
Abstract
Numerous tiny sensors are restricted with energy for the wireless sensor networks since most of them are deployed in harsh environments, and thus it is impossible for battery re-change. Therefore, energy efficiency becomes a significant requirement for routing protocol design. Recent research introduces data fusion to conserve energy; however, many of them do not present a concrete scheme for the fusion process. Emerging machine learning technology provides a novel direction for data fusion and makes it more available and intelligent. In this article, we present an intelligent data gathering schema with data fusion called IDGS-DF. In IDGS-DF, we adopt a neural network to conduct data fusion to improve network performance. First, we partition the whole sensor fields into several subdomains by virtual grids. Then cluster heads are selected according to the score of nodes and data fusion is conducted in CHs using a pretrained neural network. Finally, a mobile agent is adopted to gather information along a predefined path. Plenty of experiments are conducted to demonstrate that our schema can efficiently conserve energy and enhance the lifetime of the network.
Introduction
Rapid development of the microelectronic technology and embedding technology has resulted in the widespread use of wireless sensor networks (WSNs). 1 WSN has the features of self-organizing, convenient deployment, and environment friendly, so it is applied in extensive fields such as industrial manufacturing, 2 environment detection, 3 smart healthcare,4–6 and smart home.7,8 With the increasing scale of network size and improving measurement accuracy, the volume of data presents an explosive growth. Due to the restricted energy of sensors, the traditional routing method cannot satisfy the demand of the latest applications and much attention has been paid to data fusion for better performance of WSNs.
Traditional data fusion technology brings the following merits for different structures of WSNs. 9 First, data fusion is beneficial for enhancing sensor data accuracy. Due to the harsh environment where the sensor nodes are deployed, they are easily destroyed and result in accuracy loss. Data fusion combines data from different sensors to have a comprehensive estimation to increase accuracy. Second, it can accelerate the transmission process in the network. In a hierarchical topology network, cluster heads (CHs) take responsibility to gather their members’ data and this one-to-many structure creates collision easily. Once collision occurs, the data must be retransmitted from the source node. Data fusion decreases the possibility of collision by means of reducing redundant data from the sensor with close location. Third, it preserves energy for the network. The energy used for data transmission is about 1000 times the energy used for computation so that it is energy efficient to conduct data compression before transmission.
Data fusion can be divided into three forms basically: distributed fusion, centralized fusion, and hybrid fusion. 10 As shown in Figure 1(a), distributed fusion is conducted in nodes such as CHs and then the fused data are transmitted to the sink node. It can minimize the amount of data to be transmitted. However, it requires the fusion nodes to have a certain ability of data processing. Centralized fusion is described as shown in Figure 1(b). The fusion process is conducted in the sink node after gathering all nodes’ information to achieve a more precise result. The hybrid fusion combines the advantage of the previous two forms. With the same time, the difficulty of hybrid fusion is much higher. The current research has the following gaps which demand prompt solution: first, many routing protocols mention the data fusion technology; however, a few of them present the specific method for data fusion. Then, sensors are troubled with constrained energy and computational ability, and it is difficult to apply the tradition data fusion method in WSNs.

Different schemas of data fusion: (a) distributed data fusion and (b) centralized data fusion.
The emerging artificial intelligence provides a novel solution for data fusion and gives the sensors wisdom to handle complex data. In this article, we use a neural network to help set up a WSN with distributed data fusion. We first divided the sensor field into several equal squares and each square selects a CH on the basis of nodes’ score (as is discussed in section “CH selection”). Then the cluster members transmit data to the corresponding CH directly or using relay nodes. Data fusion is conducted in each CH using a pretrained neural network when the CH receives all its members’ data. Finally, the fused data are sent to the sink node. This work provides the following contributions:
We present a hierarchical routing protocol using the virtual grid method.
A neural network is trained for data fusion to filter the redundant data and achieve the object of energy efficiency.
A mobile sink is adopted to handle the problem of unbalanced energy of different regions.
Extensive simulations are conducted to prove that the proposed algorithm outperforms the other similar works.
The rest of the article is organized as follows. Section “Related work” describes some latest research achievements about data fusion in a WSN. Some models adopted in this article are introduced in detail in section “The system model.” Section “Our proposed algorithm” presents the specific algorithm of IDGS-DF. Section “Performance evaluation” presents the simulation and analyzes the results. Section “Discussion” provides some reasonable discussion as well as proposes some future work and section “Conclusion” concludes this article.
Related work
Much attention has been paid to energy-efficient routing protocol design during the past few years.11–17 Due to the primary mission of data transmission, energy conservation in WSNs can be achieved in two aspects: energy saving during data transmission and redundant data filtration. Topology control is one of the significant methods for energy saving during data transmission. Much work has been focused on it and achieved great results.
In Heinzelman et al., 13 a hierarchical routing schema called low-energy adaptive clustering hierarchy (LEACH) is presented. In LEACH, the idea of hierarchy is first proposed which has a profound impact on routing protocol design. CHs are selected randomly and each node can be selected as CH only once over a period of time. The advantage of LEACH is that it avoids unnecessary transmission and long-distance communication and makes distributed data fusion easier. However, the defect for the uneven distribution of CHs and clusters is obvious. Based on LEACH, many variations such as Gnanambigai et al. 14 and Kaur and Grover 15 have been proposed to make up for the drawbacks of LEACH.
Many studies adopt the metaheuristic algorithm for better routing topology construction. In Wang et al., 18 the particle swarm optimization (PSO) algorithm is adopted for clustering. The whole sensor field is divided into subareas using straight lines repeatedly and each straight line is represented by a tuple. The straight line is adjusted continually to achieve a better fitness function value. Kuila and Jana 19 adopt the PSO algorithm for better gateway selection. Two different types of sensors are deployed in the target field: ordinary nodes and gateways. Each particle represents a whole solution for gateway routing. Azharuddin and Jana 20 improve the algorithm proposed in Kuila and Jana 19 and pay more attention to energy balancing. Wang et al. 21 the adopt ant colony optimization (ACO) algorithm to schedule the moving path of the mobile sink. The problem of designing the mobile agent moving path is transformed into traveling salesman problem (TSP) and ACO is used for shortest path searching. Wang et al. 22 proposed an algorithm called variable dimension particle swarm optimization (VD-PSO). In VD-PSO, each particle has variable dimensions according to the number of CHs and it presents a novel method for local and global optimal solution updating.
For the purpose of settling the problem of unbalanced energy consumption between sensors, many researchers adopt unequal clustering in their work. Li et al. 23 proposed an algorithm called energy-efficient unequal clustering (EEUC). In EEUC, the CHs are selected by competition and the competition radius is in proportion to the source nodes’ distance to the sink. Energy-based cluster head selection unequal clustering algorithm with dual sink (ECH-DUAL) 24 is an improved version compared to EEUC. During the tentative CH selection, the residual energy, node ID, and trust value are considered and the final CHs are selected according to competition radius, degree of node, and hop count. Yang et al. 25 present an unequal clustering algorithm with different energy levels (UCR-H). In UCR-H, the optimal number of units is calculated using linear programming and the cluster size in each unit is determined by the nodes’ energy level and number of clusters. In addition, many studies introduce the mobile agent for data gathering to handle the problem of unbalanced energy consumption. Wang et al. 26 divide the circular sensor field into fan-shaped areas and the mobile agent travels with a predefined trajectory. In each fan-shaped area, CH is elected according to the residual energy and inter-cluster routing is established using the greedy algorithm. Wang et al. 27 use mobile nodes to patch the coverage holes for better network performance.
In many applications, too much data generation has caused the heavy burden of data transmission so that data fusion gradually becomes a necessary part for WSNs’ routing design to reduce redundant data. Alam et al. 28 conduct an overview of multi-domain data fusion. According to the data type and target, they classify data fusion into three categories: different phase fusion, feature-level fusion, and semantic-level fusion.
Yadav et al. 29 presented a new schema for data gathering called tree-based fusion technique (TBFT). In TBFT, the data fusion technology is introduced to filter the redundant data for decreasing energy consumption. A tree structure topology is constructed for data transmission and the schema adopts the fusion center residing in each root node. The TBFT schema allows the parent nodes to have a flexible fusion ratio according to the depth of the current node. The simulation results demonstrate the presented schema outperforms the classic LEACH algorithm.
Yue and Jiang et al. first analyze the disadvantages of the current technology with data aggregation in Internet of Things and then present a data aggregation collection in wireless mobile mesh networks (DAC-WMMN) algorithm in Yue et al. 30 The authors classify the conflict in data fusion under two categories: intra-tree conflict and inter-tree conflict. Intra-tree conflict means that the parent node cannot communicate with multiple child nodes at the same time and inter-tree conflict means that, when two nodes are transmitting data, they could be influenced by the other nodes within the transmission range. There are two main steps in DAC-WMMN: first, a mobile agent moving path is established according to Create-MRT algorithm and then the data aggregation scheduling for mobile routing tree (DAS-MRT) algorithm is introduced to optimize the collision of transmission. Most of the simulation results illustrate that the presented algorithm has excellent performance in terms of validity, latency, and effectiveness.
Baloch et al. 31 present a novel data aggregation method using contextual information in the area of smart health. The process of data aggregation contains contextual information gathering, environmental model formation, and inference. During the contextual information gathering phase, ordinary data can be collected using a series of wearable sensing equipment. The environment model forming phase handles the situation and relation information. The inference phase combines all the features to give an inference.
The system model
The network model
We divide the whole sensor field into several squares and each square represents a subdomain of the sensor field. We randomly deploy

The network model.
In order to ensure that nodes in every subdomain can communicate with each other, the size of each square

where
We make the following assumption to conduct the experiments conveniently:
Sensor nodes almost remain static after being deployed and have their own position knowledge by means of the equipped GPS.
The energy of nodes is restricted and their batteries cannot be changed.
Each node owns adequate computational ability to conduct data fusion.
The energy of mobile sink is unconstrained and it can move freely in the sensor field for data gathering.
The energy model
We introduce the energy model presented by Arjunan and Sujatha
32
and just consider the energy consumption used in data transmission and data fusion. Figure 3 presents the energy consumption during the process of wireless communication. The transmission consumption
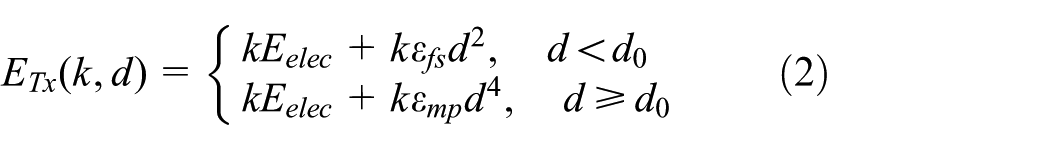

The energy model.
where
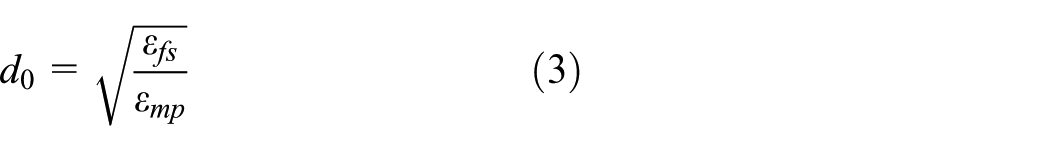
The reception consumption

Our proposed algorithm
CH selection
There are several factors influencing the selection of CHs. We analyze each factor and combine them to give a comprehensive score for each node. Nodes with the highest score will be selected as the CH.
Residual energy ratio
The residual energy is a significant criterion for CH selection. Due to the role the CHs play, CHs need to collect their members’ data, thus consuming much more energy. The possibility of being selected as CHs is determined by the residual energy ratio. The residual energy ratio
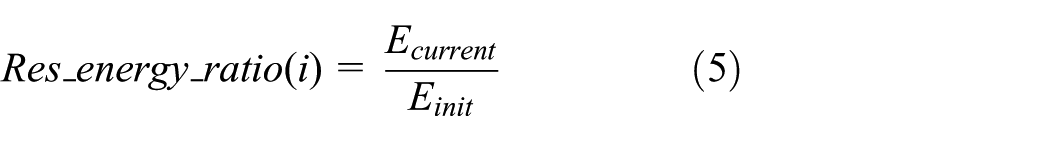
Total neighbor distance
According to the free space model, the energy consumption during transmission is in proportion to the square of transmission distance. The total neighbor distance describes the distance from its neighbor. Nodes with less total neighbor distance are more likely to be selected as CHs. The total neighbor distance

The score of each node in the subarea can be calculated using formula (7). Then each subarea selects the node with the highest score as CH

Data fusion processing
Neural networks are inspired by neurons in the human brain and it is an abstract model of our nervous system. Neural networks are not restricted to the rigorous ratiocinative method and refined calculation and bring up a new methodology for data fusion. The basic unit of a neural network is neuron and the structure of neuron is shown in Figure 4.

The neuron model.
Each neuron receives the input information of other


Considering the ability of computation, we only construct a four-layer neural network for data fusion. The neural network structure is described as shown in Figure 5.

Neural network structure.
The activation of the first three layers is a ReLu function because it has a steep slope and accelerates the learning of the network. The activation of the output layer is a logistic function to make an inference.
We first initialize the weight of each neuron using a method proposed in He et al. 33 We use the following equation to initialize the weight of the network

where
Then the network uses the forwarding propagation algorithm to calculate the output of each layer until the last layer. We use cross-entropy loss as our loss function to estimate the performance of our model after the output layer. The loss function is shown as follows

where
With that, a backpropagation algorithm is adopted to achieve the gradient of each layer according to the error of each layer. Finally, the weight of each layer will be updated according to the gradient and we use formula (12) to update the weight
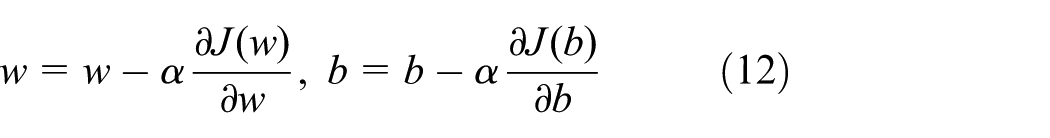
where
We apply our proposed algorithm in forest fire prediction. 34 The input of the neural network is the sensor data that the sensors detect and the output is the possibility that forest fire breaks out. When the possibility exceeds a threshold value, the data will be transmitted to the sink for further estimation. We use the fire data of the Montesinho Natural Park downloaded from the website to train the neural network. The data contain features like date, humidity, temperature, wind speed, and the amount of precipitation. Once a CH node is selected, it will design a time-division multiple access (TDMA) schedule and inform its members. The CH node in each subarea introduces the pretrained neural network to estimate the possibility of forest fire breaking out with the detected data.
Sink mobility strategy
Sink mobility technology is adopted to handle the problem of hot spots and balance the energy of different regions to enhance the lifetime of the network. We first define the agent node as a substitute of the mobile agent because when the mobile agent keeps moving, it owns a high package loss rate and needs to broadcast its location in real time. The CH in the current subdomain of mobile agent plays the role of the agent node. The mobile agent moves toward a predefined path as shown in Figure 6. When the mobile agent moves into a subdomain, it will broadcast a location message that contains the subdomain ID. Each CH employs the greedy algorithm to transmit its data to a neighbor CH which is closer to the agent node and the agent node communicates with the mobile agent immediately. The mobile agent will backtrack when it moves to the last subdomain.

Sink moving trajectory.
Performance evaluation
Neural network training
We employ MATLAB as our simulator to analyze the performance of our presented schema. We first train the neural network that we designed for data fusion. There are several hyper-parameters in the training process and different combinations of hyper-parameters may lead to an entirely different performance of the neural network. By means of numerous simulations, when the neural network achieves the best performance, the hyper-parameters are listed in Table 1.
Neural network parameters.

Cost value describes the error of prediction that the neural network outputs. The cost of the training process is shown in Figure 7. We can clearly see that, when the algorithm iterates about 1500 times, the cost value tends to converge.

Cost value in the training process.
Network performance evaluation
We randomly deploy 300 sensor nodes in a
Simulation parameters.

We analyze the network performance mainly in two aspects: average energy consumption and network lifetime compared to the classic LEACH algorithm and TBFT. In order to show the contribution of performance by the data fusion process, we also compare our proposed algorithm introducing data fusion with no data fusion. Figure 8 illustrates the energy consumption of different schemas. Our proposed algorithm obviously outperforms LEACH in terms of energy consumption because data fusion filtrates the redundant sensor data and decreases the energy consumption in transmission. In addition, our presented algorithm consumes less energy compared to TBFT because of the high-efficiency data fusion method. Without data fusion, our presented schema still has an excellent performance due to the even distribution of CHs to avoid long-distance communication compared to LEACH.
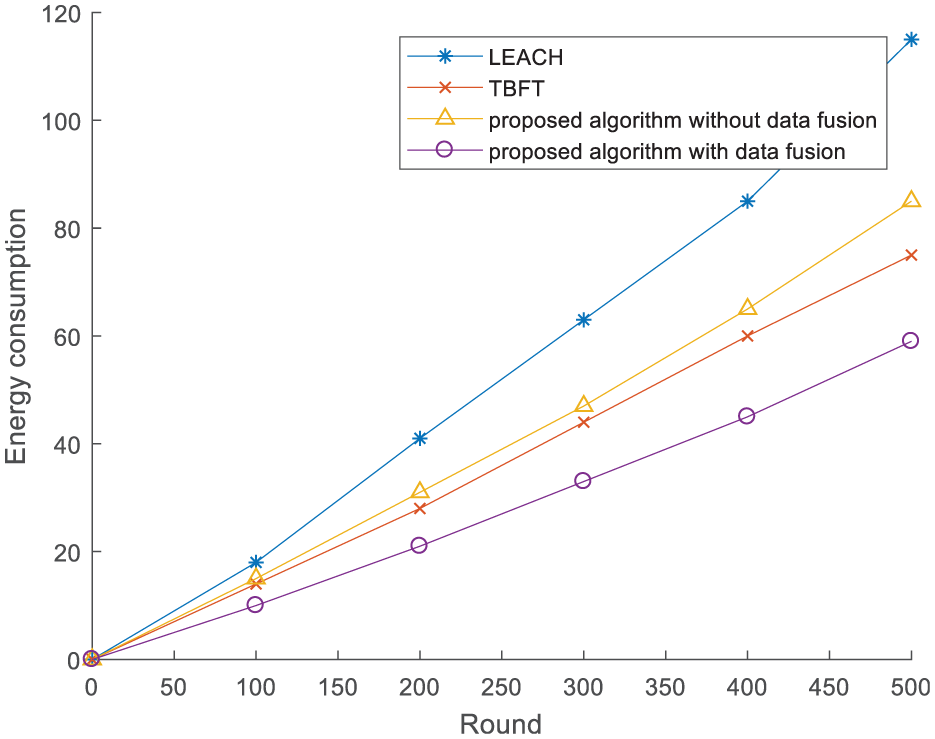
Comparison of energy consumption.
Figure 9 demonstrates the changes of living nodes along with the rounds increasing under different schemas. Each point in the picture denotes the number of live nodes after a complete round and the slope of each line denotes the node death rate. Once there are dead nodes in our system, the accuracy of data fusion in the subarea will make a big difference. Therefore, the first node death is a significant evaluation index of network performance. During the initial stage of the network, the death rates in different schemas are almost the same due to the abundant node energy. With increasing rounds, nodes begin to die in LEACH at about 200 rounds, whereas the rounds of the first node death in our proposed algorithm are 300 and 600, respectively. Clusters in LEACH are uneven such that one cluster may contain excess nodes and result in CH’s death. Our proposed algorithm adopts virtual grids to divide clusters evenly so that the round of the first node death is postponed. Mobile sink also balances the energy consumption of different subareas. Data fusion reduces redundant data and further enhances the network lifetime. Therefore, our presented algorithm is superior to TBFT from the aspect of network lifetime.
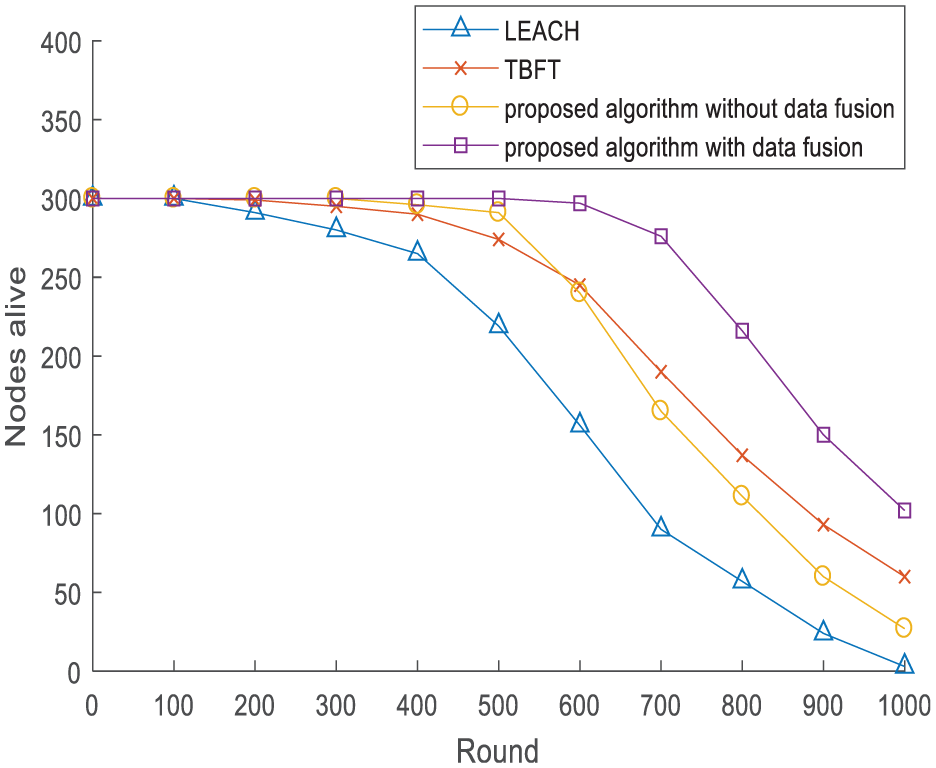
Comparison of network lifetime.
Discussion
The explosive increase of data volume has accelerated the development of data fusion technology. There are many methods to achieve the goal of data fusion such as direct concatenation, deep neural network (DNN)-based data fusion, and multi-view-based data fusion. It is difficult to estimate which method is best for data fusion because of the different application scopes of different methods. DNN has an excellent performance, especially when the amount of input data is very huge. However, the training process of DNN is much difficult using backpropagation because of the large structure of the network.
There are several evaluation indexes for the network lifetime such as first node death, death of half the nodes, and death of all nodes. When the first node dies because of energy depletion, the performance of the network decreases rapidly because the network connectivity is reduced and coverage hole may emerge. Therefore, energy balancing of nodes plays a significant role in topology control. The uneven energy distribution in clusters can be solved by CH’s rotation and the uneven energy distribution between clusters can be addressed by mobile data gathering.
The main limitation of our proposed IDGS-DF algorithm is that the training process of a neural network needs to be supported by the great computational ability. Although sensors do not need to train the network, the execution of a neural network still consumes lots of energy. Another drawback is that once the types of sensor data change, the neural network needs to be retrained to fit the data which means that the network owns poor portability. Our future work mainly focuses on the following: first, we hope to simplify the construction of the adopted neural network to decrease the amount of computation; second, we wish to try to apply more machine learning models in data fusion; third, the traveling path of the mobile agent needs to be further optimized.
Conclusion
In this article, a distributed routing schema with data fusion using neural networks is proposed for WSNs. With the aim of decreasing the energy consumption and enhancing the network lifetime, we introduce a neural network into our system for data fusion. We first divide the whole network into several subdomains by virtual grids. Then the CH in each subdomain conducts data fusion using the pretrained neural network. We apply our proposed algorithm in forest fire detection and the outputs of the neural network that exceed the possibility threshold will be transmitted to the sink nodes with ordinary data. Moreover, the mobile agent is adopted to move along a predefined path for data gathering and the agent node is selected to mark the location of the mobile agent. Extensive simulations are conducted to prove that our proposed algorithm has better performance in terms of energy consumption and network lifetime.
Footnotes
Handling Editor: Mohamed Abdel-Basset
Author contributions
J.W. and H.-J.K. conceived and designed the experiments; Y.G. and W.L. performed the experiments; A.K.S. analyzed the data and helped to revise the paper; H.-J.K. advised on the simulation settings; and J.W. wrote the paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (61772454, 61811530332, 61811540410).