
Abstract
The keywords extraction of bilingual news events in China and Vietnam has a very important role in understanding bilingual news events. It can quickly locate and briefly compare the news of the same events reported by the two countries. Chinese–Vietnam news texts are typically unstructured big data. How to extract the keywords that characterize the news in these unstructured data is the difficult problem of unstructured big data analysis. Bilingual documents are difficult to understand because bilingual Chinese and Vietnamese are not in the same language space. However, the hypergraph of the hypergraph model can better express the multiple relations of the vocabulary association and the entity association for bilingual news. Therefore, a method based on hypergraph for bilingual news keywords extraction is proposed. In this method, bilingual news words are extracted to construct a bilingual word set, and the words are taken as vertices. Chinese–Vietnamese sentences and bilingual words with the same semantic meaning as different types of hyperedges and the bilingual word frequency are used as the attribute to construct a bilingual news item word hypergraph model. Then, the directional diffusion algorithm in the wireless sensor network is used to iteratively calculate the weights of the vertices so as to realize the extraction of keywords in the Chinese–Vietnam bilingual news. The experimental results show that the proposed hypergraph method is better than the single-document extraction method, which can better obtain the keywords of the bilingual unstructured text data.
Keywords
Introduction
With the rapid development of the Internet, the number of Chinese-Vietnamese-related news is increasing. How to effectively understand these unstructured data plays an important role in promoting political, economic, and cultural exchanges between the two countries. Keywords extraction is an important direction of text data mining.1,2 Keywords are the smallest unit that describes news events and also is key to unstructured text data. Keyword extraction is important in the automatic summarization of documents, the extraction of web pages, the classification and clustering of documents, and the retrieval of information. For Chinese–Vietnamese bilingual news keyword extraction, how to express the complex Chinese and Vietnamese bilingual news document structure is very important.
Based on the above problems, this article introduces hypergraph to represent the Chinese–Vietnamese bilingual news documents and associates bilingual vocabulary with a bilingual dictionary to map documents in different languages space to the same language space. When documents in different languages space are mapped to the same space, we can iteratively calculate the change of weight to achieve keyword extraction.
The remainder of this article is organized as follows. Section “Related woks” discusses the main keyword extraction algorithms. Section “An algorithm for extracting words from Chinese–Vietnam news based on hypergraph” describes how to construct a hypergraph model of the Chinese–Vietnamese news documents. Section “Chinese–Vietnamese keyword extraction based on directed diffusion” discusses how to iteratively extract keywords on the hypergraph model. Section “Experiments” describe the experiment and analysis. Section “Conclusion” presents conclusion and future work.
Related works
In the aspect of keyword extraction, there is mostly single-word keyword extraction, single-language multi-document keyword extraction, and multi-language multi-document keyword extraction. Single-document keyword extraction is only a document on the extraction of keywords, which is mainly through the word frequency, the relationship between the word and word topic information keyword extraction. Salton and Buckley 3 classify the words in the document by counting the frequency Term Frequency (TF) and the reverse document frequency Inverse Document Frequency (IDF) appearing in the document for each word, according to the size of the Term Frequency–Inverse Document Frequency (TF-IDF). The algorithm proposed by Y Matsuo and M Ishizuka 4 divides the candidate words with different subsets by word frequency and judges whether the word is the keywords for the document based on the degree of bias of the word of these subsets. R Mihalcea and P Tarau 5 use the word as a node, then convert the text into a graph through the co-occurrence of words, and finally extract the keywords through iteration. DM Blei et al. 6 proposed latent Dirichlet allocation (LDA). Z Liu et al. 7 and R Saeidi et al. 8 applied the LDA model of keyword extraction and achieved good results. Single-language multi-document keyword extraction refers to the same language from the representation of a number of news documents to extract the main theme of the keywords. And it mainly uses the words of document information and documents-related information to achieve multi-document keyword extraction. KM Hammouda and DN Matute 9 extract key phrases for multi-document collections and clusters by CorePhrase algorithm. Y Jie and J Duo 10 use the Average Term Frequency (ATF) × Proportional Document Frequency (PDF) method to select the candidate words in the document set and then use the combined weights method to extract the keywords according to the semantic similarity between the candidate words. The ATF × PDF method determines the weight of a word by the product of the average word frequency of the word in the entire document set and the proportional document of the word. Multi-language multi-document keyword extraction research work needs less research. The main purpose of the multi-language multi-document keyword extraction is to extract the bilingual keyword set which can express the news event from the multi-language multi-document, and the concrete manifestation is the bilingual multi-document understanding problem. However, because different languages cannot be calculated in the same space, single-language environment extraction algorithm cannot be completely suitable for Chinese and Vietnamese bilingual news keyword extraction.
Through statistical keyword extraction, one can obtain statistical information about terms, but cannot describe the relationship between words and sentences. Graph-based keywords extraction considers the relationship between words and words, but it is limited to simple binary co-occurrence relations and cannot express the multi-relationship of cross-language documents well. Keywords extraction based on topic models is too dependent on topic distribution, and it is difficult to represent cross-language documents in the same space. Therefore, this article uses the hypergraph to model the Chinese–Vietnamese bilingual news documents.
The hypergraph is a generalization of ordinary graphs. In the general diagram, an edge can only connect two vertices that have a certain relationship. However, in reality, the relationship between the various objects is usually much more complex. For example, a hypergraph of a hyperedge can contain multiple vertices, so when constructing a hypergraph for a document set, a hyperedge can represent an author, and this hyperedge of each vertex can be expressed as the author of each work. And the hypergraph can express the relationship between the author and the work well. Therefore, we believe that the hypergraph can better express the multivariate relationship. Chinese–Vietnamese bilingual news event keyword extraction is a multi-lingual document understanding problem. As bilingual-related news events have a correspondence between bilingual entities, at the same time, there are related relationships in terms of time, place, and reason. These relationships are complex, but the hypergraph structure can characterize bilingual multivariate relationships. Therefore, this article constructs bilingual news event word hypergraph model based on hypergraph thinking and obtains bilingual news keywords.
An algorithm for extracting words from Chinese–Vietnam news based on hypergraph
Hypergraph
The hypergraph is based on set theory and graph theory and first proposed by C Berge11–13 in 1973. Up to now, hypergraph theory has been in the field of computer science and artificial intelligence has been developed by leaps and bounds. The concept of hypergraph is defined as follows:
Suppose that the hypergraph expression is
The incidence matrix of the hypergraph is

The elements of the weighted hypergraph correlation matrix

where
The degree of the hyperedges in the weighted hypergraph is defined as follows

The hypergraph model can well reflect the various relationships of news documents. If the word of a news document is taken as the vertex, the hyperedge can represent the sentence in the news document. And the hypergraph model can be more precise by giving weight to the hyperedge. If a sentence contains multiple core words, then this sentence is obviously very important, so it can give a higher weight to the hyperedges that represent the sentence. The hypergraph model not only reflects the inclusion relation between words and sentences but also describes the attribute information about sentences, which can help the extraction of keywords.
Build a hypergraph model
This article takes the Chinese and Vietnamese bilingual news events document as the research object. We crawl the Internet news events first through the news text clustering and related events analysis and access to the relevant news events. Then, after the Chinese and Vietnamese news documents are segmented and part of speech and entity recognized, the stop words are removed, and nouns, verbs, adjectives, time words, position words, and place words are selected as the word set of the news representation. Due to the existence of entities, time, place, and logic within the news event document, there is also an association with words and entities in the documents. Therefore, it is possible to realize the relationship between the bilingual news documents through the Chinese–Vietnamese bilingual dictionaries and the entity correspondence library and to establish the multiple relations such as the word association and the entity association between Chinese–Vietnamese bilingual events.
The hypergraph model can express the collection of Chinese and Vietnamese bilingual news documents and describe the multiple relations between Chinese and Vietnamese words. The hypergraph vertices are used to represent words of the Chinese and Vietnamese bilingual news document, and the hyperedges are used to express the sentences in the Chinese and Vietnamese bilingual news document.
The construction of hypergraph model is as follows: In Figure 1,

Chinese–Vietnamese bilingual hypergraph model.
Vertex weight calculation
In the Chinese–Vietnamese bilingual news hypergraph model, the vertices represent the words of Chinese news documents and Vietnamese news documents. When computing vertex weights, this article combines some ideas of single-document news keyword extraction and at the same time takes into account the characteristics of bilingual news documents and finally selects the following features to participate in the vertex weight calculation.
Word span factor. Word span refers to the distance between the first occurrence and the last occurrence of a word in a document, indicating the extent to which the word appears in a document. And the larger the value, the wider the range of influence in the text. The advantage of word span is the ability to know whether or not a particular word appears in all passages of the text.
The word span is calculated as follows

In formula (4),
Word span can effectively reduce the impact of local keywords on the final extraction results.
2. The part-of-speech factors. The part of speech has a positive effect on keywords extraction.15–17 The part of speech of the word expresses the function of the word in a sentence. According to syntactic rules, words of different parts of speech tend to have different degrees of importance. For example, nouns are often used to describe the concept of an entity and to be able to express specific things. Therefore, most of the keywords are mainly nouns in a news document. But conjunctions and prepositions are less capable of expressing specific things and are almost impossible to become keywords.
In this article, 100 news pages are randomly selected from Tencent News, Sina News, and NetEase News, and these news documents are marked with keywords by manual means. Then, the words are counted according to the frequency of part of speech, and the part of speech is used. The pos(t) is defined as shown in Table 1.
3. Location factors. Because of its rigor, the news documentation always requires a clear structure, so most of the news documents will briefly introduce the main contents of the news event at the beginning. Therefore, the higher the position of a word of a news document, especially the words of the title, the more likely it is to become a keyword.
Part of speech and weights.

The formula of position weight of words is as follows

In formula (5),
4. Bilingual word frequency factors. Taking into account the characteristics of bilingual news documents, we add the characteristic information of bilingual word frequency to the vertices of the Chinese–Vietnamese news hypergraph model.
One of the biggest features of bilingual news is that when describing the same news document, there is differences between the two sides of the news content because of differences in the national standpoint. Table 2 is the difference reported by Chinese and Vietnamese News on the same incident.
Differences in bilingual news reports.

In the bilingual news keyword extraction, the conventional TF-IDF has been unable to accurately express the importance of a word. Because in the context of a bilingual document, there may be some differences in the news content reported by the two countries. It has certain words that occur frequently in the news of one country, while in another country the concentration of news documents is almost invisible. If you blindly calculate the TF-IDF for the entire bilingual news document set, there will be inevitably a big error. Therefore, TF-IDF values of our restricted words are only calculated in the news documents in the same locale in the Chinese–Vietnamese bilingual news hypergraph model. In this way, errors caused by differences in news content of the two countries can be avoided.
Keyword extraction in a bilingual environment must take into account the infrequent words of a country’s news media, a factor that may be important to another country. According to these analyses, we propose the bilingual word frequency features of words, which are calculated as follows
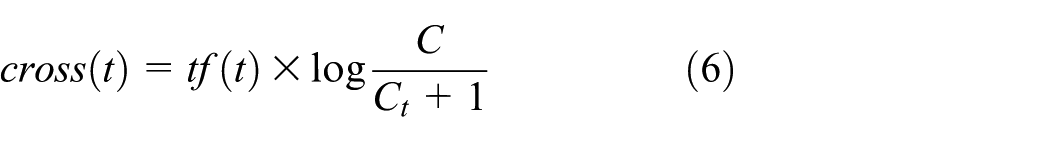
In formula (6), 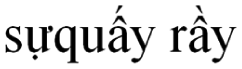 ” (harassment), then
” (harassment), then
In summary, we can get the final calculation formula of the vertex weights in Chinese–Vietnamese bilingual news hypergraph model

Among them,
Override weight calculation
There are two different types of hyperedges in the Chinese–Vietnamese bilingual news hypergraph model. One of the hyperedge represents a sentence in the news document and the other is the same-meaning word of the Chinese–Vietnamese bilingual news documents set.
For the hyperedge that represents a sentence, the idea of natural language processing is the more important the words contained in a sentence, the more important the sentence becomes. Therefore, the weight of a sentence is determined by the weight of all the words contained in the sentence. At the same time, long sentences are effectively penalized in order to prevent long sentences that might not have been important, but they contain a high number of words.
The calculation formula for the weight of the hyperedge is as follows

In formula (8),
The hypergraph model can express the inclusion relationship between words and sentences. In general, important sentences will get a higher weight, and the words of them rank higher in the rankings.
For the hyperedges of the set of words that represent the same meaning in bilingual news documents, we think that if some words appear frequently in the Chinese–Vietnamese news document, the words may be related to news events. Even though the description of the news of Chinese and Vietnamese differs from the point of view and content, the news event is actually the same news event; for example, “Vietnamese fishermen arrested by China,” the descriptions of time, place, people, and specific figures are the same for both Chinese and Vietnamese. At the same time, there are many words such as “starting” and “to make” which appeared in the news documents of the Chinese and Vietnamese, but not too much value of the news documents themselves. Therefore, for the calculation of the weight of such hyperedges, the importance of the Chinese–Vietnamese word contained in the hyperedge must be considered, as shown in the following formula

In formula (9),
Chinese–Vietnamese keyword extraction based on directed diffusion
Wireless sensor networks have a large number of nodes and data-centric features. 18 In the abstract, wireless sensor networks and hypergraphs have similarities. At the same time, directional diffusion protocol 19 is a query-based routing mechanism, which is a typical data-centric routing mechanism. The route-directed diffusion protocol establishes a route by broadcasting an interest message to the network. The message can traverse every node of the wireless sensor network and establishes an interest list of each node to record interest information. This protocol can be applied to the iterative calculation of vertex weights on hypergraphs.
The iterative weighting of hypergraphs uses the interest diffusion phase of the directional routing protocol. In addition, certain changes are made to the original route-directed diffusion protocol. The specific description is as follows.
In the first step, a node
In the second step, from the hyperedge
The transfer matrix

The matrix representation is as follows

where
After that, this article uses the PageRank algorithm to iteratively calculate the vertex weights;

In this article, the damping coefficient
In the iterative process, if the value of
Experiments
Experimental data
This article selects 400 news articles from mainstream news media in China and Vietnam, including 200 Chinese news texts, mainly from websites such as Xinhua News Agency, NetEase News, and Tencent News. The other 200 are Vietnamese news, mainly from Vietnam’s People’s Daily, Vietnam News Agency, Vietnam Daily Express, and other mainstream news media in Vietnam. The average word for each document is about 300–1000.
We first extract the keywords of Chinese news and Vietnamese news through manual selection. Among them, Vietnamese news keywords using Google Translate to translate the article, and then read through the artificial extraction of Vietnamese keywords. In addition, 20 keywords are manually extracted for each news. Finally, we use the method proposed in this article to extract cross-language news keywords in Chinese and Vietnamese. The method outputs the top 20 Chinese words and Vietnamese words as keywords of Chinese documents and Vietnamese documents, respectively, and compares the results obtained by manual extraction to verify the validity of the method. Evaluation criteria are precision, recall rate, and F value index for evaluation.
Documents preprocessing
In order to effectively process the Chinese and Vietnamese bilingual news documents, the news documents must be processed by word segmentation and part of speech. Institute of Computing Technology, Chinese Lexical Analysis System (ICTCLAS) is used to analyze Chinese word segmentation, labeled and entity recognition. And Vietnamese news document analysis uses the vnTokenizer 20 toolkits developed by the Hanoi National University in Vietnam to provide APIs and models for handling Vietnamese participle and labeled. On this basis, Vietnamese word segmentation and part of speech tagging tool are used to achieve the Vietnamese word segmentation and part of speech tagging platform. 21
Experiments and analysis
We compared the results of bilingual news keywords extraction with those of news keywords of single-language environment to judge the effect of the bilingual extraction method mentioned in this article. We use single-language news document keyword extraction method of comparative experiments:
Hypergraph-Directed Diffusion (HDD) for Chinese. For the 200 Chinese news documents in the document set, a single-document news keyword extraction method based on hypergraph sorting is used to construct a Chinese news document hypergraph model. Then, use the HDD algorithm to iteratively calculate and output the highest ranked 20 words as keywords of news documents.
HDD for Vietnamese. Using single-document hypergraph sorting method, we extract keywords from 200 Vietnamese documents in the document set and finally obtain the keywords of Vietnamese news documents.
HDD for Bilingual. Using the Chinese and Vietnamese bilingual hypergraph models mentioned in this article, the hypergraph is constructed, and then, the HDD algorithm is used to calculate the hypergraph. The final output is the highest ranking of 20 Chinese words and 20 Vietnamese words, that is, the keywords of the Chinese–Vietnamese bilingual news document (Table 3).
Experimental results.

From the experimental results, it can be concluded that from the bilingual corpus, the bilingual hypergraph sorting method proposed to this article is better than the one using the single-document hypergraph sorting to extract Chinese and Vietnamese separately. The result of Vietnamese single-document news extraction is the worst, mainly because of the lexical difference between Vietnamese and Chinese; when using the Vietnamese news document set, the method of calculating the feature information using only Chinese words can produce errors. But in the Chinese–Vietnamese bilingual news keywords extraction, for each word, in addition to considering the characteristics of the word in the language environment, the characteristics and calculation method of the word in different language environment are also considered. Therefore, the bilingual news keywords extraction effect than the single-document keyword extraction effect is better. Of course, this is also because the news documents we choose from a bilingual environment are aimed at the more important domestic or international news events. For these news events, the news media in both countries reported that although there are some differences in content, there is some similarity in the content of the documents because the same news events are described.
Table 4 shows the keywords taken under different methods, taking the news document “5.27 China Hitting the Fishing Boat in Vietnam” as an example.
Chinese–Vietnamese news keyword extraction results.

Conclusion
In this article, we propose a bilingual news keyword extraction method based on the hypergraph in view of the characteristics of the news text data, combined with the correlation characteristics of Chinese and Vietnamese bilingual events. This method takes the bilingual words as the vertexes and the bilingual words and the semantic similar bilingual words as the hyperedges and calculates the weights of the hyperedges by the importance degree of the words of the sentences. Then, the bilingual Chinese–Vietnamese hypergraph model is constructed by bilingual dictionaries and bilingual entity library, and the key data are obtained by iteration. The experimental results prove the effectiveness of the proposed method. The use of bilingual multivariate relations has a very good supportive role for the keywords extraction in bilingual events in Chinese and Vietnamese. Further research focuses on how to effectively use bilingual multiple relationships to construct multi-language event hypergraphs such as entity, entity relationship, and sentence relevance in order to find a better method to mine the key data in unstructured big data.
Footnotes
Handling Editor: Songhua Xu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant Nos 61472168, 61672271, and 61732005), High-tech Industry Development Project of Yunnan Province (Grant No. 2016ZA006), Science and Technology Leading Talent Program of Yunnan Province (Grant No. 2017HA001), and Major Science and Technology Project of Yunnan Province (Grant No. 2016ZA006).