
Abstract
As a fundamental assumption in simultaneous localization and mapping, the static scenes hypothesis can be hardly fulfilled in applications of indoor/outdoor navigation or localization. Recent works about simultaneous localization and mapping in dynamic scenes commonly use heavy pixel-level segmentation net to distinguish dynamic objects, which brings enormous calculations and limits the real-time performance of the system. That restricts the application of simultaneous localization and mapping on the mobile terminal. In this article, we present a lightweight system for monocular simultaneous localization and mapping in dynamic scenes, which can run in real time on central processing unit (CPU) and generate a semantic probability map. The pixel-wise semantic segmentation net is replaced with a lightweight object detection net combined with three-dimensional segmentation based on motion clustering. And a framework integrated with an improved weighted-random sample consensus solver is proposed to jointly solve the camera pose and perform three-dimensional object segmentation, which enables high accuracy and efficiency. Besides, the prior information of the generated map and the object detection results is introduced for better estimation. The experiments on the public data set, and in the real-world demonstrate that our method obtains an outstanding improvement in both accuracy and speed compared to state-of-the-art methods.
Introduction
Simultaneous localization and mapping (SLAM) is a technology that builds a map of an unknown environment while simultaneously localizing the sensor with the input information. It has been widely used in mobile robots, autopilot, or AR/VR applications over the past decades.
There is a basic assumption in the visual SLAM that the environment is static and the changes in visual field only come from the motion of the camera. So the previous SLAM systems treat the environment as a whole rigid body. Unfortunately, in some main application scenarios of the SLAM system such as urban roads or indoor places with people, this assumption will not hold. The dynamic objects in the view will have a tremendous negative impact on the accuracy and robustness of the SLAM system. Therefore, the SLAM problem in a dynamic environment has attracted much attention in recent years.
The core problem of the SLAM for dynamic scenes is the confusion of multiple sets of geometric constraints that existed in the data association. These constraints themselves are inconsistent. If only two pictures are given, it is challenging to distinguish whether objects in the scene are moving. Humans can make a judgment by experience, which is based on the semantic information. That makes the SLAM technology naturally develop to semantic SLAM. A typical choice is to introduce a pixel-wise segmentation network such as Mask R-CNN 1 and FCN 2 to eliminate the dynamic parts before tracking and mapping, which brings huge consume of graphics processing resources at the same time. For instance, the Mask R-CNN takes more than 2 s to process a frame on CPU. Previous works usually make use of GPU 3 –5 to accelerate computation and run very hard on CPU, not to mention on small mobile devices or operate in real time. In this article, we focus on the capacity of real-time operation on CPU of the SLAM system with semantic segmentation for better application in practice.
In addition, most of the existing dynamic SLAM solutions are designed for RGB-D SLAM. 3,5 –7 Since the RGB-D camera can obtain the depth directly, it makes the dynamic object easily to be detected by the inconsistency between the actual depth and the projection depth. However, the RGB-D camera may be easily affected by complex illumination, and its effective distance is limited, generally no more than 10 m. That makes it unsuitable for applications in outdoor environments such as autonomous driving and drone navigation. In contrast, the monocular camera has no limitation of perception distance and can be easily integrated into mobile devices at low cost. And the monocular camera is more sensitive to dynamic objects due to its lack of depth information. But there are few solutions based on monocular SLAM. 8,9
In this article, we propose a lightweight method to mitigate the negative effects of dynamic objects, which attains a real-time performance on CPU. The solution can be used in monocular SLAM as well as in stereo and RGB-D SLAM. The main contributions of this system can be summarized as follows: Instead of performing instance segmentation on the 2D image, we use the object detection network combined with the spatial information to segment the 3D point clouds directly. A framework with a weighted-random sample consensus (RANSAC) solver is designed, which hierarchically solves the camera pose and the motion of each moving object. The weight of each data point introduces the prior reliability as guidance to the pending model. A comprehensive feature evaluation approach with a semantic probability map that integrates multiple dimensions of information including the tracking quality, motion probability, and multi-view geometric information.
The proposed method is integrated into the ORB-SLAM2 10 and shows obvious improvements to the system in dynamic scenes. The experiments on the TUM-RGBD data set and the KITTI data set demonstrate that our method outperforms the state-of-the-art method Dyna-SLAM in accuracy with a huge advantage in speed.
The rest of this article is organized as follows. In section “Related work,” we discuss the previous work about SLAM systems in dynamic scenes. Section “System” shows the framework of the proposed method and details of the proposed framework to estimate the camera pose and perform 3D segmentation. Section “Experiment” provides qualitative and quantitative experimental results. At last, the conclusions and future work are given in section “Conclusion.”
Related work
Saputra et al. 11 summarized the previous work about the SLAM methods for dynamic scenes before 2018 and divided them into three types according to their outputs and applications: (1) for robustness SLAM; (2) for dynamic object tracking; (3) for joint segmentation and reconstruction.
Among them, a convention is to remove the dynamic objects as outliers, and the commonly used strategy can be summarized into two categories: motion consistency detection based on multi-view geometry and semantic segmentation based on deep learning network. Semantic-based methods can detect those objects that people subjectively believe that they will not remain stationary, such as vehicles and pedestrians, while geometry-based methods can identify those objects that are objectively moving. The two are often used alone or in combination.
DS-SLAM 6 applies SegNet to achieve real-time pixel-level segmentation and eliminate pedestrians in the image. The authors conduct dynamic point detection by optical flow from the difference between the patch on both sides of tracking and the distance of reprojection and treat all points in the semantic segmentation boundary containing dynamic points as dynamic points. What’s more, an octree map is established. Zhong et al. 12 proposed to combine SLAM with a deep-neural-network-based object algorithm, aiming to make target detection and SLAM promote each other. This article uses the SSD-NET fine-tuned on the SLAM data set along with the GrabCut algorithm to segment the background and foreground and dynamically estimate the probability of feature points and 3D points to be dynamic points. The perception of “motion” is mainly derived from CNN object detection and is propagated through the 2D-2D, 3D-2D correspondences with the assumption that “Proximity is similarity.” Mask-SLAM 13 uses the mask generated by semantic segmentation to remove feature points from the sky and cars and improve the robustness of vSLAM system. Zhang et al. 14 solves object association and pose optimization in a tightly coupled processing of optimization, by which both aspects can promote each other.
In addition, RGB-D camera is widely used as the sensor for SLAM in dynamic scenes as it can directly obtain depth information. Zhou et al. 15 utilizes k-means clustering after combining RGB images and depth maps to realize image segmentation. Dyna-SLAM 3 integrates Mask RCNN into ORB-SLAM2 for instance segmentation and performs dynamic object detection based on multi-view geometry when the input is RGB-D. What’s more, they project the RGB and depth map of the previous keyframe onto the current frame to inpaint the occluded background without dynamic objects. Sünderhauf et al. 16 proposed a method of semantic mapping based on RGB-D data, which uses SSD-NET to perform object detection on a single RGB frame, and then applies the 3D segmentation algorithm proposed by Pham et al. 17 to further segment the 3D point clouds based on the detection results and depth information. An ICP-like method is applied for data association and fusion between objects. Zhang et al. 5 proposed a dense RGB-D SLAM system, which treats dynamic/static segmentation, camera ego-motion estimation, and map reconstruction as a whole and solves them simultaneously. The RGB images are sent into the PWC-Net for optical flow estimation and dynamic object segmentation is realized based on the optical flow residual between the warped image and the real frame.
In general, subject to the principle of consistent motion detection, dynamic SLAM only on pure multi-view geometry has many limitations and cannot identify objects with low speed or slowly moving parts. Recent studies are mostly focused on the use of convolutional neural networks for semantic segmentation of images, assisted by motion consistency detection based on multi-view geometry, such as the most commonly used optical flow method. 18,19 These two methods are executed in sequence, and the geometric motion detection is mainly for the purpose of checking and filling the semantic segmentation results. Our method utilizes a lightweight object detection network as the replacement of the heavy instance segmentation network. A spatial clustering algorithm based on the relative motion solver is proposed, which combines 3D segmentation, motion detection, and camera pose estimation, aiming to achieve a more accurate and robust track as well as outperforming real-time performance. Unlike most of the existing methods that use RGB-D camera as the sensor, our method targets to monocular SLAM systems.
Notation
The set of 3D points (map points) in the system is denoted as
System
In this article, the processing for dynamic scenes is divided into two aspects. The first is to make judgments about the probability of a feature comes from a dynamic object. The second is to reduce the impact of the dynamic objects based on the probability information from the first part while increasing the weight of “reliable” data points to gain more stable and accurate camera pose estimation results.
Figure 1 shows an overview of JD-SLAM. In addition to the tracking, local mapping, and loop closing thread of the ORB-SLAM2, JD-SLAM adds another object detecting thread, which is responsible for calling the parameters of the deep network to perform object detection on newly inserted key frames.

Overview of our JD-SLAM. The system is based on ORB-SLAM2, and the additional modules of JD-SLAM are marked in color. The segmentation of the point cloud is divided into two parts. The object detection runs in parallel with local mapping, and the pose estimation and segmentation are solved in a whole framework in the tracking thread in which the background and each moving objects are modeled as different relative poses. The points cloud can be segmented by hierarchically solving the different motions and searching inliers. It should be noted that the segmentation is not determined by a single track, but by a probability map constructed and updated from multiple observations.
We combine the space information to perform the semantic segmentation of the 3D point clouds, which can be splitted into two parts. In the mapping thread, an object detection network is introduced to realize the perception and approximate position prediction of dynamic objects. In the tracking thread, we combine the results of object detector with previous tracking information and the generated map to perform instance-level segmentation on the 3D point clouds and update the probability map.
The system is mainly designed for monocular SLAM, but it can also be transplanted to stereo or RGB-D SLAM. The following article will be based on monocular SLAM. If it is applied to stereo or RGB-D SLAM, just ignore the triangulation step and replace with the depth information obtained by stereo or RGB-D camera.
Object detection
As mentioned earlier, we propose to achieve semantic segmentation with object detection network and spatial information as a replacement of the complex 2D instance segmentation net such as Mask-R-CNN.
To get fast detection speed along with high accuracy, we choose Efficient-Det 20 as the object detection network, which is claimed to achieve state-of-the-art performance in real time. Efficient-Det is trained on COCO data set 21 and could segment 80 classes in total. It has seven versions of d0-d7, and the accuracy gradually improves with the speed decreases. The version d0 that we applied could achieve 38.2mAP on COCO 2017 validation data set with only 3.9 M parameters, which is enough to meet our accuracy requirements. The output of Efficient-Det is the object proposals with specified classes in the forms of a bounding box and a confidence score. We focus on several of the classes: “person,” “bicycle,” “car,” “bus,” “chair,” and “keyboard.” The left column of Figure 2 illustrates the result of Efficient-Det-d0. With respect to the amount of calculation, we only perform object detection in key frames.

Results of the core steps in the proposed system. Left: Detection results of the Efficient-Det. Middle: Clustering results of the weighted-RANSAC solver. (The size of the circle reflects the probability that the point belongs to the object.) Right: Performance of the 3D point clouds segmentation. (a) fr3/sitting_halfsphere; (b) fr2/_desk_with_person; (c) run in the real-world.
Joint Pose Estimation and 3D Segmentation.


Semantic probability map
Throughout the system, we maintain a probability map. The map records the probability that a data point comes from an object of interests or an unknown object (collectively processed as background). The probability map stores the label of a feature point and its probability of belonging to the current classification. To prevent overly complex calculations, we only allow each data point to have one possible label. If the point does not belong to any kind of objects of interests, it will be treated as a static point from the static background. In the subsequent estimation of camera poses, we will consider these points with a high possibility to be static to be more reliable and prefer to select these points for pose estimation.
Semantic probability map initialization
Since the object detection network can only provide us with the bounding box of the objects, the feature points in the bounding box cannot be distinguished to come from the object or the background. Given that the depth of the feature points is unknown at this time, we cannot make further judgments about the property of these points. To further segment the features in space, we mark all the feature points in the bounding box as potential semantic points. At the same time, an initial probability estimation is given. We believe that the feature points with a small distance from the center point of the bounding box will be more likely to come from that object. Suppose the center point coordinates of the bounding box are

where
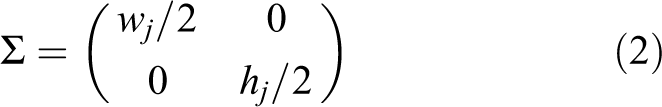
If this frame is selected as a keyframe, the new generated points will be added as the candidate map points. In the next several frame tracking, the probability that the point belongs to this object will be calculated and updated continuously from the proposed 3D segmentation framework. If the point can be observed stably and the probability of belonging to the background remains to be greater than a threshold (in this article is 0.85) until a few frames later, the point will be ultimately added to the mature map, and its probability will be continuously verified and updated when it is subsequently observed.
The system has no local map information when it has not been initialized. With respect to the fact that the accuracy of the SLAM system seriously depends on the quality of initialization, we set a more strict condition for initialization. All the feature points in the bounding box of dynamic objects will be eliminated, only the remaining points are used for initialization.
Update the semantic probability map
To update the semantic probability map of existed mature points in the map, we combine the prediction of the CNN object detector with the geometry information from the local map. By projecting the local map into the current frame and checking the consistency of the new prediction from the network, the omission of CNN object detector could be compensated.
When an existing 3D point is observed again in the next frame, its probability will be updated according to the following equation

where
If this is the first frame after generating the map point, the initial value of
Joint camera pose estimation and moving object segmentation
Weighted-RANSAC.


Local optimization.


As ORB-SLAM2 get an initial estimation of the camera pose by the feature matches from the past key frame, we project both the mature local map and the candidate map points into the current frame to get more 3D-2D correspondences. The correspondences obtained in data association cannot be completely accurate, the mismatches and noise may have a negative impact on subsequent pose estimation. In the scene with many dynamic objects, the assumption of overall rigidity cannot be satisfied, the correspondences from the dynamic objects and those from the static background may conflict when calculating the pose. If those correspondences from the dynamic objects are introduced into the calculation, it actually calculates the camera pose relative to the dynamic object other than the pose relative to the local map. The pose estimation in ORB-SLAM2 is based on nonlinear optimization of PNP estimation, which directly uses the motion of the reference frame as the initial value of the current frame for optimization and iteratively minimizes the reprojection error of the map points. This strategy may make better use of constraints and introduce more information when the data association is stable, while it may instead lead the optimization to a terrible solution when the outlier ratio increases.
A more common approach of pose estimation is to eliminate correspondences from the dynamic objects refer to the results of the segmentation networks and motion consistency detector, and then solve the camera pose within the remaining correspondences by the RANSAC algorithm. RANSAC iteratively searches the parameters of a mathematical model that can fit the most data points from a set of data containing outliers. The standard RANSAC considers that each data point has equal confidence when evaluating the estimated model. Therefore, the number of data elements that the model can fit within a given tolerance is used as the evaluation criteria of model quality. And the model with the most inliers found in iteration will be returned. However, that leads to the fact that the performance of standard RANSAC method will decrease rapidly as the outliers ratio increases. When it is higher than 50%, the optimal solution can hardly be found by standard RANSAC. And it is very sensitive to the threshold boundaries for dividing inliers and outliers. Matching from moving objects in dynamic scenes will further reduce the possibility of RANSAC to find an accurate pose model. Therefore, the method based on ordinary RANSAC is also not suitable for pose estimation in a dynamic environment.
We propose a novel framework with a weighted-RANSAC solver to jointly estimate the camera pose and perform 3D point clouds segmentation, which differs from the usual pose solver based on the ordinary RANSAC in the following terms: Each moving object in the image and the background is modelled as different relative poses, then those motion will be solved from the constructed correspondences hierarchically. The data points that can be fitted by an object’s relative pose will be regarded as a part of it. It should be noted that the segmentation is not determined by one observation. It is reflected by a probability map constructed and updated by multiple observations. For different solving objects, different voting weights are assigned to different data points. The weights aim to introduce the prior information from the generated map and semantic segmentation which reflects the reliability of each point for current estimation. That strategy makes the model estimation results tend to be more affected by the parts with a high probability of being inliers and enables a stable and accurate estimation result under the disordered data.
Hierarchically estimation framework
The whole framework is described by Alogrithm 1, where M represents the best model of camera pose found in the iterations, and the rest symbols are consistent with those in section “Notation.” It has three steps. The first step aims to initially estimate the pose of the camera relative to the background. By assigning higher dominance to those correspondences with higher reliability in pose calculation, the impact of correspondences from dynamic objects and inferior association can be significantly reduced. The reliability score is a comprehensive response of multiple dimensions including the past tracking quality, multi-view geometric information, and generated point clouds map equipped with the motion probability. The calculation method will be detailed in the following. Here, only the pairs from mature map points are chosen to participate in the calculation. After obtaining the pose, we take all the data points that can be fitted by the current model as the part from the static background
The second step estimates the motion of each object and segments the point clouds based on the motion clustering. For each object j detected by the Efficient-Det, we denote those correspondences that are extracted from the region in the bounding box and do not belong to the background as
At last, the camera pose of the current frame will be refined by a nonlinear optimization whose elements are all of the points from the background.
The probability of the map points calculated in this process

To speed up tracking, for the objects whose bounding box accounted for less than a certain value of the screen, we just remove all the features in the scope of the bounding box without solving its relative poses. If more than 90% of the feature points in a bound box can be fitted by the pose of background, it is considered that the object is currently in a static state. And features from that object will participate in the pose estimation in tracking, but not be added into the mature map, which aims to make the generated map reusable.
At the same time, in each iteration, we will supplement the missing points according to their 3D spatial distribution. To be exact, if a 3D point without object label is surrounded by three or more points with the same label within a certain distance, then this point will also be marked as coming from this object.
Weighted-RANSAC solver
The core of the proposed framework is the weighted-RANSAC solver, which integrates with an evaluation function with different voting weights and an extra local optimization step. The weighted-RANSAC solver is summarized in Algorithm 2. Here
To obtain higher robustness, a local optimization step
22
is introduced into the ordinary RANSAC method to optimize the results from coarse to fine. The samples input here are only the ones from
Unlike the usual RANSAC, which evaluates the models by the proportion of inliers, we use the sum of the Lagrangian distances between the estimated value and the true value as the criterion. And the score
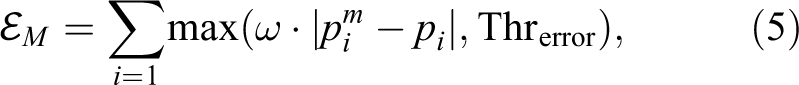
Where pi is the real position of an image point,
Reliability of correnspondences
We evaluate the reliability
1. Probability of being dynamic:
According to the motion probability of the point calculated in equation (3), if this point has high possibility driven from the background, it will be considered relatively reliable.
2. Motion consistency of adjacent frames detected by optical flow:
Optical flow is a way of describing the motion of individual pixels between images over time. It can serve as an approximation of the physical motion projected onto the image plane. With the assumption that the intensity of a pixel is invariant between two images, the optical flow tracker iteratively searches the correspondence of the source patch in the target image by minimizing the sum of squared difference (SSD) between them. Optical flow method is widely used for object detection and track.
After ORB-SLAM2 obtains the initial pose of the current frame through the assumption model such as uniform motion, the relative translation between the current frame and the previous frame can be solved. By multiplying the last image with the estimated transformation, the warped image can be obtained as a rough estimate of the current frame. We adopt an LK-optical-flow-tracker
23
to search the corresponding position
Since the disparity between the two adjacent frames is small, we can assume that the camera motion contains only rotation and no translation, so the transformation between the two images can be approximately described by a homography matrix H

Figure 3 shows the detection results of motion consistency on the TUM RGB-D data set. It can be seen that although it has some deviations, the detected motion probability is approximately consistent with the actual situation.

Results of the motion consistency detection of adjacent frames by optical flow. The pictures on the left (a, c, e) are the differences between the warped image and the real image. The pictures on the right (b, d, f) are the visualized motion probability
3. Continuous observability in tracking:
We use the past recurrence rate of a map point

where N is the number of past frames at which the point can be observed and
In general, the score of a 3D-2D correnspondence Ci can be calculated as follows

where the

Comparison of the results of the standard RANSAC and our method in segmenting a tricycle in motion. The red points represent the background and the green points represent the moving tricycle. (a) Our method and (b) standard RANSAC.
Experiment
To demonstrate the robustness and real-time performance of JD-SLAM, we integrate it to ORB-SLAM2 and operate experiments on a public data set and in a real-world environment. Figure 2 shows the performance of the core modules of our method. The dynamic objects and the background are represented in green and red, respectively, and the different circle sizes represent the probability that the point belongs to the current object. The images in Figure 2(c) are captured by the camera equipped by HUAWEI V20 with the resolution of 1920
Evaluation of accuracy
The proposed method is integrated into ORB-SLAM2. We evaluate the improved system on the TUM RGB-D data set 24 and the KITTI odometry data set. 25 The TUM RGB-D data set contains dozens of indoor sequences captured by an RGB-D camera. Among these sequences, several of them are classified as “dynamic objects” and widely used for evaluating the SLAM system for dynamic scenes. The KITTI data set contains outdoor sequences recorded from a moving car on urban roads. Although it does not specifically classify scenes containing dynamic objects, we selected several sequences that contain moving vehicles for experiment. Both of the selected data sets provide the ground truth of the camera pose for accuracy evaluation. Since JD-SLAM is mainly designed for monocular SLAM, all of the experiments are run with the monocular mode.
Along with comparing the JD-SLAM against the original ORB-SLAM2, the Dyna-SLAM is chosen as a comparison since it is also built on the ORB-SLAM2 and is the state-of-the-art method of SLAM in dynamic scenes. The experimental results of them are obtained by running the authors’ open-source codes. Accounting for the randomness of multi-threading system, we run each sequence for five times and pick the median result. For comprehensive result, the camera poses of all frames are recorded in accuracy evaluation.
We adopt absolute trajectory error (ATE) and relative pose error (RPE) to conduct the quantitative evaluation of the system. The ATE directly calculates the difference between the ground truth and the estimated camera poses, which reflects the overall performance of system. And the RPE describes the pose difference of two frames during a fixed time interval. It reflects the drift of the system. The root-mean-square error of ATE and RPE is shown in Table 1, which is calculated by the benchmark tool. 26
Localization error comparison of each frame for JD-SLAM, ORB-SLAM2, and Dyna-SLAM.

*Bold data marks the best indicators in horizontal comparison.
It can be seen in Table 1 that our system outperforms ORB-SLAM2 and Dyna-SLAM on most of the sequences and indexes, especially on the TUM-RGBD data set. As the proportion of dynamic objects occupying the screen is not large, the improvement on the KITTI data set is not as obvious as that on the TUM-RGBD data set. Some sequences in KITTI data set contain many vehicles parked on the roadside. These vehicles will be cut out in Dyna-SLAM, which reduces the available information and makes its accuracy lower than the original ORB-SLAM2, such as on sequence 03. We retain those points in tracking and avoid such problem. But on those sequences with complicated road conditions and numerous passing vehicles such as sequence 08, our method may be confused due to the interlacing of bounding boxes, while Dyna-SLAM uses Mask-RCNN to accurately segment each vehicle and achieves higher accuracy than our method. But our method still performs better than the original ORB-SLAM2.
Figure 5 shows the estimated trajectories by our method, ORB-SLAM2, and Dyna-SLAM on TUM RGB-D data set. It can be seen clearly that our estimated trajectories are much closer to the ground truth. Above quantitative comparison indicate that our method yields significant boosts in terms of robustness and accuracy, especially in the sequences of high-dynamic environments. That benefits from the object detection combined with the subsequent points cloud segmentation, which eliminate the possible dynamic data points and give an accurate pose estimation. Meanwhile, the motion consistency test by the optical flow and the observation quality check further provides reliable filtering for data.

Estimated trajectories by JD-SLAM, ORB-SLAM2, and Dyna-SLAM on TUM RGB-D data set. (a) Sitting halfsphere; (b) walking halfsphere; (c) walking xyz.
Evaluation of real-time performance
Running time is an important factor of the performance of the online system. We test the time cost of camera pose tracking. Table 2 shows the time cost of the core modules of 3D segmentation in JD-SLAM. As a comparison item, Dyna-SLAM often takes more than 2 s just in the 2D instance segmentation step. And Table 3 shows the time cost comparisons of our camera pose tracking method with the ordinary ORB-SLAM2 and Dyna-SLAM on the fr3/walking–halfsphere.
Time consumption of each module of JD-SLAM.

Tracking time cost of each frame on the TUM RGB-D dataset.

In the experiment, the operating speed of JD-SLAM basically maintains at 22 ± 5 fps (on a single-core CPU), which achieves real-time performance in most of the test sequences. Since the JD-SLAM avoids the 2D segmentation, and the adopted network has a small amount of parameters, it gains a huge advantage in speed over the Dyna-SLAM. Also, that makes JD-SLAM suitable for running on small devices with limited computing power.
Conclusion
In this article, we present JD-SLAM, a novel method to improve the performance of the monocular SLAM system in a dynamic environment while focusing on the efficiency-accuracy balance of the system. To make better use of semantic information and geometric constraint information, instead of directly segmenting 2D images, we cluster the point clouds in space with respect to the motion distribution and the object detection result. To this end, we propose a hybrid framework based on an improved weighted-RANSAC solver, which makes estimating the camera pose and solving the object motion into a whole. At the same time, the weight distribution based on the motion probability and tracking quality and the introduction of the local optimization module in RANSAC could further improve the robustness of the system. Experiments show that the proposed system has superior performances in terms of accuracy and speed than state-of-the-art methods. And it is proved that the system can run in real time on CPU with a single core.
In the future, we will try to use the results of 3D point clouds segmentation to optimize the performance of the target detection network and explore the possibility of performing SLAM and objection tracking at the same time.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China No. 61901436