
Abstract
Autonomous agents require the capability to identify dynamic objects in their environment for safe planning and navigation. Incomplete and erroneous dynamic detections jeopardize the agent’s ability to accomplish its task successfully. Dynamic detection is a challenging problem due to the numerous sources of uncertainty inherent in interpreting sensor measurements and the wide variety of applications, which often lead to use-case-tailored solutions. We propose a robust approach to segmenting moving objects in point cloud data. The foundation of the approach lies in describing each voxel using a hidden Markov model (HMM) to use a change-point detection approach to identify dynamic voxels. The proposed approach is evaluated on benchmark datasets using handheld, robot-mounted, and vehicle-mounted LiDARs, each with varying sensor characteristics. We consistently achieve performance that is better than or on par with state-of-the-art results across all scenarios, with strong generalized performance using the same algorithm configuration. Our analysis reveals inconsistencies in benchmarking metrics and ground-truth labelling methodologies for the various public domain datasets, making meaningful comparisons between moving object segmentation (MOS) algorithms challenging. This underscores the need for a standardized definition of moving points and corresponding benchmark frameworks that enable fair and accurate performance evaluations across algorithmic approaches. The proposed approach is open-sourced at https://github.com/vb44/HMM-MOS.
Introduction
The Moving Object Segmentation (MOS) problem involves identifying moving objects in an agent’s environment. Detecting motion in the workspace is a crucial capability for autonomous agents, as dynamic objects pose a threat to the agent’s ability to safely achieve its goal. Agents typically employ exteroceptive sensors such as cameras and Light Detection and Ranging (LiDAR) to image their surroundings. MOS involves separating static and dynamic elements by categorizing the pixels in an image or the points in a LiDAR scan into static and dynamic classes.
The significant challenge in developing a solution to the MOS problem is to provide consistent performance across various environments, platform dynamics, and sensor characteristics. Learning-based frameworks are often employed to provide a solution to the MOS problem. While these approaches can yield impressive results, they often fail to generalize to a wider range of problems, see Schmid et al. (2023); Wu et al. (2024). For example, a method trained on a labelled dataset from a vehicle in an urban environment with a particular sensor may not perform adequately for a robot navigating an indoor space. Figure 1 illustrates the labelling of dynamic measurements in several environments using the algorithm proposed in this paper with the same set of algorithm configuration parameters: a shopping centre, a person jumping over a moving ball, a vehicle passing a pedestrian crossing the road, and several cars on a highway. Performance generalization is important as typical operating environments contain diverse dynamic elements such as pedestrians, children, animals, vehicles and cyclists. These vary extensively with pedestrians carrying objects, pushing a pram, or cyclists travelling in large groups. The proposed approach accurately detects moving objects in point cloud data using the same algorithm configuration in all scenarios, including a shopping centre (top left), a person jumping over a moving ball with a suitcase (top right), a pedestrian walking alongside a car (bottom left), and multiple cars on a highway (bottom right).
There is a need for a solution that offers accurate dynamic object detection for agents operating in diverse environments. To address this, we propose a novel MOS approach to accurately identify dynamic objects in point cloud data irrespective of the sensor characteristics, platform dynamics, and operating environments.
The contribution of this work is a low-configuration and learning-free approach to segmenting moving points from point cloud data. The foundation of the proposed approach lies in modelling each voxel using a hidden Markov model to exploit existing probabilistic frameworks for change-point detection tasks (James et al., 2024). For the application of labelling dynamic points, this amounts to identifying voxels that have changed occupancy. The change-point detection results are filtered using classical image processing techniques extended to point cloud data to reduce false positives and increase the performance recall by capturing the entire dynamic object. Integration of the ideas presented in this paper illustrates a simple MOS pipeline that (i) demonstrates strong generalized performance across platform dynamics (handheld, mobile robot, vehicle), sensor characteristics (Velodyne, Ouster, Livox, etc.), and sensing environments (indoor, outdoor, urban), while (ii) having a small and meaningful set of algorithm configuration parameters that remain unchanged for all experiments. In supporting the claims regarding the algorithm’s performance, we also highlight the loose definition of a moving object in the existing work and the variability in benchmarking MOS algorithms. The work is open-sourced at https://github.com/vb44/HMM-MOS to aid future development and provide reproducibility of all benchmarking results presented in this paper.
Challenges
Segmenting moving points in point cloud data is a challenging task. This Section discusses the uncertainty in the problem inputs, the challenge of providing generalized performance, meeting real-time performance requirements, and the diversity in the benchmark evaluations. Approaches to solving the MOS problem need to handle these challenges.
Handling uncertainty in the problem inputs
The MOS problem requires two inputs: a sequence of point cloud data, and the corresponding 6-DOF pose of the sensor.
Point cloud measurements are typically recorded using LiDAR sensors. LiDARs return a set of range measurements at specified heading and elevation angles at frequencies typically between 5 and 20 Hz. The sensors exhibit range measurement uncertainty that increases with distance. Additionally, the intrinsic parameters (beam heading, elevation angles) are only known to a level of uncertainty and require careful calibration to allow correct interpretation of the range measurement (Nouiraa et al., 2016).
Transforming the point cloud measurements into a frame relative to previous measurements (e.g. a map frame) requires accurate sensor pose estimation. The sensor’s pose is generally estimated by Global Navigation Satellite Systems (GNSS) or point cloud odometry, such as MOLA (Blanco-Claraco, 2024). These pose estimates inherently contain uncertainty, which, combined with the sensor’s measurement uncertainty, propagates in transforming the point cloud to the common reference frame. The effects are more pronounced at greater ranges, where pose errors result in substantial errors in the transformed measurements. Furthermore, if the platform’s pose solution and LiDAR are offset, as in the case of using GNSS for platform pose, accurate extrinsic calibration is required to locate the LiDAR relative to the navigation solution (D’Adamo et al., 2018).
LiDAR provides accurate range measurements at high frequencies but has known sensing limitations. Sensor measurements are sparse at long ranges, making it challenging to separate noisy detections from objects with only a few measurements. The behaviour of range returns from reflective surfaces is unpredictable and leads to incorrect beliefs about space occupancy, resulting in subsequent false detections. However, these surfaces are commonly encountered, and algorithms need to account for these sources of uncertainty. Sensor returns from vegetation and atmospheric obscurants such as dust also exhibit unpredictable behaviour (Phillips et al., 2017).
Providing real-time performance
Systems aim to provide detection results at rates commensurate with the cycle times of decision-making processes that consume the information. High-density scanners capture more information about the environment, but processing the increased measurements leads to greater computational demand. Modern LiDARs provide millions of measurements per second at high frequencies. Processing significant amounts of data in real-time applications requires hardware that is typically uncommon on mobile robots. Alternatively, the data volume can be reduced through pre-processing, but this generally introduces quantization and diminishes the level of detail in information about the scene.
Providing generalized performance
MOS has numerous applications ranging from robots interacting with humans (Falque et al., 2023) to vehicles navigating unstructured environments (Wojke and Häselich, 2012). An approach is desired that provides generalized performance across varying platform dynamics, sensor characteristics, and application environments. Learning-based approaches commonly fail to generalize performance between different sensors, platforms, and operational environments due to the large variation in the possible inputs. A common property of all sensors is the information provided about occupied and free space, and we use this to form confident beliefs about dynamic measurements.
Benchmarking metrics
Numerous labelled datasets are available for benchmarking the performance of MOS algorithms in comparison to existing methods. Each benchmark dataset includes a sequence of scans, in some cases the sensor’s estimated pose, and a set of labelled ground truth scans. A labelled ground truth scan provides a binary classification of static and dynamic points in the scan. These scans have either been annotated manually (Schmid et al., 2023), by a static map generation approach (Lim et al., 2023), a deep-learning network (Chen et al., 2022), or a combination of any. While numerous labelled datasets exist, the definition of a moving point varies significantly, leading to an inaccurate comparison between algorithms. This raises the question of what defines a moving object?
An object is moving if its pose is changing relative to a fixed reference frame, regardless of the object’s velocity and previous dynamic state. Given the k-th point cloud located in a fixed reference frame, for example, the map frame, sensor measurements corresponding to objects that are moving are classified as dynamic. The remaining measurements are static. Measurements corresponding to objects that (i) were moving and have stopped moving, (ii) move at a future instance (t = k + 1), or (iii) have the potential to move, are not dynamic objects given the earlier description.
This work focuses on detecting objects that are currently moving. We acknowledge the difficulty in generating ground-truth labels using experimental data, with labelling often capturing other instances.
Existing MOS solutions
Literature is rich with many learning-free and learning-based approaches for solving the MOS problem. Learning-free methods use traditional algorithmic approaches to identify dynamic points, compared to learning-based approaches that employ deep-learning networks to train models based on rules and verify performance on unseen datasets. The following discusses recent advancements in both categories. The reader is encouraged to view (Peng et al., 2024) for an in-depth review of dynamic object detection using point clouds.
Learning-free approaches
Learning-free approaches are generally categorized into methods identifying discrepancies between successive scans registered in a common frame and methods constructing a continuous representation of the environment updated sequentially with new observations. In common, these approaches query changes in free space to provide cues for detecting dynamic objects.
Scan-based
Scan-based methods compare observations to highlight discrepancies in the environment. Static points are likely to overlap when aligning successive point clouds, whereas dynamic points are likely to be misaligned in a common observed space. The discrepancies seed the detection of dynamic objects, with subsequent stages responsible for growing the region or rejecting them as noisy detections.
Underwood et al. (2013) detect changes between 3D scans by identifying discrepancies in the observed space, with points labelled dynamic if they are greater than a threshold distance from points in previously registered scans. Analogous to other methods, this relies on identifying the free space and finding instances that violate these constraints. Yoon et al. (2019) propose a multi-stage pipeline for complete object detection, consisting of a backward and forward free-space check between scans to identify dynamic points, a box filter to reject noisy estimates, and a final region growth algorithm to capture the entire dynamic object. Dynamic detection relies on selecting a suitable window size that allows sufficient displacement of the dynamic object – a characteristic that differs between object classes such as vehicles, cyclists, and pedestrians. Dewan et al. (2016) encounter similar problems, leading to suboptimal detection in multiclass scenarios. A simple approach examining changes in spatiotemporal normals to detect dynamic objects is presented by Falque et al. (2023), but only short-range detection results are provided in human-centric environments. M-detector by Wu et al. (2024) provide real-time detection of events from LiDAR point streams. The method is unique in its approach to the fast detection of diverse dynamic points using simple occlusion principles embedded in a three-module network consisting of event detection, clustering and region growth, and depth image construction and maintenance. Experimental results demonstrate agnosticity across operational environments. However, the algorithm is configured using 14 parameters dependent on the LiDAR’s characteristics.
Map-based
Map-based methods construct a representation of the environment and query changes in its state to identify dynamic objects. These approaches are commonly probabilistic and exploit the characteristics of a LiDAR’s beam to label space as free or occupied.
Modayil and Kuipers (2008) demonstrate this basic idea by constructing a confident static representation of the environment using a 2D LiDAR and believing that any changes in the environment must be due to dynamic objects. This belief keeps the detection object-agnostic, however, application to 3D point clouds in highly dynamic environments demonstrates below-par performance (Schmid et al., 2023). The Octomap probabilistic mapping framework by Hornung et al. (2013) uses maximum and minimum clamping on the occupancy and free probabilities to evolve beliefs in dynamic environments. These thresholds dictate the rate at which voxels change state and are not agnostic to objects with varying dynamics. Extensions to Octomap aim to improve its performance in dynamic environments, see Arora et al. (2021); Liu et al. (2023). Methods using similar techniques, such as clamping and forgetting policies described by Yguel et al. (2008), cannot adapt to different object classes to provide fast detection results without compromising the mapping quality and introducing significant false positive detections. Dynablox by Schmid et al. (2023) uses a Truncated Signed Distance Field (TSDF) map representation and integrates temporal properties to allow for motion detection and consequently construct a static map. The method builds a high-confidence spatiotemporal estimate of free space and identifies transitions between occupied and free space to seed dynamic objects. It demonstrates state-of-the-art performance in detecting dynamic objects in complex environments, as many learning-based approaches fail to generalize their detection capability to a broader class of dynamic objects. The algorithm is evaluated on various handheld human-centric datasets only.
Learning-based approaches
Most recent MOS approaches are learning-based. These methods use labelled data to train deep-learning networks that learn patterns to identify dynamic objects in point cloud data. The idea is to train these networks with sufficient high-quality labelled data to allow for accurate performance in unseen instances with variations in the input data quality, that is, sensor characteristics, sensor noise, and pose estimation uncertainty. The performance usually depends on the design of the network architecture and the quality of the labelled data used for training.
Convolutional Neural Networks (CNNs) frequently form the foundation of MOS deep-learning models. Chen et al. (2021) use sequential range images with a CNN to identify residuals in point clouds registered over a receding window to separate static and dynamic points. The algorithm performs accurately in scenarios similar to its training set but shows significantly reduced performance when evaluated with datasets collected with differing motion profiles and diverse dynamic objects. To improve the robustness of the network across applications, Mersch et al. (2022) employ spatiotemporal 4D convolutions combined with a binary Bayes filter for a recursive fusion of predictions over a receding horizon. This unique approach to training a CNN allows for significant improvements in the generalized performance across testing scenarios as the network trains to detect changes in a sequence of scans compared to appearance-based techniques. Mersch et al. (2023) extend this to include volumetric beliefs and increase dynamic detection while recursively updating a local static map of the environment. Wang et al. (2023) also uses 4D convolutions with instance detection and feature fusion to better identify static and dynamic objects in the scan.
Several other architecture designs also achieve accurate performance, including the use of dynamic graph CNNs (Wang and Solomon, 2021), leveraging semantic and motion labels in a range image-based CNN (Kim et al., 2022), and using a bird’s-eye view approach for motion detection (Zhou et al., 2023).
The critical hurdle involves generalizing performance across various operating environments and sensors with differing point cloud densities and scan patterns. The recently introduced HeLiMOS dataset by Lim et al. (2024) emphasizes the importance of generalization and provides labelled data from four different LiDARs along the same sequence. The performance of existing methods on the different LiDAR datasets without retraining highlights the poor generalized performance. Furthermore, the dependence on the training inputs and consequent variation in results reveals the gap for a robust approach to the MOS problem.
Identifying dynamic points using hidden Markov models
The MOS problem is defined as follows. Given, (1) a sequence of N point clouds in the sensor frame (2) the corresponding pose estimates of the sensor in a map frame
the aim is to separate each point cloud into static and dynamic points,
We treat the MOS task as a change-point detection problem, where the goal is to identify measurements in areas that have changed occupancy, that is, space transitioning from being free to occupied, and extend the dynamic detection to capture the entire object. James et al. (2024) presents an application-agnostic framework for modelling change-point detection tasks using hidden Markov models (HMMs). Hidden Markov models provide a strong probabilistic framework for handling uncertain observations and estimating a system’s true state. For the MOS task, this amounts to handling uncertain point cloud measurements and sensor pose estimates to infer the true occupancy of the voxel, and consequently, when it changes state. We adapt the framework presented by James et al. (2024) to model each voxel and update its occupancy based on uncertain observations. Meyer-Delius et al. (2012) and Wang et al. (2014) have previously used HMMs to model space occupancy for mapping tasks due to their fast adaptability to changes in the environment.
This section details the design of the proposed algorithm. Figure 2 illustrates the simple three-stage process for labelling dynamic measurements. The proposed approach uses a simple three-stage process to label dynamic measurements. The point cloud is first voxelized at a resolution of Δ, followed by a raycasting operation to determine all the observed voxels. Information about free and occupied space is described using a Gaussian distance field to generate the likelihood of each voxel being occupied or free. This information is used by the HMM filter to probabilistically update the occupancy of each voxel. The local map is queried to detect voxels that have transitioned occupancy. These changes are filtered using a spatiotemporal convolution to decrease incorrect detections and capture the entire object. The methodology details each submodule.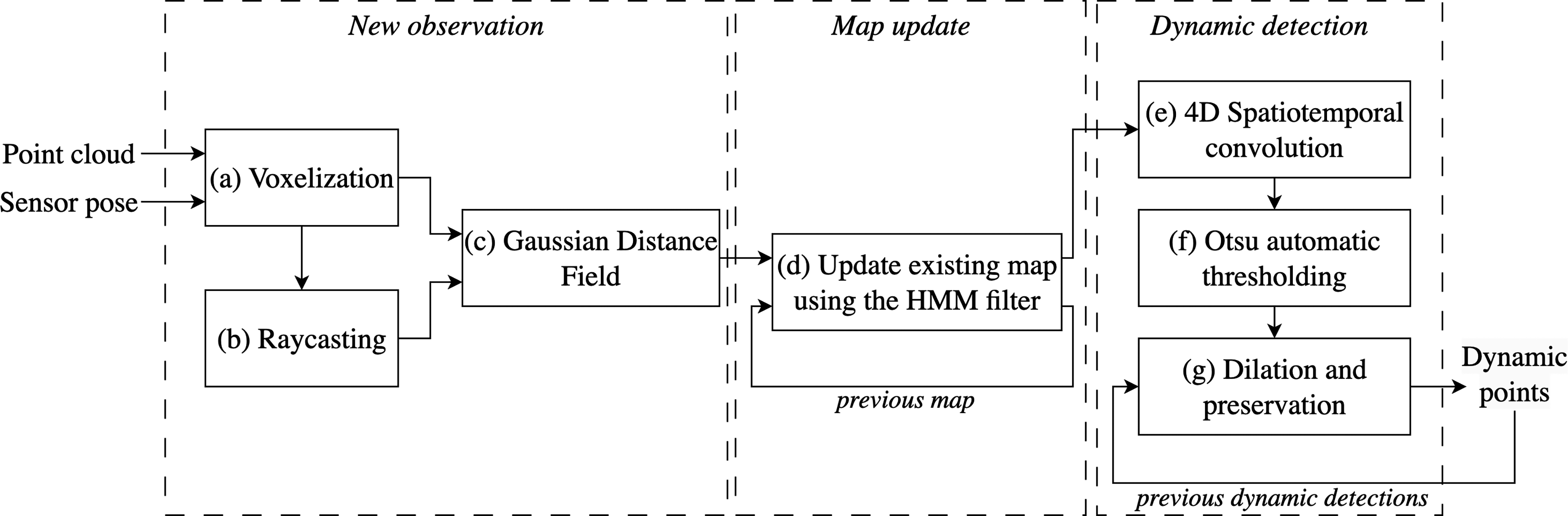
Map representation and update
A global map frame, Each voxel, v
i
, has several properties augmented with its discretized position (x
i
, y
i
, z
i
) to provide temporal information for detecting state changes.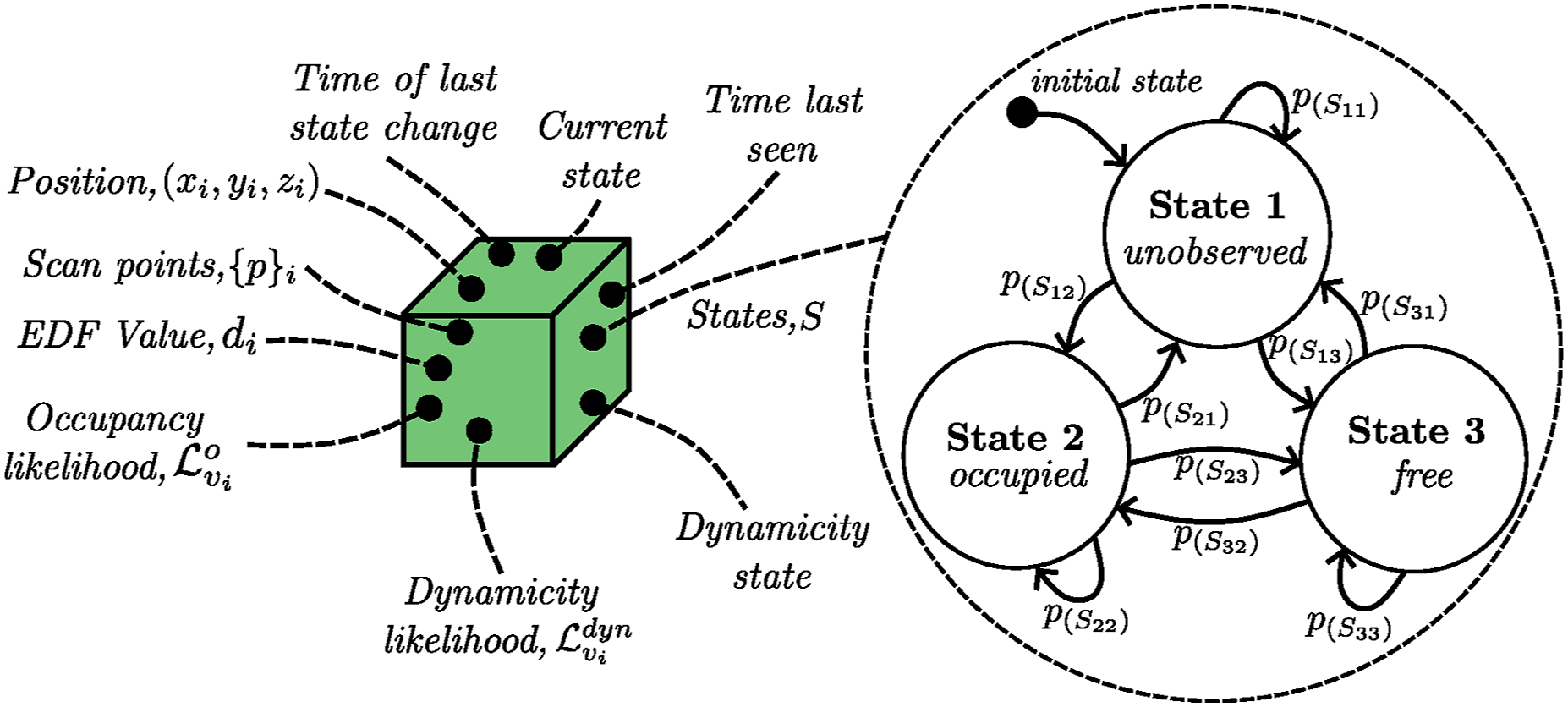
Without uncertainty, detecting dynamic objects is as simple as updating voxel occupancy with new observations. If a voxel’s state changes from free to occupied, it suggests a dynamic measurement. However, uncertainties in point cloud measurements, sensor pose, or poor sensing conditions lead to incorrect or missed detections. Existing beliefs should be fused probabilistically to handle the various sources of uncertainty. As the state of each voxel is not directly interpretable due to the associated uncertainty, an HMM is used to represent the state of each voxel in the map,
Representing each voxel using an HMM (Rabiner, 1989) requires defining: the n states of the voxel, S = {S1, …, S
n
}, the transition probabilities between the states captured in the state transition matrix
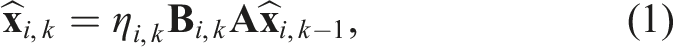
Each voxel, v, is represented using three states (n = 3), S = {unobserved, occupied, free}, with each voxel initialized in the unobserved state,
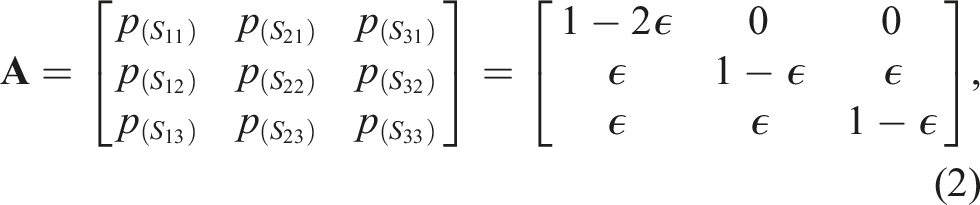
Interpretation of a new observation
The new point cloud at time k in the sensor frame,
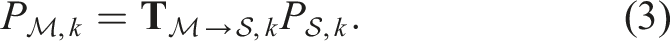
The interpretation of the current scan provides information about occupied and free voxels. However, believing the information and overwriting previous beliefs directly generates suboptimal results, as uncertainty leads to a rapid transition of voxels between occupied and free states. This is problematic as the main cue used for dynamic detection is the transition of previously free voxels turning occupied. Instead, the likelihood of each observed voxel being free and occupied is used to construct a belief of the current state of the voxel. The measurement conditional densities of the i-th voxel being in a particular state given an observation are
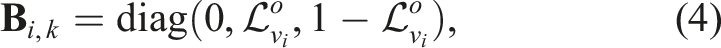
An observed voxel is likely to be occupied if it is close to a voxel in the voxelized scan, A voxelized scan is shown on the left, captured by the LiDAR at the origin. The computed Euclidean Distance Field (EDF) of the point cloud is shown on the right. The EDF values are transformed by a Gaussian function to compute an occupancy likelihood. Voxels close to occupied measurements are likely to be occupied, and voxels located away are more likely to be free.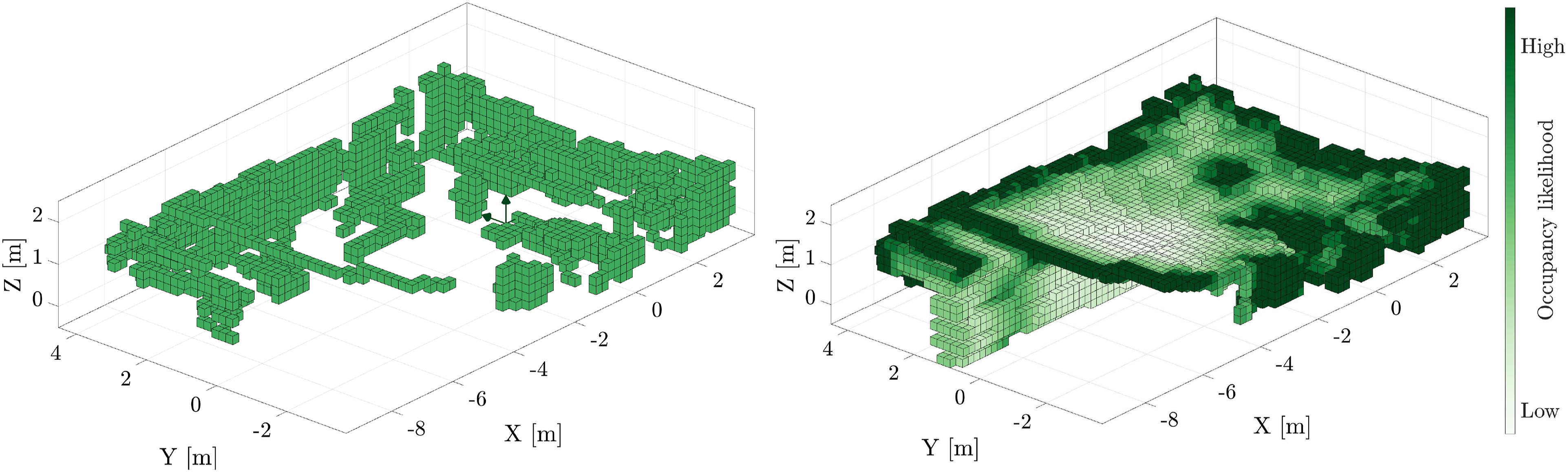
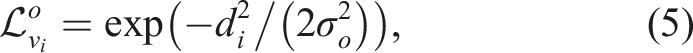
A voxel’s current state, Si,k, is updated when the probability of being in a particular state,
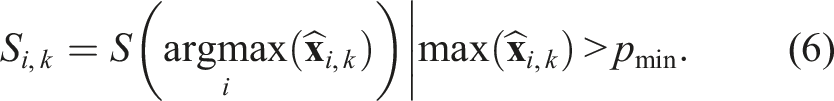
Dynamic point identification
This process allows for an efficient probabilistic update of each voxel’s state in the global map. A voxel’s transition between free and occupied space is used to seed the detection of dynamic objects. The HMM per voxel allows for an accumulation of confidence before transitioning state. Figure 5 illustrates the process of estimating dynamic voxels with the following detailing each step. A 4D convolution is performed to capture spatial and temporal changes. The figure illustrates an example of performing a spatial convolution on a voxelized point cloud after detecting changes in the voxel’s state. Voxels that have changed state are shown in dark green. An example kernel (red), K3, is convolved with the point cloud to identify missed detections and suppress noisy estimates. The convolution is temporally extended across a local window of w
l
to calculate the likelihood of each voxel being dynamic, 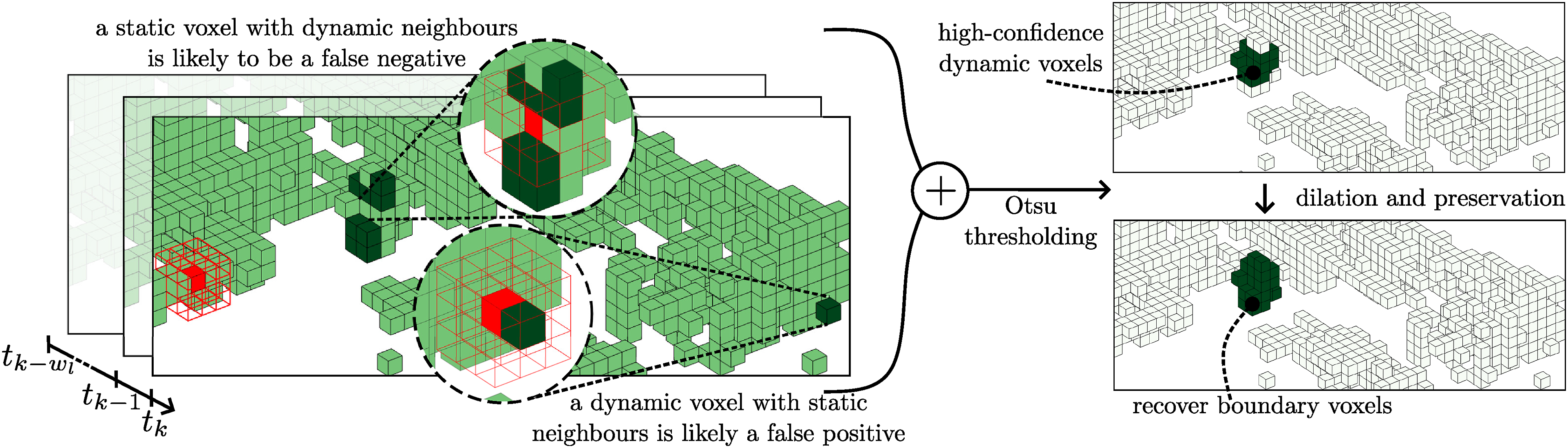
Detecting changes in voxel states
The first step is to identify voxels from the current voxelized scan,
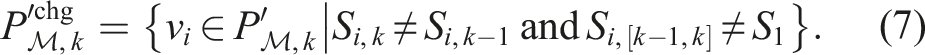
Capturing neighbourhood behaviour using a spatiotemporal (4D) convolution
The change detection allows for likely dynamic voxels to be identified. However, each voxel is modelled independently, and changes in the voxel’s neighbourhood are not examined. Dynamic objects are likely to occupy space composed of several voxels, given a sufficiently small discretization resolution. Two heuristics can be stated without assuming the object’s shape or dynamics to keep the algorithm application agnostic; (i) a static voxel with many dynamic neighbours is likely a missed detection (false negative), and (ii) a dynamic voxel with many static neighbours is likely a false detection (false positive). A spatial (3D) convolution is performed to identify missed detections to reduce the false negatives and suppress noisy detections to decrease false positives.
While both heuristics significantly improve the results, they do introduce unwanted effects. As a consequence of heuristic (i), detections at sparse, and often long ranges, are missed as they exhibit similar behaviour to noisy measurements. Heuristic (ii) captures parts of static objects when a dynamic object moves close to static parts of the environment. This depends on the voxel size, as it is common for a voxel to capture both static and dynamic parts of the environment (e.g. feet and wheels contacting the ground). The benefits of performing the convolution significantly outweigh the unwanted side effects.
For each occupied voxel,
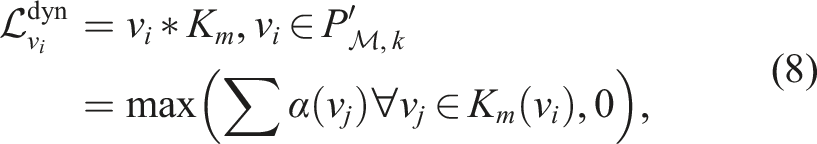
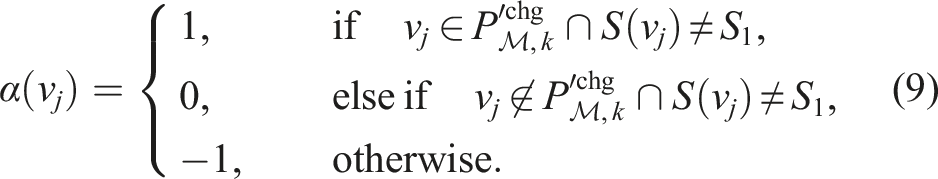
The condition, S(v j ) ≠ S1, is added to avoid including detections that are close to the boundary between unobserved (S1) and observed (S2, S3) space, as voxelization is known to be inaccurate at this boundary. A dynamic detection close to this boundary is penalized as in the third constraint of equation (8) to allow for the detection of high-confidence dynamic voxels only. Voxels missed due to this constraint are recovered in the final step of the pipeline. The likelihood of being dynamic increases with the number of voxels in the convolution kernel, K m , that have changed state. A post-processing local neighbourhood median filter is also applied to smooth the likelihood values.
The spatial 3D convolution (equation (8)) is extended over a receding local window of size w
l
, to compute a spatiotemporal 4D convolution,
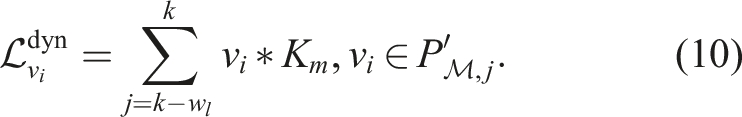
Automatic thresholding the 4D convolution
The spatiotemporal convolution assigns a high likelihood for dynamic voxels and a low likelihood for static voxels. The likelihood of a voxel being dynamic depends on many factors: the voxel size, Δ; the size of the convolution kernel, K
m
; the sparsity of the original point cloud,
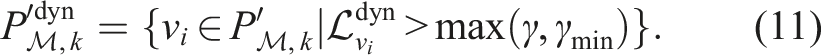
Preserving high-confidence dynamic voxels and extending to low-confidence areas
High-confidence dynamic voxels from the previous scan are preserved in the current scan (Figure 2(g)). The recursive preservation is independent of the receding window, w
l
, used in previous operations. This aims to help capture the complete object. All dynamic predictions from the previous scan are not preserved, as these may contain false positive detections. Instead, only voxels with a likelihood of being dynamic,
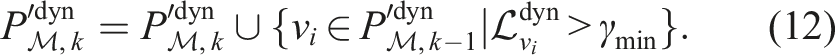
A nearest-neighbour dilation is applied to the high-confidence voxels to grow the dynamic detection results into neighbouring regions (Figure 2(g)), which were previously disregarded due to strict constraints to avoid identifying false positives,
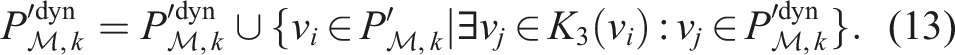
The final step involves extracting the original point cloud measurements from
Summary
Summary of all algorithm configuration parameters and purpose.

Results
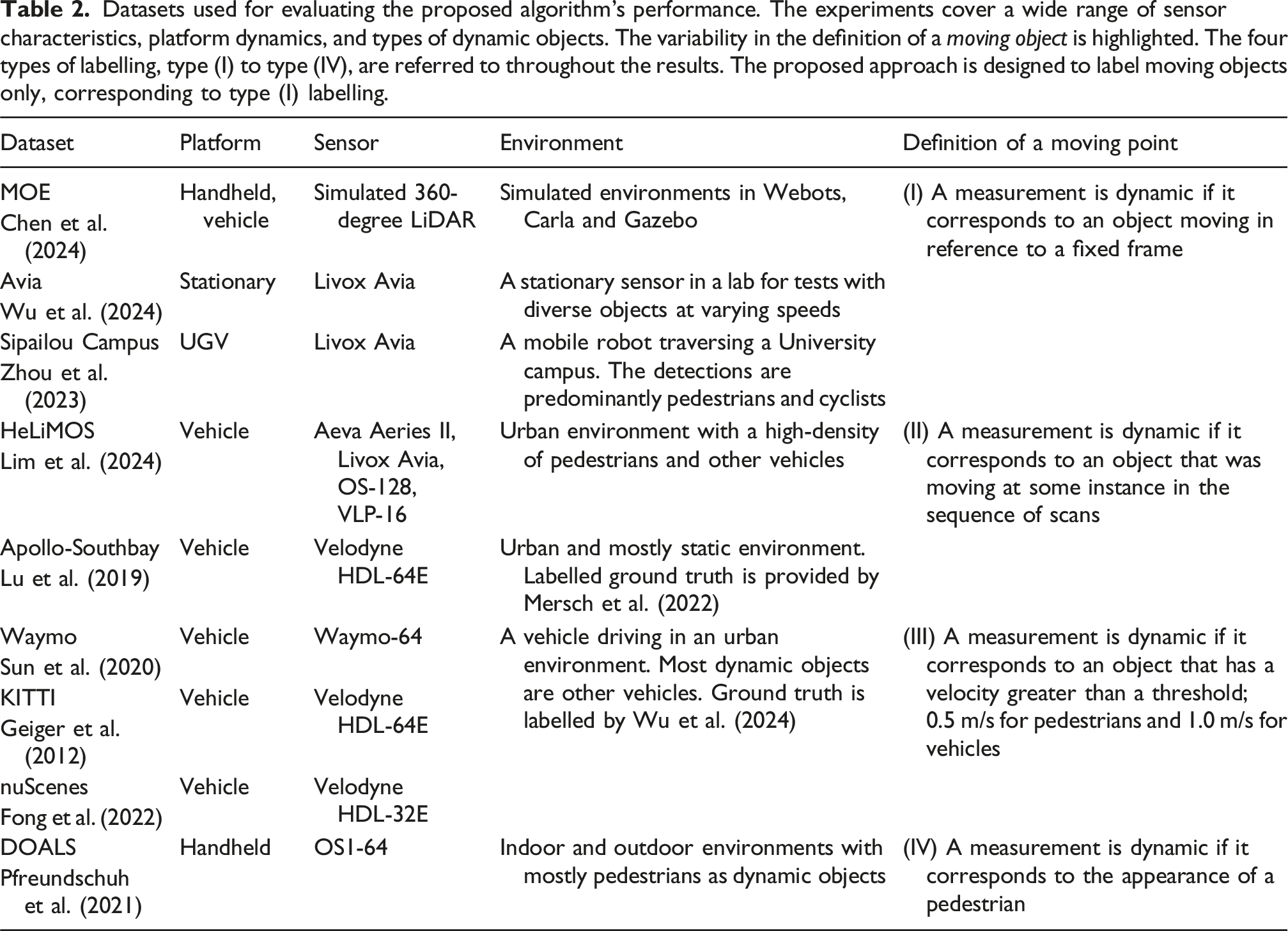
Datasets used for evaluating the proposed algorithm’s performance. The experiments cover a wide range of sensor characteristics, platform dynamics, and types of dynamic objects. The variability in the definition of a moving object is highlighted. The four types of labelling, type (I) to type (IV), are referred to throughout the results. The proposed approach is designed to label moving objects only, corresponding to type (I) labelling.
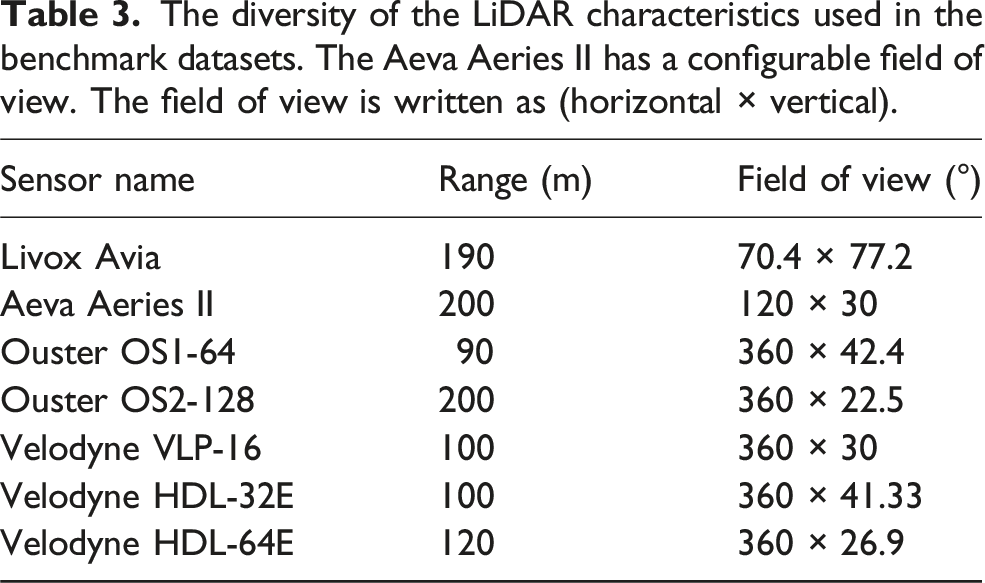
The diversity of the LiDAR characteristics used in the benchmark datasets. The Aeva Aeries II has a configurable field of view. The field of view is written as (horizontal × vertical).
We excluded the widely used Semantic KITTI dataset by Behley et al. (2019) from our analysis due to inaccuracies in its point cloud data collection and deskewing processes. These errors significantly misrepresent the performance of approaches that depend on accurate occupancy and free space information from the point cloud. This exclusion highlights a critical issue: datasets with acquisition flaws can lead to misleading algorithm evaluations and potentially skew research directions. Learning-free methods seem particularly vulnerable to such data inconsistencies, as they cannot compensate through ‘training’ for errors in spatial representation.
The proposed algorithm uses the default configuration listed in Table 1 for all tests. The testing is performed on an Intel i5 CPU with 14.9 GiB of memory running Ubuntu 20.04.6 LTS. Real-time processing relies on CPU threading only, implemented using Intel’s open-source Thread Building Blocks API (Intel, 2025). All results are reproducible using the instructions on the open-source page.
The algorithm’s performance is benchmarked using the Intersection over Union (IoU %) metric (Everingham et al., 2010),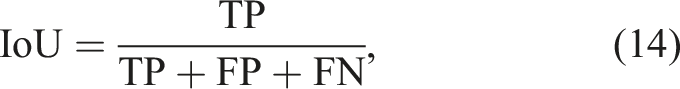
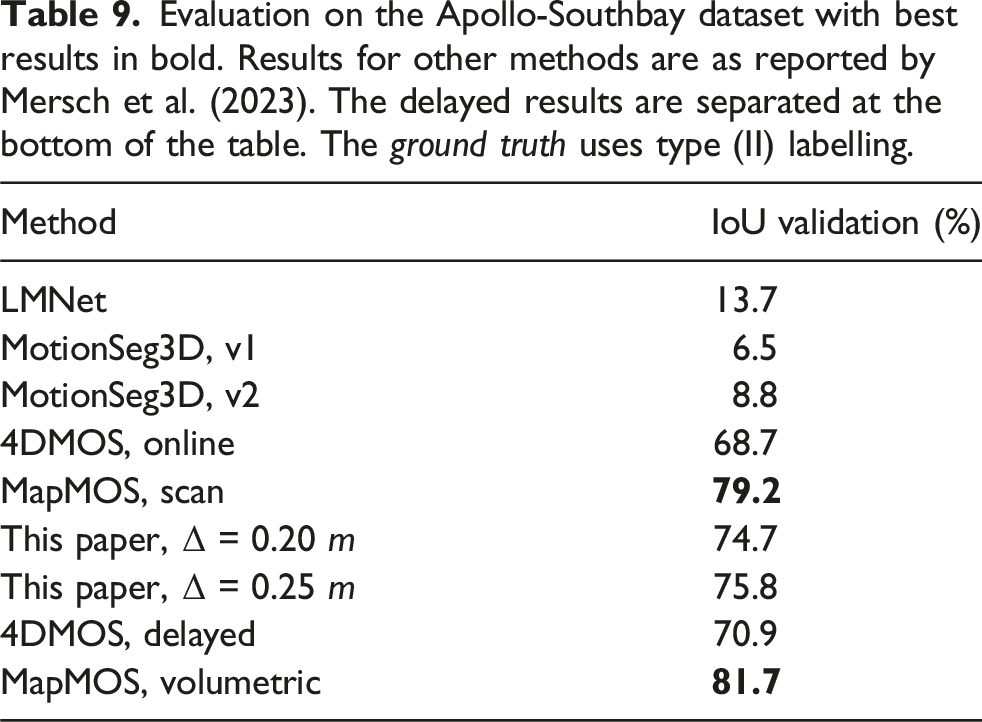
The proposed approach is compared to several existing approaches. 4DMOS by Mersch et al. (2022) is a state-of-the-art MOS approach that only uses a limited history of past scans to detect moving objects. Online and delayed results are provided. The delayed results fuse scans within a delayed window to estimate dynamic points. The published MapMOS (Mersch et al., 2023) results provide two variants as well: (i) dynamic object predictions using the current scan and (ii) dynamic object predictions using a volumetric belief that includes a delay of 10 scans. MapMOS retains a history of objects that transition from being dynamic to static, and hence demonstrates strong performance in datasets that label the ground truth accordingly. M-detector by Wu et al. (2024) do not benchmark using any of the existing baselines and alternatively releases ground-truth labels for datasets to only capture objects that are moving as per their definition. Dynablox by Schmid et al. (2023) only provide quantitative results for the DOALS dataset.
All methods use point cloud data provided in the sensor’s frame. 4DMOS and MapMOS use KISS-ICP (Vizzo et al., 2023) internally to estimate the sensor’s pose. M-detector uses FAST-LIO (Xu and Zhang, 2021) to estimate the sensor’s pose and does not publish the relevant poses with its labelled datasets. Deskewed scans (similar to KITTI) are used where possible, such as the HeLiMOS dataset.
Performance benchmarking
The following evaluates the algorithm’s performance on nine datasets to support the claims of providing generalized performance across platform dynamics, sensor characteristics, and operating environments while using the same algorithm configuration. Results for two different voxel sizes are included, Δ = 0.2 m and Δ = 0.25 m, with corresponding lumped uncertainties of σ o = 0.2 m and σ o = 0.25 m. While the accuracy results are similar, a significant computational benefit is achieved using the slightly larger voxel size. A trend is observed in some results where the larger voxel size returns a better result as it captures the complete object, however, this is usually at the expense of increasing false positives. This is a consequence of the quantization. The average runtime of each dataset is detailed in the corresponding section. A comparison with existing methods is provided when runtime results are published by the corresponding method or the open-source package results are reproducible. The reader’s attention is drawn to the variability in the ground truth of the benchmark datasets.
Moving event dataset (MOE)
Evaluation on the MOE dataset with best results in bold. 4DMOS and MapMOS were evaluated using their open-source packages, with the delayed results separated at the bottom of the table. Results for all other methods are as documented by Chen et al. (2024). The ground truth uses type (I) labelling.
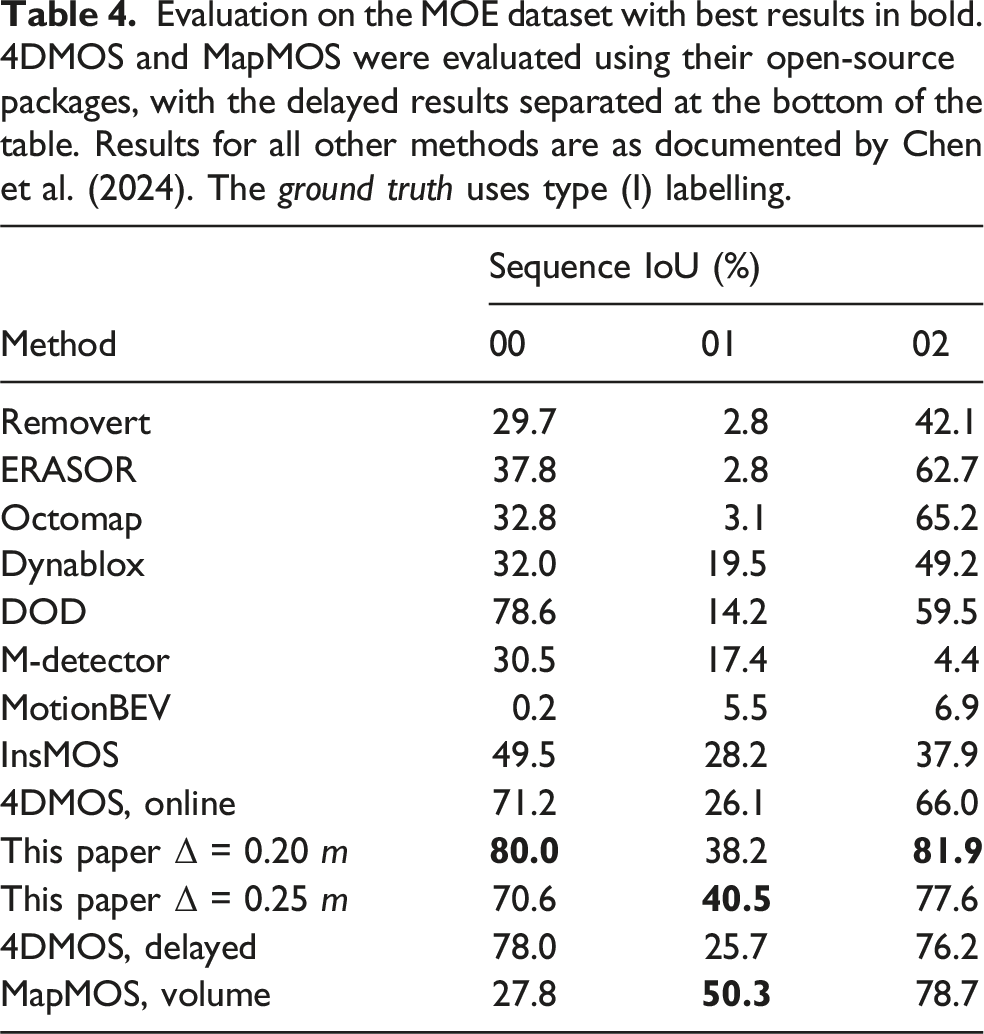
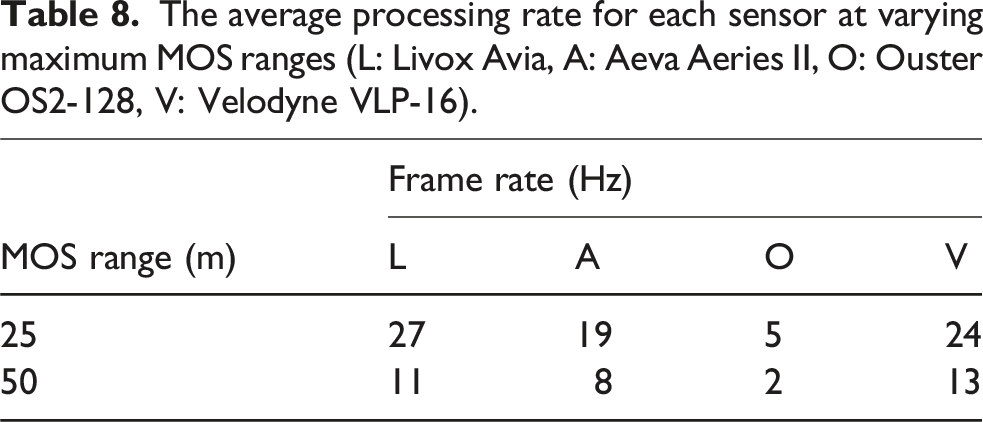
Sequences 00 and 02 are processed at 40 Hz for a maximum 50 m MOS range, whereas sequence 01 processes at 10 Hz for a maximum 20 m range and 3 Hz for a 50 m range. Sequences 00 and 02 are indoor environments, providing dense scans with a low maximum range, whereas sequence 01 is recorded in an outdoor environment with dense long ranges. The per-frame computation is proportional to the number of measurements (scanning density) and the scanning range. This relationship is observed for all datasets. The algorithm does not discard measurements that are greater than the configured maximum range. Instead, the ray is truncated at the maximum range to accurately model free space.
HeLiMOS
The HeLiMOS dataset provides the ground-truth labels for a single sequence from the HeLiPR dataset (Jung et al., 2024) captured simultaneously by four LiDARs: a Livox Avia, an Aeva Aeries II, a Velodyne VLP-16, and an Ouster OS2-128. The dataset is unique in highlighting the importance of sensor-agnostic MOS, with the purpose of providing consistent performance independent of the sensor used to generate the point cloud data. We achieve consistent performance across all sensors as demonstrated in Figure 6 and Table 5. The sensor pose is estimated using SiMpLE (Bhandari et al., 2024). 4DMOS and the proposed approach provide instantaneous detection of dynamic objects and use a small temporal history only, whereas MapMOS predicts all moving objects, even when they transition to being static. We outperform 4DMOS in all scenarios, except for the Aeva dataset with the delayed variant of 4DMOS. We achieve consistent performance in the HeLiMOS (Lim et al., 2024) irrespective of the sensor used to record point cloud data. The figure shows the same instance captured by four different LiDARs. The proposed algorithm correctly labels dynamic objects (green), with minimal missed detections (orange), and false positives (red). The figure is best viewed in colour. Evaluation on the HeLiMOS dataset with best results in bold (L: Livox Avia, A: Aeva Aeries II, O: Ouster OS2-128, V: Velodyne VLP-16). Results for other methods are as documented by Lim et al. (2024). The delayed results are separated at the bottom of the table. The ground truth uses type (II) labelling.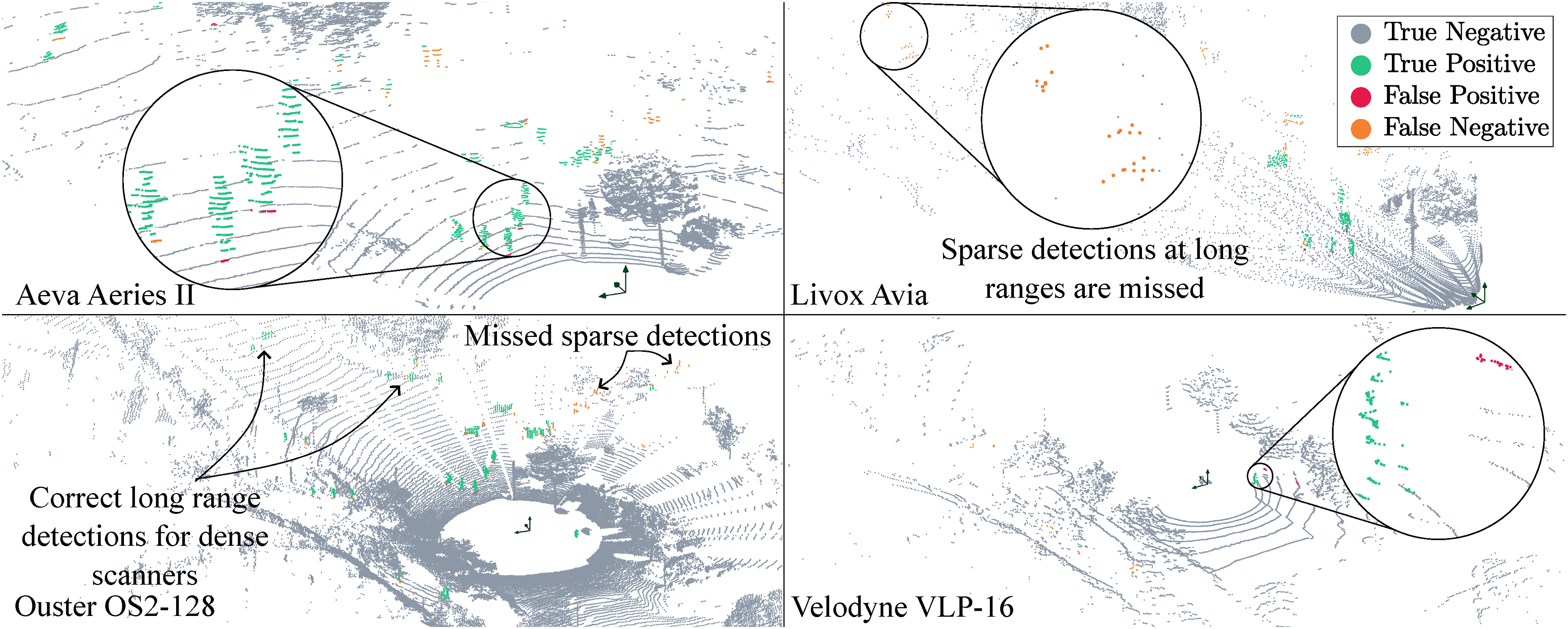

We present only the generalized performance of alternative approaches without retraining them on the new dataset, as retraining would undermine our goal of evaluating algorithm robustness in unseen environments and new applications. An interesting study was conducted by the authors of the dataset, who trained 4DMOS and MapMOS with various combinations of the sensor data to examine the impact on performance. They acknowledge the significant improvements required for existing MOS methods to operate in a sensor-agnostic approach, providing further motivation for this work. Dynablox constructs a global TSDF map using the point cloud data and hence requires significant computational memory to be evaluated on the HeLiMOS dataset. We evaluate a fraction of the dataset and qualitatively analyze its performance compared to the proposed approach in Figure 7. Dynablox performs well with dense point cloud data in the Ouster sequence, but has missed and incomplete detections for the other sensors, which record lower-density point clouds. The sensor-specific configuration parameters were updated where appropriate, or else configured to provide the best result possible. The proposed approach provides better detection for all sensors. A comparison between the performance of Dynablox and the proposed approach for all sequences using their default configurations. Dynablox performs well with high-density point clouds in the Ouster sequence. However, low-density scan patterns in the other sequences result in incomplete detections. The figure is best viewed in colour.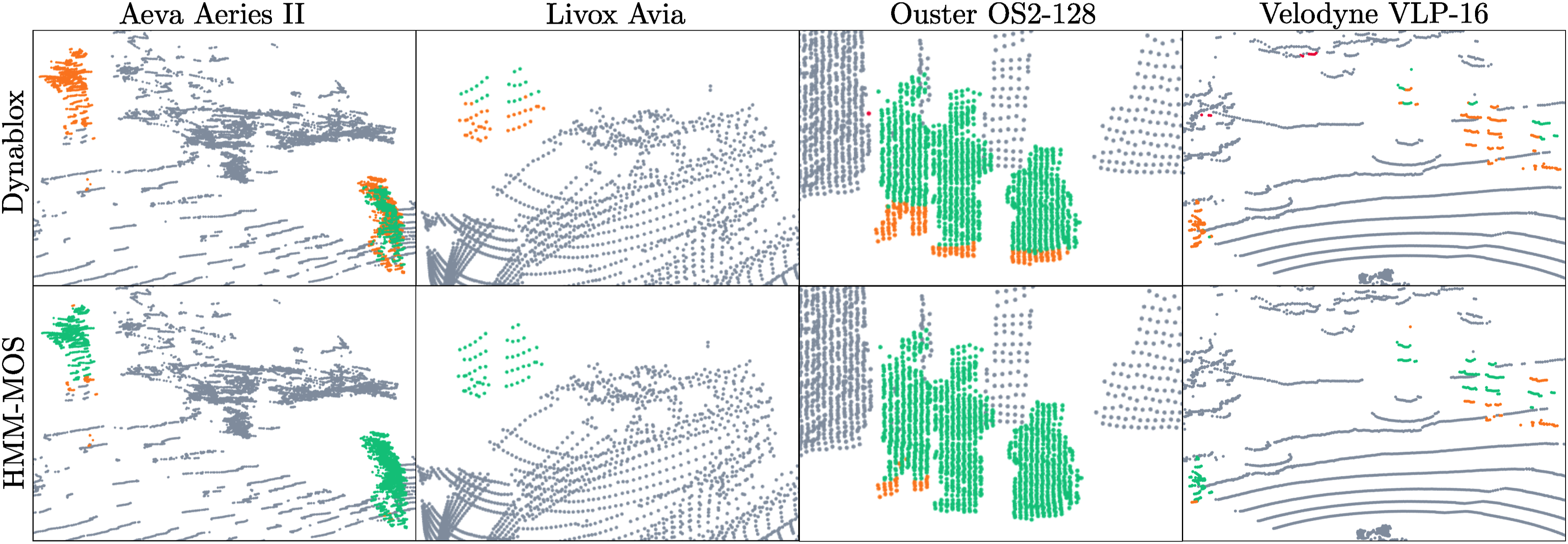
Precision and recall results of the proposed approach on the HeLiMOS dataset (L: Livox Avia, A: Aeva Aeries II, O: Ouster OS2-128, V: Velodyne VLP-16).
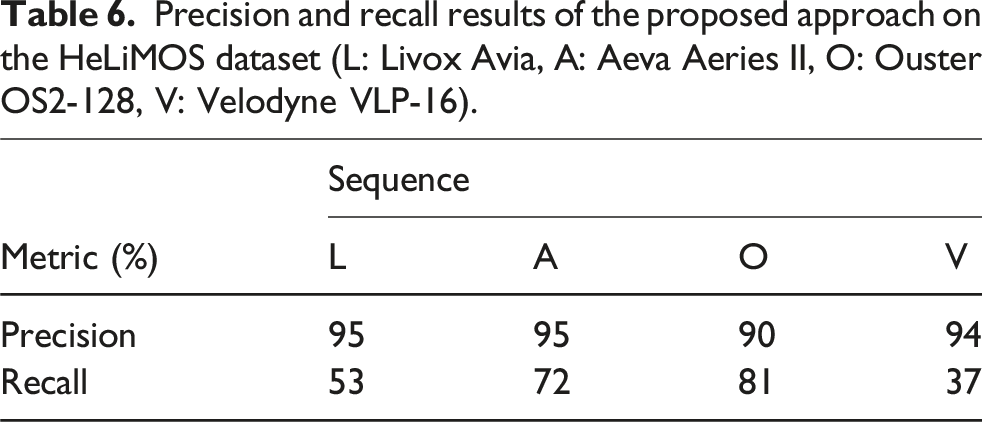
It is important to mention that the ground-truth labels any dynamic objects that have moved throughout the sequence. This includes objects that transition from being dynamic to static and objects that transition from being static to dynamic. These situations occur in several scenes, drastically reducing the recall. The effect is detrimental to the Livox (L) results for all methods. The ground-truth labels are useful for map cleaning approaches (e.g. Removert, ERASOR), but they hinder the performance of all MOS approaches as the vehicles transition from stationary to moving. The proposed approach cannot predict if an object will move and capture these instances. Results on all LiDARs confidently detect moving objects only. Figure 8 depicts this scenario, and Table 7 quantifies the significant increase in the re-evaluated performance when scans 570–881 are correctly labelled. The Livox (L) and Aeva (A) sequences are significantly affected by the incorrectly labelled static vehicles due to their mounting locations and field of view. The Velodyne (V) sensor’s field of view is blocked at its mounting location, resulting in a minor performance change. While the Ouster (O) sequence is affected, the relative number of false positives in this sequence is outweighed by the true positive detections captured by its 360-degree FOV. For comparison, the Ouster sequence is labelled with approximately 8.4e6 dynamic measurements, whereas the Livox sequence has 1.8e6 dynamic measurements only. A snapshot of the environment in scans 570-881 from the HeLiMOS dataset. Vehicles are labelled as dynamic but move in a future instance. This scenario incorrectly depicts the recall metrics of the Aeva, Livox, and Ouster sequences for all MOS methods. The Velodyne has a limited view of these vehicles due to its mounting position. The figure is best viewed in colour. The re-evaluated performance by removing an instance of the incorrectly labelled dynamic detections between scans 570 to 881 for the HeLiMOS dataset (L: Livox Avia, A: Aeva Aeries II, O: Ouster OS2-128, V: Velodyne VLP-16).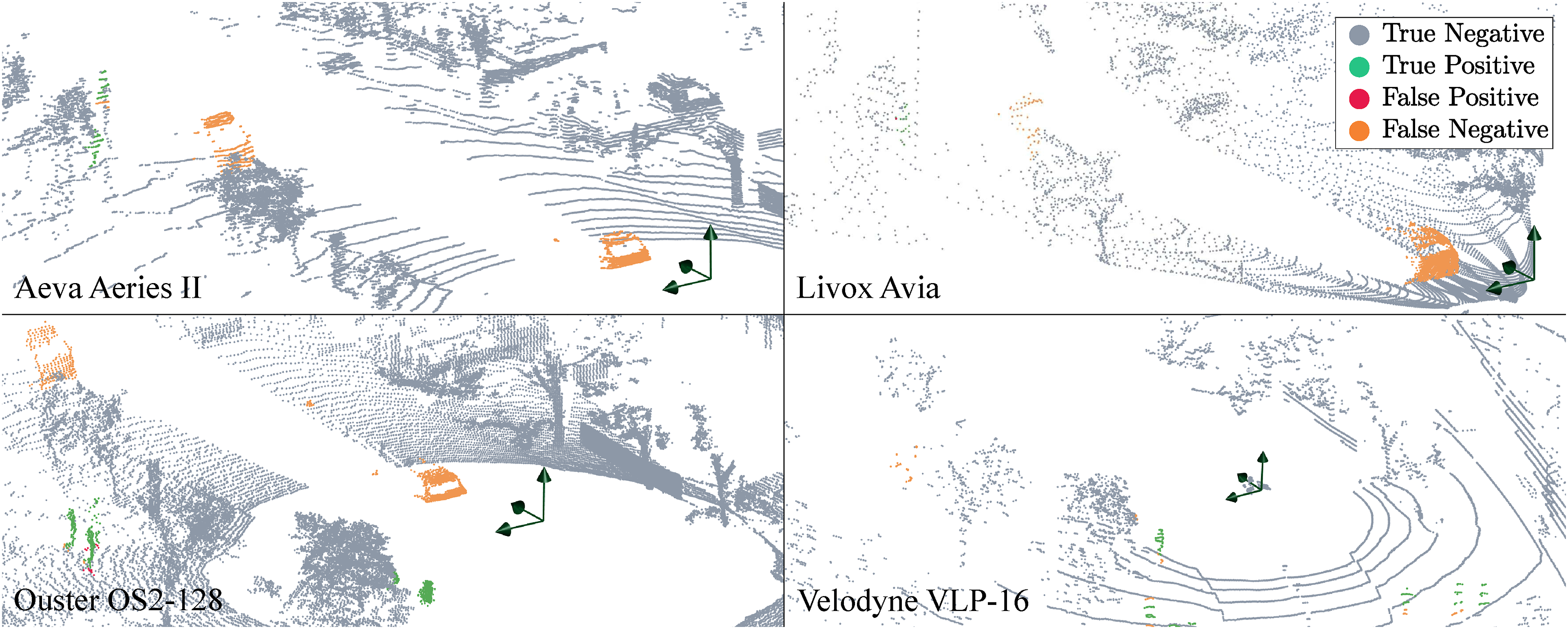
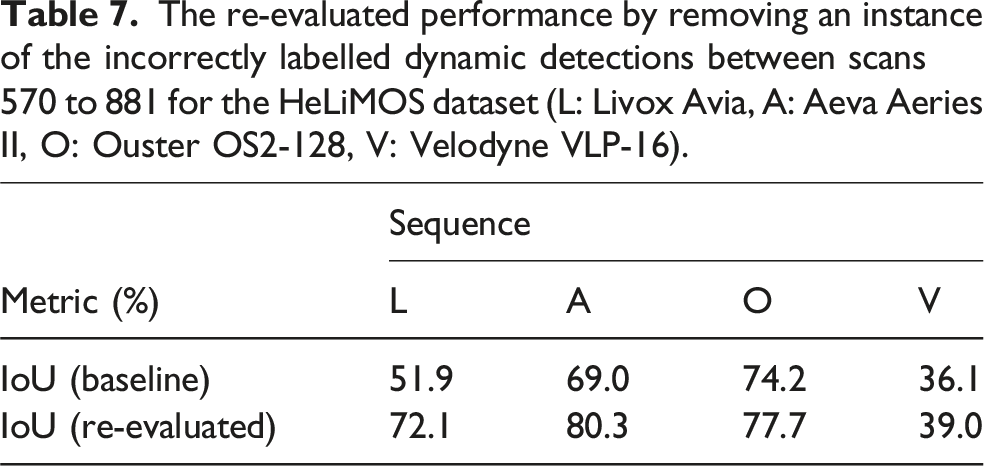
The results for the Velodyne sensor (V) show the most significant performance discrepancy in comparison to the other LiDARs for all methods. The 16-beam scans provide challenging input, as it is difficult to discriminate between noisy detections and sparse measurements at long ranges. Figure 6 illustrates the drastic difference in scan density for all LiDARs. The proposed approach demonstrates consistent performance across all scenarios, independent of the sensor characteristics, as it uses information about free and occupied space from the point cloud data only. This is seen as an advantage of our proposed approach.
The average processing rate for each sensor at varying maximum MOS ranges (L: Livox Avia, A: Aeva Aeries II, O: Ouster OS2-128, V: Velodyne VLP-16).
Apollo-Southbay
Evaluation on the Apollo-Southbay dataset with best results in bold. Results for other methods are as reported by Mersch et al. (2023). The delayed results are separated at the bottom of the table. The ground truth uses type (II) labelling.
The proposed approach accurately identifies moving vehicles, cyclists, and pedestrians without any parameter tuning and identifies minimal false positives as displayed in Figure 9 (left). Like the HeLiMOS dataset, AutoMOS’s ground-truth labels (Chen et al., 2022) classify objects as dynamic if they moved at any point during the sequence. This classification approach significantly alters recall scores when vehicles stop moving. The proposed approach accurately identifies objects of various sizes travelling at different speeds indicated by the green measurements. False positives shown in red arise at the boundary of the static and dynamic points, such as where the wheels touch the ground. The scan on the right shows a vehicle labelled as dynamic by the ground truth that transitioned from being dynamic to static. These instances incorrectly portray algorithm performance. The figure is best viewed in colour.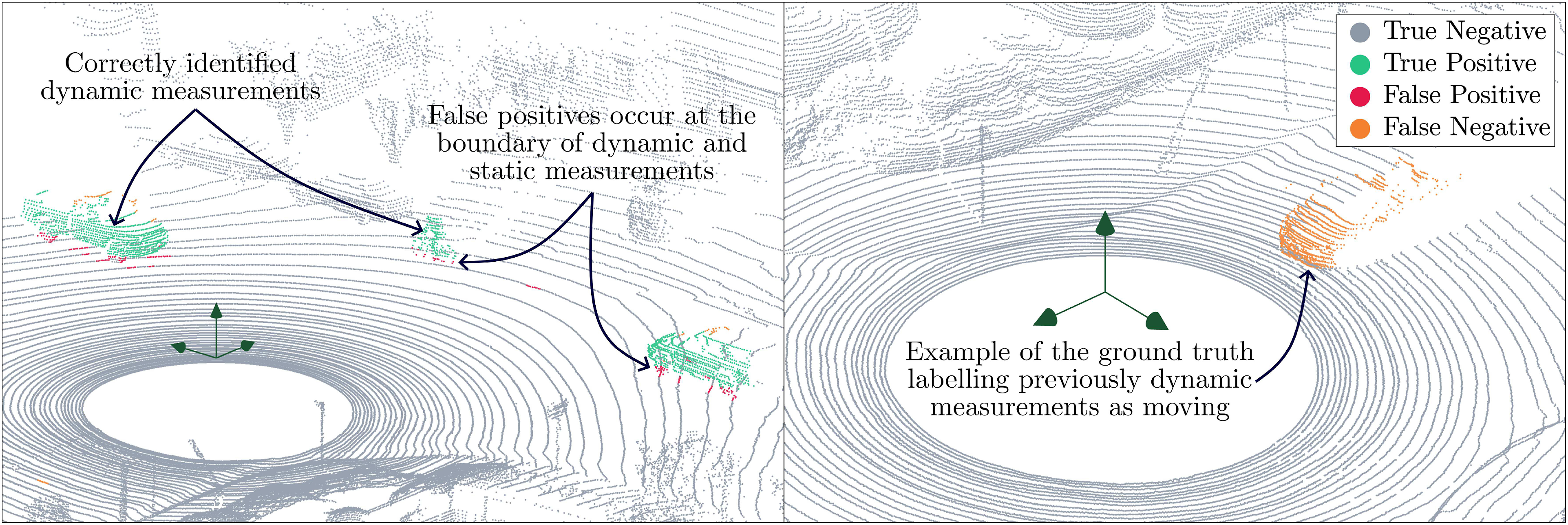
There is a sequence of 150 scans in Apollo sequence 00 where a vehicle transitions from being dynamic to static behind the instrumented vehicle. The ground truth continues to label these as measurements corresponding to a dynamic object. Figure 9 (right) shows an example of this situation. Correcting the ground truth by ignoring these measurements results in a 17% increase in recall. Furthermore, removing all such instances between scans 180–530 results in a 26% increase in recall. This represents a significant discrepancy when benchmarking results are compared to other methods that continue to label these measurements as dynamic.
We firmly maintain that a moving object should be defined as one that is actively in motion during the current scan, not one that moved previously or might move later. Our approach adheres to this definition by correctly identifying temporarily stationary vehicles as static, while the ground truth continues to label them as dynamic based on their movement history.
The algorithm processes the Velodyne HDL-64 scans at 10 Hz for a 25 m MOS range, and at 5.5 Hz for a 50 m range.
Waymo, KITTI, nuScenes, Avia
M-detector by Wu et al. (2024) benchmarks performance on three open datasets; KITTI (Geiger et al., 2012), Waymo (Sun et al., 2020), and nuScenes (Fong et al., 2022). Wu et al. (2024) provide the ground truth pointwise labels for these datasets. The KITTI dataset is labelled using the bounding boxes provided in the object-tracking sequences. The velocity of the bounding boxes is estimated using consecutive frames, with all measurements in bounding boxes having a velocity greater than a threshold, labelled as dynamic, 0.5 m/s for pedestrians and 1.0 m/s for vehicles. The authors of this paper label any dynamic detections as moving. In comparison to the other experiments in this paper, this introduces a different evaluation metric. A similar approach is used for the Waymo and nuScenes datasets. The method proposed in our work captures any moving objects, irrespective of their speed. This introduces an inaccuracy when benchmarking results. It must be noted that the KITTI ground-truth labels only capture moving objects within a 120-degree field of view due to the limited object-tracking bounding boxes. Any motion behind the sensor or on the sides is not captured. Wu et al. (2024) additionally record and label a unique indoor dataset capturing small flying objects with a Livox Avia. This dataset challenges learning-based approaches as the scan pattern, object shape, and dynamics are very different from the training data.
Figure 10 illustrates sample detections from the various datasets. The proposed approach successfully captures dynamic objects in all tests. The nuScenes dataset captures a large number of points on the vehicle itself. The sequence of Avia scans shows a small, fast-moving object correctly captured by the proposed algorithm. The example for the Waymo dataset illustrates an instance of the minimum velocity threshold, labelling the vehicle as slowing down as a static object ( Example results on the datasets benchmarked by M-detector. The Waymo dataset uses a 64-beam custom LiDAR. The proposed approach correctly identifies moving objects. False positives occur (i) at the boundary of static and dynamic points, and (ii) due to the minimum velocity threshold on the dynamic objects. The nuScenes dataset uses a 32-beam LiDAR. A large density of points is captured on the vehicle itself, biasing the results. The Avia dataset tests the capability to capture small and fast-moving objects, providing a unique experimental study. The figure is best viewed in colour.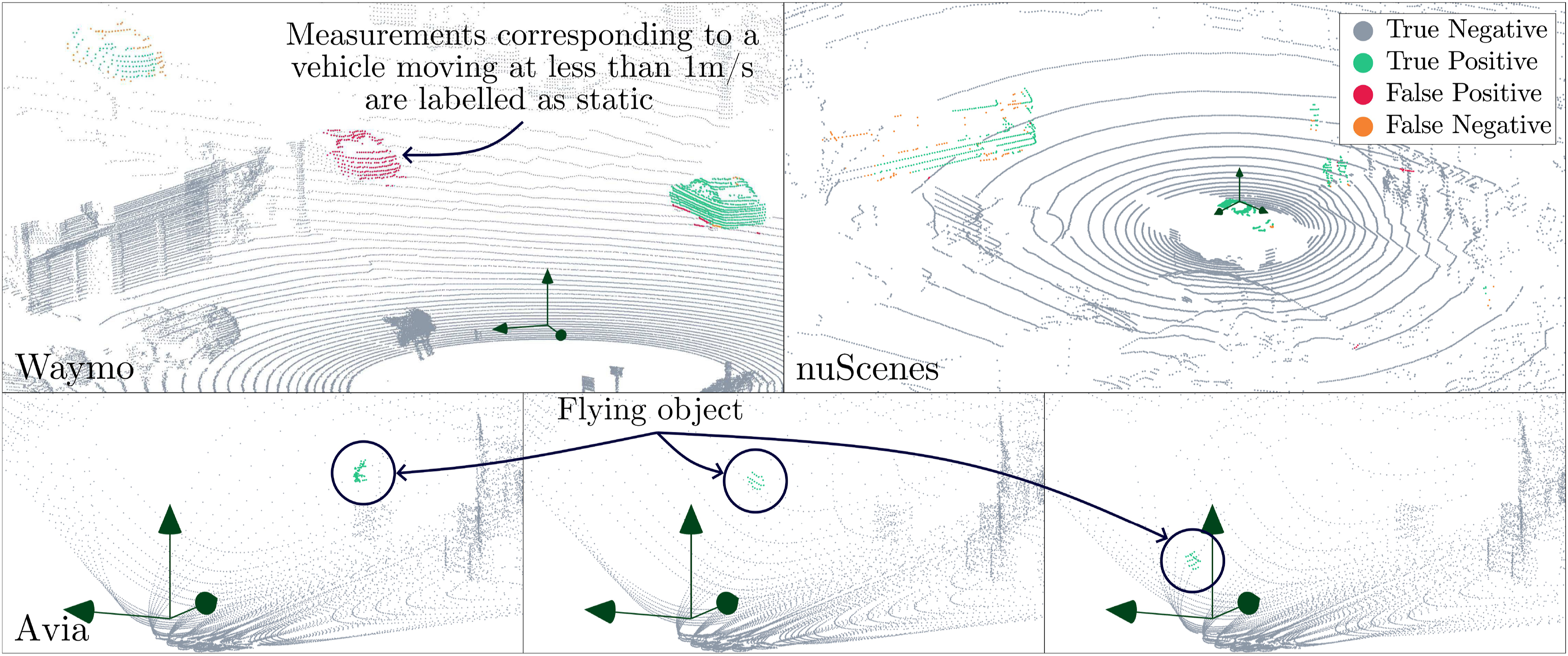
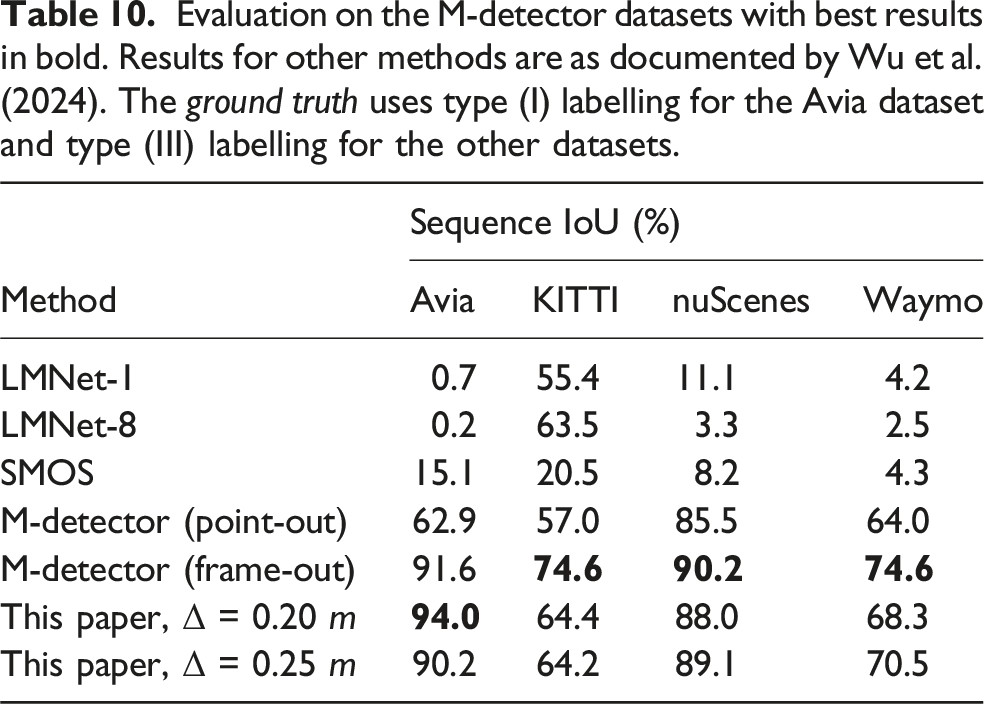
Evaluation on the M-detector datasets with best results in bold. Results for other methods are as documented by Wu et al. (2024). The ground truth uses type (I) labelling for the Avia dataset and type (III) labelling for the other datasets.
The algorithm’s processing rate for varying MOS ranges for the proposed algorithm (top) and the results reported by M-detector (bottom).
DOALS
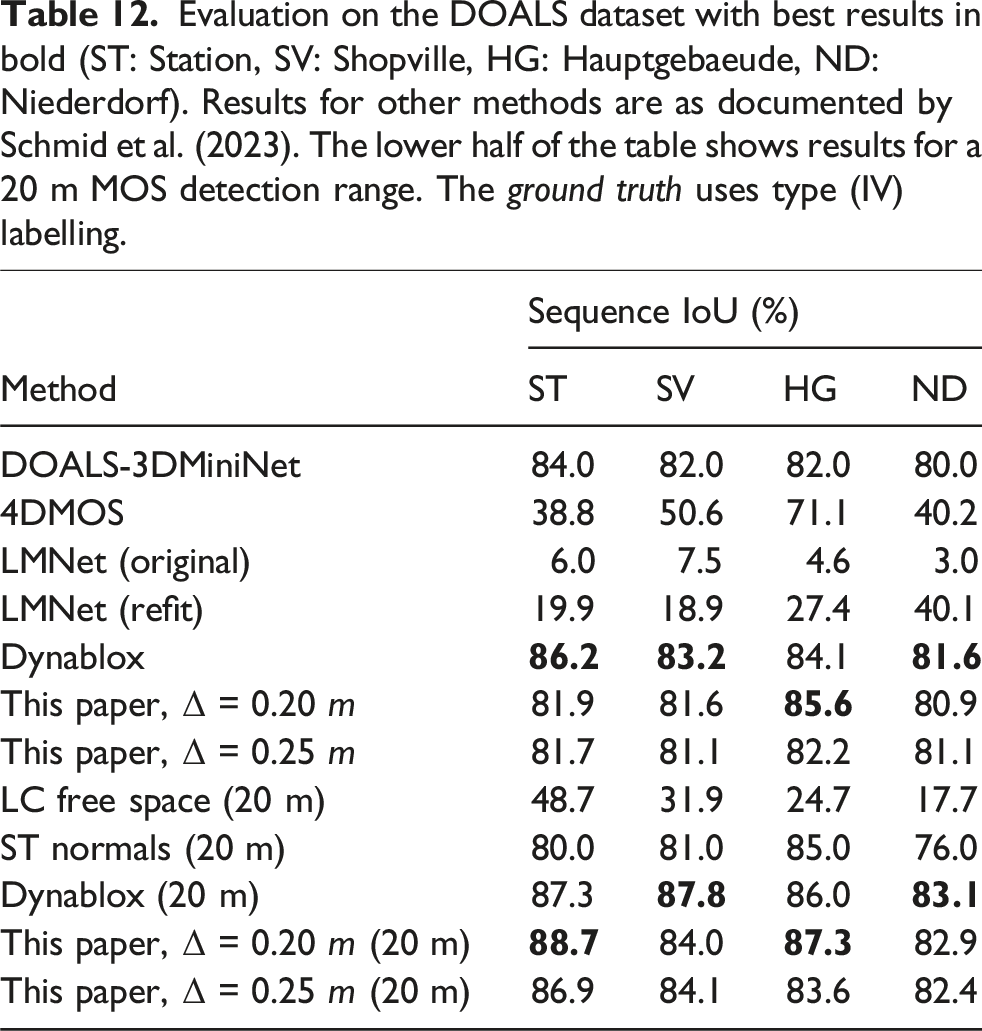
Evaluation on the DOALS dataset with best results in bold (ST: Station, SV: Shopville, HG: Hauptgebaeude, ND: Niederdorf). Results for other methods are as documented by Schmid et al. (2023). The lower half of the table shows results for a 20 m MOS detection range. The ground truth uses type (IV) labelling.
The algorithm’s processing rate for a 20 m MOS range in comparison to Dynablox.

Results are provided for full-range (172 m) and short-range (20 m) test cases. We outperform existing learning-based approaches such as LMNet and 4DMOS and are on par with Dynablox for the full-range tests. The learning-based approaches fail to generalize performance as indicated by the low IoU. We outperform all approaches on the short-range test with similar results to Dynablox again. We achieve a mean precision of 96% and recall of 90% for all evaluated scans. The high precision indicates the low false positives, whereas the slightly lower recall highlights the challenge of capturing the entire object, but is also affected by the labelling process.
Sipailou campus
Evaluation on the Sipailou Campus dataset with best results in bold. Results for other methods are as reported by Zhou et al. (2023). The ground truth uses type (I) labelling.
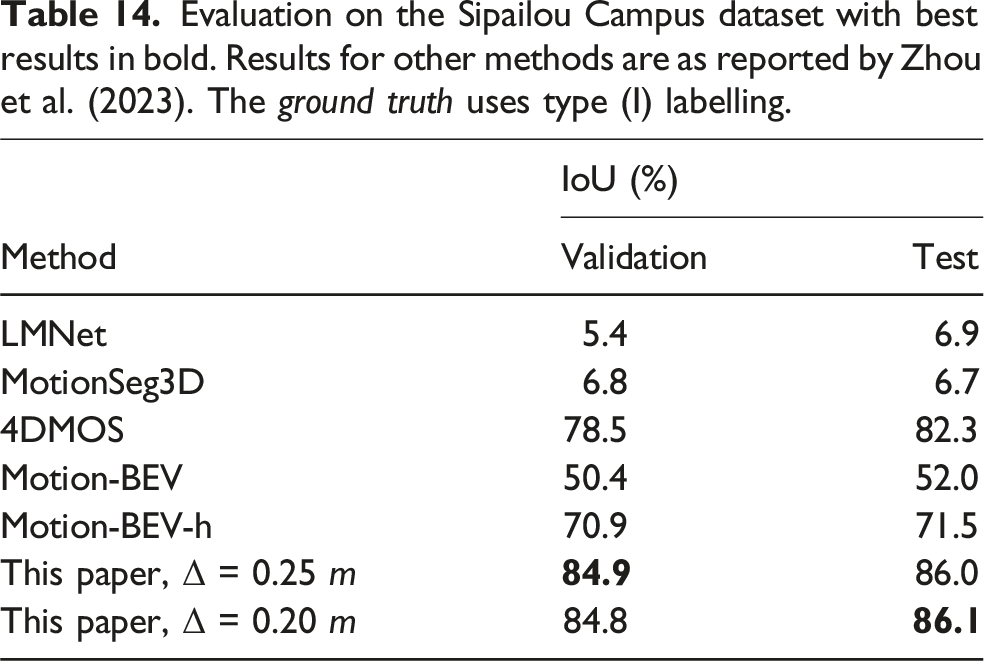
The results for the other methods are used directly from Zhou et al. (2023) and only consider the evaluation without retraining the networks on the new data to provide a fair test of generalized performance. The results are evaluated using the Semantic KITTI API (Behley et al., 2019) to be consistent with the original evaluation process and benchmark results. Learning-based approaches such as LMNet, MotionSeg3D, and MotionBEV fail to generalize due to differences in the sensor’s characteristics. 4DMOS demonstrates strong generalization with its unique design of learning changes in sequential data, being model-independent. The proposed approach cannot capture sparse measurements at longer ranges corresponding to dynamic objects, as they are difficult to differentiate from noisy estimates. The results are processed with an average frame rate of 10 Hz for a maximum 50 m MOS range.
Case study: Detecting moving objects in an excavator’s workspace
This Section investigates the use of MOS in detecting dynamic objects within an excavator’s workspace using onboard LiDAR. Excavator operators have limited visibility from the cab, and their proximity to other machines can result in collisions, leading to operator fatalities, equipment damage, and significant operational downtime. Sensors such as LiDAR enable imaging of the workspace’s immediate environment, and extending the discussed MOS algorithms to this scenario provides the ability to identify the presence of dynamic objects in the agent’s workspace.
This case study demonstrates the performance of the proposed algorithm in detecting the presence of dynamic objects within the excavator’s workspace. The sensor data is from a field study where two Velodyne HDL-64 LiDARs were mounted on the back of an excavator. Two scenarios from the dataset are presented: (i) identifying the presence of a light vehicle that enters the work area during a shift change, and (ii) the changes in the workspace during regular operation as haul trucks come and go.
Figure 11(a) shows the field environment, displaying the instrumented excavator and haul trucks moving in its workspace. Detection results for the left sensor are shown as the excavator is loading trucks to its left only. (a) A view of the case study’s field environment. Two LiDARs are mounted to the rear of the house to image the workspace. Trucks enter and leave the workspace as they are loaded. (b) A comparison of scans captured from the Semantic KITTI dataset (left) and the excavator (right). The change in sensor orientation, mounting height, motion profile, and scanning frequency, pose challenges to providing accurate MOS predictions in an unknown environment for learning-based approaches.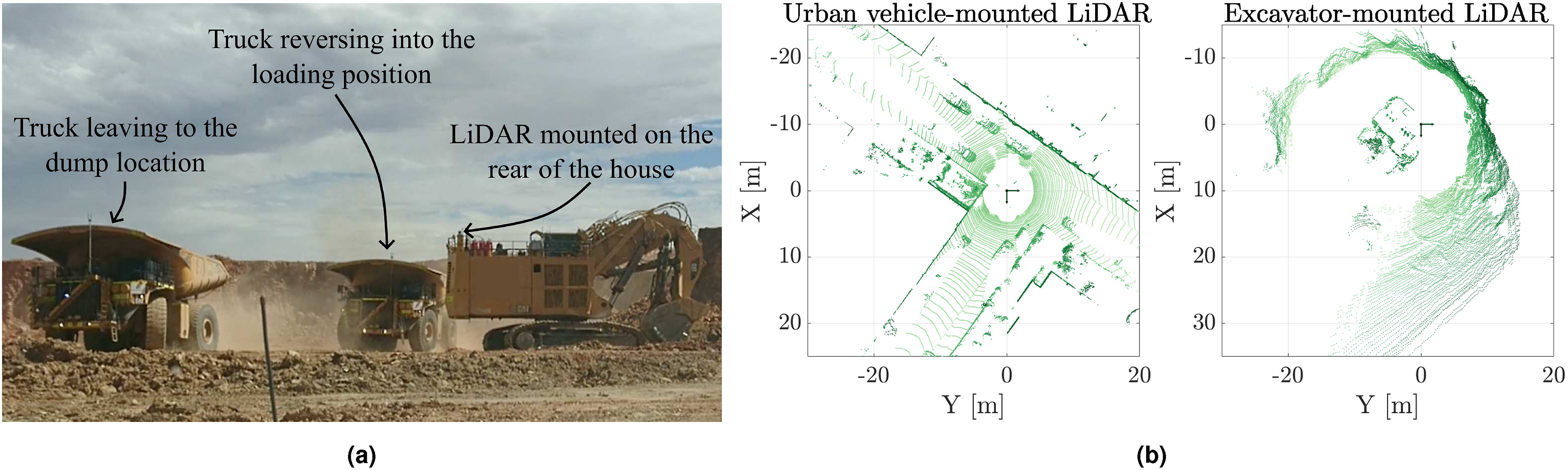
The performance of the proposed algorithm is compared to 4DMOS (Mersch et al., 2022) and MapMOS (Mersch et al., 2023), both of which were trained on the Semantic KITTI dataset (Behley et al., 2019), and Dynablox (Schmid et al., 2023). The Semantic KITTI dataset and this case study both use the Velodyne HDL-64 sensor. However, the sensor’s motion profile, scanning frequency, mounting height, and mounting orientation are drastically different in both datasets. Figure 11(b) displays examples of scans from the Semantic KITTI dataset (left) and the excavator (right). The scan from the Semantic KITTI dataset provides high coverage of the workspace at all times. In contrast, the scan from the excavator is unstructured and has a limited view of different areas in the workspace as the machine slews on its swing axis. The proposed algorithm continues to perform well; 4DMOMS and MapMOS are less effective. Dynablox also performs well, with the high-density scans matching the sensor characteristics from its published evaluation.
All MOS approaches use the same inputs for fair testing, with Dynablox, 4DMOS, and MapMOS configured using their default parameters. The sensor’s pose is estimated using the point cloud data. All detections are performed in the sensor’s frame, allowing for testing with the open-source repositories.
The first scenario assesses the ability of the MOS approaches to identify a light vehicle and its operator within the excavator’s workspace during a shift change. Figure 12 displays the dynamic detection results for the MOS approaches on a sequence of scans as a light vehicle enters the excavator’s workspace. MapMOS and the proposed algorithm yield nearly identical results for all scans, completely capturing the moving vehicle. Dynablox performs well, only missing a small fraction of the vehicle’s bonnet in the last frame. 4DMOS provides a late partial detection, possibly due to the receding horizon used to fuse beliefs about dynamic measurements. This scenario provided a simple scenario with a well-observed vehicle, being similar to the dynamic detections in the Semantic KITTI dataset. A sequence of scans showing a light vehicle entering the excavator’s workspace during an operator shift change. The estimated dynamic detections are shown in green, with missed detection coloured orange. 4DMOS provides late detection and only partially labels the vehicle. The proposed approach, MapMOS, and Dynablox provide fast and accurate detection of the vehicle for the entire sequence. The figure is best viewed in colour.
The second scenario involves a truck maneuvering into the loading position. Figure 13 displays the performance of the MOS approaches for a sequence of scans during the scenario. 4DMOS detects the moving truck in most frames, but generates numerous false positives on the terrain, failing to identify the truck accurately. MapMOS captures the truck in the first frame, provides a partial detection for the second frame, but fails to capture any detections thereafter. The proposed algorithm and Dynablox provide consistent detection across all frames, regardless of the truck’s observability. A sequence of scans of a truck maneuvering into the loading position. The estimated dynamic detections are shown in green, incorrect detections in red, and missed detection coloured orange. Only the proposed approach and Dynablox correctly identify all detections, regardless of the moving truck’s observability. MapMOS correctly identifies the truck when it is fully observable, but misses all occasions of partial visibility in frames. The figure is best viewed in colour.
Both scenarios provide unique scenarios for examining the performance of the MOS approaches. MapMOS performs well without being retrained, but is unable to capture dynamic measurements in partially observable conditions. Its strength lies in using the probabilistic backend to keep a history of the occupied and free space. 4DMOS fails as the scene’s observability changes throughout its receding horizon, from which the dynamic detections are estimated. Dynablox performs well with its default configuration with only minor missed detections. The dense point cloud data closely matches the DOALS dataset used to originally evaluate Dynablox’s performance. The proposed algorithm provides consistent performance in both scenarios.
Computation
Figure 14(a) displays the mean execution time per scan at varying measurement ranges for different sequences. The proposed algorithm provides real-time results for dynamic object detection within a 20 m sensor range, with computation time increasing at larger ranges. The computation time is bi-proportional to the point cloud’s size and discretization resolution. Using a smaller voxel size increases accuracy, but consequently leads to a larger computation time due to the larger number of voxels that need to be updated. The Sipailou campus dataset and HeLiMOS Velodyne (V) are the fastest due to their small point cloud size in comparison to the high-density Ouster (O) scanners. It is important to note that the 20 m range constraint is applied to the measurement’s ray to allow for accurate modelling of free space. Consequently, this means that modelling large open spaces as in DOALS Station (ST) sequences leads to a slightly longer execution time of 148 ms/scan, compared to the Shopville (SV) sequences with an execution time of 60 ms/scan. (a) The algorithm’s timeliness at varying measurement integration ranges for different tests. The algorithm provides real-time results for up to a 20 m range for most scenarios, with computation depending on the point cloud density and voxel size. (b) The computational breakdown of each module for various sequences. The map update and dynamic detection modules are computationally expensive for environments with large open spaces. The figure is best viewed in colour.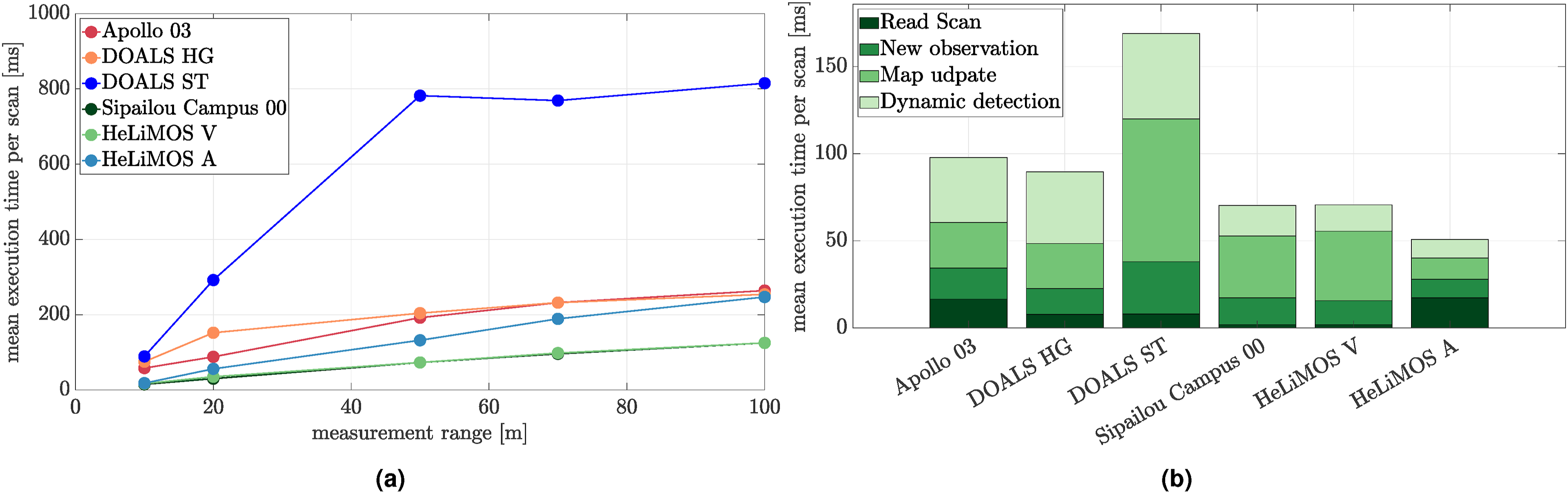
A breakdown of the computational expense of each stage is provided in Figure 14(b). A pattern is observed with the map update and dynamic detection modules being most computationally expensive. Both of these modules involve iterating over all observed voxels. The DOALS ST sequence has a greater computation time for integrating a new observation due to the raycasting operation in a large open space. Implementation of the proposed algorithm relies strongly on CPU threading to provide timely results.
Algorithm configuration
The proposed algorithm has several configuration parameters summarized in Table 1. This Section (i) investigates the effect of the different stages in the MOS pipeline, (ii) provides visualizations of varying configuration parameters to provide a better intuition of their selection, (iii) investigates the sensitivity of the configuration parameters, (iv) details a guide to selecting the configuration parameters, and (v) concludes by analyzing the algorithm’s failure modes.
The purpose of the MOS pipeline’s stages
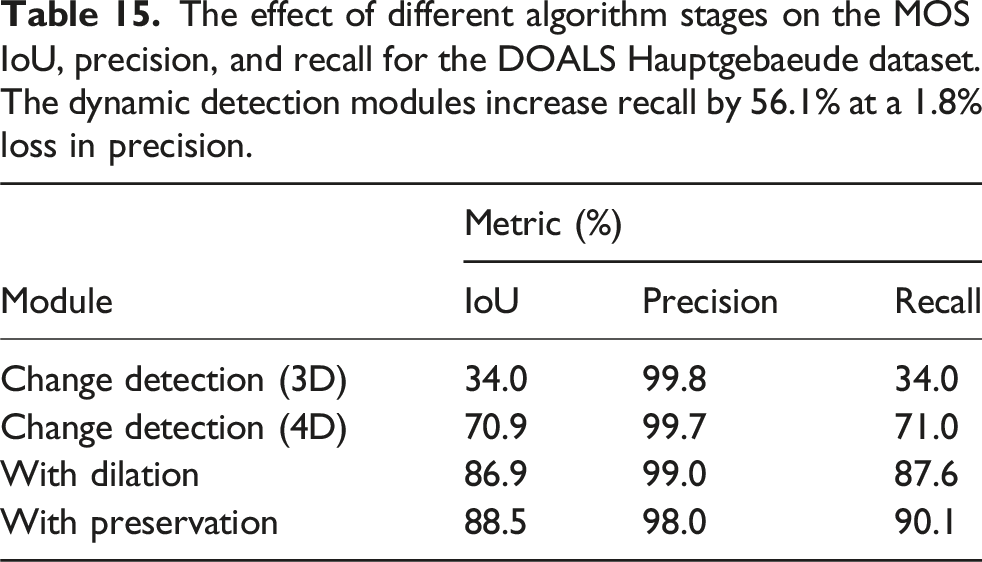
The effect of different algorithm stages on the MOS IoU, precision, and recall for the DOALS Hauptgebaeude dataset. The dynamic detection modules increase recall by 56.1% at a 1.8% loss in precision.
Visualizing different algorithm configurations
Figure 15 visualizes the affect of different configuration parameters on the algorithm’s performance. The first sequence of the DOALS Niederdorf sequence is used for the comparison, with the first column showing the performance of the algorithm using default parameters. The results are analyzed below. Visualization of different algorithm configurations. The first column shows the performance of the default configuration for various scans in the first DOALS Niederdorf sequence. Poor parameter selection leads to incomplete or erroneous detection. For example, configuring a very low lumped measurement uncertainty (σ
o
) leads to the voxel update behaving like a Markov model, where new observations directly overwrite the voxel’s existing state. This does not accurately account for measurement uncertainty, which motivates the use of a hidden Markov model. A local window size of one results in incomplete object detection, equivalent to performing a 3D convolution only. Some parameters, such as the transition probability, ϵ ∈ [0, 1], demonstrate low sensitivity across a range of values. The figure is best viewed in colour.
Voxel state update module
A voxel’s transition between states depends on the transition probability (ϵ), the probability threshold for a voxel transitioning state (pmin), and the evidence supporting the transition, computed using σ o , which is a function of the voxel size (Δ). All these parameters affect a voxel’s state probability.
The state transition matrix,
Decreasing the minimum transition threshold, pmin, results in an increase in the number of noisy detections labelled as dynamic, as shown in the second row. A large value for this threshold is preferred to allow for the sufficient accumulation of evidence to support a transition, minimizing the inclusion of voxels with rapidly changing states.
The uncertainty in the measurements, σ o , affects the rate at which the state probabilities change. As illustrated in the third row of Figure 15, configuring a very low lumped measurement uncertainty, σ o , leads to the voxel update behaving like a Markov model, where new observations directly overwrite the voxel’s existing state. This often causes voxels to rapidly switch between free and occupied states, being identified as corresponding to a dynamic object. Thin surfaces, measurements from reflective surfaces such as glass, and the corners of structures are prone to this rapid switching, as illustrated in the results (second row, second column). Assigning a large lumped uncertainty results in a significant delay in identifying dynamic objects, as it slows the change in voxel state probabilities. The result for the larger uncertainty shows multiple missed observations.
The voxel size, Δ, and the lumped uncertainty, σ o , are strongly linked. The result of the continuous Gaussian function with standard deviation, σ o , is discretized with a resolution of Δ. The EDF is constructed using voxelized measurements.
Dynamic detection module
The dynamic detection module is configured by the convolution size (m), the lower bound on the minimum Otsu threshold (γmin), the local window size (w l ), and the voxel size (Δ). The algorithm computes the likelihood of being dynamic by performing a spatiotemporal convolution over the length of the local window. This likelihood depends on the properties of the dynamic object (size, shape, speed). The kernel attempts to capture the entire object within the local window size, using Otsu’s algorithm to provide a dynamic binary separation threshold between the static and dynamic voxels. The minimum Otsu threshold corresponds to the number of minimum dynamic voxels captured by the kernel across the local window, which is a function of the voxel size, the kernel, and the local window length.
A local window size of one is equivalent to performing a spatial convolution (3D) only, resulting in the incomplete detection of larger objects such as the pram shown in the fourth row in Figure 15. However, it allows for the detection of significantly smaller objects that are usually rejected in the 4D convolution as it is difficult to differentiate from noisy changes in the environment. A larger window size allows for capturing the complete object more effectively.
The size of the convolution kernel, m, is defined in terms of the number of voxels. Consequently, a larger voxel size corresponds to a larger convolution kernel, physically corresponding to the analysis of a larger 3D volume. This additionally requires the minimum Otsu threshold (γmin) to be revised. For example, a large value for γmin is only satisfied by a large number of dynamic detections in the convolution kernel across the local window. The results in the fifth row show minimal differences for a step increase or decrease in the convolution kernel’s size. A smaller kernel size of m = 3 yields numerous false positives near the boundaries of dynamic objects on the ground. A larger kernel size of m = 7 results in incomplete object detection, with the presence of false negatives at the boundary of static and dynamic labels. These examples scale the minimum Otsu value using the same ratio from the default configuration.
The minimum Otsu value is insensitive in the presence of dynamic objects, as the automatic threshold provides a clear distinction between the spatiotemporal convolution scores. The results in the sixth row show several incorrect detections on a tree. A lower minimum Otsu value causes the incorrect detections to grow into areas of lower confidence, whereas a larger minimum threshold minimizes these.
The last row shows the results of increasing the voxel size while keeping the remaining configuration constant. Increasing the voxel size to 0.5 m results in the missed detection of sparse measurements corresponding to dynamic objects and false positives on thin surfaces. A further increase in the voxel’s size to 1 m results in the failure to identify most dynamic objects. Only two people walking together are captured, representing a large dynamic object. This behaviour occurs as the convolution size is large by default (m = 5), and the minimum Otsu value is γmin = 3. These constraints grow relative to the voxel’s size in physical space, only being satisfied by a large dynamic object.
The global window size, w g , and the maximum MOS/sensor range, rmax, are insensitive parameters that do not significantly affect the algorithm’s performance, provided that the global window size is sufficiently large, for example, 300 scans. A small global window, for example, 20 scans, does not allow sufficient time to construct a confident belief of the environment.
Configuration sensitivity
We take the view that an algorithm needs to be insensitive to its configuration parameters if it is to be robust. This section illustrates the effect of varying the algorithm’s configuration parameters on the performance IoU, precision, and recall.
Figure 16 shows the dependency between the lumped uncertainty, σ
o
, the state transition probability threshold, pmin, and the local window size, w
l
. As discussed previously, the lumped uncertainty, σ
o
, corresponds to the uncertainty in observations being integrated into the local map. A very low uncertainty (e.g. σ
o
= 0.1 m) corresponds to trusting the observations directly. Consequently, the results indicate a very high recall at the cost of identifying numerous false positives, as indicated by the low precision. On the other hand, a very high uncertainty (e.g. σ
o
= 0.5 m) leads to dynamic objects being missed, indicated by the low recall. In this case, there is high precision as sufficient observations are required to support state transitions. An anomaly is the w
l
= 10, which displays a very low precision for high uncertainties. This is attributed to accumulating state changes occurring over a longer time compared to the other window lengths and using a minimum Otsu threshold of γmin = 3 for all test cases. The local window plays a significant role in smoothing false positives, with a higher mean precision in the results using a window size of five compared to one. The heatmaps show the insensitivity of the algorithm configuration parameters, σ
o
, pmin, w
l
, on the performance IoU (top), precision (middle), and recall (bottom). A low uncertainty in the observations treats each voxel’s update as a Markov model, leading to a high recall at the expense of identifying many false positives. The Shopville (SV) sequence from the DOALS dataset is used for the investigation. The figure is best viewed in colour.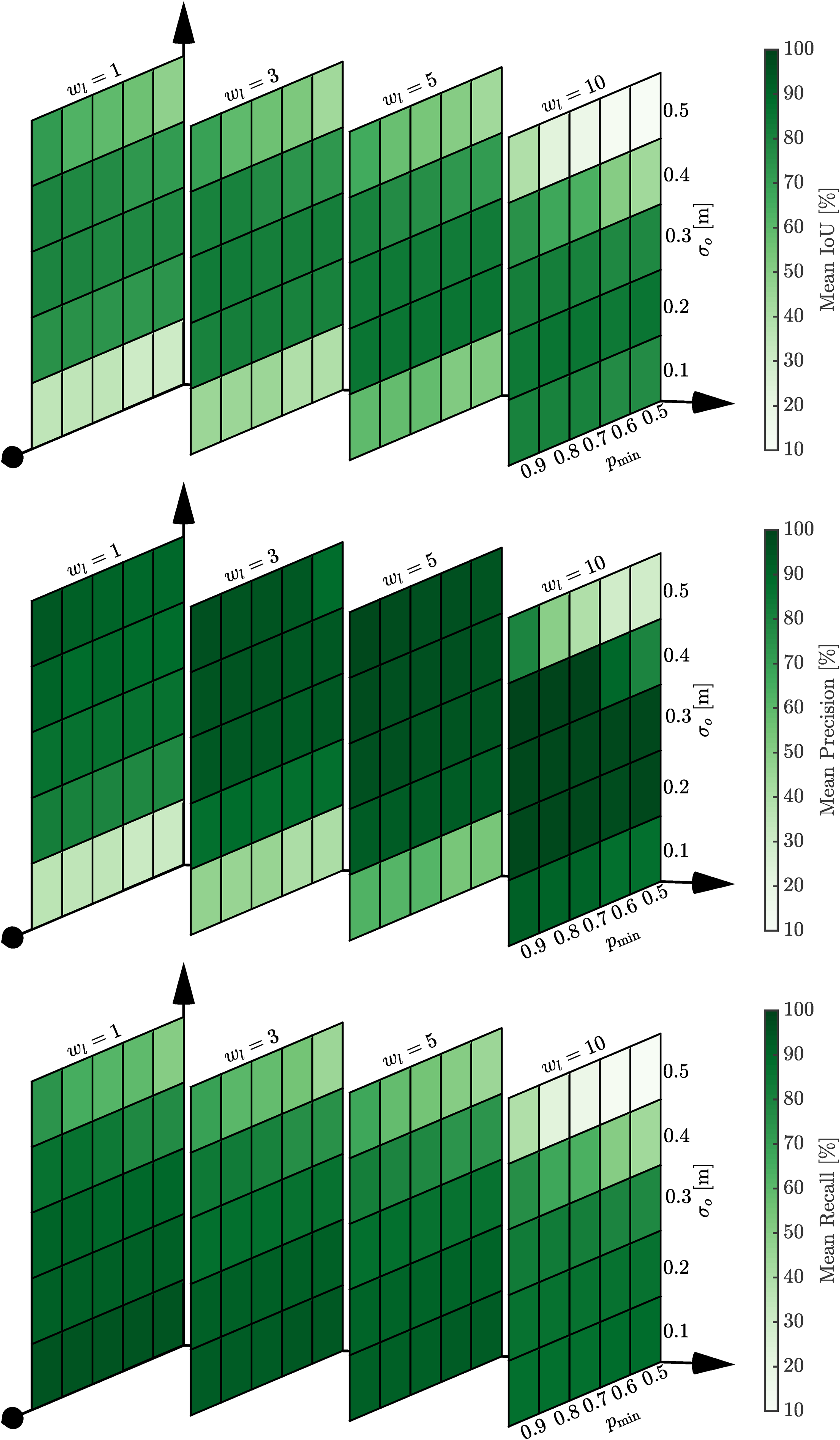
Figure 17 shows the dependency between the size of the convolution kernel, m, the minimum Otsu threshold, γmin, and the voxel size, Δ. A smaller voxel size allows for finer classification and segmentation of measurements corresponding to dynamic objects. The heatmaps illustrate degraded performance with a large voxel size. Only a single configuration parameter is varied at a time, which contributes to poor performance, as these parameters are interdependent. That is, all three parameters represent physical space. A large voxel size, combined with a large convolution kernel, results in the analysis of a larger area. This explains the poor performance with a voxel size of v = 0.5 and convolution kernel sizes of m = 7 and m = 9. The minimum Otsu threshold filters noisy dynamic detections in static scans. A large value such as γmin = 4 is shown to reduce performance for a range of voxel sizes. The smallest voxel size continues to perform well, as the dynamic object will occupy more voxels and hence be less affected by the lower threshold. The heatmaps show the relationship between the algorithm configuration parameters, m, γmin, and Δ, on the performance IoU (top), precision (middle), and recall (bottom). A smaller voxel size allows for better performance, but is computationally expensive. All three parameters represent the size of the dynamic detection operation in physical space. A large convolution size, m = 9, results in a high precision, but fails to capture the entire object as reported by the lower recall. The minimum Otsu value is used to filter noisy detections. A large value, γmin = 4, results in many correct detections being missed. The Shopville (SV) sequence from the DOALS dataset is used for the investigation. The figure is best viewed in colour.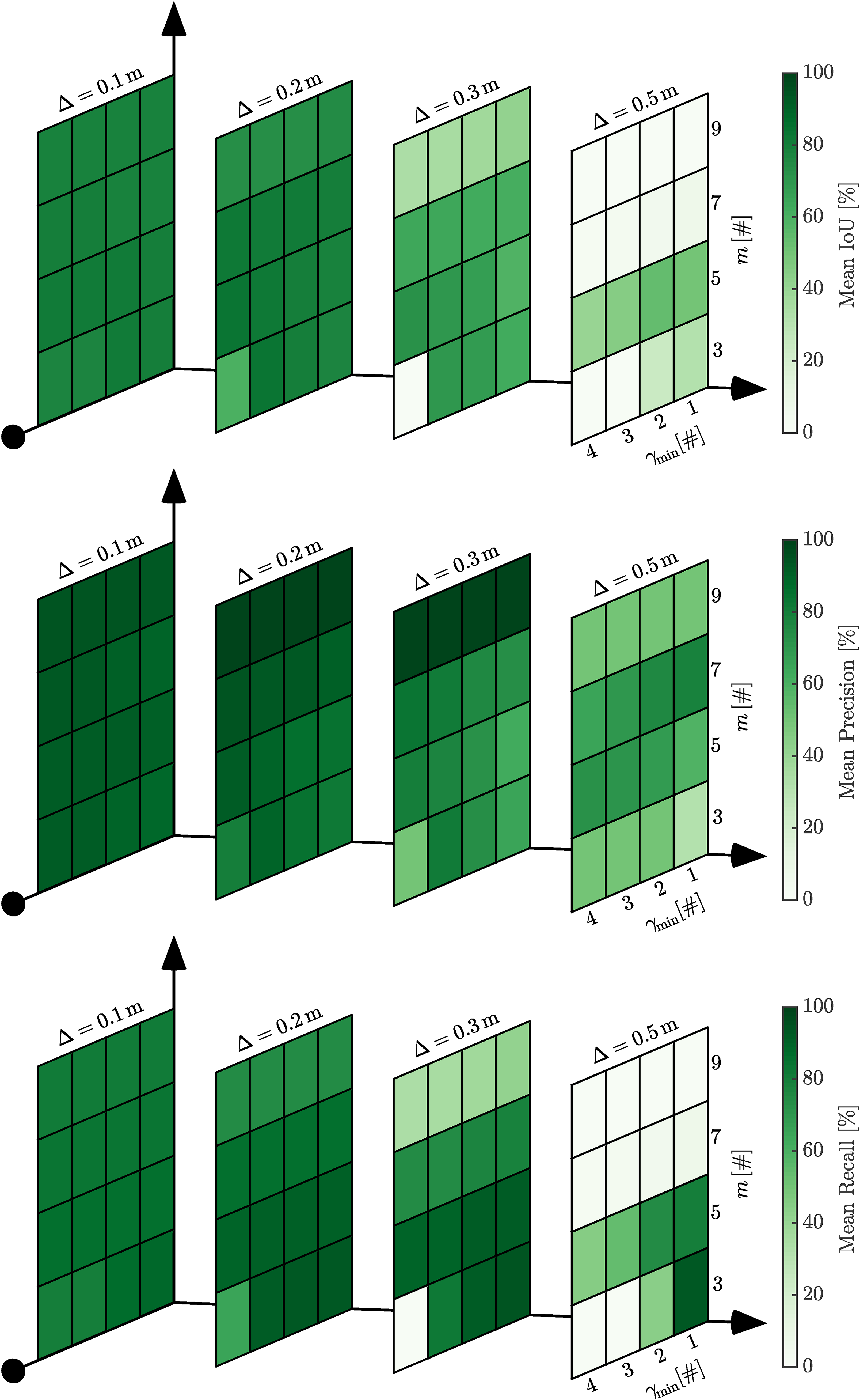
Selecting configuration parameters
The discussion of the proposed MOS pipeline’s stages, visualization of the different algorithm configurations, and analysis of their sensitivity reveal several insights into the effect on the algorithm’s performance. This Section uses these insights to outline an adaptive strategy for selecting the algorithm’s configuration parameters.
A guide for selecting the algorithm’s configuration parameters.
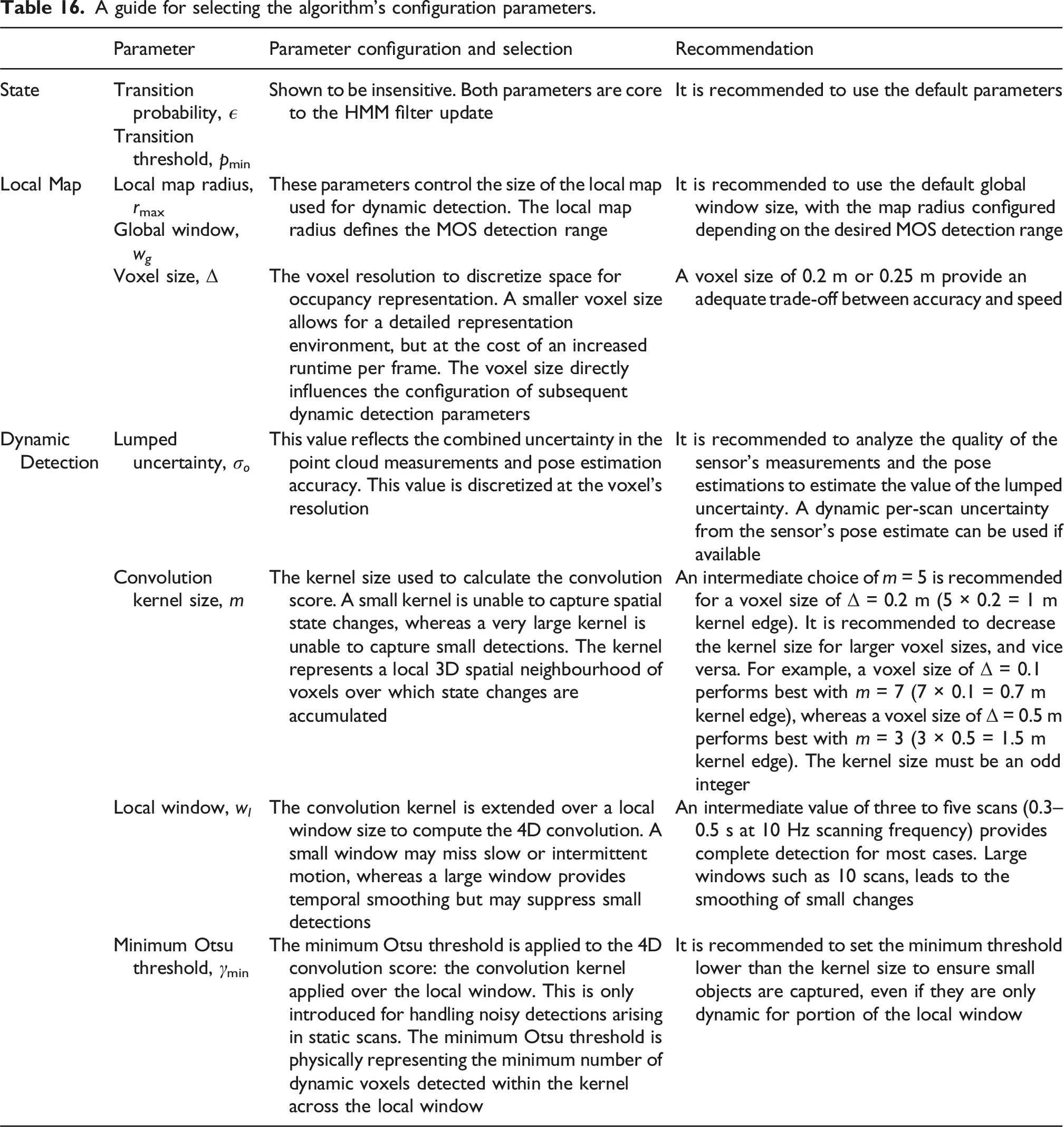
Each of the algorithm’s configuration parameters has a physical meaning. Ill-defined parameters lead to poor performance. The algorithm configuration used for the benchmark tests was tuned using the first Hauptgebaeude sequence from the DOALS dataset during early testing. This allowed the authors to gain an understanding of the parameters and verify beliefs about their dependencies. Upon benchmarking, the configuration was tested with other datasets, resulting in the benchmarked results. We do not see value in optimizing over all nine datasets, as the aim is to design an algorithm that is insensitive to small changes in the configuration and has a meaningful parameter set adaptable for a variety of applications. We invest in describing these relationships to allow for easy and correct adaptation of the algorithm to different applications.
Failure modes
Figure 18 illustrates the failure modes of the proposed approach. Namely, (i) labelling objects moving into unobserved space, (ii) labelling sparse measurements corresponding to dynamic objects, (iii) capturing the complete object, for example, long vehicles such as buses, and (iv) handling large errors in the sensor’s estimated pose. The failure modes of the proposed approach include the inability to capture objects moving into unobserved space (top left), differentiating sparse measurements from dynamic objects from noisy detections (top right), capturing the complete dynamic object (bottom left), and handling significant errors, or jumps, in pose (bottom right). The figure is best viewed in colour.
The top left figure shows the failure in identifying dynamic objects moving into unobserved space (see equation (8)). This occurs due to the strict constraints enforced during the 4D convolution, where voxels cannot have unobserved neighbours. The constraint is important as raycasting is known to be inaccurate around the boundary of observed and unobserved space. Other approaches commonly introduce a delay in the detection, for example, 10 scans, to provide better detection around these boundaries.
The top right figure shows a scenario where dynamic labels are missed for sparse measurements. It is challenging to differentiate these measurements from noisy dynamic detections. Consequently, they are rejected in the 4D convolution when using the automatic Otsu thresholding. This failure occurs due to the sensor’s sparse scanning density at longer ranges.
The bottom left corner shows the partial detection of a bus. From a voxel’s perspective, it remains occupied for the entire length of the bus, during which its state does not change. Hence, it identifies the voxel to be static. This failure can be mitigated by introducing the concept of an object rather than examining it at a voxel level only.
The bottom right image shows several false detections occurring due to a significant error in the sensor’s pose. The algorithm depends on an accurate sensor pose locally. That is, large errors or jumps in pose result in incorrect detections, whereas pose drift outside the global window does not impact MOS performance. The probabilistic state update is capable of handling noisy measurements and sensor pose estimates, but large errors cannot be detected in the current implementation.
Future work
The algorithm currently operates at the voxel-level, with the spatiotemporal convolution aiming to capture the complete object. Current approaches use learning-based approaches to identify measurements corresponding to dynamic objects. There is potential to use existing point cloud segmentation methods (Ošep et al., 2024; Xu et al., 2025) in parallel with the proposed approach to allow for complete object detection.
Analysis of the algorithm’s configuration parameters reveals the interdependency between the hyperparameters. A breakdown of the hyperparameters reveals four critical parameters that substantially affect performance: the lumped measurement uncertainty, the convolution kernel size, the local window size, and the minimum Otsu threshold. The other four parameters are either shown to be insensitive (the state transition probability and the state probability threshold) or are for map maintenance only (maximum sensor radius and global window). There is potential to automatically determine the values of the four critical parameters online by analyzing the characteristics of the point cloud data and the operation environment.
The current pipeline uses the lumped uncertainty, σ o , to capture the uncertainty in the sensor’s pose estimates. Future work involves identifying erroneous pose to avoid false detections. An intermediate module can be introduced to filter poor poses and consequently avoid corrupting the map. Hidden signals, such as significant jumps in the number of estimated dynamic measurements, can be used to identify such instances.
The current algorithm provides accurate MOS detections. However, the MOS range is limited to 25-50 m for real-time results with LiDARs such as the Aeva Aeries II or the Livox Avia. GPU-based solutions can be explored to enable better parallelization of the spatiotemporal convolutions.
Conclusions
Autonomous robots must be capable of detecting dynamic objects. The significant contribution of this work is the provision and demonstration of a solution to the MOS problem that performs as well as, or better than, existing methods, irrespective of the sensor characteristics, platform dynamics, and the robot’s environment. By modelling each voxel as an HMM, the proposed approach allows for confidence-based mapping. The map is queried for changes and facilitates the detection of dynamic measurements. Classic image processing techniques are extended to point cloud data to suppress noisy detections and grow the detection to capture the entire object.
A total of 15 MOS algorithms have been compared across nine datasets, and the proposed algorithm ranks first or second for all datasets. The proposed algorithm ranks first where the ground-truth labels specifically capture movement observed in a scan. Importantly, this is achieved without varying the algorithm’s configuration parameters. A sensitivity study illustrates the motivation for using a probabilistic approach to integrate sensor measurements, and dissecting the pipeline illustrates the benefit provided by each module. The combination of probabilistic modelling using HMMs and 4D convolutions provides a simple approach that works regardless of the inputs and progresses state-of-the-art in labelling moving objects in point cloud data.
The extensive benchmarking conducted in this paper highlights the need for clear and consistent definitions of what constitutes ‘moving’ in a moving object segmentation (MOS) task, along with appropriate benchmarks that enable fair comparison among alternate approaches. We define a moving object strictly as one that is actively in motion during the period of the current scan, not objects that moved previously or might move in the future. While our definition prioritizes instantaneous motion, we acknowledge that this could be extended by definitions that segment objects that have moved in the past or might be expected to move in the future, and these would serve different but equally valid use cases. We propose three classifications of moving objects: • Objects that are currently moving. • Objects that have the potential to move. • Objects that have moved previously and are currently static.
This would allow for consistent performance evaluation. The current confusion of the definition hinders this. We strongly believe this needs to be a consensus decision, not an ex cathedra proclamation.
The establishment of consensus definitions, the creation of consistently labelled datasets, and the development of standardized performance metrics would significantly advance the field. We think this represents an opportunity for collaborative work on datasets labelled by various motion definitions. Inter alia, this would enable meaningful algorithm comparison. The authors welcome approaches from other researchers towards the objective of achieving this.
Footnotes
Acknowledgements
The authors would like to thank the reviewers and editors for their constructive feedback. Data collection for the case study was undertaken by UQ colleagues Dr Timothy D’Adamo and Dr Sam Bettens. The authors also acknowledge the support of Caterpillar in facilitating the collection of the data set.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The first named author has been funded by the Research Training Program (RTP) provided by the Australian Commonwealth and administered by the University of Queensland.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.