
Abstract
Movie data has a prominent role in the exponential growth of multimedia data over the Internet, and its analysis has become a hot topic with computer vision. The initial step towards movie analysis is scene segmentation. In this article, we investigated this problem through a novel intelligent Convolutional Neural Network (CNN) based three folded framework. The first fold segments the input movie into shots, the second fold detects objects in the segmented shots and the third fold performs object-based shots matching for detecting scene boundaries. Texture and shape features are fused for shots segmentation, and each shot is represented by a set of detected objects acquired from a light-weight CNN model. Finally, we apply set theory with the sliding window–based approach to integrate the same shots to decide scene boundaries. The experimental evaluation indicates that our proposed approach outran the existing movie scene segmentation approaches.
Keywords
Introduction
The exponential growth of multimedia data exposes various domains for the researchers around the globe in which the entertainment data, such as movies, have a prominent role. In such huge video data,1,2 efficient organization3,4 and browsing/retrieval 5 of a specific movie are challenging problems. To tackle these problems, the basic step is to develop schemes to parse a movie by segmenting it into shots and scenes, which is based on its hierarchical structure that is shown in Figure 1. A continuous sequence of frames acquired by a single camera is called a shot, which is the basic building blocks of a movie. However, a single shot is insufficient to deliver any semantic meaning. On the other hand, a scene consists of one or more consecutive shots, which are semantically correlated and share the same physical settings or presents a continuous action performed by the actors. Thus, users are more likely to recall a scene rather than a shot, because it covers a whole event or sub-story in a movie.

Hierarchical structure of a movie.
Scene segmentation plays a vital role in movies data analysis that have a large number of applications, such as summarization,6,7 indexing and retrieval,8,9 alignment of subtitles, 10 and characters identification.11,12 Due to the diverse nature of movies, the available literature for scene segmentation can be grouped into three major categories based on features extraction, which include (1) visual-based, (2) audio-based, and (3) hybrid scene segmentation methods. The first algorithm for video segmentation based on credible scene boundaries is presented by Kender and Yeo. 13 They calculated short-term shot-to-shot coherence using a color histogram to measure the similarity between new and current shots. Similarly, Rui et al. 14 calculated a color histogram of the first and last frame of a shot and then used activity measure clustering to get similar shots from the video. Finally, they merged the overlapping shots of the video to identify the scene boundaries. Rasheed and Shah 15 pointed out the problem of over-scene segmentation in action movies by calculating the length of shots and motion contents to compare it with the adjacent shots. Finally, shots that have high motion are grouped into the same scene. In another work 16 , they proposed a graph partitioning–based scene segmentation scheme in which each node represented a shot and the edges between these nodes represented the temporal–visual coherence. A normalized cuts technique was then applied to produce a number-prescribed segmentation of a scene. However, this method was unable to segment the scenes based on the semantic meaning, which is one of the main challenges in the scene segmentation literature. A statistical approach based on Markov Chain Monte Carlo (MCMC) was proposed for scene segmentation by Zhai and Shah 17 where scenes were generated using stochastic Monte Carlo sampling. They introduced diffusion to merge and split updates to determine the scene boundaries. Gu et al. 18 proposed an energy minimization–based video scene segmentation scheme by formulating the procedure of segmentation as minimal energy, in which the global constraint was presented as content and local constraint as context energy. A text-based scene segmentation scheme was proposed by Cour et al., 10 they analyzed specified-scripts of the movies and segmented the movie into scenes by aligning the common dialogues and timestamps. Due to the extensive inconsistencies between the scripts and captions, the alignment of the text rate was restricted, which affected the overall accuracy of the scene segmentation technique. Weng et al. 19 studied the social relationships of actors in movies and tried to segment movie scenes based on their appearance. They built a role social network of the actors and then analyzed the variance in context. This method showed good results in segmenting movie scenes. Badrinarayanan et al. 20 used a Shot Transition Graph (STG), where each mentioned node presented a shot and the edges among them were weighted based on their similarity. Finally, the STG was split into sub-graphs using normalized cuts to partition the graph to detect the scene boundaries. Baraldi et al. 21 combined a local image descriptor and temporal clustering to divide the videos into coherent scenes. Kalith et al. 22 performed video segmentation using moving object detection in each frame. A semantic video scene segmentation method was proposed by Ji et al. 23 for image captioning using a deep model. First, keyframes were selected from shots and then forwarded to a deep model to generate semantic text descriptions. The generated captions for each keyframe was then utilized to check the similarity between the shots. For three-dimensional (3D) point cloud videos, a generic segmentation approach is presented in Lin et al. 24 by exploiting geometry in RGBD, which is based on low-level features like connectivity and compactness. They represented the object’s rough estimation in one frame to exploit temporal coherence with hierarchical structures. This hierarchical structure was used in an efficient way to establish temporal correspondence on different scales of the object’s connectivity, temporally managing the splits, and merging of the objects helps to update the segmentation.
Shot-based keyframe selection is one of the main limitations found in existing literature because presenting a shot by one keyframe results in missing lots of information for lengthy shots. On the other hand, such schemes need a special module for keyframes selection. The second major issue in these schemes is low level feature–based shots similarity measurements, because the shots of a single scene are semantically related, and it is very challenging to represent semantic meaning through low-level features. To tackle these problems, we proposed a scheme to segment a movie into scenes based on the object’s appearance in each shot. First, the movie is segmented into shots using texture and color features, and then the objects are detected in each shot using a YOLOv3 25 Convolutional Neural Network (CNN) model, trained on Common Objects in Context (COCO) dataset 26 that has eighty classes of daily life objects. Finally, we proposed a novel set theory–based mechanism for shot matching to detect scene boundaries. The main contributions of this article are summarized as follows:
In movies, multiple cameras are used to capture a scene from different angles, and finally shots from each angle are merged to present a scene. We fused texture and color features to detect these shots in an efficient way.
Existing techniques rely on a single or two keyframes to represent a shot, which results in the loss of information. Also, these techniques need an extra module for keyframe extraction. In contrast, we represented a shot through a set of detected objects that appeared in the same shot. Our strategy covers maximum information of a shot by detecting objects in all the frames.
Shots similarity is a crucial step in scene segmentation techniques, which is usually done through feature matching, which needs extensive processing time. Thus, a novel set theory–based shots matching approach is proposed, which is computationally efficient compared to the features-based matching approaches.
The rest of the article is organized as follows: section “The proposed method” discusses the proposed methodology for scene detection in detail. Experimental results and discussion are presented in section “Experimental evaluation,” which is followed by the conclusion and future work in section “Conclusion.”
The proposed method
In this section, we present the proposed framework in detail. Our method is three folded: (1) shot segmentation, (2) shot-based object detection, and (3) shot matching using set theory. All these steps are discussed in subsequent sections in detail. The proposed system can effectively segment a full-length movie of any genre into scenes for further analysis. The overall framework of the proposed system is given in Figure 2.

Our proposed framework for scene segmentation in movies.
Shot segmentation
The hierarchical structure of movies assists in parsing a movie into short-length clips, which makes high-level video segmentation and movie analysis more effective. Using this advantage, we first segmented the whole movie into shots. Low level features, such as a color histogram, Local Binary Patterns (LBPs), and a Histogram of Gradients (HoG), shows better performance in shot segmentation when it comes to frame-by-frame comparison. Inspired from the histogram based method, 27 we used HSV color space for a color histogram and LBP for texture features to compute the similarity between two consecutive frames. A single frame is represented by a feature vector FV of size 360 by concatenating a color histogram of 70 bins, which is achieved using color quantization in HSV color model and 290 texture features. For texture features, the first LBP patterns are extracted from a frame, in which we only selected 58 uniform patterns, and then we applied five 2 × 2 angular structures to analyze these patterns. Finally, a texture feature vector of size 5 × 58 = 290 is obtained. A detailed description of these features extraction is given in Sajjad et al. 27 The similarity S between two consecutive frames is calculated using equations (1) and (2)


where S(i,j) is the similarity score between feature vectors FVi and FVj of the ith and jth frames, respectively. If the calculated similarity score between the ith and jth frames is greater than a predetermined threshold, then the jth frame is considered as related to the previous shot; otherwise, a new shot is considered to be initiated. We have set the threshold value equal to 0.9 after extensive experiments.
Shots based object detection
The recent integration of deep learning with high computational power enable machines to successfully solve object detection, 28 classification, 29 and several other problems related to images and videos in real time. 30 We applied deep learning in the domain of movie scene segmentation to detect various objects in a shot. For object detection, we used a YOLOv3 CNN 25 model with DarkNet backend framework, trained on the COCO dataset. 26 Due to its ability to recognize multiple objects in a single image by encountering multiple regions at once using only one neural network makes it suitable for our problem. The objects contained in the COCO dataset are categorized into 80 classes that can be favorably used in objects based shot segmentation in movies. The objects include pedestrians, vehicles, signboards, and many other indoor and outdoor objects that play a vital role in movie data. In YOLOv3, the object detection problem is treated as a regression problem, and it simultaneously makes prediction for multiple classes in one look. It also encodes the contextual information of the classes based on their appearances, which makes it applicable to our problem. The architecture of YOLOv3 uses successive convolutional filters of size 3×3 and 1×1 in the sequence of 53 convolutional layers. Each layer is followed by a non-linear activation function, which is called Leaky Rectified, and a max-pooling layer of size 2×2 with stride 2. YOLOv3 has significant benefits over previous versions in terms of time complexity and accuracy, and it can process 78 fps without batch processing. Figure 3 shows some sample frames from the testing movies with detected objects using YOLOv3.

Sample frames from testing movies with the detected objects of various categories.
Most of the scene segmentation schemes select one keyframe or the first and last frames to represent the whole frames sequence of a shot.31,32 Such schemes ignore lots of useful information when the shot is lengthy. In our scheme, we detect objects in all frames of the shots to make sure that none of the information is lost. A union of the detected objects in each shot is then taken to associate the set of objects with the concern shot using equations (3) and (4)


where ⊙ is the function to detect objects in the frames f1, f2, …, fN of shot Sh; S is the set of all detected objects ob1, ob2, …, obm; and Sset is the set of objects that appeared in the shot after taking the union. The union of all detected objects of the shot is taken to avoid the repetition of same object in a single shot. Finally, we represent each shot as a set of objects based on the contents present in it with this mechanism.
Scene boundaries detection using set theory and sliding window approach
As discussed in the introduction, a scene is a group of consecutive shots that are semantically correlated and share similar coherence in time and space to present an entire event. Low-level features can give some useful information about the connection between shots, but they are unable to describe the semantic correlation between shots. Therefore, we efficiently utilize the contents of the shots to measure similarity using set theory in the proposed scheme. An example is given in Figure 4 to explain the concept of the proposed shots matching mechanism.

Scene boundary detection using sliding window approach.
In the previous step, each shot is represented as a set of detected objects as shown in Figure 4. A window of four shots is taken to determine the similarity between the shots. According to Figure 4, let’s say the set of shots 2, 3, 4, and 5 are in the red window. Then, we assume that the set of shots 2, 3, and 4 belongs to the same scene, and to check the set of shot 5, we compare it with the rest of the sets in the window. The comparison is based on set theory, and the intersection of set 5 is taken with sets 2, 3, and 4, separately. If the number of elements of intersection is greater than or equal to any of the total elements of sets 2, 3, or 4, the shot is considered to be a part of the previous running scene and the window moves to the next shot, as highlighted with the green window. Now the intersection of set 6 with the rest of the sets in the green window gives an empty set, which means there are zero elements in common with these shots. Hence, a new scene is started, and the window will start from set 6 (blue window). The overall mechanism is given in Algorithm 1.

Experimental evaluation
In this section, we present the experimental details of the proposed movie scene segmentation scheme. The experiments were conducted on a desktop computer with an Intel® Core™ i7-3770 CPU that has 16 GB of RAM. The programming environment was Python 3.5 running on a Windows 10 x64 operating system. The dataset information is given in the subsequent section.
Dataset and ground truth
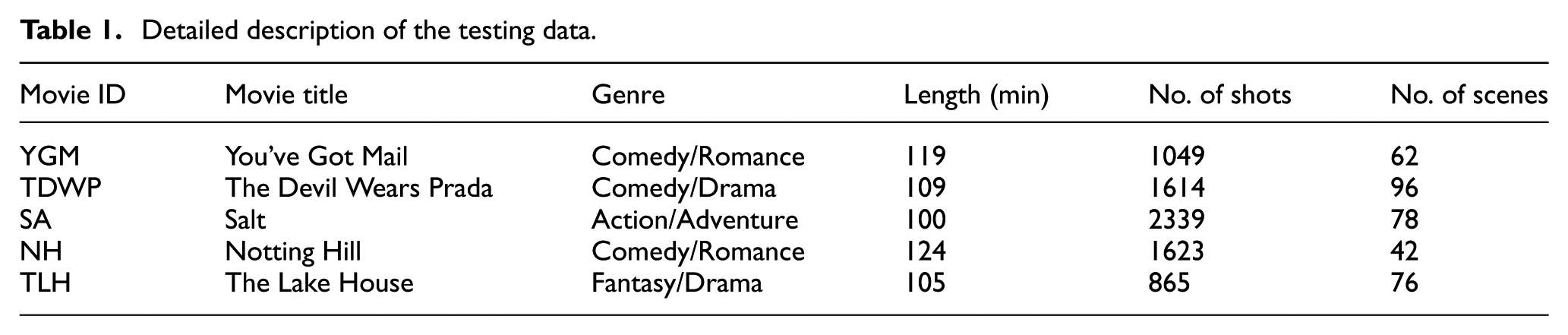
A total of five movies of different genres were used in our experiments to evaluate the scene segmentation performance. These movies included You’ve Got Mail, The Devil Wears Prada, Salt, Notting Hill, and The Lake House. Detailed information about the testing data is given in Table 1. Due to the variation found in the definition of a scene, there is no benchmark dataset with common ground truth in the literature for movie scene segmentation. In our experiments, we generated ground truth by selecting scene boundaries with the help of movie scripts. The last column of Table 1 shows the total number of scenes as the ground truth for all movies.
Detailed description of the testing data.
Scene change detection
The common metrics used by most of the researchers to evaluate scene change accuracy are Precision (P), Recall (R), and F-measure (F). We followed the criteria used in Chen et al. 33 to evaluate scene change accuracy using equations (5)–(7)


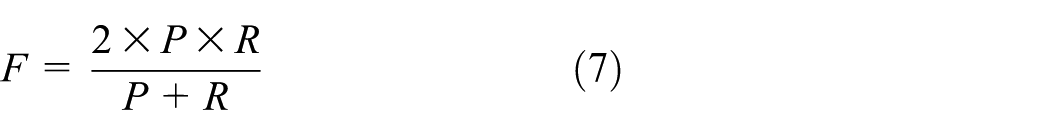
where Nc is the number of correct detected scenes boundaries, Nm is the number of missed ones, and Nf is the number of false detected scene boundaries. Table 2 represents the overall performance of the proposed scheme. The results for movie NH are lower, because in this movie most of the shots are close-ups of the actors’ faces due to which in most of the shots only a single class is detected, such as person. This kind of error is briefly discussed in the next sub-section.
Overall results of the proposed scheme.

Analysis for window size determination
To determine the window size for shots comparison, we repeated our experiments for different sized windows. We noticed during the experiments that our algorithm took more time as the window size increased. Figure 5 shows the average performance of all the movies varying the size of the window, such as from 2 to 7 shots, where abscissa presents the window size and the ordinate presents the average F-measure value of all the movies. It is proved from the experiments that the preferable window size is 4. The movie NH gave its best results on a window size of 5, but the average results of the overall movies were much better on size 4.

F-measure values for different sizes of the sliding window.
Analysis of missed boundaries
The missing of scene boundaries in our approach is occurring due to two types of errors. The first one is appearance of the same objects in two adjacent scenes. For example, almost 95% of the shots in a movie must contain an actor, which were predicted as a person class in our proposed scheme. Hence, common object detection in all shots leads to miss-detection of scene boundaries. Examples of such scenes can be found in the movie NH, which are given in Figure 6(a). This type of error is difficult to recover using visual cues without causing many false detections. The second reason for miss-detection of scene boundaries is the gradual transition between two shots. Although, there are very few gradual transitions between shots in movies, and most are found between scenes changes. A robust shot transition detection scheme can recover such errors. Figure 6(b) shows a gradual transition between two scenes.

Samples of missed detected scene boundaries: (a) common object detection problem in two different scenes, where the first two frames represent one scene and the rest represent the second; (b) gradual transition between shots of different scenes.
Conclusion
Movies data in computer vision domain is considered as one of the most challenging data due to its long length, diversity, high semantics, and camera motion. However, its hierarchical structure is helpful for its segmentation into shots and scenes for better understanding. In this article, we proposed an efficient three folded framework for scene segmentation in movies. First of all, the shots are segmented using fusion of low-level features. Next, a CNN model is employed for object detection in each shot, and the shots with similar objects are combined together. Finally, the set theory with sliding window approach is used to find similarity between shots and assign them to an appropriate scene. Our approach is not only an effective tool for scene boundaries detection in movies, but it can be applicable to other movie-related tasks, such as keyframes extraction for indexing and retrieval, video abstraction, skims selection, and trailer generation. In future research, we intend to apply a movie summarization algorithm on these segmented scenes for movies trailer generation.
Footnotes
Handling Editor: Fuyuan Xiao
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2018R1D1A1B07043302).