtain the final optimal solution.
Cryptogram resource matching for sub-goal
Scenario of cryptogram resource matching for a sub-goal is depicted in Figure 4, where given
Scenario of cryptogram resource matching for sub-goals.
Similarly, to address this issue, an ant colony algorithm that includes just once cryptogram resource matching is introduced. Each matching process aims at finding the preponderant cryptogram resource for current sub-goal. Rules for cryptogram resource matching are depicted in equations (9) and (10)


where
Candidate solution producing
Candidate solution producing adopts the idea of concentrating group wisdom. Once all epochs are accomplished, to incorporate preponderant components of each solution, all generated solution are embedded into preponderant component extracting vectors using a linear projection

where
Solution verification and optimization
In case that the candidate solution is a relative maximum one rather than the absolute one, an optimal solution verification and optimization process is indispensable to guarantee that the real optimal solution is obtained. To address this issue, a Lévy flight 6 –based stochastic gradient algorithm is employed. The main idea is to introduce the advantages of frequent short-distance steps and accidental long-distance steps in Lévy flight into stochastic gradient policies.
Assume
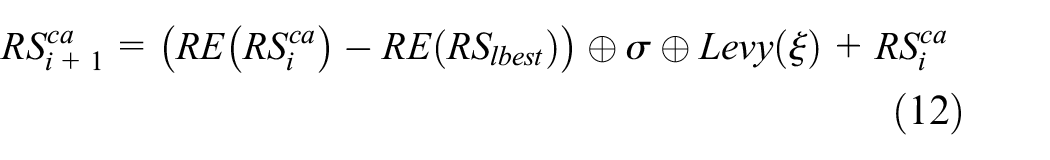
where

For ease of calculation, equation (14) is adopted to calculate the Lévy random number

where

To speed the convergence process of optimal solution optimization, some solutions are discarded and substituted by new solutions with certain probability. These new solutions are generated based on random walk policy as follows

where
After the aforementioned solution optimization, assume
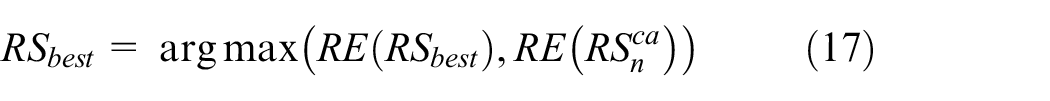
Hierarchical pheromone updating
In HiCoACR, besides the proposed hierarchical coordinated ant colony algorithm, a hierarchical pheromone is defined for reinforcing the positive feedback of the Explorer and the Worker and for sharing wisdom among populations as well. In addition, hierarchical pheromone points out the reconfiguration policies of RDMP. The hierarchical pheromone is defined as follows

where the upper pheromone
Once sub-goal generating or cryptogram resource matching is finished, a pheromone updating process is triggered. Considering the difference of ant colony algorithms used in the Explorer and the Worker, different pheromone updating rules are adopted.
Pheromone updating for sub-goals
Pheromone updating for sub-goals occurs mainly in the sub-goal generation phase. As it is mentioned in section “Sub-goal generation,” sub-goal generation adopts the ant colony algorithm with Q-learning. Once the sub-goal is generated, the pheromone of this sub-goal is updated according to the following rule


where
Updating of pheromone for cryptogram resources
Pheromone updating for cryptogram resources is triggered in two occasions, namely the cryptogram resource matching phase and the solution verification and optimization phase. During the cryptogram resource matching phase, when the best-suitable cryptogram resource for each received sub-goal is found, pheromone for this best-suitable cryptogram resource will be updated. Meanwhile, when the optimal solution is generated in solution verification and optimization phase, pheromones for all cryptogram resources constituting the optimal solution will be updated. The updating rule can be formulized as follows

where
Model details
RE evaluation
RE evaluation is the fundamental of model training in reconfiguration decision-making, which evaluate the efficiency of both cryptogram resources and security protocol. For ease of RE evaluation, evaluation indexes used in this article include E-time, security level, resources consumption, energy consumption, and so on. E-time refers to as the time consumption that a protocol or cryptogram resource fulfills certain functionality. Security level indicates the security strength of a protocol or cryptogram component. Meanwhile, resources consumption represents the resources used by a protocol, such as memory and central processing units (CPUs). Thus, with these main indexes, a RE vector

where
Without loss of generality, a linear model is adopted as efficiency evaluation model to computer the RE of a security protocol or a cryptogram resource

where
However, it is worth noting that considering the features of efficiency indexes, components of
Reconfiguration decision-making algorithm based on HiCoACR
Once HiCoACR is trained, the reconfiguration decision-making can be done to address the RDMP with HiCoACR. The reconfiguration decision-making algorithm takes the cryptogram resources and trained hierarchical pheromone as input, and output the optimal resources set and corresponding protocol flow for the target protocol.
In details, the algorithm begins at the initial system state

Where
Experiments and discussion
Experiments setup
To explore the properties of HiCoACR, experiments are carried out to analyze its convergence, performance, and transferability. The subjects in our experiments include a reconfigurable cryptogram resources set and a security protocols set. Table 1 lists a simplified reconfigurable cryptogram resources set, which includes a mass of atomic and compound cryptogram resources in diverse forms such as cryptocards, cryptographic devices developed on FPGAs or reconfigurable processors, and so on. The developing platforms, performances, and other attributes are left out in Table 1. And for any one resource list in Table 1, there may be multiple physical devices with different performances corresponding to it.
Simplified reconfigurable cryptogram resources.

Security protocols adopted to test HiCoACR are listed in Table 2, which include authentication protocols, communication protocols, and key agreement protocols. Convergence and performance experiments are mainly tested on authentication protocols, but communication protocols and key agreement protocols are utilized to demonstrate the transferability of HiCoACR. Moreover, details of these security protocols can be derived from related references.
Security protocols.

The simulation mainly includes three procedures. The first phase is data preparing, where data such as functionality, interface, and performance of all cryptogram resources and the composition of target protocols have to be provided. In fact, we extract these data of cryptogram resources and target protocols and organize them in JSON format instead of operating physical devices which simplifies the training process. Usually, resource files with different amounts of cryptogram resources are prepared to simulate different scales of cryptogram resources.
The second phase is model adjusting, where the inputs and parameters of our algorithm are adjusted to simulate different scenarios. For instance, the scale of cryptogram resources is set to different values by inputting different resource files while testing their influences on convergence ratio. While examining the influence of pheromone volatility factors on convergence ratio, parameter
The third phase is model training, where the convergence, performance, and model transferability are analyzed. During this phase, the proposed model is executed and a best reconfiguration solution for the target protocol is generated. Meanwhile, the policies for reconfiguration decision-making are stored, which can be transferred to reconfiguration decision-making for other target protocols.
Convergence analysis under different parameters
Convergence analysis mainly focuses on the influences of cryptogram resources requirements of security protocol, total scale of cryptogram resources, the step length of global optimization, the pheromone volatility factor, and the population collaboration on the model convergence. And the stopping condition for training is that the deviation of two adjacent solutions is less than 0.01.
Resources requirements of protocol and total scale of cryptogram resources
The total size of cryptogram resources carried on nodes and the cryptogram resources requirements of security protocol directly affect the performance of the reconfiguration decision model. To verify the influences, authentication protocols listed in Table 2 are chosen as target security protocol to represent different scales of cryptogram resources requirements, and we range the total scale of cryptogram resource from 0 to 500.
The influences of cryptogram resources requirements or scale of cryptogram resources on model convergence are illustrated in Figure 5. The x-axis represents the total scale of cryptogram resource and the y-axis denotes the convergence time. From Figure 5, it can be drawn that when cryptogram resource requirement is fixed, the larger the size of the total cryptogram resources, the slower the convergence rate. The reason is that the larger the size of the total cryptogram resources is, the bigger the searching space of RS is, which results in slower convergence speed. Thus, larger scale of cryptogram resource leads to lower model convergence rate.

Influence of resources requirements and resource size on convergence.
Meanwhile, when the value of x-axis is set to be fixed, the convergence time of Hsieh’s scheme, Priauth, Jiang’s scheme, Roy-Chowdhury’s scheme, and Chen’s scheme increase in turn, where the resources requirement increases in turn as well. That is to say that when the size of the total cryptogram resources is fixed, the greater size the resources requirement of protocol is, the slower the convergence rate is. Similarly, the reason is that the times of loops enlarge with the increase of resources requirement, which leads to slower convergence as well. Even when concurrency strategies are adopted to optimize the algorithm performance, the tendency will remain the same for the reason that the next loop depends on the pheromone updated in last loop.
Step type in solution verification and optimization phase
In solution verification and optimization of HiCoACR, a Lévy flight–based stochastic gradient decline algorithm is adopted. The convergence rate of this stochastic gradient decline algorithm greatly influences the convergence rate of HiCoACR, where the Lévy step plays a vital role. To analyze the influence of different step types on model convergence, the fixed step and the random step are taken as benchmarks. And
From Figure 6, we can find that the Lévy flight step outperforms the random step and fixed step in convergence. After deep analysis, we find that the Lévy flight–based stochastic gradient decline algorithm adopts the Lévy flight step which combines long step and short step, and steps will be adjusted according to the distance to the optimal solution, resulting in faster convergence speed. In addition, compared to fixed step, random step possesses faster convergence because randomness of step length increases the probability to find the best reconfiguration solution.

Influence of step type on convergence.
Volatility factor of pheromone
In HiCoACR, a hierarchical pheromone is defined to reinforce positive behaviors, which is adopted to imitate memory ability of ant colonies and is updated in each loop. Meanwhile, the pheromone volatility factor is used to simulate memory deterioration. To examine the effects of volatility factor, the total size of cryptogram resources is set to be 100 and choose Hsieh’s scheme as target security protocol. As both the flow pheromone and cryptogram resource pheromone have its own volatility factor, the influence of these two volatility factors is tested separately. Value of volatility factor for resources pheromone is set to be 0.08, 0.1, 0.12, 0.15, 0.2, 0.25, 0.3, and 0.35, while value of volatility factor for flow pheromone is set to be 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, and 0.4.
From Figure 7, we can find intuitively that larger volatility factor possesses less convergence time, which means the larger volatility factor, the faster the convergence speed. The reason is that the volatility factor denotes forgetting probability of history interactive information among populations. When a pheromone gets to 0, the sub-goal generation action or matching action is forgotten, which influences the ability of solution searching. When the volatility factor gets larger, the pheromones of unvisited cryptogram resources or protocol flow which are relatively less than that of frequently visited ones will drop to 0 much faster and the probability that the visited ones are selected again will get larger, leading to the speed-up of convergence process. However, larger volatility factor leads to less diversity of reconfiguration policies due to the rapid decline of pheromone, which decreases the randomness of sub-goal generation and cryptogram resources matching.

Influence of volatility factor of pheromone on convergence.
In addition, when the volatility factor of protocol flow and cryptogram resources are set equal, the convergence time of the former is shorter than that of the latter. Because volatility factor of protocol flow not only affects the directions of reconfiguration, but also influences the resources pheromone. When the volatility factor of protocol pheromone gets larger, the probabilities that unvisited protocol flow will be selected is lower, which will lead to the pheromones of corresponding cryptogram resources in unvisited protocol flows lower than that of cryptogram resources in frequently visited protocol flows. This further increases the convergence speed. Thus, the influence of volatility factor of protocol flow pheromone is greater than that of resources pheromone. And either of these two volatility factors is set unsuitable, the collaboration relationship of the Explorer and the Worker will be broken.
Population collaboration
Population collaboration is one of the most vital mechanism to decrease the searching space of reconfiguration solutions in HiCoACR. To analyze its influence on model convergence, change the ant number in the Explorer and the Worker to adjust the degree of collaboration of the Explorer and the Worker. First, let the numbers of ants in the Worker to be 50, set numbers of ants in the Explorer to be
From Figure 8, when the number of ants in the Explorer or in the Worker drops to 0, the convergence time gets longer. Meanwhile, when the number of ants reaches a certain value, the convergence time is tending toward stability. The reason is that when the ant number in the Explorer or the Worker equals 0, there exists only one population and interpopulation collaboration disappears, which results in that HiCoACR degenerates to Cuckoo search algorithm when number of ants in the Explorer is 0 or degenerates to ant-Q algorithm when number of ants in the Worker equals 0. And at that moment, the convergence time approximately reaches the ceiling. In addition, according to the experiments results, number of ants in the Explorer and the Worker is more suitable to be set to about 50 in terms of the given protocol samples.

Influence of population collaboration on convergence.
Performance analysis
Performance analysis of HiCoACR model aims to compare model performance with certain benchmark algorithms. Set size of whole cryptogram resources to be 100, take ant colony algorithm, 40 Cuckoo search algorithm, 41 and reinforcement learning 42 as benchmark algorithm and set authentication protocol in Table 2 as target security protocol.
From Table 3, it could be seen that HiCoACR model possesses less time cost and much higher accuracy, which indicates that HiCoACR outperforms given benchmark algorithms in accuracy and efficiency. According to above designation, HiCoACR model divides the reconfiguration solution searching process into two sub-process including controlling directions of protocol flow and cryptogram resources matching. Sub-goal generation phase implemented by the Explorer screens the reconfiguration solutions with higher RE and controls the directions of sub-process according to protocol flows using ant colony algorithm with Q-learning, which greatly narrows the solution space. Meanwhile, cryptogram resources scheduling phase executed by the Worker is consist of sub-goal matching, candidate solution producing, solution verification and optimization and responsible for reconfiguration solution producing and optimization. Compared to above benchmark algorithms, HiCoACR adopts the advantages of population collaboration and reinforcement learning. When the number of ants in the Explorer is 0, HiCoACR degrades into Cuckoo search algorithm. When the number of ants in the Worker is 0, HiCoACR degenerates into ant colony algorithm with Q-learning. Thus, HiCoACR outperforms the given benchmarks in performance.
Performance analysis.

Model transferability analysis
Model transferability analysis aims at verifying the transferability of trained model on different categories of security protocols. Model transferability mainly reflects in the acceleration of convergence under the condition of ensuring accuracy in reconfiguration decision-making. Thus, average speed-up ratio is adopted to assess the model transferability. And speed-up ratio is defined as the ratio of convergence time of baseline and convergence time of given model, namely

where
Three modes are taken into consideration in this experiment including without pre-training, pre-trained with same category, and pre-trained with different categories. For mode of without pre-training, no reconfiguration policy is trained ahead of time and the pheromone of both protocol flow and cryptogram resources is initialized with 0. For mode of pre-trained with same category, reconfiguration policy has been generated according to security protocols the same category with the test samples. For mode of pre-trained with different categories, reconfiguration policy has already been generated with security protocols whose category is different with the test samples.
Set size of total cryptogram resources to be 100, take the first three authentication protocols in Table 2 as training samples and adopt rest two authentication protocols, key agreement protocols and communication protocols as test samples. Meanwhile, ant colony algorithm, Cuckoo search algorithm, and reinforcement learning are selected as benchmark algorithms as well.
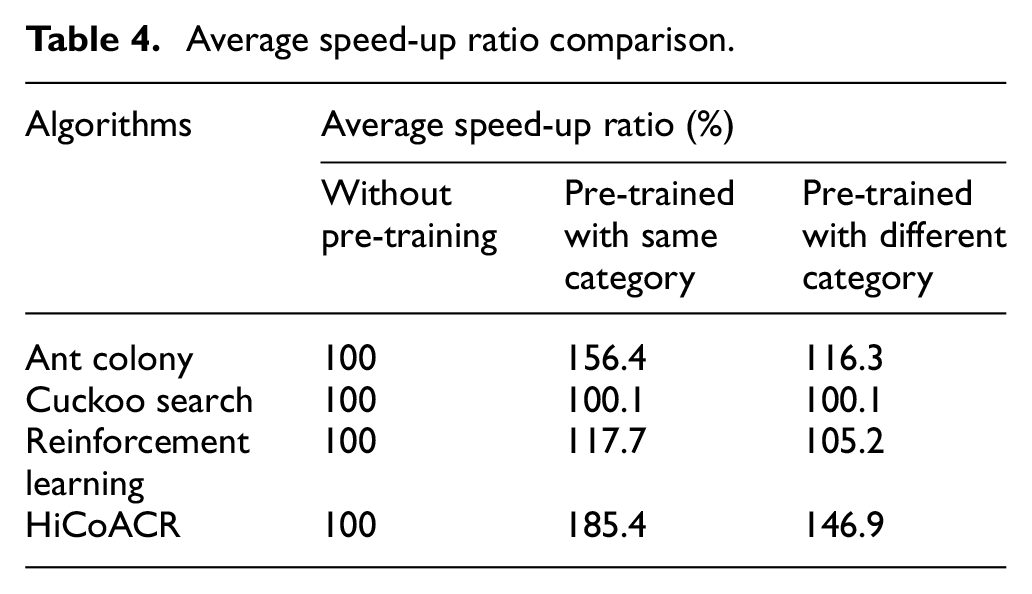
Set the time cost of the mode without pre-training as baseline, we can see from Table 4 that average speed-up ratio of pre-trained with protocols in same category is larger than that of pre-trained with protocols in different categories. The reason is that the mode pre-trained with same category provides more useful information for reconfiguration than the mode pre-trained with different categories. Meanwhile, we can find that average speed-up ratio of HiCoACR is higher than that of given benchmarks regardless of application modes. The reason is that both protocol pheromone and resources pheromone can provide reconfiguration policy during decision-making, which results in less time cost in HiCoACR than other benchmark algorithms. Thus, HiCoACR outperforms the given benchmark in model transferability.
Average speed-up ratio comparison.
In conclusion, the hierarchically collaborative ant colony-based reconfiguration proposed in this article enjoys higher convergence speed, better performance, and model transferability. However, as the ant colony algorithm has the shortcomings of long convergence time and is easy to get into the local optimal solution, our model may exist the same problem in some degree, although an adaptive pseudorandom ratio selection rule and a parallel computing mechanism are adopted in the simulation to alleviate the two shortcomings.
Conclusion
Reconfiguration decision-making is one of the key processes to reconfigurable security protocol design, which determines the performance of security protocol. This article combines the idea of hierarchical reinforcement learning and collaborative behavior of biological populations and proposes a reconfiguration decision-making model named HiCoACR based on hierarchical coordinated ant colony algorithm. It takes the advantages of reinforcement learning and population collaboration and handles the RDMP commendably. The method of this article may also be applied to decision-making problem such as military task programming, route planning. In addition, in order to eliminate the problems of long convergence time and falling into local optimal solution, we will keep on improving our model in the future study.
Footnotes
Acknowledgements
The authors would like to thank the Associate Editor and all the anonymous reviewers for their insightful comments and constructive suggestions.
Handling Editor: Suat Ozdemir
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (grant nos 61773399 and 61403400) and China Postdoctoral Science Foundation special funded project (grant no. 2017T100792).